使用 Palantir 表征单细胞数据中的细胞状态概率
使用 Palantir 表征单细胞数据中的细胞状态概率
写在前面的概览
Palantir算法主要用于模拟细胞分化的轨迹,将细胞命运视为概率过程,并利用熵来衡量轨迹中的细胞可塑性。它生成细胞的高分辨率伪时间排序,并为每个细胞状态分配分化为每个终态的概率??。
要使用Palantir算法,需要提供一组分化细胞的单细胞RNA测序(scRNA-seq)数据和用户定义的“早期”细胞的表达谱。Palantir使用扩散图和最近邻图来表示表型流形,专注于发展趋势。这种方法旨在有效捕捉分化轨迹。算法构建了一个马尔可夫链来模拟分化作为一个随机过程,推断出终态,并计算每个细胞到达这些终态的分支概率。Palantir为每个细胞分配一个伪时间(相对于起点的距离)和到所有终态的分支概率,从而提供了一个统一的排序,便于对所有谱系的基因表达动态进行精确的表征和比较??。
在RNA速率和轨迹分析方面,Palantir与传统的轨迹分析方法不同,后者通常将分化视为一系列离散的分叉。相反,Palantir提供了一个连续的模型,表明谱系承诺是分层的,细胞逐步倾向于特定的谱系,如淋巴系、红系,最后是髓系。这个模型反映了细胞从干细胞到分化状态的过程中分化潜能(DP)的逐渐丧失,DP的变化标志着推动分化的关键分子和细胞事件??。
因此,Palantir可以被归类为一个轨迹分析工具,重点是将细胞命运选择建模为一个连续的概率过程。它的优势在于能够处理复杂数据集,在分化轨迹上提供高分辨率的映射,并且即使在未富集前体细胞的数据集中也能稳健地恢复表达趋势??
正文内容
摘要
分化系统的单细胞 RNA 测序研究提出了有关分化和细胞命运的离散与连续性质的基本问题。在这里,我们提出了 Palantir,一种算法,通过将细胞命运视为概率过程来模拟细胞分化的轨迹,并利用熵来测量沿轨迹的细胞可塑性。 Palantir 生成细胞的高分辨率伪时间排序,并为每个细胞状态分配分化为每个最终状态的概率。我们将我们的算法应用于人类骨髓单细胞 RNA 测序数据并检测造血分化的重要标志。 Palantir 的解决方案能够识别驱动谱系命运选择的关键转录因子,并密切跟踪细胞何时失去可塑性。我们表明,Palantir 在识别细胞谱系和概括分化过程中的基因表达趋势方面优于现有算法,可推广到不同的组织类型,并且非常适合解决研究较少的分化系统。
Introduction
分化是生物学中最基本的过程之一。在传统观点中,细胞通过一系列离散的、明确定义的阶段从分化程度较低的状态转变为分化程度较高的状态。然而,单细胞研究表明,在分化过程中,细胞状态存在于基本上连续的空间中。尽管思维方式发生了这种演变,但细胞命运决定在很大程度上仍然被概念化为发育过程中一系列离散的分叉,导致细胞的终末状态。
然而,表观遗传学研究支持细胞命运选择的概率观点。表观基因组测量,例如 DNase I 超敏位点测序 (DNase-seq) 和使用测序进行转座酶可及染色质分析 (ATAC-seq),通过指示渐进增强子限制以及预先建立谱系特异性增强子,提示了连续过程的潜在机制在前体细胞中,可以作为驱动分化的载体。事实上,在人类骨髓中,当单细胞 RNA 测序(scRNA-seq)图谱沿着最强的变异轴投影时,我们观察到缺乏明确的分叉点(图 1a)。即使在单个基因的水平上,我们也发现了基因比率的广泛代表性,而不是双峰表达状态(图1a)。这些观察结果提出了一些基本问题:细胞命运(类似于细胞状态转变)是否是连续的,以及细胞命运选择何时以及如何做出。
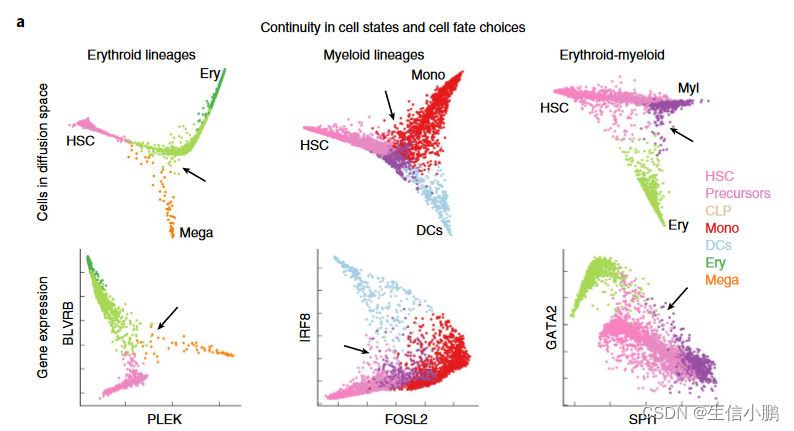
为了研究这些问题,我们开发了 Palantir,这是一种利用 scRNA-seq 数据对分化景观进行建模并表征细胞状态和命运选择的连续性的算法。由于分化是异步的,对分化细胞群进行测序会产生代表一系列细胞状态的快照。基于来自单个样本的 scRNA-seq 数据和代表性早期细胞的选择,Palantir 生成细胞的伪时间排序,并为每个细胞状态分配分化为每个最终状态的概率。我们应用 Palantir 使用约 25,000 个富含 CD34(造血干细胞和祖细胞标记物)的细胞的 scRNA-seq 图谱来表征人类造血分化。 Palantir 确定了已建立的终端状态,并沿着伪时间对细胞进行排序,概括了已知的发育标记趋势。
值得注意的是,Palantir 确定了分化潜力 (DP) 急剧变化的轨迹上的点。这些转变标志着造血过程中的关键事件。因此,Palantir 提供了一种定量方法来表征细胞命运选择的连续模型。
结果
马尔可夫过程
分化通过细胞分裂进行,其中子细胞通常与其母细胞非常相似。因此,群体是通过增量分歧建立的,由调节机制驱动,这些机制在可能的细胞状态(表型)空间中创建路径。调节将细胞状态限制为可能表型的低维流形。最近邻图,其中每个节点代表特定的细胞状态,边连接最相似的细胞,已被广泛用于对流形进行建模。
单个骨髓样本包含造血细胞状态的全谱,重要的是每种细胞状态的频率。我们利用细胞状态频率来告知我们的模型邻居图中可能的分化路径及其可能性。重要的是,沿图的路径表示群体中细胞的可能轨迹,而不是特定细胞的路径,并且每个细胞状态(图节点)与到达最终状态的概率分布相关联。我们断言,细胞以小步遍历流形,可以基于两个关键假设,使用马尔可夫链进行建模,以概率方式表示细胞命运选择。首先,与所有伪时间推理算法(1、3、7、8,这里是原文的参考文献,可以翻阅原文)一样,我们假设从低分化状态到高分化状态的单向进展。我们假设它是健康分化的合理一阶近似,但请注意,它在癌症等异常系统中失败,因为癌症需要额外的信息(例如突变)来确定方向性。其次,我们假设对于任何节点,遍历到任何邻居的概率与其历史记录(即到达该状态所采取的路径)无关。请注意,对于特定细胞,细胞的发育历史可能被编码在其表观遗传特征中,并且可能会影响细胞命运的选择。
然而,**节点是代表多个历史和潜在轨迹的抽象细胞状态, 而不是单个细胞的路径。**考虑到进入该细胞状态的所有过去路径,我们可以根据图流形中节点的结构和连接性计算未来状态的群体水平概率。
The Palantir algorithm
给定来自分化细胞样本的 scRNA-seq 数据和用户定义的“早期”细胞的表达谱,Palantir 沿着伪时间对细胞进行排序,表征终末分化状态,并为每个细胞分配代表细胞分支的概率分布达到每个最终状态的概率(补充说明1)。
首先,我们使用最近邻图来表示表型流形(补充图1a和补充注1)。我们使用扩散图 来关注发育趋势,并避免 scRNA-seq 中稀疏性和噪声导致的虚假边缘。将数据投影到顶部扩散组件上可以有效地将边缘集中在高细胞密度的方向上,并重新权衡沿这些方向的相似性(补充图1a)。扩散图以前曾用于研究单细胞数据,并且特别擅长捕获分化轨迹。与其他工具不同,Palantir 在计算细胞的伪时间排序时使用多个扩散组件,因为我们观察到单个扩散组件只能近似导致命运子集的轨迹(补充图 2)。来自用户定义的早期细胞的最短路径启动伪时间,然后通过识别距路点(采样以跨越分化景观的细胞集)的最短距离来迭代细化伪时间(补充图1b-c)。计算出的伪时间并不代表单个轨迹,而是为每个细胞分配与初始细胞的相对距离,无论其谱系或最终命运如何。
我们使用邻域图和伪时间构建马尔可夫链,将分化建模为随机过程,其中细胞通过流形中的一系列步骤达到一个或多个最终状态(图1b)。
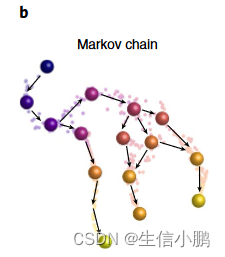
伪时间提供了方向性,用于以与排序一致的方式定向邻居图中的边缘(补充图1d-e)。对于每个有向边,我们分配一步到达相邻单元的转移概率。到达更远的单元的概率是通过多个步骤计算的,如果有许多路径连接它们,那么到达更远的单元的概率就会很高——也就是说,观察到的中间单元状态的密度很高(补充图1f和补充注释1)。因此,虽然每个步骤都是随机的,但在较长的距离上,流形图结构隐式地编码了发展轨迹。
马尔可夫链还用于从数据推断终端状态。 Palantir 将终端状态识别为边界单元(扩散分量的极值),它们是平稳分布中的异常值,即随机游走收敛的状态(图 1c)。
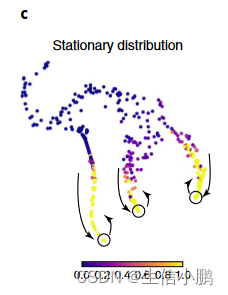
一旦确定了终端状态,我们就将它们转换为没有传出边缘的吸收状态。在吸收马尔可夫链中,从任何状态开始的随机游走都将继续,直到到达终端吸收状态。对于每个单元,Palantir 然后整合从单元到每个可能的最终状态的所有可能的随机游走,以产生分支概率向量(补充图 1f、g)。我们将细胞的分化潜能(DP)定义为分支概率的熵,为细胞可塑性提供定量指标(图1d和补充图1h)。
Palantir 为每个单元分配伪时间(距起点的相对距离)和所有终止状态的分支概率。因此,Palantir 的伪时间提供了统一的排序,可以精确对齐、表征和比较所有谱系的基因表达动态,而无需选择谱系子集中的细胞(补充说明 1)。根据这个顺序,我们使用广义加性模型计算基因表达趋势,根据分支概率权衡每个细胞的贡献(图1e,补充图3和补充说明2)。
广义加性模型特别适合导出非线性趋势的稳健估计并估计预测的标准误差。
介绍算法部分着实有些难度,有必要的话,应该翻阅原文进行学习。
早期人类造血的景观
造血是一个经过充分研究的生物过程,具有已建立的标记以促进谱系的识别,并且已经使用它作为模型系统开发了许多伪时间算法??。虽然 scRNAseq 已广泛用于研究小鼠的造血作用,但我们选择研究早期人类造血作用,因为单细胞研究在不可能发生扰动的系统中特别有帮助。造血作用传统上被描述为一系列导致成熟、终末细胞状态的分叉,但分选群体的单细胞分析表明命运分配的连续过程。关于细胞命运选择如何在人类造血的最早阶段决定以及早期祖细胞的可塑性程度仍然存在基本问题。为了研究这些细胞命运选择,我们使用 10X Chromium 从 3 名人类骨髓捐赠者中生成了大约 25,000 个珠纯化的 CD34+ 细胞的单细胞转录组(方法)。
我们首先使用 PhenoGraph13 对 scRNA-seq 配置文件进行聚类(补充图 4a)。我们鉴定了完整的造血细胞,包括造血干细胞和祖细胞,以及分化为淋巴样、红细胞、单核细胞、经典树突状细胞和浆细胞样树突状细胞(分别为cDC和pDC)谱系和巨核细胞的细胞(图2a,b)和补充图 4b,c)19,20。造血干细胞和祖细胞约占总分选细胞的 63%。由于 CD34 纯化不完善(纯度约 90%)以及表面蛋白水平与信使 RNA 相比存在时间滞后,也检测到了谱系定型细胞。
Palantir 概括了预期的造血趋势
我们将 Palantir 应用于造血数据,选择 CD34 高细胞作为起始细胞(方法),并分别分析三个重复,以评估稳健性。该算法正确识别了所有预期的细胞类型,包括单核细胞、红细胞、巨核细胞、淋巴祖细胞和两个树突细胞群,作为最终状态(图2b,c)。 Palantir确定的伪时间顺序遵循从造血干细胞(HSC)到分化细胞类型的预期进展(图2c),

并且伪时间开始时的细胞有可能达到任何最终状态,并逐渐丧失当它们致力于特定的谱系时,它们具有可塑性(图2d,e)。
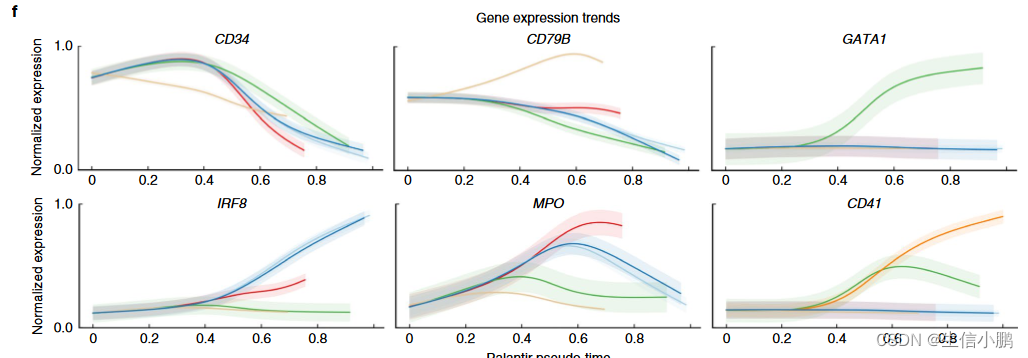
为了评估轨迹,我们计算了关键标记的表达趋势(图2f)。正如预期的那样,随着细胞commit11,CD34在所有谱系中均呈现下降趋势,而谱系特异性因子(例如CD79A、GATA1和IRF8)分别在淋巴、红细胞和树突细胞谱系中选择性上调。 MPO 在所有谱系中都显示出最初的上升趋势,随后仅在单核细胞谱系中保持不变(图 2f)。最后,CD41 表达与其作为早期红细胞和巨核细胞前体细胞标志物的作用一致,表现出巨核细胞谱系的持续上调。
接下来我们评估了 Palantir 的稳健性和可重复性。我们的实验表明,伪时间和 DP 对各种参数都具有鲁棒性,包括用于图构建的邻居数量、扩散分量的数量以及路点的不同采样和单元的子采样(参见补充图 5-8)和方法)。 Palantir 对来自不同骨髓捐赠者的数据集的独立应用之间的伪时间和 DP 高度相关(补充图 9-11),并且基因表达趋势在生物重复中也是可重现的(补充图 11)。这些发现共同表明 Palantir 结果是可重复的,并表明它们正确地表征了早期造血过程中的基因表达动态。
在文中还做了一些其他的例子,如 识别造血分化标志, 小鼠造血和结肠分化分析, 红细胞参与的转录调控。可以仔细再研读一下。
与轨迹推理算法的比较
虽然在解决细胞排序方面已经取得了重大进展,但最先进的伪时间算法继续将分化建模为一系列离散的、确定性的分叉,主要通过数据聚类来近似。我们将 Palantir 与领先且广泛使用的伪时间算法进行了比较,例如 Monocle2、基于分区的图抽象 (PAGA)、扩散伪时间 (DPT)、Slingshot和 FateID。
我们根据算法识别谱系和恢复人类造血中已知基因表达趋势的能力来评估算法,这是一个经过充分研究的系统,在地面实况基准上达成了科学共识(补充图 17-22 和补充说明 6)。特别是,我们评估了它们识别低频谱系(例如巨核细胞、cDC 和 pDC)的能力,并恢复关键基因(例如 CD34(参考文献 11)、MPO(参考文献 38)、CD79B(参考文献 39))的表达趋势的能力。 )、GATA1(参考文献 28)、CSF1R(参考文献 40)和 CD41(参考文献 21)。我们还比较了生成的输出的性质以及作为每个算法的输入所需的先前生物学知识的数量。 Palantir 需要最少量的先验生物信息(起始细胞),并提供伪时间和细胞命运概率作为输出(补充图 17a)。然而,PAGA 是唯一允许通用拓扑结构的算法。
Palantir 通过区分两个树突细胞群、识别与红系谱系分开的巨核细胞(图 2e 和补充图 6)以及准确恢复关键谱系基因的表达动态(图 2e 和补充图 6),优于其他算法(补充图 17b)。图2f;评估详情另见补充说明6)。 Monocle 2(参考文献 17)和 FateID(使用 RaceID 聚类)未能生成连贯的造血图(补充图 18 和 21)。 PAGA41 和 DPT3 识别主要谱系,但无法识别较稀有的谱系,并且无法解析基因表达趋势(补充图 19)。 Slingshot识别了主要谱系,但没有识别稀有种群,导致不正确的基因表达动态(补充图 20),并且它没有提供统一的框架来比较跨谱系的表达趋势8。使用 Palantir 预处理和聚类的 FateID对于大多数细胞命运概率来说仍然很大程度上不正确,而且更重要的是,它包括淋巴谱系中的所有早期细胞,导致表达动态特征错误(补充图 21)。最后,虽然单个扩散成分已用于模拟分化轨迹15,42,但在 CD34+ 人骨髓数据中,它们只能用于推断淋巴和单核细胞谱系的排序(补充图 22)。值得注意的是,上面讨论的算法都没有明确地建模和量化沿微分景观的可塑性和分支概率。总而言之,只有 Palantir 能够准确地将关键转录因子的表达变化与这些调控谱系的变化联系起来。
讨论
与现有算法不同,Palantir 生成细胞命运选择的概率模型作为一个连续过程。 Palantir 对参数具有鲁棒性,可在重复中重现,并可推广到不同的数据集。 Palantir 沿分化轨迹绘制的细胞高分辨率图谱使我们能够表征驱动造血谱系选择的调节因子的顺序和时间。我们的研究结果表明,DP 在从干细胞到分化细胞的过程中逐渐下降,并且是分层的,因此细胞依次倾向于淋巴系、红系,最后是骨髓系(每个谱系内的电位逐渐下降)。
Palantir 伪时间高分辨率的关键是使用多个扩散分量和邻近图来测量该嵌入空间中细胞之间的距离(补充图 23a-c)。这使得马尔可夫链的构建成为可能,这对于谱系选择中的终端状态识别和连续性建模至关重要。 Palantir 在恢复生物学上一致的基因表达趋势和谱系关系方面优于其他伪时间算法,这些算法主要将谱系选择视为离散分叉。富集骨髓中的干细胞和前体细胞对于以高分辨率表征早期人类造血的谱系选择是必要的。然而,Palantir 可以稳健地恢复未富集前体的数据集中的表达趋势。
我们预计 Palantir 将成为许多特征较少的系统的有价值的发现工具,包括人类细胞图谱项目所描述的系统。一个关键的必要条件是存在全系列的分化细胞,这是由于骨髓、结肠和嗅上皮等组织中分化的异步性质而成为可能。我们注意到这不是胚胎发生的一个特征,胚胎发生通常是使用时间过程实验来研究的。时间过程数据需要对时间点之间的连接性进行显式建模,并针对批次效应的混淆进行修正。
包括 Palantir 在内的伪时间算法做出的最重要的假设是,分化是单向的,并且朝着功能成熟的细胞进行。虽然这对于健康分化来说是合理的,但在组织再生和癌症等系统中违反了这一假设。如果细胞去分化或转分化到早期转录状态,仅 scRNA-seq 数据将不足以区分这些群体及其分化路径。体内谱系追踪技术可以为谱系关系提供基础事实,但需要基因改造,因此不适合研究人体组织中的癌症进展、转移和健康发育。作为替代方案,突变在大多数癌症中迅速发生,并且可以为人类系统提供方向性和谱系信息的来源。最近的研究表明,体细胞突变的发生速度甚至可以在健康的人体组织中进行谱系追踪。同时分析转录组和 DNA 的能力通过扩展 Palantir 将谱系信息纳入细胞命运决策模型,具有阐明疾病发生和进展的巨大潜力。
这篇文献涉及到轨迹分析和推理,但更多是在造血系统中的应用,在肿瘤领域的应用还是有限的。具体如何拓展还要在未来继续深入研究。
学习文献
Setty, M., Kiseliovas, V., Levine, J. et al. Characterization of cell fate probabilities in single-cell data with Palantir. Nat Biotechnol 37, 451–460 (2019). https://doi.org/10.1038/s41587-019-0068-4

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!