使用apriori来挖掘关联规则
2023-12-14 16:50:19
1、apriori最重要的三个概念:
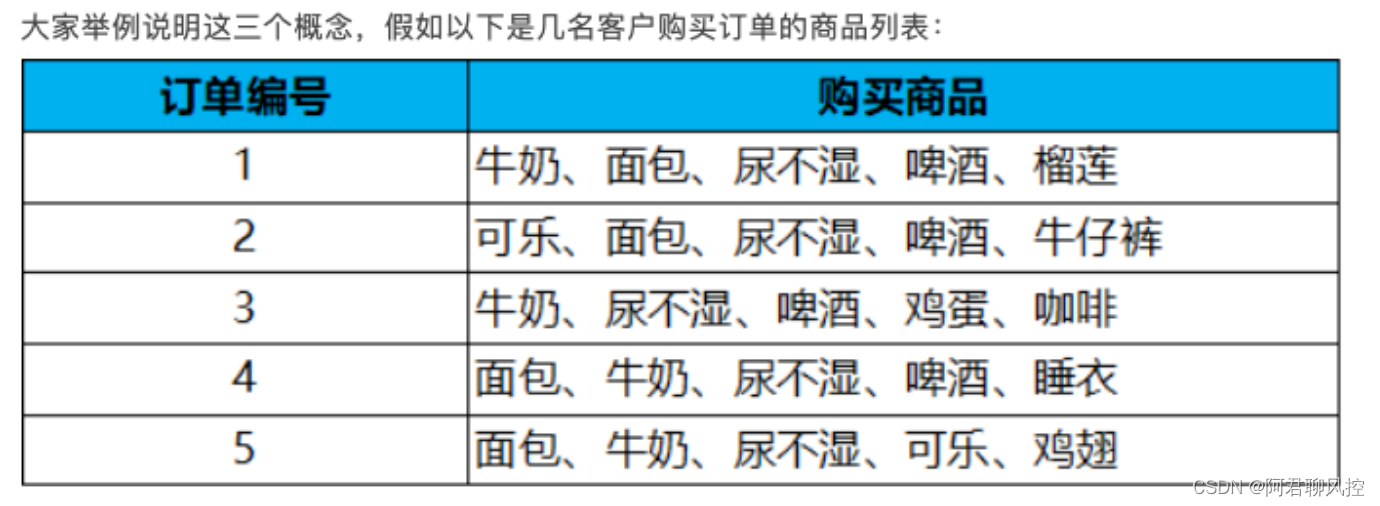
1、支持度
支持度 (Support):指某个商品组合出现的次数与总订单数之间的比例。
在这个例子中,我们可以看到“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是 4/5=0.8。
2、置信度
置信度 (Confidence):指的就是当你购买了商品 A,会有多大的概率购买商品 B,在包含A的子集中,B的支持度,也就是包含B的订单的比例。
置信度(牛奶→啤酒)= 3/4=0.75,代表购买了牛奶的订单中,还有多少订单购买了啤酒
3、提升度
提升度 (Lift):我们在做商品推荐或者风控策略的时候,重点考虑的是提升度,因为提升度代表的是A 的出现,对B的出现概率提升的程度。
提升度 (A→B) = 置信度 (A→B)/ 支持度 (B)
所以提升度有三种可能:
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
提升度 (啤酒→尿不湿) =置信度 (啤酒→尿不湿) /支持度 (尿不湿) = 1.0/0.8 = 1.25,可见啤酒对尿不湿是有提升的,提升度为1.25,大于1。
可以简单理解为:在全集的情况下,尿不湿的概率为80%,而在包含啤酒这个子集中,尿不湿的概率为100%,因此,子集的限定,提高了尿不湿的概率,啤酒的出现,提高了尿不湿的概率。
2、风控策略自动化挖掘
在电商的聊天对话中,有大量的欺诈消息和垃圾消息,挖掘看看哪些是高风险的词汇,可以当成违禁词库,直接进行屏蔽了。下面数据集包含欺诈消息文本:
示例:
我是做涮.单的,提高店铺等.级,排.名,权.重,好.评,成交率,让顾客进店更信任,从而快速下单,提高成交率全网最低价+V咨.询,免费送100粉丝,提高店铺活跃度:Rreeww6
安全提醒:支付完成已冻结 商户未提升额度《收款超额》导致您购买的商品资金冻结,双方无法查到交易详情,请商家复制以下订单编号至手机浏览器恢复出售。 36.xxx.com
系统提醒:商铺暂停交易,由于【店铺收款累计额度超出】导致,请等待商户设置完成后再试。商户复制以下链接至手机浏览器打开!4s.shanghu872.cc
系统通知:已停止支付,检测到该商户存在风险,【收银上限】导致,请商家复制网址联系专员解开上限!237.xx.cc
警告??通知:拒绝?支付,当前店铺存在风险《店铺流水未重新认证》请商家及时复制链接到浏览器联系专员重新认证。237.xxx.cc
系统提示:支付已拦截,商铺未授权收款上限导致,请等待店主设置完成再试,店主复制以下链接至手机浏览器打开恢复!xx-5l.com
安装python包
pip install mlxtend -i https://pypi.tuna.tsinghua.edu.cn/simple
代码:
import jieba
from mlxtend.frequent_patterns import apriori
from mlxtend.preprocessing import TransactionEncoder
import pandas as pd
dataset = []
for line in open("im_cheat_msg.csv"):
ll = line.strip()
words = jieba.cut(ll)
cut_words = list(words)
dataset.append(cut_words)
# 将数据集转换为二进制矩阵
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 使用Apriori算法查找频繁项集
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
frequent_itemsets_df = pd.DataFrame(frequent_itemsets)
# 打印频繁项集
frequent_itemsets_df.to_csv("im_msg_cheat_apriori_res.csv", sep = "\t")
结果:
support itemsets
0 0.9655172413793104 frozenset({'.'})
1 0.43103448275862066 frozenset({':'})
2 0.5344827586206896 frozenset({'cc'})
3 0.5172413793103449 frozenset({'商家'})
4 0.6724137931034483 frozenset({'复制'})
5 0.4482758620689655 frozenset({'导致'})
6 0.41379310344827586 frozenset({'已'})
8 0.4482758620689655 frozenset({'您'})
9 0.46551724137931033 frozenset({'未'})
10 0.5517241379310345 frozenset({'浏览器'})
11 0.43103448275862066 frozenset({'订单'})
12 0.6379310344827587 frozenset({'请'})
。。。
54 0.3258426966292135 frozenset({'!', '请', '.'})
55 0.3146067415730337 frozenset({'复制', '链接', 'cc'})
56 0.3146067415730337 frozenset({'请', '浏览器', '复制'})
57 0.3146067415730337 frozenset({'浏览器', '链接', '复制'})
58 0.3146067415730337 frozenset({'.', '复制', '链接', 'cc'})
59 0.3146067415730337 frozenset({'.', '请', '浏览器', '复制'})
60 0.3146067415730337 frozenset({'.', '浏览器', '链接', '复制'})
进一步的
import jieba
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import fpgrowth
from mlxtend.frequent_patterns import association_rules
import pandas as pd
dataset = []
for line in open("im_cheat_msg.csv"):
ll = line.strip().replace(",","")
words = jieba.cut(ll)
cut_words = list(words)
dataset.append(cut_words)
# 将数据集转换为二进制矩阵
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 使用Apriori算法查找频繁项集
frequent_itemsets = apriori(df, min_support=0.3, use_colnames=True)
# frequent_itemsets_df = pd.DataFrame(frequent_itemsets)
# # 打印频繁项集
# frequent_itemsets_df.to_csv("im_msg_cheat_apriori_res_2.csv", sep = "\t")
#求关联规则,设置最小置信度为0.3
rules = association_rules(frequent_itemsets,
metric = 'confidence',
min_threshold = 0.3
)
rules.rename(columns = {'antecedents':'from','consequents':'to','support':'sup',
'confidence':'conf'},inplace = True)
rules = rules[['from','to','sup','conf','lift']]
print(rules)
# rules = rules[rules['to']==frozenset({'Risk'})]
rules['from'] = rules['from'].apply(lambda x:set(x))
rules['to'] = rules['to'].apply(lambda x:set(x))
rules.to_csv('rules_1.csv',header=True,index=False)
from to sup conf lift
0 (cc) (.) 0.370787 1.000000 1.483333
1 (.) (cc) 0.370787 0.550000 1.483333
2 (商家) (.) 0.337079 1.000000 1.483333
3 (.) (商家) 0.337079 0.500000 1.483333
4 (.) (复制) 0.483146 0.716667 1.483333
.. ... ... ... ... ...
185 (链接, 复制) (浏览器, .) 0.314607 0.848485 2.097643
186 (浏览器) (链接, ., 复制) 0.314607 0.777778 2.097643
187 (.) (浏览器, 链接, 复制) 0.314607 0.466667 1.483333
188 (链接) (浏览器, ., 复制) 0.314607 0.848485 2.097643
189 (复制) (浏览器, ., 链接) 0.314607 0.651163 2.069767
文章来源:https://blog.csdn.net/u010569893/article/details/134995712
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!