语音识别之百度语音试用和OpenAiGPT开源Whisper使用
0.前言: 本文作者亲自使用了百度云语音识别,腾讯云,java的SpeechRecognition语言识别包 和OpenAI近期免费开源的语言识别Whisper(真香警告)介绍了常见的语言识别实现原理
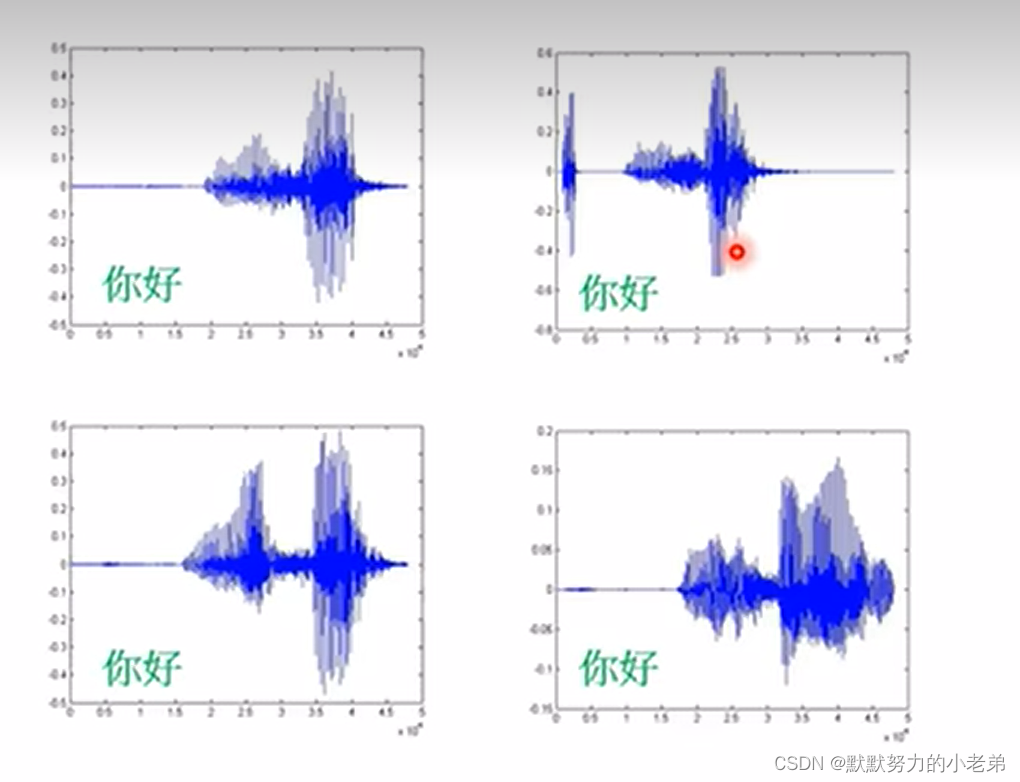
1.NLP 自然语言处理(人类语言处理) 你好不同人说出来是不同的信号表示
单位k 16k=16000个数字表示 1秒16000个数字(向量)表示声音
图 a a1

2.处理的类别
audition-->text
audition-->audition
class-->audition(hey siri)
3.深度学习带来语言的问题 一定几率合成错误
发财发财发财
发财发财 //语气又不一样
发财 //只有发
语言分割(两个人同时说话)
(电信诈骗)语气声调模仿
4.怎么辨识
word 一拳超人 一拳 超人 一拳超 人
personal computer
morpheme 根 unbreakable的break
bytes 不同语言按01标识, language independent
grapheme
5.常用的模型
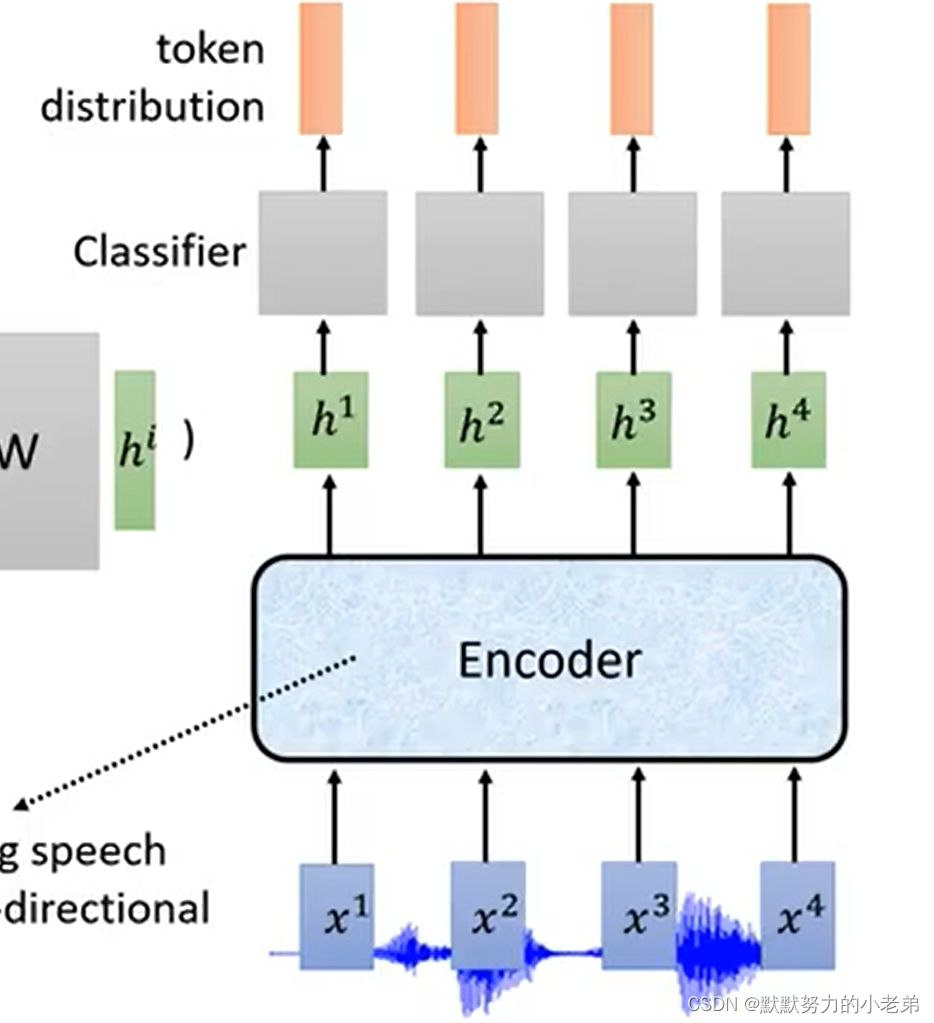
- LAS 提取范围feature decoder->attention 相邻信息差不多,不能事实翻译
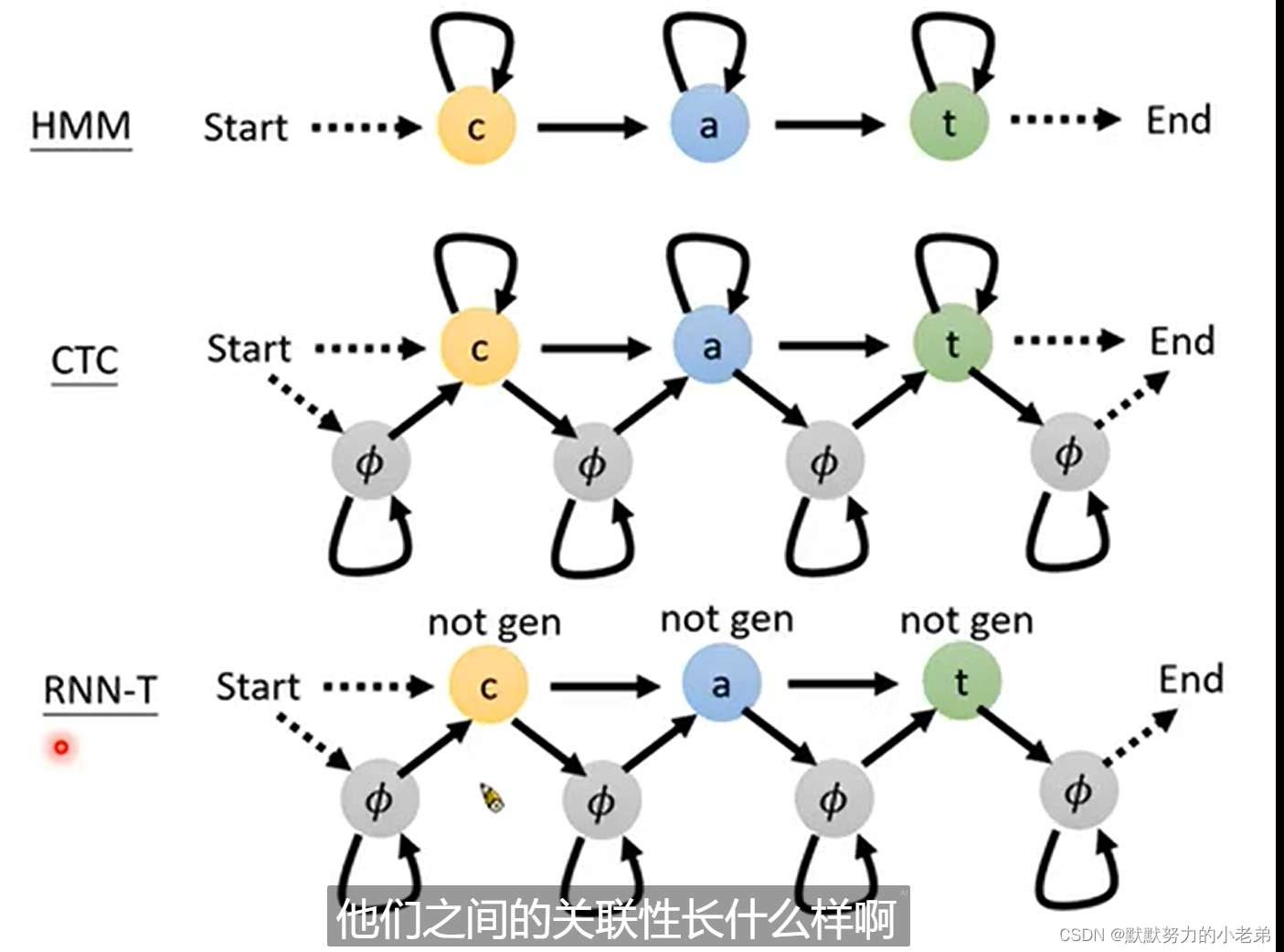
- CTC sequence to sequence 可实时输出 图ctc 好null好null棒棒>棒–>好棒
要自己制作label null null好棒 好 null好棒- RNN-T sequence to sequence 如果前面结果满意就处理next
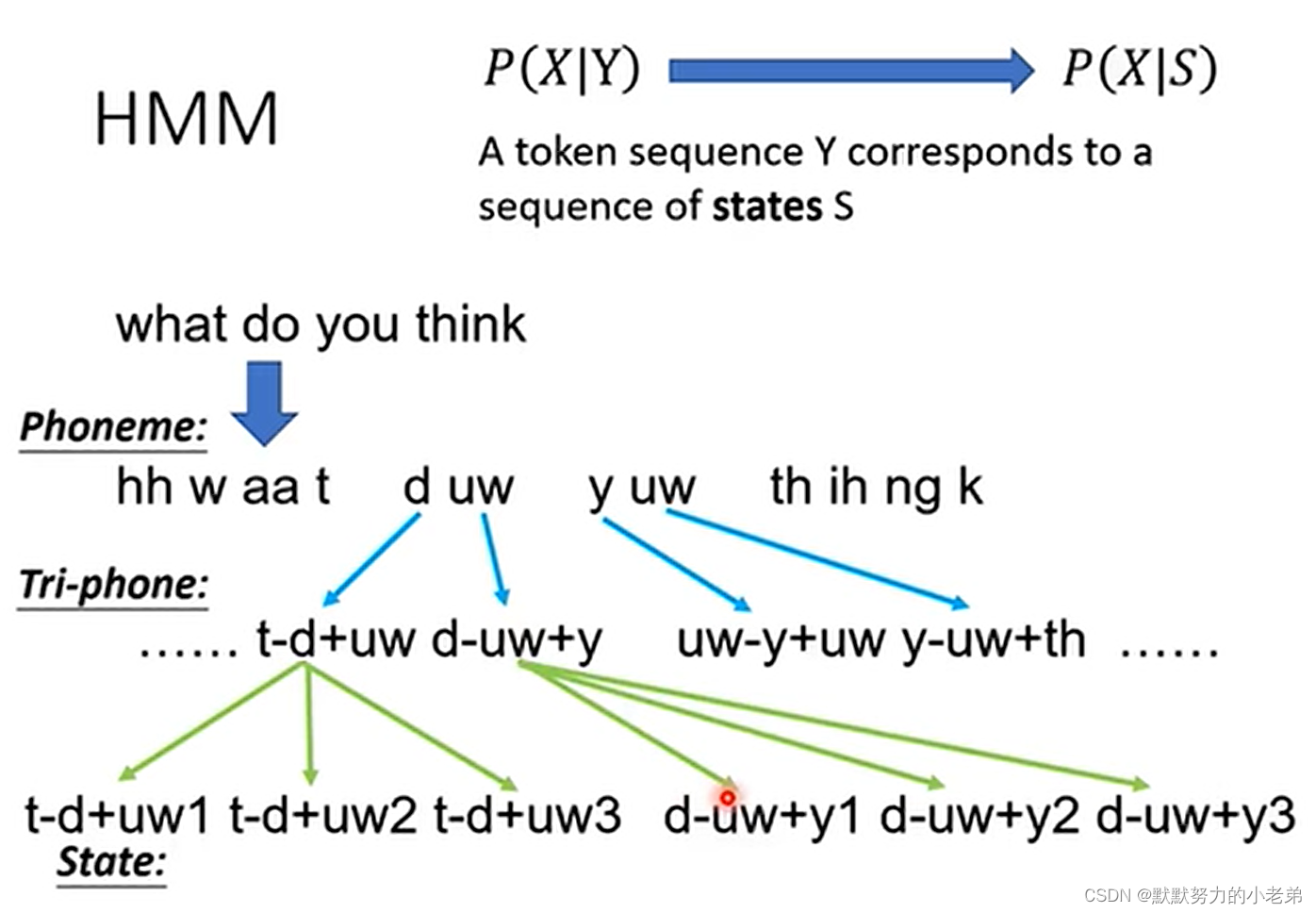
图rnnt/1 解决自己train的label,窗口移动做范围attention MoChA window 大小动态的变化- HMM: 过去没有深度学习的解决方案 ,phoneme 发音 为单位猜概率,tri-phone : what do you
–>do发音受what和you影响
预测下一个的几率 图hmm1
图ctc
图hmm
6.深度学习使用到模型上
Tandem 09年满大街, 得到训练的语音概率,再放到模型运行
DNN-HMM HyBrid 2019(google IBM 5%错误率)主流 DNN(使用一个文件)可以训练
对比 图(not gen代表没有路径可以抵达)
7.js可以使用语音识别(调用google aip,国内被封需要科学上网)
//真香,不过(科学上网,再开个node服务器)公司使用会不会有纷争就不知道了
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>语音识别示例</title>
</head>
<body>
<h1>语音识别示例</h1>
<button id="start-btn">开始识别</button>
<button id="stop-btn">停止识别</button>
<div id="result-div"></div>
<script>
// 获取DOM元素
const startBtn = document.querySelector('#start-btn');
const stopBtn = document.querySelector('#stop-btn');
const resultDiv = document.querySelector('#result-div');
// 创建一个SpeechRecognition对象
const recognition = new webkitSpeechRecognition();
// 设置语音识别参数
recognition.lang = 'zh-CN'; // 设置语言为中文
recognition.continuous = true; // 设置为连续模式
// 开始语音识别
startBtn.addEventListener('click', function() {
recognition.start();
});
// 停止语音识别
stopBtn.addEventListener('click', function() {
recognition.stop();
});
// 监听语音识别结果
recognition.onresult = function(event) {
const result = event.results[event.resultIndex][0].transcript;
resultDiv.innerHTML += `<p>${result}</p>`;
};
// 监听语音识别错误
recognition.onerror = function(event) {
console.error('语音识别错误:', event.error);
};
</script>
</body>
</html>
- 使用SpeechRecognition 没有中文包,识别英文全是oh
9.百度云语音识别(能识别就是没有说话的时候出现奇奇怪怪的句子) 免费半年还挺好的,腾讯云只有5000次调用试用
//图baidu
//识别语音的文件,controller只需要得到io流放到byte数据就可以识别,我觉得每次生成一个pcm应该就不会出现下图的识别识别的情况
import java.io.File;
import java.io.FileInputStream;
import java.util.HashMap;
import com.baidu.aip.speech.AipSpeech;
import org.json.JSONObject;
public class test01 {
// 在百度 AI 平台创建应用后获得
private static final String APP_ID = "xxxx";
private static final String API_KEY = "xxxx";
private static final String SECRET_KEY = "xxxxx";
public static void main(String[] args) throws Exception {
// 初始化 AipSpeech 客户端
AipSpeech client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
// 设置请求参数
HashMap<String, Object> options = new HashMap<String, Object>();
options.put("dev_pid", 1537); // 普通话(支持简单的英文识别)
// 读取音频文件
File file = new File("path/to/audio/file.pcm");
FileInputStream fis = new FileInputStream(file);
byte[] data = new byte[(int) file.length()];
fis.read(data);
fis.close();
// 调用语音识别 API
JSONObject result = client.asr(data, "pcm", 16000, options);
if (result.getInt("err_no") == 0) {
String text = result.getJSONArray("result").getString(0);
System.out.println("识别结果:" + text);
} else {
System.out.println("识别失败:" + result.getString("err_msg"));
}
}
}
//实时录音测试
//图baidu
//优化需要像图片处理一样,直接上传文件而不是流
import java.util.HashMap;
import javax.sound.sampled.*;
import com.baidu.aip.speech.AipSpeech;
import org.json.JSONObject;
public class test01 {
// 在百度 AI 平台创建应用后获得
private static final String APP_ID = "xxxxxxx";
private static final String API_KEY = "xxxxxx";
private static final String SECRET_KEY = "xxxxxx";
public static void main(String[] args) throws Exception {
// 初始化 AipSpeech 客户端
AipSpeech client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
// 设置请求参数
HashMap<String, Object> options = new HashMap<String, Object>();
options.put("dev_pid", 1537); // 普通话(支持简单的英文识别)
// 获取麦克风录制的音频流
AudioFormat format = new AudioFormat(16000, 16, 1, true, false);
TargetDataLine line = AudioSystem.getTargetDataLine(format);
line.open(format);
line.start();
// 创建缓冲区读取音频数据
int bufferSize = (int) format.getSampleRate() * format.getFrameSize();
byte[] buffer = new byte[bufferSize];
// 循环读取并识别音频数据
while (true) {
int count = line.read(buffer, 0, buffer.length);
if (count > 0) {
// 调用语音识别 API
JSONObject result = client.asr(buffer, "pcm", 16000, options);
if (result.getInt("err_no") == 0) {
String text = result.getJSONArray("result").getString(0);
System.out.println("识别结果:" + text);
} else {
System.out.println("识别失败:" + result.getString("err_msg"));
}
}
}
}
}
10.腾讯云语音识别 5000条免费,读者可以自己下载项目看看
//控制台
https://console.cloud.tencent.com/asr#
//项目地址
https://github.com/TencentCloud/tencentcloud-speech-sdk-java
11.使用whisper(2022年9月21日开源的,openAI格局真的大,腾讯云实时识别都要1个小时2块钱不过也不贵,但是对于大多数公司来说要压缩成本,嵌入式也有tiny版本的模型来使用)
- 安装python3.10
pip3 install torch torchvision torchaudio
2.powershell安装coco和ffmpeg
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
//切换阿里源,找不到ffmpeg(专门来处理音频的)如果不安装就找不到路径和文件
choco source add --name=aliyun-choco-source --source=https://mirrors.aliyun.com/chocolatey/
choco source set --name="'aliyun-choco-source'"
choco source list
choco install ffmpeg
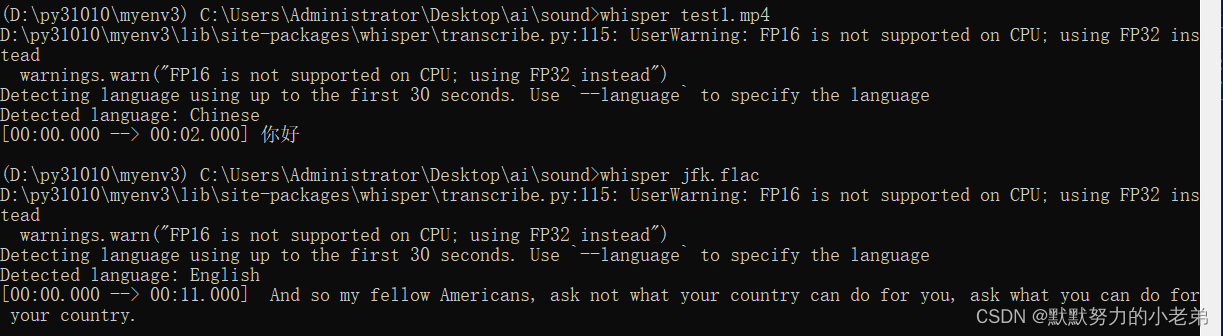
2.测试 速度挺快的,用小一点的模型岂不是慢一定可以通过准确又快速的半实时语言识别!!!
whisper test1.mp4
结果
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!