【AI】YOLO学习笔记三-YOLOV5代码解析
YOLOv5是Glenn Jocher等人研发,它是Ultralytics公司的开源项目。YOLOv5根据参数量分为了n、s、m、l、x五种类型,其参数量依次上升,其效果也是越来越好。由于其代码是长期维护的且具有工程化的思维,所以方便应用在实际的项目中,对于CV领域的初学者来说,其代码具有很高的参考价值。
我从自己学习的角度来说,很多时候我们读论文和读源码是有割裂感的,论文的内容比较精练,理解起来较为困难,源码的内容比较直接,但是其组织又是比较松散,结合论文和源码综合来理解,可能就会事半功倍了。
1.训练数据处理
要训练模型数据是第一步的,我们先看一下YOLO 5是怎么进行数据处理的。Torch框架处理数据的目标就是要构建Dataset和Dataloader,YOLO V5的构建代码在dataset.py模块中,可以从create_dataloader方法看起,这里面首先创建了LoadImagesAndLabels类:
dataset = LoadImagesAndLabels(path, imgsz, batch_size, # 路径、图像大小、batch大小
augment=augment, # augment images 是否进行数据增强
hyp=hyp, # augmentation hyperparameters 超参数
rect=rect, # rectangular training
cache_images=cache, #缓存文件
single_cls=opt.single_cls, #单类别用到
stride=int(stride), #降采样比例-32
pad=pad, #马赛克用
rank=rank)
LoadImagesAndLabels继承自dataset类,最重要的是__init__方法和__getitem__方法的实现:
__init__方法
init方法主要做的事情是将数据和标签从存储路径中取出
首先将图像取出,这里兼顾了windows系统和linux系统,方便大家用不同的环境。
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]: #win和linux有点区别 所以这里面代码稍微处理的内容多了点
p = str(Path(p)) # os-agnostic
parent = str(Path(p).parent) + os.sep
if os.path.isfile(p): # file
with open(p, 'r') as t:
t = t.read().splitlines()
f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
elif os.path.isdir(p): # folder
f += glob.iglob(p + os.sep + '*.*') #所有数据全部取出
else:
raise Exception('%s does not exist' % p)
self.img_files = sorted(
[x.replace('/', os.sep) for x in f if os.path.splitext(x)[-1].lower() in img_formats])
except Exception as e:
raise Exception('Error loading data from %s: %s\nSee %s' % (path, e, help_url))
然后计算跟batch有关的一些参数
n = len(self.img_files)
assert n > 0, 'No images found in %s. See %s' % (path, help_url)
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index #batch索引
nb = bi[-1] + 1 # number of batches #一个epoch有多少个batch
保存类构造及读取的一些参数值
self.n = n # number of images
self.batch = bi # batch index of image
self.img_size = img_size
self.augment = augment
self.hyp = hyp
self.image_weights = image_weights
self.rect = False if image_weights else rect
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
self.mosaic_border = [-img_size // 2, -img_size // 2] #限定范围
self.stride = stride#下采样总值
然后进行标签的处理,首先会加载标签缓存,如果没有,就会新建
# Check cache #可以设置缓存,再训练就不用一个个读了
cache_path = str(Path(self.label_files[0]).parent) + '.cache' # cached labels
if os.path.isfile(cache_path):
cache = torch.load(cache_path) # load
if cache['hash'] != get_hash(self.label_files + self.img_files): # dataset changed
cache = self.cache_labels(cache_path) # re-cache
else:
cache = self.cache_labels(cache_path) # cache
然后对标签的类别做处理
pbar = enumerate(self.label_files)
if rank in [-1, 0]:
pbar = tqdm(pbar) #设置进度条
for i, file in pbar:
l = self.labels[i] # label
if l is not None and l.shape[0]:
assert l.shape[1] == 5, '> 5 label columns: %s' % file #5列是否都有
assert (l >= 0).all(), 'negative labels: %s' % file #标签值是否大于0 防止出现越界情况
assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels: %s' % file #归一化
if np.unique(l, axis=0).shape[0] < l.shape[0]: # duplicate rows 计算重复的
nd += 1 # print('WARNING: duplicate rows in %s' % self.label_files[i]) # duplicate rows
if single_cls:
l[:, 0] = 0 # force dataset into single-class mode 单个类别,设置其类别为0
self.labels[i] = l
__getitem__方法
getitem方法顾名思义就是在训练的时候为模型提供具体数据用的,方法中集成了数据增强的方法,如YOLO V4中提到的Bag of freebies(BOF)处理方式在这边都有体现。这里的操作除了做图像的旋转、平移、缩放、hsv操作等处理外,还进行了图像拼接的工作,V4中引入的4张图像拼接一张大图的方式就是在这里实现的。这里重点需要注意的是对图像进行的这些操作同时也需要对标签值进行操作,才能让做完数据增强后的图像和标签能够一一对应。
首先根据配置进行马赛克拼接工作:
hyp = self.hyp
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index) #马赛克拼接4张图像
shapes = None
# MixUp https://arxiv.org/pdf/1710.09412.pdf
if random.random() < hyp['mixup']:
img2, labels2 = load_mosaic(self, random.randint(0, len(self.labels) - 1))
r = np.random.beta(8.0, 8.0) # mixup ratio, alpha=beta=8.0
img = (img * r + img2 * (1 - r)).astype(np.uint8)
labels = np.concatenate((labels, labels2), 0)
else:
# Load image
img, (h0, w0), (h, w) = load_image(self, index)
# Letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
mosaic = self.mosaic and random.random() < hyp['mosaic']这里对是否进行马赛克拼接作了随机处理,超参数中设置了mosaic的值,如果设置为1,那么就会必须进行马赛克拼接。
这里需要进入load_mosaic方法去看如何进行拼接
def load_mosaic(self, index):
# loads images in a mosaic
labels4 = []
s = self.img_size
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y 随机中心点
indices = [index] + [random.randint(0, len(self.labels) - 1) for _ in range(3)] # 3 additional image indices 随机选3张图像进行拼接
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left
# 1.初始化大图;现在所有的图像点都被填充上了背景值
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
# 2.计算当前图片放在拼接后的大图中什么位置;
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# 3.计算在小图中取哪一部分放到拼接后的大图中
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
#1.截图小图中的部分放到大图中 2.由于小图可能填充不满,所以还需要计算差异值,因为一会要更新坐标框标签
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax] 将小图中的值填充到大图中
padw = x1a - x1b
padh = y1a - y1b
# Labels 标签值要重新计算,因为现在都放到大图中了
x = self.labels[index]
labels = x.copy()
if x.size > 0: # Normalized xywh to pixel xyxy format
labels[:, 1] = w * (x[:, 1] - x[:, 3] / 2) + padw
labels[:, 2] = h * (x[:, 2] - x[:, 4] / 2) + padh
labels[:, 3] = w * (x[:, 1] + x[:, 3] / 2) + padw
labels[:, 4] = h * (x[:, 2] + x[:, 4] / 2) + padh
labels4.append(labels)
# Concat/clip labels 坐标计算完之后可能越界,调整坐标值,让他们都在大图中
if len(labels4):
labels4 = np.concatenate(labels4, 0)
np.clip(labels4[:, 1:], 0, 2 * s, out=labels4[:, 1:]) # use with random_perspective
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment 对整合的大图再进行随机旋转、平移、缩放、裁剪
img4, labels4 = random_perspective(img4, labels4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4
回到getitem方法中来,继续根据参数做数据增强处理
if self.augment:
# Augment imagespace
if not mosaic: #这个之前在mosaic方法最后做过了
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
# Augment colorspace h:色调 s:饱和度 V:亮度
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
然后将数据增强处理过程中修改的标签坐标表示方式改回xywh形式
nL = len(labels) # number of labels
if nL: #1.调整标签格式 2.归一化标签取值范围
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5]) # convert xyxy to xywh
labels[:, [2, 4]] /= img.shape[0] # normalized height 0-1
labels[:, [1, 3]] /= img.shape[1] # normalized width 0-1
还需要将CV处理增强后的图像修改成torch需要的图像格式:
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416 要满足pytorch的格式
img = np.ascontiguousarray(img)
2.YOLO V5网络结构中的处理方式
借用一张YOLO V5的网络结构图:

模型构建
YOLO模型位于yolo.py模块中,其中最主要的是根据配置文件进行模型的构建,YOLO V5的配置文件相较于之前V3的配置文件,可以说简单明了的多,对于配置文件的解读有时间可以单独写写,这里就先不做引申了。
参数解析
我们可以从parse_model方法进入,看看YOLO V5是如何通过配置文件构建模型的。
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
# c1是输入CHANEL数,c2是输出chanel数
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
# 需要和系数相乘
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_divisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
# 打印进度
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
# layers包含所有定义的层
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
前向传播
前向传播就是一直调用forward函数的过程
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
i = 1
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
try:
import thop
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # FLOPS
except:
o = 0
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
#print('层数:',i,'特征图大小:',x.shape)
i+=1
y.append(x if m.i in self.save else None) # save output
if profile:
print('%.1fms total' % sum(dt))
return x
这里面通过遍历之前构筑好的模型层for m in self.model,来进行一步一步的调用模型层进行处理x = m(x) # run,如果代码跟进去的话,就是跳入模型的forward函数中执行。
backbone层
Focus层
Focus层是将大图像在xy的方向上每隔一个像素取一个值,从而可以生成4个长宽是原有图像1/2的图像,然后将4个图像拼接起来成为一个输入数据。Focus层不仅可以看做是对图像的重采样,还进行了卷积和平滑的操作。
所有的模型层定义都在common.py模块中
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
这里的Conv不是简单的卷积处理,而是包含卷积conv2d、归一化BatchNorm2d和平滑Hardswish的综合操作:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
BottleneckCSP
简单理解,这一层的处理是可以认为是走了两条路,一条比较长,走了Bottleneck和卷积的处理,另一条比较短,只走了卷积层,然后将两者的结果进行concat操作。
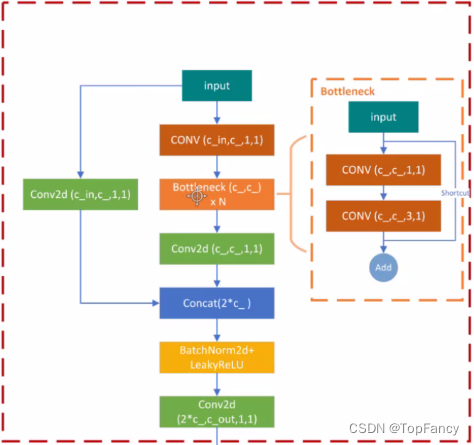
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
forward方法中的操作比较简单明了,y1和y2是分别走的两条线的结果,然后将两个结果cat之后再做处理。
Bottleneck的操作在上图中也有体现,就不单独解析了,其思想也是走两条路,一条走两次卷积,一条走shotcut,然后再进行相加操作。代码如下:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
SPP层
spp层主要是对特征进行Maxpool的操作,其参数配置为[1024, [5, 9, 13]],这里1024为输入channel数,5、9、13分别为3个maxpool的kernel大小。
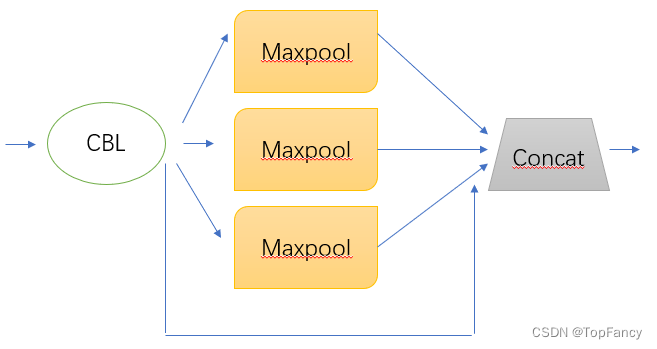
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
这里的代码写的很简洁,三个maxpool操作用一个循环[m(x) for m in self.m]就完成了
head层

head层操作主要是包含PANet,主要是将小尺度的特征图进行上采样,拼接到较大尺度的特征图中,具体可以看上图第二列的操作,这一部分的操作在YOLO V3中已经引入了;YOLO V4又将大尺度的特征图通过卷积与小尺度特征图进行拼接,在上图的第三列可以看出具体操作,然后再进行输出。
这部分的操作仍然在模型层的循环中,可以从配置文件中体现出来:
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
上采样操作可以直接使用torch框架Upsample方法来实现,下采样是通过卷积Conv设置stride为2来进行的。
Detect层
这一层是输出层,可以从配置文件中看出在哪一层进行输出
[[17, 20, 23], 1, Detect, [nc, anchors]]
这里就是输出17/20/23层。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!