爬虫工作量由小到大的思维转变---<第二十二章 Scrapy开始很快,越来越慢(诊断篇)>
前言:
相信很多朋友在scrapy跑起来看到速度200+/min开心的不得了;可是,越跑到后面,发现速度变成了10-/min;刚开始以为是ip代理的问题,结果根本不得法门...
新手跑3000 ~ 5000左右数据,我相信大多数人没有问题,也不会发现问题;
可一旦数据量上了10W+,你是不是就能明显感觉到速度逐渐下降了!!
于是,你以为是要开始分布式! 分出来之后,果真发现,好使!!速度上去了----但如果你这时候跑100/1000w+的数据,你一样还是要出问题! 因为,你的scrapy设计在单个spiders的时候,就出问题了!但问题出在哪?
我准备用3章来解决这个'scrapy速度越来越慢'的问题!
(目前来看,好像只有我在做这事了;会不会侵害到XX,请私联我.我就删文)
正文:
首先,我们需要诊断问题的关键是用一个检测工具;也是scrapy手册里讲的`telnet`:
telnet用途:
- 查看爬虫状态:你可以使用Telnet命令来查看正在运行的爬虫的状态,包括已爬取的页面数、请求队列中的请求数、已抓取的数据等统计信息。
- 动态修改配置:通过Telnet,你可以修改Scrapy的配置选项,例如下载延迟、请求头、请求过滤规则等,而无需停止和重新启动整个Scrapy进程。
- 控制爬虫行为:你可以通过Telnet命令暂停、恢复或终止正在运行的爬虫。这对于调试和管理爬虫的行为非常有用。
- 执行扩展命令:Scrapy提供了一些内置的扩展命令,可以通过Telnet进行调用,例如导出爬取的数据、监视爬虫性能等。
windows如何使用?

相信你看到网上的教程用的时候,会遇上这种问题;这是因为,你没有开启telnet;
如何开启telnet:
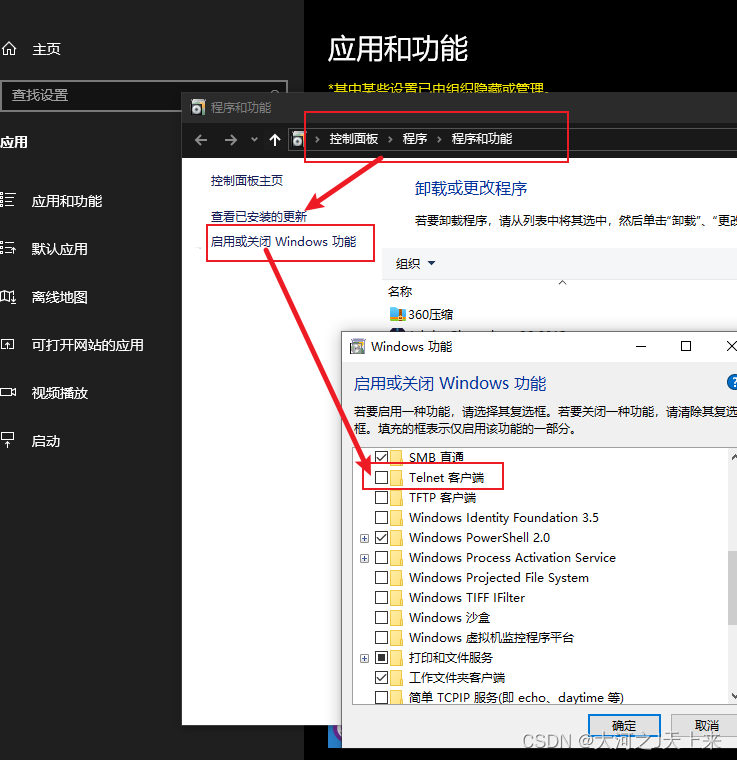
在控制面板里面,找到这个客户端,勾上-->确认!就是开启!
随后,cmd-->输入:telnet?
欢迎使用 Microsoft Telnet Client
Escape 字符为 'CTRL+]'
Microsoft Telnet>
出现这种,就是成功了(表示开启了telnet)
如何连接scrapy,进行监控呢?
1.设置爬虫setting里面:
我不推荐None,因为我发现设置None的时候,他还是需要密码;且经常卡bug-->于是,我自己在监控的时候,会设置一个简单的账号/密码,如图:

2.运行你的爬虫;让他开始工作...
如果你没有设置账号密码,他会在日志的info里,有这么一段:
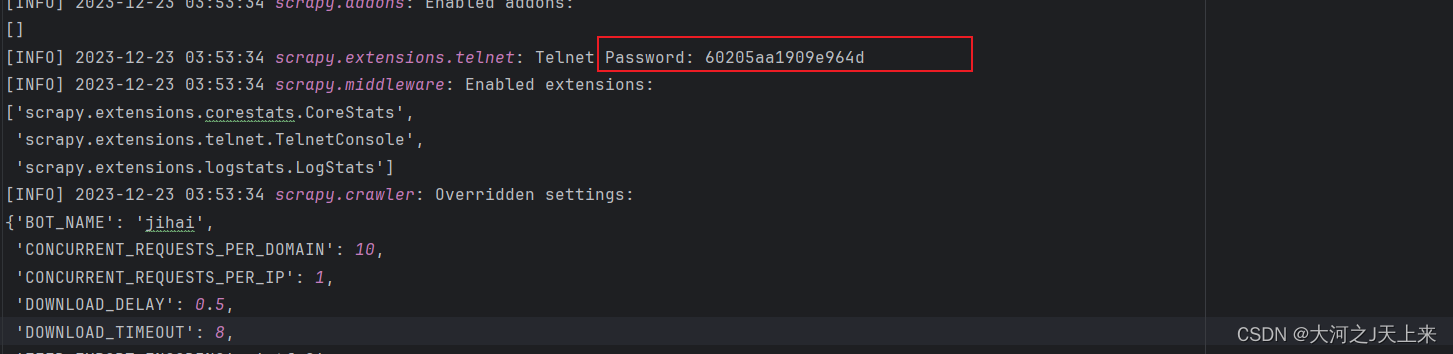
这是是scrapy生成的随机密码;(所以,我推荐你自己定一个密码好些,后面没那么多事!)
3.开启telnet,查看scrapy运行状况
cmd--->输入:
telnet localhost 6023然后,对应输入你的账号/密码 (输入密码的时候,没反应;直接输完,回车就行了!)
4.telnet命令:
- help:显示可用的Telnet命令列表,以及每个命令的简要说明。
- shell:打开Scrapy shell,允许你在交互式Python环境中执行Scrapy的操作和命令。
- stop:停止当前正在运行的爬虫。
- start:启动之前已经停止的爬虫。
- pause:暂停当前正在运行的爬虫。
- resume:恢复之前暂停的爬虫。
- list:列出当前正在运行的爬虫和已完成的爬虫的状态。
- status:显示当前正在运行的爬虫的状态信息,包括请求和响应的统计数据。
- spiders:显示已定义的爬虫列表。
- stats:显示当前Scrapy进程的全局统计信息,例如已处理的请求数、失败数等。
- log [level]:设置和显示当前日志记录的级别。可选的level参数包括DEBUG、INFO、WARNING、ERROR和CRITICAL。
- close_spider [spider_name]:关闭指定名称的爬虫。
例如(想启动一个已经定义的爬虫)
start spider_name
5.诊断:
我们的关键是找到为什么scrapy会越来越慢...
于是,我们可以输入:
prefs()--->看图说话:

我们可以看到表上,当我的爬虫已经运行一段时间后:
缓存中累计有1178条item,最老的一条是在368秒前
request请求,有5840调,最老的也是在368秒前
.....
他表示:我的scrapy里面,问题最大的是在request,他已经堆积了很多没有处理完的任务;当调度器从一开始在100条数据里进行调度,再慢慢增加到5840条数据,你说他的速度是不是就慢了?
------这也就是为什么我们的scrapy会越来越慢,归根结底是内存泄漏--->通俗点:内存没好好管理,释放;导致6分钟以前的请求还卡在调度器里,一直没发起请求; 导致管理这个scrapy的内存慢了,于是处理起来速度就慢了!
总结:
分享的这个案例,并不是说所有的scrapy都是request的请求满的问题;但是,可以通过telnet的监控工具,来检查一下,自己的scrapy是否健康;哪一块会有问题?? 就跟去医院拍X光照一样,对症诊断...你只有保证每一只爬虫都是健康的情况下,再去突破瓶颈开发分布式,才是王道; 否则,你的爬虫看起来能跑,但生命力不强,就是这个原因!!!
-------这一章讲完了"诊断",下一章教"医病"!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!