Java文件流大家族(通俗易懂,学习推荐版,很详细)——操作文件本身和文件中的数据
1.File(操作文件本身)
1.定义
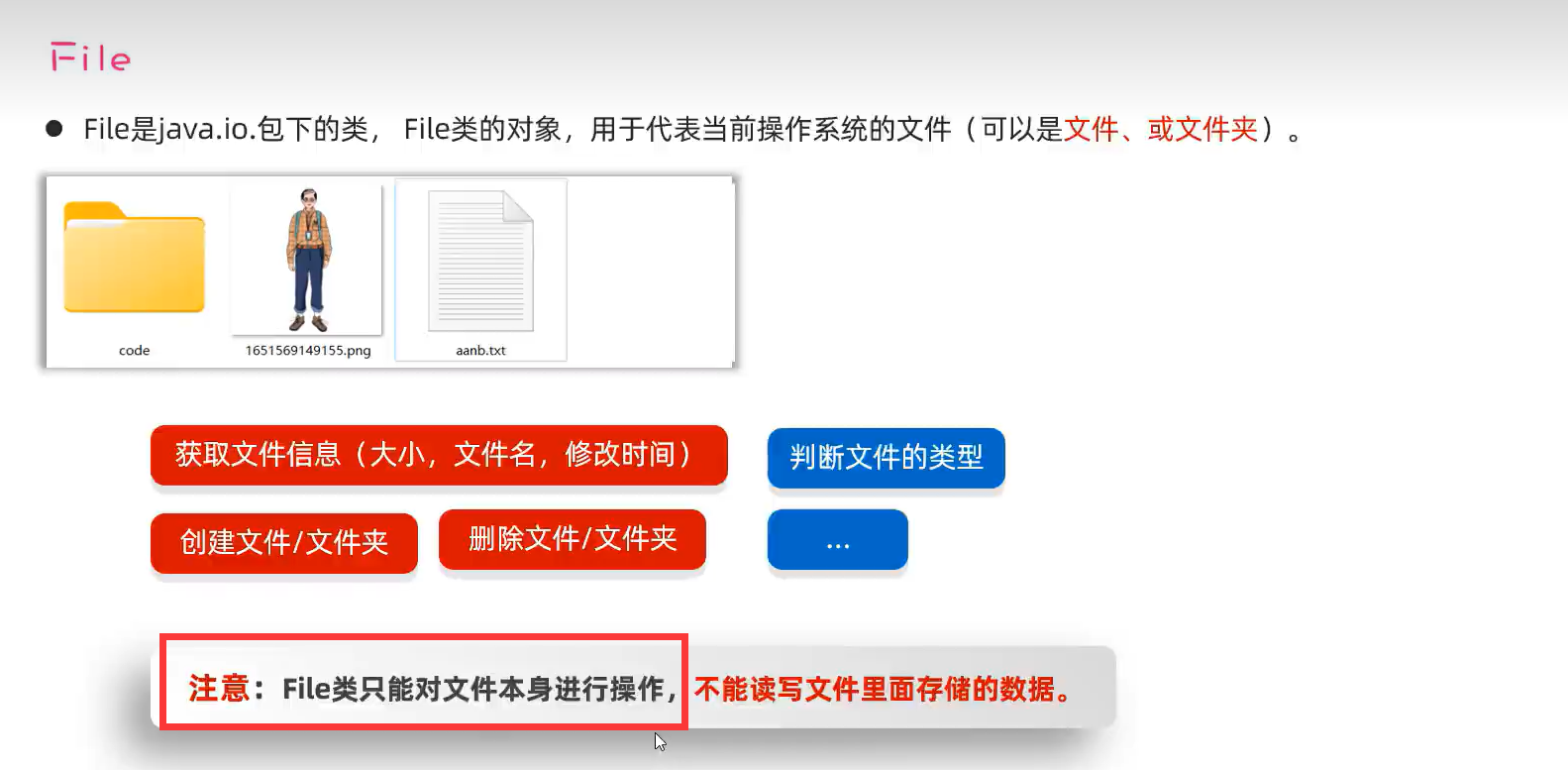
目录

2.常用方法





3.路径引用符
可以用/或者\\分隔路径

还可以用File.separator分隔路径,会根据不同系统使用啥分隔符。

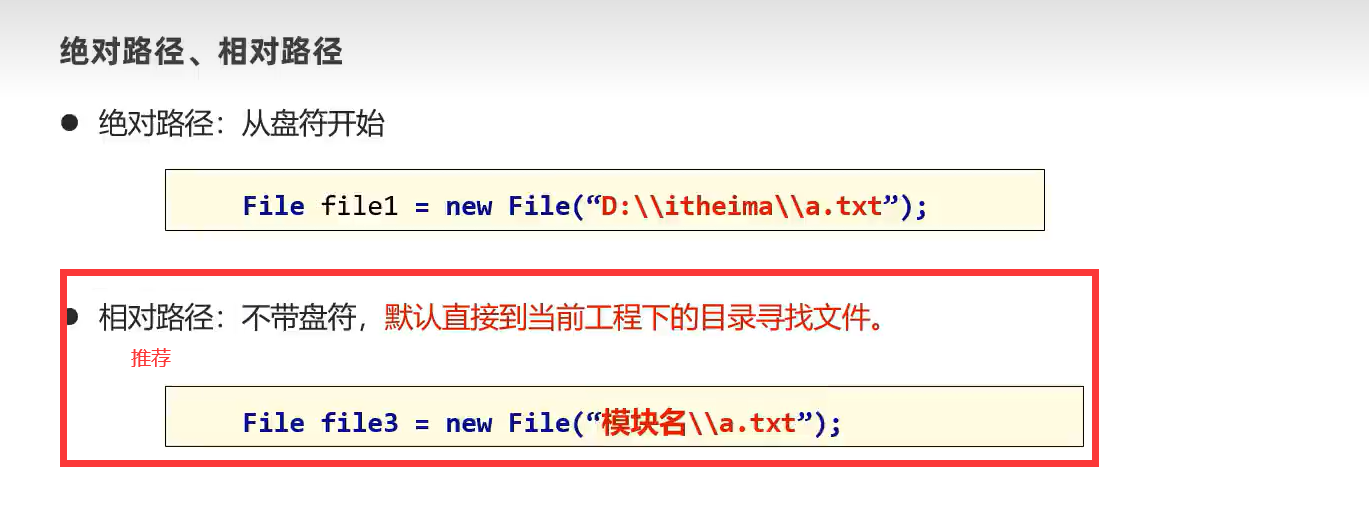
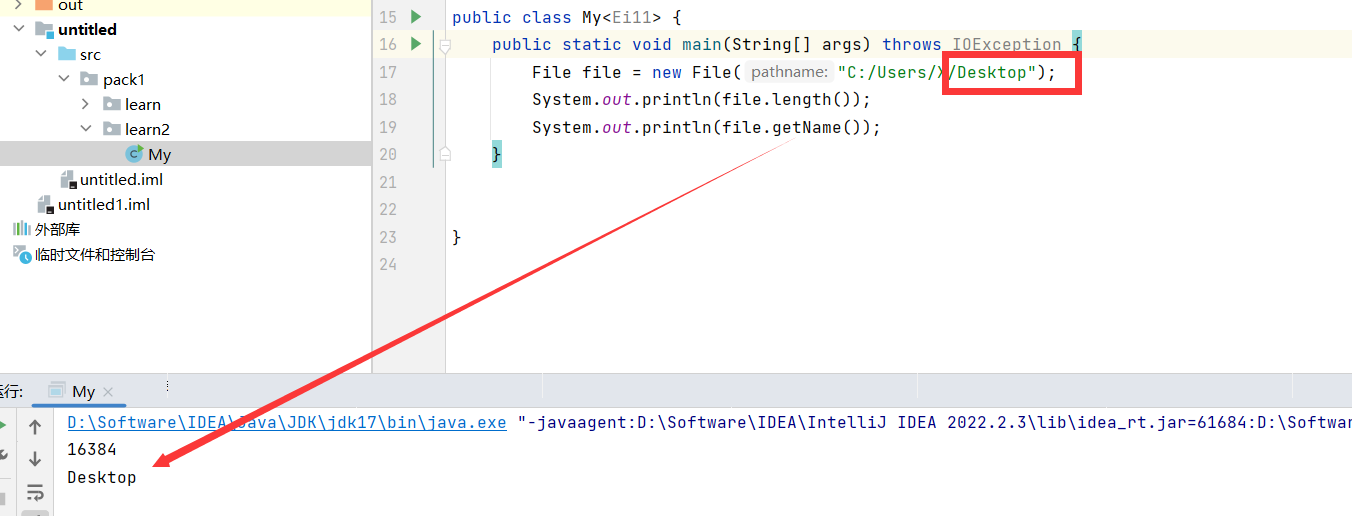
4.绝对路径、相对路径及桌面路径表示
桌面路径为:

我电脑的用户名为X
5.示例代码(遍历文件夹)
1.创建文件对象
示例:
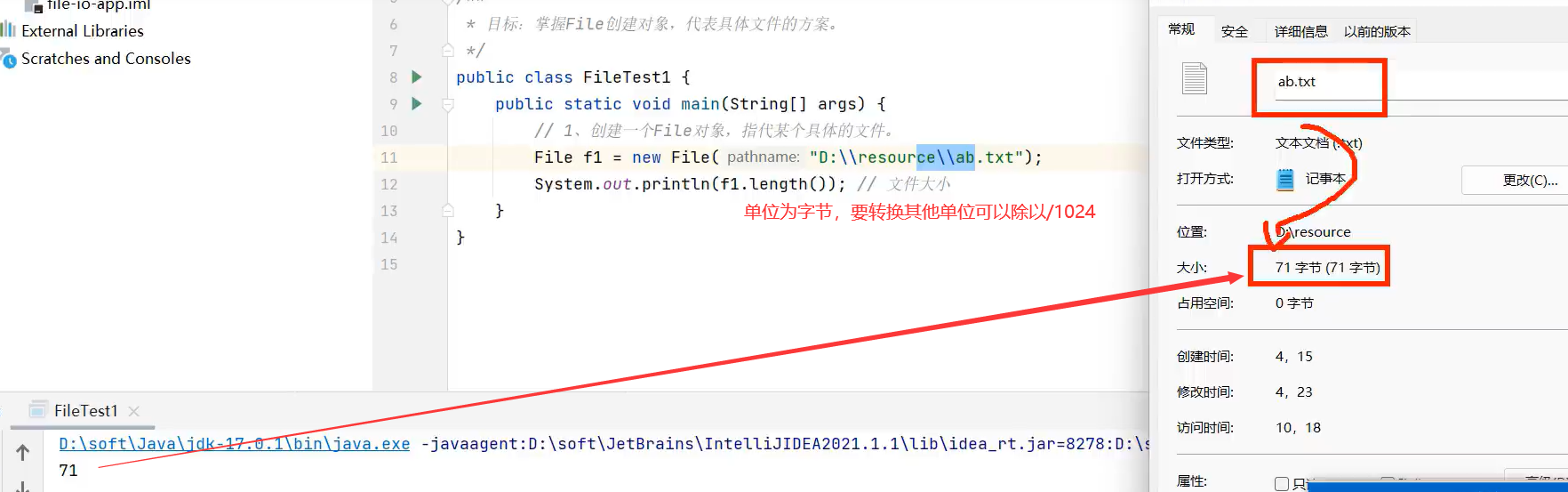
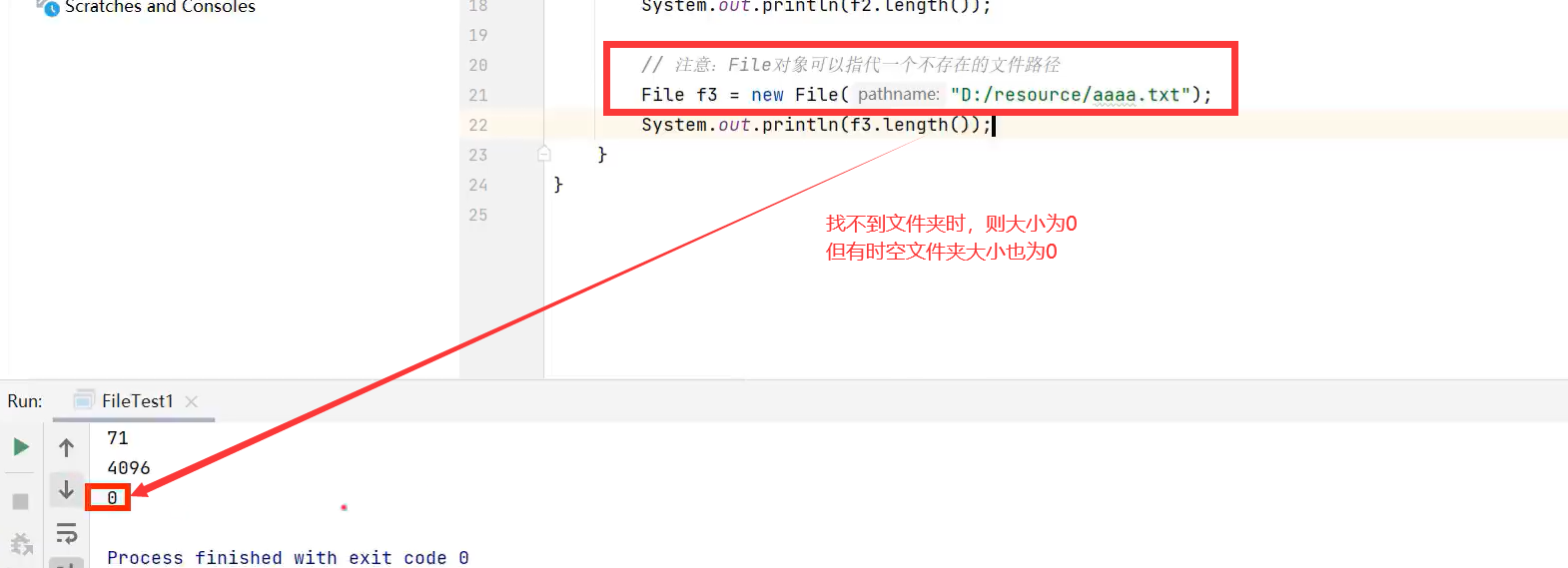
f1.length():以字节为单位,仅仅是获取该文件夹/文件的大小,如果是文件夹 不是获取文件夹的大小及文件夹里面文件夹的大小之和。
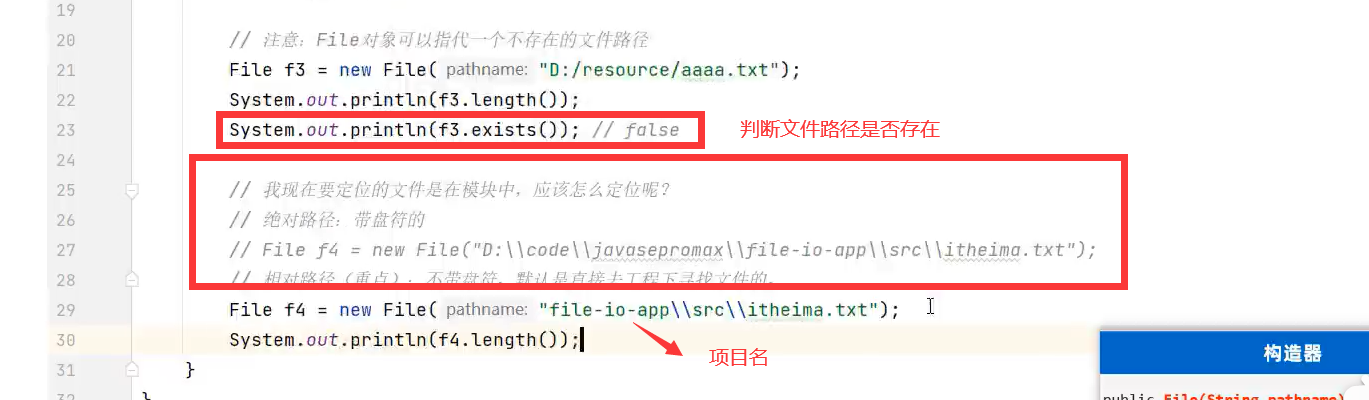
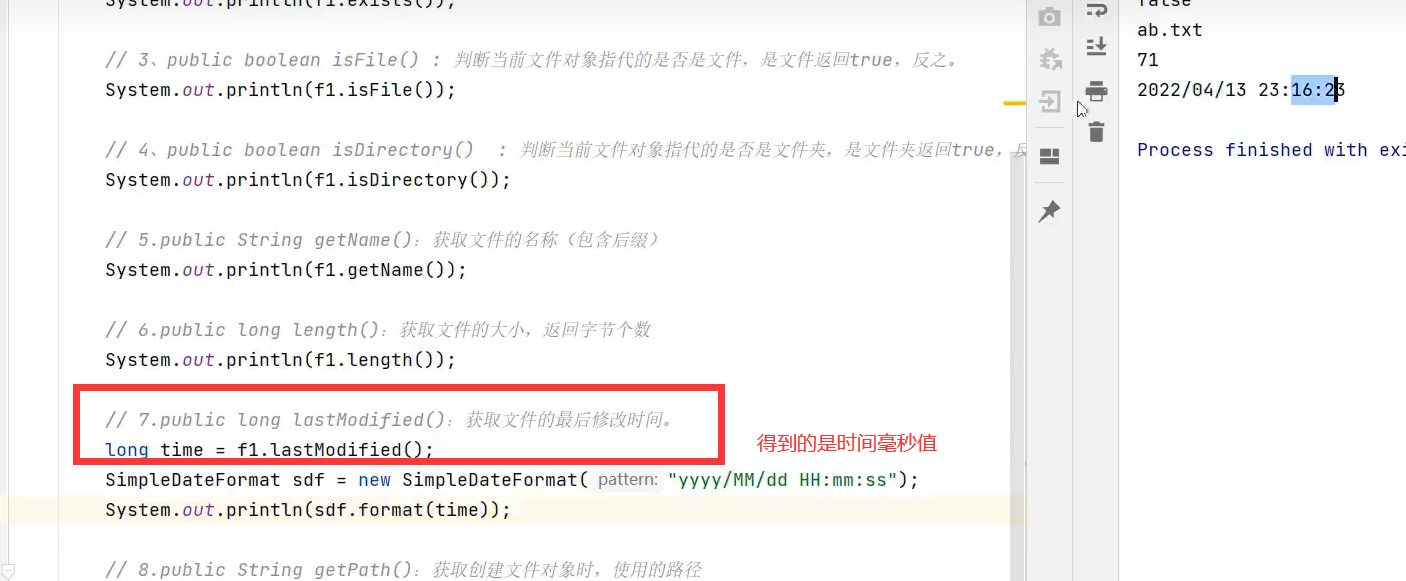
2.常用方法1:判断文件类型(文件、文件夹),获取文件信息等
示例:
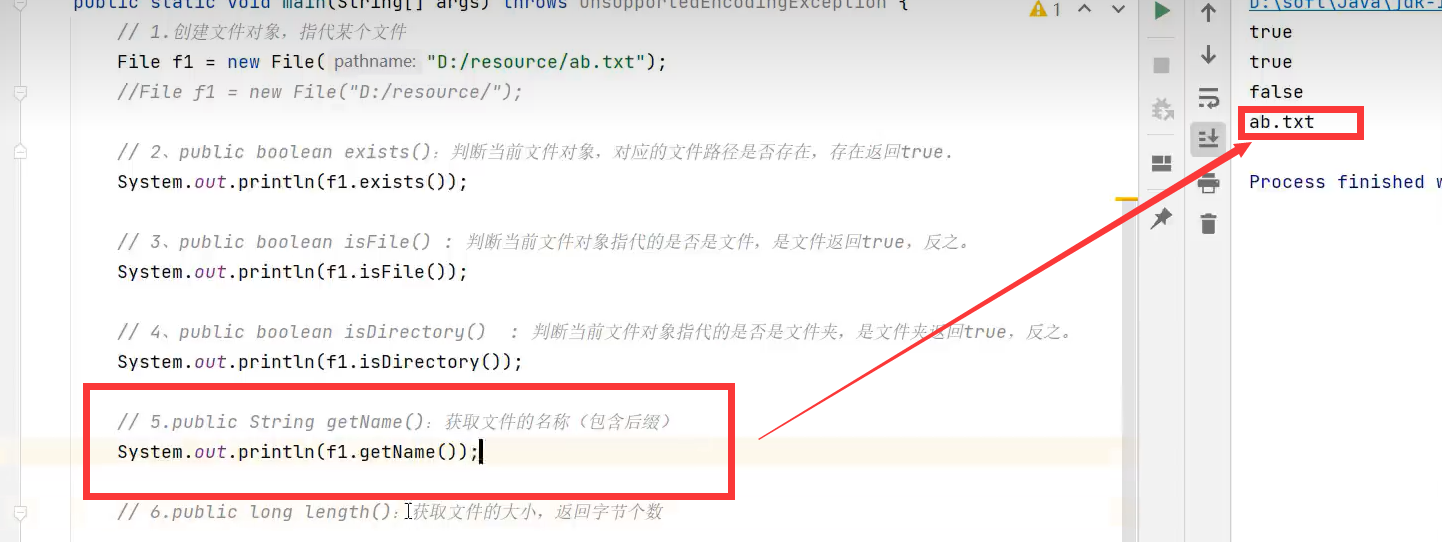
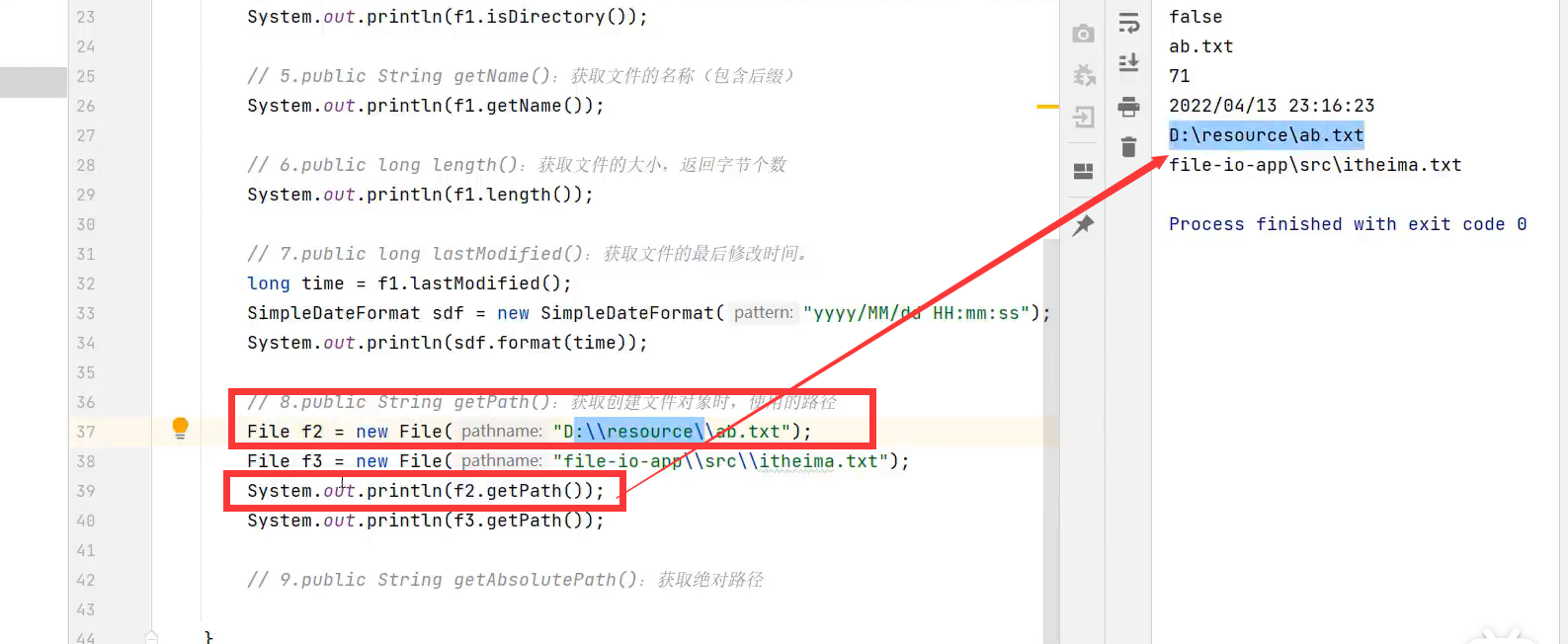
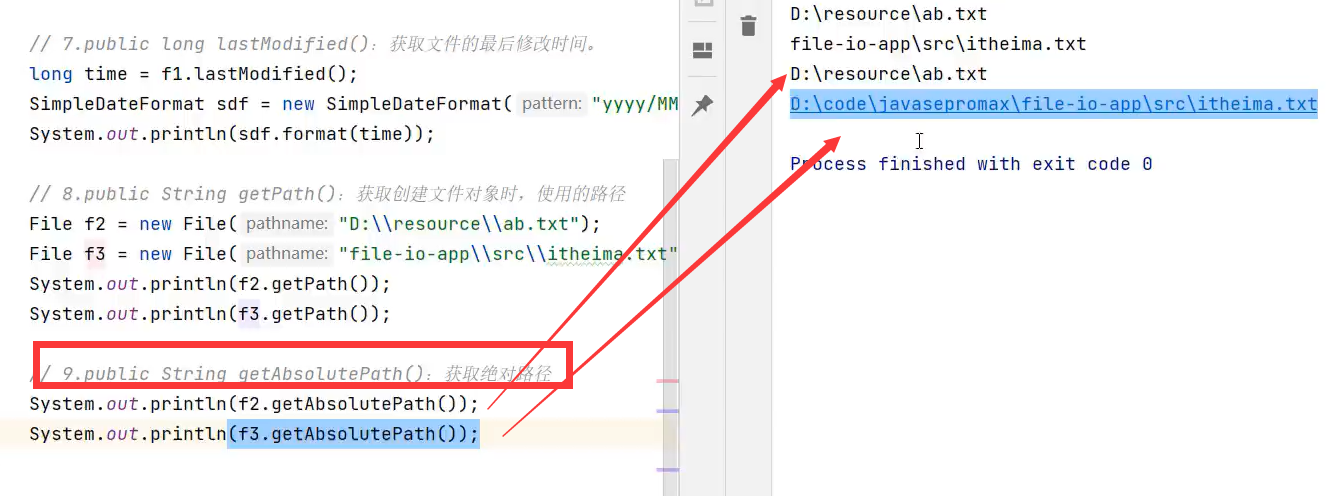
如果该文件对象是绝对路径的话,则getAbsolutePath就是绝对路径,若是相对路径则会补全为绝对路径(路径都是带后缀的)
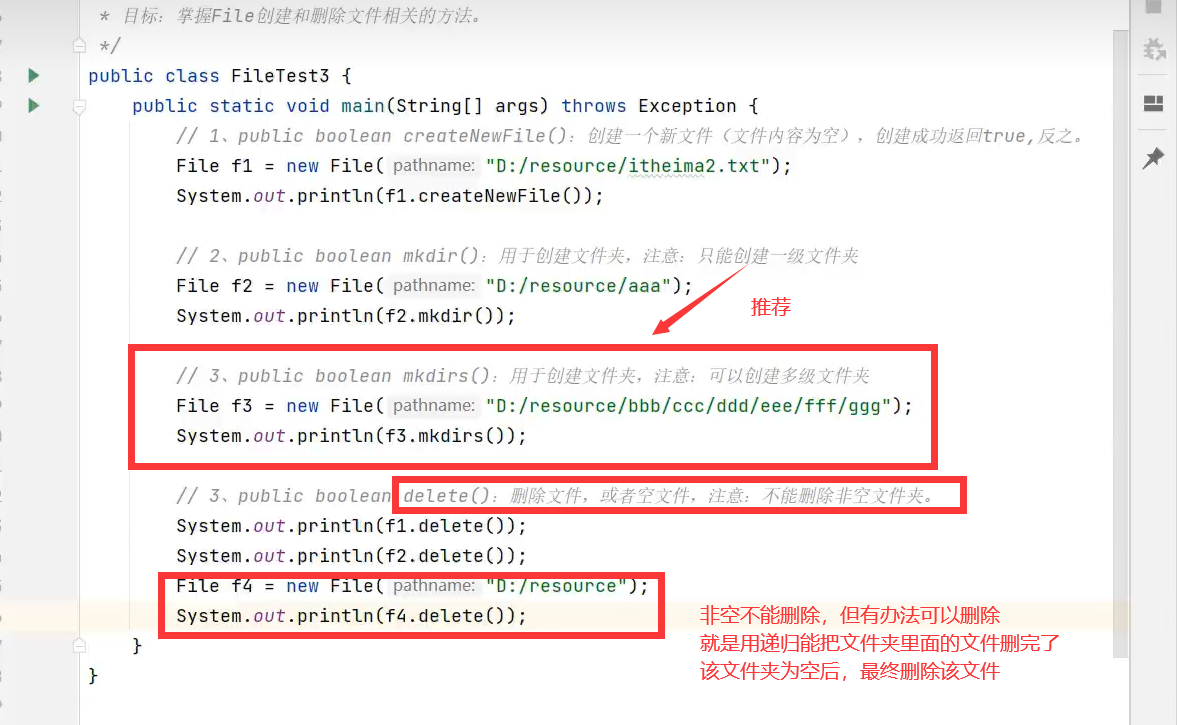
3.常用方法2:创建和删除文件、文件夹
示例:
4.常用方法3:遍历文件夹
示例:
list()列表的名称及包括文件夹名称也包括文件名称(如图中的授课新得.txt)
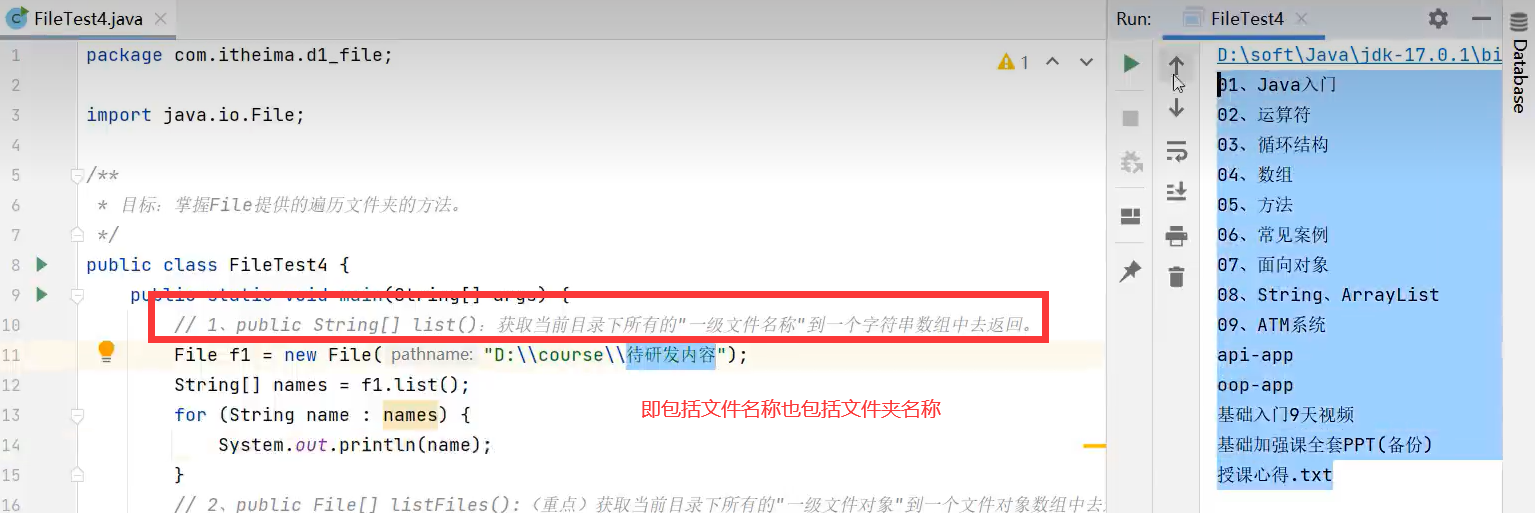
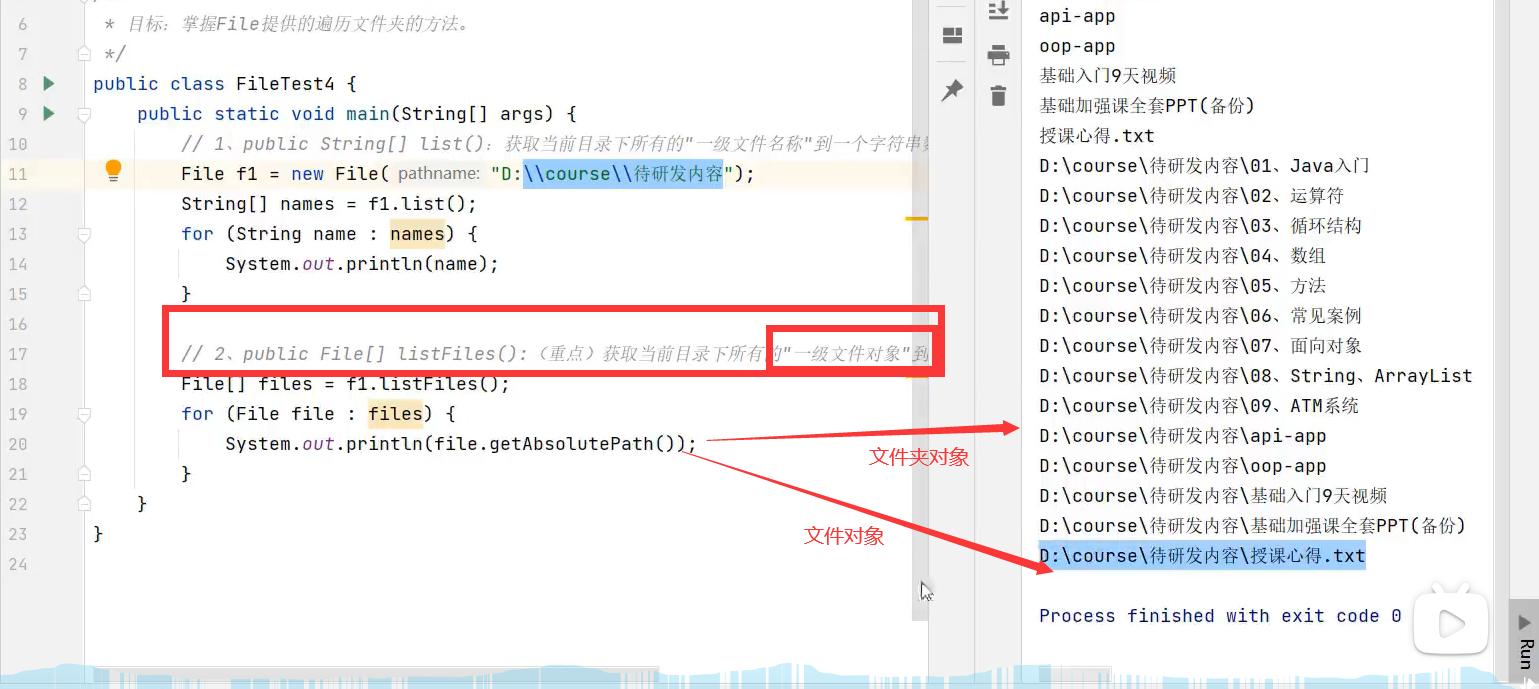
listFiles()方法能获取当前文件对象路径的一级文件对象,注意是一级文件对象
listFiles()使用注意事项

示例:
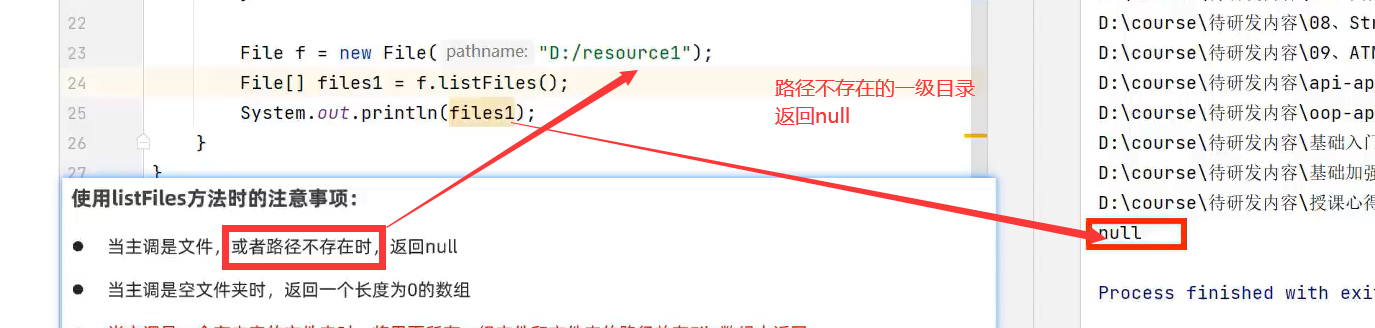
1.当主调是文件,返回null
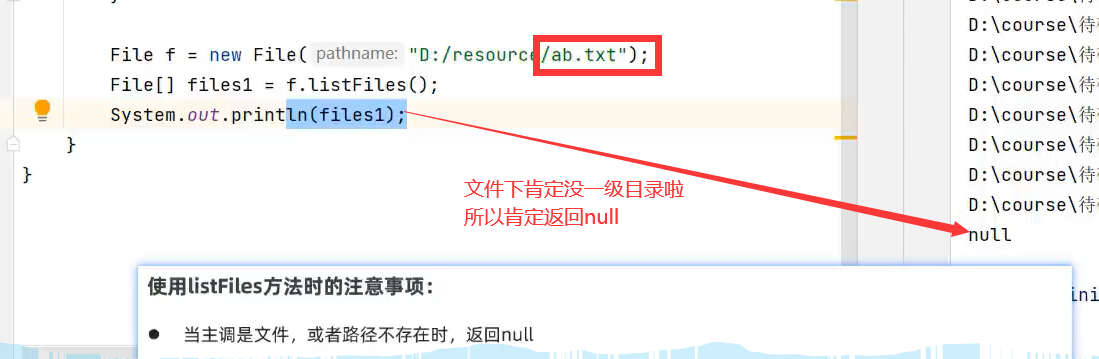
无需ab.txt存不存在,只要是获取文件的一级目录对象都返回null。
路径不存在的一级目录文件对象返回null
2.当主调是空文件夹是,返回一个长度为0的数组,数组内容为[]。图中aaa是空文件夹
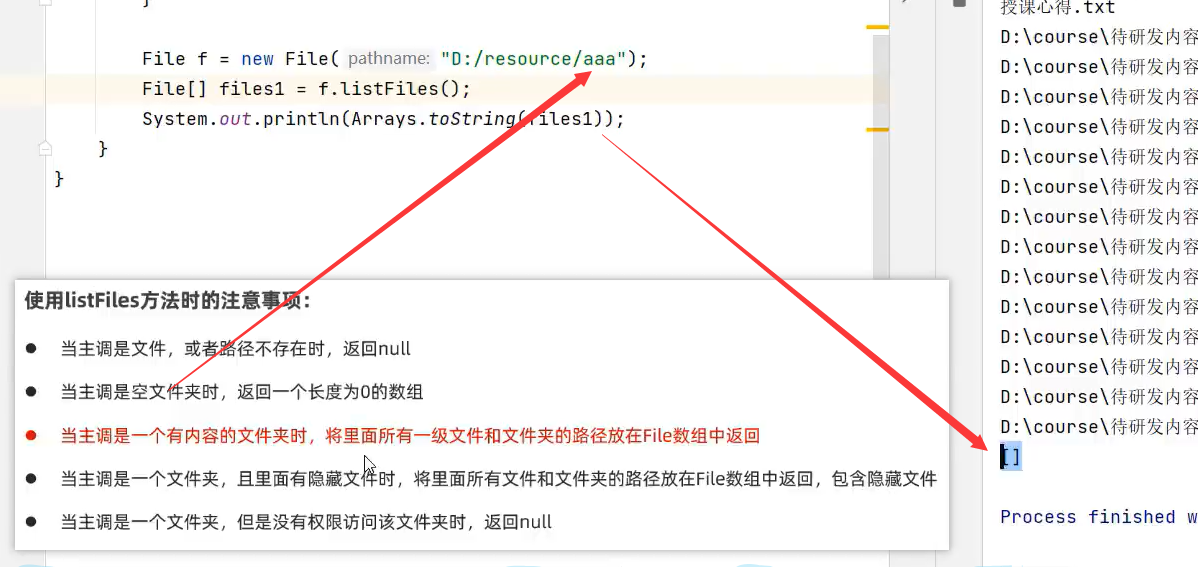
3.当主调是一个有内容的文件夹时,将里面所有的一级文件及文件夹的路径放在File数组中返回(即正常情况)
4.这里只演示第一点


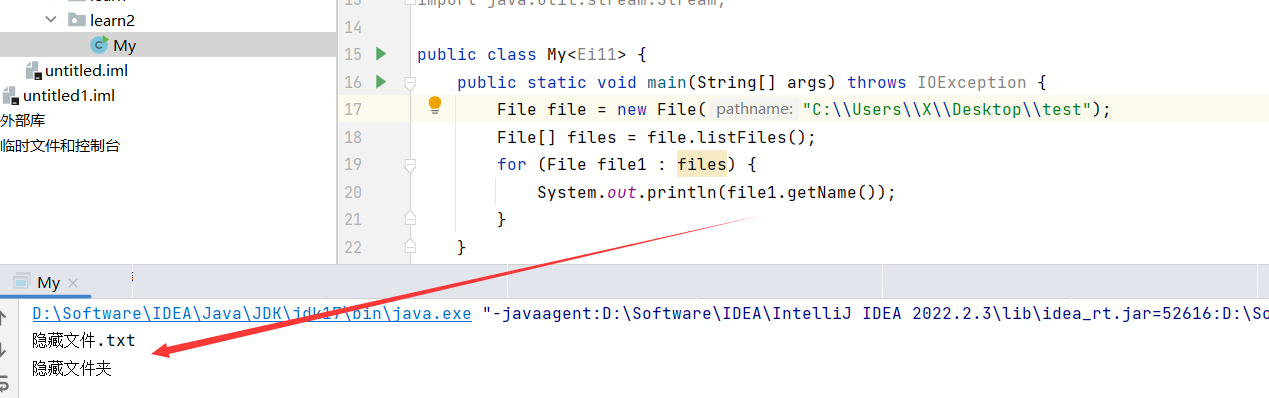
test是桌面上的一个文件夹。现在现在这个文件夹和文件进行隐藏。
可以看到隐藏结果获取到了
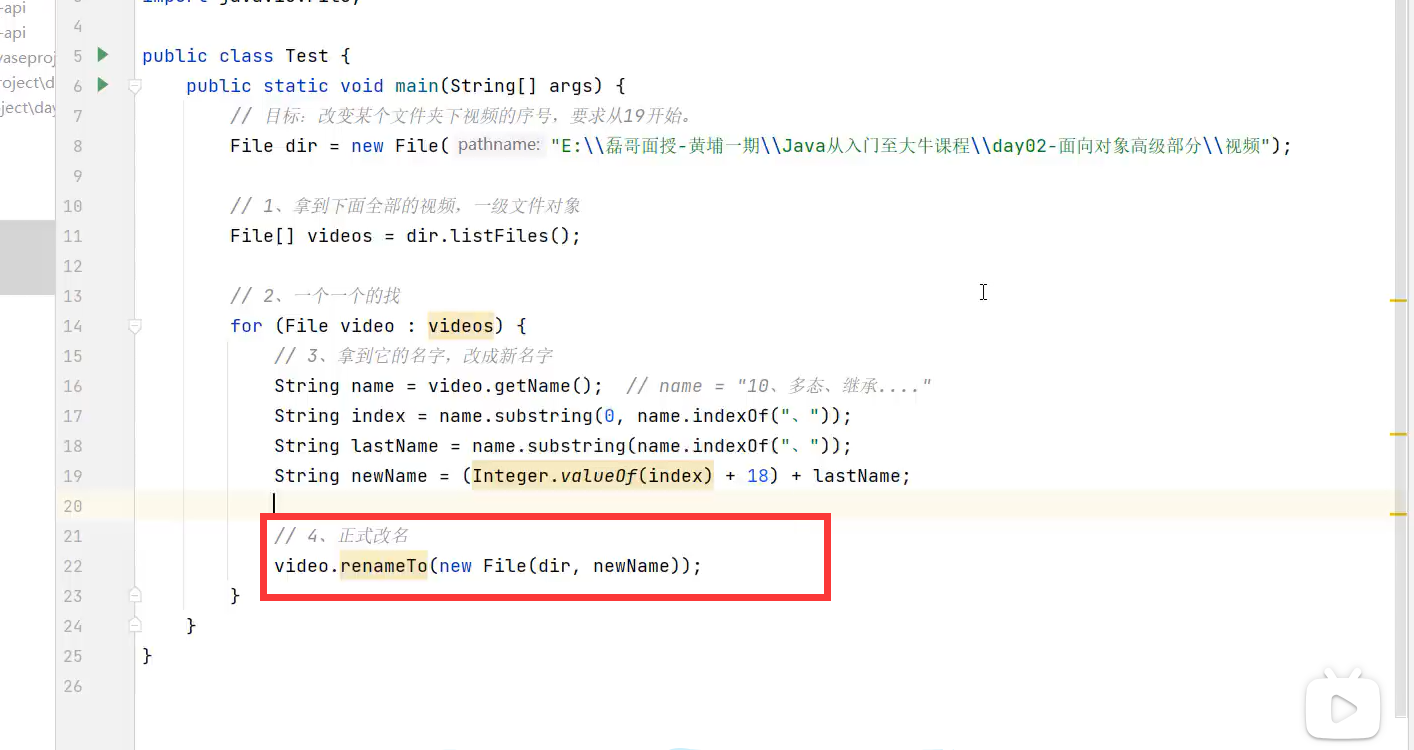
6.重命名文件、文件夹(renameTo(文件对象))
案例:改变某个文件夹下的视频序号,要求从19开始

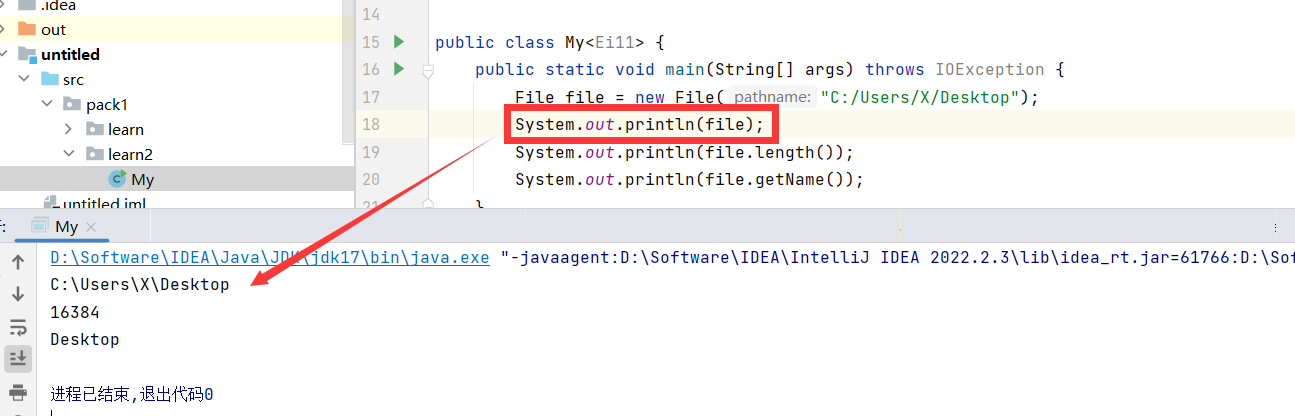
直接输出文件对象,会直接输出该文件对象对应的路径
7.文件搜索(递归实现)

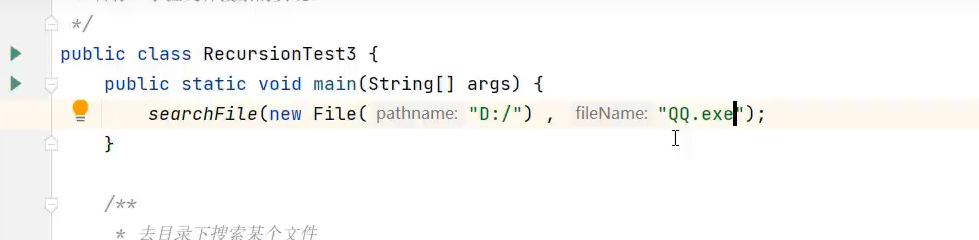
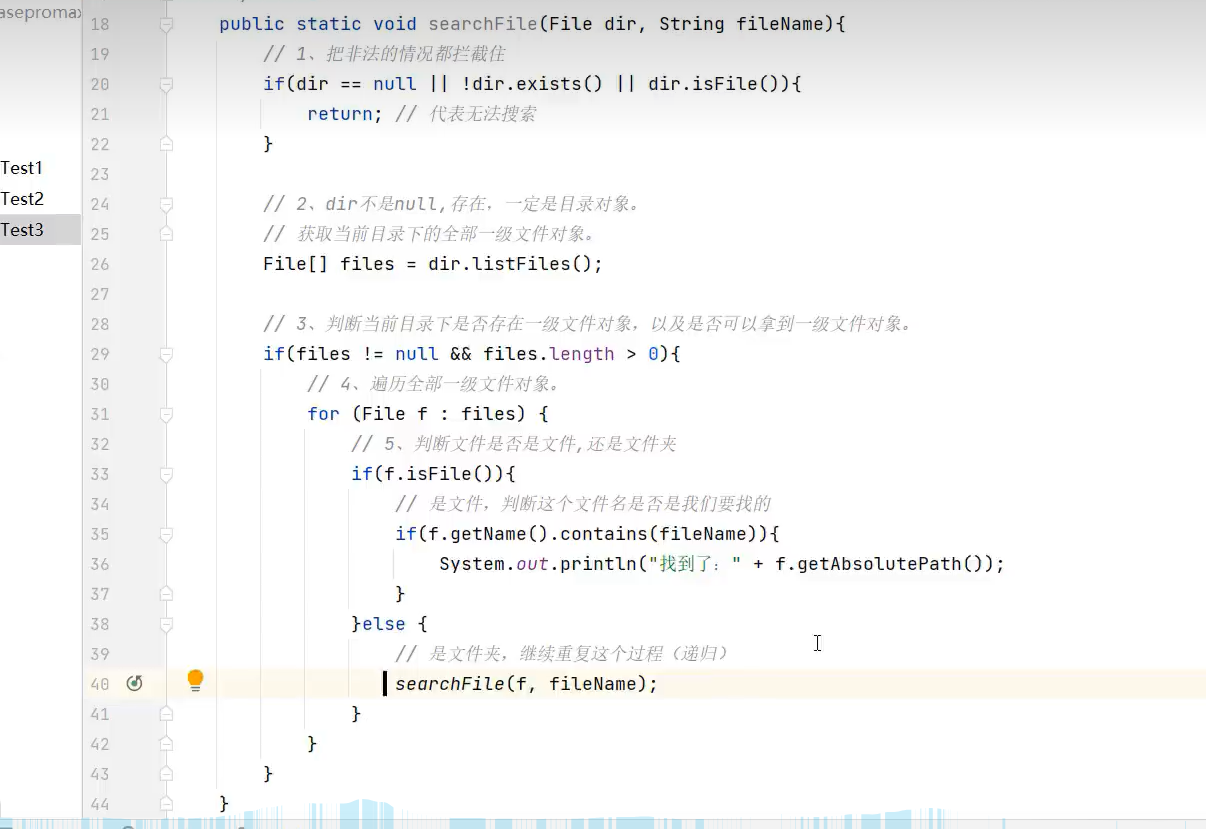
再找到像要的文件(对象)后如果要打开或执行,可以用以下代码实现
?Runtime runtime = Runtime.getRuntime(); ?runtime.exec(文件对象.getAbsolutePath());
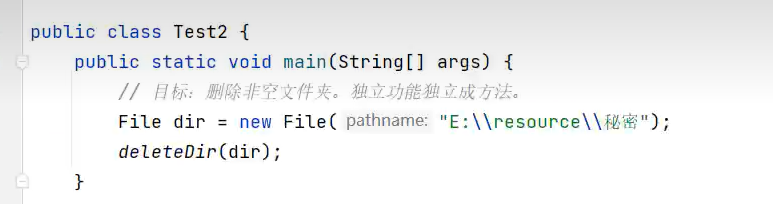
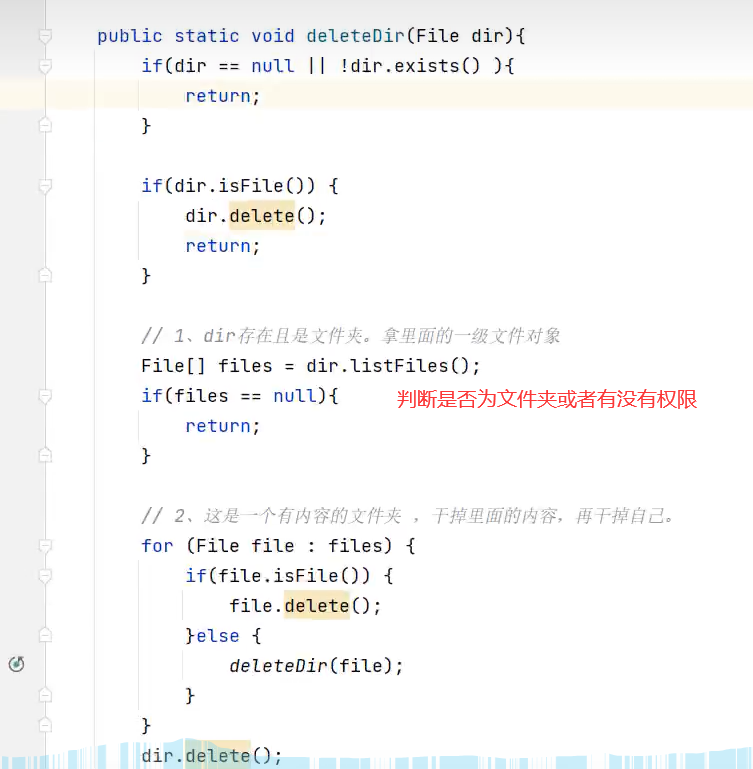
8.删除非空文件夹(删除文件和删除空文件用相应的方法,可以直接调用)
此密码文件夹假如非空,也就是里面有文件或文件夹
2.IO流(操作文件的数据)
注意:流使用完之后必须用.close()方法关闭
1.概述
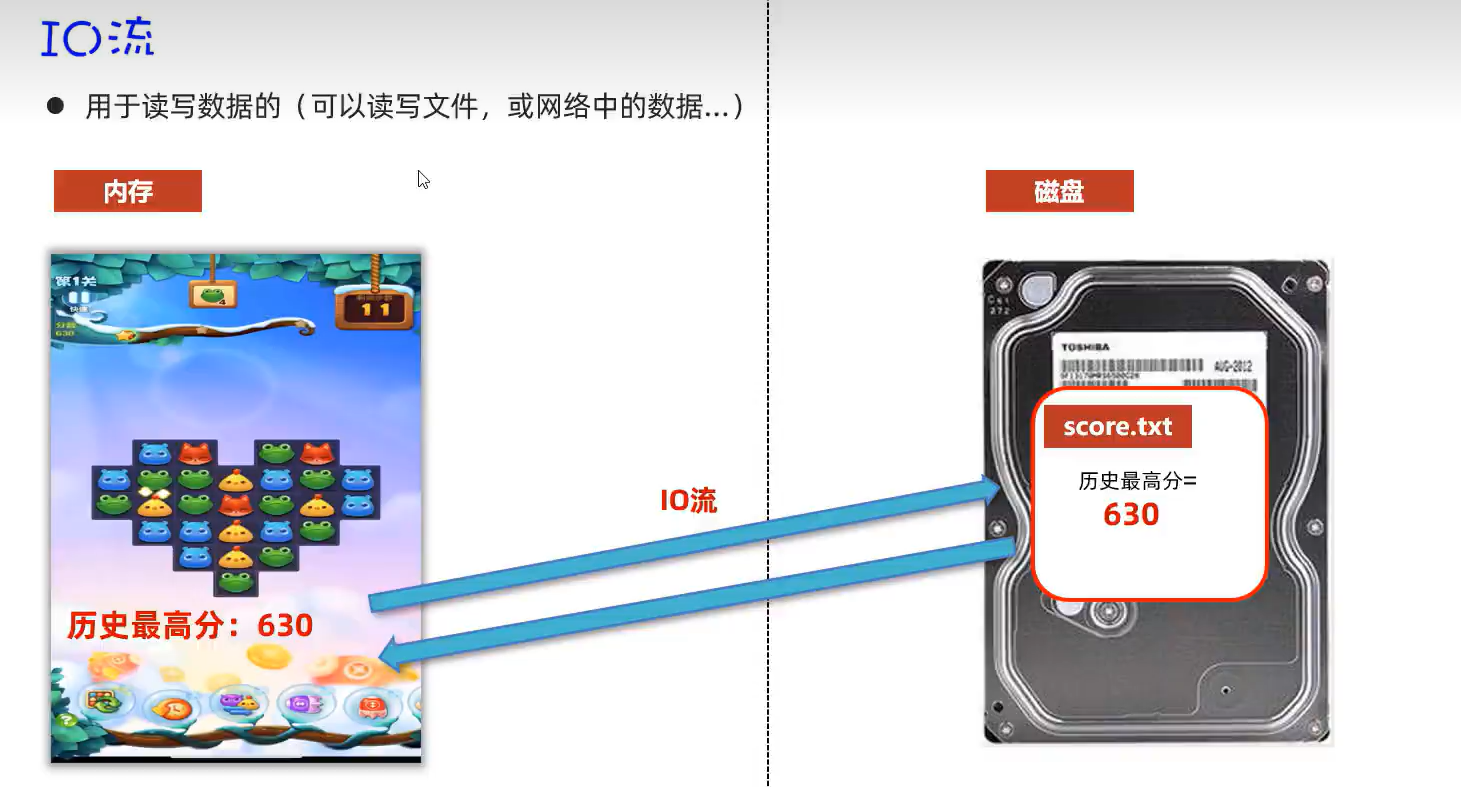

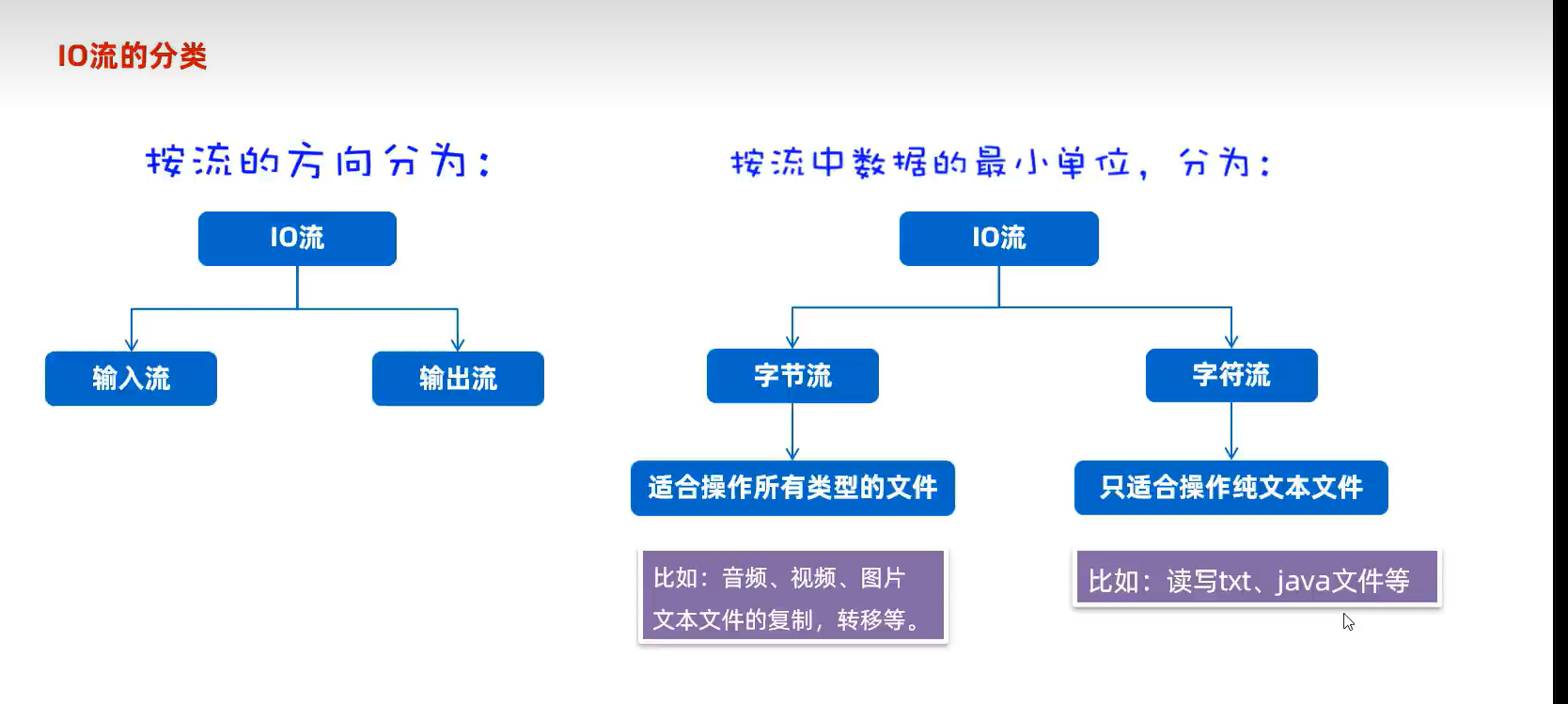
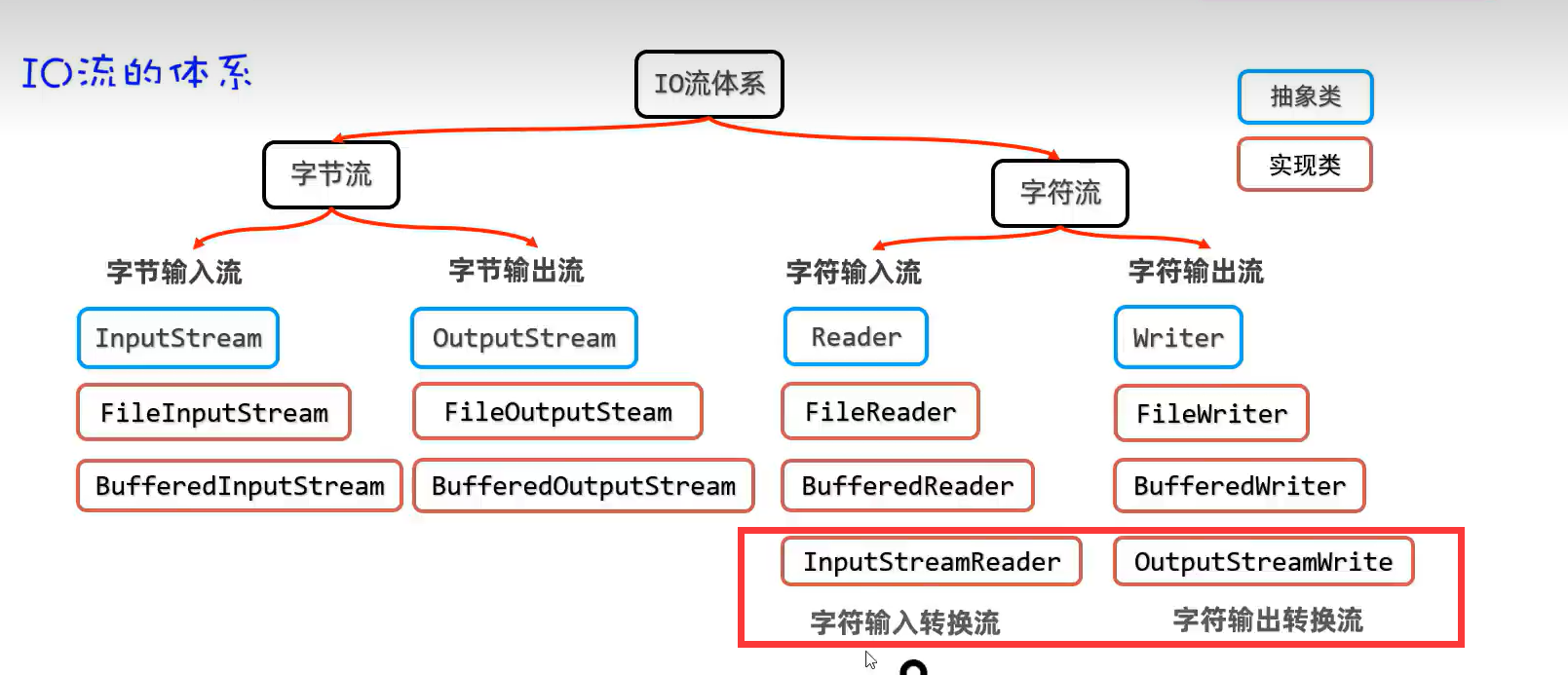
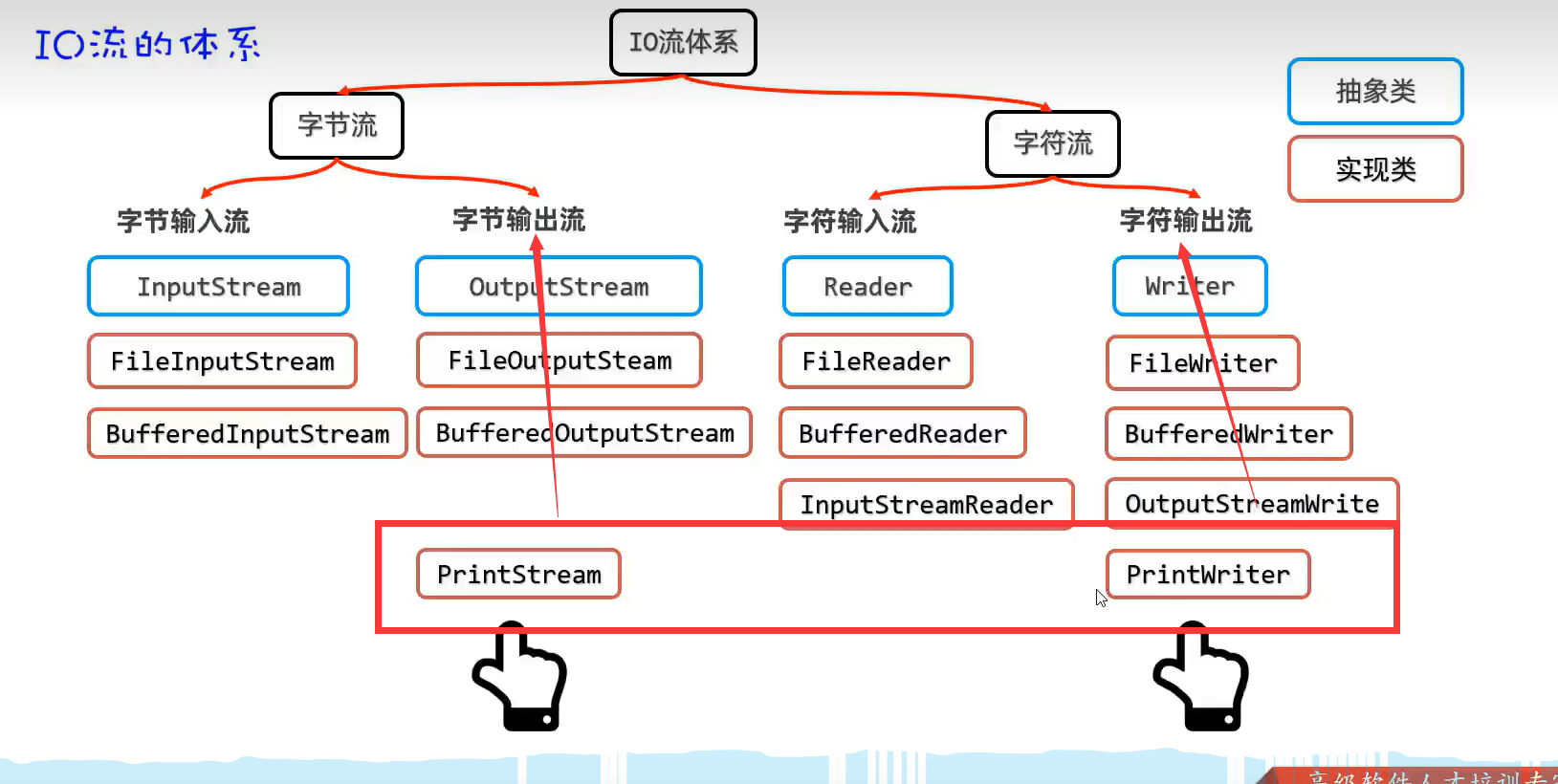
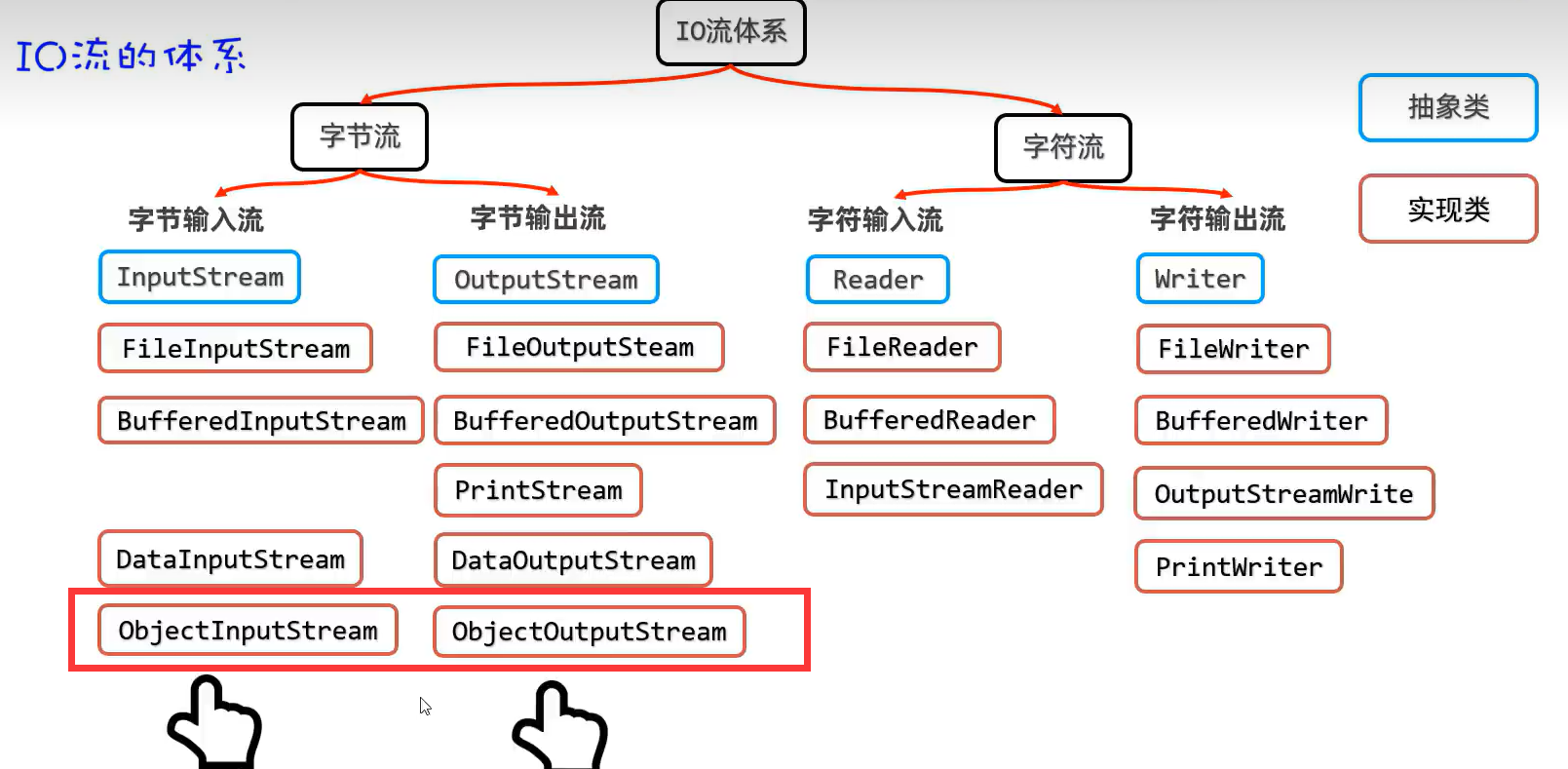
2.分类

3.文件流体系结构(基础原始流)
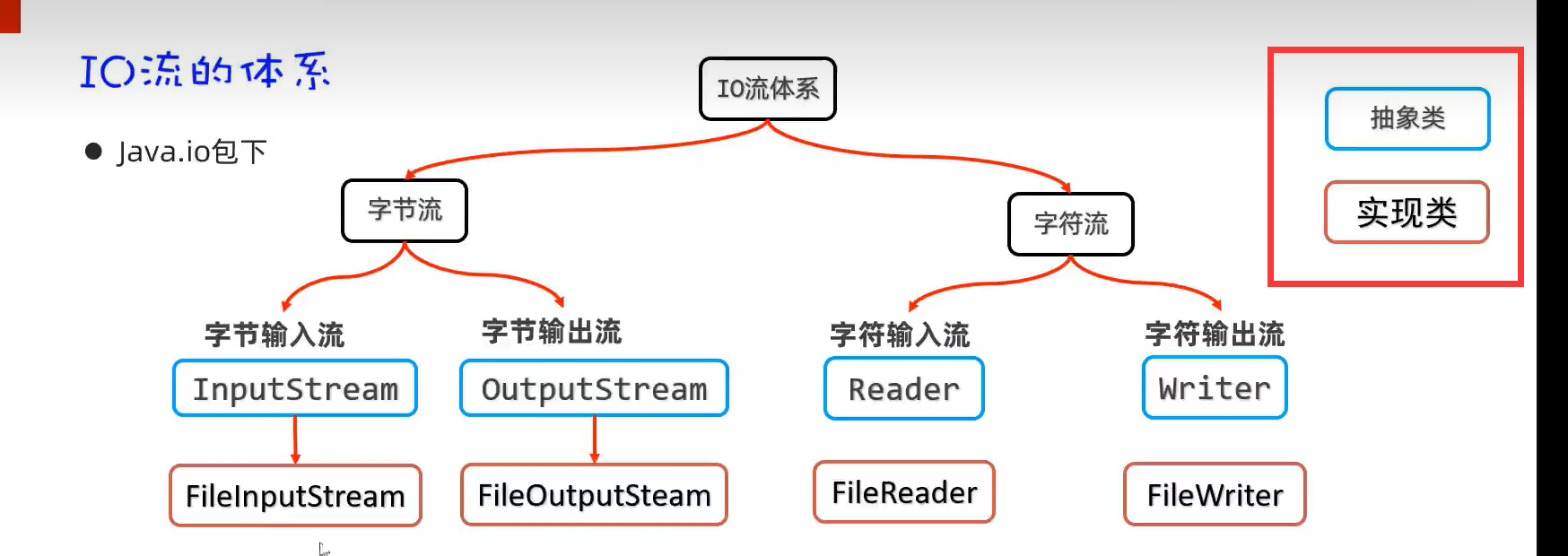
1.FileInputStream(字节输入流)
常用于拷贝文件,文件传输等操作。

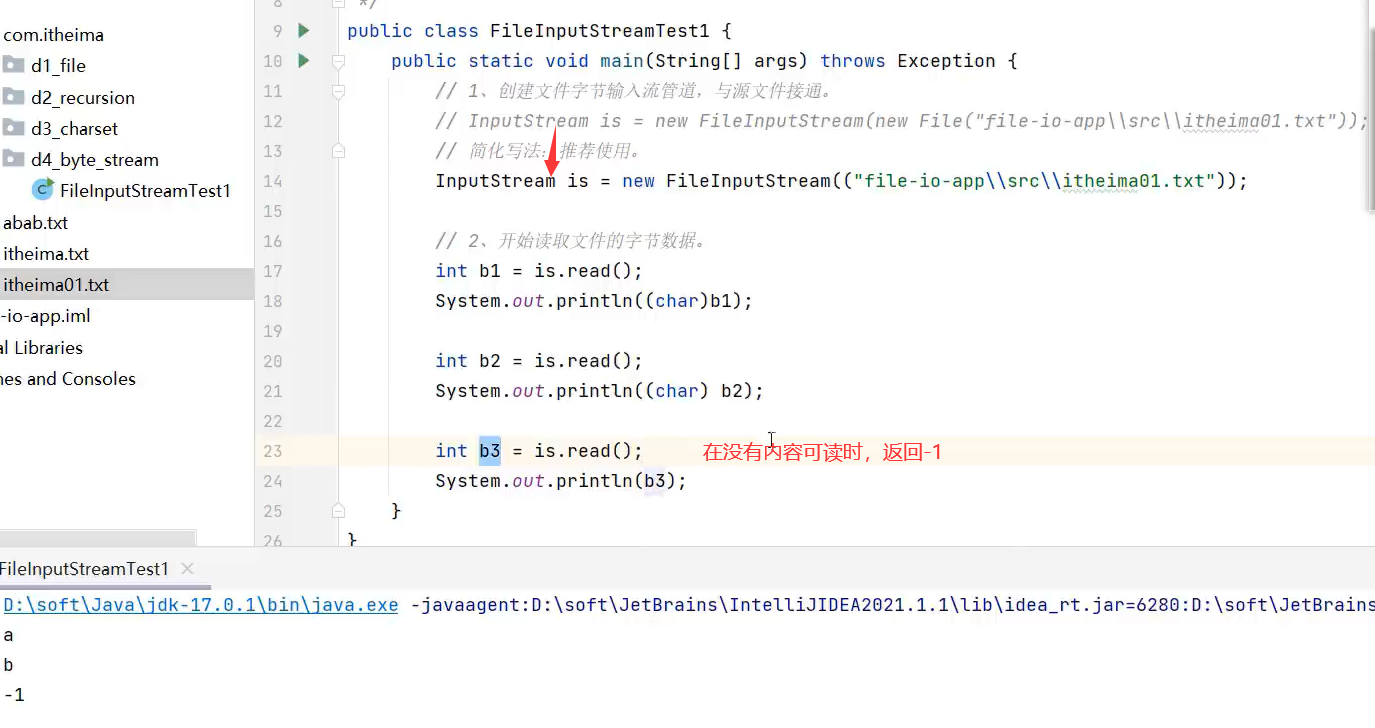
1.每次读一个字节(性能差)
1.单个读取文件内容(每次读一个字节,性能能差,而且因为每次读一个字节读汉字会乱码)
2.循环读取文件内容(每次读一个字节,性能能差,而且因为每次读一个字节读汉字会乱码)
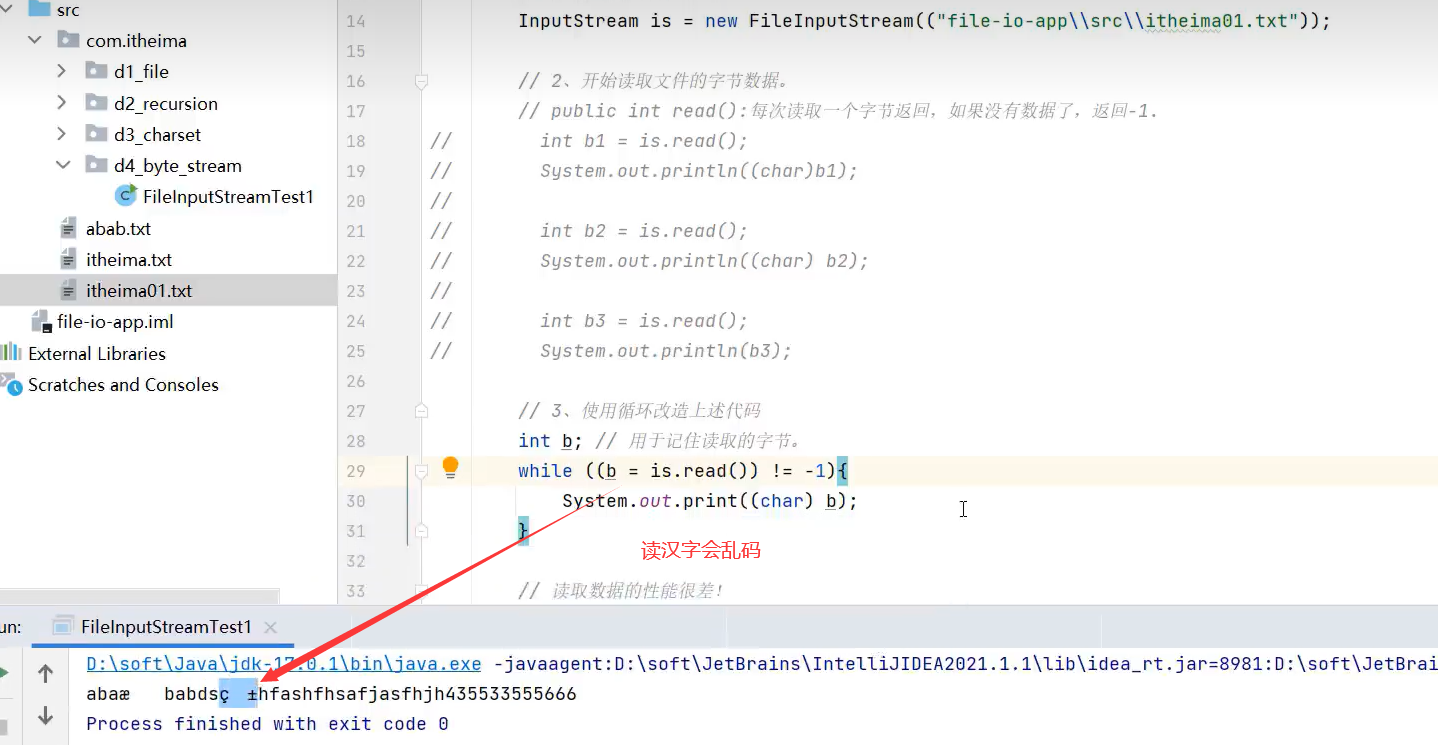
下面进行改善
2.每次读多个字节(推荐)
自定义字节数组byte [] buffer = new byte[每次读取的字节大小]
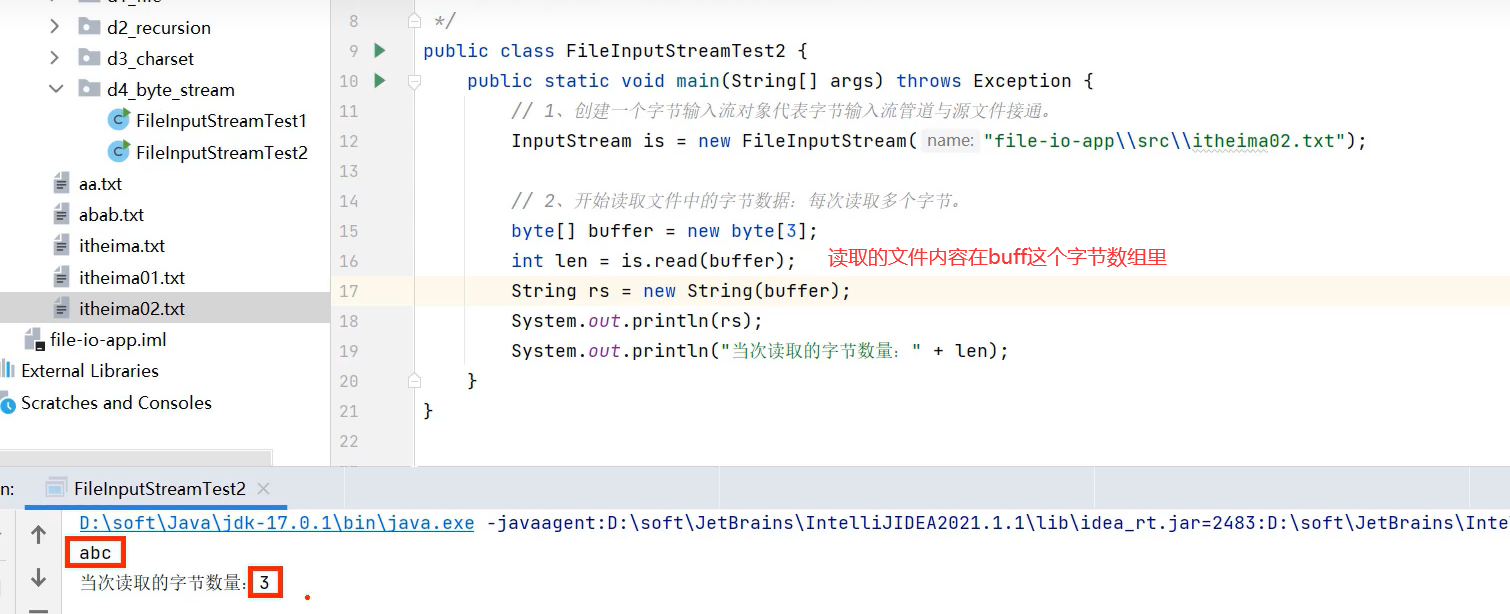
bug
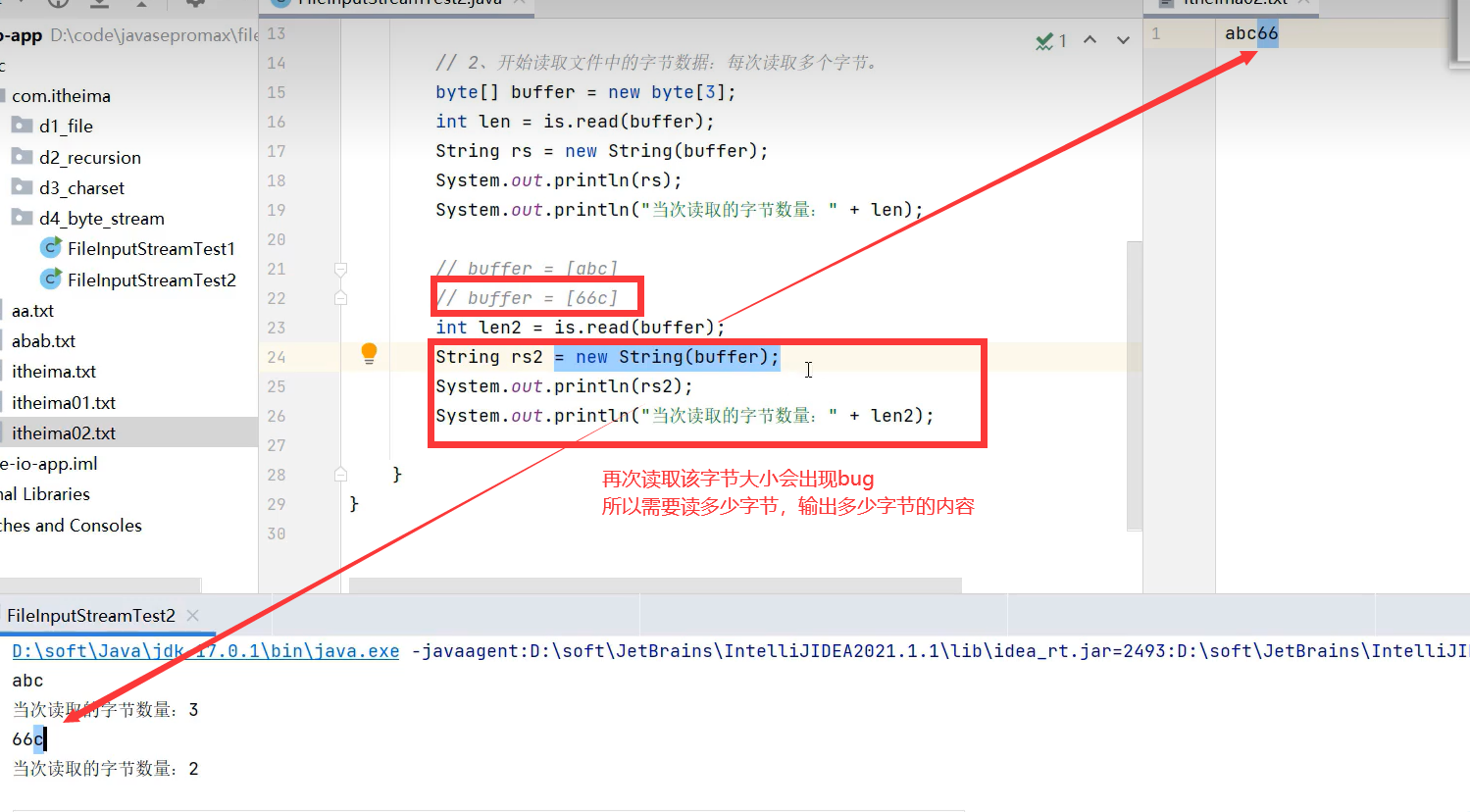
最终优化后的代码:
性能得到了明显提升,但是还是不能避免读取汉字时会乱码,如下图每次截取3个字节,可能会把汉字中的字节截断
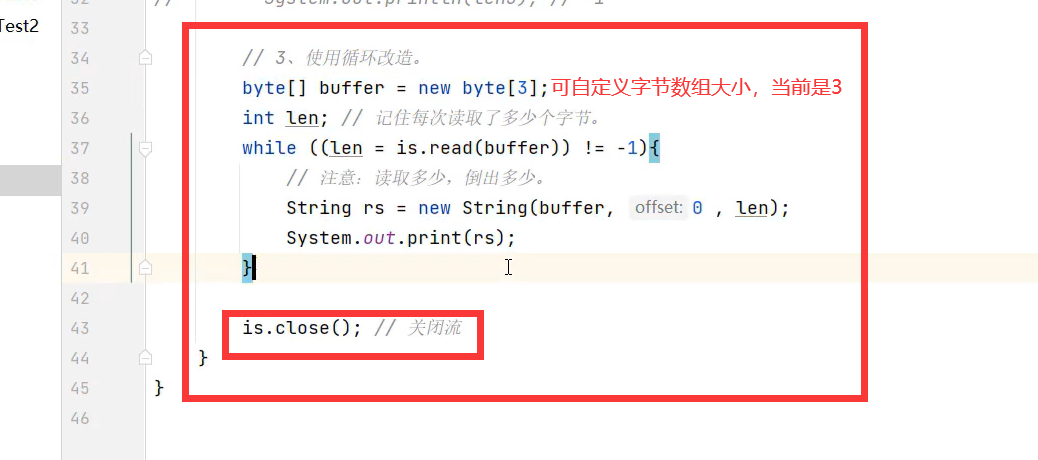
常用于拷贝文件,文件传输等操作。
3.一次读取完全部字节(可以解决读取的内容中文乱码问题)——不适合一次性读取大文件


方式1
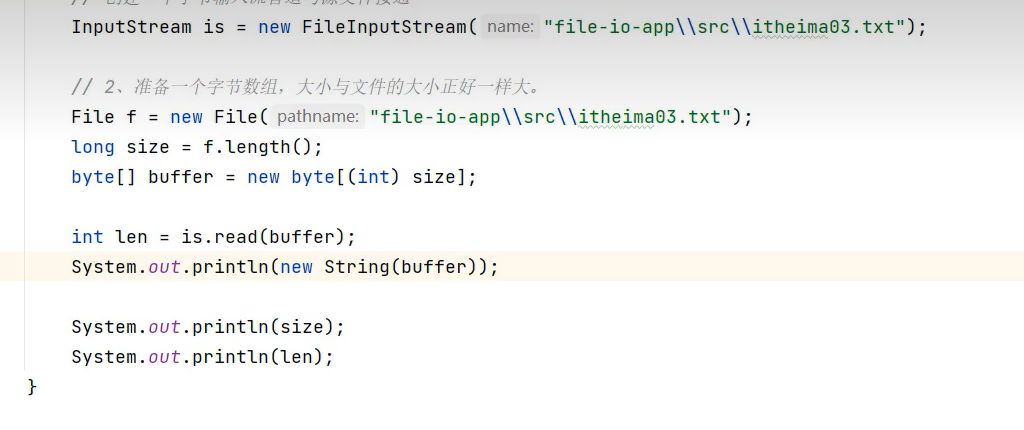
用完记得用close()方法关闭流
方式2(代码简洁,若读取的文件太大,会抛异常)
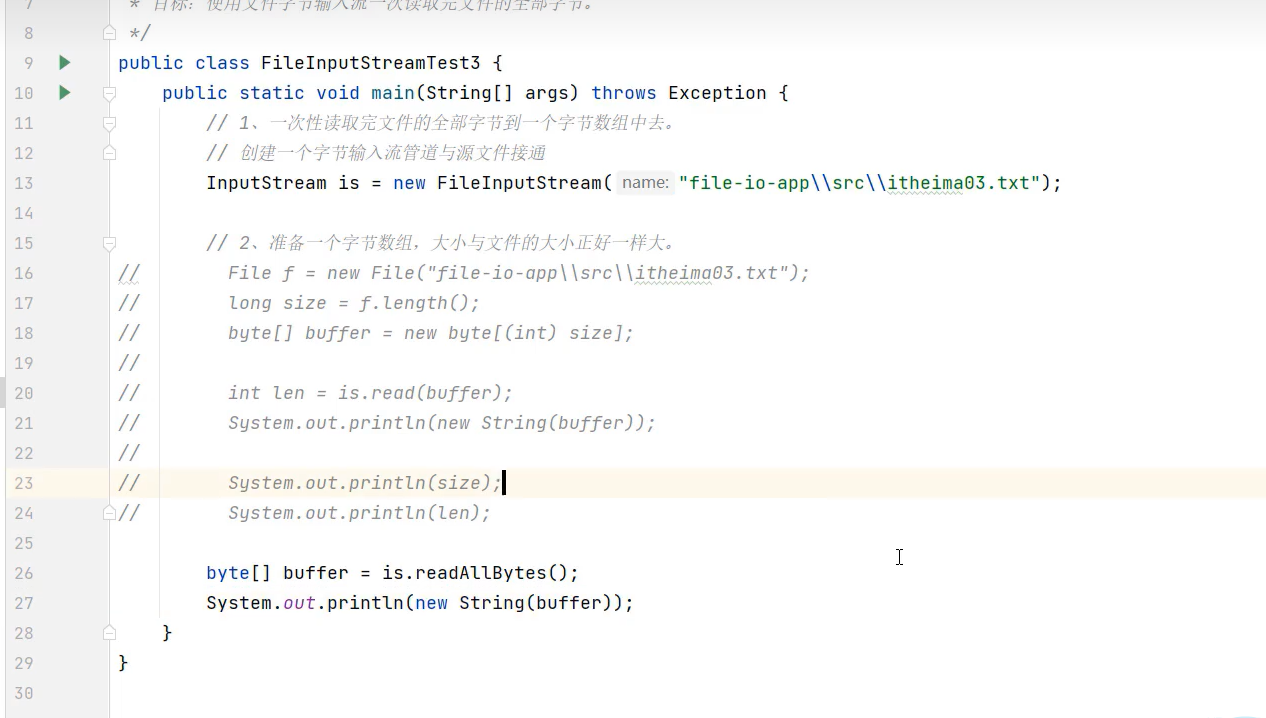
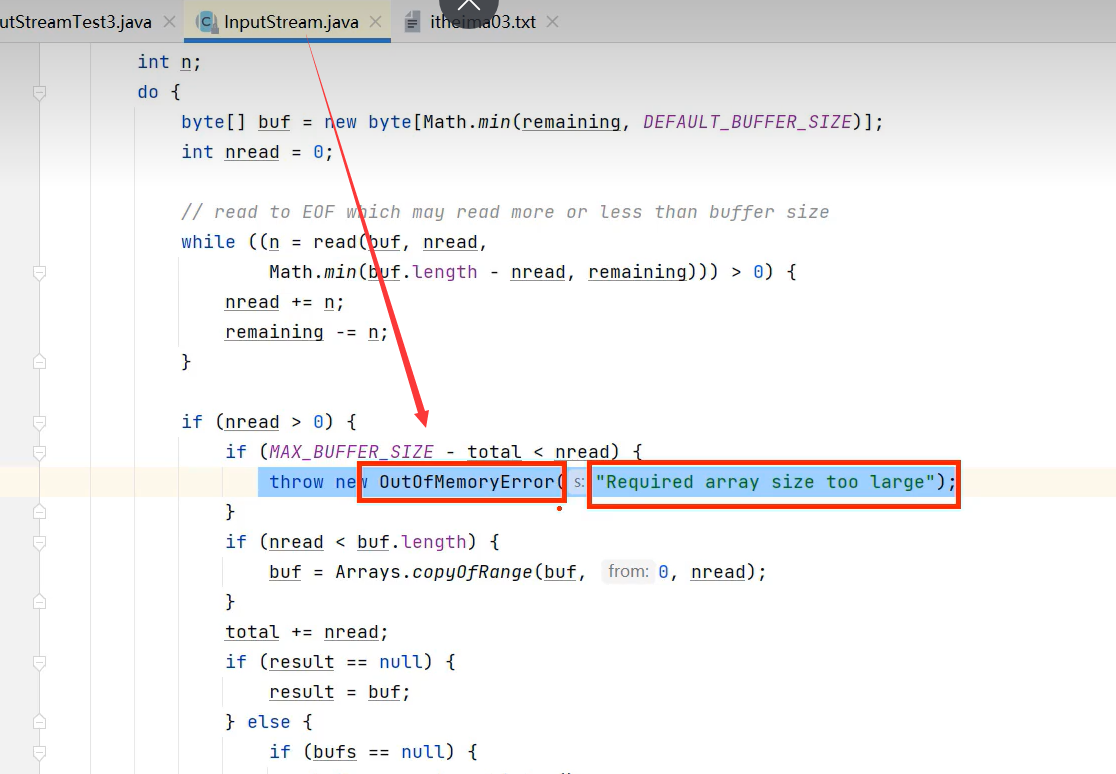
总结

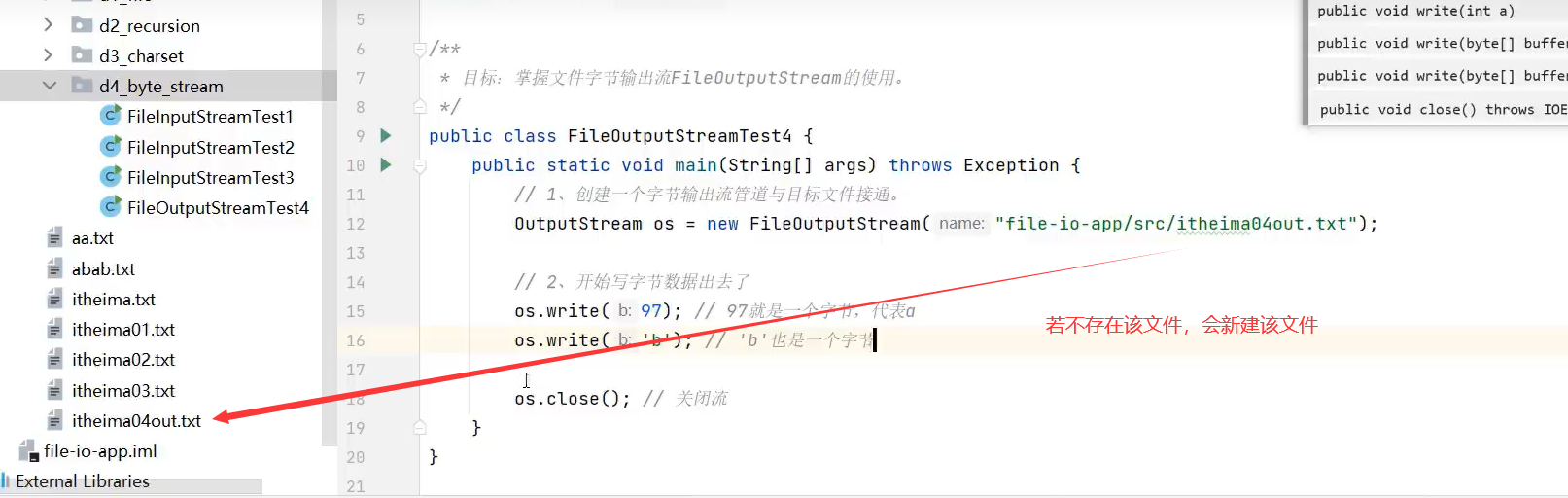
2.FileOutputStream(字节输出流)


close()方法关闭流。
示例代码:
1.写单个字节
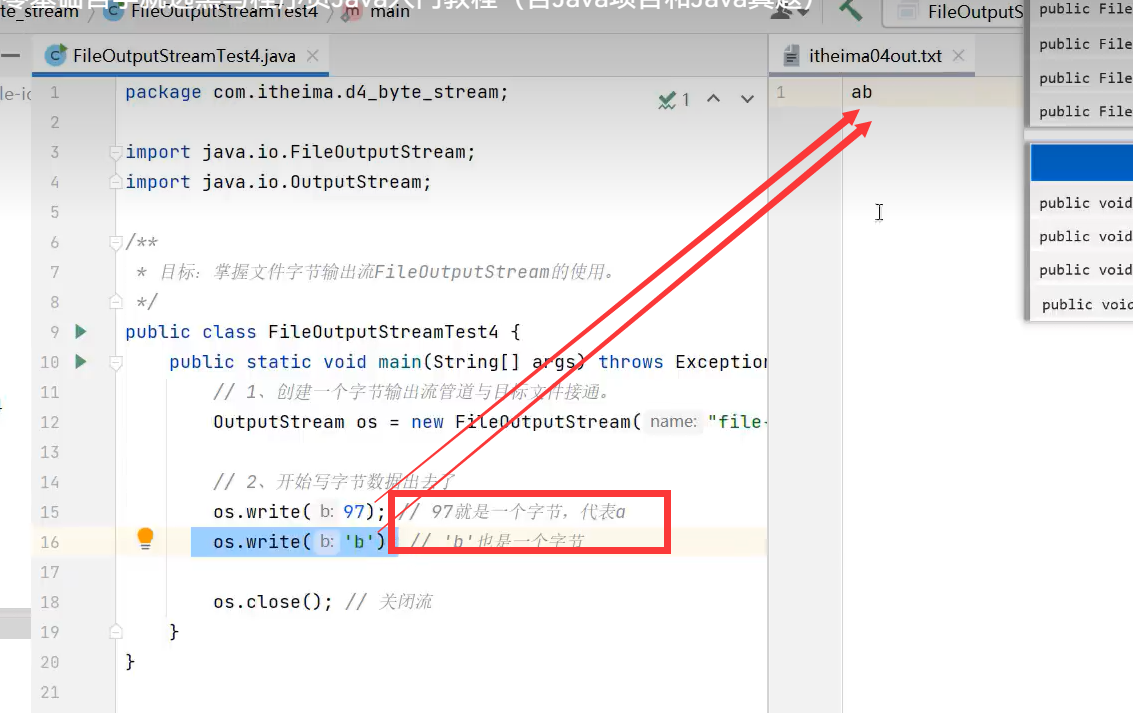
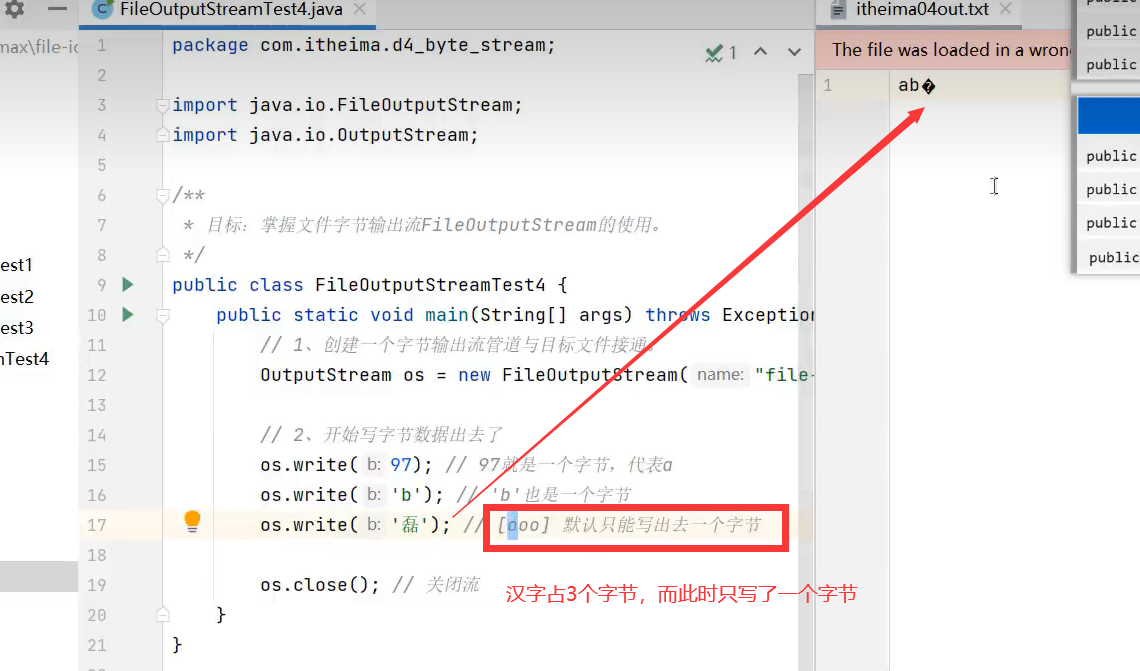
2.写多个字节(要写回车直接写"\r\n".getBytes())
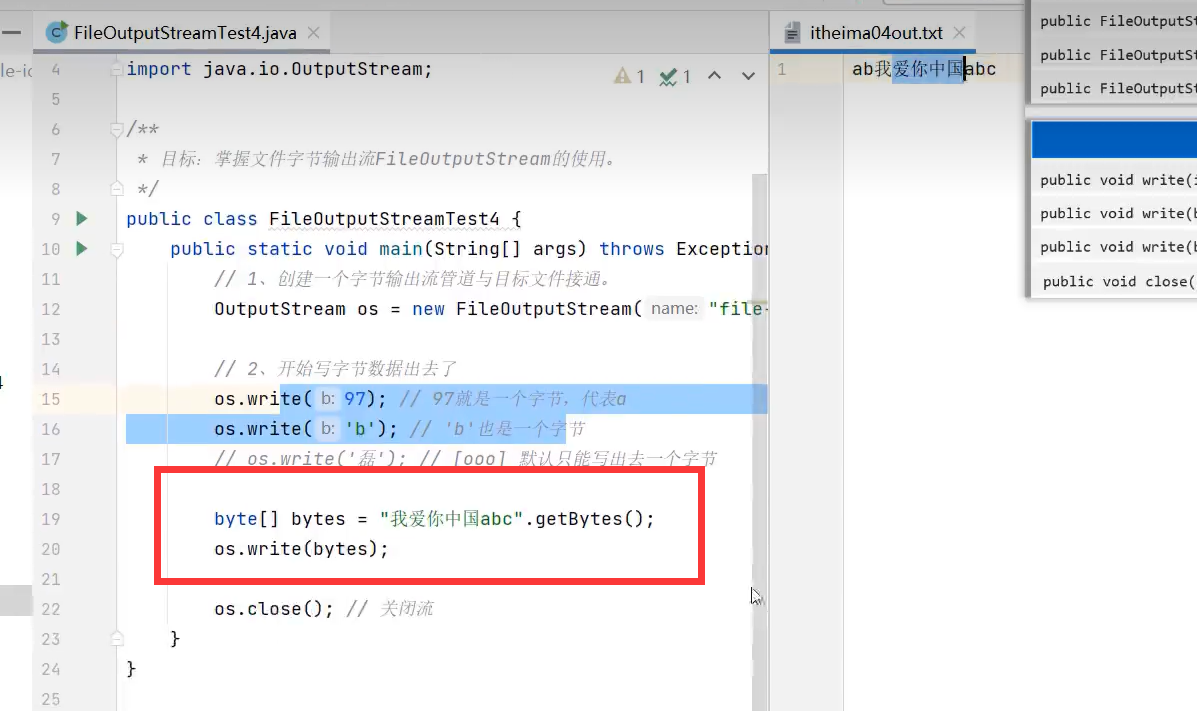
按需写多个字节
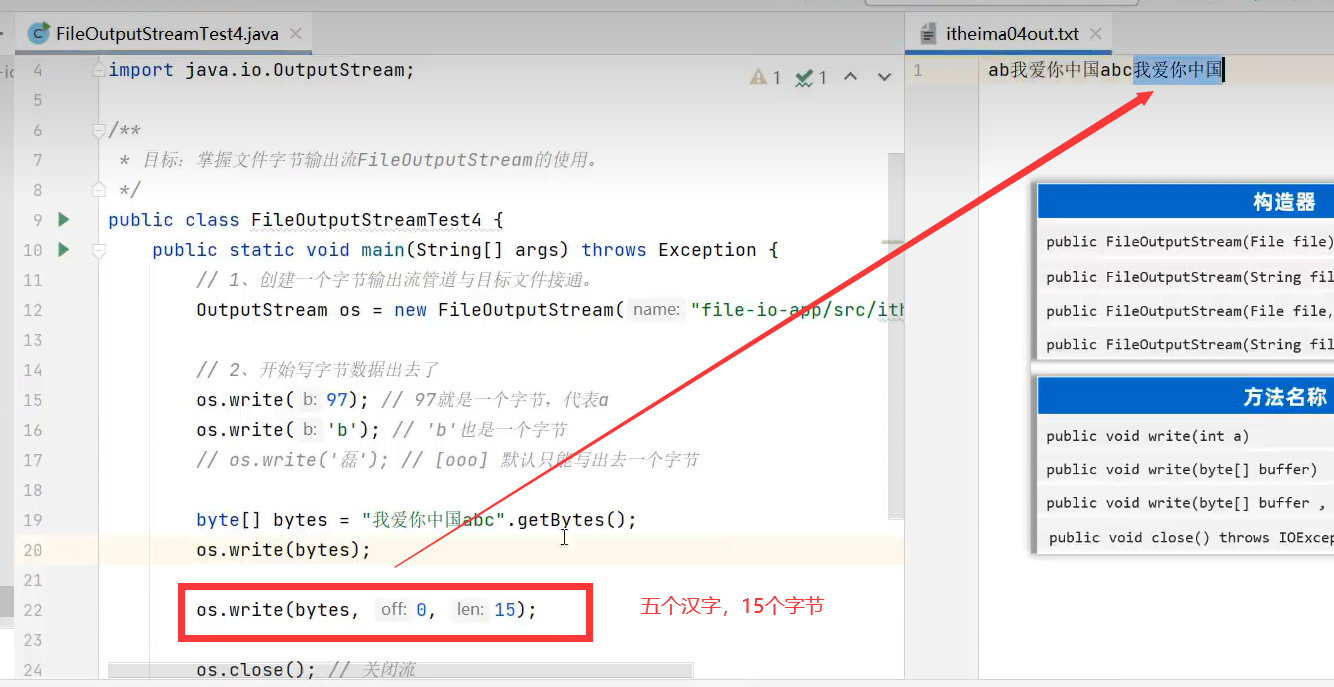
上面的文件写操作都是重新覆盖,要追加文件写的内容,需在下一个参数中填true
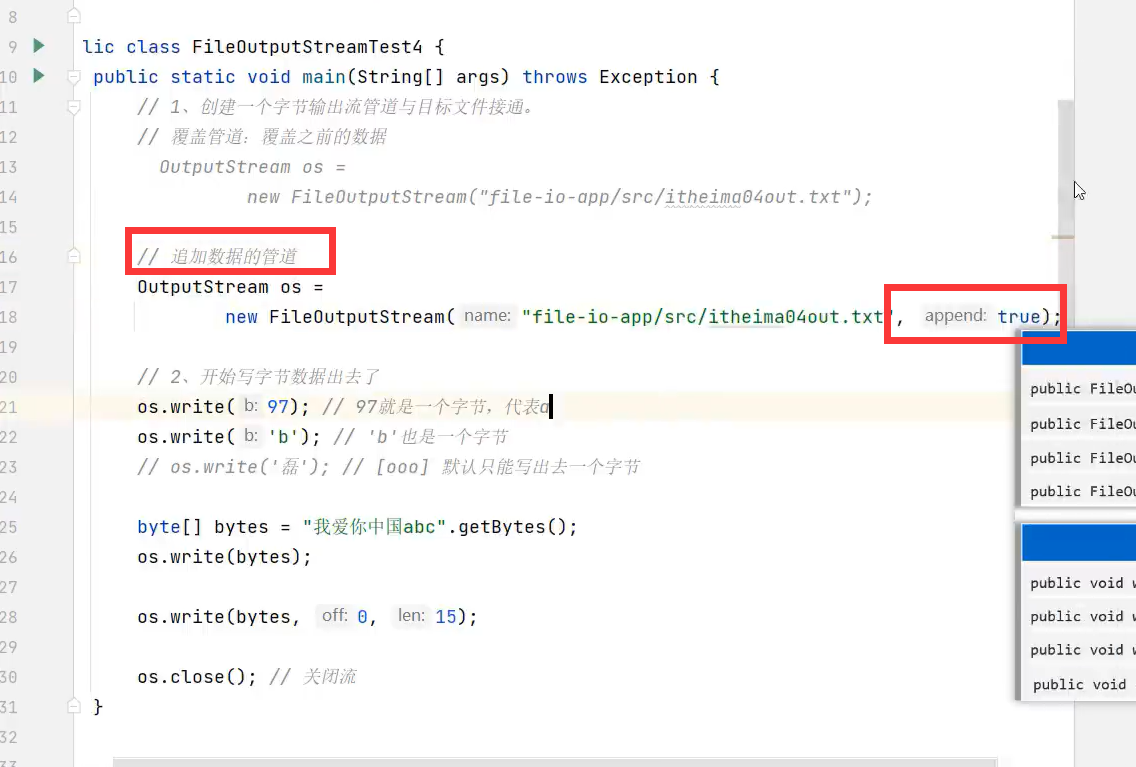
要写换行符直接用"\r\n"
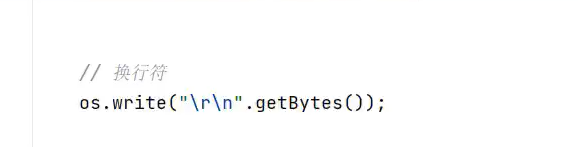
文件拷贝案例(字节输入流和字节输出流实现)
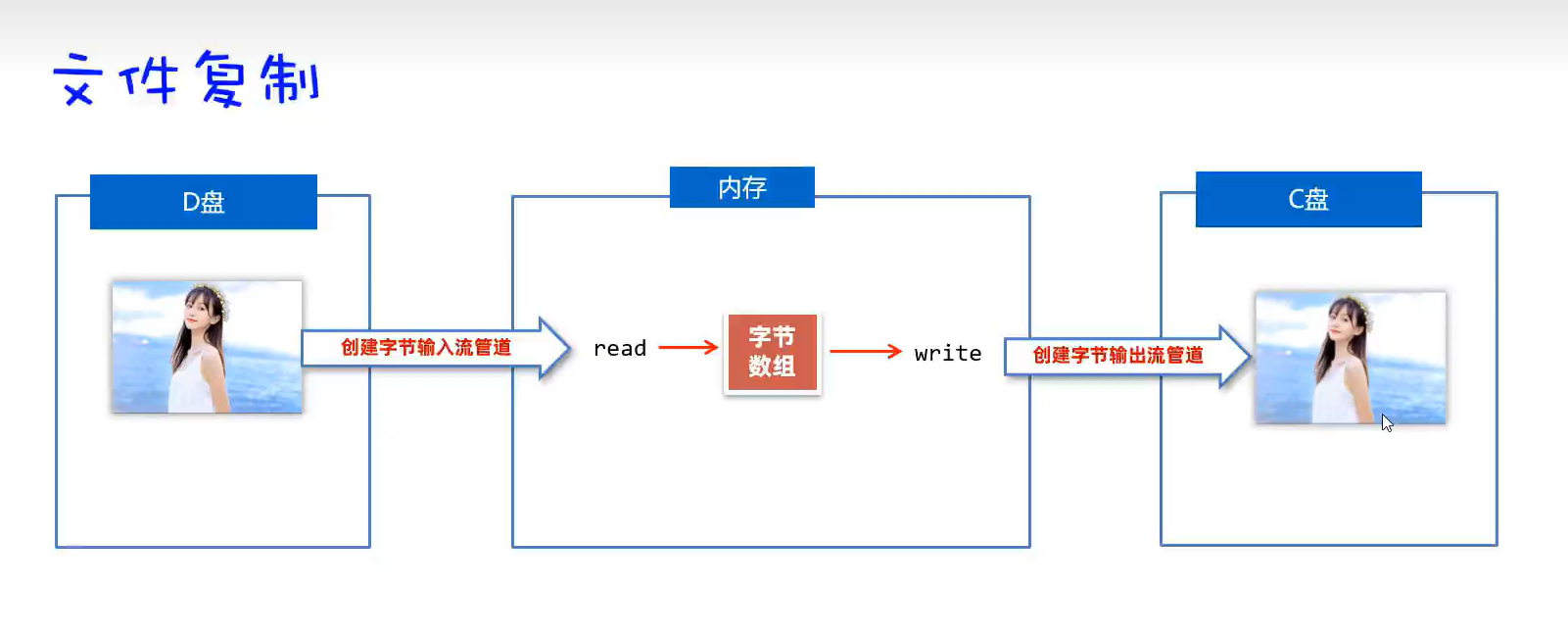

实现代码
释放资源
1.try-catch-finally(代码比较复杂,但也可以使用)
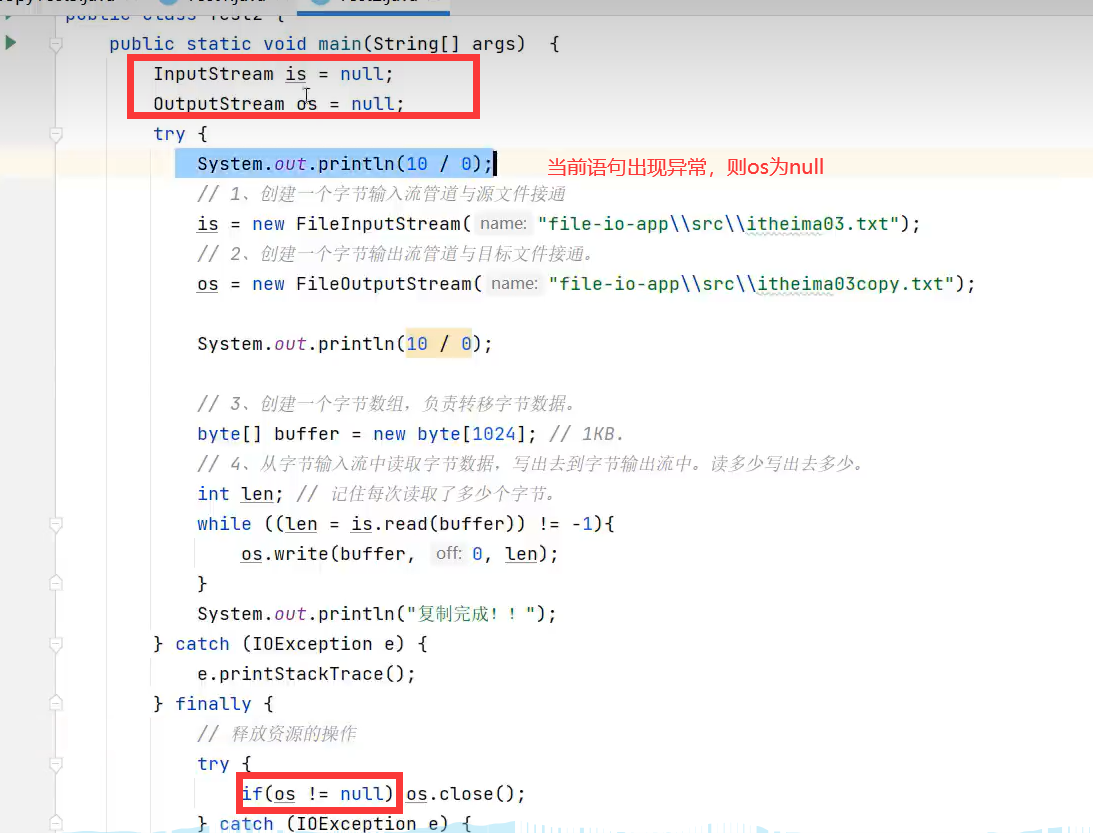
2.try-witch-resource(代码简洁)
try-catch执行完成后,会自动执行资源的close()方法
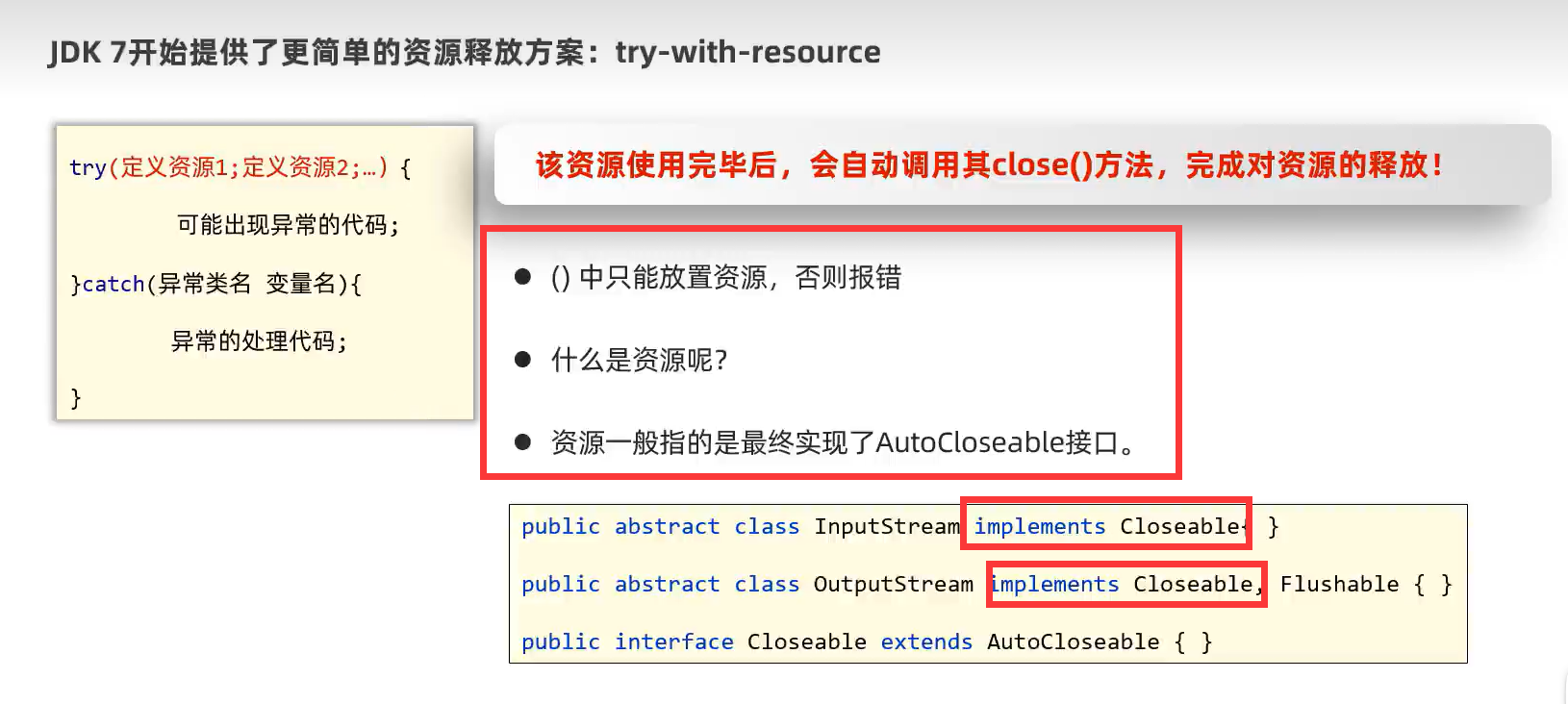
图1-1
格式:
try(
资源
)
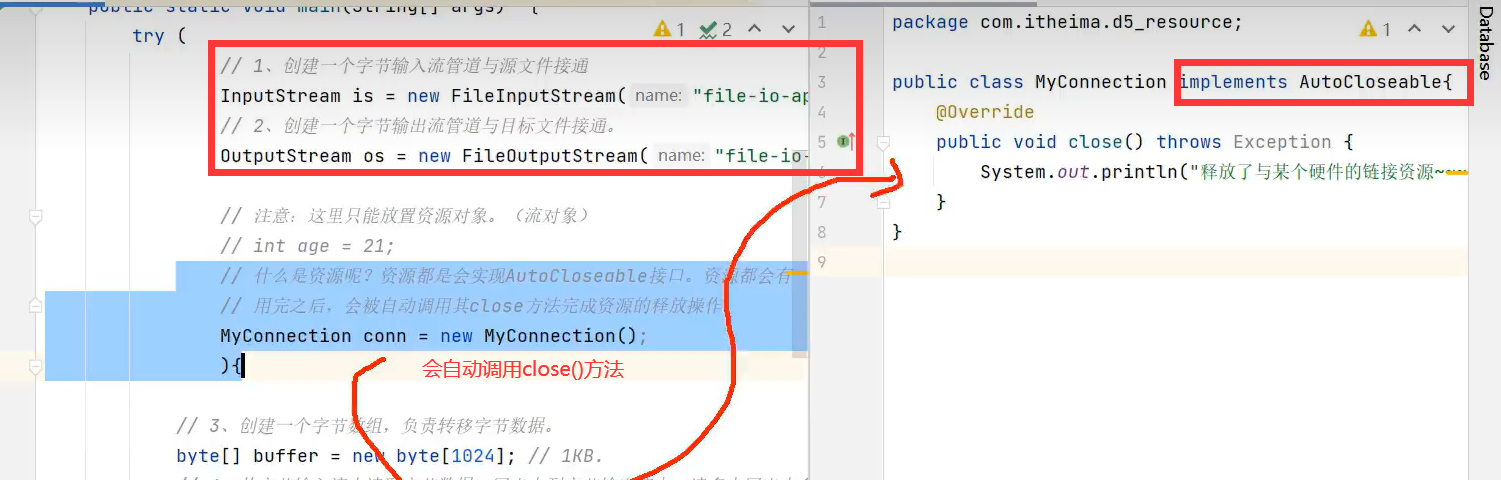
资源就是该类实现AutoCloseable接口或者它的父类实现了AutoCloseable也算该子类实现了哦,在代码执行后会自动执行重写的close()方法,如上图1-1。
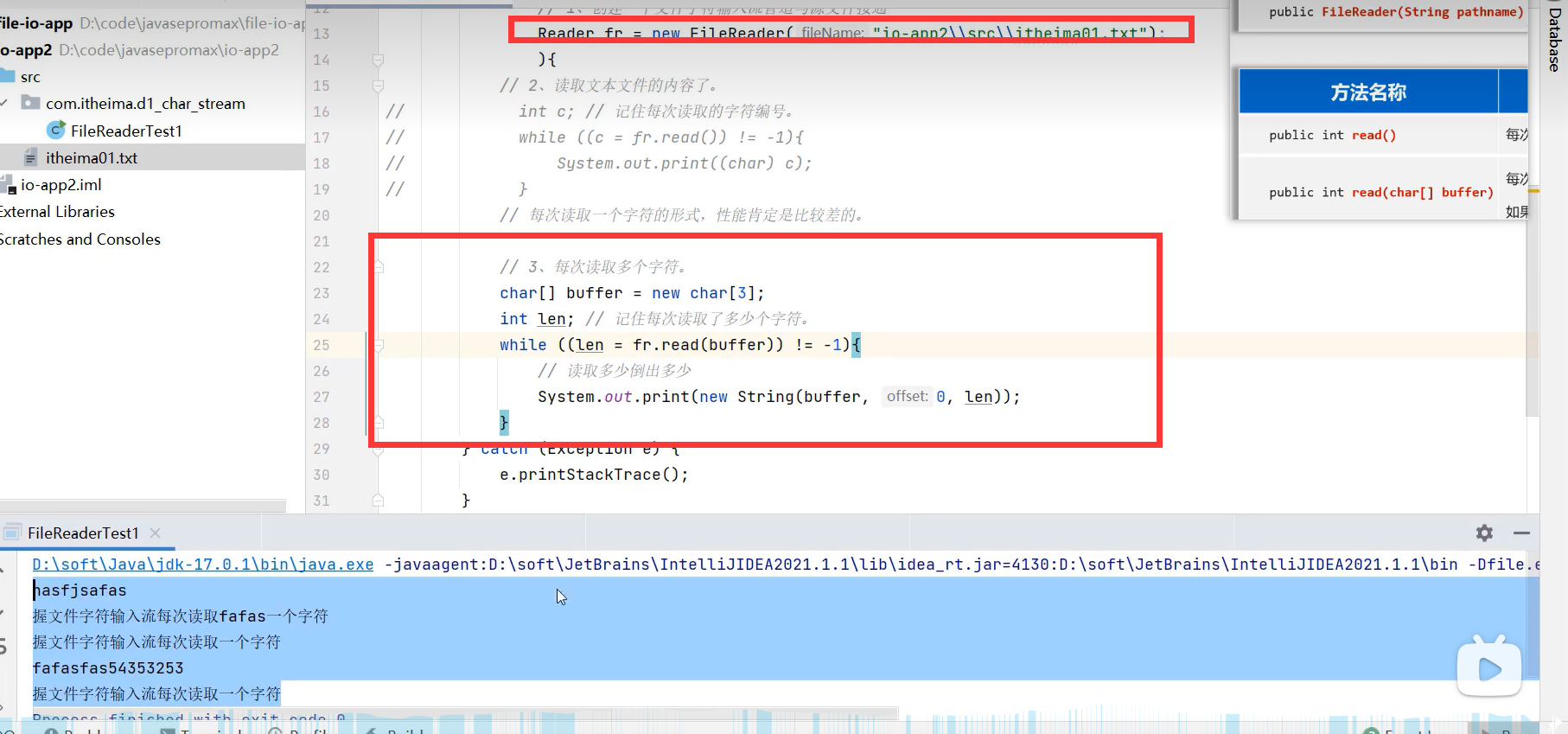
3.FileReader(字符输入流)

示例代码:
1.每次读单个字符(性能差)
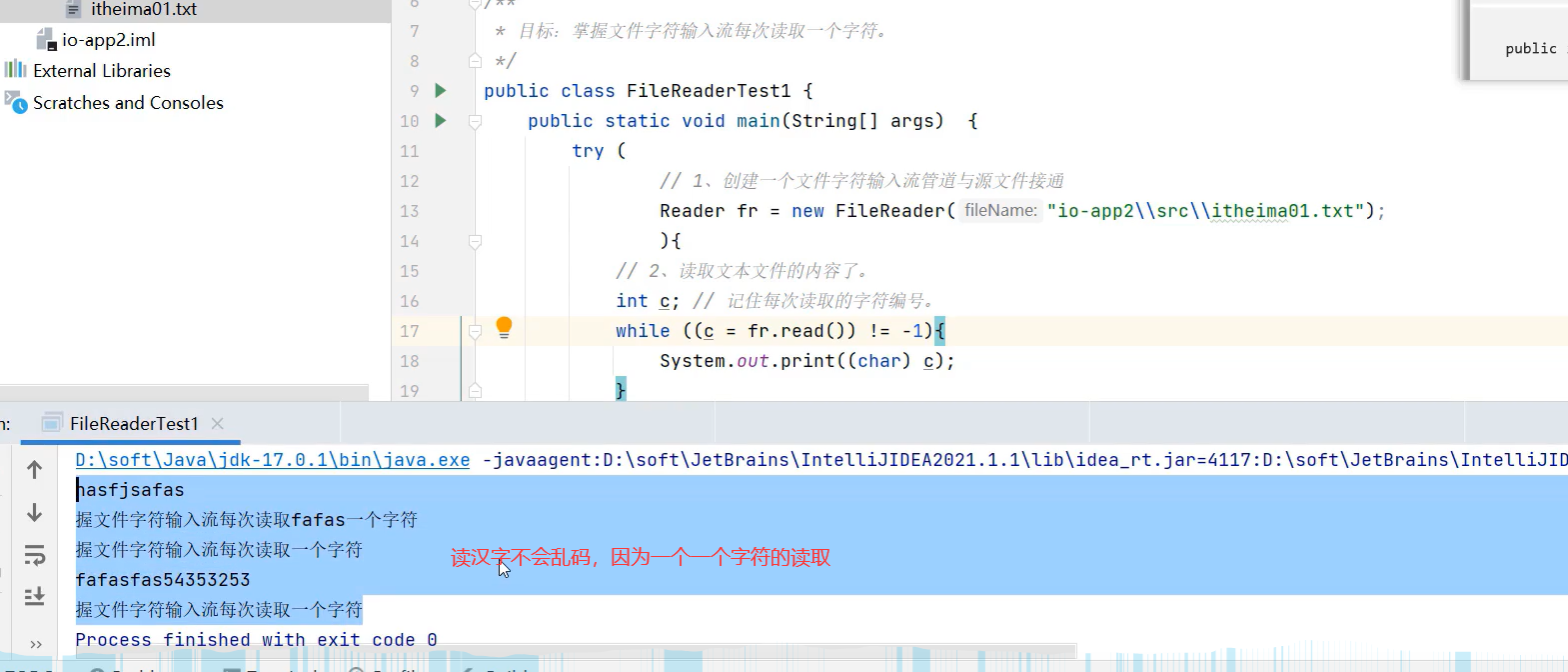
2.每次读多个字符(推荐)
4.FileWtiter(字符输出流)
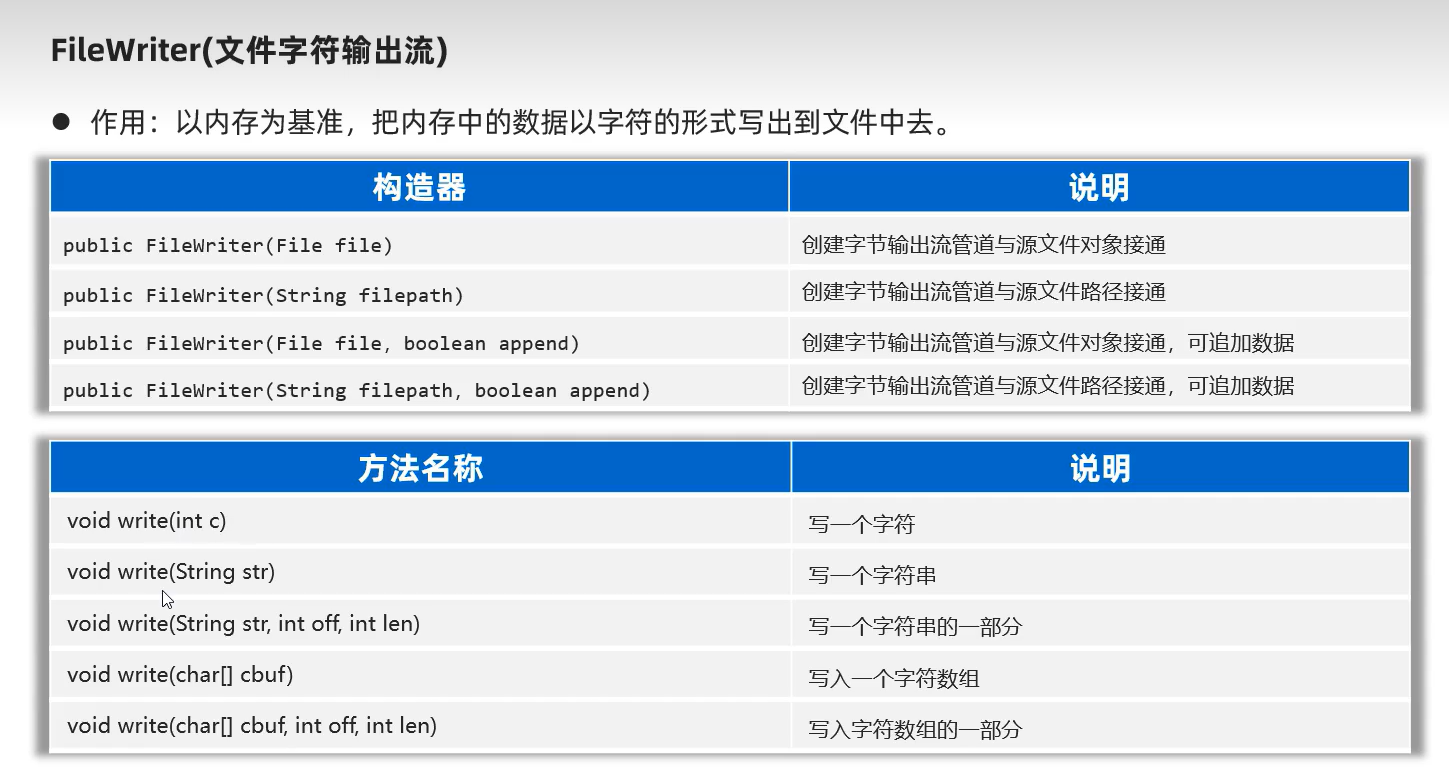
new FileWriter(File/String, true)中的true表示追加文件内容,默认不填写的话是覆盖文件内容操作。
.write("\r\n");表示写入换行。
示例代码
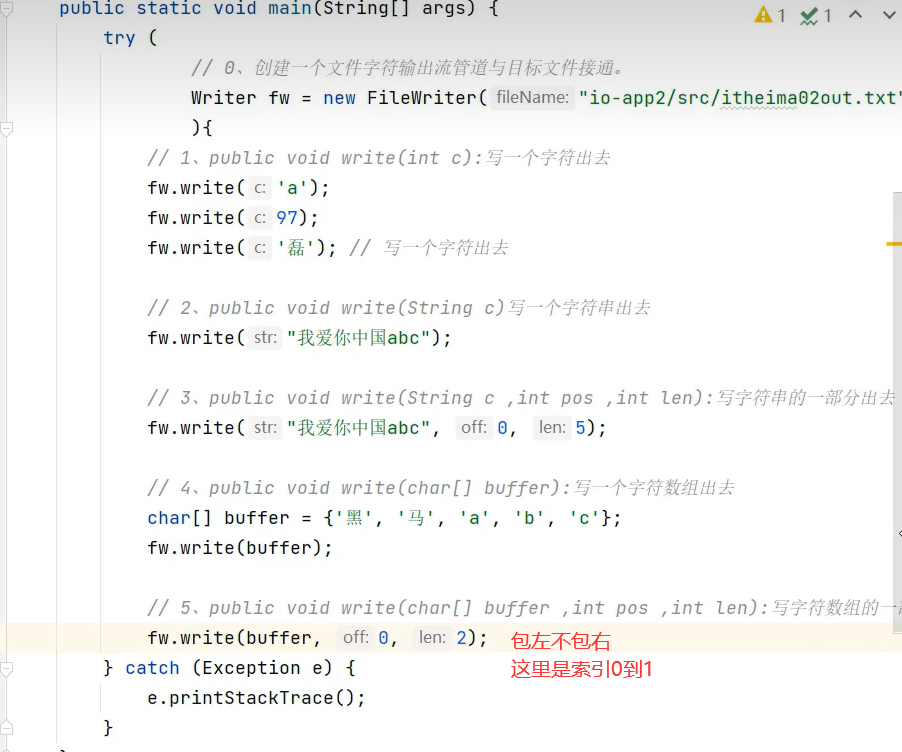
注意事项

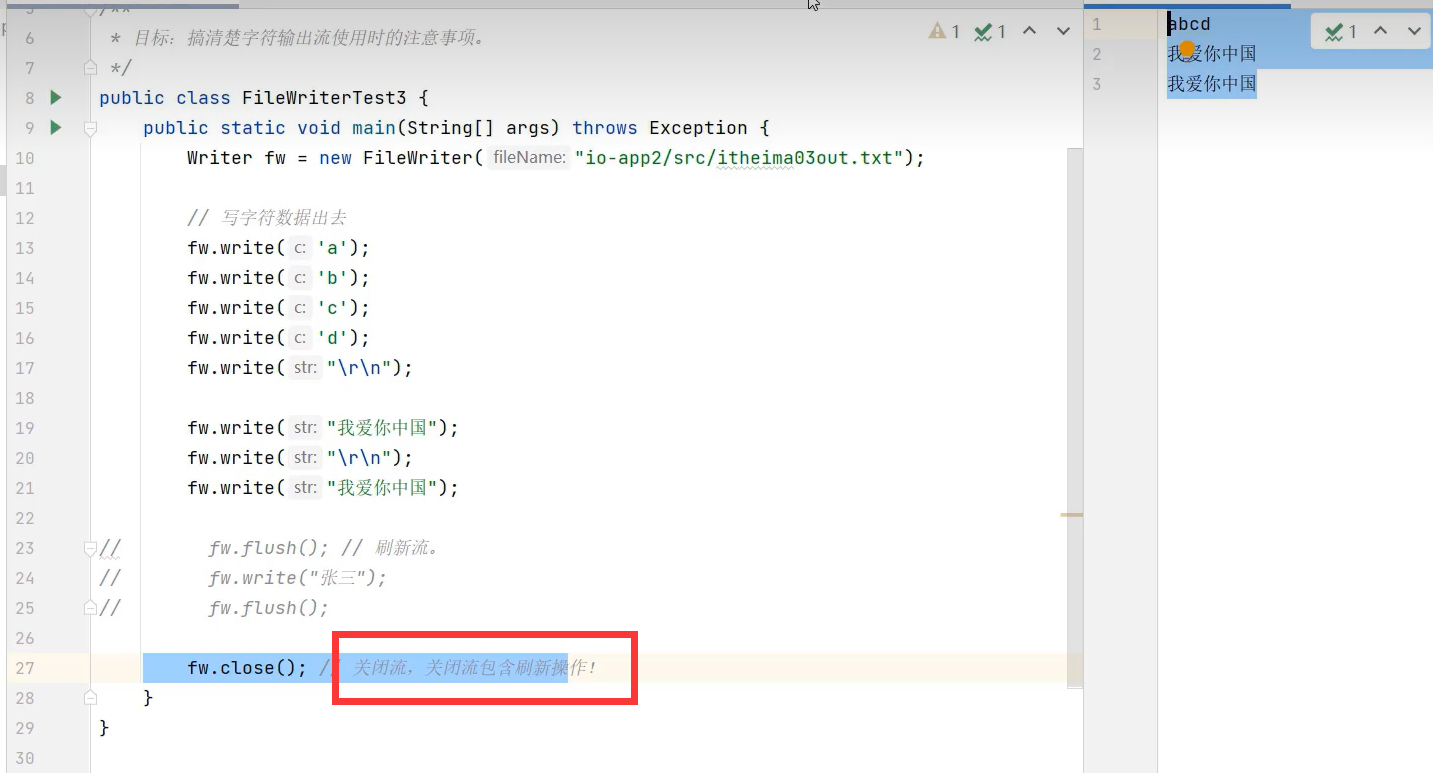
注意:字符流写内容的时候,会先把内容存入内存的一块区域暂时保存,当你调用flush或close方法时,才会真正写入到文件中去。若该内容区域满了,还没刷新或关闭的话,会先把这块区域的内容先写入到文件中去,以便存其他写入内容。
所以它的效率比字节输出流的效率高,因为字节输出流每次写文件内容会调用系统资源往文件里面写内容,而字符输出流可以自己控制写入次数
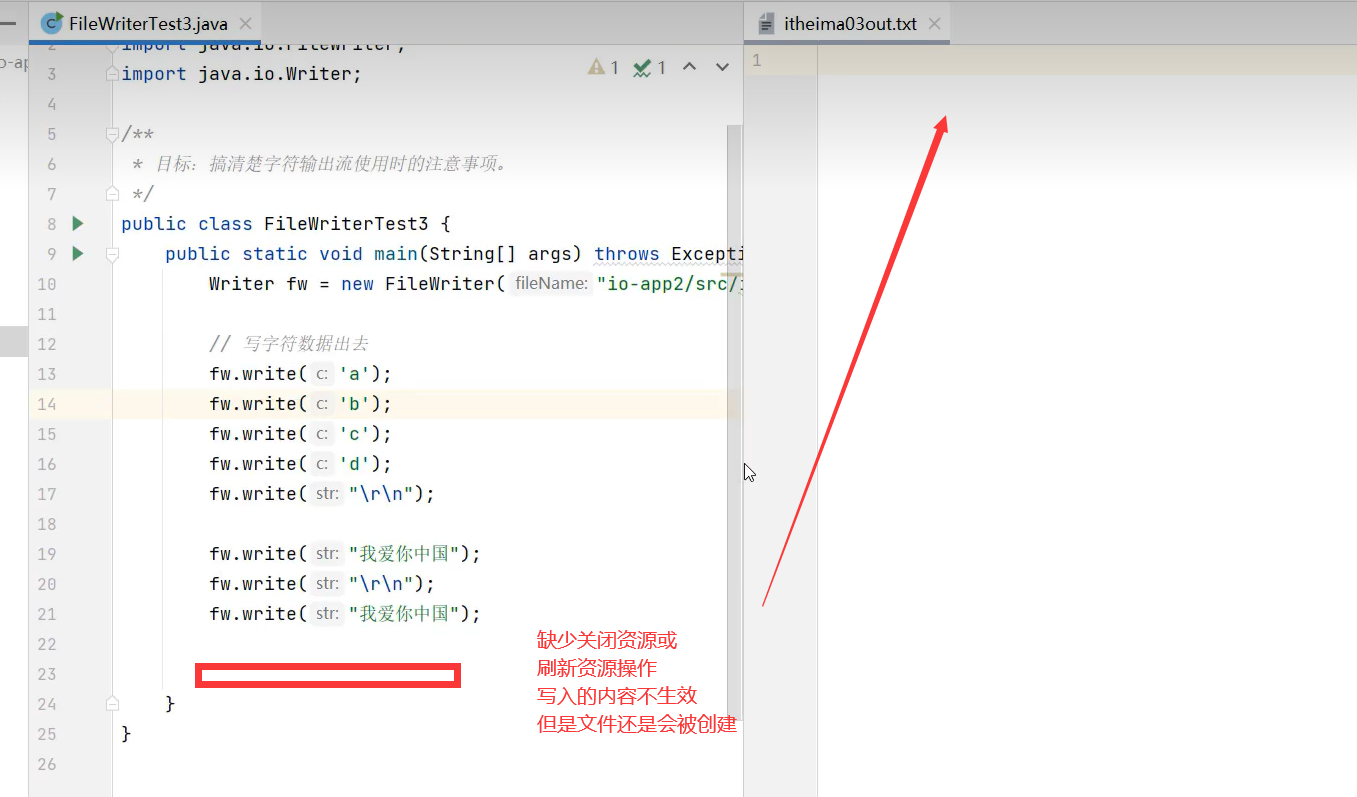
flush()方法刷新流,使得写入数据生效。刷新后还可以使用该流,也可以多次刷新
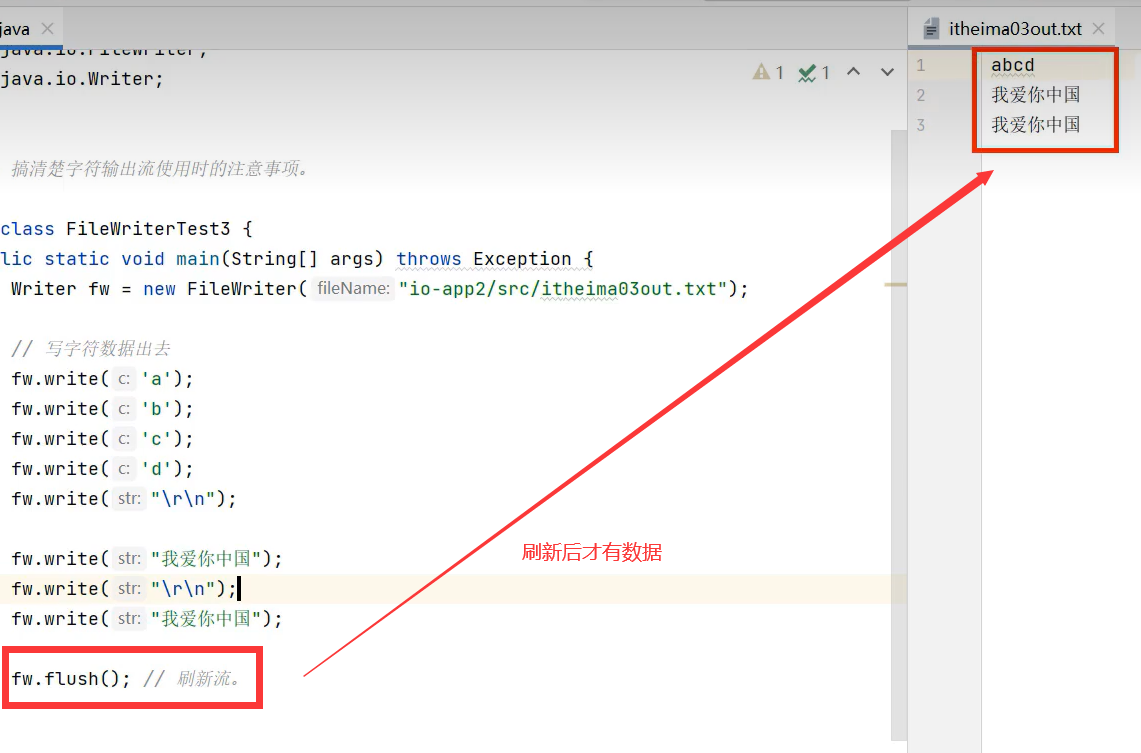
close()关闭流,使得写入数据生效。关闭流后,不能在使得该流,否则报错“Stream closed ”
4.缓冲流(提高读写数据的性能)
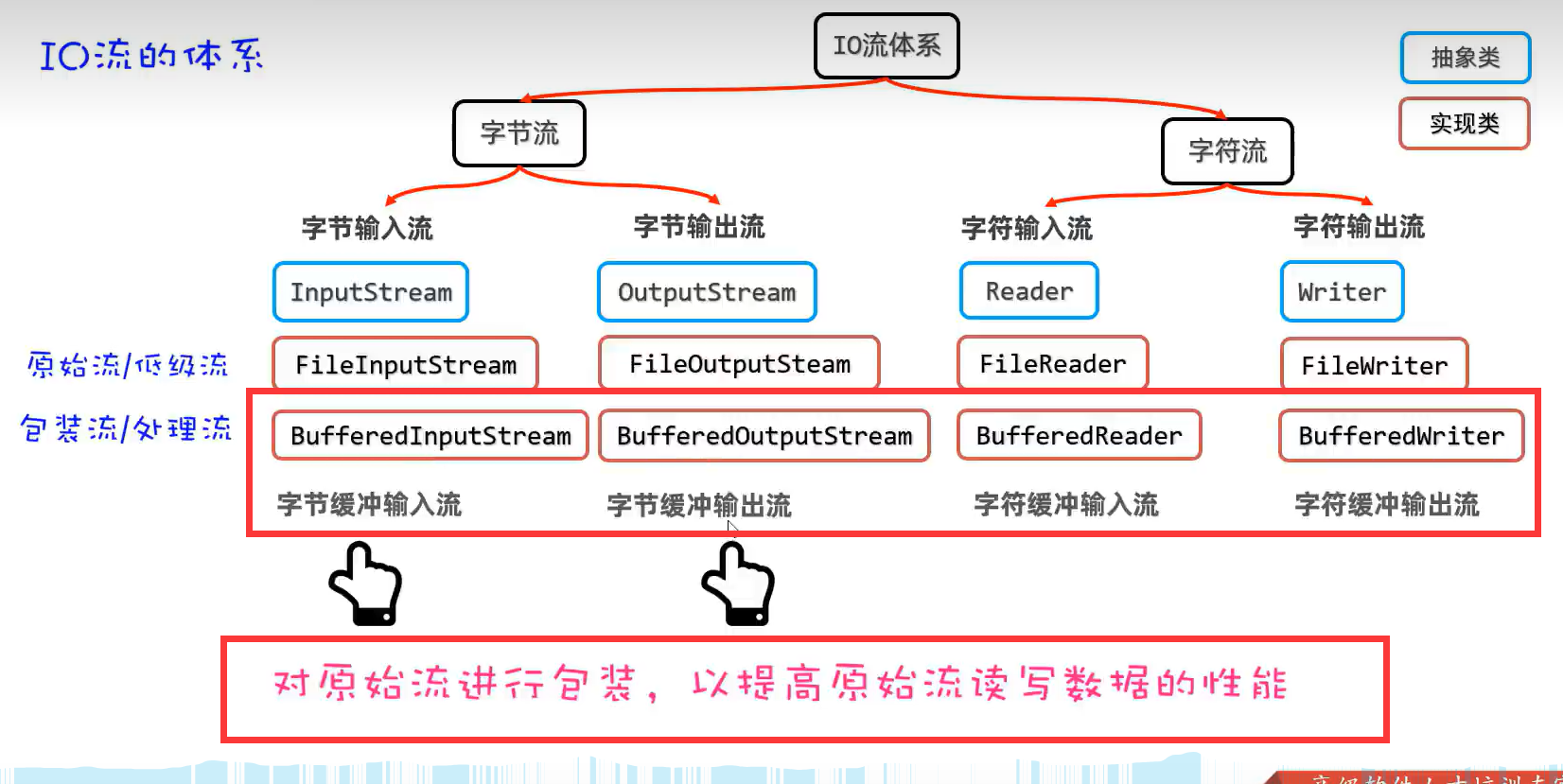
对原始流进行加工
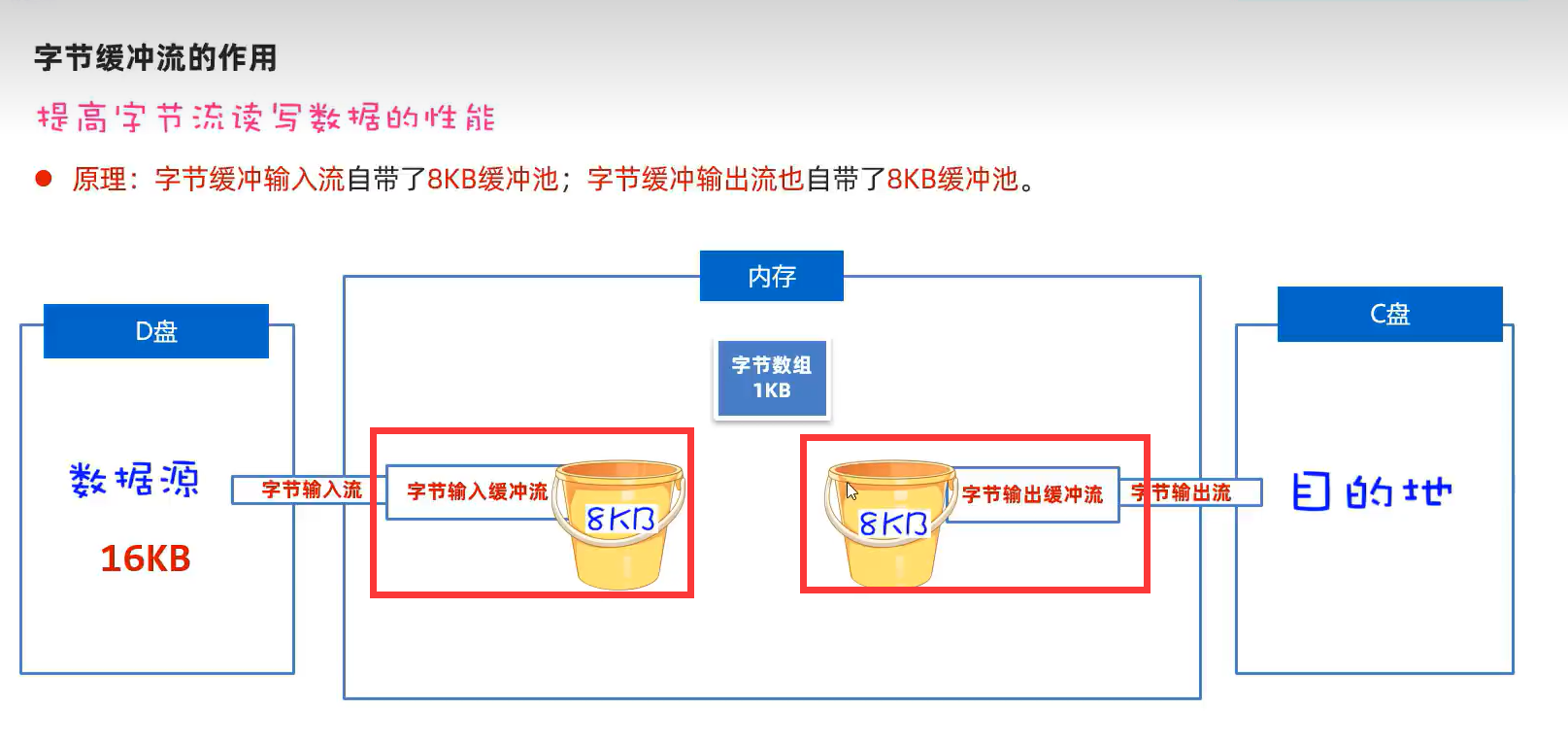

1.字节缓冲输入、输出流(BufferedInputStream、BufferedOutputStream)
代码不变,多了二行包装代码
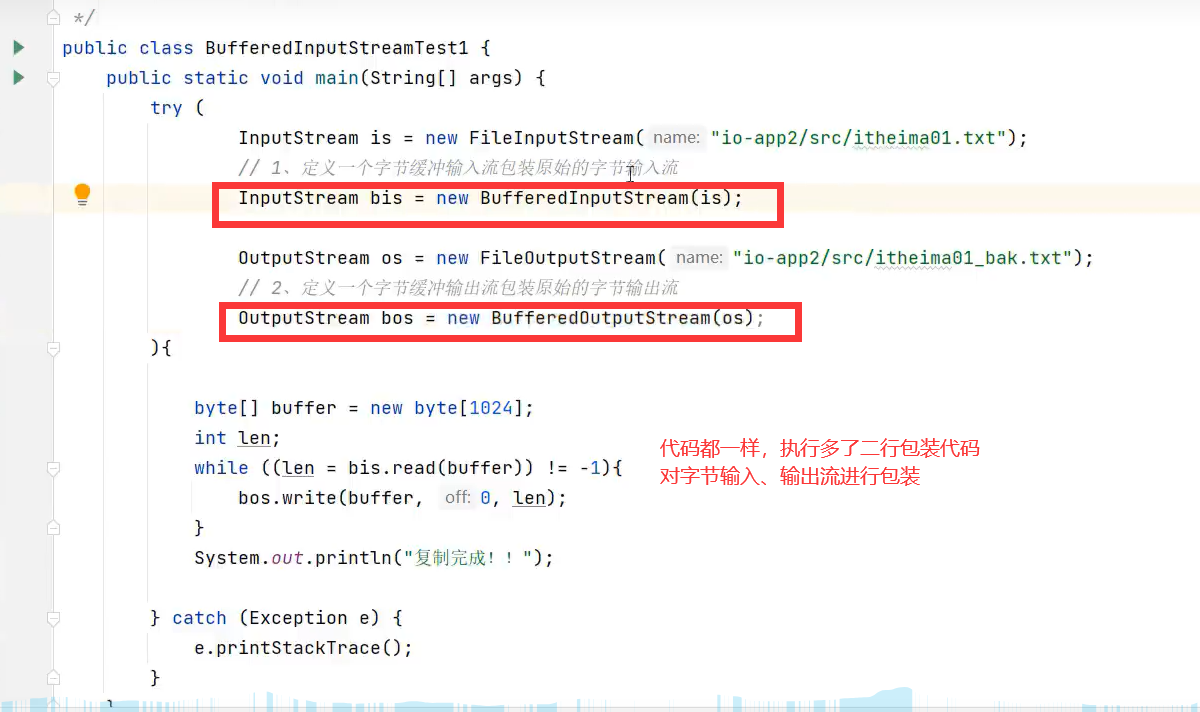
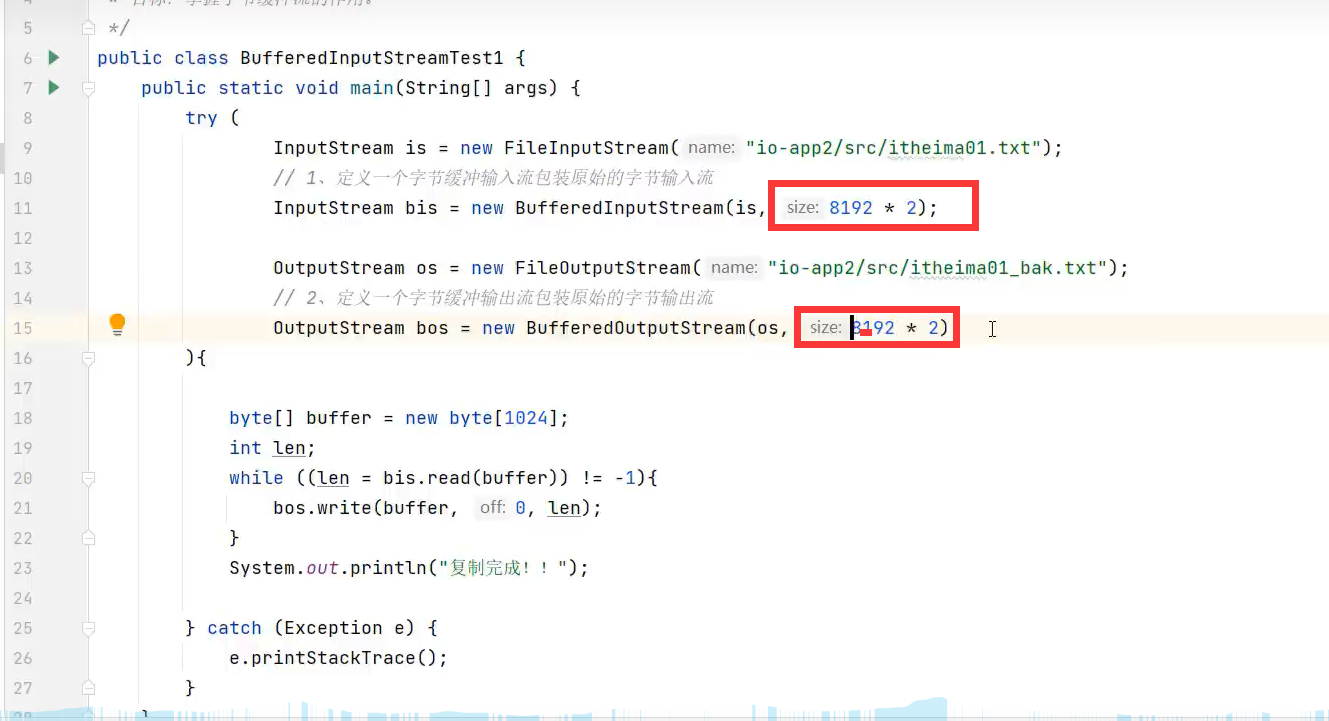
可定义缓冲池大小,默认8KB
2.字符缓冲输入、输出流(BufferedReader、BufferedWriter)
1.字符缓冲输入流(BufferedReader)

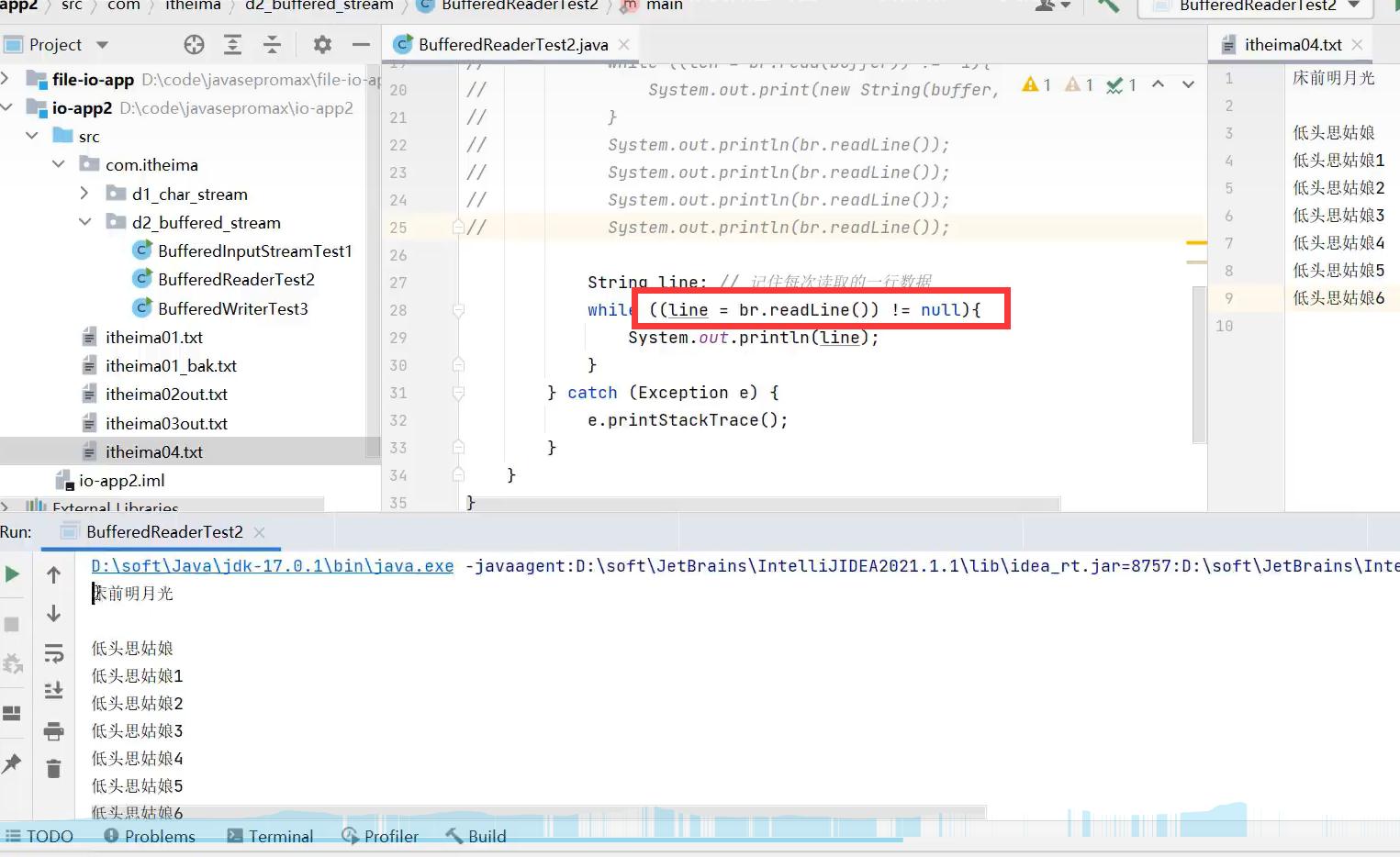
注意:readLine()是该BufferedReader的独有方法,若用多态写法的话,就不能调用该独有功能了。
示例代码:
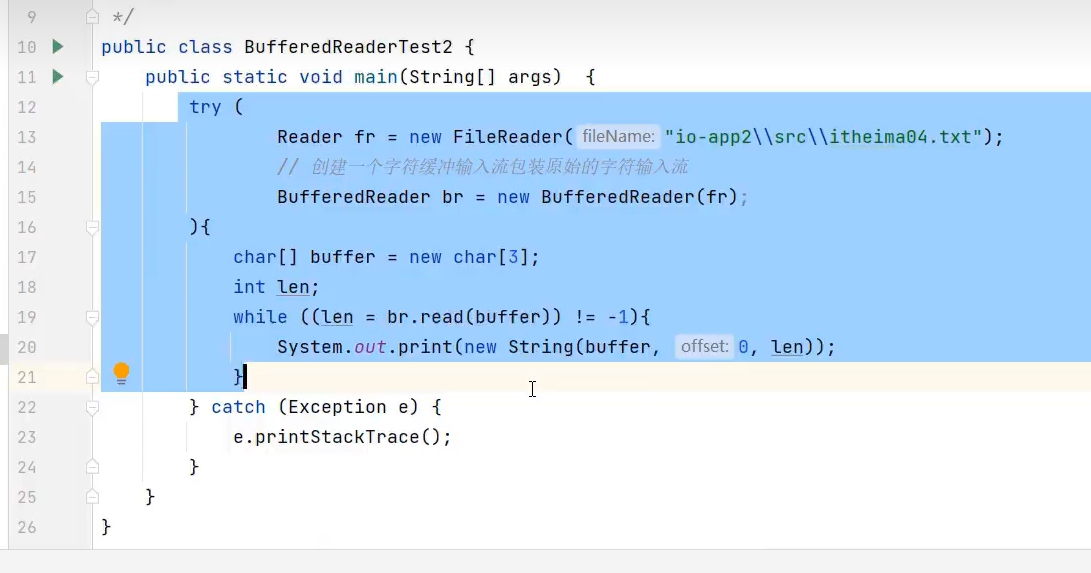
独有的readLine()方法,不能用多态写法
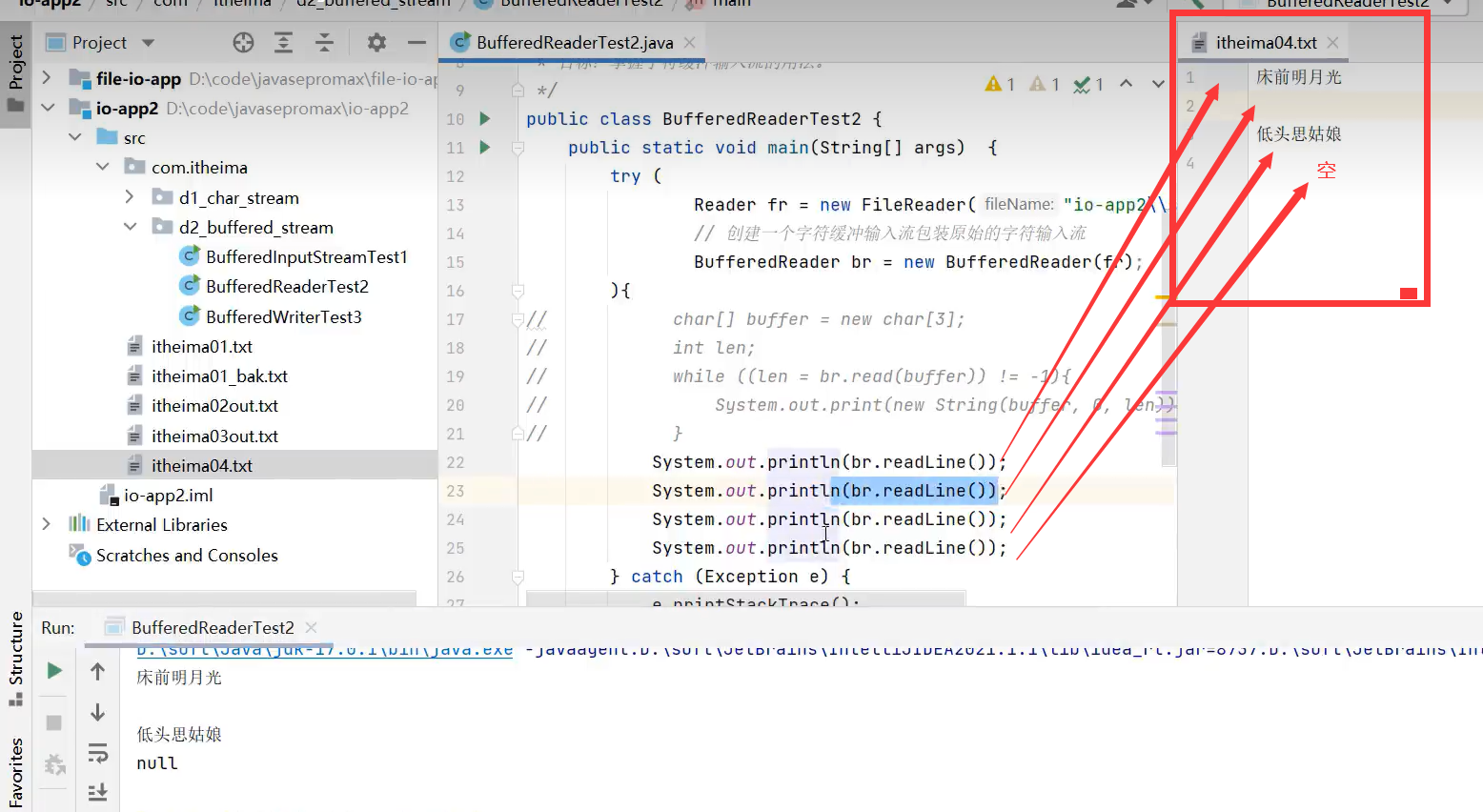
readLine()读到结尾会返回null,所以可以配合循环来实现读内容
2.字符缓冲输出流(BufferedWriter)
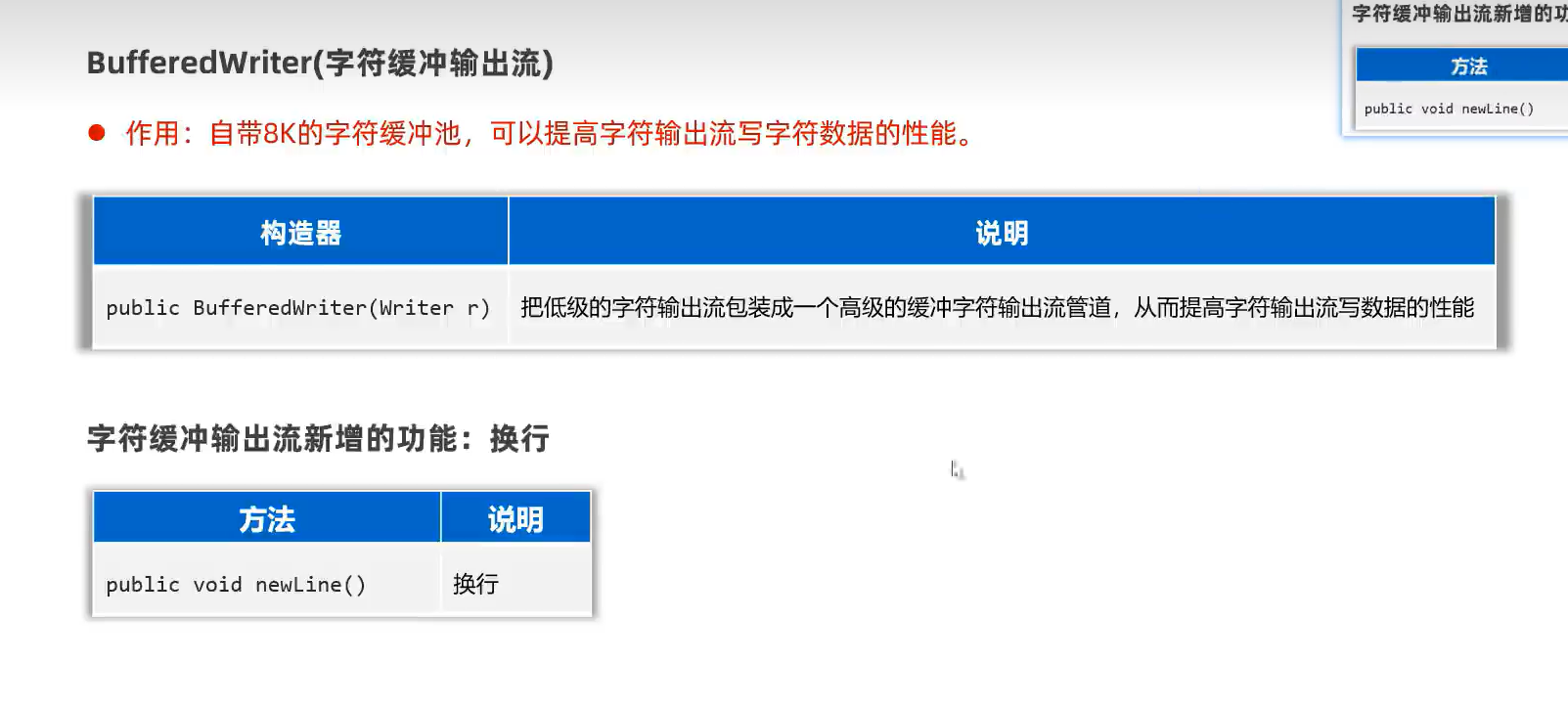
newLine()是该类的独有方法用于写入换行,要调用该方法不能用多态写法,只能该类变量接收。
5.字符转换流(解决不同编码读取时乱码问题)
注意:该字符转换流是针对原始字节流,因为只有字节流才会出现乱码问题,而不针对字符流(字符流不存在乱码问题)。
该字符转换流可以理解为原始字节输入、输出流的字符流。该流还是低级流,可以用缓存流进行包装

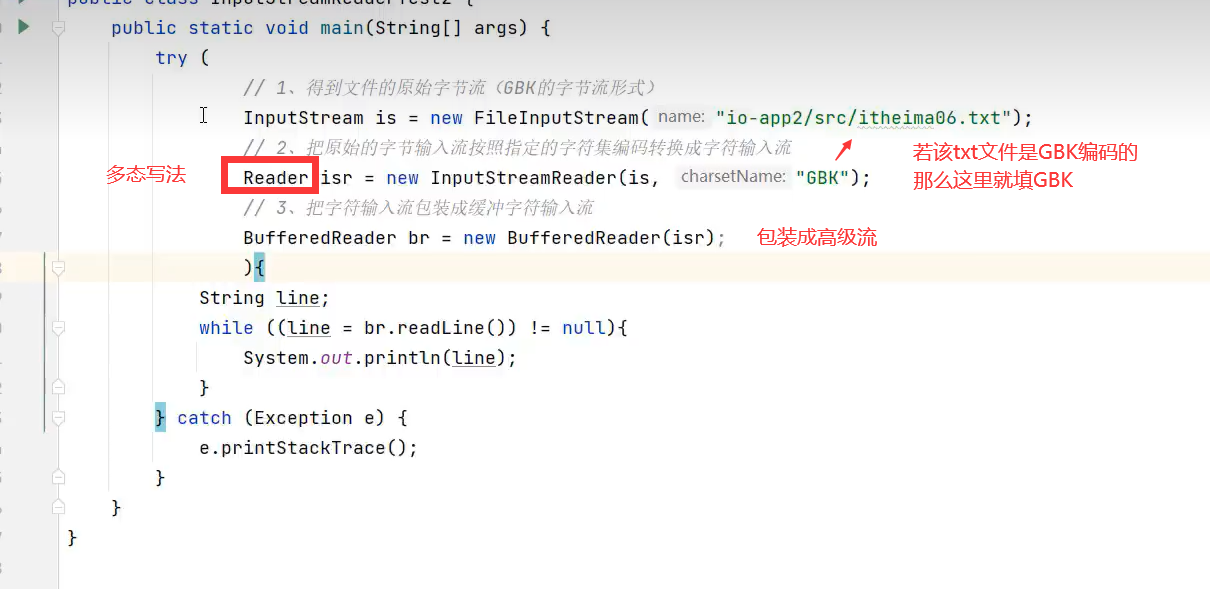
1.字符输入转换流

示例代码:
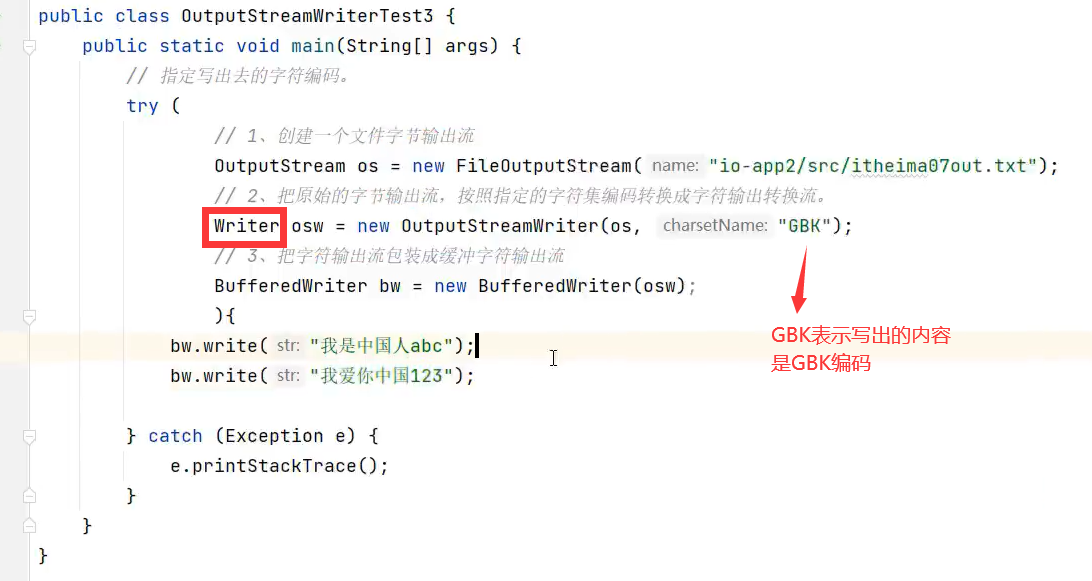
2.字符输出转换流

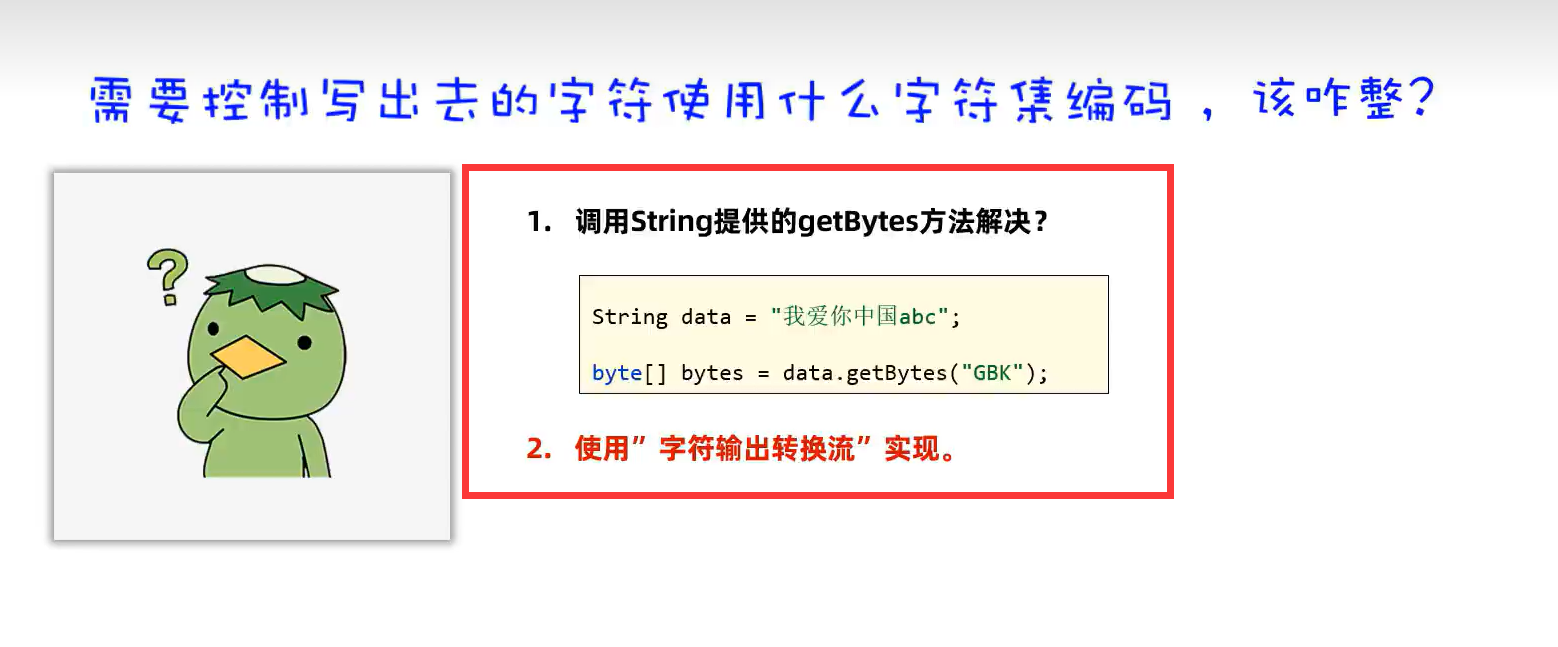
示例代码:
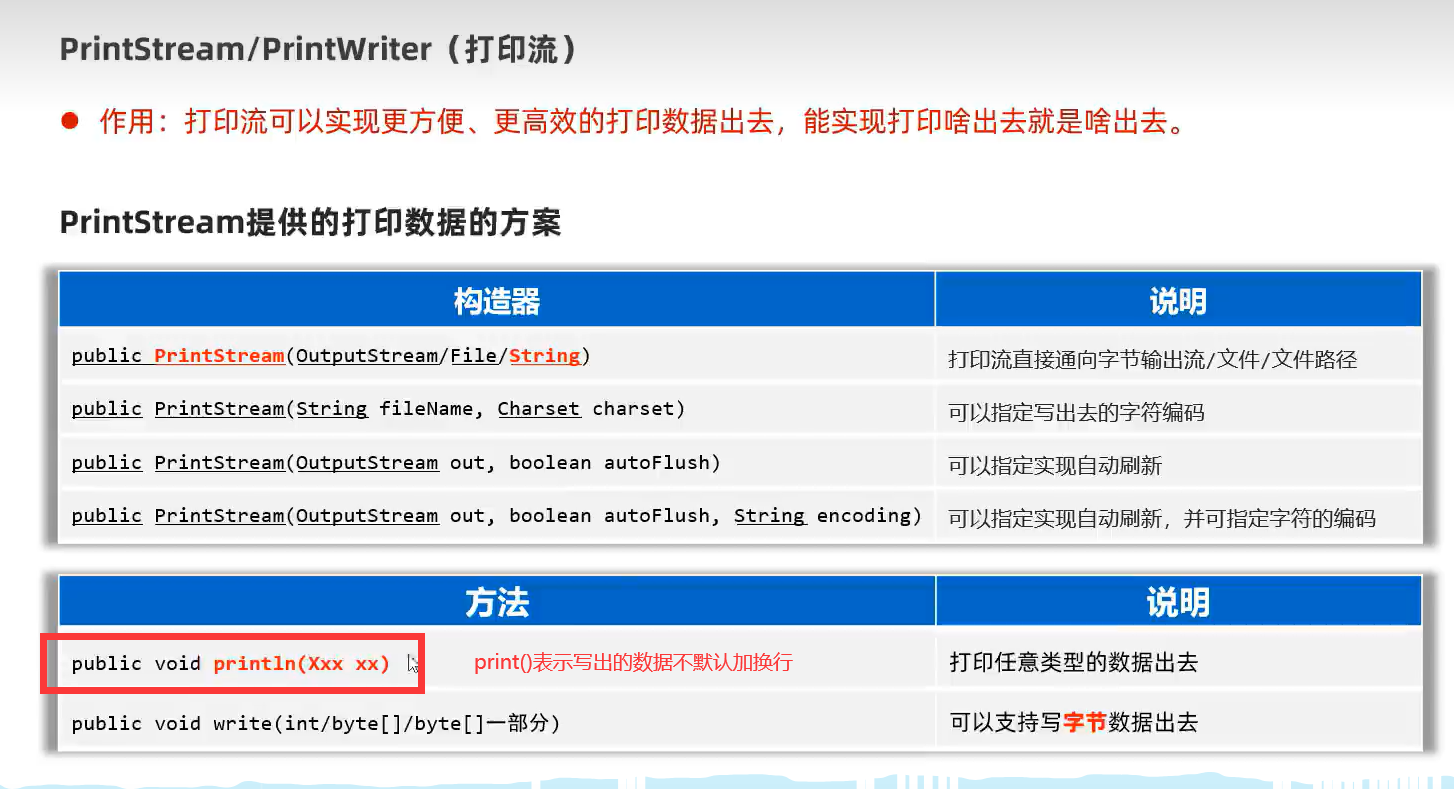
6.打印流(往文件里写啥内容就是啥内容,不进行任何转换)——底层自动包装缓存流,高效
如write(97)表示写的是a,而使用打印流write(97)表示可以写的就是这个原始内容97,不进行任何转换。
print(内容)方法表示写入的内容不默认添加换行。而且是该类的独有方法,必须子类变量接收赋值才能使用,多态写法则不能使用该独有方法。
1.PrintStream(字节打印流)
print(内容)方法表示写入的内容不默认添加换行。而且是该类的独有方法,必须子类变量接收赋值才能使用,多态写法则不能使用该独有方法。
示例代码:
-
97不进行转换成a,就是原始内容97
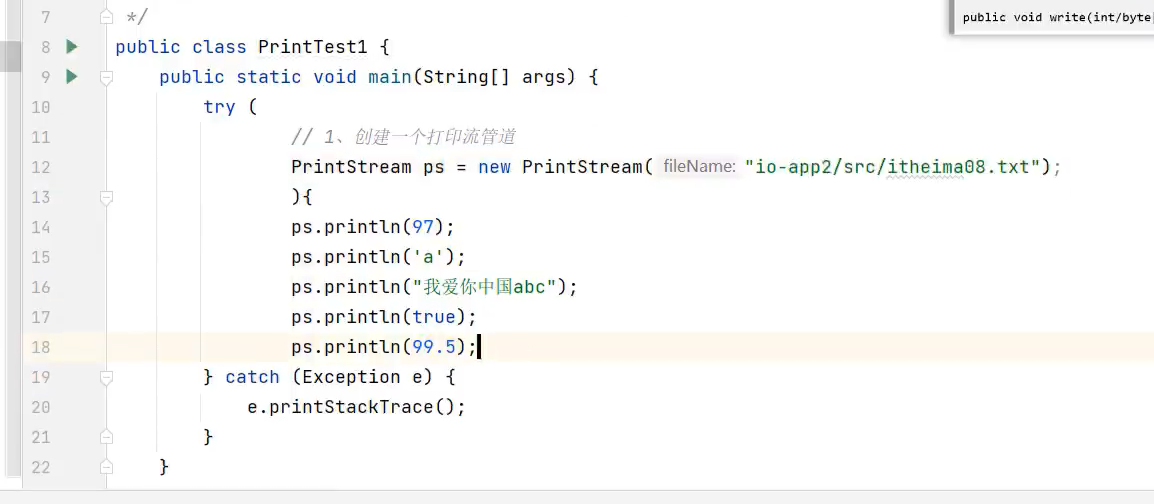
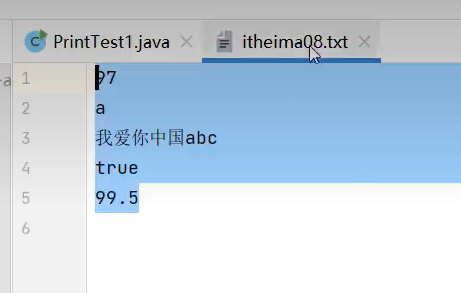
打印后的文件内容为
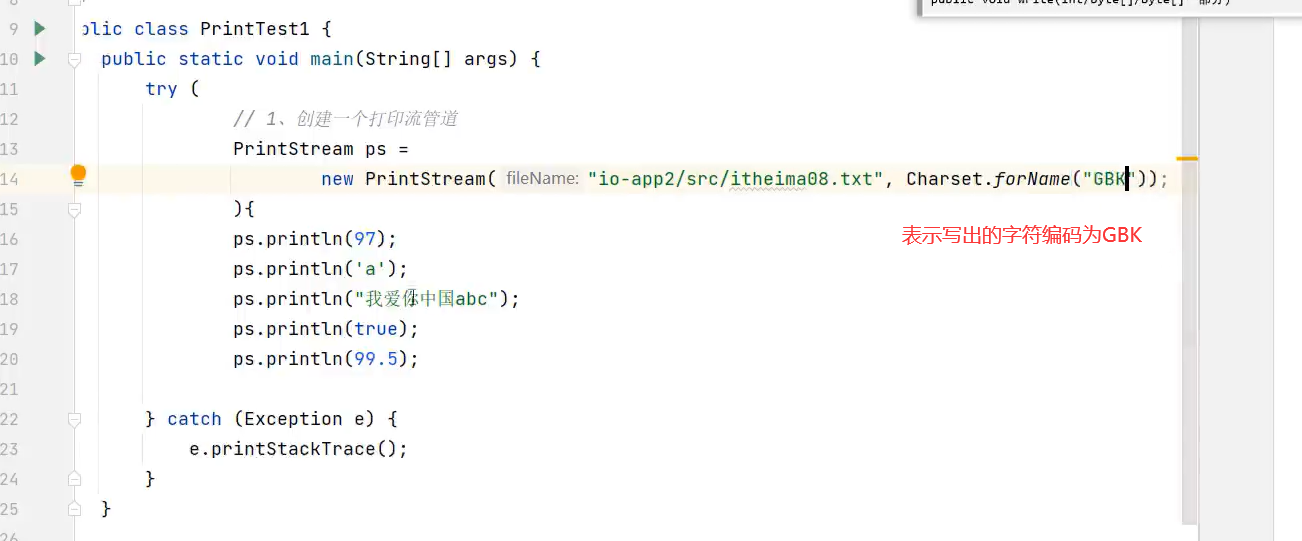
2.指定写入内容的编码
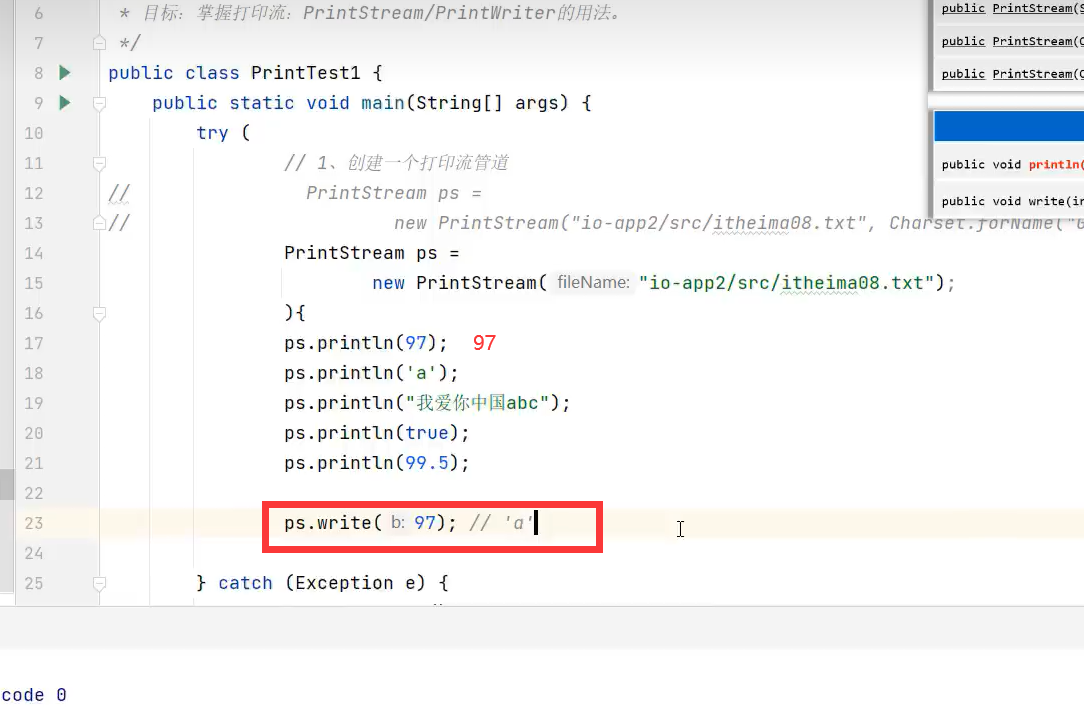
3.write()会对数字转为ACII码
底层包装了缓存流性能高效。
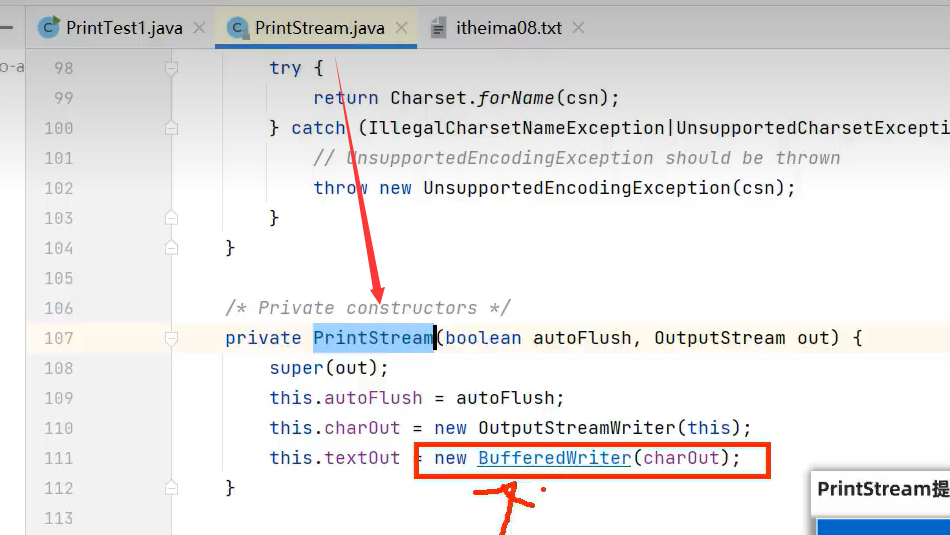
2.PrintWriter(字符打印流)

print(内容)方法表示写入的内容不默认添加换行。而且是该类的独有方法,必须子类变量接收赋值才能使用,多态写法则不能使用该独有方法。
示例代码:
用法和PrintStream一样
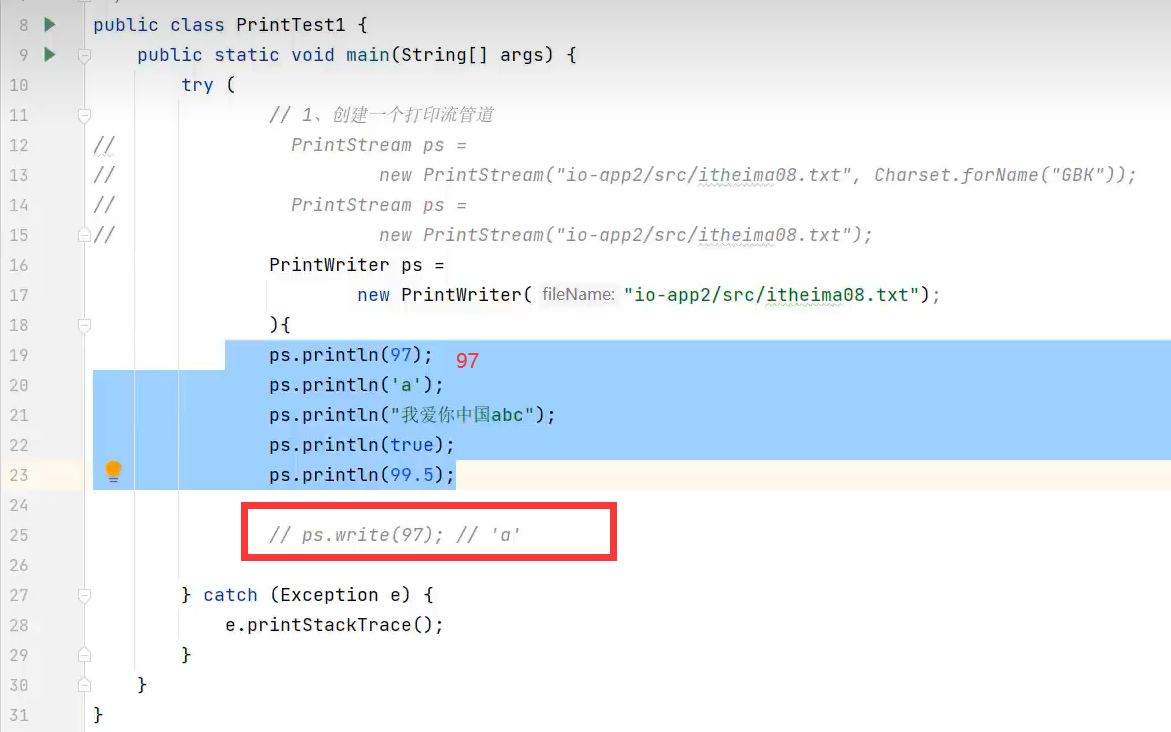
3.追加文件内容的写法
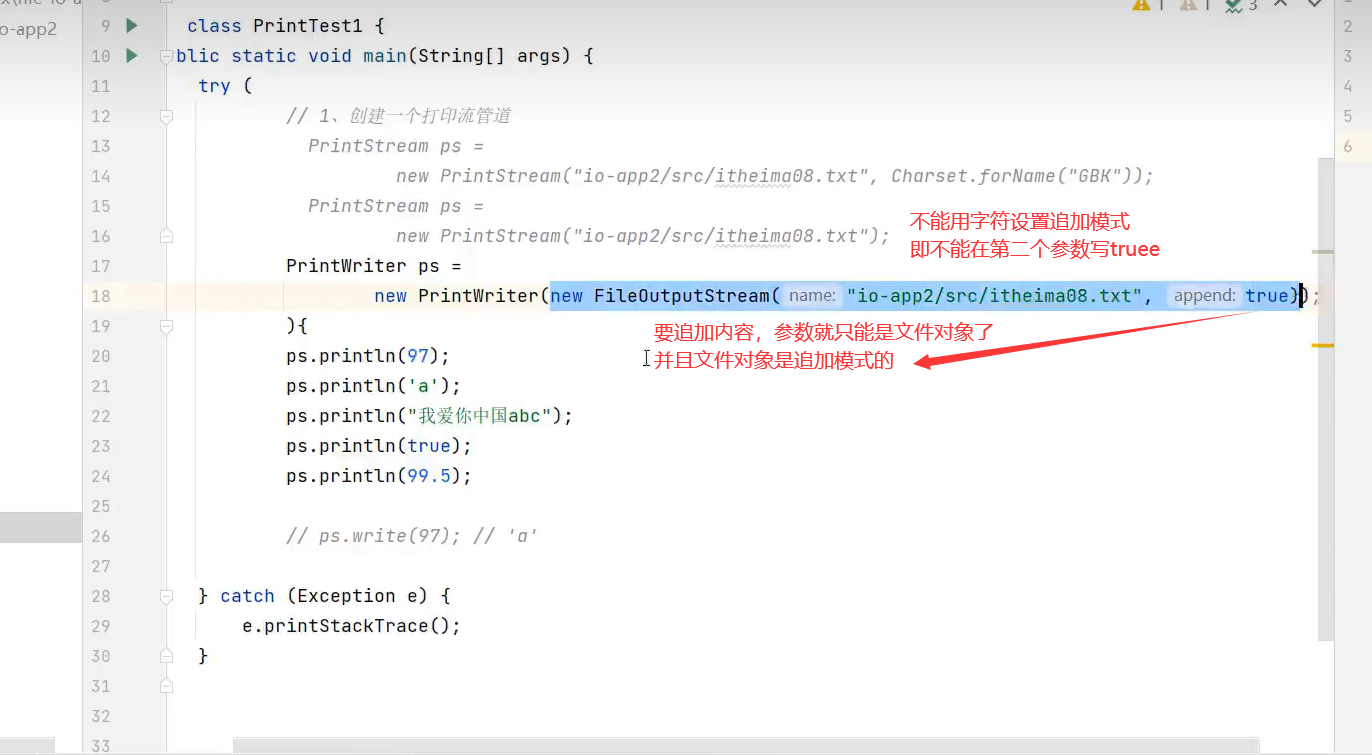
正确方式:
格式为new PrintWriter(文件对象)或PrintStream(文件对象) ,文件对象内部必须设置追加模式,如new FileOutputStream("C:\\a.txt", true)
错误方法:
new PrintWriter(文件对象或字符串路径, true)为错误写法。
4.输出重定向
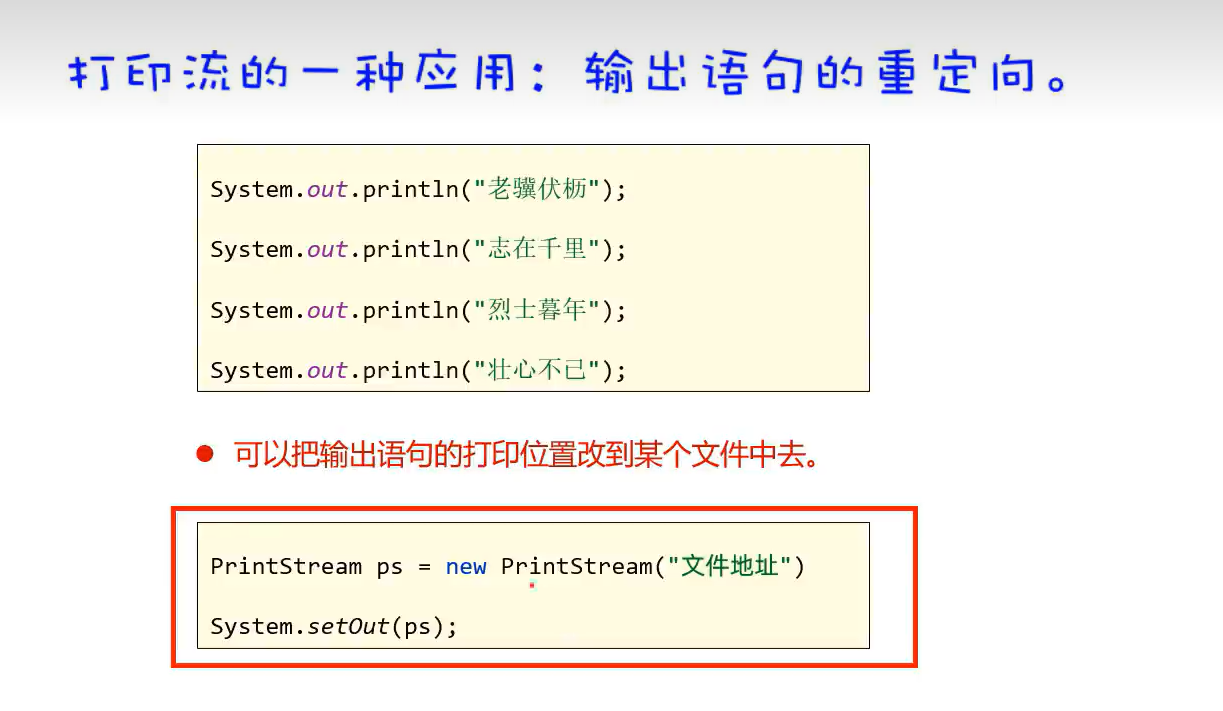
示例代码:重定向输出到文件
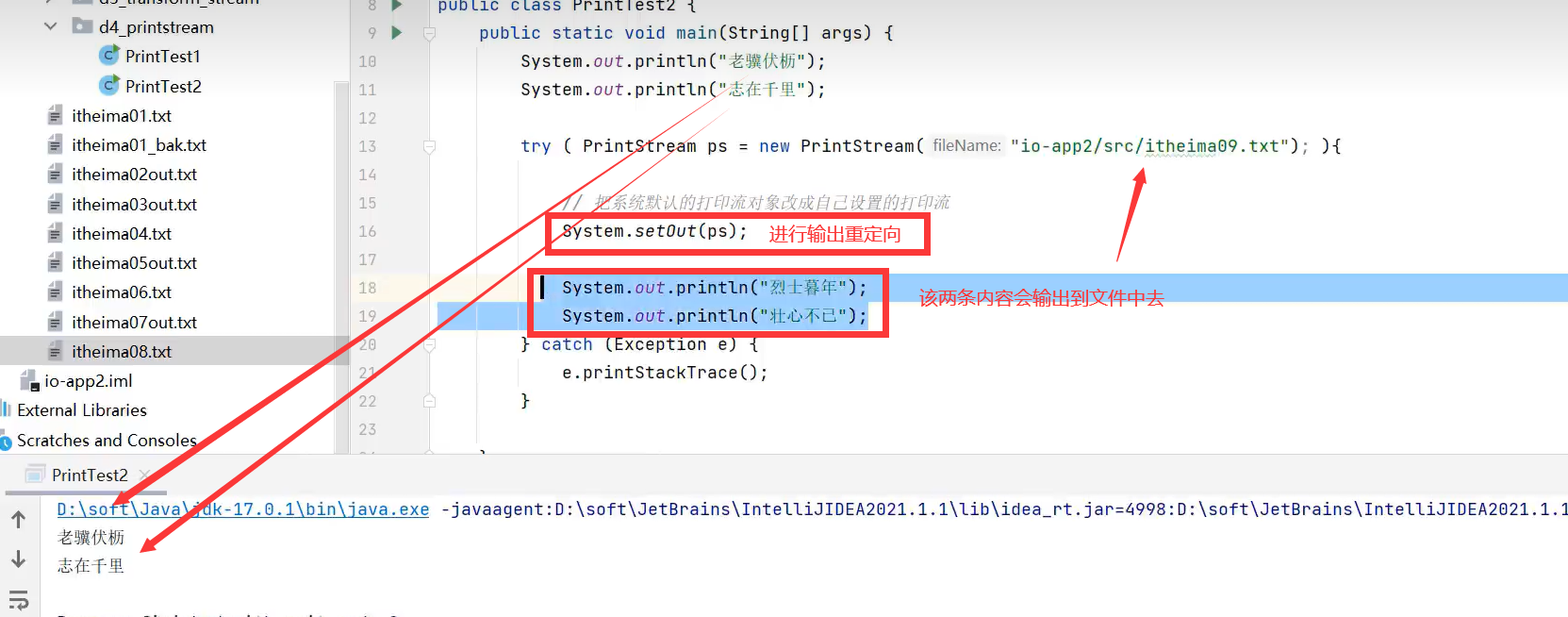
日志文件就是输出重定向到日志文件中记录
7.数据流(常用于数据通信,比较方便)

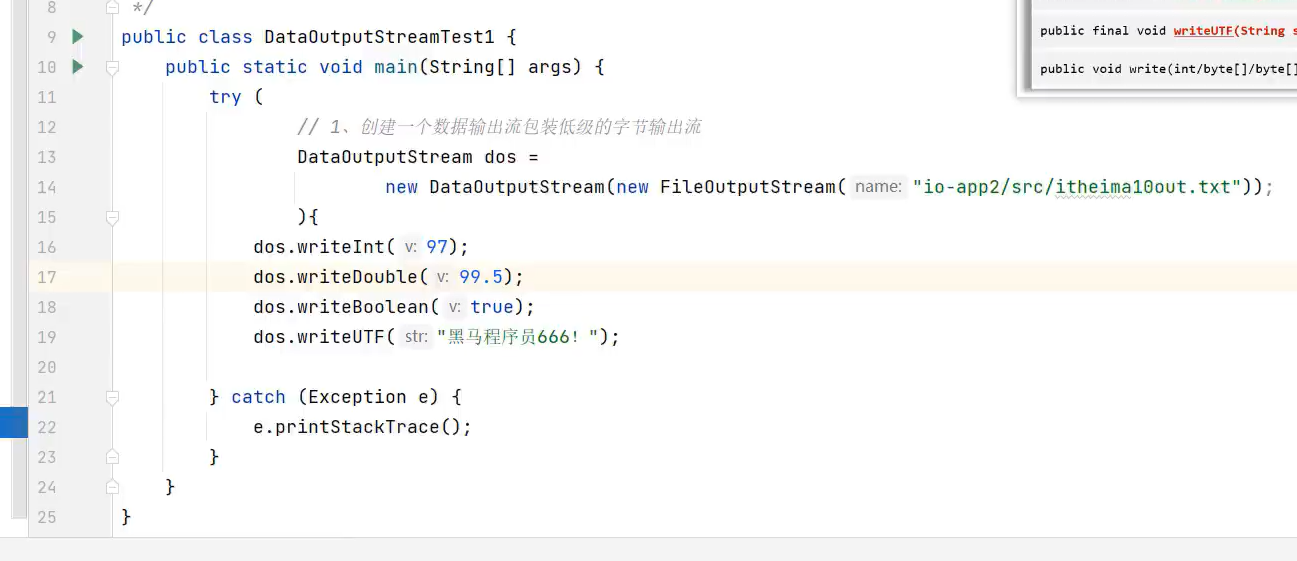
1.DataOutputStream(数据字节输出流)

要使用独有方法,就不要用多态写法了。
示例代码:
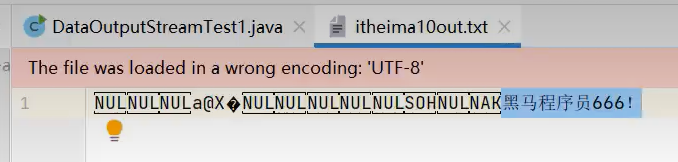
该文件内容还包含了数据类型,以一种特殊形式存储的,不是用来看的
2.DataInputputStream(数据字节输入流)

示例代码:

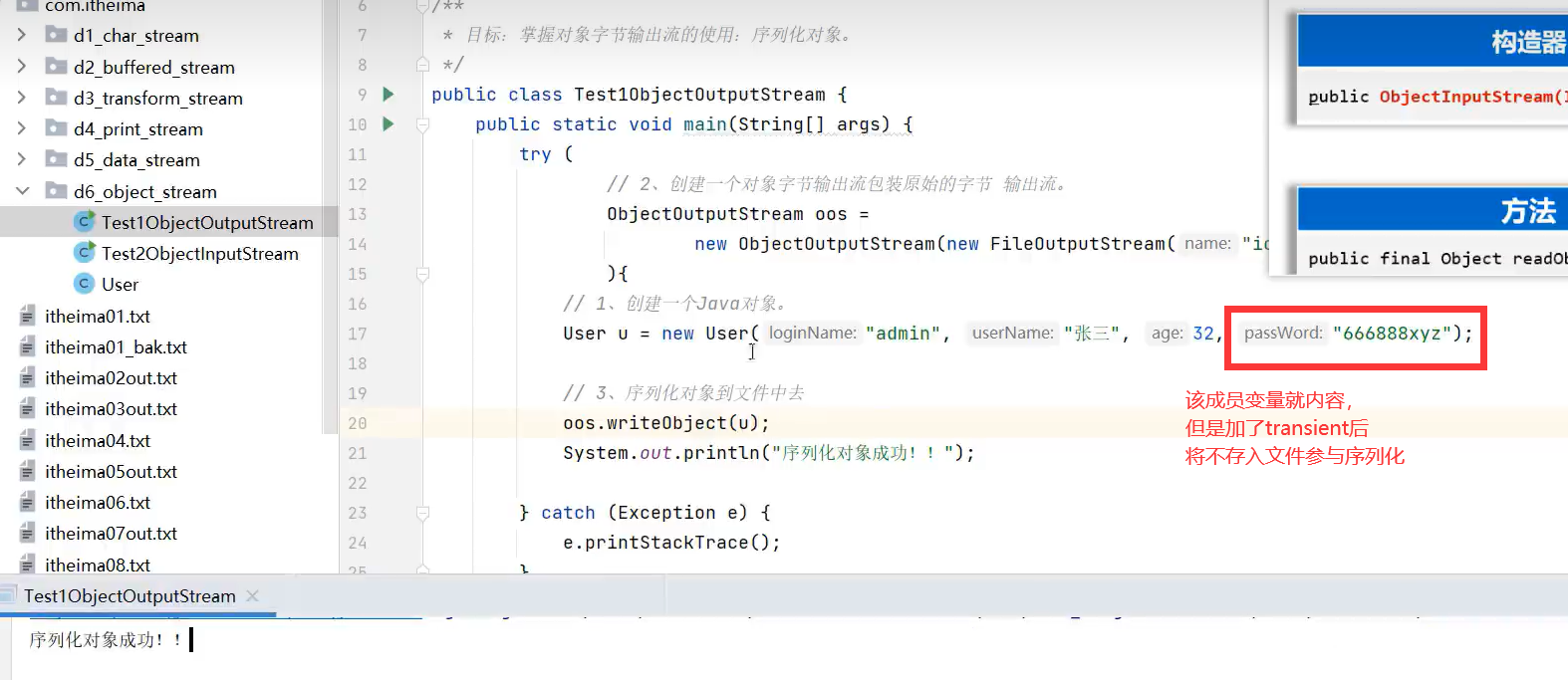
8.序列化流(及transient关键字)
序列化与反序列化:

1.ObjectOutputStrean(序列化流)

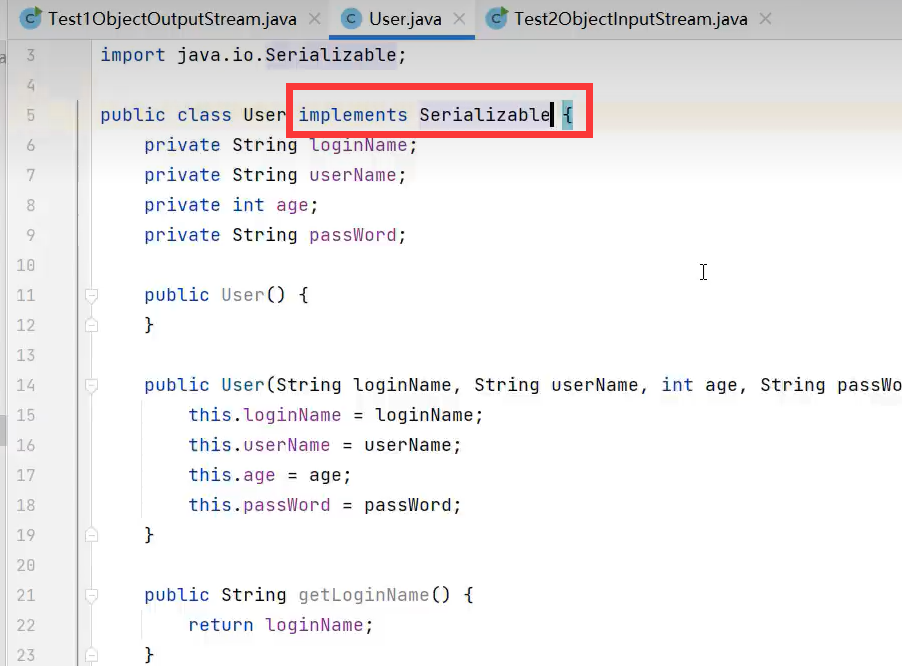
类要使用序列化,必须实现Serializable接口。
示例代码:
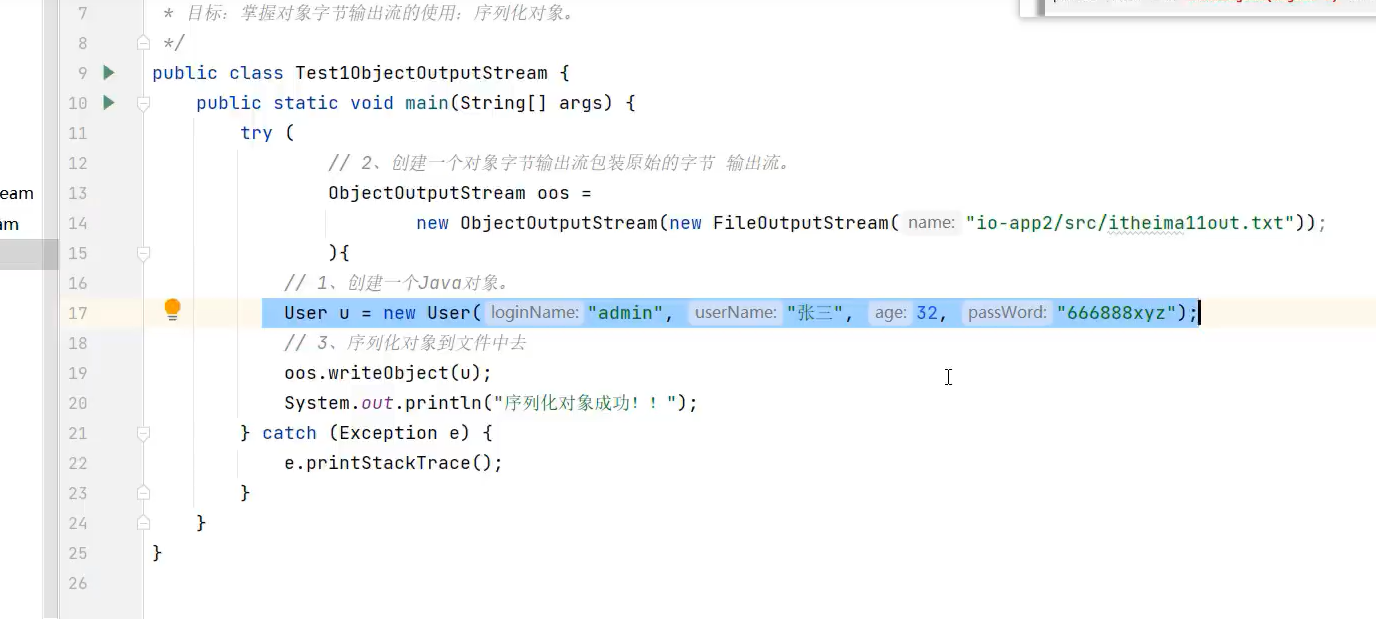
文件内容

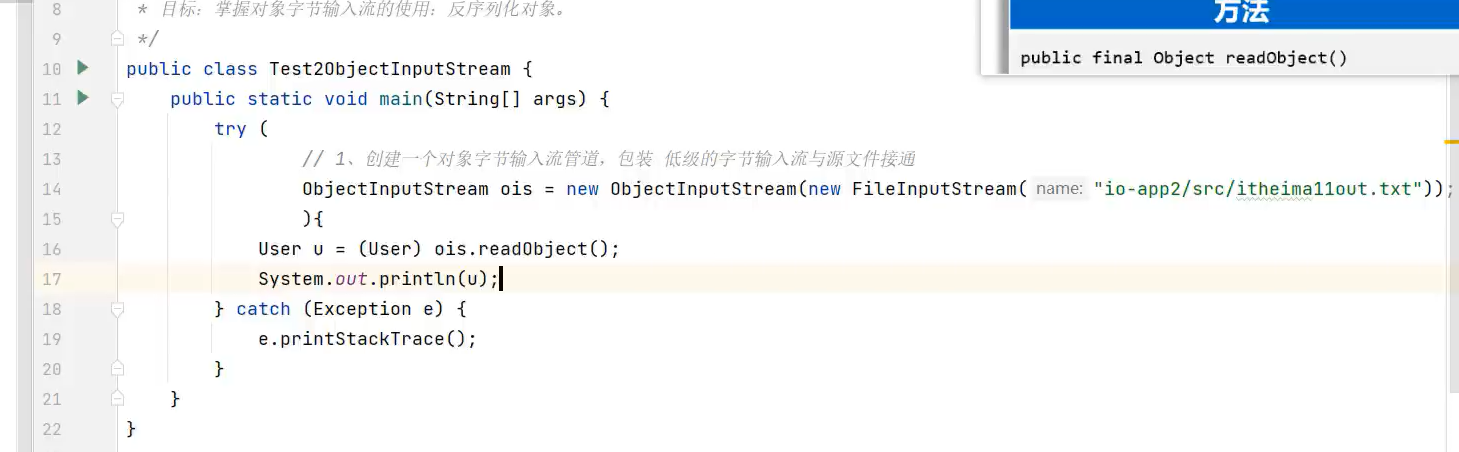
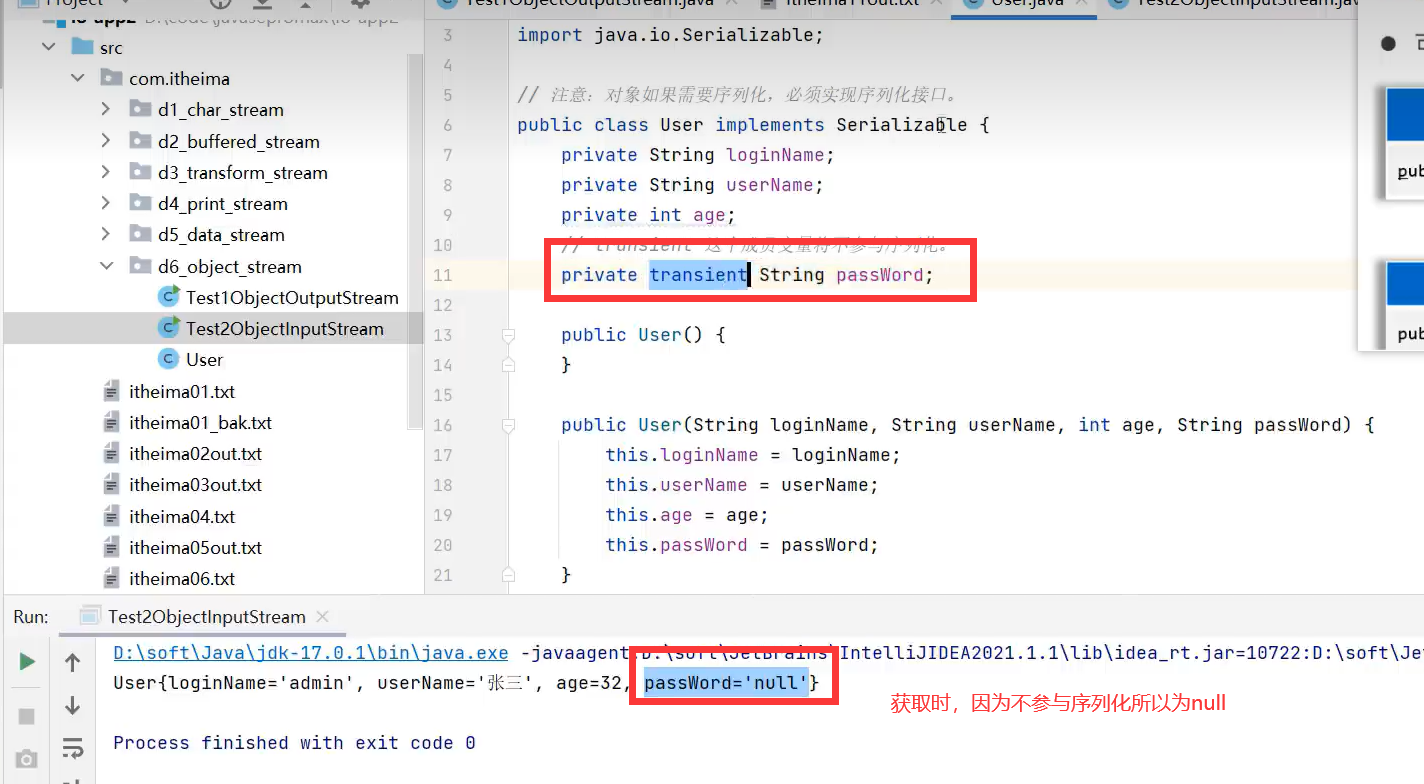
2.ObjectInputStrean(反序列化流)
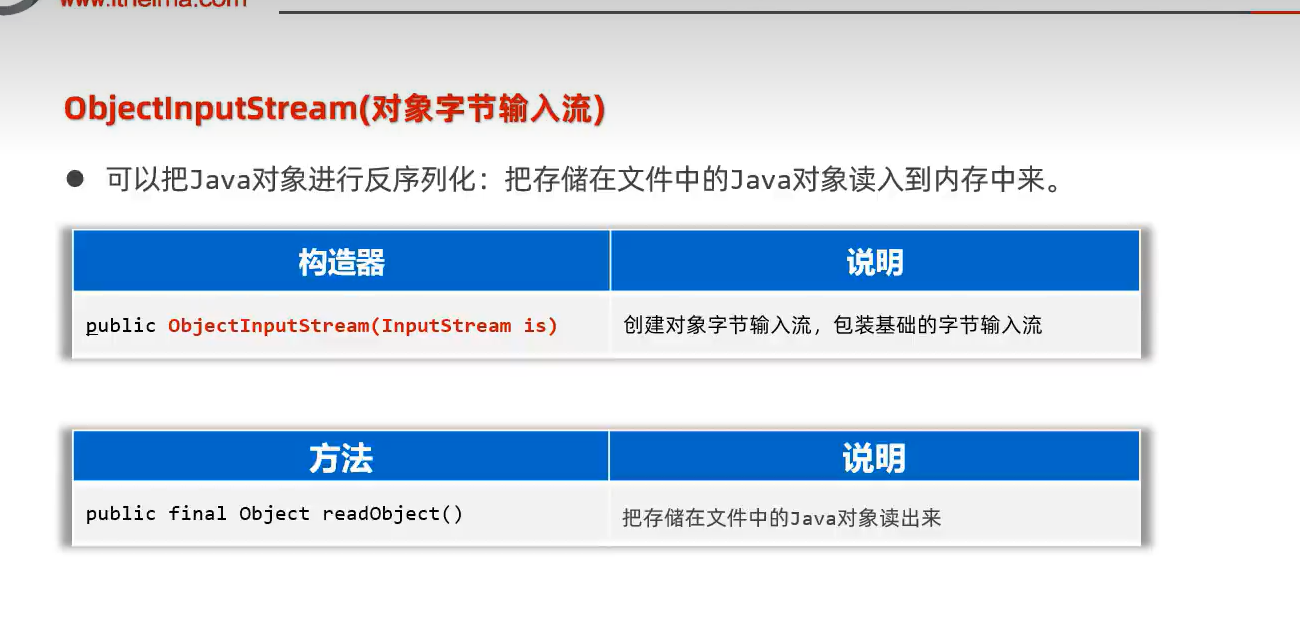
示例代码:
3.transient关键字
示例理解
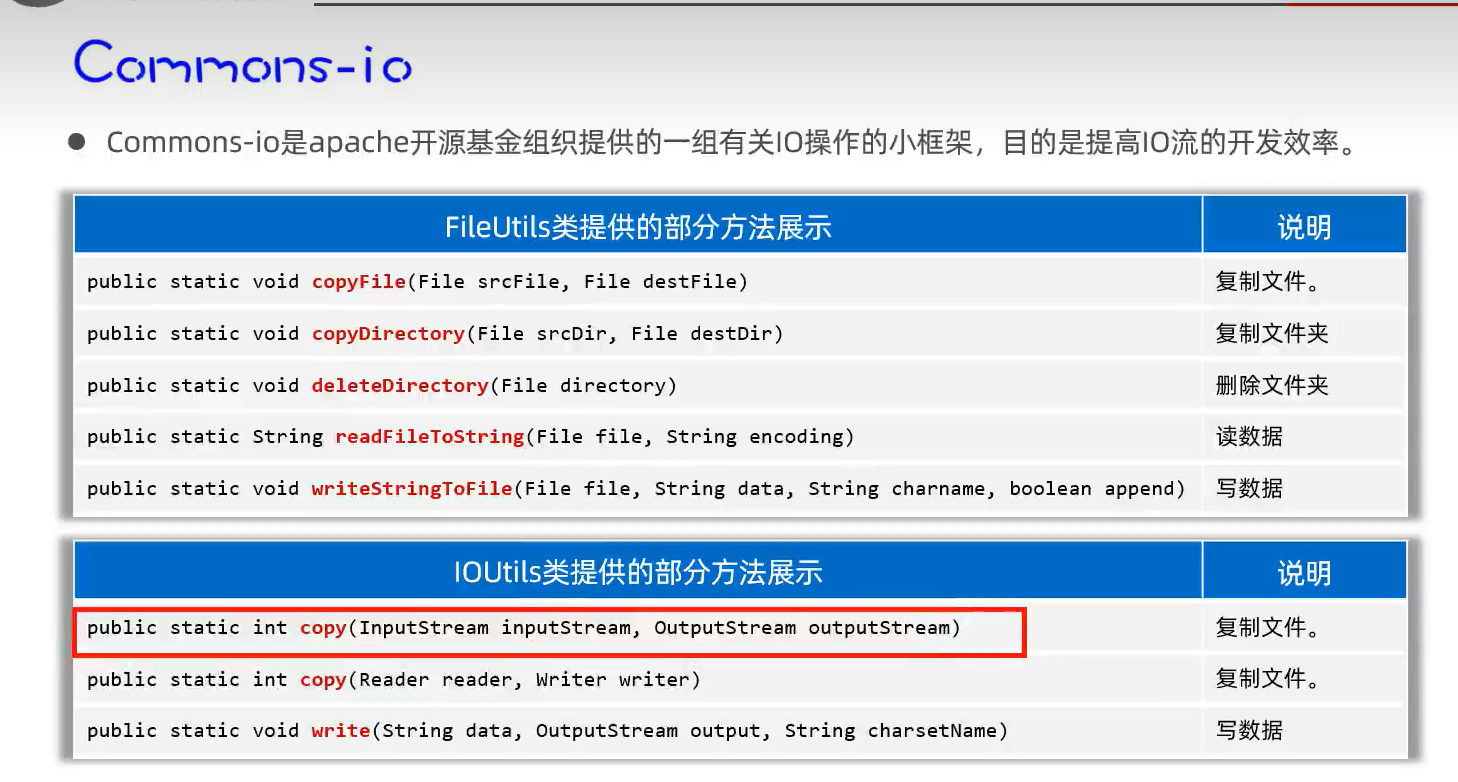
3.IO框架
1.定义及方法

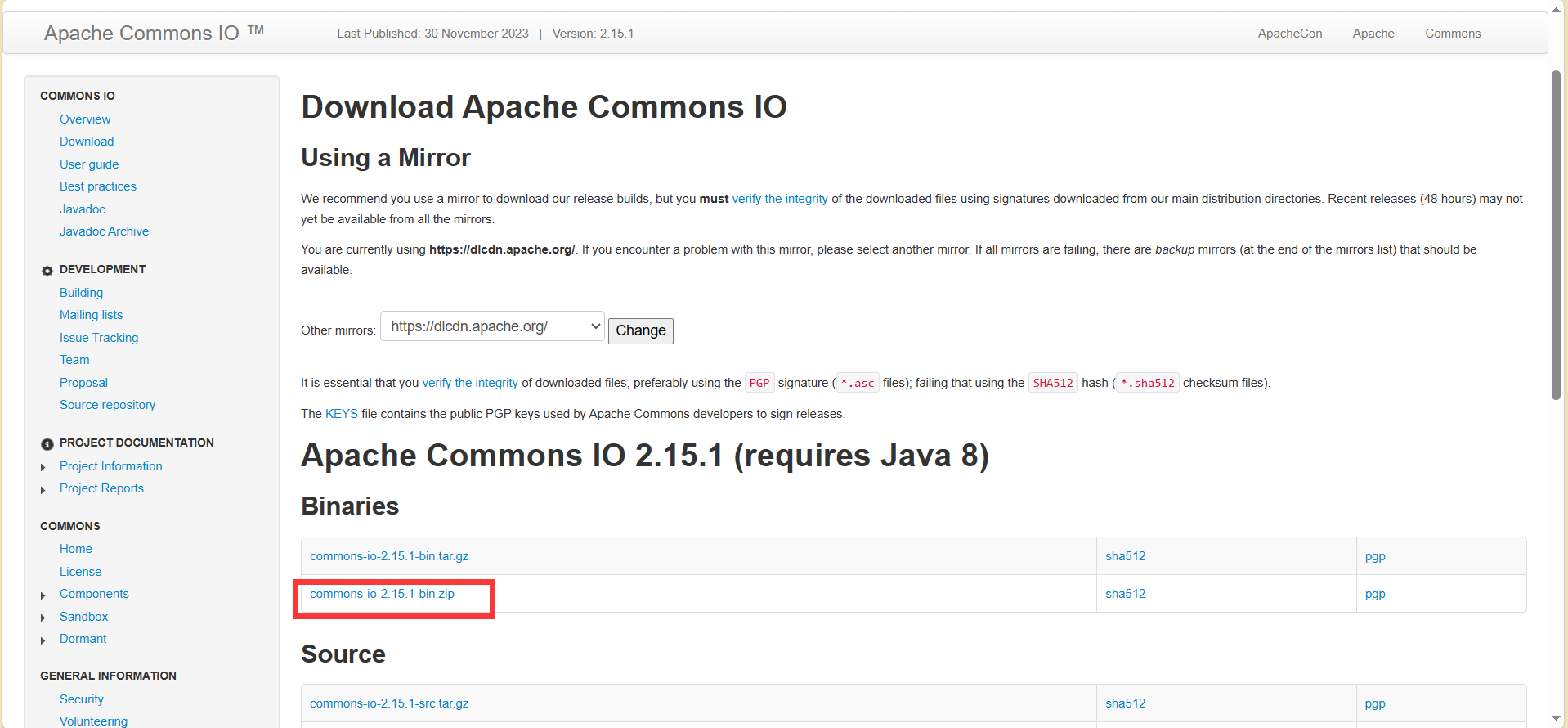
2.使用步骤
1.去官方Commons-io官网下载压缩包
2.解压后复制该jar包到项目中去
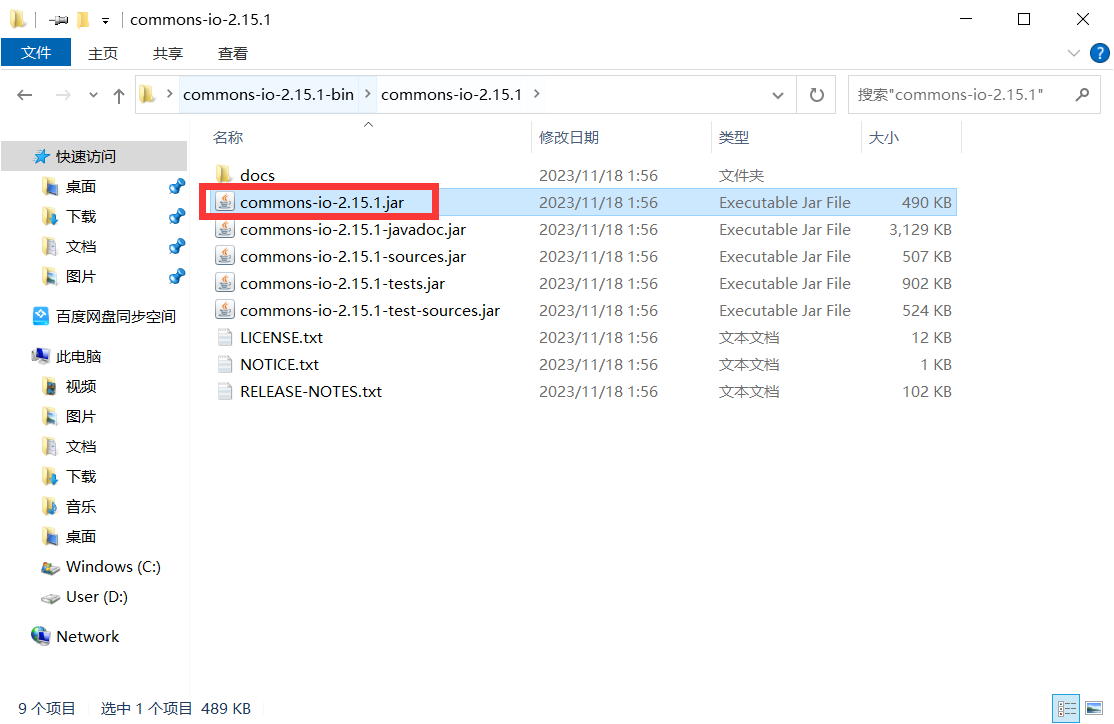
3.在项目中新建文件夹lib,并右击Add as Library
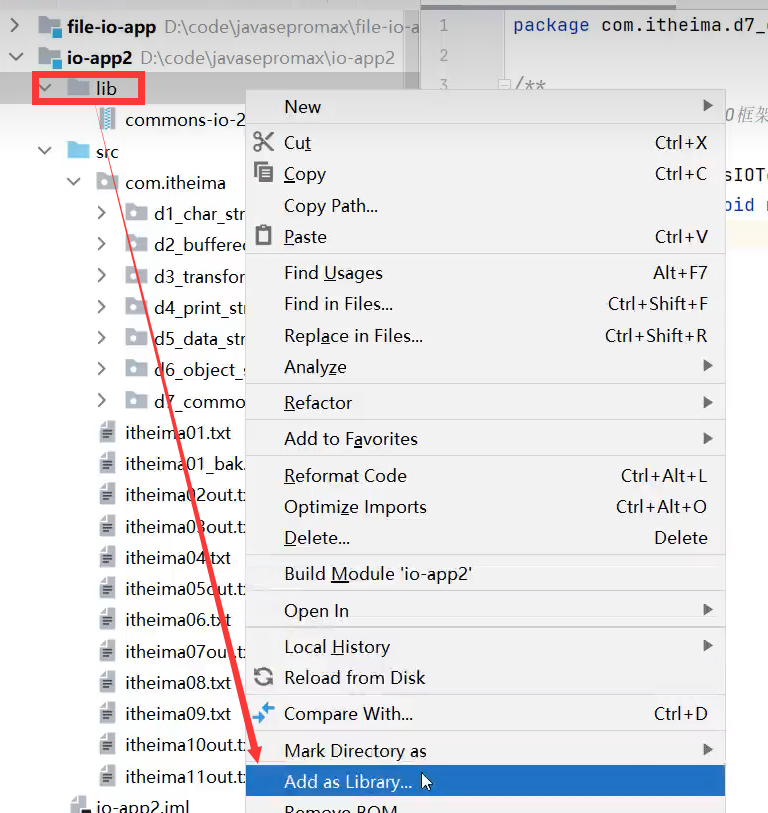
4.将该jar包复制到该lib文件夹下就能使用了
3.示例代码

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!