算法测试、模块与系统调用、读者写者
算法测试、模块与系统调用、读者写者
1、算法测试
- Ubuntu下支持哪些C语言的排序算法,查找算法?你是怎么得到的?提交截图
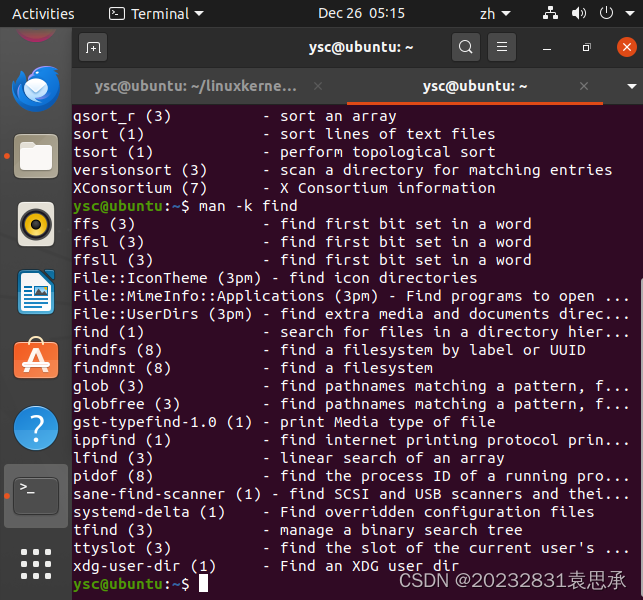
① 排序算法:
通过man-k的两种方式查找(一个全局查找,一个只在手册第三页库函数里面查找),发现必须在手册第1页和第3页才是C语言排序算法,在ChatGPT中询问发现只有alphasort (3) - 字母排序算法、bsearch (3) - 二分查找算法、qsort (3) - 快速排序算法、qsort_r (3) - 快速排序算法的可重入版本、sort (1) - 文本文件行排序工具、tsort (1) - 执行拓扑排序这几个排序。
man -s 3 -k sort
man -k sort
截图即如下:

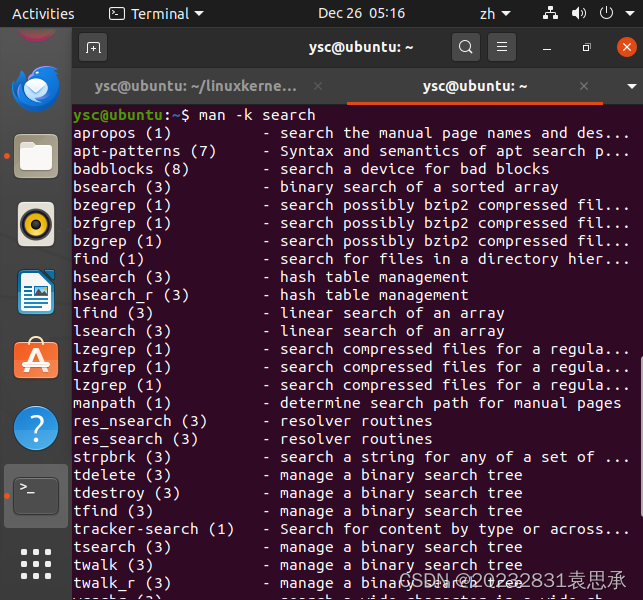
② 查找算法
查找算法也是用man方法来查找,即man -k find或者man -k search。
man -k find
man -k search
截图如下:
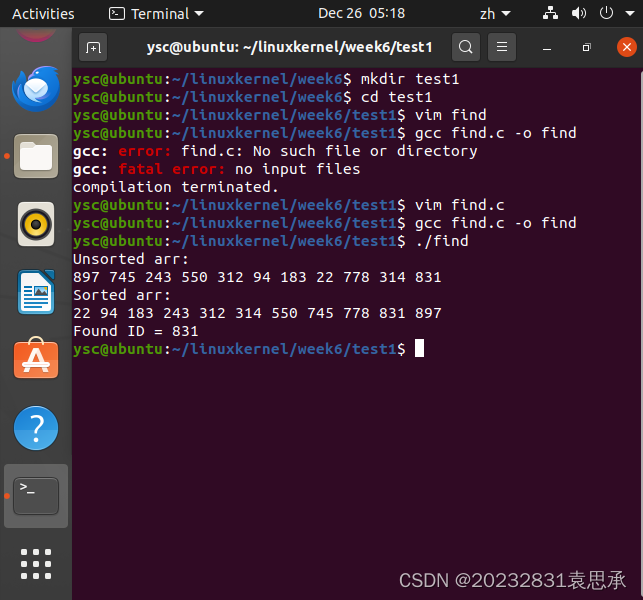
- 针对下面的数组,调用Linux的 快速排序或二分查找算法。查找算法查自己的学号。
用随机数函数产生10个 1-1000之间的数存到一个数组int arr[11]中, arr[10] = 你学号的后三位。
这里使用了快速排序qsort进行排序,并直接使用bsearch查找我的学号后三位831。
代码如下:
#include <stdio.h>
#include <stdlib.h>
// 比较函数,用于qsort和bsearch函数
int comp(const void *a, const void *b);
int main() {
srandom(8); // 使用种子初始化随机数生成器
int counter = 0;
int arr[11];
// 生成随机整数并存储在arr数组中(1到1000之间)
for (; counter < 10; counter++) {
arr[counter] = 1 + random() % 1000; // 随机生成1到1000之间的整数
}
// 将学号后三位831存储在arr数组的arr[10]位置
arr[10] = 831;
// 输出未排序的arr数组内容
printf("Unsorted arr:\n");
for (int i = 0; i < 11; i++) {
printf("%d ", arr[i]);
}
printf("\n");
// 使用qsort函数对arr数组进行排序
qsort(arr, 11, sizeof(int), comp);
// 输出排序后的arr数组内容
printf("Sorted arr:\n");
for (int i = 0; i < 11; i++) {
printf("%d ", arr[i]);
}
printf("\n");
int *item;
int key = 831;
// 使用bsearch函数在排序后的arr数组中查找学号后三位(831)
item = (int *)bsearch(&key, arr, 11, sizeof(int), comp);
// 检查是否找到特定值,并输出结果
if (item != NULL) {
printf("Found ID = %d\n", *item);
} else {
printf("ID = %d could not be found\n", key);
}
}
// 比较函数的定义,用于协助排序函数
int comp(const void *a, const void *b) {
return *(int *)a - *(int *)b; // 比较两个整数,返回差值
}
vim find.c
gcc find.c -o find
./find
2、模块与系统调用
参考“实验二指导书 内核模块编译.docx”完成相实践
①实验原理
Linux 模块是一些可以作为独立程序来编译的函数和数据类型的集合。之所以提供模块机制,是因为 Linux 本身是一个单内核。单内核由于所有内容都集成在一起,效率很高,但可扩展性和可维护性相对较差,模块机制可弥补这一缺陷。
linux 模块可以通过静态或动态的方法加载到内核空间,静态加载是指在内核启动过程中加载;动态加载是指在内核运行的过程中随时加载。一个模块被加载到内核中时,就成为内核代码的一部分。模块加载入系统时,系统修改内核中的符号表,将新加载的模块提供的资源和符号添加到内核符号表中,以便模块间的通信。
②编写模块代码
模块构造函数:
执行insmod或modprobe指令加载内核模块时会调用的初始化函数。函数原型必须是module_init(),括号内是函数指针
模块析构函数:
执行rmmod指令卸载模块时调用的函数。函数原型是module_exit()
模块许可声明:
函数原型是MODULE_LICENSE(),告诉内核该程序使用的许可证,不然在加载时它会提示该模块污染内核。一般会写GPL。
模块参数
模块导出符号
模块作者信息声明
头文件module.h,必须包含此文件;
头文件kernel.h,包含常用的内核函数;
头文件init.h包含宏_init和_exit,允许释放内核占用的内存。
写一个简单的代码,用来向内核输出一段文字。
代码很简单,里面包括了上文提到的构造、析构和许可证。如下所示:
vim printname.c
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
MODULE_LICENSE("Dual BSD/GPL");
static char *name="ldz";
static int __init name_init(void){
printk("==Hello world==\n");
printk("==Hello %s==\n",name);
return 0;
}
static void __exit name_exit(void){
printk(KERN_INFO"Name module exit\n");
}
module_init(name_init);
module_exit(name_exit);
module_param(name,charp,S_IRUGO);
③编译模块
接下来写Makefile
Makefile里面有用到上学期学过的简写形式。
第一行的printname换成你自己写的.c文件名。
第三行的LINUX_KERNEL_PATH后面要写你自己的内核版本对应的内核源码包地址。
即:
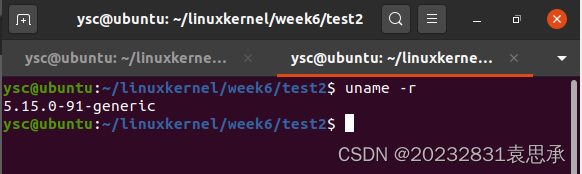
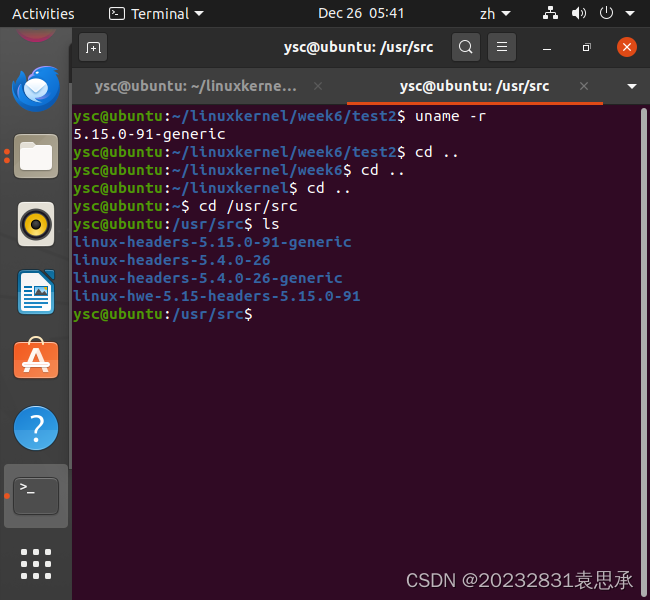
内核版本: 5.15.0-91-generic
·
地址:/usr/src/linux-headers-5.15.0-91-generic
两个命令如下:
uname -r
cd /usr/src
ls
解释一下make命令:make-C$(LINUX_KERNEL_PATH)指明跳转到内核源码目录下读取那里的Makefile
vim Makefile
故Makefile代码如下:
obj-m := printname.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-5.15.0-91-generic
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
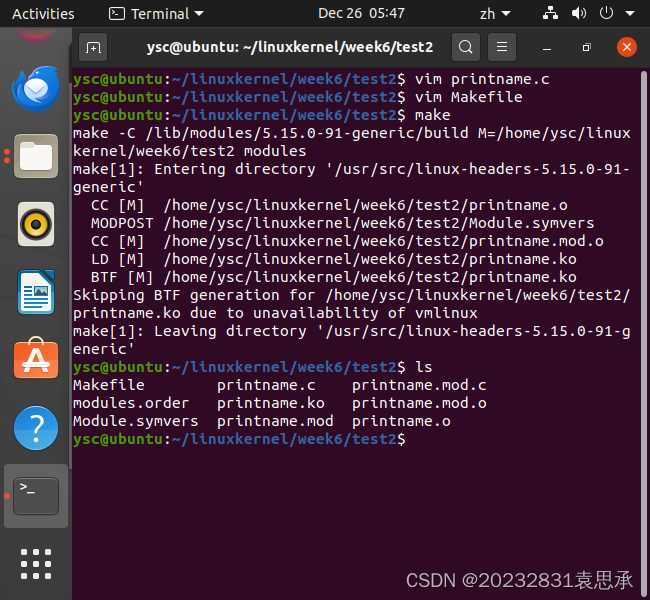
最后,make一下,生成很多文件
make
④加载模块
sudo insmod printname.ko
⑤测试模块
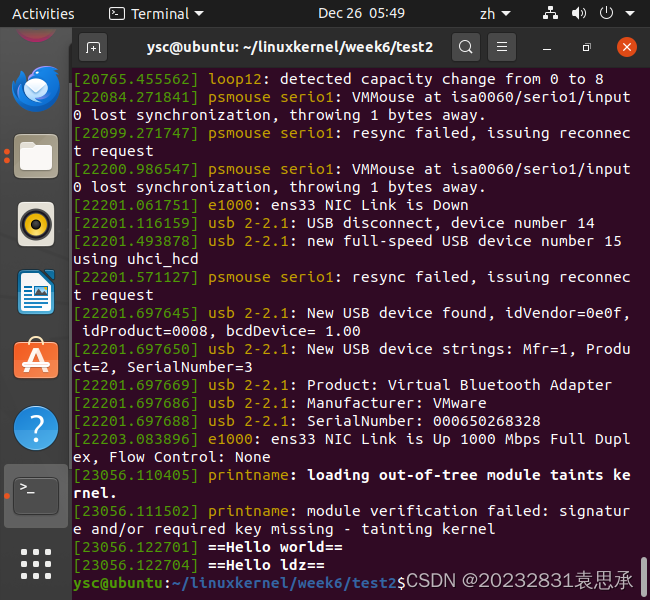
输入以下代码:
dmesg
输出如下,可发现测试成功:
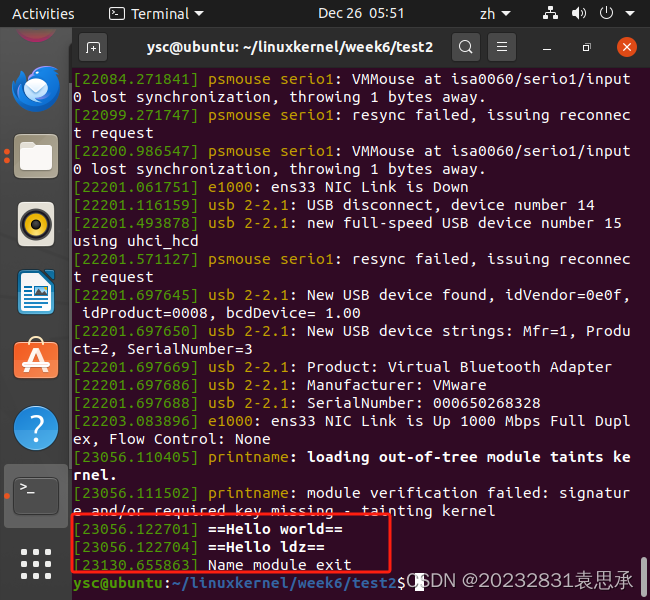
⑥卸载模块
sudo rmmod printname
⑦实现输出当前进程信息的功能
vim module2.c
因为需要换内核版本,但是我的虚拟机没有低版本的内核,为了简便,查找了如何解决state问题,结果如下:
Linux 5.14后把task_struct的state改成__state了。因此修改代码即可实现:
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/sched.h>
MODULE_LICENSE("GPL");
static struct task_struct *pcurrent;
int print_current_task_info(void);
static int __init print_init(void)
{
printk(KERN_INFO "print current task info\n");
print_current_task_info();
return 0;
}
static void __exit print_exit(void) {
printk(KERN_INFO "Finished\n");
}
int print_current_task_info(void)
{
pcurrent = get_current();
printk(KERN_INFO "Task state:%u\n",current->__state);
printk(KERN_INFO "pid:%d\n", current->pid);
printk(KERN_INFO "tgid:%d\n", current->tgid);
printk(KERN_INFO "prio:%d\n", current->prio);
return 0;
}
module_init(print_init);
module_exit(print_exit);
修改Makefile中的printname.o为module2.o
obj-m := module2.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-5.15.0-91-generic
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
make
sudo insmod module2.ko
dmesg
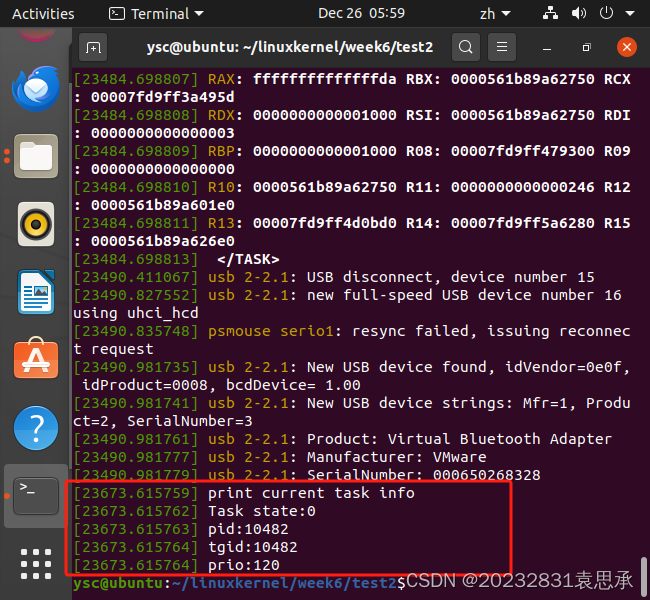
⑧实现读取进程链表的功能
vim module3.c
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/sched/signal.h>
MODULE_LICENSE("GPL");
static struct task_struct *pcurrent;
int print_current_task_info(void);
static int __init print_init(void)
{
printk(KERN_INFO "print current task info\n");
printk("pid\ttgid\tprio\tstate\n");
for_each_process(pcurrent)
{
printk("%d", pcurrent->pid);
printk("\t");
printk("%d", pcurrent->tgid);
printk("\t");
printk("%d", pcurrent->prio);
printk("\t");
printk("%u\n", pcurrent->__state);
}
return 0;
}
static void __exit print_exit(void) {
printk(KERN_INFO "Finished\n");
}
修改Makefile中的module2.o为module3.o
obj-m := module3.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-5.15.0-91-generic
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
make
sudo insmod module3.ko
dmesg

完成!
3、读者写者
用多线程和信号量实现"读者写者"模型
该实验要求使用多线程和信号量实现读者写者模型,来管理对共享资源的访问。
① 首先是读者优先:
1、读者写者问题的读写操作限制(读者优先)
写-写互斥,即不能有两个写者同时进行写操作。
读-写互斥,即不能同时有一个线程在读,而另一个线程在写。
读-读允许,即可以有一个或多个读者在读。
2、读者优先的附加限制
如果一个读者申请进行读操作时已有另一个读者正在进行读操作,则该读者可直接开始读操作。
3、以下是实现的详细代码:
vim test.c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
int sharedValue = 0; // 共享资源,初始值为0
int readerCount = 0; // 当前读者数量,初始值为0
sem_t mutex; // 互斥信号量,用于保护readerCount的互斥访问
sem_t writeBlock; // 写者信号量,用于控制写者的访问
void *reader(void *arg) {
sem_wait(&mutex); // 进入临界区,请求互斥信号量
readerCount++; // 增加读者数量
if (readerCount == 1) sem_wait(&writeBlock); // 第一个读者阻止写者
sem_post(&mutex); // 离开临界区,释放互斥信号量
// 读取数据
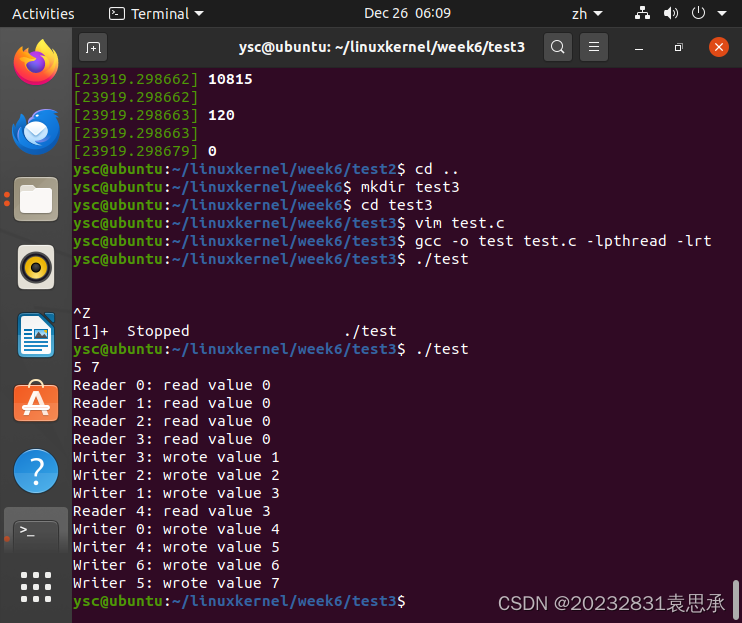
printf("Reader %ld: read value %d\n", (long)arg, sharedValue);
sem_wait(&mutex); // 进入临界区,请求互斥信号量
readerCount--; // 减少读者数量
if (readerCount == 0) sem_post(&writeBlock); // 最后一个读者允许写者
sem_post(&mutex); // 离开临界区,释放互斥信号量
pthread_exit(NULL); // 线程退出
}
void *writer(void *arg) {
sem_wait(&writeBlock); // 请求资源,等待写者信号量
// 写入数据
sharedValue++; // 增加共享资源的值
printf("Writer %ld: wrote value %d\n", (long)arg, sharedValue);
sem_post(&writeBlock); // 释放资源,释放写者信号量
pthread_exit(NULL); // 线程退出
}
int main() {
// 初始化信号量
sem_init(&mutex, 0, 1); // 互斥信号量,初始值为1
sem_init(&writeBlock, 0, 1); // 写者信号量,初始值为1
int N, M;
scanf("%d %d", &N, &M); // 从标准输入读取N和M的值,假设N个读者,M个写者
pthread_t rtid[N], wtid[M]; // 创建N个读者和M个写者线程
long i;
// 创建读者线程
for (i = 0; i < N; i++) {
pthread_create(&rtid[i], NULL, reader, (void *)i);
}
// 创建写者线程
for (i = 0; i < M; i++) {
pthread_create(&wtid[i], NULL, writer, (void *)i);
}
// 等待线程结束
for (i = 0; i < N; i++) {
pthread_join(rtid[i], NULL);
}
for (i = 0; i < M; i++) {
pthread_join(wtid[i], NULL);
}
// 销毁信号量
sem_destroy(&mutex);
sem_destroy(&writeBlock);
return 0; // 返回0表示程序成功结束
}
注意,这里编译该C文件时,需要使用以下代码:
gcc -o test test.c -lpthread -lrt
-lpthread和-lrt表明用于链接pthread库和实时扩展库rt 库,以实现多线程等功能。
详细解释如下:
-lpthread:
-lpthread 用于链接 POSIX 线程库,也称为 pthread 库。POSIX 线程库提供了用于多线程编程的函数和数据类型。如果您的程序使用多线程技术,例如在使用 pthread_create 创建线程时,需要链接 pthread 库,以便在编译后可以正确运行多线程程序。
-lrt:
-lrt 用于链接 POSIX 实时扩展库,也称为 rt 库。这个库提供了一些与实时性和时间相关的功能,例如定时器、消息队列等。如果您的程序使用这些实时特性,需要链接 rt 库以使这些功能可用。
4、运行结果如下:
./test
② 下面是写者优先
1、读者写者问题的读写操作限制(写者优先)
写-写互斥,即不能有两个写者同时进行写操作。
读-写互斥,即不能同时有一个线程在读,而另一个线程在写。
读-读允许,即可以有一个或多个读者在读。
2、写者优先的附加限制
如果一个读者申请进行读操作时已有另一写者在等待访问共享资源,则该读者必须等到没有写者处于等待状态后才能开始读操作。
3、以下是详细代码:
vim test1.c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
int sharedValue = 0; // 共享资源,初始值为0
int writerCount = 0; // 当前写者数量,初始值为0
sem_t mutex; // 互斥信号量,用于保护共享资源的互斥访问
sem_t readBlock; // 读者信号量,用于控制读者的访问
sem_t writeBlock; // 写者信号量,用于控制写者的访问
void *reader(void *arg) {
sem_wait(&readBlock); // 请求读者信号量,控制读者的访问
sem_wait(&mutex); // 进入临界区,请求互斥信号量
// 读取数据
printf("Reader %ld: read value %d\n", (long)arg, sharedValue);
sem_post(&mutex); // 离开临界区,释放互斥信号量
sem_post(&readBlock); // 释放读者信号量
pthread_exit(NULL); // 线程退出
}
void *writer(void *arg) {
sem_wait(&writeBlock); // 请求写者信号量,等待写者信号量
sem_wait(&mutex); // 进入临界区,请求互斥信号量
writerCount++; // 增加写者数量
if (writerCount == 1) sem_wait(&readBlock); // 第一个写者阻止读者
// 写入数据
sharedValue++; // 增加共享资源的值
printf("Writer %ld: wrote value %d\n", (long)arg, sharedValue);
sem_post(&mutex); // 离开临界区,释放互斥信号量
writerCount--; // 减少写者数量
if (writerCount == 0) sem_post(&readBlock); // 最后一个写者允许读者
sem_post(&writeBlock); // 释放写者信号量
pthread_exit(NULL); // 线程退出
}
int main() {
// 初始化信号量
sem_init(&mutex, 0, 1); // 互斥信号量,初始值为1
sem_init(&readBlock, 0, 1); // 读者信号量,初始值为1
sem_init(&writeBlock, 0, 1); // 写者信号量,初始值为1
int N, M;
scanf("%d %d", &N, &M); // 从标准输入读取N和M的值,假设N个读者,M个写者
pthread_t rtid[N], wtid[M]; // 创建N个读者和M个写者线程
long i;
// 创建读者线程
for (i = 0; i < N; i++) {
pthread_create(&rtid[i], NULL, reader, (void *)i);
}
// 创建写者线程
for (i = 0; i < M; i++) {
pthread_create(&wtid[i], NULL, writer, (void *)i);
}
// 等待线程结束
for (i = 0; i < N; i++) {
pthread_join(rtid[i], NULL);
}
for (i = 0; i < M; i++) {
pthread_join(wtid[i], NULL);
}
// 销毁信号量
sem_destroy(&mutex);
sem_destroy(&readBlock);
sem_destroy(&writeBlock);
return 0; // 返回0表示程序成功结束
}
4、使用相同方法进行编译运行后,得到结果如下:
gcc -o test1 test1.c -lpthread -lrt
./test1
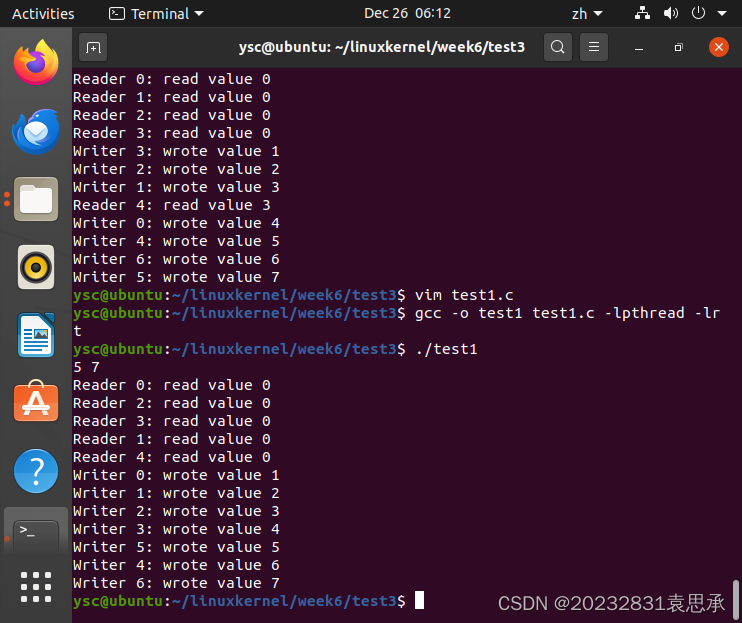
进行运行后,输入的两个数字分别代表读者和写者的数量(N 和 M),此后程序将创建多个读者和写者线程,并模拟它们的并发操作。在程序执行完毕后,可以看到读者和写者的活动输出。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!