白鼠轨迹检测追踪系统:融合在线卷积重参数化OREPA改进YOLOv8
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着计算机视觉和深度学习的快速发展,目标检测和跟踪成为了计算机视觉领域的热门研究方向。在实际应用中,目标检测和跟踪系统在许多领域都具有重要的应用价值,例如智能监控、自动驾驶、人机交互等。其中,白鼠轨迹检测追踪系统在生物医学研究中具有重要的意义。
白鼠是生物医学研究中常用的实验动物之一,广泛应用于药物研发、疾病模型建立等领域。在白鼠实验中,轨迹检测和追踪是对白鼠行为进行分析和研究的关键步骤。通过对白鼠的行为轨迹进行分析,可以获取白鼠的运动模式、活动范围、行为特征等信息,从而揭示白鼠的行为习惯、认知能力、疾病模型等方面的特征。因此,白鼠轨迹检测追踪系统对于生物医学研究具有重要的意义。
目前,传统的白鼠轨迹检测追踪方法主要基于图像处理和计算机视觉技术,如基于背景建模的方法、基于轮廓匹配的方法等。然而,这些方法在复杂场景下容易受到光照变化、遮挡等因素的干扰,导致检测和追踪的准确性和稳定性较低。因此,如何提高白鼠轨迹检测追踪系统的准确性和稳定性成为了当前研究的热点和挑战。
近年来,深度学习技术的兴起为目标检测和跟踪领域带来了革命性的突破。特别是基于卷积神经网络(CNN)的目标检测算法,如YOLO(You Only Look Once)系列算法,以其高效的检测速度和较高的准确性受到了广泛关注。然而,传统的YOLO算法在白鼠轨迹检测追踪中仍然存在一些问题,如对小目标的检测效果较差、对遮挡和光照变化敏感等。
因此,本研究旨在改进YOLOv8算法,提出一种融合在线卷积重参数化(Online Convolutional Re-parameterization,OREPA)的方法,以提高白鼠轨迹检测追踪系统的准确性和稳定性。OREPA是一种基于在线学习的参数化方法,通过动态调整卷积核的参数,可以适应不同目标的尺寸和形状变化,从而提高目标检测的准确性。通过将OREPA与YOLOv8算法相结合,可以有效解决白鼠轨迹检测追踪中的一些问题,提高系统的性能。
本研究的意义主要体现在以下几个方面:
首先,通过改进YOLOv8算法,提出一种融合OREPA的方法,可以提高白鼠轨迹检测追踪系统的准确性和稳定性。该方法可以有效解决传统方法在复杂场景下的问题,提高系统的性能。
其次,本研究的方法可以为生物医学研究提供更准确、可靠的白鼠行为分析工具。通过对白鼠的行为轨迹进行分析,可以更好地理解白鼠的行为特征和疾病模型,为药物研发和疾病治疗提供科学依据。
最后,本研究的方法还可以为其他目标检测和跟踪领域提供借鉴和参考。融合在线卷积重参数化的方法可以适应不同目标的尺寸和形状变化,具有较好的通用性和扩展性,可以在其他领域中得到广泛应用。
综上所述,白鼠轨迹检测追踪系统的研究具有重要的意义。通过改进YOLOv8算法,融合在线卷积重参数化的方法,可以提高系统的准确性和稳定性,为生物医学研究提供更准确、可靠的白鼠行为分析工具,同时也为其他目标检测和跟踪领域提供借鉴和参考。
2.图片演示



3.视频演示
白鼠轨迹检测追踪系统:融合在线卷积重参数化OREPA改进YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集MTDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.2 predict.py
封装为类后的代码如下:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
def postprocess(self, preds, img, orig_imgs):
preds = ops.non_max_suppression(preds,
self.args.conf,
self.args.iou,
agnostic=self.args.agnostic_nms,
max_det=self.args.max_det,
classes=self.args.classes)
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for i, pred in enumerate(preds):
orig_img = orig_imgs[i]
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i]
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
这是一个名为predict.py的程序文件,它是基于检测模型进行预测的。它使用了Ultralytics YOLO库,并且遵循AGPL-3.0许可证。
该文件定义了一个名为DetectionPredictor的类,它是BasePredictor类的扩展。该类用于进行基于检测模型的预测。
该文件还定义了一个postprocess方法,用于对预测结果进行后处理,并返回一个Results对象的列表。在后处理过程中,它使用了ops.non_max_suppression函数对预测结果进行非最大值抑制。然后,它将预测框的坐标进行缩放,并将结果存储在Results对象中。
该文件还提供了一个示例代码,展示了如何使用DetectionPredictor类进行预测。示例代码中使用了yolov8n.pt模型和ASSETS作为输入源。
5.3 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ?? 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这是一个用于训练基于检测模型的程序文件train.py。它使用了Ultralytics YOLO库进行目标检测模型的训练。
程序文件中定义了一个名为DetectionTrainer的类,它继承自BaseTrainer类,用于训练基于检测模型的任务。该类具有以下功能:
- 构建YOLO数据集:根据给定的图像路径、模式和批次大小,构建YOLO数据集。
- 获取数据加载器:根据给定的数据集路径、批次大小和模式,构建并返回数据加载器。
- 预处理批次数据:对一批图像进行预处理,包括缩放和转换为浮点数。
- 设置模型属性:将类别数、类别名称和超参数等属性附加到模型上。
- 获取模型:返回一个YOLO检测模型。
- 获取验证器:返回一个用于YOLO模型验证的DetectionValidator。
- 标记损失项:返回一个带有标记的训练损失项的损失字典。
- 训练进度字符串:返回一个格式化的训练进度字符串,包括当前的训练轮数、GPU内存、损失、实例数和数据集大小。
- 绘制训练样本:绘制带有注释的训练样本图像。
- 绘制指标:绘制来自CSV文件的指标。
- 绘制训练标签:创建一个带有标签的训练模型的绘图。
在程序文件的最后,使用给定的参数创建了一个DetectionTrainer对象,并调用其train方法进行模型训练。
5.5 backbone\VanillaNet.py
import torch
import torch.nn as nn
from timm.layers import weight_init
class activation(nn.ReLU):
def __init__(self, dim, act_num=3, deploy=False):
super(activation, self).__init__()
self.deploy = deploy
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num*2 + 1, act_num*2 + 1))
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6)
self.dim = dim
self.act_num = act_num
weight_init.trunc_normal_(self.weight, std=.02)
def forward(self, x):
if self.deploy:
return torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)
else:
return self.bn(torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, padding=self.act_num
该程序文件名为backbone\VanillaNet.py,是一个用于构建VanillaNet模型的Python代码文件。
该文件定义了以下类和函数:
- activation类:继承自nn.ReLU类,用于定义激活函数。
- Block类:继承自nn.Module类,用于定义VanillaNet的基本模块。
- VanillaNet类:继承自nn.Module类,用于定义整个VanillaNet模型。
- update_weight函数:用于更新模型的权重。
- vanillanet_5到vanillanet_13_x1_5_ada_pool函数:用于创建不同版本的VanillaNet模型。
其中,VanillaNet类是主要的模型定义部分,包括了模型的前向传播过程和权重初始化等。其他函数则是用于创建不同版本的VanillaNet模型。
在程序的最后,通过调用
5.6 extra_modules\head.py
import torch
import torch.nn as nn
from torch.nn.init import constant_, xavier_uniform_
from ..modules import Conv, DFL, C2f, RepConv, Proto
from .block import *
from .rep_block import *
from .afpn import AFPN_P345, AFPN_P345_Custom, AFPN_P2345, AFPN_P2345_Custom
from ultralytics.utils.tal import dist2bbox, make_anchors
class Detect_DyHead(nn.Module):
"""YOLOv8 Detect head with DyHead for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, hidc=256, block_num=2, ch=()): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channels
self.conv = nn.ModuleList(nn.Sequential(Conv(x, hidc, 1)) for x in ch)
self.dyhead = nn.Sequential(*[DyHeadBlock(hidc) for i in range(block_num)])
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(hidc, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for _ in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(hidc, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for _ in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
for i in range(self.nl):
x[i] = self.conv[i](x[i])
x = self.dyhead(x)
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
class Detect_DyHeadWithDCNV3(Detect_DyHead):
def __init__(self, nc=80, hidc=256, block_num=2, ch=()):
super().__init__(nc, hidc, block_num, ch)
self.dyhead = nn.Sequential(*[DyHeadBlockWithDCNV3(hidc) for i in range(block_num)])
class Detect_AFPN_P345(nn.Module):
"""YOLOv8 Detect head with AFPN for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, hidc=256, ch=()): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channels
self.afpn = AFPN_P345(ch, hidc)
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(hidc, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for _ in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(hidc, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3
该程序文件是一个用于目标检测模型的头部模块。它包含了多个不同的检测头部模型,用于在检测模型中生成预测的边界框和类别概率。
文件中定义了以下类:
Detect_DyHead: 使用DyHead的YOLOv8检测头部模型。Detect_DyHeadWithDCNV3: 使用DyHead和DCNV3的YOLOv8检测头部模型。Detect_AFPN_P345: 使用AFPN的YOLOv8检测头部模型。Detect_AFPN_P345_Custom: 使用自定义AFPN的YOLOv8检测头部模型。Detect_AFPN_P2345: 使用AFPN的YOLOv8检测头部模型。Detect_AFPN_P2345_Custom: 使用自定义AFPN的YOLOv8检测头部模型。Detect_Efficient: 使用Efficient的YOLOv8检测头部模型。
这些类中的每一个都有一个forward方法,用于计算预测的边界框和类别概率。这些类还包含一些其他方法,用于初始化模型参数和计算输出形状等。
该程序文件还导入了其他模块和函数,用于辅助计算和构建模型。
6.系统整体结构
整体功能和架构概述:
该项目是一个白鼠轨迹检测追踪系统,基于YOLOv8目标检测模型,并融合了在线卷积重参数化(OREPA)技术进行改进。该系统包含了多个程序文件,用于模型训练、预测、导出、图形界面展示等功能。
下表整理了每个文件的功能:
| 文件路径 | 功能概述 |
|---|---|
| export.py | 将YOLOv8模型导出为其他格式的程序文件 |
| predict.py | 基于检测模型进行预测的程序文件 |
| train.py | 用于训练基于检测模型的任务的程序文件 |
| ui.py | 使用PyQt5编写的图形用户界面(GUI)程序文件 |
| backbone\VanillaNet.py | 构建VanillaNet模型的代码文件 |
| extra_modules\head.py | 目标检测模型的头部模块 |
| extra_modules\kernel_warehouse.py | 存储卷积核的仓库 |
| extra_modules\orepa.py | 在线卷积重参数化(OREPA)模块 |
| extra_modules\rep_block.py | 重参数化块模块 |
| extra_modules\RFAConv.py | 递归特征聚合卷积(RFAConv)模块 |
| extra_modules_init_.py | extra_modules模块的初始化文件 |
| extra_modules\ops_dcnv3\setup.py | ops_dcnv3模块的安装配置文件 |
| extra_modules\ops_dcnv3\test.py | ops_dcnv3模块的测试文件 |
| extra_modules\ops_dcnv3\functions\dcnv3_func.py | ops_dcnv3模块的函数定义文件 |
| extra_modules\ops_dcnv3\functions_init_.py | ops_dcnv3模块的函数初始化文件 |
| extra_modules\ops_dcnv3\modules\dcnv3.py | ops_dcnv3模块的模型定义文件 |
| extra_modules\ops_dcnv3\modules_init_.py | ops_dcnv3模块的模型初始化文件 |
| models\common.py | 通用模型定义和功能函数 |
| models\experimental.py | 实验性模型定义 |
| models\tf.py | TensorFlow模型定义 |
| models\yolo.py | YOLO模型定义 |
| models_init_.py | models模块的初始化文件 |
| utils\activations.py | 激活函数定义 |
| utils\augmentations.py | 数据增强函数定义 |
| utils\autoanchor.py | 自动锚框生成函数定义 |
| utils\autobatch.py | 自动批次大小调整函数定义 |
| utils\callbacks.py | 回调函数定义 |
| utils\datasets.py | 数据集处理函数定义 |
| utils\downloads.py | 下载函数定义 |
| utils\general.py | 通用工具函数定义 |
| utils\loss.py | 损失函数定义 |
| utils\metrics.py | 指标计算函数定义 |
| utils\plots.py | 绘图函数定义 |
| utils\torch_utils.py | PyTorch工具函数定义 |
| utils_init_.py | utils模块的初始化文件 |
| utils\aws\resume.py | AWS恢复函数定义 |
| utils\aws_init_.py | AWS模块的初始化文件 |
| utils\flask_rest_api\example_request.py | Flask REST API示例请求定义 |
| utils\flask_rest_api\restapi.py | Flask REST API定义 |
| utils\loggers_init_.py | loggers模块的初始化文件 |
| utils\loggers\wandb\log_dataset.py | WandB日志记录器的数据集日志定义 |
| utils\loggers\wandb\sweep.py | WandB日志记录器的超参数搜索定义 |
| utils\loggers\wandb\wandb_utils.py | WandB日志记录器的工具函数定义 |
| utils\loggers\wandb_init_.py | WandB日志记录器的初始化文件 |
请注意,以上概述仅基于文件路径和文件名进行推测,具体功能可能需要查看代码来确认。
7.YOLOv8简介
继YOLOv5之后,Ultralytics公司在2023年1月发布了YOLOv8,该版本可以用于执行目标检测、实例分割和图像分类任务。整个网络结构由4部分组成:输入图像, Backbone主干网络获得图像的特征图, Head检测头预测目标对象和位置, Neck融合不同层的特征并将图像特征传递到预测层。
1)相比于YOLOv5和 YOLOv7算法,YOLOv8在训练时间和检测精度上得到极大提升,而且模型的权重文件只有6 MB,可以部署到任一嵌入式设备中,它凭借自身快速、高效的性能可以很好地满足实时检测的需求。
2)由于YOLOv8算法是YOLOv5的继承版本,对应提供了N、S、 M、L、X 等不同尺度的模型,用于满足不同场景的需求,在精度得到大幅提升的同时,能流畅地训练,并且能安装在各种硬件平台上运行。
3)在输入端,YOLOv8算法使用了Mosaic数据增强[15]、自适应锚框计算[16]等方法。Mosaic数据增强是通过随机缩放、随机裁剪、随机排布的方式进行拼接,丰富检测数据集。自适应锚框计算是网络在初始锚框的基础上输出预测框,通过差值计算、反向更新等操作计算出最佳锚框值。
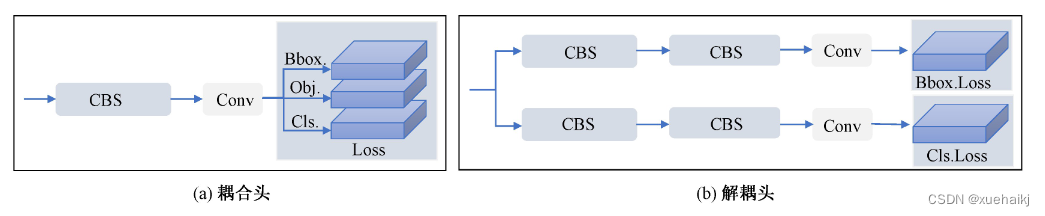
4)在输出端,YOLOv8算法使用解耦头替换了以往的耦合头,将分类和回归解耦为两个独立的分支,通过解耦使各个任务更加专注,从而解决复杂场景下定位不准及分类错误的问题。
8.OREPA:在线卷积重参数化
卷积神经网络(CNNs)已经在许多计算机视觉任务的应用成功,包括图像分类、目标检测、语义分割等。精度和模型效率之间的权衡也已被广泛讨论。
一般来说,一个精度较高的模型通常需要一个更复杂的块,一个更宽或更深的结构。然而,这样的模型总是太重,无法部署,特别是在硬件性能有限、需要实时推理的场景下。考虑到效率,更小、更紧凑和更快的模型自然是首选。
为了获得一个部署友好且高精度的模型,有研究者提出了基于结构重参数化的方法来释放性能。在这些方法中,模型在训练阶段和推理阶段有不同的结构。具体来说,使用复杂的训练阶段拓扑,即重参数化的块,来提高性能。训练结束后,通过等效变换将一个复杂的块重参为成一个单一的线性层。重参后的模型通常具有一个整洁架构模型,例如,通常是一个类似VGG的或一个类似ResNet的结构。从这个角度来看,重参化策略可以在不引入额外的推理时间成本的情况下提高模型的性能。
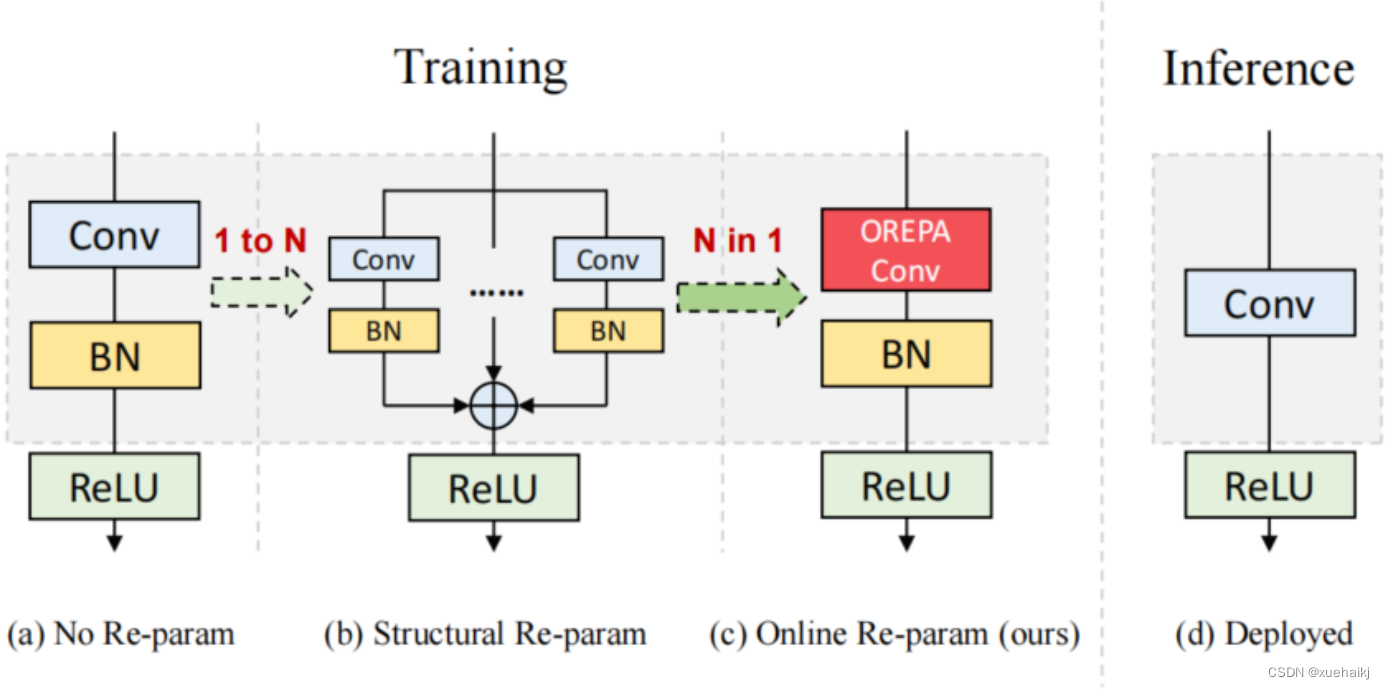
BN层是重构模型的关键组成部分。在一个重新解析块(图1(b))中,在每个卷积层之后立即添加一个BN层。可以观察到,去除这些BN层会导致的性能退化。然而,当考虑到效率时,这种BN层的使用出乎意料地在训练阶段带来了巨大的计算开销。在推理阶段,复杂的块可以被压缩成一个卷积层。但是,在训练过程中,BN层是非线性的,也就是说,它们将特征映射除以它的标准差,这就阻止了合并整个块。因此,存在大量的中间计算操作(large FLOPS)和缓冲特征映射(high memory usage)。更糟糕的是,这么高的训练预算使得很难探索更复杂和可能更强的重参块。很自然地,下面的问题就出现了:
为什么标准化在重参中这么重要?
通过分析和实验,作者认为BN层中的尺度因子最重要,因为它们能够使不同分支的优化方向多样化。
基于观察结果,作者提出了在线重参化(OREPA)(图1?),这是一个两阶段的pipeline,使之能够简化复杂的training-time re-param block。
在第一阶段,block linearization,去除所有的非线性BN层,并引入线性缩放层。这些层与BN层具有相似的性质,因此它们使不同分支的优化多样化。此外,这些层都是线性的,可以在训练过程中合并成卷积层。
第二阶段,block squeezing,将复杂的线性块简化为单一的卷积层。OREPA通过减少由中间计算层引起的计算和存储开销,显著降低了训练成本,对性能只有非常小的影响。
此外,高效化使得探索更复杂的重参化拓扑成为可能。为了验证这一点,作者进一步提出了几个重参化的组件,以获得更好的性能。
在ImageNet分类任务上评估了所提出的OREPA。与最先进的修复模型相比,OREPA将额外的训练时间GPU内存成本降低了65%到75%,并将训练过程加快了1.5-2.3倍。同时,OREPA-ResNet和OREPA-VGG的性能始终优于+0.2%~+0.6%之前的DBB和RepVGG方法。同时作者还评估了在下游任务上的OREPA,即目标检测和语义分割。作者发现OREPA可以在这些任务上也可以带来性能的提高。
提出了在线卷积重参化(OREPA)策略,这极大地提高了重参化模型的训练效率,并使探索更强的重参化块成为可能;
通过对重参化模型工作机制的分析,用引入的线性尺度层代替BN层,这仍然提供了不同的优化方向,并保持了表示能力;
在各种视觉任务上的实验表明,OREPA在准确性和训练效率方面都优于以前的重参化模型(DBB/RepVGG)。
结构重参化
结构重参化最近被重视并应用于许多计算机视觉任务,如紧凑模型设计、架构搜索和剪枝。重参化意味着不同的架构可以通过参数的等价转换来相互转换。例如,1×1卷积的一个分支和3×3卷积的一个分支,可以转移到3×3卷积的单个分支中。在训练阶段,设计了多分支和多层拓扑来取代普通的线性层(如conv或全连接层)来增强模型。Cao等讨论了如何在训练过程中合并深度可分离卷积核。然后在推理过程中,将训练时间的复杂模型转移到简单模型中,以便于更快的推理。
在受益于复杂的training-time拓扑,同时,当前的重参化方法训练使用不可忽略的额外计算成本。当块变得更复杂以变得更强的表示时,GPU内存利用率和训练时间将会越来越长,最终走向不可接受。与以往的重参化方法不同,本文更多地关注训练成本。提出了一种通用的在线卷积重参化策略,使training-time的结构重参化成为可能。
Normalization
BN被提出来缓解训练非常深度神经网络时的梯度消失问题。人们认为BN层是非常重要的,因为它们平滑了损失。最近关于无BN神经网络的研究声称,BN层并不是不可或缺的。通过良好的初始化和适当的正则化,可以优雅地去除BN层。
对于重参化模型,作者认为重参化块中的BN层是关键的。无BN的变体将会出现性能下降。然而,BN层是非线性的,也就是说,它们将特征图除以它的标准差,这阻止了在线合并块。为了使在线重参化可行,作者去掉了重参块中的所有BN层,并引入了BN层的线性替代方法,即线性缩放层。
卷积分解
标准卷积层计算比较密集,导致大的FLOPs和参数量。因此,卷积分解方法被提出,并广泛应用于移动设备的轻量化模型中。重参化方法也可以看作是卷积分解的某种形式,但它更倾向于更复杂的拓扑结构。本文的方法的不同之处在于,在kernel-level上分解卷积,而不是在structure level。
在线重参化
在本节中,首先,分析了关键组件,即重参化模型中的BN层,在此基础上提出了在线重参化(OREPA),旨在大大减少再参数化模型的训练时间预算。OREPA能够将复杂的训练时间块简化为一个卷积层,并保持了较高的精度。
OREPA的整体pipeline如图所示,它包括一个Block Linearization阶段和一个Block Squeezing阶段。

参考该博客通过分析多层和多分支结构的优化多样性,深入研究了重参化的有效性,并证明了所提出的线性缩放层和BN层具有相似的效果。
最后,随着训练预算的减少,进一步探索了更多的组件,以实现更强的重参化模型,成本略有增加。
重参化中的Normalization
作者认为中间BN层是重参化过程中多层和多分支结构的关键组成部分。以SoTA模型DBB和RepVGG为例,去除这些层会导致严重的性能下降,如表1所示。

这种观察结果也得到了Ding等人的实验支持。因此,作者认为中间的BN层对于重参化模型的性能是必不可少的。
然而,中间BN层的使用带来了更高的训练预算。作者注意到,在推理阶段,重参化块中的所有中间操作都是线性的,因此可以合并成一个卷积层,从而形成一个简单的结构。
但在训练过程中,BN层是非线性的,即它们将特征映射除以其标准差。因此,中间操作应该单独计算,这将导致更高的计算和内存成本。更糟糕的是,如此高的成本将阻止探索更强大的训练模块。
Block Linearization
如3.1中所述,中间的BN层阻止了在训练过程中合并单独的层。然而,由于性能问题,直接删除它们并不简单。为了解决这一困境,作者引入了channel级线性尺度操作作为BN的线性替代方法。
缩放层包含一个可学习的向量,它在通道维度中缩放特征映射。线性缩放层具有与BN层相似的效果,它们都促进多分支向不同的方向进行优化,这是重参化时性能提高的关键。除了对性能的影响外,线性缩放层还可以在训练过程中进行合并,使在线重参化成为可能。

基于线性缩放层,作者修改了重参化块,如图所示。具体来说,块的线性化阶段由以下3个步骤组成:
首先,删除了所有的非线性层,即重参化块中的BN层
其次,为了保持优化的多样性,在每个分支的末尾添加了一个缩放层,这是BN的线性替代方法
最后,为了稳定训练过程,在所有分支的添加后添加一个BN层。
一旦完成线性化阶段,在重参化块中只存在线性层,这意味着可以在训练阶段合并块中的所有组件。
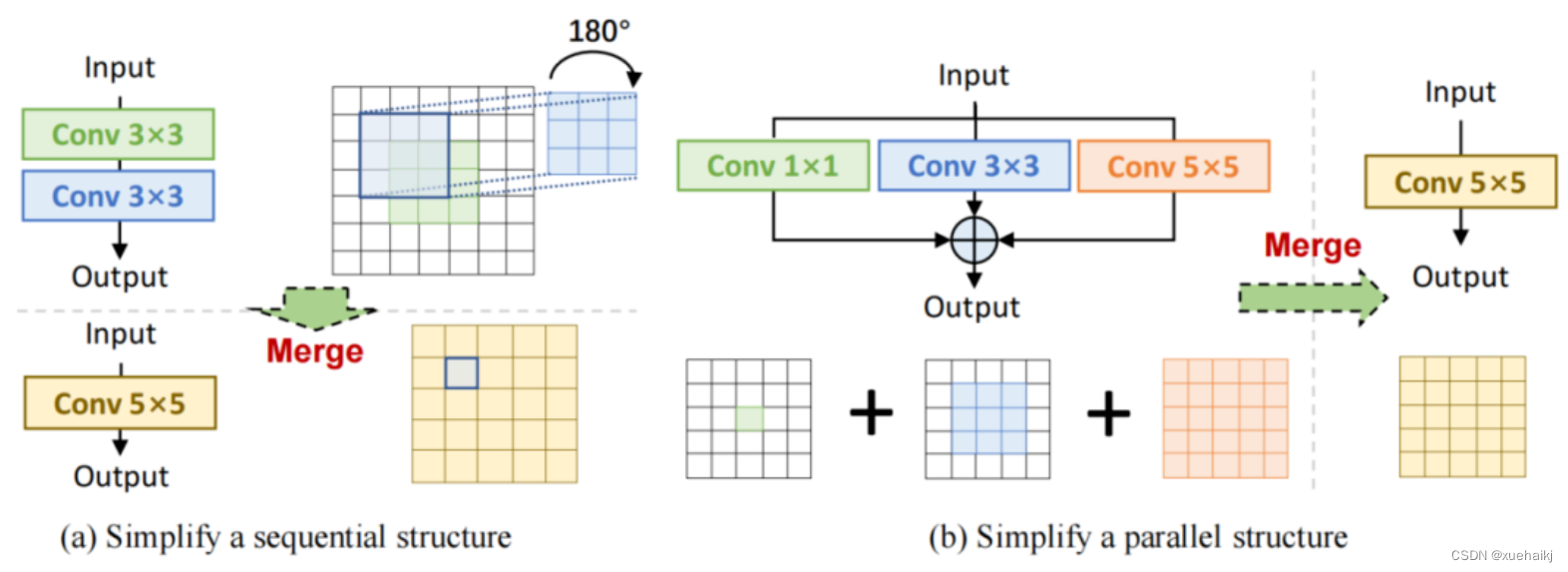
Block Squeezing
Block Squeezing步骤将计算和内存昂贵的中间特征映射上的操作转换为更经济的kernel上的操作。这意味着在计算和内存方面从减少到,其中、是特征图和卷积核的空间尺寸。
一般来说,无论线性重参化块是多么复杂,以下2个属性始终成立:
Block中的所有线性层,例如深度卷积、平均池化和所提出的线性缩放,都可以用带有相应参数的退化卷积层来表示;
Block可以由一系列并行分支表示,每个分支由一系列卷积层组成。
有了上述两个特性,如果可以将
多层(即顺序结构)
多分支(即并行结构)
简化为单一卷积,就可以压缩一个块。在下面的部分中,将展示如何简化顺序结构(图(a))和并行结构(图(b))。
9.训练结果可视化分析
评价指标
Epoch:训练纪元数。
训练损失:训练期间的损失,包括train/box_loss、train/obj_loss和train/cls_loss。
指标:绩效指标,如precision、recall、mAP_0.5和mAP_0.5:0.95。
验证损失:验证数据的损失,包括val/box_loss、val/obj_loss和val/cls_loss。
学习率:不同层或参数的学习率,x/lr0,x/lr1, 和x/lr2。
为了进行全面的数据分析和可视化,我们将探讨以下几个方面:
训练结果可视化
损失分析:跟踪训练和验证损失在不同时期的变化情况。
性能指标分析:检查精确度、召回率和平均精确度 (mAP) 在不同时期的演变情况。
学习率趋势:观察训练过程中学习率的变化。
让我们从可视化这些方面开始。我们将为每个类别创建绘图,以便更好地了解这些指标在训练过程中的趋势和行为。?
import matplotlib.pyplot as plt
# Setting up the plots
fig, axs = plt.subplots(3, 1, figsize=(15, 18))
# Plotting Training and Validation Losses
axs[0].plot(data['epoch'], data['train/box_loss'], label='Train Box Loss', color='blue')
axs[0].plot(data['epoch'], data['train/obj_loss'], label='Train Object Loss', color='green')
axs[0].plot(data['epoch'], data['val/box_loss'], label='Validation Box Loss', linestyle='--', color='blue')
axs[0].plot(data['epoch'], data['val/obj_loss'], label='Validation Object Loss', linestyle='--', color='green')
axs[0].set_xlabel('Epoch')
axs[0].set_ylabel('Loss')
axs[0].set_title('Training and Validation Losses')
axs[0].legend()
# Plotting Performance Metrics
axs[1].plot(data['epoch'], data['metrics/precision'], label='Precision', color='red')
axs[1].plot(data['epoch'], data['metrics/recall'], label='Recall', color='purple')
axs[1].plot(data['epoch'], data['metrics/mAP_0.5'], label='mAP_0.5', color='orange')
axs[1].plot(data['epoch'], data['metrics/mAP_0.5:0.95'], label='mAP_0.5:0.95', color='brown')
axs[1].set_xlabel('Epoch')
axs[1].set_ylabel('Metric Value')
axs[1].set_title('Performance Metrics Over Epochs')
axs[1].legend()
# Plotting Learning Rates
axs[2].plot(data['epoch'], data['x/lr0'], label='LR0', color='cyan')
axs[2].plot(data['epoch'], data['x/lr1'], label='LR1', color='magenta')
axs[2].plot(data['epoch'], data['x/lr2'], label='LR2', color='yellow')
axs[2].set_xlabel('Epoch')
axs[2].set_ylabel('Learning Rate')
axs[2].set_title('Learning Rate Trends Over Epochs')
axs[2].legend()
plt.tight_layout()
plt.show()
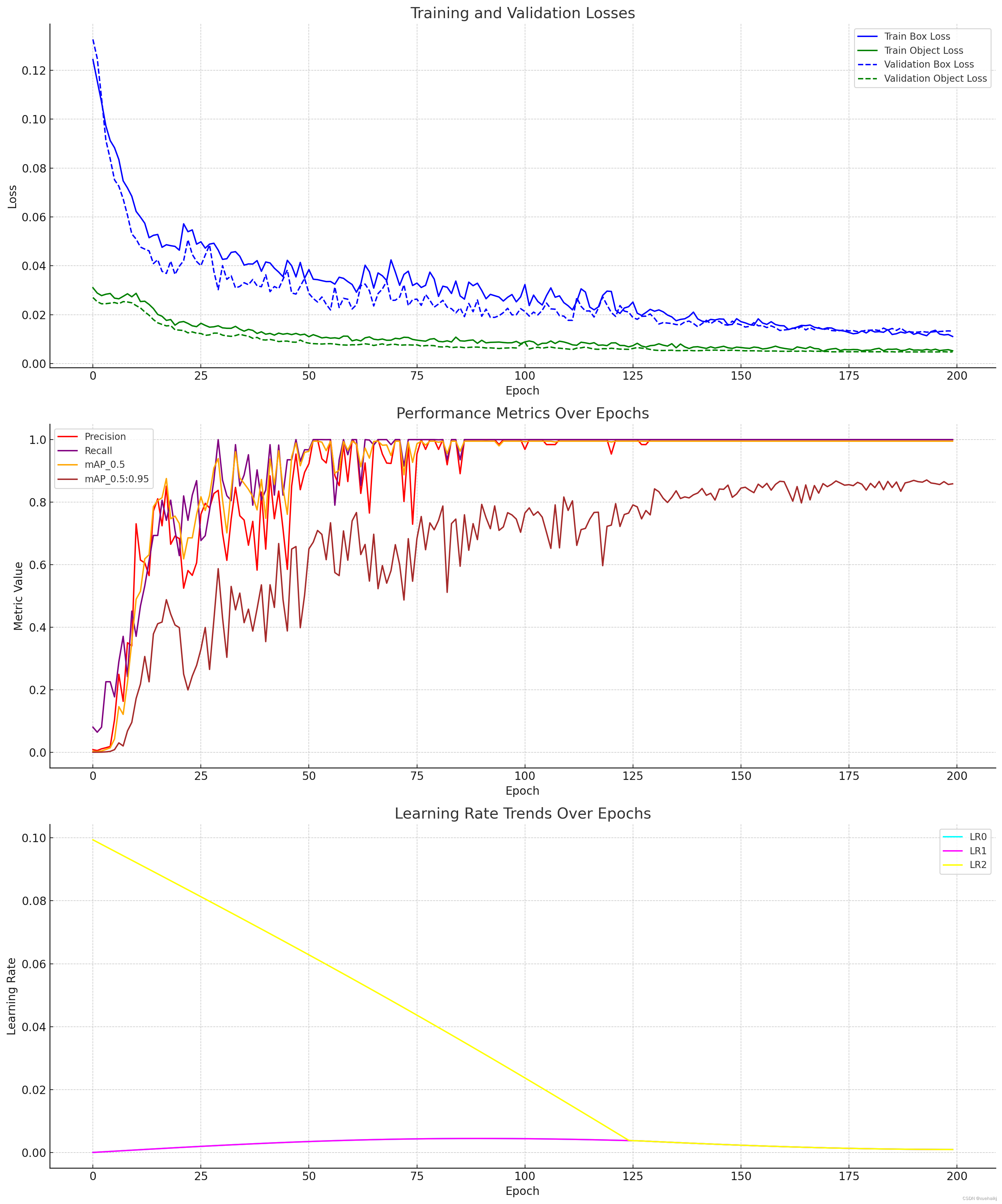
训练和验证损失:第一个图说明了训练(框损失和对象损失)和验证(框损失和对象损失)期间的损失。历元内损失值的下降通常表明模型性能的学习和改进。
性能指标:第二张图显示了各个时期的性能指标(如精度、召回率、mAP_0.5 和 mAP_0.5:0.95)的演变。这些指标对于评估模型正确识别和分类对象的能力至关重要。
学习率趋势:第三个图显示了不同时期不同层或参数的学习率趋势。学习率的变化可以显着影响模型的训练过程及其收敛行为。
现在,让我们详细分析这些图:
训练和验证损失
训练集和验证集上的框丢失和对象丢失都显示出趋势。理想情况下,两者都应随着时间的推移而减少,表明模型正在有效地学习。
如果验证损失与训练损失不同(训练损失增加而训练损失减少),则可能表明过度拟合。
性能指标
精确率和召回率分别衡量模型的准确性及其检测所有相关实例的能力。这两个指标之间的平衡至关重要。
IoU=0.5 和 IoU=0.5:0.95 的平均精度 (mAP) 值提供了模型在不同阈值下的检测精度的综合度量。mAP 值的改进表明模型性能更好。
10.系统整合

参考博客《白鼠轨迹检测追踪系统:融合在线卷积重参数化OREPA改进YOLOv8》
11.参考文献
[1]祝玉华,司艺艺,李智慧.基于深度学习的烟雾与火灾检测算法综述[J].计算机工程与应用.2022,58(23).DOI:10.3778/j.issn.1002-8331.2206-0154 .
[2]谢书翰,张文柱,程鹏,等.嵌入通道注意力的YOLOv4火灾烟雾检测模型[J].液晶与显示.2021,(10).DOI:10.37188/CJLCD.2020-0312 .
[3]殷亚萍,柴文,凌毅德,等.基于特征分析的卷积神经网络烟雾识别[J].无线电工程.2021,(7).DOI:10.3969/j.issn.1003-3106.2021.07.002 .
[4]陈俊周,汪子杰,陈洪瀚,等.基于级联卷积神经网络的视频动态烟雾检测[J].电子科技大学学报.2016,(6).DOI:10.3969/j.issn.1001-0548.2016.06.020 .
[5]佚名.Two-Step Real-Time Night-Time Fire Detection in an Urban Environment Using Static ELASTIC-YOLOv3 and Temporal Fire-Tube[J].Sensors.2020,20(2).2202.DOI:10.3390/s20082202 .
[6]Lin, Gaohua,Zhang, Yongming,Xu, Gao,等.Smoke Detection on Video Sequences Using 3D Convolutional Neural Networks[J].Fire technology.2019,55(5).1827-1847.DOI:10.1007/s10694-019-00832-w .
[7]Gao Xu,Yongming Zhang,Qixing Zhang,等.Video smoke detection based on deep saliency network[J].Fire Safety Journal.2019.105277-285.DOI:10.1016/j.firesaf.2019.03.004 .
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!