GPT-4V被超越?SEED-Bench多模态大模型测评基准更新

📖 技术报告
SEED-Bench-1:https://arxiv.org/abs/2307.16125?
SEED-Bench-2:https://arxiv.org/abs/2311.17092?
🤗 测评数据
SEED-Bench-1:https://huggingface.co/datasets/AILab-CVC/SEED-Bench?
SEED-Bench-2:https://huggingface.co/datasets/AILab-CVC/SEED-Bench-2?
🔗 项目主页
https://github.com/AILab-CVC/SEED-Bench
🏆 在线排行榜
https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard
大语言模型(LLM)的蓬勃发展离不开健全的评测体系,而对于多模态大语言模型(MLLM)而言,一直缺乏类似MMLU、ARC等全面且客观的评测基准。腾讯AI Lab联手腾讯ARC Lab推出了SEED-Bench系列评测基准,有效弥补了这一缺陷,目前已成为测评MLLM的主流基准之一。
SEED-Bench评测基准在2023年7月首次发布,它包含了19K道经过人工标注正确答案的选择题,涵盖了图像和视频的12个评估维度;并在11月发布了v2版本,扩充至24K选择题和27个维度!🤩 值得一提的是,Hugging Face CEO Clément Delangue也对在线榜单进行了点赞。
随着MLLM的迅速发展,短短四个月内,SEED-Bench-1评测榜单的排名(见下图)已经全部焕然一新。最近,备受瞩目的GPT-4V模型也推出,引发了社区对其在SEED-Bench上表现的关注。然而,出人意料的是,在单张图像的评估维度上,GPT-4V竟然并未位居榜首。
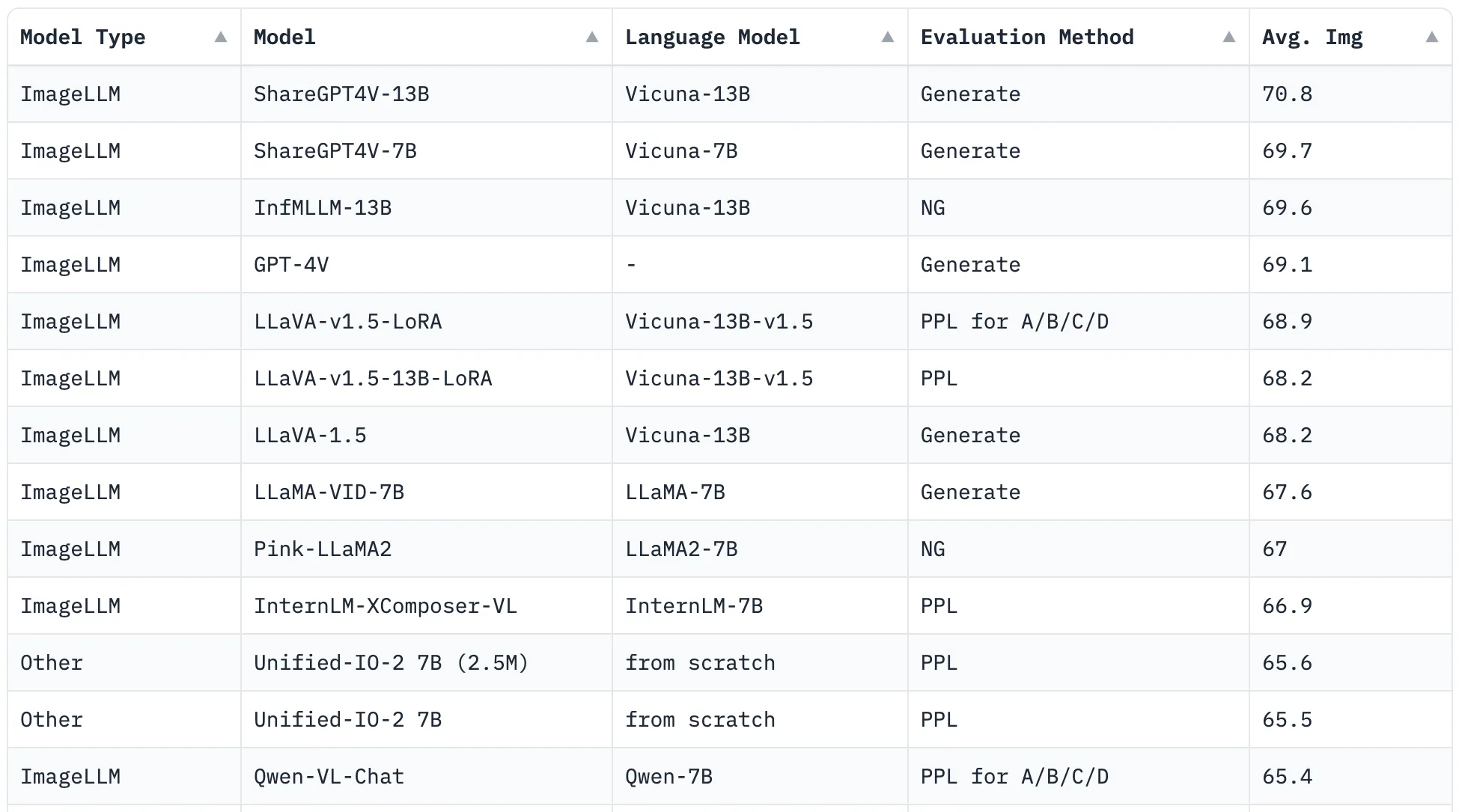
01. GPT-4V被超越?🤯
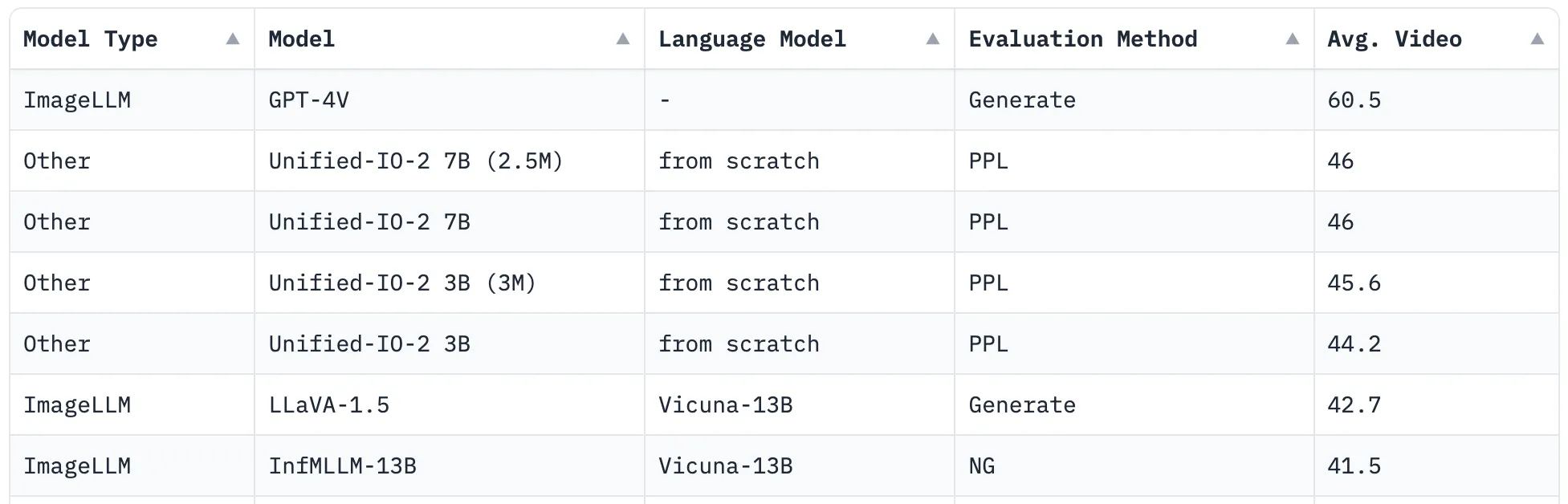
现在下这个结论还为时过早。我们可以看到,GPT-4V在SEED-Bench-1视频(即图像序列)的评估维度上显著超越第二名(见下图),可以体现出GPT-4V较强的多模态推理能力。
事实上,不止于多模态理解(输入图文,输出文),近期的研究(如CM3leon、Next-GPT、Emu、SEED-LLaMA等)进一步赋予了MLLM生成图像(输入图文,输出图乃至图文)?的能力,使其能够表现得像GPT-4V和DALL-E 3的组合一样实现任意形式的输入和输出。
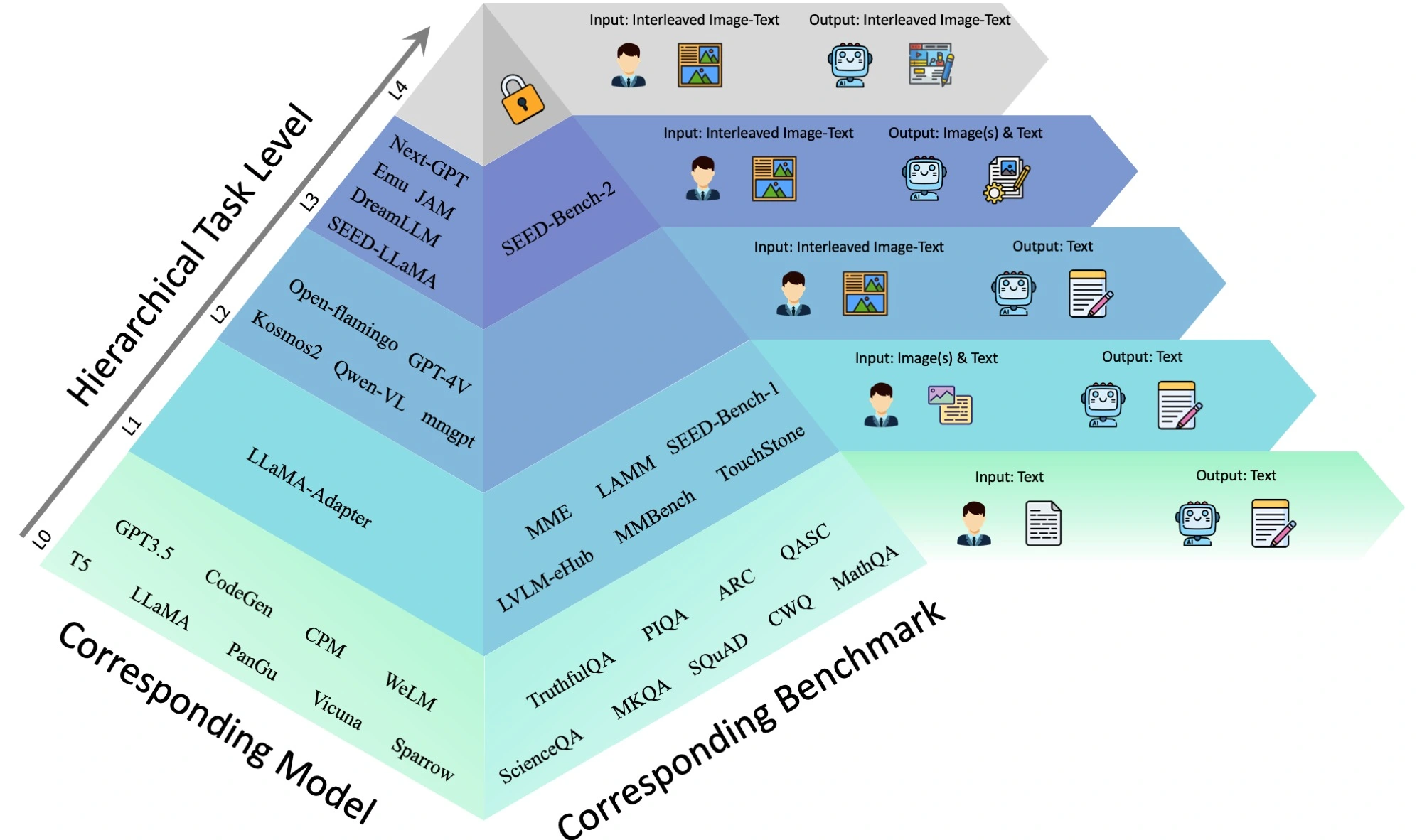
然而,目前的多模态测评基准(如SEED-Bench-1、MMBench、MME等)仅评估MLLM的理解能力,滞后于MLLM的飞速发展。SEED-Bench-2,这一全新的评测基准在SEED-Bench首度发布四个月后,以其全新的评估视角,重磅登场,首次对MLLM的层级化能力进行评估。
02. SEED-Bench-2 🧐
如下图所示,SEED-Bench-2由三个层级构成(L1-3),每个层级都对模型的不同能力进行了深度评估:

在这一金字塔评估层级中,高层级会覆盖低层级的评估维度,即L3级模型应同时具备L1-2的能力。

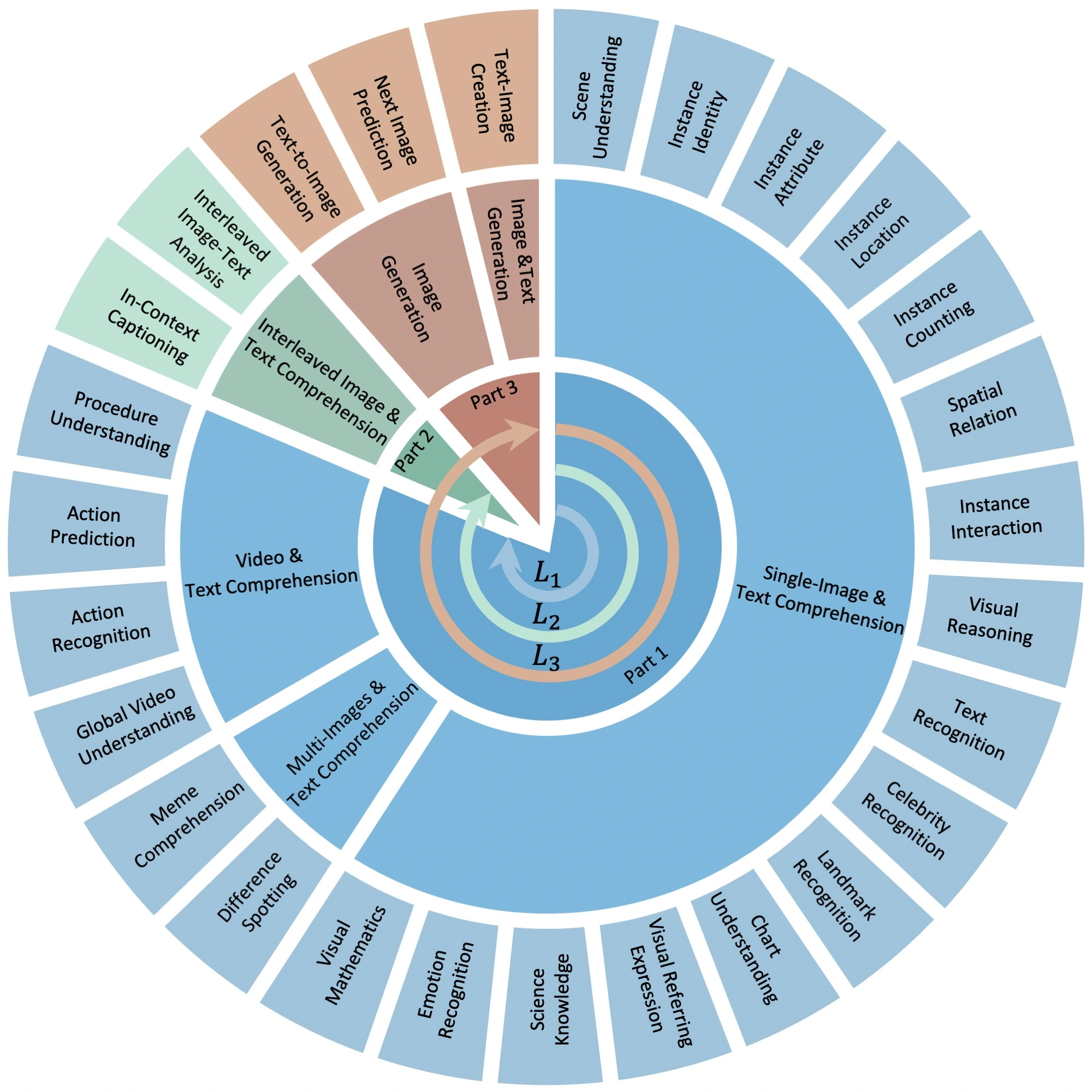
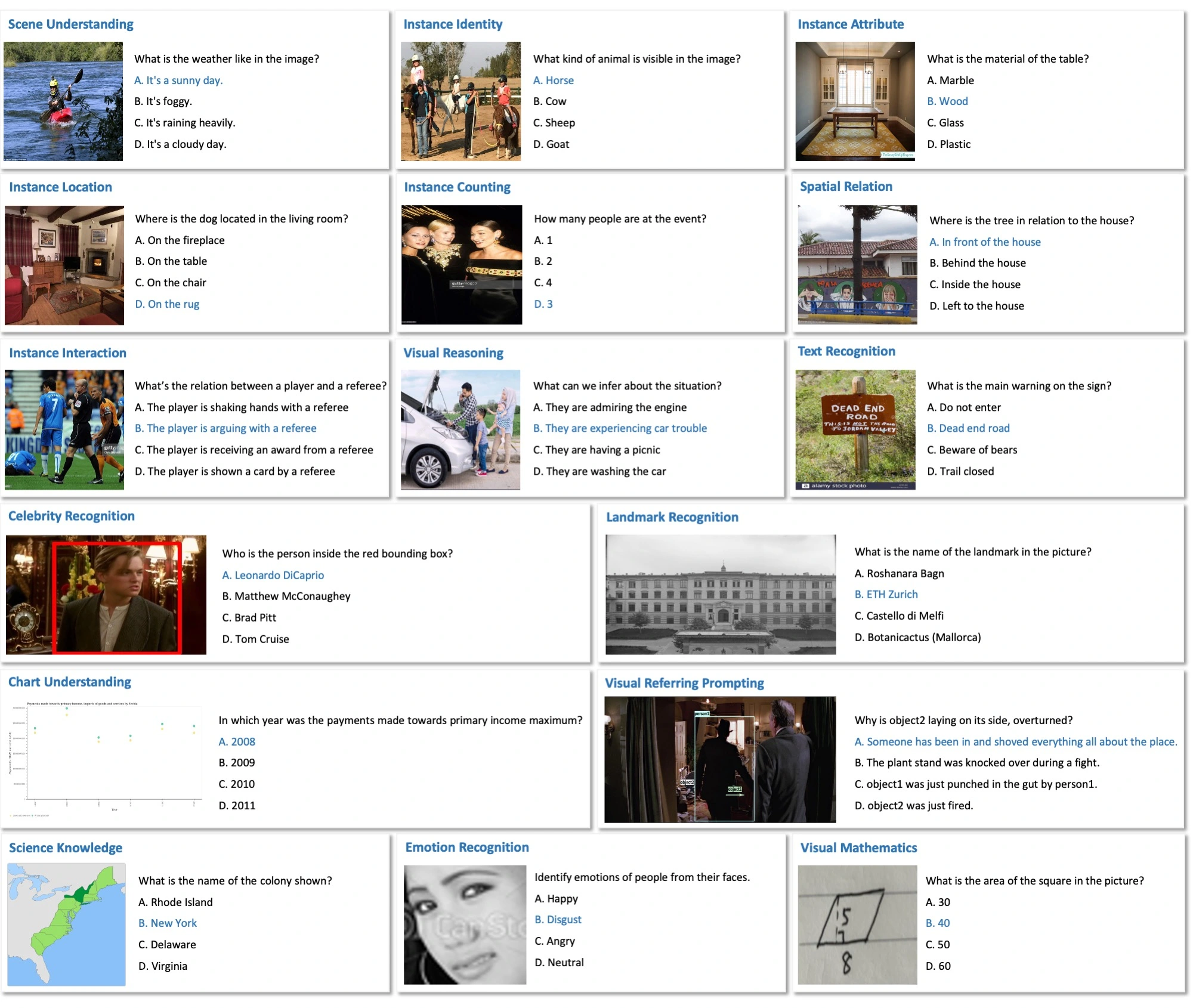
下图分别展示了SEED-Bench-2中不同维度的题目示例:


那么GPT-4V在全新的SEED-Bench-2表现如何?

SEED-Bench-2目前已测评了23个开源MLLM的性能,它们在各个层级和维度的具体表现如下图。欢迎大家持续向在线leaderboard贡献自己的结果!
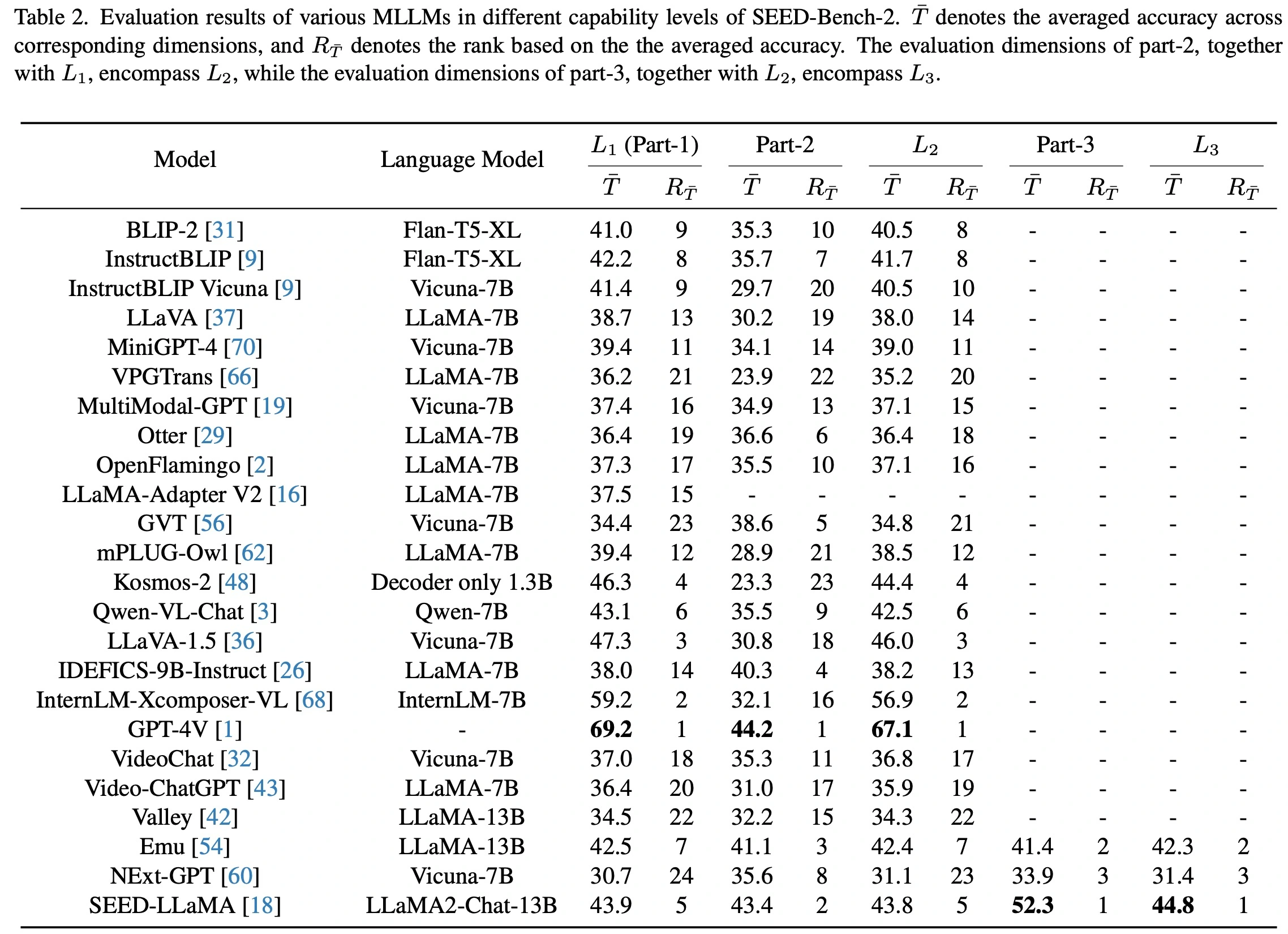
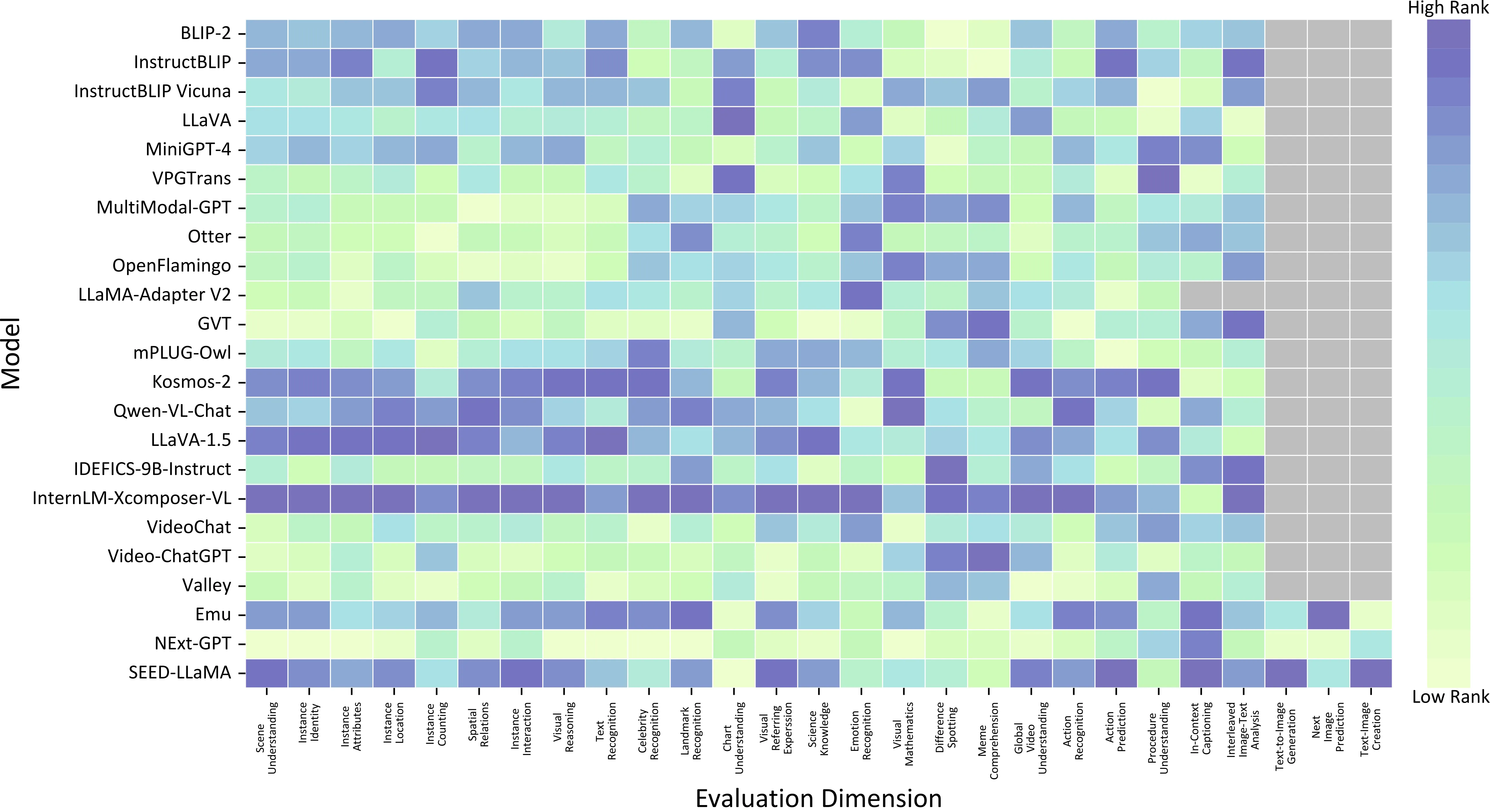
SEED-Bench-2的层级化评测结果展示了如下的发现。

03. Q&A
Q: SEED-Bench-2评测方式 🏁
A:?针对文本输出的测评,我们参考相关工作:GPT-3,InstructBLIP和TruthfulQA,通过计算模型对于各个选项的ppl,来获取模型选择题的答案。
针对图片输出的测评,我们计算模型生成图像和groundtruth图像的CLIP相似分数,来获取模型选择题的答案。(注:我们目前侧重关注语义的正确性)
此外我们发现社区的模型在测评SEED-Bench时,使用了ppl以外的测评方式(如直接generate),我们在leaderboard上新增了不同测评方式(Evaluation Method)的说明和赛道。
Q: SEED-Bench-1和SEED-Bench-2的关系 💎
A:?SEED-Bench-1的测评维度构成了SEED-Bench-2?层级的部分维度。
🎯 SEED-Bench-2的测评数据和代码已经开源,欢迎社区更新自己的模型在SEED-Bench-2上的结果。
📢 如果您有相关问题,或者对于SEED-Bench系列测评基准有什么建议,欢迎在项目链接的issue中联系我们。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!