Transformer从菜鸟到新手(一)
引言
这是从Transformer到LLM(大语言模型)系列的第一篇文章,几乎所有的大语言模型都是基于Transformer结构,因此本文回顾一下Transformer的原理与实现细节,包括分词算法BPE的实现。最终利用从零实现的Transformer模型进行英中翻译。
本文主要介绍Transformer中用到的子词分词算法BPE,在文章的最后你会自己实现一个BPE算法。
下篇文章介绍Transformer的核心模块——多头注意力以及位置编码的实现。
Transformer模型
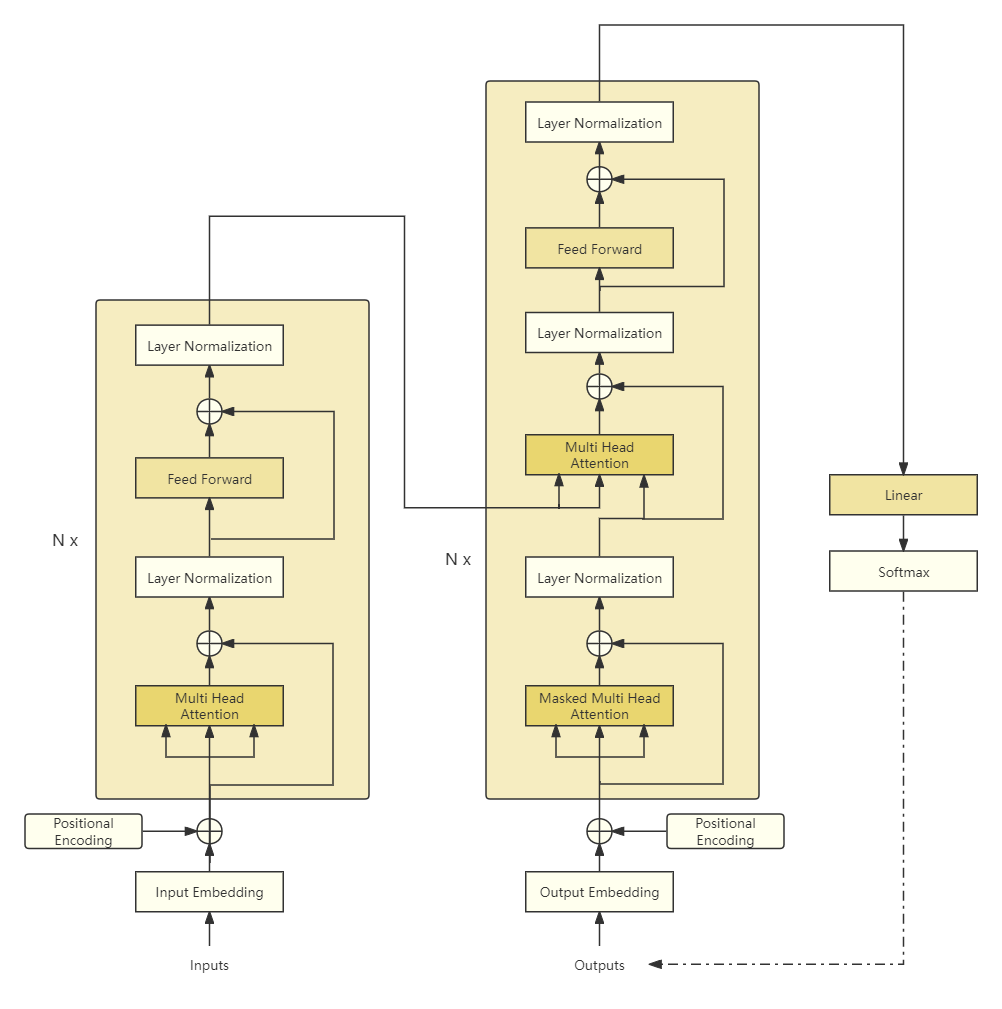
Transformer模型如上图所示,它也属于编码器-解码器架构,左边是编码器,右边是解码器。它们都由N个Transformer Block(块)组成。编码器的输出作为解码器多头注意力的Key和Value,Query来自解码器输入经过掩码多头注意力后的结果。
主要涉及以下几个模块:
-
嵌入表示(Input/Output Embedding) 将每个标记(token)转换为对应的向量表示。
-
位置编码(Positional Encoding) 由于没有时序信息,需要额外加入位置编码。
-
多头注意力(Multi-Head Attention) 利用注意力机制对输入进行交互,得到具有上下文信息的表示。根据其所处的位置有不同的变种:邻接解码器嵌入位置是掩码多头注意力,特点是当前位置只能注意本身以及之前位置的信息;掩码多头注意力紧接的多头注意力特点是Key和Value来自编码器的输出,而Query来自底层的输出,目的是在计算输出时考虑输入信息。
-
层归一化(Layer Normalization) 作用于Transformer块内部子层的输出表示上,对表示序列进行层归一化。
-
残差连接(Residual connection) 作用于Transformer块内部子层输入和输出上,对其输入和输出进行求和。
-
位置感知前馈网络(Position-wise Feedforward Network) 通过多层全连接网络对表示序列进行非线性变换,提升模型的表达能力。
下面依次介绍各模块的功能和实现。
嵌入表示
对于输入文本序列,首先要进行分词,而Transformer所采用的分词算法为更能解决OOV(Out of Vocabulary)问题的子词分词算法——BPE(Byte Pair Encoding)。分词之后得到子词标记,当成我们常用的标记使用,来构建词表。最后基于词表大小创建一个对应的嵌入层。
嵌入层的实现如下:
class Embedding(nn.Module):
def __init__(self, vocab_size: int, d_model: int) -> None:
"""
Args:
vocab_size (int): size of vocabulary
d_model (int): dimension of embeddings
"""
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.sqrt_d_model = math.sqrt(d_model)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x (Tensor): (batch_size, seq_length)
Returns:
Tensor: (batch_size, seq_length, d_model)
"""
# multiply embedding values by the square root of the embedding dimension
return self.embed(x) * self.sqrt_d_model
vocab_size是词表大小;d_model是嵌入层的维度,如原始论文所说,会用嵌入结果与
d
model
\sqrt{\text{d}_{\text{model}}}
dmodel??相乘。
我们重点来看BPE分词算法的实现。
BPE
BPE分词算法主要由以下四个步骤组成:
- 标准化
- 预分词
- 单词拆分成字符
- 根据学习到的规则应用到这些拆分
标准化对输入的单词进行一些预处理,包括大小写转换、(英文)复数转换为单数等。我们这里简单处理,只进行大小写转换。
预分词做的是将文本序列按照某一规则拆分最小单元——单词,我们这里英文按空格拆分,中文通过jieba进行分词。
将单词拆分成字符比较简单,英文就拆分成字母;中文拆分成字。
最后利用BPE学习到的合并规则来对拆分后的结果进行合并,得到我们想要的子词(subtoken)。
因此BPE算法主要通过训练算法学习的是这些合并规则。
BPE训练算法的步骤如下:
- 初始化语料库
- 将语料库中每个单词拆分成字符作为子词,
并在单词结尾增加一个</w>字符 - 将拆分后的子词构成初始子词词表
- 在语料库中统计单词内相邻子词对的频次
- 合并频次最高的子词对,合并成新的子词,并将新的子词加入到子词词表
- 重复步骤4和5直到进行了设定的合并次数或达到了设定的子词词表大小
我们以参考2中的例子为例介绍BPE算法的实现,注意这只是为了让我们更好地理解原理,实际应用中应该直接使用🤗Tokenizer库。
以下是由几句话构成的语料库:
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
然后我们执行上面所说的标准化和预分词过程:
for sentence in corpus:
sentence = sentence.lower()
print([c for c in jieba.cut(sentence) if c != " "])
['this', 'is', 'the', 'hugging', 'face', 'course', '.']
['this', 'chapter', 'is', 'about', 'tokenization', '.']
['this', 'section', 'shows', 'several', 'tokenizer', 'algorithms', '.']
['hopefully', ',', 'you', 'will', 'be', 'able', 'to', 'understand', 'how', 'they', 'are', 'trained', 'and', 'generate', 'tokens', '.']
为了简单起见,我们可以直接用jieba对其进行分词,它能帮我们把单词和标点符号拆开,但是它会把空格也拆分出来,我们直接过滤掉空格。
有了这些结果,我们就可以统计每个单词出现的频次:
word_freqs = defaultdict(int)
for sentence in corpus:
sentence = sentence.lower()
words = [w for w in jieba.cut(sentence) if w != " "]
for word in words:
word_freqs[word] += 1
print(word_freqs)
defaultdict(<class 'int'>, {'this': 3, 'is': 2, 'the': 1, 'hugging': 1, 'face': 1, 'course': 1, '.': 4, 'chapter': 1, 'about': 1, 'tokenization': 1, 'section': 1, 'shows': 1, 'several': 1, 'tokenizer': 1, 'algorithms':
1, 'hopefully': 1, ',': 1, 'you': 1, 'will': 1, 'be': 1, 'able': 1, 'to': 1, 'understand': 1, 'how': 1, 'they': 1, 'are': 1, 'trained': 1, 'and': 1, 'generate': 1, 'tokens': 1})
下面我们将语料库中每个单词拆分成字符作为子词,构建初始子词词表:
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
print(alphabet)
[',', '.', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'v', 'w', 'y', 'z']
我们在词表中加入模型要使用的特殊标记,这里有<PAD>、<BOS>、<EOS>和<UNK>,分别表示填充、句子开头、句子结尾和未知词。
vocab = ["<PAD>", "<UNK>", "<BOS>", "<EOS>"] + alphabet.copy()
初始词表构建好了之后,我们将语料库中每个单词拆分成字符作为子词:
splits = {word: [c for c in word] for word in word_freqs.keys()}
pprint(splits)
{',': [','],
'.': ['.'],
'able': ['a', 'b', 'l', 'e'],
'about': ['a', 'b', 'o', 'u', 't'],
'algorithms': ['a', 'l', 'g', 'o', 'r', 'i', 't', 'h', 'm', 's'],
'and': ['a', 'n', 'd'],
'are': ['a', 'r', 'e'],
'be': ['b', 'e'],
'chapter': ['c', 'h', 'a', 'p', 't', 'e', 'r'],
'course': ['c', 'o', 'u', 'r', 's', 'e'],
'face': ['f', 'a', 'c', 'e'],
'generate': ['g', 'e', 'n', 'e', 'r', 'a', 't', 'e'],
'hopefully': ['h', 'o', 'p', 'e', 'f', 'u', 'l', 'l', 'y'],
'how': ['h', 'o', 'w'],
'hugging': ['h', 'u', 'g', 'g', 'i', 'n', 'g'],
'is': ['i', 's'],
'section': ['s', 'e', 'c', 't', 'i', 'o', 'n'],
'several': ['s', 'e', 'v', 'e', 'r', 'a', 'l'],
'shows': ['s', 'h', 'o', 'w', 's'],
'the': ['t', 'h', 'e'],
'they': ['t', 'h', 'e', 'y'],
'this': ['t', 'h', 'i', 's'],
'to': ['t', 'o'],
'tokenization': ['t', 'o', 'k', 'e', 'n', 'i', 'z', 'a', 't', 'i', 'o', 'n'],
'tokenizer': ['t', 'o', 'k', 'e', 'n', 'i', 'z', 'e', 'r'],
'tokens': ['t', 'o', 'k', 'e', 'n', 's'],
'trained': ['t', 'r', 'a', 'i', 'n', 'e', 'd'],
'understand': ['u', 'n', 'd', 'e', 'r', 's', 't', 'a', 'n', 'd'],
'will': ['w', 'i', 'l', 'l'],
'you': ['y', 'o', 'u']}
然后编写一个函数计算每个连续对的频次:
def compute_pair_freqs(splits):
pari_freqs = defaultdict(int)
for word, freq in word_freqs.items():
# word拆分后的列表
split = splits[word]
# 至少要有2个字符才能合并
if len(split) == 1:
continue
for i in range(len(split) - 1):
# word中连续的字符
pair = (split[i], split[i + 1])
# 累加其频次
pari_freqs[pair] += freq
return pari_freqs
pair_freqs = compute_pair_freqs(splits)
for i, key in enumerate(pair_freqs.keys()):
print(f"{key}: {pair_freqs[key]}")
if i >= 10:
break
('t', 'h'): 6
('h', 'i'): 3
('i', 's'): 5
('h', 'e'): 2
('h', 'u'): 1
('u', 'g'): 1
('g', 'g'): 1
('g', 'i'): 1
('i', 'n'): 2
('n', 'g'): 1
('f', 'a'): 1
并且我们查看10个对(未排序)的频次。
现在我们只需要一次遍历就能找到最高频次的对:
best_pair = None
max_freq = 0
for pair, freq in pair_freqs.items():
if max_freq < freq:
best_pair = pair
max_freq = freq
print(best_pair, max_freq)
('t', 'h') 6
所以第一个合并的是('t', 'h') -> 'th',然后将合并后的子词加入到子词词表,同时合并前的两个字符还在词表中,这样我们的词表扩展了一个标记:
# 学习到的第一条合并规则
merges = {("t", "h"): "th"}
# 加入到词表中
vocab.append("th")
然后别忘了,我们还要应用该合并规则到splits字典中,我们也可以编写一个函数来完成:
def merge_pair(a, b, splits):
# 合并split中所有的(a,b) -> ab
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
# 如果刚好是a和b
if split[i] == a and split[i + 1] == b:
# 合并
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
# 重新赋值给word
splits[word] = split
return splits
splits = merge_pair("t", "h", splits)
print(splits["they"])
['th', 'e', 'y']
此时我们就有遍历整个语料所需的全部必要实现,我们可以编写代码调用这些实现,先试试将目标词表大小设置为50:
merges = {}
vocab_size = 50
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits)
best_pair = None
max_freq = 0
for pair, freq in pair_freqs.items():
if max_freq < freq:
best_pair = pair
max_freq = freq
# 用*对best_pair元组进行解包
# 得到新的splits
splits = merge_pair(*best_pair, splits)
# 学习到的合并规则
merges[best_pair] = best_pair[0] + best_pair[1]
# 词表扩充
vocab.append(best_pair[0] + best_pair[1])
pprint(merges)
{('a', 'b'): 'ab',
('a', 't'): 'at',
('e', 'n'): 'en',
('e', 'r'): 'er',
('h', 'o'): 'ho',
('ho', 'w'): 'how',
('i', 'n'): 'in',
('i', 'o'): 'io',
('i', 's'): 'is',
('io', 'n'): 'ion',
('n', 'd'): 'nd',
('o', 'u'): 'ou',
('s', 'e'): 'se',
('t', 'h'): 'th',
('t', 'o'): 'to',
('th', 'e'): 'the',
('th', 'is'): 'this',
('to', 'k'): 'tok',
('tok', 'en'): 'token',
('token', 'i'): 'tokeni',
('tokeni', 'z'): 'tokeniz'}
我们学习了21个合并规则,初始词表大小为29(25个字母加上4个特殊标记)。
['<PAD>', '<UNK>', '<BOS>', '<EOS>', ',', '.', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'v', 'w', 'y', 'z', 'th', 'is', 'er', 'to', 'en', 'this', 'ou', 'se', 'tok', 'token', 'ho', 'nd', 'the', 'in', 'ab', 'tokeni', 'tokeniz', 'at', 'io', 'ion', 'how']
BPE分词最重要的合并规则已经学好了,那如何遇到新文本,要如何应用我们的BPE分词算法呢?
其实就是我们BPE分词算法的四个步骤,回顾一下:
- 标准化
- 预分词
- 单词拆分成字符
- 根据学习到的规则应用到这些拆分
def tokenize(text, merges):
# 1. 标准化和预分词
text = text.lower()
words = [w for w in jieba.cut(text) if w != " "]
# 2. 单词拆分成字符
splits = [[c for c in word] for word in words]
# 3. 根据学习到的规则应用到这些拆分
# 3.1 遍历所有的合并规则
for pair, merge in merges.items():
# 3.2 遍历所有的splits
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
# 应用合并结果
splits[idx] = split
# splits是包含列表的列表
# 返回一个包含所有子列表元素的新列表
return sum(splits, [])
print(tokenize("This is not a token.", merges))
['this', 'is', 'n', 'o', 't', 'a', 'token', '.']
这就是我们最终BPE算法对这行文本分词的结果。注意为了更容易理解,我们上面没有考虑在单词的最后加上</w>字符,我们这里封装的时候考虑进来,但</w>在我们的代码中会被当成多个字符:<、/、w和>,为了不对代码进行太多的修改,我们用特殊字符?来代表</w>。
最后用类封装所有操作:
class BPETokenizer:
def __init__(self, special_tokens=[]) -> None:
self.word_freqs = defaultdict(int)
self.merges = {}
self.token_to_id: dict[str, int] = {}
self.id_to_token: dict[int, str] = {}
if special_tokens is None:
special_tokens = []
special_tokens = [
"<PAD>",
"<UNK>",
"<BOS>",
"<EOS>",
"?", # stands for </w>
] + special_tokens
for token in special_tokens:
self._add_token(token)
def _add_token(self, token: str) -> None:
if token not in self.token_to_id:
idx = len(self.token_to_id)
self.token_to_id[token] = idx
self.id_to_token[idx] = token
@property
def vocab_size(self) -> int:
return len(self.token_to_id)
def _learn_vocab(self, corpus: list[str]) -> None:
for sentence in corpus:
sentence = sentence.lower()
words = [w + "?" for w in jieba.cut(sentence) if w != " "]
for word in words:
self.word_freqs[word] += 1
def _compute_pair_freqs(self, splits) -> dict[Tuple, int]:
pair_freqs = defaultdict(int)
for word, freq in self.word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
def _merge_pair(self, a: str, b: str, splits):
for word in self.word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
def _merge_vocab(self, vocab_size, splits):
merges = {}
while self.vocab_size < vocab_size:
pair_freqs = self._compute_pair_freqs(splits)
best_pair = None
max_freq = 0
for pair, freq in pair_freqs.items():
if max_freq < freq:
best_pair = pair
max_freq = freq
splits = self._merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
self._add_token(best_pair[0] + best_pair[1])
return merges
def train(self, corpus, vocab_size):
self._learn_vocab(corpus)
splits = {word: [c for c in word] for word in self.word_freqs.keys()}
for split in splits.values():
for c in split:
self._add_token(c)
self.merges = self._merge_vocab(vocab_size, splits)
def tokenize(self, text):
text = text.lower()
words = [w + "?" for w in jieba.cut(text) if w != " "]
splits = [[c for c in word] for word in words]
for pair, merge in self.merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
主要的修改点就是在预分词后每个单词后面增加了表示结尾的特殊字符?。
在_learn_vocab()方法中得到的word_freqs字典就变成了:
print(self.word_freqs)
defaultdict(<class 'int'>, {'this?': 3, 'is?': 2, 'the?': 1, 'hugging?': 1, 'face?': 1, 'course?': 1, '.?': 4, 'chapter?': 1, 'about?': 1, 'tokenization?': 1, 'section?': 1, 'shows?': 1, 'several?': 1, 'tokenizer?': 1, 'algorithms?': 1, 'hopefully?': 1, ',?': 1, 'you?': 1, 'will?': 1, 'be?': 1, 'able?': 1, 'to?': 1, 'understand?': 1, 'how?': 1, 'they?': 1, 'are?': 1, 'trained?': 1, 'and?': 1, 'generate?': 1, 'tokens?': 1})
还是像上面那样进行测试:
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
tokenizer = BPETokenizer()
tokenizer.train(corpus, 50)
print(tokenizer.tokenize("This is not a token."))
['this?', 'is?', 'n', 'o', 't', '?', 'a', '?', 'token', '?', '.?']
这样我们得到了子词词表,可以继续添加encode和decode方法,此时代码如下:
class BPETokenizer:
def __init__(self, special_tokens=[]) -> None:
self.word_freqs = defaultdict(int)
self.merges = {}
self.token_to_id: dict[str, int] = {}
self.id_to_token: dict[int, str] = {}
if special_tokens is None:
special_tokens = []
special_tokens = [
"<PAD>",
"<UNK>",
"<BOS>",
"<EOS>",
"?", # stands for </w>
] + special_tokens
for token in special_tokens:
self._add_token(token)
self.unk_token = "<UNK>"
self.unk_token_id = self.token_to_id.get(self.unk_token)
def _add_token(self, token: str) -> None:
if token not in self.token_to_id:
idx = len(self.token_to_id)
self.token_to_id[token] = idx
self.id_to_token[idx] = token
@property
def vocab_size(self) -> int:
return len(self.token_to_id)
def _learn_vocab(self, corpus: list[str]) -> None:
for sentence in corpus:
sentence = sentence.lower()
words = [w + "?" for w in jieba.cut(sentence) if w != " "]
for word in words:
self.word_freqs[word] += 1
def _compute_pair_freqs(self, splits) -> dict[Tuple, int]:
pair_freqs = defaultdict(int)
for word, freq in self.word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
def _merge_pair(self, a: str, b: str, splits):
for word in self.word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
def _merge_vocab(self, vocab_size, splits):
merges = {}
while self.vocab_size < vocab_size:
pair_freqs = self._compute_pair_freqs(splits)
best_pair = None
max_freq = 0
for pair, freq in pair_freqs.items():
if max_freq < freq:
best_pair = pair
max_freq = freq
splits = self._merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
self._add_token(best_pair[0] + best_pair[1])
return merges
def train(self, corpus, vocab_size):
self._learn_vocab(corpus)
splits = {word: [c for c in word] for word in self.word_freqs.keys()}
for split in splits.values():
for c in split:
self._add_token(c)
self.merges = self._merge_vocab(vocab_size, splits)
def tokenize(self, text):
text = text.lower()
words = [w + "?" for w in jieba.cut(text) if w != " "]
splits = [[c for c in word] for word in words]
for pair, merge in self.merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
def _convert_token_to_id(self, token: str) -> int:
return self.token_to_id.get(token, self.unk_token_id)
def _convert_id_to_token(self, index: int) -> str:
return self.id_to_token.get(index, self.unk_token)
def _convert_ids_to_tokens(self, token_ids: list[int]) -> list[str]:
return [self._convert_id_to_token(index) for index in token_ids]
def _convert_tokens_to_ids(self, tokens: list[str]) -> list[int]:
return [self._convert_token_to_id(token) for token in tokens]
def encode(self, text: str) -> list[int]:
tokens = self.tokenize(text)
return self._convert_tokens_to_ids(tokens)
def clean_up_tokenization(self, out_string: str) -> str:
out_string = (
out_string.replace("?", " ")
.replace(" .", ".")
.replace(" ?", "?")
.replace(" !", "!")
.replace(" ,", ",")
.replace(" ' ", "'")
.replace(" n't", "n't")
.replace(" 'm", "'m")
.replace(" 's", "'s")
.replace(" 've", "'ve")
.replace(" 're", "'re")
)
return out_string
def decode(self, token_ids: list[int]) -> str:
tokens = self._convert_ids_to_tokens(token_ids)
return self.clean_up_tokenization("".join(tokens))
接着之前的测试:
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
tokenizer = BPETokenizer()
tokenizer.train(corpus, 50)
# ['this?', 'is?', 'n', 'o', 't', '?', 'a', '?', 'token', '?', '.?']
print(tokenizer.tokenize("This is not a token."))
# 50
print(tokenizer.vocab_size)
token_ids = tokenizer.encode("This is not a token.")
# [38, 33, 12, 16, 5, 4, 14, 4, 41, 4, 35]
print(token_ids)
# this is not a token.
print(tokenizer.decode(token_ids))
['this?', 'is?', 'n', 'o', 't', '?', 'a', '?', 'token', '?', '.?']
50
[38, 33, 12, 16, 5, 4, 14, 4, 41, 4, 35]
this is not a token.
通过clean_up_tokenization()方法处理空格替换以及最后一个标点符号后有额外空格的问题。
SentencePiece
上面自己实现的BPE仅适用于学习,但实际使用起来分词非常慢。
我们这里使用sentencepiece工具进行BPE分词,它底层基于C++实现,速度非常快。同时支持批数据处理。
import json
import sentencepiece as spm
from concurrent.futures import ProcessPoolExecutor
import os
from utils import convert_to_zh, make_dirs
from config import train_args, model_args
def get_wmt_pairs(data_dir: str, splits=["train", "dev", "test"]):
chinese_sentences = []
english_sentences = []
"""
json content:
[["english sentence", "中文语句"], ["english sentence", "中文语句"]]
"""
for split in splits:
with open(f"{data_dir}/{split}.json", "r", encoding="utf-8") as f:
data = json.load(f)
for pair in data:
english_sentences.append(pair[0] + "\n")
chinese_sentences.append(pair[1] + "\n")
assert len(chinese_sentences) == len(english_sentences)
print(f"the total number of sentences: {len(chinese_sentences)}")
return chinese_sentences, english_sentences
def get_en_cn_pairs(data_dir: str, splits=["train", "dev", "test"]):
chinese_sentences = []
english_sentences = []
"""
txt content:
english sentence\t繁体中文语句
english sentence\t繁体中文语句
"""
for split in splits:
with open(f"{data_dir}/{split}.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
if line:
pair = line.strip().split("\t")
english_sentences.append(pair[0])
chinese_sentences.append(convert_to_zh(pair[1]))
assert len(chinese_sentences) == len(english_sentences)
print(f"the total number of sentences: {len(chinese_sentences)}")
return chinese_sentences, english_sentences
def train_sentencepice_bpe(input_file: str, model_prefix: str, vocab_size: int, character_coverage: float = 0.9995, pad_id:int =0, unk_id:int=1, bos_id:int=2, eos_id:int=3):
cmd = f"--input={input_file} --model_prefix={model_prefix} --vocab_size={vocab_size} --model_type=bpe --character_coverage={character_coverage} --pad_id={pad_id} --unk_id={unk_id} --bos_id={bos_id} --eos_id={eos_id}"
spm.SentencePieceTrainer.train(cmd)
def train_tokenizer(
source_corpus_path: str,
target_corpus_path: str,
source_vocab_size: int,
target_vocab_size: int,
source_character_coverage:float = 1.0,
target_character_coverage:float = 0.9995
) -> None:
with ProcessPoolExecutor() as executor:
futures = [
executor.submit(
train_sentencepice_bpe,
source_corpus_path,
"source",
source_vocab_size,
source_character_coverage
),
executor.submit(
train_sentencepice_bpe,
target_corpus_path,
"target",
target_vocab_size,
target_character_coverage
),
]
for future in futures:
future.result()
sp = spm.SentencePieceProcessor()
source_text = """
Tesla is recalling nearly all 2 million of its cars on US roads to limit the use of its
Autopilot feature following a two-year probe by US safety regulators of roughly 1,000 crashes
in which the feature was engaged. The limitations on Autopilot serve as a blow to Tesla’s efforts
to market its vehicles to buyers willing to pay extra to have their cars do the driving for them.
"""
sp.Load("./source.model")
print(sp.encode_as_pieces(source_text))
ids = sp.encode_as_ids(source_text)
print(ids)
print(sp.decode_ids(ids))
target_text = """
今晨(12月14日),中央气象台继续发布寒潮黄色预警、大风蓝色预警、暴雪黄色预警和冰冻黄色预警,
中东部的大范围雨雪降温天气仍在持续进行中,公众需关注预报预警信息,做好保暖御寒和除雪工作,
外出需警惕路面湿滑、道路结冰等带来的不利影响,注意出行安全。
"""
sp.Load("./target.model")
print(sp.encode_as_pieces(target_text))
ids = sp.encode_as_ids(target_text)
print(ids)
print(sp.decode_ids(ids))
if __name__ == "__main__":
make_dirs(train_args.save_dir)
chinese_sentences, english_sentences = get_wmt_pairs(
data_dir=train_args.dataset_path, splits=["train", "dev", "test"]
)
with open(f"{train_args.dataset_path}/corpus.ch", "w") as f:
f.writelines(chinese_sentences)
with open(f"{train_args.dataset_path}/corpus.en", "w") as f:
f.writelines(english_sentences)
train_tokenizer(
f"{train_args.dataset_path}/corpus.en",
f"{train_args.dataset_path}/corpus.ch",
source_vocab_size=model_args.source_vocab_size,
target_vocab_size=model_args.target_vocab_size
)
这里针对WMT中英数据集训练分词器,这样就可以得到训练好的分词器。训练完毕后将分词器移到指定的目录。
想了解更多建议参考官方文档。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!