【UnityShader入门精要学习笔记】(1)了解渲染流水线

本系列为作者学习UnityShader入门精要而作的笔记,内容将包括:
- 书本中句子照抄 + 个人批注
- 项目源码
- 一堆新手会犯的错误
- 潜在的太监断更,有始无终
总之适用于同样开始学习Shader的同学们进行有取舍的参考。
渲染流水线
什么是流水线
什么是流水线?书中举了一个生产洋娃娃的例子。一个洋娃娃的生成过程可以被分为4个步骤:
1. 制作躯干
2. 缝上眼睛和嘴巴
3. 添加头发
4. 最终包装
洋娃娃的制作经过了四道工序,如果每道工序耗时一小时。而一个工人想要生产一个洋娃娃则需要四个小时。资本家们想到了一个好方法,让每个专人负责一道工序,这样四个人四道工序,所有步骤就可以同时并行。假设工序1完成了洋娃娃A的躯干制作任务,那么他不需要等待洋娃娃A被最终包装就能直接进行下一个洋娃娃B的躯干制作任务了。
熟悉编程的小伙伴可能更了解它的另一个名字,就是PipeLine。例如很多程序都会封装一条Pipeline来自动化调用整条流水线。
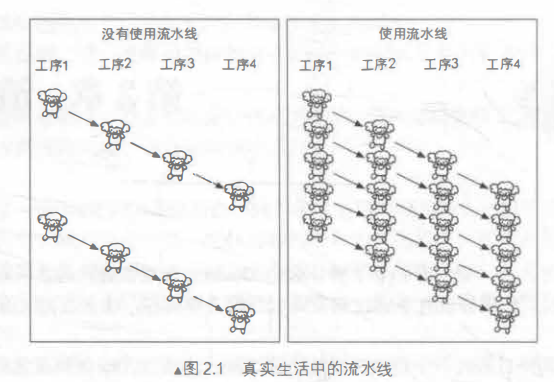
那么显然,一个洋娃娃生产所耗费的最大时间将由其中最耗时的工序来决定。在了解了流水线的概念之后,我们来看看什么是渲染流水线?
什么是渲染流水线
实际上,计算机的图像渲染也是流水线工作,它的任务是由一个3D场景出发,渲染成屏幕显示的2D图像。这个工作常常是由GPU和CPU共同完成的。
根据书中的介绍,我们将整个渲染流水线分为三个阶段,分别为:
- 应用阶段(Application Stage)
- 几何阶段(Geometry Stage)
- 光栅化阶段(Rasterizer Stage)

其中每个阶段内部也包含了一些子流水线阶段。
应用阶段
这个阶段是由我们的应用主导的,并通常由CPU负责实现。我们开发者具有这个阶段的绝对控制权。
在这个阶段,我们需要做的工作有:
- 首先准备好场景数据,包括摄像机,视锥体,场景中的模型和光源等等。
- 然后为了提高渲染性能,我们需要进行粗粒度剔除(Culling) 的工作,剔除不需要渲染的物体。
- 最后,我们还需要设置好每个模型的渲染状态,包括但不限于其材质(漫反射颜色,高光反射颜色贴图)、纹理、使用的Shader等。(恰好部分内容在之前写的光照渲染笔记中粗略学习了)
这一阶段最终的输出是渲染所需的几何信息,即渲染图元(Rendering Primitives) ,通俗来讲,渲染图元可以是点,线,三角面(3d图形学中的面都是三角面构成的),这些渲染图元最终会被传入到下一个阶段——几何阶段
几何阶段
几何阶段通常在GPU上进行,用于和每个渲染图元打交道,决定绘制什么图元,怎样绘制它们,在哪里绘制。
几何阶段会进行逐顶点,逐多边形的操作,当然内部可以分为更小的流水线阶段。几何阶段的一个重要任务就是把顶点坐标变换到屏幕空间中,再交给光栅器进行处理。通过对输入的渲染图元进行多步处理后,这一阶段将会输出屏幕空间的二维顶点坐标信息、每个顶点对应的深度值、着色器Shader等相关信息、并传递给下一个阶段。
光栅化阶段
这一阶段将会使用上个阶段传递的数据来产生屏幕上的像素,并渲染出最终的图像,这一阶段也是再GPU上运行的。光栅化的任务最终决定每个渲染图元中的哪些像素应该被绘制再屏幕上,它需要对上一个阶段得到的逐顶点数据(例如纹理坐标UV,顶点颜色等)进行插值,然后进行逐像素的处理。同样的,光栅化阶段也可以分成更小的流水线阶段。
犹记得n月前初学Unity刚看到这些知识,看的云里雾里。现在再看,能够理解其中的流程,真是收获良多。
原作者注:
要把上面的3个流水线阶段和我们将要讲到的 GPU 流水线阶段区分开来;这里的流水线均是概念流水线,是我们为了给一个渲染流程进行基本的功能划分而提出来的(也就是渲染图像的三个主要阶段)。下面要介绍的 GPU 流水线, 则是硬件真正用于实现上述概念的流水线(也就是GPU的工作流程)。
CPU和GPU的通信
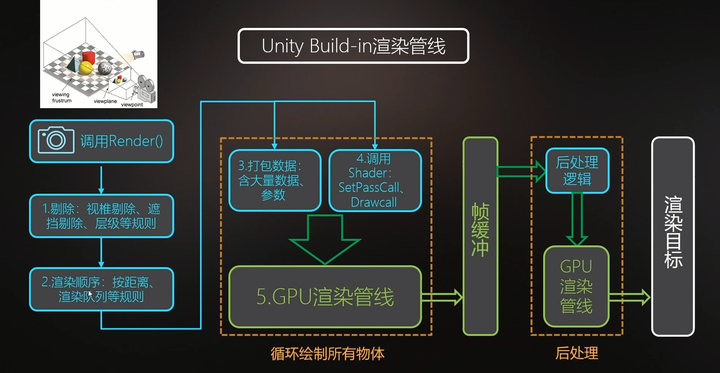
渲染流水线的起点是CPU,也就是之前提到的应用阶段。该阶段可大致分为下列3个阶段:
- 把数据加载到显存
- 设置渲染状态
- 调用Draw Call
把数据加载到显存
所有需要渲染的数据都是存储在硬盘(HDD)中的(例如模型的网格体,贴图纹理等数据),然后数据从硬盘被加载到系统缓存中(RAM),最终从系统缓存又被加载到显卡上的存储空间(Video RAM)。因为显卡对于RAM没有直接访问权限,而被加载到显卡的显存VRAM中则可以直接访问,并且显卡对于显存的访问速度显然更快。(为什么固态硬盘可以提高游戏渲染速度也是因为加快了数据从硬盘缓存到RAM的速度)
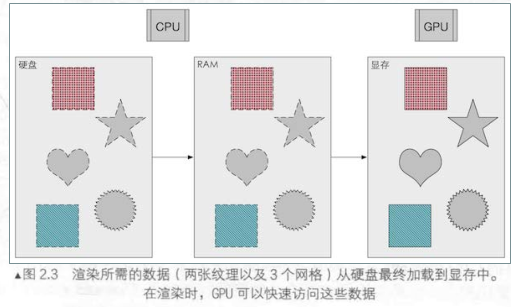
当然,真实加载到显存的数据要复杂得多,例如顶点位置信息,法线方向,顶点颜色,纹理坐标等等。
当数据被加载到显存后,显卡就可以访问了。那么RAM中的数据也可以被移除,不过某些数据依然需要CPU的访问(例如网格数据,我们需要CPU通过网格数据计算碰撞检测),那么这些数据是不会被移除的,因为数据从硬盘加载到RAM是十分耗时的。
此外,开发者还需要通过CPU设计渲染状态,来指导GPU的渲染工作。
设置渲染状态
渲染状态定义了场景中的网格是怎样被渲染的。例如使用哪些个顶点着色器(Vertex Shader)/片元着色器(Fragment Shader)、光源属性、材质等。这些都是我们可以在程序阶段进行自定义的:
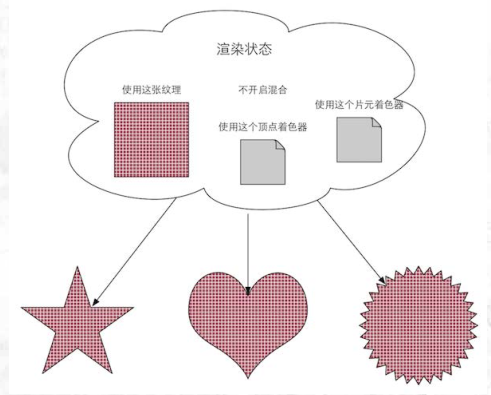
(上图显示了使用同一种材质在不同渲染状态设置下最终渲染出的三个网格)
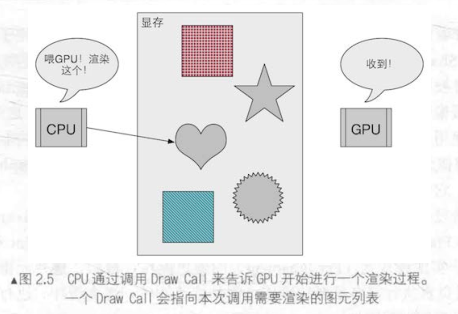
在准备好了上述工作后,CPU需要一个命令来通知GPU可以进行渲染了,这个渲染指令就是Draw Call
调用Draw Call
在Unity中渲染优化经常需要优化DrawCall ,那么Draw Call 到底是什么?实际上它就是一个调用命令,直译一下下,Draw(绘画)Call(指令)。就是CPU对GPU发起的调用指令。这个命令会指向一个需要被渲染的图元(primitives ,这个单词倒是挺常用,也可以指代操作系统中的原语)列表,而不包含任何材质信息——因为所有材质、纹理、着色器等数据信息都在上一步设置渲染状态时被打包好了,实际上DrawCall是图像编程的一个调用接口,是CPU与GPU间的一种通信,类似于CPU打电话通知GPU:“我这里用到什么,该怎么用都全部准备好了,目标是那个图元,剩下的你知道该怎么做。”
通过对原理的学习,我们发现即使是不同的教程,其内部知识也是融会贯通的,更方便我们多方考证。
那么调用了DrawCall之后,GPU就会根据CPU设定的渲染状态和所有输入的顶点数据来进行计算,最终输出成屏幕上显示的那些漂亮的像素,这个计算过程就是GPU流水线!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!