第6章:知识建模:概述、方法、实例
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

🍋知识建模概述
🍋知识建模的定义
知识建模是将领域内的知识、概念和关系转化为计算机可处理的形式的过程。它涉及到对现实世界的抽象和形式化,以便计算机能够理解、推理和处理这些知识。知识建模的目标是创建一个结构化的知识表示,以支持信息管理、知识发现、决策支持等应用。
通俗的讲,就是经过知识抽取、知识融合之后,本体和实体从数据源中被识别、抽取,并且经过消岐,统一处理后,此时得到的关联数据就是对客观事实的基本表达,但客观事实还不是知识图谱需要的知识体系,想要获得结构化的知识网络,还需要经过知识建模,知识推理,质量评估等知识加工的过程。
自顶向下(Top-Down)知识建模:

在自顶向下的知识建模中,建模的过程从高层次的抽象开始,然后逐步细化为更具体和详细的层次。这通常涉及到以下步骤:
需求分析: 识别并理解问题领域的需求,明确知识建模的目标和范围。
概念定义: 定义问题领域的核心概念和关系,形成高层次的抽象模型。
本体设计: 创建一个本体,其中包含领域的概念、属性和关系,以及它们之间的层次结构。
详细建模: 在本体的基础上,逐步添加更具体的实体、属性和关系,形成一个详细的知识模型。
验证和调整: 验证知识模型是否符合需求,进行必要的调整和优化。
自底向上(Bottom-Up)知识建模:
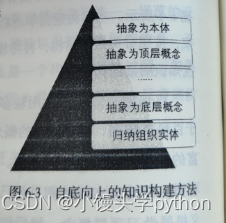
在自底向上的知识建模中,建模的过程从底层的实际数据和信息开始,然后逐步组织和抽象为更高层次的知识表示。关键步骤包括:
数据收集: 收集和整理领域内的实际数据、文档和信息。
模式识别: 识别数据中的模式、关联和重要特征。
概念提取: 从数据中提取概念、实体和关系。
关联建模: 建立实体之间的关联和关系模型。
抽象和一般化: 将底层的数据和关系抽象为更高层次、更一般化的知识表示。
验证和优化: 验证构建的知识模型是否准确,进行必要的优化。
共同点和差异:
共同点: 无论是自顶向下还是自底向上,都需要深入理解问题领域,创建结构化的知识表示,以便计算机能够有效地处理和利用知识。
差异: 自顶向下强调从高层次到低层次的逐步细化,而自底向上强调从底层数据到高层次的抽象和概念化。选择使用哪种方法通常取决于问题的性质、需求和可用的数据。
🍋知识建模的方法
🍋手工建模方法
手工建模指的是完全依托人工来对本体模式进行设计。
手工建模目前没有统一的标准,研究人员使用的方法包括Methontology、IDEF-5、TOVE、骨架法等,这里我们参照业界较为成熟的七步法进行介绍。
-
确定领域范围(Determine the Scope of the Domain):
在这一步,用户需要明确知识建模的领域范围。确定模型的范围有助于明确本体需要包含哪些实体、属性和关系。 -
确定类和子类(Identify Classes and Subclasses):
确定模型中的类和它们之间的层次结构。这一步涉及定义核心概念和它们的层次关系,即哪些类是其他类的子类。 -
确定属性(Identify Properties):
识别实体之间的关系,即属性。确定哪些属性是必要的,以及它们之间的关系。这一步有助于构建实体之间的连接。 -
确定实例(Identify Instances):
确定模型中的实例,即实际存在的个体。这一步有助于在模型中具体化概念,并为知识图谱增加具体的内容。 -
确定关系(Identify Relationships):
识别实体之间的关系,即哪些实体之间存在关联。确定关系有助于模型更好地捕捉现实世界中的连接性。 -
添加属性和关系的域与值(Specify Domains and Ranges for Properties):
为属性和关系明确定义域和值域。这一步有助于确保知识图谱的一致性和规范性。 -
创建实例(Create Instances):
在这一步,用户可以开始在知识图谱中创建实例,即根据先前确定的类、属性和关系为模型添加具体的数据。
🍋半自动建模方法
半自动建模方法先通过自动方式获取知识图谱,然后进行大量的人工干预。
半自动建模方法在知识建模的复杂任务中取得了良好的平衡,通过结合人的智慧和计算机的自动化能力,提高了建模效率和质量。这种方法通常适用于大规模的、复杂的领域,其中自动化工具能够处理大量数据,而领域专家的知识则是至关重要的。
🍋本体自动建模方法
数据驱动的本体自动建模方法主要可分为以下三步
实体并列关系相似度计算
在本体建模中,识别实体之间的相似性是一个关键任务。实体并列关系相似度计算的目标是度量实体之间的相似性,以便更好地组织它们在知识图谱中的关系。
方法:使用自然语言处理(NLP)技术,可以利用词向量模型或其他嵌入式表示方法来计算实体的语义相似度。这样的方法可以在不同实体之间建立相似性得分,从而有助于识别实体之间的并列关系。
实体上下位关系抽取
在本体中,实体之间的上下位关系(is-a关系)是构建层次结构的关键。自动抽取实体上下位关系的方法有助于建立本体的层次结构。
方法:使用自然语言处理技术和机器学习算法,可以从文本数据中抽取实体之间的上下位关系。例如,可以训练模型来识别"X是Y的一种"或"X属于Y"等语句,从而推断实体之间的上下位关系。这些关系的自动抽取可以减轻本体构建的工作负担。
本体生成
本体生成是将抽取到的知识组织为本体的最后一步。这包括将实体、属性、关系等元素组织成一个层次结构,并定义它们之间的语义关系。
方法:通过将上述得到的实体相似性和上下位关系整合到一个本体编辑工具或语言中,系统可以自动创建本体结构。例如,可以使用OWL(Web Ontology Language)来定义本体的类、属性和关系。在这一步中,可以考虑使用本体学习、图表示学习等方法,以自动发现和填充本体的潜在结构。
🍋知识建模实例—webprotege
webprotege在线网址,进入界面,使用邮箱可以免费注册,登录后在左上角选择新建项目,填写项目名、语言、项目描述。
点击create new project按钮后,就创建成功了,点击项目名进去即可
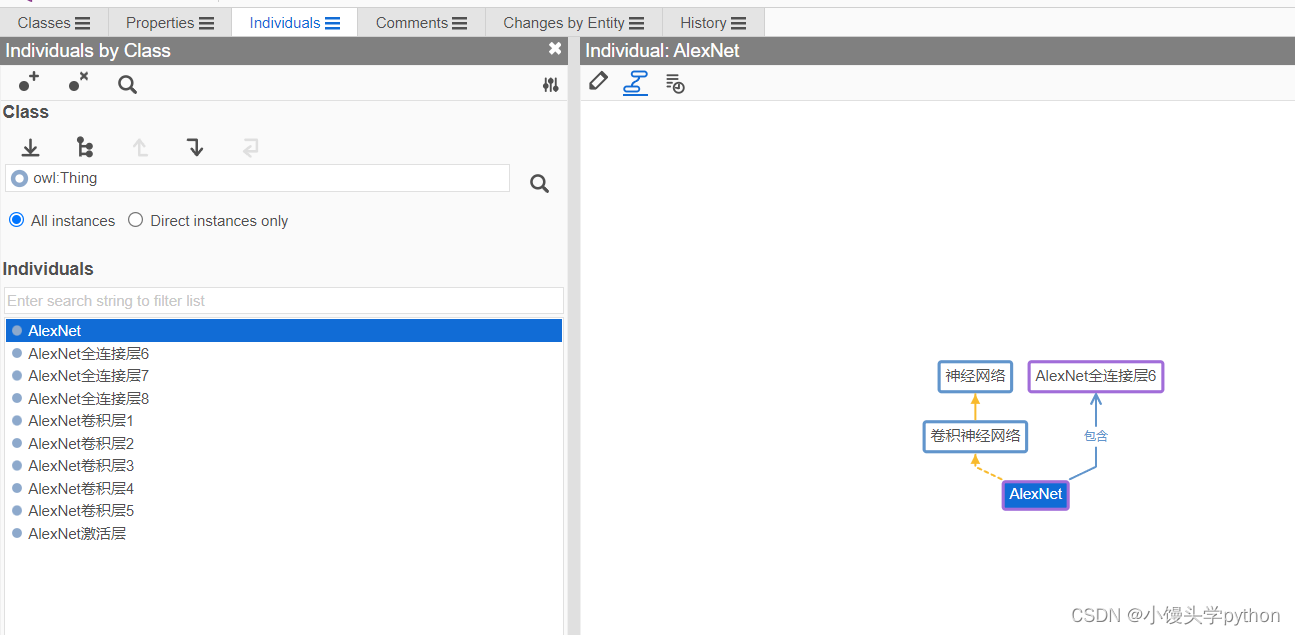
默认的初始打开位置是Classes界面,并预设了一个owl:Thing类,这个类是所有类的最高级,代表整个项目中最为广泛的类,在菜单栏中选择对Classes(类),Individual(实体)、Comments(批注)等进行选择修改。
以下是项目的完整类数据
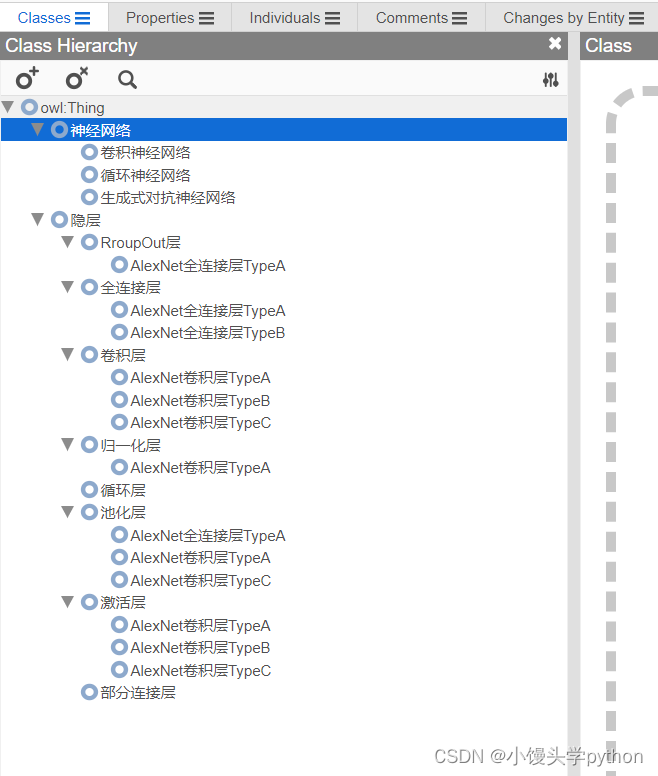
在实体里面可以关联不同的类,这里不做一一关联,知道怎么个事就行

挑战与创造都是很痛苦的,但是很充实。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!