深入学习Laravel缓存知识点(原理、策略及实例)
缓存对于实现高性能和可扩展性至关重要。从开发阶段就实施正确的缓存策略对于避免滞后的API和缓慢的页面加载时间至关重要。Laravel是最流行的PHP框架之一,因此实现最佳的Laravel缓存策略对于更好的用户体验和更大的业务影响是必不可少的。
在本文中,我们将探讨在Laravel中实现和操作缓存的策略。您将了解Laravel缓存的工作原理、几个Laravel缓存查询,以及如何处理Laravel应用程序上的缓存。
如果您已经掌握了以下方面的基本知识,您将从本文中获得更多信息:
- 良好的网络开发知识
- Laravel的基本理解
- 使用Laravel构建API
- 缓存的基本理解
本文将从五个方面全面介绍Laravel缓存相关知识内容,希望对您有一定的帮助!
为什么缓存很重要?
随着最近互联网业务的蓬勃发展,不同公司的统计数据显示网站加载时间和低性能如何在没有缓存的情况下严重影响SEO、用户参与度和对话率。这从一个出色的缓存策略开始。
一项在线研究发现,“1秒的加载延迟时间将使亚马逊每年损失16亿美元的销售额。”
谷歌的另一项研究报告称,“我们的研究表明,如果搜索结果慢了几分之一秒,人们的搜索就会减少(严重的是:400毫秒的延迟会导致搜索量下降0.44%)。这种不耐烦不仅限于搜索:如果视频在加载时停顿,五分之四的互联网用户会点击离开。”
您的网页加载时间稍有迟缓可能会对您的用户体验产生巨大影响并导致资金损失。
什么是Laravel缓存?
Laravel提供了一个健壮且易于使用的缓存和不同缓存后端的实现。使用Laravel缓存,您无需编写任何代码即可在多个缓存引擎之间高效切换。
您可以在config/cache.php文件夹中找到Laravel缓存的配置,但您可能只需要.env文件即可在不同的缓存后端之间切换。
Laravel缓存还提供了许多实用的方法,我们可以使用它们来实现不同的缓存策略。
缓存驱动程序和比较
Laravel缓存提供了很棒的缓存后端和驱动程序。根据您的用例,您可以在它们之间切换以提高应用程序性能和加载时间。
也就是说,Laravel缓存还提供了一种无缝方式来创建自定义后端并将其与Laravel缓存一起使用,但前提是下面的列表不适合您的用例。
接下来我们将讨论Laravel缓存提供的所有后端列表。
1.文件
当.env文件中没有指定驱动程序时,文件驱动程序是Laravel缓存使用的默认后端。
文件后端被设计为高速缓存的数据存储在下找到的加密文件storage/framework/。当缓存新数据时,Laravel会使用数据和缓存密钥创建一个加密文件。当用户尝试检索内容时也会发生同样的情况。Laravel缓存在文件夹中搜索指定的键,如果找到,则返回内容。
虽然文件后端工作完美,节省了安装和配置外部驱动程序的时间,但它也非常适合开发。它比直接从数据库服务器访问数据要快。
要使用文件驱动程序,请将以下代码添加到.env文件中:
CACHE_DRIVER=file
2. 数组
数组驱动器是用于运行自动化测试完美缓存后端并与Github上操作,詹金斯等容易地构成
数组后端存储在PHP中的数组缓存的数据,并且不需要你安装或配置任何驱动程序。它非常适合自动化测试,并且比文件缓存后端快一点。
要使用数组驱动程序,请将以下代码添加到.env文件中:
CACHE_DRIVER=array
3. 数据库
使用数据库驱动程序时,数据存储在当前PHP进程的内存中。因此,您需要创建一个数据库表来存储缓存的数据。此外,数据库缓存通过将查询工作负载从后端分配到多个前端来提高可伸缩性。
您可以运行这个Artisan命令——php artisan cache:table自动生成数据库驱动程序所需的数据库模式。
数据库驱动程序主要用于情况下您可以在主机平台上安装任何软件。
例如,假设您使用的是选项有限的免费托管计划。为此,我们建议坚持使用文件驱动程序,因为在大多数情况下,数据库驱动程序是应用程序的最薄弱点,并且试图将更多数据推入该瓶颈并不是一个好主意。
要使用数据库驱动程序,请将以下代码添加到.env文件中:
CACHE_DRIVER=database
4. Redis
redis驱动程序使用内存为基础的缓存技术被称为Redis。尽管与上面讨论的其他缓存驱动程序相比它很快,但它需要安装和配置外部技术。
要使用redis驱动程序,请将以下代码添加到.env文件中:
CACHE_DRIVER=redis
5.?内存缓存
众所周知,Memcached是最流行的基于内存的缓存存储。如果你不介意一些额外的服务器维护(必须安装和维护额外的服务),基于内存的缓存驱动程序Memcached是不错的选择。
使用memcached驱动程序需要安装Memcached PECL包。
要使用memcached驱动程序,请将以下代码添加到.env文件中。
CACHE_DRIVER=memcached
要使用的最佳缓存驱动程序和缓存驱动程序的性能取决于您的项目用例和要检索的数据量。
缓存使用和方法
Laravel缓存提供了许多有价值的方法用于实现许多缓存策略。下面我们将列出并解释不同的方法(按用例分类):
put()get()many()putMany()increment()decrement()forever()forget()flush()remember()rememberForever()
存储缓存
使用不同的方法在缓存中存储新数据非常简单,每种方法都有几个用例。
1. Cache::put()
该方法接受三个关键参数,?duration和要缓存的data。让我们来看看如何使用?Cache::put():
Cache::put(key, data, duration)
$post = Post::find(1);
Cache::put('post_1', $post, 20);上面的代码将使用唯一键缓存文字20秒。
2. Cache::putMany()
此方法以相同的持续时间在缓存中一次性存储一组数据。它接受两个参数,分别是data和seconds?。
让我们来看看如何使用Cache::putMany():
Cache::putMany(data, duration) // syntax
$posts = Post::all();
Cache::putMany($posts, 20);3. Cache::remember()
此方法是另一种实现缓存Aside策略的绝佳方法。这Cache::remember()方法接受三个参数,一个key?、?seconds和closure,用于在未找到时从数据库中检索数据。
让我们来看看如何使用Cache::remember()::
Cache::remember(key, duration, closure) // syntax
Cache::remember('posts', 20, function(){
return Post::all();
});Laravel缓存也有Cache::rememberForever()方法,它不接受seconds参数并永久存储数据。
4. Cache::forever()
此方法将数据永久存储在缓存服务器中,无需指定任何持续时间。您可以使用以下代码实现它:
Cache::forever(key, data)
$post = Post::find(1);
Cache::forever('post_1', $post);检索缓存数据
此类别中的方法从缓存中检索数据。根据是否找到数据,其中一些方法的行为可能有所不同。
1. Cache::get()
此方法使用特定键从缓存服务器检索数据。您可以使用以下代码检索项目:
Cache::get(key) // syntax
$posts = Cache::get('posts');2. Cache::many()
这种方法类似于Cache::putMany()。它用于使用缓存键数组一次检索缓存数据数组。您可以使用以下代码检索缓存数组:
Cache::many(keys) // syntax
const $keys = [
'posts',
'post_1',
'post_2'
];
$posts = Cache::many($keys);3. Cache::remember()
您还可以使用此方法通过使用提供的密钥检查缓存服务器来检索缓存数据。如果数据存储在缓存中,它将检索它。否则,它将从数据库服务器检索数据并将其缓存。此方法与Cache::rememberForever()方法中仅增加了一个额外的seconds参数的Cache::remember()方法相同。
从缓存中删除项目
此类别下的方法用于从缓存中删除项目,按功能分组。
1. Cache::forget()
此方法使用指定的键参数从缓存中删除单个项目:
Cache :: forget ( 'key' ) ;2. Cache::flush()
此方法清除所有缓存引擎。它删除存储在缓存中任意位置的所有项目:
Cache :: flush ( ) ;递增或递减缓存值
您可以分别使用increment和decrement方法调整存储在缓存中的整数值的值:
Cache::increment('key');
Cache::increment('key', $amount);
Cache::decrement('key');
Cache::decrement('key', $amount);Laravel缓存有很多我们上面没有讨论的很棒的方法,但是上面的方法很流行。?您可以在官方Laravel缓存文档中获得所有方法的概述。
缓存命令解释
Laravel提供了一些命令来让Laravel缓存的使用变得简单快捷。以下是所有命令及其功能的列表。
清除Laravel缓存
此命令用于在Laravel缓存过期之前使用终端/控制台清除它。例如,您可以运行以下命令:
php artisan cache:clear清除路由缓存
此命令用于清除Laravel应用程序的路由缓存。例如,运行以下命令来清除您的路由缓存:
php artisan config:cache清除编译的视图文件
此命令用于清除Laravel应用程序的编译视图文件。您可以使用以下命令实现它:
php artisan view : clear数据库表
使用数据库驱动时,需要创建一个名为cache的数据库模式来存储缓存数据。您还可以使用Artisan命令生成具有正确架构的迁移:
php artisan cache:tableLaravel缓存策略
根据您的应用程序用例和数据结构,您可能可以使用几种不同的缓存策略。您甚至可以创建自定义策略来满足您的需求。下面我们将介绍您可以在Laravel项目中实施的流行缓存策略列表。
writeThrough
在writeThrough策略中,缓存服务器位于请求和数据库服务器之间,使得每个写操作在进入数据库服务器之前都要经过缓存服务器。因此,writeThrough缓存策略类似于readThrough策略。
您可以使用以下代码使用Laravel缓存实现此策略:
public function writeThrough($key, $data, $minutes) {
$cacheData = Cache::put($key, $data, $minutes)
// Database Server is called from(after) the Cache Server.
$this->storeToDB($cachedData)
return $cacheData
}
private function storeToDB($data){
Database::create($data)
return true
}writeBack (writeBehind)
此策略是通过添加写入操作延迟来实现writeThrough策略的更高级方法。
您也可以将此称为writeBehind策略,因为在将数据写入数据库服务器之前应用于缓存服务器的时间延迟。
您可以使用以下代码使用Laravel缓存实现此策略:
$durationToFlush = 1; // (in minute)
$tempDataToFlush = [];
public function writeBack($key, $data, $minutes){
return $this->writeThrough($key, $data, $minutes);
}
public function writeThrough($key, $data, $minutes) {
$cacheData = Cache::put($key, $data, $minutes);
$this->storeForUpdates($cacheData);
return $cacheData;
}
// Stores new data to temp Array for updating
private function storeForUpdates($data){
$tempData = {};
$tempData['duration'] = this.getMinutesInMilli();
$tempData['data'] = data;
array_push($tempDataToFlush, data);
}
// Converts minutes to millisecond
private function getMinutesInMilli(){
$currentDate = now();
$futureDate = Carbon(Carbon::now()->timestamp + $this->durationToFlush * 60000)
return $futureDate->timestamp
}
// Calls to update the Database Server.
public function updateDatabaseServer(){
if($this->tempDataToFlush){
foreach($this->tempDataToFlush as $index => $obj){
if($obj->duration timestamp){
if(Database::create($obj->data)){
array_splice($this->tempDataToFlush, $index, 1);
}
}
}
}
}writeBack方法调用writeThrough方法,该方法将数据存储到缓存服务器和稍后使用updateDatabaseServer方法推送到数据库服务器的临时数组。您可以设置CronJob以每五分钟更新一次数据库服务器。
writeAround
此策略允许所有写入操作直接进入数据库服务器,而无需更新缓存服务器——仅在读取操作期间更新缓存服务器。假设用户想要创建一个新文章,文章直接存储到数据库服务器。当用户第一次想要阅读文章的内容时,文章会从数据库服务器中检索出来,并更新缓存服务器以供后续请求使用。您可以使用以下代码使用 Laravel 缓存实现此策略:
此策略允许所有write操作直接进入数据库服务器,而无需更新缓存服务器——仅在read操作期间更新缓存服务器。
假设用户想要创建一个新Article,Article直接存储到数据库服务器。当用户第一次想要阅读Article的内容时,Article会从数据库服务器中检索出来,并更新缓存服务器以供后续请求使用。
您可以使用以下代码使用Laravel缓存实现此策略:
public function writeAround($data) {
$storedData = Database::create($data);
return $storedData;
}
public function readOperation($key, $minutes){
$cacheData = Cache::remember($key, $minutes, function() {
return Article::all();
})
return $cacheData;
}缓存搁置(延迟加载)
在此策略中,数据库处于旁观状态,应用程序首先从缓存服务器请求数据。然后,如果命中(找到),则将数据返回给客户端。否则,如果有未命中(未找到),数据库服务器将请求数据并更新缓存服务器以用于后续请求。
您可以使用以下代码使用Laravel缓存实现此策略:
public function lazyLoadingStrategy($key, $minutes, $callback) {
if (Cache::has($key)) {
$data = Cache::get($key);
return $data;
} else {
// Database Server is called outside the Cache Server.
$data = $callback();
Cache::set($key, $data, $minutes);
return $data;
}
}上面的代码展示了cache Aside Strategy的实现,相当于实现了Cache::remember方法。
Read Through
此策略与缓存Aside策略直接相反。在这个策略中,缓存服务器位于客户端请求和数据库服务器之间。
请求直接发送到缓存服务器,如果在缓存服务器中没有找到,缓存服务器负责从数据库服务器检索数据。
您可以使用以下代码使用Laravel缓存实现此策略:
public function readThrough($key, $minutes) {
$data = Cache::find($key, $minutes);
return $data;
}
private function find($key, $minutes){
if(Cache::has($key);){
return Cache::get($key);
}
// Database Server is called from the Cache Server.
$DBdata = Database::find($key);
Cache:put($key, $DBdata, $minutes);
return $DBdata;
}有了它!我们现在已经为您的下一个Laravel应用程序讨论了一些流行的缓存策略。请记住,您甚至可以使用最适合您的项目要求的自定义缓存策略。
缓存Laravel应用程序的UI部分
缓存我们的Laravel应用程序的UI是一个称为全页面缓存FPC的概念。该术语指的是缓存来自应用程序的HTML响应的过程。
它非常适合动态HTML数据不经常更改的应用程序。您可以缓存HTML响应,以便更快地整体响应和呈现HTML。
我们可以使用以下代码行来实现FPC:
class ArticlesController extends Controller {
public function index() {
if ( Cache::has('articles_index') ) {
return Cache::get('articles_index');
} else {
$news = News::all();
$cachedData = view('articles.index')->with('articles', $news)->render();
Cache::put('articles_index', $cachedData);
return $cachedData;
}
}
}乍一看,您可能已经注意到,我们会检查该articles_index页面是否已存在于我们的缓存服务器中。然后我们通过使用Laravel的view()和render()方法渲染它来返回页面。否则,在将呈现的页面返回给浏览器之前,我们渲染页面并将输出存储在我们的缓存服务器中以用于后续请求。
构建一个Laravel应用
现在我们将通过创建一个新的 Laravel 项目并实现 Laravel 缓存来应用我们迄今为止学到的知识。
如果您还没有使用过Laravel,您可以先了解Laravel,并阅读优秀的Laravel教程再开始使用。
设置Laravel
首先,我们将使用以下命令创建一个新的Laravel实例。您可以查看官方文档了解更多信息。
在运行以下命令之前,打开您的控制台并导航到您存储PHP项目的位置。确保已正确安装和配置Composer。
composer create-project laravel/laravel fast-blog-app
// Change directory to current Laravel installation
cd fast-blog-app
// Start Laravel development server.
php artisan serve配置和填充数据库
接下来,我们将建立我们的数据库,创建一个新的文章模型,并填充500个假数据点进行测试。
打开您的数据库客户端并创建一个新数据库。我们将对名称fast_blog_app_db执行相同的操作,然后使用数据库凭据填充我们的.env文件:
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=fast_blog_app_db
DB_USERNAME=//DB USERNAME HERE
DB_PASSWORD=//DB PASSWORD HERE接下来,我们将运行以下命令来同时创建迁移和文章模型:
php artisan make:model Article -m打开新创建的迁移找到的database/migrations/xxx-create-articles-xxx.php?,粘贴如下代码:
<?php
use Illuminate\Support\Facades\Schema;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Database\Migrations\Migration;
class CreateArticlesTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('articles', function (Blueprint $table) {
$table->id();
$table->string('title');
$table->text('description');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('articles');
}
}接下来,运行下面的命令来创建一个新的seeder:
php artisan make:seeder ArticleSeeder在database/seeders/ArticleSeeder.php找到的新创建的seeder文件并粘贴以下代码:
<?php
namespace Database\Seeders;
use App\Models\Article;
use Illuminate\Database\Seeder;
class ArticleSeeder extends Seeder
{
/**
* Run the database seeds.
*
* @return void
*/
public function run()
{
Article::factory()->count(500)->create();
}
}打开同目录下的DatabaseSeeder.php文件,添加如下代码:
<?php
namespace Database\Seeders;
use Illuminate\Database\Seeder;
class DatabaseSeeder extends Seeder
{
/**
* Seed the application's database.
*
* @return void
*/
public function run()
{
$this->call(ArticleSeeder::class);
}
}接下来,运行以下命令来创建一个新factory:
php artisan make:factory ArticleFactory在database/factories/ArticleFactory.php找到并打开新建的factory文件,粘贴如下代码:
<?php
namespace Database\Factories;
use App\Models\Article;
use Illuminate\Database\Eloquent\Factories\Factory;
class ArticleFactory extends Factory
{
/**
* The name of the factory's corresponding model.
*
* @var string
*/
protected $model = Article::class;
/**
* Define the model's default state.
*
* @return array
*/
public function definition()
{
return [
'title' => $this->faker->text(),
'description' => $this->faker->paragraph(20)
];
}
}现在,运行下面的命令来迁移我们新创建的模式,并为我们的假数据做种子测试:
php artisan migrate --seed创建文章控制器
接下来,我们将创建我们的控制器并设置我们的路由来处理我们的请求并使用上述模型检索数据。
运行以下命令在app/Http/Controllers文件夹中创建一个新的ArticlesController:
php artisan make:controller ArticlesController --resource打开文件并将以下代码添加到类中:
// Returns all 500 articles with Caching
public function index() {
return Cache::remember('articles', 60, function () {
return Article::all();
});
}
// Returns all 500 without Caching
public function allWithoutCache() {
return Article::all();
}之后,在routes/文件夹中找到并打开api.php文件并粘贴以下代码以创建一个端点,我们可以调用它来检索我们的数据:
Route::get('/articles', 'ArticlesController@index');
Route::get('/articles/withoutcache', 'ArticlesController@allWithoutcache');测试性能
最后,我们将测试应用程序在是否使用 Laravel 缓存的情况下的响应性能。
这张截图显示了应用程序接口在使用缓存后的响应时间:
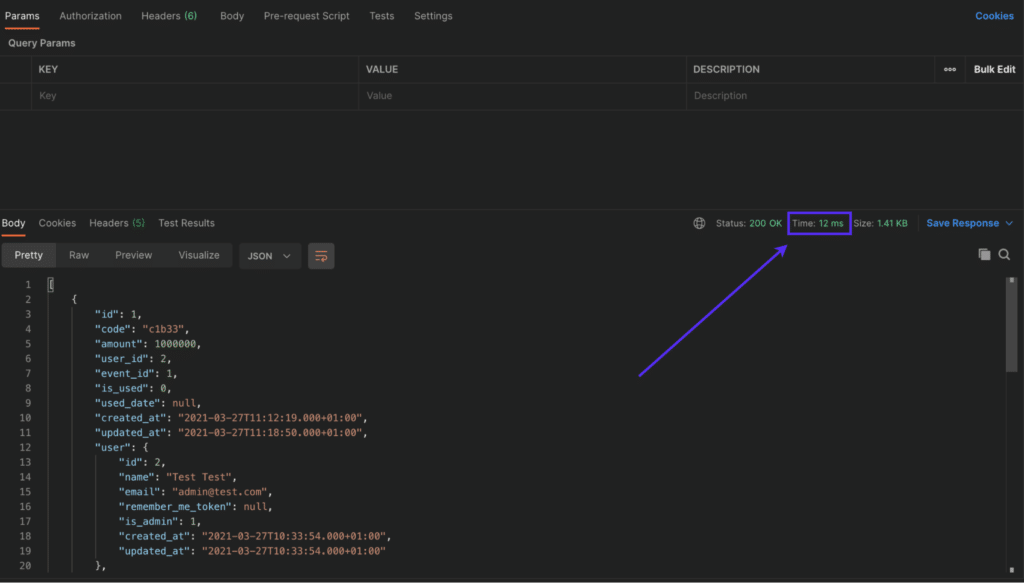
带缓存的Laravel API响应时间
以下屏幕截图显示了未实现缓存的API的响应时间 – 请注意,响应时间比缓存实例增加了5,000%以上:
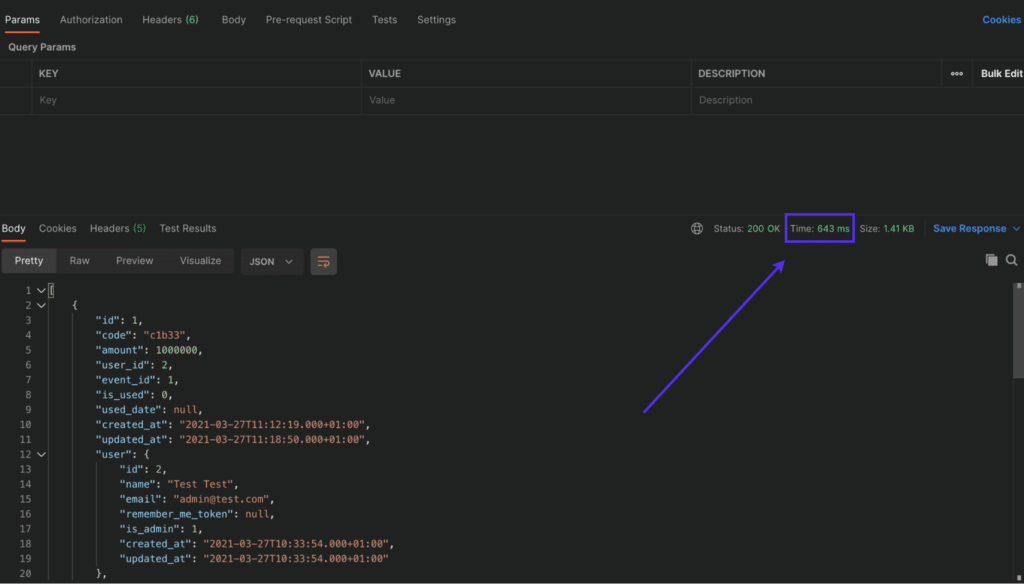
没有缓存的Laravel API响应时间
小结
我们通过构建一个新项目、对其响应进行基准测试并比较结果,探索了实施和操纵 Laravel 缓存的各种策略。
你还学会了如何使用不同的 Laravel 缓存驱动和方法。此外,我们还实施了不同的缓存策略,帮助你找出适合自己的缓存策略。
如需了解更多 Laravel 信息,请浏览我们精心挑选的最佳 Laravel 教程。无论你是初学者还是高级 Laravel 开发人员,这里都有适合每个人的内容!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!