ElasticSearch学习篇9_文本相似度计算方法现状以及基于改进的 Jaccard 算法代码实现
背景
XOP亿级别题库的试题召回以及搜题的举一反三业务场景都涉及使用文本相似搜索技术,学习此方面技术以便更好的服务于业务场景。
目前基于集合的Jaccard算法以及基于编辑距离的Levenshtein在计算文本相似度场景中有着各自的特点,为了优化具体的计算时间抖动超时问题,需要学习此方面知识,本文主要内容为文本相似度计算方法的现状、Jaccard、Levenshtein算法实现基本原理以及代码实现论文基于改进的 Jaccard 系数文档相似度计算方法的算法。
ps:你知道的越多,你不知道的也越多,搜索技术真是让人上头hhh
参考
- 基于改进的 Jaccard 系数文档相似度计算方法论文 http://www.c-s-a.org.cn/csa/article/pdf/6123
- 莱文斯坦距离概述以及DP实现https://www.zhihu.com/question/315634571/answer/620984468
- 文本相似度计算工具https://github.com/shibing624/similarity
- 什么是TD-IDFhttps://zh.wikipedia.org/wiki/Tf-idf
- 超级好懂的min-hash算法https://juejin.cn/post/7025522652898918414
目录
- 文本相似度计算方法的现状
- 向量空间模型
- KNN
- 编辑距离
- 集合相似度
- 基于改进的Jaccard系数文档原理与尝试代码实现
- 算法原理
- 本地代码实现demo
- 效果测试
1、文本相似度计算方法的现状
1.1、向量空间模型
传统的文本相似度计算方法一般采用向量空间模型[3] , 实际上就是将语义相似度用空间上的相似度来表 达, 对文本进行特征项选取后再对其做加权处理, 用向 量来表示特征项权重, 使这些特征项权重从离散的数 字转化为一个个带向量的分量, 于是文本的相似度计 算就转化成特征项权重在高维空间内的相似度计算[4] .
传统向量空间模型特点
- 这种计算方法简单直观,有效地将文本处理的问题转 化为数学问题.
- 但是在对特征项进行加权时向量空间 模型没有考虑到特征项在文本中的位置信息, 并且忽 略了各个特征项的语义在文本之间的关联性.也就是频率权重和位置权重。
举个例子,下面两个文本
- 文本1: “机器学习是人工智能领域中非常重要的一部分,它可以用于各种任务,包括图像识别和自然语言处理等。”
- 文本2: “计算机视觉是机器学习领域的一个研究方向,主要涉及图像处理和图像识别等技术应用。”
传统方法可能只考虑关键词的出现频率,并将这两篇文章当作包含如下关键词的向量进行比较:
- 关键词向量1:[机器学习, 人工智能, 图像识别, 自然语言处理]
- 关键词向量2:[计算机视觉, 机器学习, 图像处理, 图像识别]
如果我们使用传统方法,可能会直接比较这两个向量之间的相似度,例如通过计算余弦相似度来判断他们的相似程度。但是这样的方法没有考虑到特征项的频率权重和位置权重信息。
- 位置权重:为了解决传统方法的不足, 王小林[8]考虑到特征项在文本中的位置对权重的影响, 对特征项添加了位置权重, 进行信息增益和熵值计算, 虽然该算法在一定程度上提高了查全率和查准率, 但该算法的时间复杂度较高, 还需进一步改进才能运用在实际环境中
- 频率权重:周丽杰[9]将得到的特征项权值经过马尔科夫模型与向 量空间模型的结合, 得到一个总体相似度, 提高了准确 率, 忽略了关键词在不同文档中的权重问题
特征提取之嵌套词串
特征提取也很重要,需要注意特征提取算法中对嵌套词串处理避免丢失重要信息。
涂建军提出的特征提取算法通过对嵌套词串的处理有效地避免了在降维过程中丢失重要信息的问题。下面是一个例子来说明这个算法的作用:
(1)假设我们有一段文本:“这部电影真的非常好看,情节紧凑、剧情曲折扣人心弦。”
(2)传统的特征提取方法可能会直接将文本拆分成单个词语的集合,比如[“这部”, “电影”, “真的”, “非常”, “好看”,…]。然后可以使用词频或者TF-IDF等方式来表示每个词的重要性,并构建一个稀疏向量来表示整个文本。
(3)但是,在这种方法中,单个词语的顺序和组合并没有得到很好的保留。例如,上述文本中,“剧情曲折扣人心弦” 这个词串表达了电影的核心特点,但在传统方法中却被拆分为独立的单个词语。
(4)而涂建军所提出的特征提取算法则考虑到了嵌套词串,在处理文本时会以更长的片段作为特征单位。对于上述例子,该算法可以将文本分解为 [“这部电影”, “真的非常”, “好看情节”, “紧凑剧情”, “曲折扣人心弦”] 等嵌套词串。
这样一来,我们就能更好地捕捉到连续出现的相关词语以及它们之间的关系。在文本相似度计算或者其他自然语言处理任务中,这种特征提取方法可以更全面、准确地表达文本的含义和特征。
特征提取之n-gram
什么是n-gram:https://zhuanlan.zhihu.com/p/32829048
王贤明提出的基于 n-Gram 的相似度算法操作简单,避免了传统文本相似度计算方法中繁杂的特征提取过程,从而有效地提高了计算效率。然而,在计算权重的评价函数过程中,该算法采用了随机挑选元素的方法,导致元素权重的不确定性。
具体来说,该算法首先将文本进行分词处理,然后根据n-Gram模型生成特征项集合。例如,对于一个二元的2-Gram模型,可以得到所有由两个相邻词组成的特征项。接下来,通过计算每个特征项在文本中的频率,并结合一些其他因素(如长度惩罚),来计算特征项的权重。
1.2、KNN
上面两个方法则会对每个关键词进行加权,并考虑不同位置上的权重变化。因此,在计算文本相似度时,我们需要综合考虑关键词的权重、位置和波动等因素。虽然考虑了特征项的频率权重以及位置权重对相似性准确度有一定效果。但是还有那种文字特征联系弱,但是上下文有相关联系的场景处理不到,
1、举个例子,下面一个场景,例如,考虑一个搜索主题是"狗粮品牌推荐",另一个搜索主题是"如何训练小狗"。这两个主题在内容上可能没有明显的语义相似性,因为它们涉及到不同的方面:一个是关于狗粮的品牌推荐,另一个是关于狗的训练方法。然而,从实际生活经验中我们可以观察到,人们在选择狗粮之前通常会先了解如何正确地训练小狗。这意味着这两个主题之间存在某种相关性:人们在搜索狗粮品牌之前可能会搜索有关训练小狗的信息。
基于传统向量空间模型优化的方法,可以通过分析大量用户点击行为数据来发现这种潜在的相关性,并将其考虑在搜索结果的排名中。这样,即使两个主题的语义相似度较低,但由于它们之间可能存在隐含的相关关系,搜索引擎可以更好地理解用户的真实需求,并提供更准确、相关的搜索结果。
2、再举一个例子,对于何维的方法,他使用KNN算法来表示文本相似度,并将文本相似度用句子级别来表示。举个例子来说明这种方法可能更好理解。假设我们有两篇新闻文章A和B,它们分别是关于足球比赛的报道。我们要判断这两篇文章是否相似。
- 在传统的文本相似度计算方法中,我们通常会将文章A和文章B转换为向量表示(比如词袋模型),然后计算它们之间的余弦相似度或欧氏距离等指标来衡量它们的相似程度。但是这些方法无法考虑到文章中每个句子的重要性以及句子之间的关联。
- 而何维的方法则采用了不同的思路。首先,他将文章A和文章B拆解成多个句子,并计算每个句子之间的相似度。然后,通过KNN算法找出最相关的几个句子并计算它们的平均相似度作为整个文章的相似度。
例如,如果文章A包含以下三个句子:
- “昨天晚上巴塞罗那队与皇马队的足球比赛非常精彩。”
- “梅西在比赛中表现出色,打进了两个进球。”
- “皇马队则依靠贝尔的帽子戏法赢得了比赛。”
文章B包含以下三个句子:
- “切尔西队与曼联队的足球比赛在本周末进行。”
- “这场比赛吸引了众多球迷的关注。”
- “最终切尔西以2-1的比分战胜了曼联。”
通过计算每个句子之间的相似度,并使用KNN算法找出最相关的几个句子(比如选择前两个句子)来计算平均相似度。假设我们得到的结果是0.8,则可以认为文章A和文章B相似程度较高。
这种方法考虑了句子级别的相似度,能够更全面地表示文本之间的相似度,相比传统方法来说具有一定的优势。
传统的文本分类方法可能会将每个文档转换成由词频构成的向量,在高维空间中进行计算,然后使用某种机器学习算法训练分类模型。但是当邮件的数量非常庞大时,向量的维度也会变得非常高,并且随着邮件数量的增加,处理起来会越来越困难。
而K-nearest模型则采用了近邻思想,即将每个文档视为一个点在高维空间中的位置,通过寻找最近的K个文档来确定该文档的类别。在这个例子中,我们可以选取K=5,然后通过计算待分类文档与训练集中其他文档的相似度(比如使用余弦相似度),并选择最近的5个文档来判断其类别。
1.3、字符串编辑距离
一般的编辑距离实现算法如来温斯坦距离。算法详解与实现https://cloud.tencent.com/developer/article/1649884
// 一般的dfs
class Solution:
def minDistance(self, s: str, t: str) -> int:
n, m = len(s), len(t)
@cache
def dfs(i, j):
if i < 0: return j + 1
if j < 0: return i + 1
if s[i] == t[j]: return dfs(i - 1, j - 1)
return min(dfs(i - 1, j), dfs(i, j - 1), dfs(i - 1, j - 1)) + 1
return dfs(n - 1, m - 1)
// 二维DP
状态转移一,对字符串A插入操作,需要插入的值是B字符串的最后一个字母,所以问题变成了求“abcd”与“abcd”的编辑距离,现在最后一个字母相同,可以用之前得到的结论,继而问题成了求“abc”与“abc”的编辑距离。这样看来,其实是把最初的问题转移了:求“abc”与“abcd”编辑距离 = 求“abc”与“abc”的编辑距离 + 1。“+1”是因为我们对字符串A做了一个插入操作。
状态转移二,对字符串A删除操作。问题成了这样:求“abc”与“abcd”的编辑距离 = 求“ab”与“abcd”的编辑距离 + 1。
状态转移三,对字符串A替换操作。替换操作是比较隐晦的,不易看出来(对电脑而言),我们需要额外举例。现在字符串A = “abcd” 字符串B = “abce”,肉眼能够分辨,将字符串A最后一个字母“d”换成“e”,A就变成B了。可计算机没那么聪明,它需要一个字母一个字母的去比较。当同时去掉字符串A与字符串B的最后一个字母,如果剩下字符串相同,那么我们认为两个字符串之间的转换可以通过一个替换操作完成。
class Solution {
public int minDistance(String word1, String word2) {
int len1=word2.length();
int len2=word1.length();
int dp[][]=new int[len1+1][len2+1];
for(int i=1;i<=len1;i++) dp[i][0]=i;
for(int i=1;i<=len2;++i) dp[0][i]=i;
for(int i=1;i<=len1;i++){
for(int j=1;j<=len2;j++){
if(word2.charAt(i-1)!=word1.charAt(j-1)){
dp[i][j]=Math.min(dp[i-1][j-1],Math.min(dp[i-1][j],dp[i][j-1]))+1;
}else dp[i][j]=dp[i-1][j-1];
}
}
return dp[len1][len2];
}
}
// 一维DP,将空间复杂度从o(mn)压缩到o(min(m,n))
// 状态压缩
public class EditDistance {
public static int minDistance(String word1, String word2) {
// 获取字符串长度
int m = word1.length(); // abc
int n = word2.length(); // abcd
// 初始化一维DP数组
int[] dp = new int[n + 1];
// 初始化第一行,表示将空串转换成word2的前j个字符所需的操作次数
// word1 = "" 情况
for (int j = 0; j <= n; j++) {
dp[j] = j; // [0,1,2,3,4]
}
/**
* a b c
* a
* b
* c
* d
*
*/
// 迭代计算每一行的值
// 以上代码通过一个一维数组dp来保存每行的值,prev变量用于存储上一轮迭代的dp[j-1]的值。在每次更新dp[j]时,需要先将当前位置的值temp保存起来供下一轮使用。
for (int i = 1; i <= m; i++) {
int prev = dp[0]; // 对角线的值
dp[0] = i; // 本轮开始
for (int j = 1; j <= n; j++) {
int temp = dp[j];
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[j] = prev; // 字符相等,不需要进行操作
} else {
dp[j] = Math.min(prev, Math.min(dp[j], dp[j - 1])) + 1;
}
prev = temp;
}
}
return dp[n];
}
}
G Sidorov和贾惠娟则从不同的角度出发,分别探索了基于树编辑距离和结合特征词知识库的新颖计算方法,在实验中也取得了更好的结果。这些研究为我们在处理文本相似度问题时提供了更多有益的思路和工具。
基于编辑距离的基础, G Sidorov[6]提出使用 一种树编辑距离的算法来计算文本相似度, 实验结果 的准确率高于编辑距离.
贾惠娟[7]在有特征词知识库支 持的前提条件下, 提出将编辑距离与向量空间模型相 结合构建一种新的文本相似度计算模型, 虽然在数据 预处理的过程中可能会丢失一些文本特征项, 但是用 于领域文档查询也取得不错的效果.
树编辑距离以及与向量空间模型相结合,主要是提升相似准确性,举个例子
假设我们有两个句子:句子A是"我喜欢吃苹果",句子B是"我不喜欢吃橙子"。传统的编辑距离算法只考虑了单词之间的差异,它会将这两个句子视为完全不相似的。
但是,G Sidorov提出的树编辑距离算法可以更好地捕捉到结构上的相似性。通过将句子转化成语法树,并计算树之间的编辑距离,该算法能够发现句子A和句子B中都存在着"我喜欢吃"这样一个共同的片段,从而得出它们在某种程度上是相关的。
贾惠娟则进一步探索了将编辑距离与向量空间模型相结合来计算文本相似度。在她的方法中,首先使用编辑距离算法计算两个句子的相似度分数,然后再与特征词知识库中的权重进行加权。这样一来,不仅考虑了词汇层面的相似性,还充分利用了特征词的语义信息,使得相似度计算更准确。
1.4、集合相似度
一般的共同元素相似性计算实现方法如Jaccard系数。https://www.cnblogs.com/bourneli/archive/2013/04/04/2999767.html
Jaccard相似度是衡量两个集合之间相似性的一种常用方法,它利用集合中共同元素的数量来计算相似度。可以将其应用于文本相似度的计算。
举个例子,假设我们有两个句子:“我喜欢吃苹果"和"我爱吃水果”。通过将每个句子分词并构建词汇表,将每个句子表示为一个词语的集合:{我, 喜欢, 吃, 苹果}和{我, 爱, 吃, 水果}。
接下来,我们可以使用 Jaccard 相似度来计算这两个句子之间的相似度。具体而言,Jaccard 相似度计算公式如下:J(A, B) = |A ∩ B| / |A ∪ B|
- 其中,A 和 B 分别代表两个句子的词语集合,
- |A ∩ B| 表示 A 和 B 之间共同存在的词语数量
- |A ∪ B| 则表示 A 和 B 的总词语数量。
对于上述例子中的两个句子,共同存在的词语数量为3({我, 吃}),总词语数量为6。因此,它们之间的 Jaccard 相似度为 3/6 = 0.5。
通过计算 Jaccard 相似度,我们可以衡量文本之间的相似性,并用于文本聚类、社团发现等任务。这里提到的孙宇的研究使用 Jaccard 相似度实现了社团发现和聚类研究,通过计算文本集合之间的相似度来找出具有相似主题或内容的文本群体。
这种如果涉及语意层面相似度计算,那么计算的有可能不太准了,如下面demo,两句话语意计算的不准确,但是Jaccard计算的相似度为1.0
public static void main(String[] args) {
String s1 = "你好,你不是我的朋友";
String s2 = "你不好,我的朋友是你";
List<Integer> s1Chars = s1.chars().distinct().boxed().collect(Collectors.toList());
System.out.println("s1 元素ASCII集合:" + s1Chars);
List<Integer> s2Chars = s2.chars().distinct().boxed().collect(Collectors.toList());
System.out.println("s2 元素ASCII集合:" + s2Chars);
long sameChars = CollectionUtils.intersection(s1Chars, s2Chars).size();
double denominator = CollectionUtils.union(s1Chars, s2Chars).stream().distinct().count();
System.out.println("Jaccard 相似性系数为: " + sameChars / denominator); // 1.0
}
基于min-hash的进阶版Jaccard
min-hash算法就是一个在Jaccard距离基础之上进行改进,带有降维功能的进阶版Jaccard距离。如果两个集合的维度是成百万上千万的,那么比较适合,否则计算的相似度不准确。
尽管Jaccard距离本身是一个不复杂的概念,然而,随着集合的维度的增加,计算集合之间的Jaccard距离的计算成本也呈指数级增长,因此我们不得不思考一个问题:如何降低运算的复杂度?
2、基于改进的Jaccard原理与代码实现
针对传统方法的不足最简单粗暴的Jaccard算法的不足, 下面参考基于改进的 Jaccard 模型的计算方法提出的一种兼顾特征项权重与 计算效率的文本相似度计算方法, 用以获得更准确的 文本信息描述, 提高文本分类性能.本地尝试代码实现。
参考论文:基于改进的 Jaccard 系数文档相似度计算方法论文 http://www.c-s-a.org.cn/csa/article/pdf/6123
2.1、算法实现
算法公式
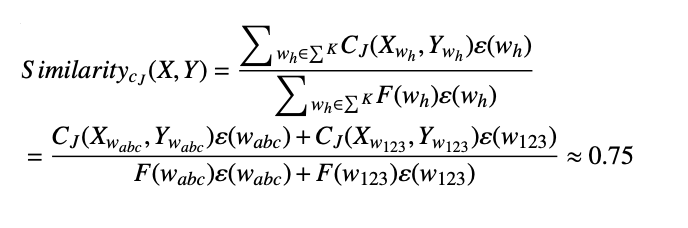
计算相似度,使用Jaccard相似系数算法。从字符串根据滑动窗口选取子串进行权重相似度计算,以下介绍本文方法的主要步骤:
- (1) 给定参数 K, K 为文档中移动窗口大小. 给定两个文档长度分别为 n1、n2 的文档 X 和文档 Y. 确定文档中长度为 K 的元素个数, 并计算每个元素在文档中所占的比重;
- (2) 计算每个元素的 Jaccard 相似度;
- (3) 计算每个元素在所有长度为 K 的元素中所占的比重;
- (4) 确定每个 K 字元素的权重;
- (5) 汇总所有 K 字元素相似度, 计算文档相似度
2.2、算法代码实现
/**
* 计算相似度,使用Jaccard相似系数算法。从字符串根据滑动窗口选取子串进行权重相似度计算
* 以下介绍本文方法的主要步骤:
* (1) 给定参数 K, K 为文档中移动窗口大小. 给定两个文档长度分别为 n1、n2 的文档 X 和文档 Y. 确定文档中长度为 K 的元素个数, 并计算每个元素在文档中所占的比重;
* (2) 计算每个元素的 Jaccard 相似度;
* (3) 计算每个元素在所有长度为 K 的元素中所占的比重;
* (4) 确定每个 K 字元素的权重;
* (5) 汇总所有 K 字元素相似度, 计算文档相似度
* @param left
* @param right
* @param denominatorPolicy
* @param windowLength 滑动窗口的大小
* @return
*/
private static double similarityByJaccardBySlidingWindow(String left, String right, JaccardDenominatorPolicy denominatorPolicy,int windowLength) {
// 检验窗口大小
int leftLen = StringUtils.length(left);
int rightLen = StringUtils.length(right);
int minLen = Math.min(leftLen, rightLen);
if(minLen < windowLength){
windowLength = minLen;
}
// 窗口元素个数
int leftElementLen = leftLen - windowLength + 1;
int rightElementLen = rightLen - windowLength + 1;
// 统计窗口元素出现的次数
Map<String,Double> leftWindowElementWeightMap = Maps.newHashMap();
Map<String,Double> rightWindowElementWeightMap = Maps.newHashMap();
for (int i = 0; i < leftElementLen; i++) {
String substring = left.substring(i, i + windowLength);
leftWindowElementWeightMap.put(substring,leftWindowElementWeightMap.getOrDefault(substring,0.0) + 1);
}
for (int i = 0; i < rightElementLen; i++) {
String substring = right.substring(i, i + windowLength);
rightWindowElementWeightMap.put(substring,rightWindowElementWeightMap.getOrDefault(substring,0.0) + 1);
}
// 计算窗口元素权重
Set<String> leftWindowElementSet = leftWindowElementWeightMap.keySet();
Set<String> rightWindowElementSet = rightWindowElementWeightMap.keySet();
for (String element : leftWindowElementSet) {
leftWindowElementWeightMap.put(element,leftWindowElementWeightMap.get(element) / leftElementLen);
}
for (String element : rightWindowElementSet) {
rightWindowElementWeightMap.put(element,rightWindowElementWeightMap.get(element) / rightElementLen);
}
// 存在两个集合的窗口元素
Collection<String> shareWindowElements = CollectionUtils.intersection(leftWindowElementSet, rightWindowElementSet);
// 计算同时存在两个集合的窗口元素的Jaccard系数 , 采用 min(weight) / max(weight)
Map<String,Double> shareWindowElementJaccardMap = new HashMap<>();
for (String element : shareWindowElements) {
Double leftWeight = leftWindowElementWeightMap.get(element);
Double rightWeight = rightWindowElementWeightMap.get(element);
shareWindowElementJaccardMap.put(element,leftWeight < rightWeight ? leftWeight / rightWeight : rightWeight / leftWeight);
}
// 计算同时存在两个集合的窗口元素的Weight系数 ,窗口元素出现的次数 / 全部窗口元素的个数
Map<String,Double> shareWindowElementWeightMap = new HashMap<>();
for (String element : shareWindowElements) {
double count = (leftWindowElementWeightMap.get(element) * leftElementLen) + (rightWindowElementWeightMap.get(element) * rightElementLen);
Double weight = count / (leftElementLen + rightElementLen);
shareWindowElementWeightMap.put(element,weight);
}
// 计算最后的结果
double molecular = 0.0;
double denominator = 1.0;
for (String element : shareWindowElements) {
molecular += shareWindowElementJaccardMap.get(element) * shareWindowElementWeightMap.get(element);
denominator += shareWindowElementWeightMap.get(element);
}
return molecular / denominator;
}
2.3、效果测评
论文推荐n-gram的n大小取7,在此基础上测试一些CASE
- 性能:目前少许CASE下,基本介于最简单粗暴的杰卡德和莱温斯坦之间
- 效果:目前少许CASE下,相似度准确度量还是可以的,相比莱文斯坦特征不那么生硬,相比最简单粗暴的杰卡德有有着结合特征权重、特征频率等相关相似性效果。
// TODO 待寻找特殊CASE评测
String[] searchTexts = {
"化学的研究对象是 A.物质 B物体 C.运动 D.实验",
"1.银是一种银白色金属,密度较大,具有良好的 导电性,长期放置会被氧化而发黑、其中属 于银的化学性质的是 () A.银白色 B.密度较大 C.导电性良好 D.能被氧化",
"6.非洲最高峰乞力马扎罗山是著名的“赤道雪山”,导致其顶部出现积雪的 因素是()。 A.纬度 B.海陆 C.地形 D.洋流",
"7. 复合题题干 (1)小问1 A. 选 4.项1 B. 选项2 C. 选项3 D. 选项4 (2)小问2 A. 选项1 B. 选项2 C. 选项3 D. 选项4",
"如图所示 一、”认真细致”填一填!(24分,每格1分。)1.在 $$1.4 \\dot{4}\\dot{5},1. \\dot{4}5,1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1.1.$$ 这四个数中,最大的数是(),最小的数是()2.根据356×24=8544,那么35.6×()-()×240=85.44。",
"1.计算下面各题. (1)27×11. (3)39×11. (5)92×11. (6)98×11.",
"—How many birds do you see? — A. I have 11. B. I'm 11. C. I see 11.",
"不等式 7?6x?x^2>0 的解集为( ) A. [?7,1] B. (?7,1) C. (?∞,?7]∪[1.+∞) D. (?∞,?7)∪(1.+∞)",
"zhaoquīlxiěchūshù&四、找规律写出数字。(16分)1.&4610142.510153045",
"1.给下列加点的字注音或根据拼音写汉字。, 阻碍() 堕落() jue ()择, jiao ()辩 强词夺理()",
"试题分析:本文叙述的是在上学时得知母亲去世的消息,我不断怀念母亲,认为他是我心中的英雄,是个伟大的人。 细节理解题。根据第一段When we returned to school,my teacher told me to go to the headmaster‘s office,当我们返回学校时,老师把我们叫到校长办公室。故得出C项。 细节理解题。根据第一段The police officer told me what had happened and we went to pick my sister up,警察告诉我发生的事,所以选D项。 细节理解题。根据第二段On the next day,the headmaster came and told my two teachers what had happened,第二天,校长过来告诉我的两个老师所发生的事 根据When my teacher took me outside,my sister ran up to me. She started crying,“She‘s gone. Teresa,mommy’s gone.得知母亲去世。故选B项。 细节推断题。根据最后一段When someone asks me who my hero is,I tell them,my mother. My mother lives every day. That is what makes her a true hero B项。 细节理解题。very good根据最后一段When someone asks me who my hero is,I tell them,my mother,母亲是个伟大的人,故选D项。",
"\"I love you\" might be one of the most important sentences in the English language. very good.It shows the closeness among family members and friends. In Mandarin, \"I love you\" translates as “我爱你”, but the way it's used in China might be a little different, and Chinese are wondering why. The Global Times reports that two online videos showing children telling their parents \"I love you\" have been widely spread in China. The first, filmed by an Anhui TV station, shows a number of college students telling their parents they love them. The answers are mixed. \"Are you drunk?\" asked one parent. In another similar video, a father even said— \"I am going to a meeting, so cut the crap.\" Even the positive attitudes make it clear that the words are expressed rarely. \"I am so happy you called to say that. It is the happiest thing that happened to me in 2014,\" one parent answered. However, Chinese families hardly use those words. \"The parents' answers show that many Chinese are not good at expressing positive feelings,\" Xia Xueluan, a Sociologist from Peking University, told the Global Times. \"They are used to educating children with negative language.\" This isn't the first time that China has done some soul-searching about familial love — last year China Daily asked a lot of people if they said 'I love you' to their parents, lovers, and children. \"I have never said 'I love you' to my family, and I don't think I will in the future,\" one 56-year-old told the paper, \"Saying it aloud is embarrassing for me.\" Still, that doesn't mean that love can't be expressed. In another article, China Daily spoke to Zhao Mengmeng, a 31-year-old woman who said she had never told her father she loved him face-to-face. Sometimes actions speak louder than words, however — Zhao gave her father, a photo album featuring photographs of them together on every one of her birthdays in June 2012. The pictures were popular online, being forwarded hundreds of thousands of times on Weibo. Her father was very excited when he heard about it. What does the underlined word Mandarin probably mean? French Japanese English Chinese What can we infer(推断) from the parents’ answers in Paragragh3 and 4? Some parents don’t love their children. Parents in China are too busy. Most Chinese students rarely express their positive feelings to their parents. Children in China are always taught negative language. What will that 56-year-old person feel if he/she says “I love you” to the families? embarrassed excited proud unhappy Why did Zhao give her father a photo album instead of saying \"I love you\"? The album is more expensive. His father likes the album better. She thinks actions speak louder than words sometimes. She hates saying \"I love you\" to her father. What’s the best title for the passage? I Love You A Photo Album Two Online Videos Family members",
"阅读下面短文, 完成短文后的问题。 In many English homes, people eat four meals a day. Breakfast is a very big meal. very good.It shows the closeness among family members and friends. People have eggs, tomatoes or bread and drink tea or coffee at breakfast. For many people, lunch is a quick meal. In sandwich bars, office workers can buy all kinds of salad sandwiches and bread. School children often have their meals at school, but many just take a sandwich, a drink and some fruit from home. Afternoon tea comes between lunch and evening meal. \"Tea\" means(意味着)two things. It is a drink and a meal. Some people have afternoon tea with sandwiches, cakes and a cup of tea. \"Dinner” is the main(主要的)meal of the day. They usually have the evening meal quite early, all the the family often eat together between six and eight. And they eat all kinds of things. First, they have soup, then they have meat, fish and vegetables. After that, they eat some fruit, like bananas, apples or oranges. Some people also eat ice-cream after dinner. How many meals do many English people have? What do English people have at breakfast ? Where do school children often have their lunch? Does \"afternoon tea\" only mean a drink? What do you think of \"Dinner\"? Why?",
"What do you think robots are able to do? You might be able to find one that fits your needs at the World Robot Conference (WRC) 2022 in Beijing. It was held from Aug 18 to 21, more than 500 robots were on display at the WRC. From human-like robots that look surprisingly lively to robots that can make jianbing 24 hours a day, this year’s WRC showed not only cutting-edge (尖端的) inventions, but also Chinese culture and youth power. A fruit-picking robot attracted visitors’ attention. With the help of different kinds of sensors (传感器) and an AI system, the robot can collect fruit according to its ripeness, quality and size. Wu Jiafeng, the exhibitor of the fruit-picking robot, told CCTV that more robotic technology will be used in agriculture (农业) in the future, including robots for daily inspection (巡检) and weeding (除草). Students from BDA School of the High School Affiliated to Renmin University of China (人大附中北京经济技术开发区学校) had their own exhibition at the WRC. Although they are young, the students brought fascinating inventions and ideas. For example, Wang Zirun, a junior student at the school, designed a three-dimensional parking facility (架空式立体停车机). Since there are usually too few parking spaces in older communities, Wang’s work aims to fit more cars into current parking spots. The facility works like a sky wheel with six parking spots. When cars need to be picked up, the facility rotates steadily, placing the car on the ground. How long did the World Robot Conference (WRC) 2022 last? 2 days 3 days 4 days 5 days Which kind of robot is mentioned in this passage? Human-like robots fruit-picking robots animal-like robots robots that can make jianbing What can help a fruit-picking robot work? Sensors AI systems ripeness A& B What is Wu Jiafeng? an exhibitior a visitor an inventor a designer Why did Wang Zirun design the three-dimensional parking facility? Because it is like a sky wheel with six parking spots. Because there are usually few parking spots in older communities. Because it can attract the visitors’ attention. Because it will be used in agriculture.",
"用所给词的适当形式填空。每词限用一次。 shut off support nod examine behave Mrs Brown when her students greeted her. The lights must when we leave the classroom. I believe John well next time. His parents many of his races since he became a runner on his school team. John what was wrong with his computer when I came back home.",
"危ない!その中に入る_。 なあ かな な ぞ",
"阅读下面的文字,完成下面小题。 材料一: 刘姥姥吃毕了饭,拉了板儿过来,舔舌咂嘴的道谢。凤姐笑道:“且请坐下,听我告诉你老人家。方才的意思,我已知道了。①若论亲戚之间,原该不等上门来就该有照应才是。但如今家内杂事太烦,太太渐上了年纪,一时想不到也是有的。况是我近来接着管些事,都不知道这些亲戚们。二则外头看着虽是烈烈轰轰的,殊不知大有大的艰难去处,说与人也未必信罢。今儿你既老远的来了,又是头一次见我张口,怎好叫你空回去呢。可巧昨儿太太给我的丫头们做衣裳的二十两银子,我还没动呢,你若不嫌少,就暂且先拿了去罢。” 那刘姥姥先听见告艰难,只当是没有,心里便突突的,后来听见给他二十两,喜的又浑身发痒起来,说道:“嗳,我也是知道艰难的。但俗语说的‘瘦死的骆驼比马大’,凭他怎样,你老拔根寒毛比我们的腰还粗呢!” 周瑞家的见他说的粗鄙,只管使眼色止他。凤姐看见,笑而不睬,只命平儿把昨儿那包银子拿来,再拿一吊钱来,都送到刘姥姥的跟前。凤姐乃道:“这是二十两银子,暂且给这孩子做件冬衣罢。若不拿着,就真是怪我了。这钱雇车坐罢。改日无事,只管来逛逛,方是亲戚们的意思。天也晚了,也不虚留你们了,到家里该问好的问个好儿罢。”一面说,一面就站了起来。 刘姥姥只管千恩万谢的,拿了银子钱,随了周瑞家的来至外面,仍从后门去了。 (选自《红楼梦》第六回,有删改) 材料二: ②那刘姥姥入了坐,拿起箸来,沉甸甸的不伏手。原是凤姐和鸳鸯商议定了,单拿一双老年四楞象牙镶金的筷子与刘姥姥。刘姥姥见了,说道:“这叉爬子比俺那里铁锹还沉,那里拿的动?”说的众人都笑起来。 只见一个媳妇端了一个盒子站在当地,一个丫鬟上来揭去盒盖,里面盛着两碗菜。李纨端了一碗放在贾母桌上。凤姐儿偏拣了一碗鸽子蛋,放在刘姥姥桌上。贾母这边说声“请”,刘姥姥便站起身来,高声说道:“老刘,老刘,食量大似牛,吃一个老母猪不抬头。”说着,却鼓着腮帮子,两眼直视,一声不语。众人先是发怔。后来一听,上上下下都哈哈大笑起来。湘云掌不住,一口饭都喷了出来;黛玉笑岔了气,伏着桌子只叫“嗳哟”;宝玉早滚到贾母怀里,贾母笑的搂着宝玉叫“心肝”;王夫人笑的用手指着凤姐儿,只说不出话来;薛姨妈也掌不住,口里的茶喷了探春一裙子;探春手里的饭碗都合在迎春身上;惜春离了坐位,拉着他奶母叫揉一揉肠子。地下的无一个不弯腰屈背。也有躲出去蹲着笑去的,也有忍着笑上来替他姊妹换衣裳的。独有凤姐、鸳鸯二人掌着,还只管让刘姥姥。刘姥姥拿起箸来,只觉不听使,又说道:“这里的鸡儿也俊,下的这蛋也小巧。怪俊的,我且抓得一个儿。” 众人方住了笑,听见这话,又笑起来。贾母笑的眼泪出来,琥珀在后捶着。贾母笑道:“这定是凤丫头促狭鬼儿闹的,快别信他的话了。”那刘姥姥正夸鸡蛋小巧,凤姐儿笑道:“一两银子一个呢,你快尝尝罢,冷了就不好吃了。”刘姥姥便伸箸子要夹,那里夹的起来,③满碗里闹了一阵,好容易撮起一个来,才伸着脖子要吃,偏又滑下来,滚在地下,忙放下箸子要亲自去捡,早有地下的人捡了出去了。刘姥姥叹道:“一两银子,也没听见响声儿就没了。”众人已没心吃饭,都看着他笑。 (选自《红楼梦》第四十回,有删改) 材料三: 只见平儿同刘姥姥带了一个小女孩儿进来,说:“我们姑奶奶在那里?”平儿引到炕边,刘姥姥便说:“请姑奶奶安。”凤姐睁眼一看,不觉一阵伤心,说:“姥姥你好?怎么这时候才来?你瞧你外孙女儿也长的这么大了。”刘姥姥看着凤姐骨瘦如柴,神情恍惚,心里也就悲惨起来,说:“我的奶奶,怎么这几个月不见,就病到这个分儿。我糊涂的要死,怎么不早来请姑奶奶的安!”便叫青儿给姑奶奶请安。青儿只是笑,凤姐看了倒也十分喜欢,便叫小红招呼着。 这里平儿恐刘姥姥话多,搅烦了凤姐,便拉了刘姥姥说:“你提起太太来,你还没有过去呢。我出去叫人带了你去见见,也不枉来这一趟。”刘姥姥便要走。凤姐道:“忙什么,你坐下,我问你近来的日子还过的么?”刘姥姥千恩万谢的说道:“我们若不仗着姑奶奶”,说着,指着青儿说:“他的老子娘都要饿死了。如今虽说是庄家人苦,家里也挣了好几亩地,又打了一眼井,种些菜蔬瓜果,一年卖的钱也不少,尽够他们嚼吃的了。这两年姑奶奶还时常给些衣服布匹,在我们村里算过得的了。阿弥陀佛,前日他老子进城,听见姑奶奶这里动了家,我就几乎唬杀了。亏得又有人说不是这里,我才放心。后来又听见说这里老爷升了,我又喜欢,就要来道喜,为的是满地的庄家来不得。昨日又听说老太太没有了,我在地里打豆子,听见了这话,唬得连豆子都拿不起来了,就在地里狠狠的哭了一大场。我和女婿说,我也顾不得你们了,不管真话谎话,我是要进城瞧瞧去的。④我女儿女婿也不是没良心的,听见了也哭了一回子,今儿天没亮就赶着我进城来了。我也不认得一个人,没有地方打听,一径来到后门,进了门找周嫂子,再找不着,撞见一个小姑娘,说周嫂子他得了不是了,撵了"
};
String[] stemTexts = {
"化学的研究对象是 A.物质 B物体 C.运动 D.实验",
"银是一种银白色金属,密度较大,具有良好的 导电性,长期放置会被氧化而发黑、其中属 于银的化学性质的是 () A.银白色 B.密度较大 C.导电性良好 D.能被氧化",
"非洲最高峰乞力马扎罗山是著名的“赤道雪山”,导致其顶部出现积雪的 因素是()。 A.纬度 B.海陆 C.地形 D.洋流",
" 复合题题干 (1)小问1 A. 选 4.项1 B. 选项2 C. 选项3 D. 选项4 (2)小问2 A. 选项1 B. 选项2 C. 选项3 D. 选项4",
"如图所示 一、”认真细致”填一填!(24分,每格1分。)1.在 $$1.4 \\dot{4}\\dot{5},1. \\dot{4}5,1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1. \\dot{5},1.1.$$ 这四个数中,最大的数是(),最小的数是()2.根据356×24=8544,那么35.6×()-()×240=85.44。",
"计算下面各题. (1)27×11. (3)39×11. (5)92×11. (6)98×11.",
"—How many birds do you see? — A. I have 11. B. I'm 11. C. I see 11.",
"不等式 7?6x?x^2>0 的解集为( ) A. [?7,1] B. (?7,1) C. (?∞,?7]∪[1.+∞) D. (?∞,?7)∪(1.+∞)",
"zhaoquīlxiěchūshù&四、找规律写出数字。(16分)1.&4610142.510153045",
"给下列加点的字注音或根据拼音写汉字。, 阻碍() 堕落() jue ()择, jiao ()辩 强词夺理()",
"试题分析:本文叙述的是在上学时得知母亲去世的消息,我不断怀念母亲,认为他是我心中的英雄,是个伟大的人。 细节理解题。根据第一段When we returned to school,my teacher told me to go to the headmaster‘s office,当我们返回学校时,老师把我们叫到校长办公室。故得出C项。 细节理解题。根据第一段The police officer told me what had happened and we went to pick my sister up,警察告诉我发生的事,所以选D项。 细节理解题。根据第二段On the next day,the headmaster came and told my two teachers what had happened,第二天,校长过来告诉我的两个老师所发生的事 根据When my teacher took me outside,my sister ran up to me. She started crying,“She‘s gone. Teresa,mommy’s gone.得知母亲去世。故选B项。 细节推断题。根据最后一段When someone asks me who my hero is,I tell them,my mother. My mother lives every day. That is what makes her a true hero B项。 细节理解题。根据最后一段When someone asks me who my hero is,I tell them,my mother,母亲是个伟大的人,故选D项。",
"\"I love you\" might be one of the most important sentences in the English language. It shows the closeness among family members and friends. In Mandarin, \"I love you\" translates as “我爱你”, but the way it's used in China might be a little different, and Chinese are wondering why. The Global Times reports that two online videos showing children telling their parents \"I love you\" have been widely spread in China. The first, filmed by an Anhui TV station, shows a number of college students telling their parents they love them. The answers are mixed. \"Are you drunk?\" asked one parent. In another similar video, a father even said— \"I am going to a meeting, so cut the crap.\" Even the positive attitudes make it clear that the words are expressed rarely. \"I am so happy you called to say that. It is the happiest thing that happened to me in 2014,\" one parent answered. However, Chinese families hardly use those words. \"The parents' answers show that many Chinese are not good at expressing positive feelings,\" Xia Xueluan, a Sociologist from Peking University, told the Global Times. \"They are used to educating children with negative language.\" This isn't the first time that China has done some soul-searching about familial love — last year China Daily asked a lot of people if they said 'I love you' to their parents, lovers, and children. \"I have never said 'I love you' to my family, and I don't think I will in the future,\" one 56-year-old told the paper, \"Saying it aloud is embarrassing for me.\" Still, that doesn't mean that love can't be expressed. In another article, China Daily spoke to Zhao Mengmeng, a 31-year-old woman who said she had never told her father she loved him face-to-face. Sometimes actions speak louder than words, however — Zhao gave her father, a photo album featuring photographs of them together on every one of her birthdays in June 2012. The pictures were popular online, being forwarded hundreds of thousands of times on Weibo. Her father was very excited when he heard about it. What does the underlined word Mandarin probably mean? French Japanese English Chinese What can we infer(推断) from the parents’ answers in Paragragh3 and 4? Some parents don’t love their children. Parents in China are too busy. Most Chinese students rarely express their positive feelings to their parents. Children in China are always taught negative language. What will that 56-year-old person feel if he/she says “I love you” to the families? embarrassed excited proud unhappy Why did Zhao give her father a photo album instead of saying \"I love you\"? The album is more expensive. His father likes the album better. She thinks actions speak louder than words sometimes. She hates saying \"I love you\" to her father. What’s the best title for the passage? I Love You A Photo Album Two Online Videos Family members",
"阅读下面短文, 完成短文后的问题。 In many English homes, people eat four meals a day. Breakfast is a very big meal. People have eggs, tomatoes or bread and drink tea or coffee at breakfast. For many people, lunch is a quick meal. In sandwich bars, office workers can buy all kinds of salad sandwiches and bread. School children often have their meals at school, but many just take a sandwich, a drink and some fruit from home. Afternoon tea comes between lunch and evening meal. \"Tea\" means(意味着)two things. It is a drink and a meal. Some people have afternoon tea with sandwiches, cakes and a cup of tea. \"Dinner” is the main(主要的)meal of the day. They usually have the evening meal quite early, all the the family often eat together between six and eight. And they eat all kinds of things. First, they have soup, then they have meat, fish and vegetables. After that, they eat some fruit, like bananas, apples or oranges. Some people also eat ice-cream after dinner. How many meals do many English people have? What do English people have at breakfast ? Where do school children often have their lunch? Does \"afternoon tea\" only mean a drink? What do you think of \"Dinner\"? Why?",
"What do you think robots are able to do? You might be able to find one that fits your needs at the World Robot Conference (WRC) 2022 in Beijing. It was held from Aug 18 to 21, more than 500 robots were on display at the WRC. From human-like robots that look surprisingly lively to robots that can make jianbing 24 hours a day, this year’s WRC showed not only cutting-edge (尖端的) inventions, but also Chinese culture and youth power. A fruit-picking robot attracted visitors’ attention. With the help of different kinds of sensors (传感器) and an AI system, the robot can collect fruit according to its ripeness, quality and size. Wu Jiafeng, the exhibitor of the fruit-picking robot, told CCTV that more robotic technology will be used in agriculture (农业) in the future, including robots for daily inspection (巡检) and weeding (除草). Students from BDA School of the High School Affiliated to Renmin University of China (人大附中北京经济技术开发区学校) had their own exhibition at the WRC. Although they are young, the students brought fascinating inventions and ideas. For example, Wang Zirun, a junior student at the school, designed a three-dimensional parking facility (架空式立体停车机). Since there are usually too few parking spaces in older communities, Wang’s work aims to fit more cars into current parking spots. The facility works like a sky wheel with six parking spots. When cars need to be picked up, the facility rotates steadily, placing the car on the ground. How long did the World Robot Conference (WRC) 2022 last? 2 days 3 days 4 days 5 days Which kind of robot is mentioned in this passage? Human-like robots fruit-picking robots animal-like robots robots that can make jianbing What can help a fruit-picking robot work? Sensors AI systems ripeness A& B What is Wu Jiafeng? an exhibitior a visitor an inventor a designer Why did Wang Zirun design the three-dimensional parking facility? Because it is like a sky wheel with six parking spots. Because there are usually few parking spots in older communities.Her father was very excited when he heard about it. Because it can attract the visitors’ attention. Because it will be used in agriculture.",
"如图所示 A.用所给动词的适当形式填空,每词限用一次.(10 分) shut, reflect, perform, stick, sense 1. Laura _that Bruce didn't believe her. 2.Don't worry. The gas in my house _off before I leave home. 3.Paul loves Africa. His music_ his interest in African culture. 4.I _to running since five years ago. 5. -I called you at eight last night, but you didn't answer my phone. _a wonderful play for my family. Which made them v",
"授業中は隣の人と話を( )。静かにしてください。 A. しなさい B. するな C. するなあ D. するぞ",
"三十一、阅读下文,回答问题。原是凤姐和鸳鸯商议定了,单拿一双老年四楞象牙镶金的筷子与刘姥姥。刘姥姥见了,说道:”这叉爬子比俺那里铁锨还沉,那里犟的过他。”说的众人都笑起来。只见一个媳妇端了一个盒子站在当地,一个丫鬟上来揭去盒盖,里面盛着两碗菜。李纨端了一碗放在贾母桌上。凤姐儿偏拣了一碗鸽子蛋放在刘姥姥桌上。贾母这边说声”请”,刘姥姥便站起身来,高声说道:”老刘,老刘,食量大似牛,吃一个老母猪不抬头。”自己却鼓着腮不语。众人先是发怔,后来一听,上上下下都哈哈的大笑起来。史湘云撑不住,一口饭都喷了出来;林黛玉笑岔了气,伏着桌子叫”嗳哟”;宝玉早滚到贾母怀里,贾母笑的搂着宝玉叫”心肝”;王夫人笑的用手指着凤姐儿,只说不出话来;薛姨妈也撑不住,口里茶喷了探春一裙子;探春手里的饭碗都合在迎春身上;惜春离了坐位,拉着他奶母叫揉一揉肠子。地下的无一个不弯腰屈背,也有躲出去蹲着笑去的,也有忍着笑上来替他姊妹换衣裳的,独有凤姐鸳鸯二人撑着,还只管让刘姥姥。刘姥姥拿起箸来,只觉不听使,又说道:”这里的鸡儿也俊,下的这蛋也小巧,怪俊的。我且攮一个。”众人方住了笑,听见这话又笑起来。贾母笑的眼泪出来,琥珀在后捶着。贾母笑道:”这定是凤丫头促狭鬼儿闹的,快别信他的话了。”那刘姥姥正夸鸡蛋小巧,要禽攮一个,凤姐儿笑道:”一两银子一个呢,你快尝尝罢,那冷了就不好吃了。”刘姥姥便伸箸子要夹,那里夹的起来,满碗里闹了一阵好的,好容易撮起一个来,才伸着脖子要吃,偏又滑下来滚在地下,忙放下箸子要亲自去捡,早有地下的人捡了出去了。刘姥姥叹道:”一两银子,也没听见响声儿就没了。'1.本语段节选自名著《红楼梦》,作者是_(朝代)的_(人名)。2.请用简洁的语言概括选文内容。3.结合选文内容分析刘姥姥形象。"
};
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 64毫秒, 文本长度: 27/27
计算试题相似度(莱温斯坦) 相似度: 100.0, 耗时: 3毫秒, 文本长度: 27/27
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 100.0, 耗时: 5毫秒, 文本长度: 27/27
计算试题相似度(杰卡德) 相似度: 97.67, 耗时: 1毫秒, 文本长度: 83/81
计算试题相似度(莱温斯坦) 相似度: 97.14, 耗时: 1毫秒, 文本长度: 83/81
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 96.88, 耗时: 1毫秒, 文本长度: 83/81
计算试题相似度(杰卡德) 相似度: 97.62, 耗时: 1毫秒, 文本长度: 61/59
计算试题相似度(莱温斯坦) 相似度: 96.0, 耗时: 0毫秒, 文本长度: 61/59
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 95.45, 耗时: 0毫秒, 文本长度: 61/59
计算试题相似度(杰卡德) 相似度: 94.44, 耗时: 1毫秒, 文本长度: 81/79
计算试题相似度(莱温斯坦) 相似度: 96.49, 耗时: 0毫秒, 文本长度: 81/79
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 96.08, 耗时: 1毫秒, 文本长度: 81/79
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 308/308
计算试题相似度(莱温斯坦) 相似度: 100.0, 耗时: 3毫秒, 文本长度: 308/308
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 308/308
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 49/47
计算试题相似度(莱温斯坦) 相似度: 94.59, 耗时: 0毫秒, 文本长度: 49/47
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 93.55, 耗时: 0毫秒, 文本长度: 49/47
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 67/67
计算试题相似度(莱温斯坦) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 67/67
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 67/67
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 78/78
计算试题相似度(莱温斯坦) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 78/78
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 78/78
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 53/53
计算试题相似度(莱温斯坦) 相似度: 100.0, 耗时: 0毫秒, 文本长度: 53/53
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 53/53
计算试题相似度(杰卡德) 相似度: 93.94, 耗时: 0毫秒, 文本长度: 56/54
计算试题相似度(莱温斯坦) 相似度: 94.44, 耗时: 0毫秒, 文本长度: 56/54
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 93.33, 耗时: 0毫秒, 文本长度: 56/54
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 2毫秒, 文本长度: 742/733
计算试题相似度(莱温斯坦) 相似度: 98.69, 耗时: 3毫秒, 文本长度: 742/733
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 98.26, 耗时: 2毫秒, 文本长度: 742/733
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 2841/2831
计算试题相似度(莱温斯坦) 相似度: 99.61, 耗时: 19毫秒, 文本长度: 2841/2831
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 99.61, 耗时: 6毫秒, 文本长度: 2841/2831
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 1228/1161
计算试题相似度(莱温斯坦) 相似度: 94.18, 耗时: 3毫秒, 文本长度: 1228/1161
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 94.15, 耗时: 1毫秒, 文本长度: 1228/1161
计算试题相似度(杰卡德) 相似度: 100.0, 耗时: 1毫秒, 文本长度: 2087/2138
计算试题相似度(莱温斯坦) 相似度: 97.59, 耗时: 10毫秒, 文本长度: 2087/2138
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 97.54, 耗时: 3毫秒, 文本长度: 2087/2138
计算试题相似度(杰卡德) 相似度: 66.67, 耗时: 1毫秒, 文本长度: 308/396
计算试题相似度(莱温斯坦) 相似度: 26.27, 耗时: 0毫秒, 文本长度: 308/396
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 79.35, 耗时: 1毫秒, 文本长度: 308/396
计算试题相似度(杰卡德) 相似度: 28.13, 耗时: 0毫秒, 文本长度: 22/54
计算试题相似度(莱温斯坦) 相似度: 14.63, 耗时: 0毫秒, 文本长度: 22/54
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 0.0, 耗时: 0毫秒, 文本长度: 22/54
计算试题相似度(杰卡德) 相似度: 47.45, 耗时: 1毫秒, 文本长度: 2000/743
计算试题相似度(莱温斯坦) 相似度: 32.59, 耗时: 4毫秒, 文本长度: 2000/743
计算试题相似度(基于n-gram改进的杰卡德) 相似度: 37.17, 耗时: 2毫秒, 文本长度: 2000/743
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!