AI绘画中采样器用于逐步去噪
介绍
Stable Diffusion 进行 AI 绘画,采样器存在的价值就是从噪声出发,逐步去噪,得到一张清晰的图像。
https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
以下是采样器在 Stable Diffusion 中的几个关键作用:
-
控制图像生成的随机性:采样器通过在生成过程中引入随机性,帮助模型创造出独特和多样化的图像。这种随机性是通过随机噪声向量来实现的,它决定了图像生成的初始状态。
-
迭代细化:Stable Diffusion 通常采用迭代的方式生成图像。采样器在每一步迭代中调整图像的细节,逐渐从初始的随机噪声状态转变为最终的清晰图像。
-
质量和风格控制:采样器可以根据预设的参数或用户的输入来调整生成图像的质量和风格。例如,用户可以指定希望图像更加清晰或模糊,或者偏向某种特定的艺术风格。
-
条件生成:在条件生成任务中,采样器利用用户提供的文本描述或其他形式的条件信息来引导图像生成的方向。这确保了生成的图像符合用户的要求。
-
优化性能:高效的采样器可以加快图像生成的速度,同时保持图像质量。这对于实时应用或资源受限的环境尤为重要。
原理
采样器和Unet都是Stable Diffusion中非常重要的组成部分,两者结合实现了图像的生成过程,可以简单理解如下:
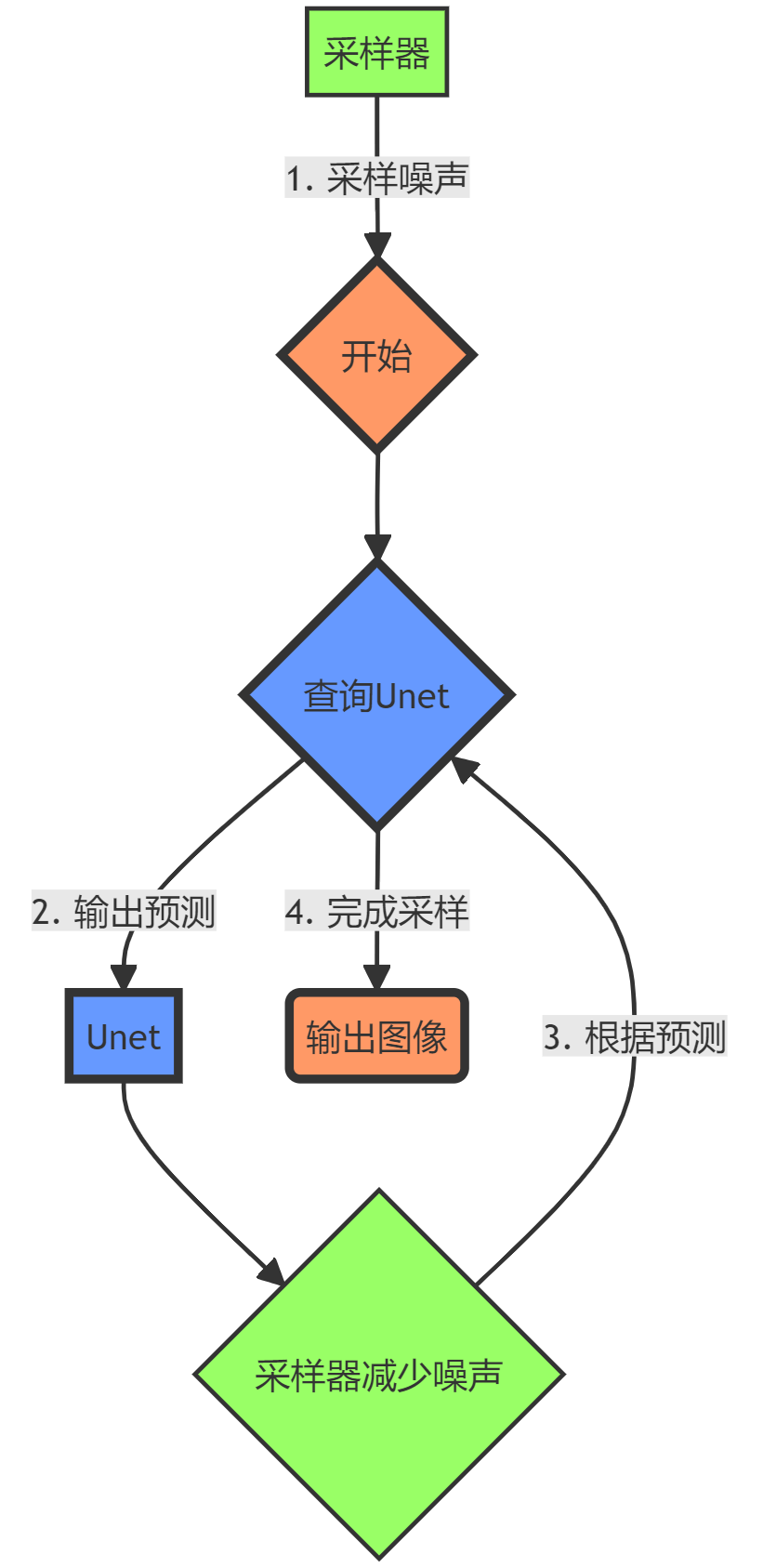
-
采样器根据Unet先验分布采样噪声数据作为输入
-
采样器查询Unet基于当前状态输出预测值
-
采样器根据预测结果减少噪声,采样更新状态
-
循环上述操作,直到完成图像采样过程
架构
在 Stable Diffusion 模型中,去噪 U-Net 是核心组件之一,它与采样器紧密配合以生成高质量的图像。这个过程可以用数学公式来更清晰地表达。为了简化,我们将重点放在去噪 U-Net 的作用和采样器如何与之交互。
去噪 U-Net
去噪 U-Net 的主要任务是预测并去除图像中的噪声。在 Stable Diffusion 中,这个过程是通过逆向扩散实现的,即将加噪图像逐步还原为清晰图像。
假设我们有一个加噪图像 ( x t ) ( x_t ) (xt?) 在时间步 ( t ),去噪 U-Net 的目标是预测在这个时间步加入的噪声 ( ? t ) ( \epsilon_t ) (?t?) 这可以用以下公式表示:
? ^ t = U θ ( x t , t ) \hat{\epsilon}_t = U_{\theta}(x_t, t) ?^t?=Uθ?(xt?,t)
其中:
- ( U θ ) ( U_{\theta} ) (Uθ?) 是去噪 U-Net,参数为 ( θ ) ( \theta ) (θ)
- ( ? ^ t ) ( \hat{\epsilon}_t ) (?^t?) 是 U-Net 预测的噪声。
反向扩散过程
一旦我们有了噪声的预测,就可以使用它来逆向重构图像。在每个时间步 ( t ),我们使用以下公式来更新图像:
x t ? 1 = 1 1 ? β t ( x t ? β t 1 ? β t ? ? ^ t ) x_{t-1} = \frac{1}{\sqrt{1 - \beta_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \beta_t}} \cdot \hat{\epsilon}_t \right) xt?1?=1?βt??1?(xt??1?βt??βt????^t?)
其中:
- ( x t ) ( x_t ) (xt?) 表示在时间步 ( t ) ( t ) (t) 的图像状态。在反向扩散过程中,这通常是一个部分加噪的图像。
- ( x t ? 1 ) ( x_{t-1} ) (xt?1?) 则表示在时间步 ( t ? 1 ) ( t-1 ) (t?1) 的图像状态,即在 ( x t ) ( x_t ) (xt?) 之前的状态。在反向扩散过程中, ( x t ? 1 ) ( x_{t-1} ) (xt?1?) 通常比 ( x t ) ( x_t ) (xt?) 拥有更少的噪声,更接近于原始(清晰)图像。
- ( β t ) ( \beta_t ) (βt?) 是预先定义的噪声比例参数。
采样器的作用
采样器在反向扩散过程中起到控制和指导的作用。具体来说,它负责以下任务:
-
决定步骤:采样器决定反向扩散过程中的每一步如何进行,包括何时和如何应用模型的输出来更新图像。
-
管理迭代:采样器管理整个迭代过程,确保图像逐步从加噪状态转变为清晰状态。
-
条件引导:在条件生成任务中,采样器还负责确保生成的图像符合给定的条件。
条件生成
在条件生成中,去噪 U-Net 还会考虑额外的条件信息(如文本描述)。这意味着 U-Net 不仅预测噪声,还根据条件信息调整图像生成的方向。公式可以稍作修改以包含条件信息 ( c ):
? ^ t = U θ ( x t , t , c ) \hat{\epsilon}_t = U_{\theta}(x_t, t, c) ?^t?=Uθ?(xt?,t,c)
损失函数
在训练过程中,去噪 U-Net 的目标是最小化预测噪声和实际噪声之间的差异。损失函数通常是均方误差(MSE):
L
(
θ
)
=
E
x
0
,
?
t
,
t
[
∥
?
t
?
?
^
t
∥
2
]
L(\theta) = \mathbb{E}_{x_0, \epsilon_t, t}\left[ \|\epsilon_t - \hat{\epsilon}_t\|^2 \right]
L(θ)=Ex0?,?t?,t?[∥?t???^t?∥2]
在这里:
- ( x 0 ) ( x_0 ) (x0?) 是原始图像。
- ( ? t ) ( \epsilon_t ) (?t?) 是实际噪声。
- ( E ) ( \mathbb{E} ) (E) 表示期望值。
通过这些数学公式,去噪 U-Net 在采样器的指导下逐步将加噪图像转化为清晰、高质量的图像,同时考虑到任何给定的条件约束。
采样器分类
https://github.com/AUTOMATIC1111/stable-diffusion-webui.git

-
DPM(离散概率模型)采样器:这些采样器基于离散概率模型,用于图像生成等任务。“2M”、“SDE” 和 “Karras” 变体可能指的是标准 DPM 方法的特定修改或改进。
-
欧拉和亨恩采样器:这些是解决微分方程的数值方法,在逆向扩散过程中至关重要。"欧拉"是一种更简单的方法,而"亨恩"则是一种更准确但计算上更密集的方法。
-
LMS(朗之万蒙特卡洛采样):这是一种用于采样的蒙特卡洛方法,在某些场景下以其效率而闻名。
-
DDIM(去噪扩散隐式模型):这是扩散模型的一种变体,允许更快的采样,并且可以更加可控。(最初发布的 SD 模型 v1 中附带的采样器)
-
PLMS(概率流朗之万蒙特卡洛采样):一种结合了概率流和朗之万蒙特卡洛方法的采样器。(最初发布的 SD 模型 v1 中附带的采样器)
-
UniPC:一个为快速采样扩散模型而设计的统一预测-校正框架。 https://github.com/wl-zhao/UniPC
你可能注意到还有一些采样器的名称中也有一个字母 a 呢?比如 Euler a、DPM2 a、DPM++ 2S a、DPM++ 2S a Karras,它们都属于祖先采样器(ancestral samplers)。祖先采样器会在每个采样步骤中向图像添加噪声。因为采样结果有一定的随机性,所以它们是随机采样器。
带有 “Karras” 标签的采样器,它们采用了 https://arxiv.org/abs/2206.00364 文章中推荐的噪声策略。在接近去噪过程结束时,将噪声步长变小。研究人员发现这可以提高图像的质量。
如何选择合适采样器
-
如果你想使用快速、新颖且质量不错的算法,最好的选择是 DPM++ 2M Karras,设置 20~30 步。
-
如果你想要高质量的图像,那么可以考虑使用 DPM++ SDE Karras,设置 10~15 步,但要注意这是一个计算较慢的采样器。或者使用 DDIM 求解器,设置 10~15 步。
-
如果你喜欢稳定、可重现的图像,请避免使用任何原始采样器(SDE 类采样器)。
-
如果你喜欢简单算法,Euler 和 Heun 是不错的选择。
https://www.reddit.com/r/StableDiffusion/comments/xmwcrx/a_comparison_between_8_samplers_for_5_different/
Reddit 用户 Any-Winter-4079 在 r/StableDiffusion 论坛上发表了一篇关于比较 8 种不同采样器在 5 种不同主题(动漫、自然、食物、动物和人物)上的表现的帖子。以下是这个比较的主要发现和建议:
主要发现
-
采样器收敛性:随着步骤数(-s)的增加,结果趋于收敛(除了 K_DPM_2_A 和 K_EULER_A)。通常在 -s100 以上步骤时收敛,但有时可能需要 -s700 以上。
-
批量生成速度:在较低的步骤数(-s8 到 -s30)产生一批候选图像可以节省数小时的计算时间。
-
采样器性能:
- K_HEUN 和 K_DPM_2 在较少的步骤中收敛(但速度较慢)。
- K_DPM_2_A 和 K_EULER_A 引入了大量的创造性/变异性。
采样器性能(每秒迭代次数)
- DDIM: 1.89
- PLMS: 1.86
- K_EULER: 1.86
- K_LMS: 1.91
- K_HEUN: 0.95(较慢)
- K_DPM_2: 0.95(较慢)
- K_DPM_2_A: 0.95(较慢)
- K_EULER_A: 1.86
建议
-
通用用途:对于大多数用例,K_LMS、K_HEUN 和 K_DPM_2 是最佳选择(后两者运行速度为 K_LMS 的一半,但收敛速度是 K_LMS 的两倍)。在非常低的步骤数(≤ -s8)下,不建议使用 K_HEUN 和 K_DPM_2,而应使用 K_LMS。
-
创造性和变异性:对于需要创造性和变异性的情况,使用 K_EULER_A(运行速度是 K_DPM_2_A 的两倍)。
不同主题的收敛性
- 自然:自然场景的初始结果更能预示最终结果,K_HEUN 和 K_DPM_2 从一开始就是最快的指标。
- 食物:K_HEUN 和 K_DPM_2 需要最少的步骤就能成为最终结果的良好指标。
- 动物:K_HEUN 和 K_DPM_2 同样需要较少的步骤。
- 人物:所有采样器收敛所需时间更长,K_HEUN 大约需要 150 步。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!