基于Wenet长音频分割降噪识别
2023-12-28 17:52:51
Wenet是一个流行的语音处理工具,它专注于长音频的处理,具备分割、降噪和识别功能。它的长音频分割降噪识别功能允许对长时间录制的音频进行分段处理,首先对音频进行分割,将其分解成更小的段落或语音片段。接着进行降噪处理,消除可能存在的噪音、杂音或干扰,提高语音质量和清晰度。最后,Wenet利用先进的语音识别技术对经过处理的音频段落进行识别,将其转换为文字或语音内容,从而实现对长音频内容的准确识别和转录。这种功能可以应用于许多领域,如语音识别、语音转文字、语音翻译以及音频内容分析等,为长音频数据的处理提供了高效而准确的解决方案。
支持上传(WAV、MP3、M4A、FLAC、AAC)

import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
import numpy as np
# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')
# 执行语音识别的函数
def recognition(audio, lang='CN'):
if audio is None:
return "输入错误!请上传音频文件!"
if lang == 'CN':
ans = chs_model.transcribe(audio)
elif lang == 'EN':
ans = en_model.transcribe(audio)
else:
return "错误!请选择语言!"
if ans is None:
return "错误!没有文本输出!请重试!"
txt = ans['text']
return txt
def reduce_noise_segmented(input_file,chunk_duration_ms,frame_rate):
try:
audio = AudioSegment.from_file(input_file,format=input_file.name.split(".")[-1])
# 将双声道音频转换为单声道
audio = audio.set_channels(1)
# 压缩音频的帧率为 16000
audio = audio.set_frame_rate(frame_rate)
duration = len(audio)
# 分段处理音频
chunked_audio = []
start = 0
while start < duration:
end = min(start + chunk_duration_ms, duration)
chunk = audio[start:end]
chunked_audio.append(chunk)
start = end
return chunked_audio
except Exception as e:
st.error(f"发生错误:{str(e)}")
return None
def extract_keywords(result):
word_list = jieba.lcut(result)
return word_list
def get_base64_link(file_path, link_text):
with open(file_path, "rb") as file:
audio_content = file.read()
encoded = base64.b64encode(audio_content).decode('utf-8')
href = f'<a href="data:audio/wav;base64,{encoded}" download="processed_audio.wav">{link_text}</a>'
return href
def main():
st.title("语音识别与词云生成")
uploaded_file = st.file_uploader("上传音乐文件", type=["wav","mp3","m4a","flac","aac"])
if uploaded_file:
st.audio(uploaded_file, format='audio/wav')
segment_duration = st.slider("分段处理时长(毫秒)", min_value=1000, max_value=10000, value=5000, step=1000)
frame_rate = st.slider("压缩帧率", min_value=8000, max_value=48000, value=16000, step=1000)
language_choice = st.selectbox("选择语言", ('中文', '英文'))
bu=st.button("识别语音")
if bu:
if uploaded_file:
st.success("正在识别中,请稍等...")
output_audio_path = os.path.basename(uploaded_file.name)
chunked_audio = reduce_noise_segmented(uploaded_file, segment_duration, frame_rate)
# 计算总的音频段数
total_chunks = len(chunked_audio)
if total_chunks>0:
# 创建进度条
progress_bar = st.progress(0)
# 对每个音频段进行降噪并合并
reduced_noise_chunks = []
result_array = []
for i, chunk in enumerate(chunked_audio):
audio_array = chunk.get_array_of_samples()
reduced_noise = reduce_noise(np.array(audio_array), chunk.frame_rate)
reduced_chunk = AudioSegment(
reduced_noise.tobytes(),
frame_rate=chunk.frame_rate,
sample_width=chunk.sample_width,
channels=chunk.channels
)
reduced_noise_chunks.append(reduced_chunk)
language=""
if language_choice=='中文':
language="CN"
else:
language="EN"
path="第"+str(i+1)+"段音频.wav"
reduced_chunk.export(path,format="wav")
while os.path.exists(path):
result = recognition(path, language)
if result:
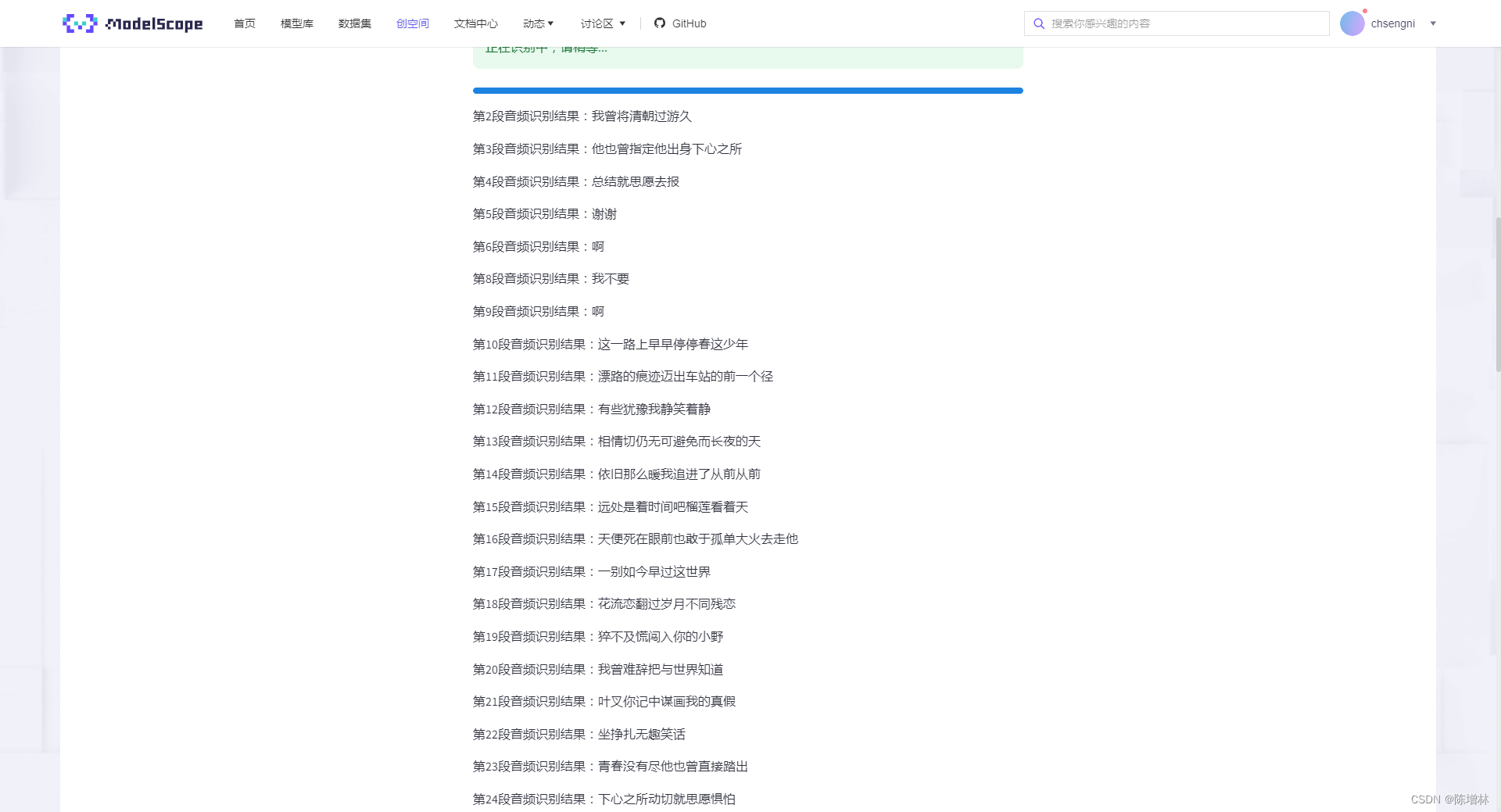
st.write(f"第{i+1}段音频识别结果:" + result)
result_array.append(result)
break
# 更新进度条的值
progress = int((i + 1) / total_chunks * 100)
progress_bar.progress(progress)
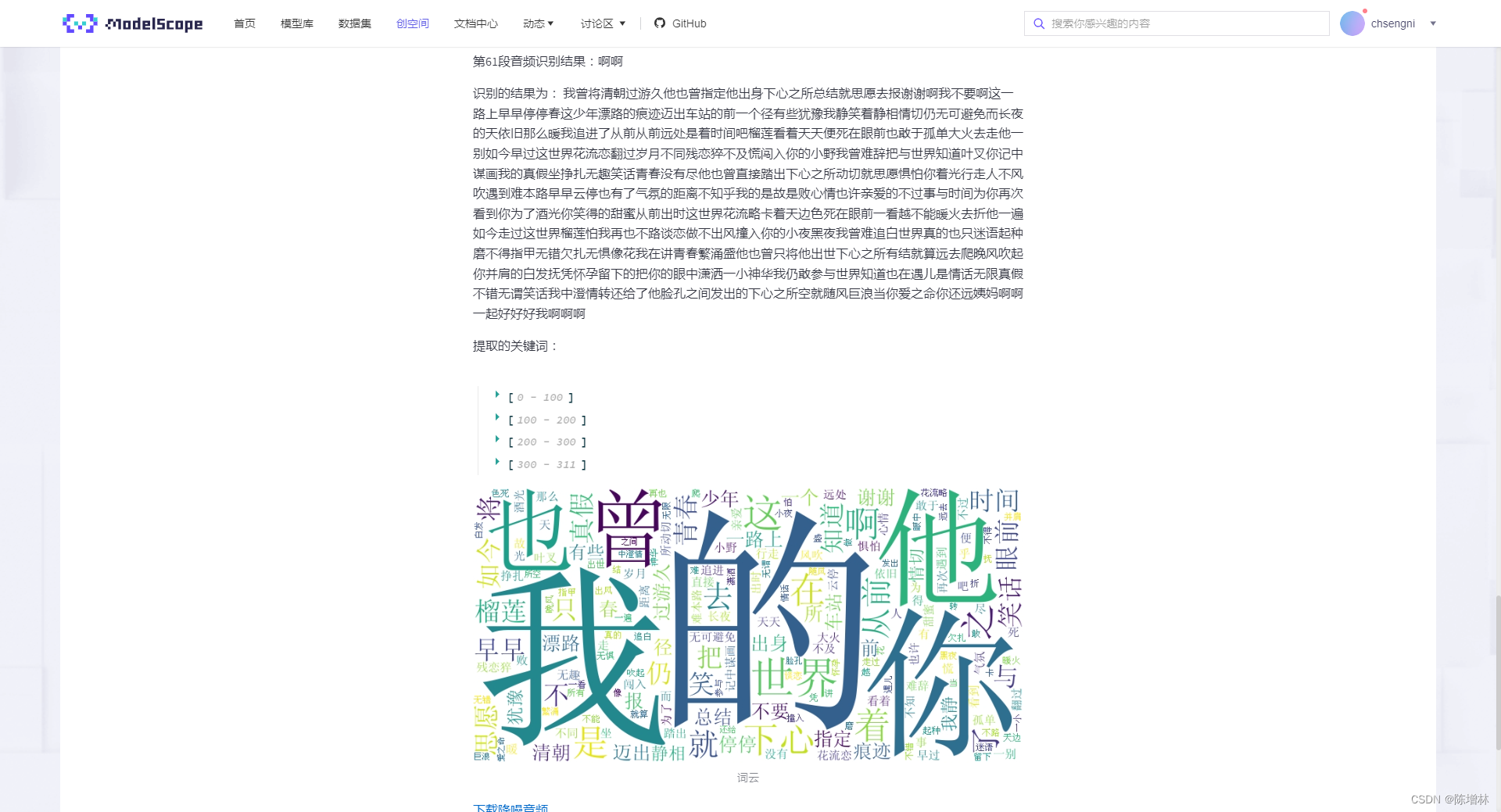
st.write("识别的结果为:","".join(result_array))
keywords = extract_keywords("".join(result_array))
st.write("提取的关键词:", keywords)
text=" ".join(keywords)
wc = WordCloud(font_path="SimSun.ttf",collocations=False, width=800, height=400, margin=2, background_color='white').generate(text.lower())
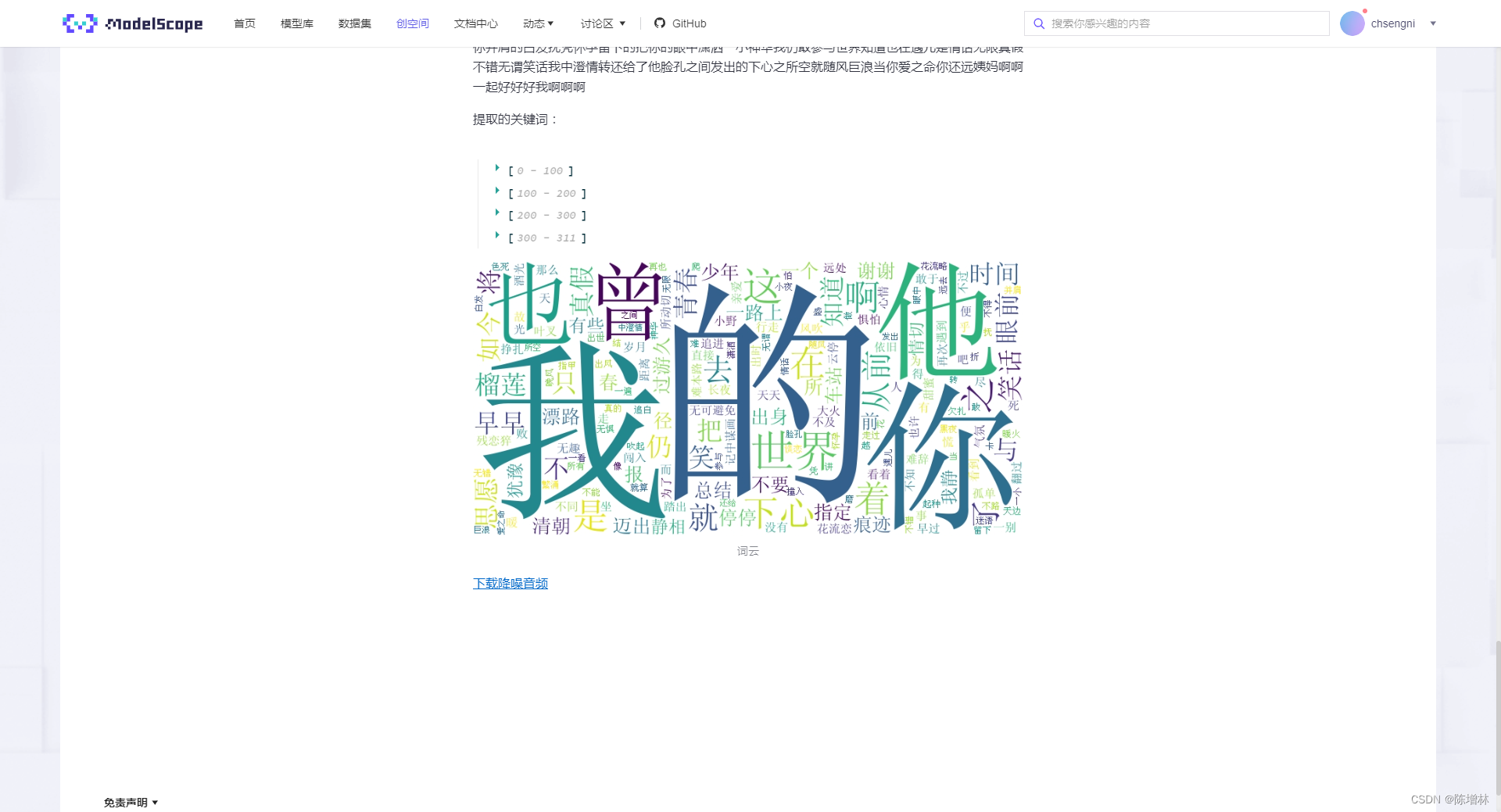
st.image(wc.to_array(), caption='词云')
# 合并降噪后的音频段
reduced_audio = reduced_noise_chunks[0]
for i in range(1, len(reduced_noise_chunks)):
reduced_audio += reduced_noise_chunks[i]
# 导出处理后的音频文件
reduced_audio.export(output_audio_path,format="wav")
while os.path.exists(output_audio_path):
# 提供处理后音频的下载链接
st.markdown(get_base64_link(output_audio_path, '下载降噪音频'), unsafe_allow_html=True)
break
else:
st.warning("请上传文件")
if __name__ == "__main__":
main()
依赖
wenet @ git+https://github.com/wenet-e2e/wenet
streamlit
wordcloud
pydub
jieba
noisereduce
numpy==1.23.5
文章来源:https://blog.csdn.net/qq_37655607/article/details/135273643
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!