分析蓝奏云下载直链!使用Python下载分享资源
【作者主页】:吴秋霖
【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作!
【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》
还有未来会持续更新的验证码突防、APP逆向、Python领域等一系列文章
1. 写在前面
??在很早之前我们做过一个针对论坛中分享安卓APK资源的采集项目。通过下面图片可以看到去广告、破解、内供、VIP…各种魔改的APP版本在论坛中层出不穷,如果说从安全的角度去思考,这些APK资源很有研究价值!
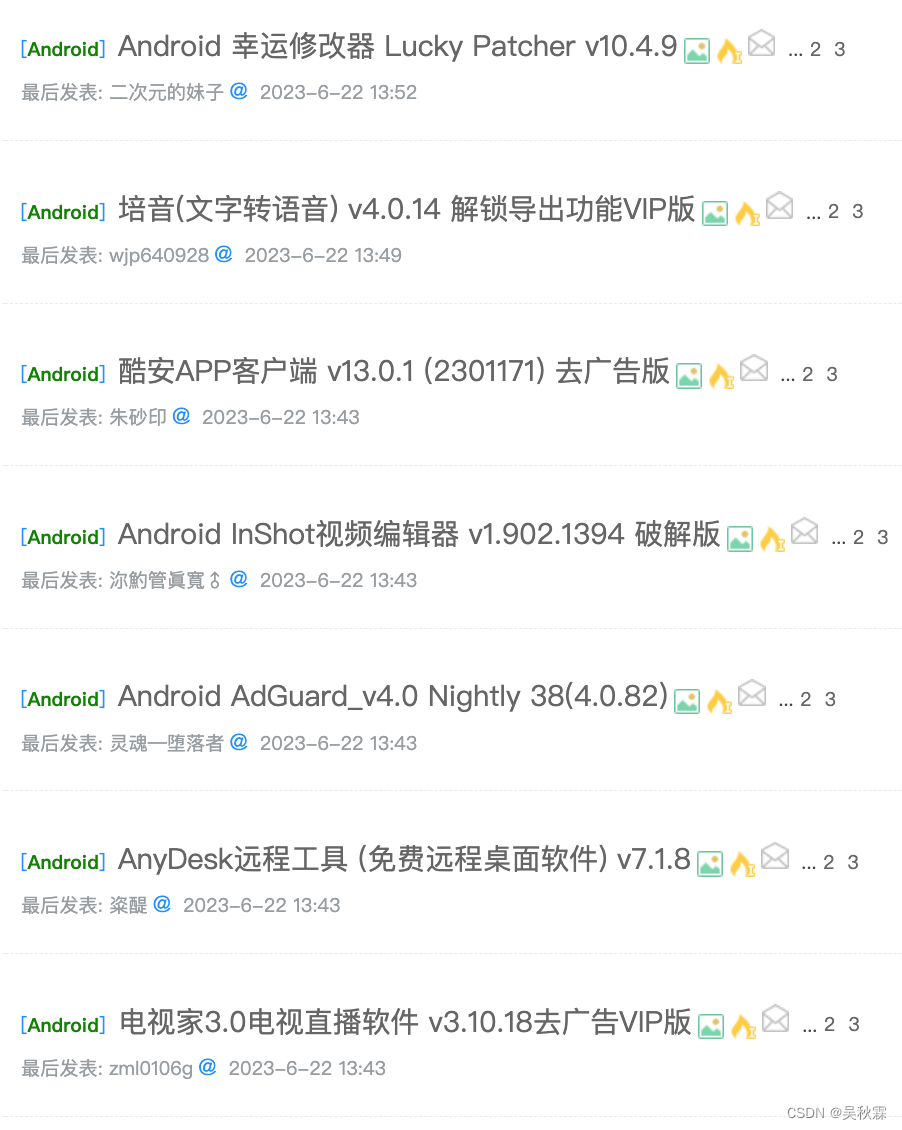
这些资源在论坛中主要通过第三方的存储介质(网盘、云盘)去分享与传播,并且链接地址将会以无序的方式嵌套在贴文内容当中!提取文本内容中的真实且有效的链接地址与密码,在早期使用的方式是基于规则,正则+特征的一个规则库去命中与识别!
那个时候没有GPT,现在处理这样的场景那可就简单了!!!
本期主要说说蓝奏云资源的下载链接获取(需要密码、多资源分享、单一资源分享)等多种情况的链接提取分析
后期有时间也会更新百度网盘跟天翼云盘的下载提取方式
庆幸的是我在写这篇文章的时候,所有涉及到的接口与参数跟以前相比并没有太大的变化!因为我是参考以前的代码去写的~~
在开始阅读这篇文章之前,请先看之前遇到过的坑,以免你恰巧也正在遇到,如下所示:
1、由于APK包寄存在云盘,直链存在是有时效性的(<10分钟)
2、网络检测那一步验证,可能会出现Sign参数校验错误,停留几秒重试几次即可通过参数验证
2. 单一文件提取
??这一类APK资源点击分享链接跳转,直接可以下载,它跟有密码提取的接口一致,参数不同区分,如下所示:
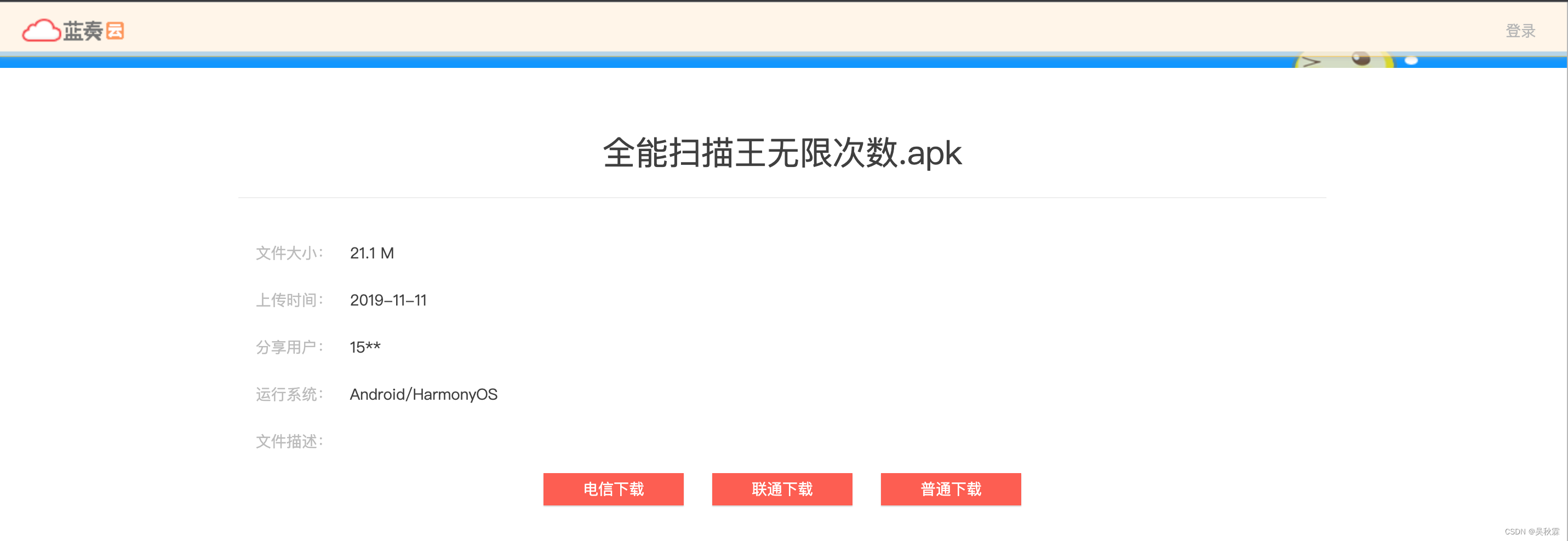
sign参数在响应的HTML代码中可获取到,其他参数为固定参数,所以基本上没有任何较大的难度,请求参数如下所示:

这里需要说一下的是,该接口请求响应的JSON数据中,需要提取dom、url两个字段拼接下一次请求的链接,响应数据如下所示:
{“zt”:1,“dom”:“https://developer-oss.lanzouc.com”,“url”:“?UjRWaF1sADEACQszUWQCbltkU2sCuAaBV/hSvFOMU+8A5gXbAfdV5wXcU4pU5wKNBtcB4lefBKZQvgOcUZ0G4VL+VqBd5gDBAOYLc1FkAnNbalNwAjsGbVc8UjFTUFM7AGQFbwFtVTIFalM8VDUCNQZrATNXLgRgUCQDOFE/BjVSY1Y3XTUAYABgC2hRIwJzW3FTawJvBjRXYVJtUyBTYwAxBX0BbVUwBXxTZ1QwAmUGZQEzVz0EMlBuA2dRaAZjUmZWN11mADcAZgs5UWMCZ1s5U24CPAYwV2dSYFNuU2oAMAViAT5VMQU2UytUYQJzBjcBIld9BHVQMgN3UWQGY1JvVjBdMABnAGMLaFEwAjdbJ1MiAjQGaVc1UjJTMlNjADcFYgFuVTIFZVM3VDICMwZqASpXJgQgUDEDaVF6BjpSY1Y2XTAAZgBlC2tRNAIyWzNTYwJ7BnFXIFIjUzJTYwA1BWUBb1U1BWtTNFQ3AjIGawEiV30Eb1AnAzhRPAY3UmRWL10zAGwAeAtsUTcCMlsvU2cCZAYw”,“inf”:0}
拼接方式需要加一个字符串file:os.path.join(dom, ‘file’, url)
拿到下一次请求的链接后,发起请求,会出现一个验证检测,这里需要点击触发才能继续后续下载操作,如下所示:
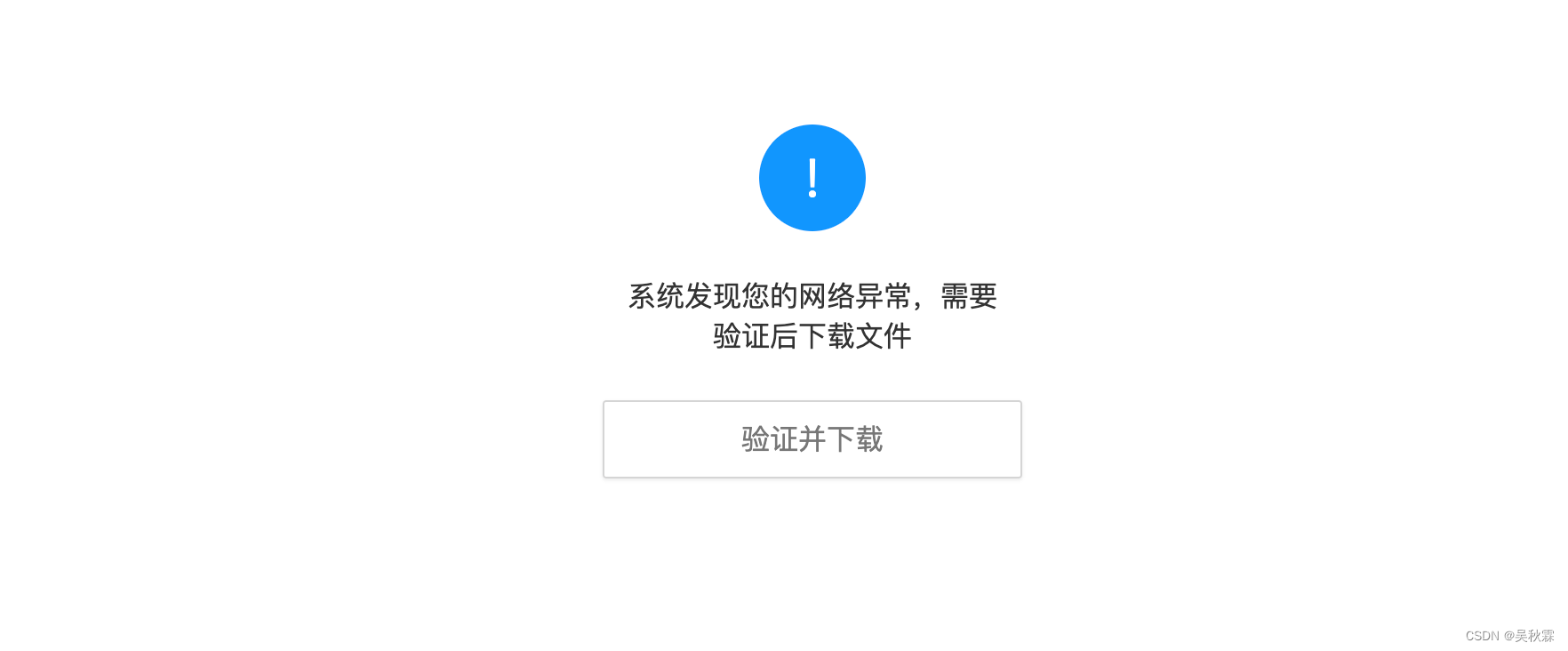
上图验证并下载的操作抓包分析一下,可以看到同样是一个Ajax的请求,sign参数同样在响应的HTML代码中可以拿到,file参数一样在HTML代码中可以获取,如下所示:



拿到上述验证检测请求所需的参数后,接下来提交验证并下载的请求,即可通过验证,如下所示:

通过验证之后,接口响应的数据就包含最终APK资源的下载链接,直接提取即可,响应数据如下:
{“zt”:1,“dom”:null,“url”:“https://c1026.lanosso.com/df137b170d87e8a5968ef81693144f7c/65780215/2019/11/11/b0f97549bed46fc0dfd88a474a800b0e.apk?fn=%E5%85%A8%E8%83%BD%E6%89%AB%E6%8F%8F%E7%8E%8B%E6%97%A0%E9%99%90%E6%AC%A1%E6%95%B0.apk”}
还有另外一种页面,就是在点击云盘的分享链接后,会直接跳转到如下页面:
这样的情况只是页面类型不一样而已,到这一步直接拼接上面含file的链接直接请求,就会来到验证检测页面那一步
3. 多文件分享提取
??另外一种就是分享链接中含多个APK资源文件,它们都不一样,可能需要全部下载,如下所示:

首先它有一个更多文件加载的接口,我们抓包分析一下,如下:
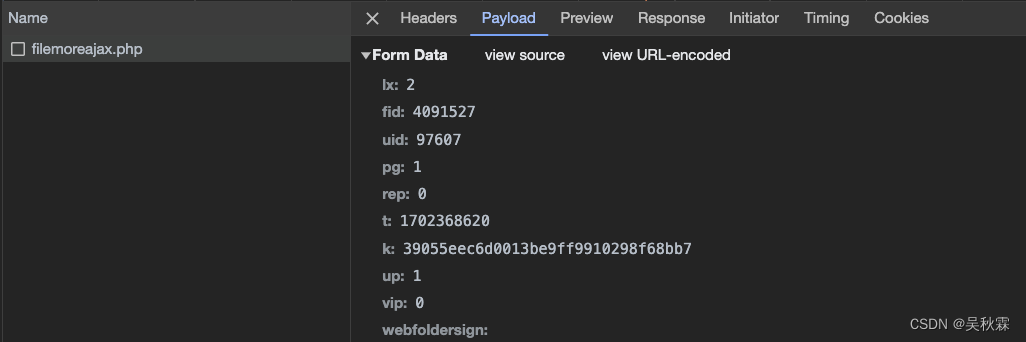
这些参数同样在响应的HTML代码中可以获取到,如下所示:
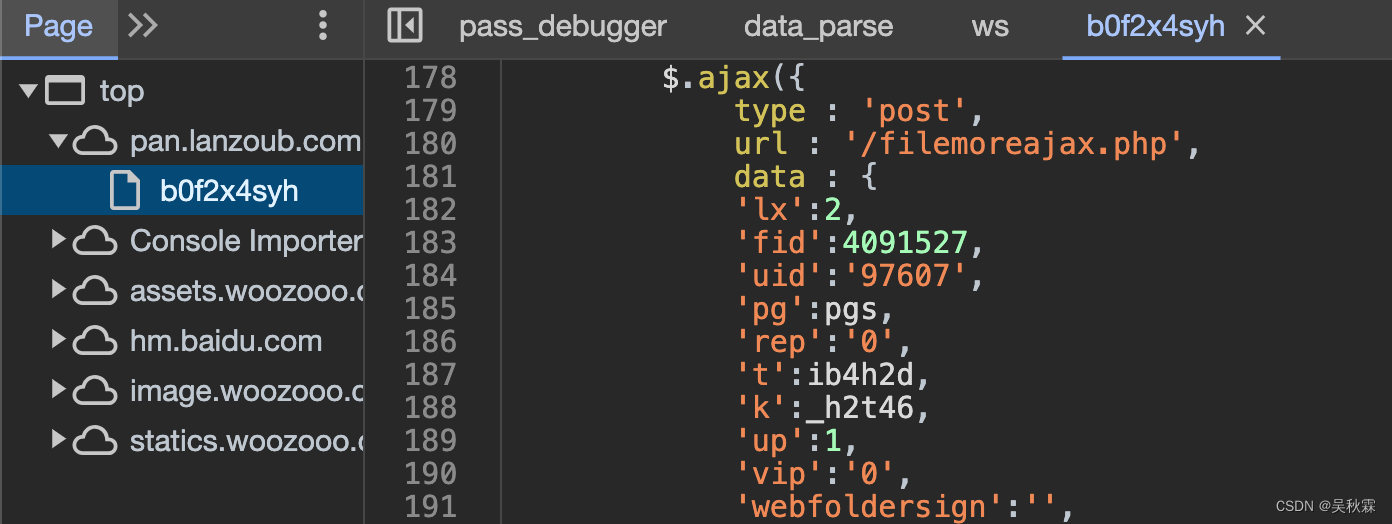
截止目前,你会发现蓝奏云的参数并没有使用很难或者多复杂的加密算法,也没有相对严格的风控!唯一繁琐的就是流程较为多。多APK资源文件提取代码如下,仅供参考:
def get_first_match(self, pattern, text):
match = findall(pattern, text)
return match[0] if match else None
def get_more_apk(self, url, html, data: dict = {}):
lx = self.get_first_match("'lx':(\\d{1})", html)
fid = self.get_first_match("'fid':(\\d{7})", html)
uid = self.get_first_match("'uid':'\\d{5}'", html)
pgs = self.get_first_match("pgs =(\\d{1})", html)
_k = self.get_first_match("'k':([0-9a-zA-Z]{6}),", html)
_t = self.get_first_match("'t':([0-9a-zA-Z]{6}),", html)
if _k and _t:
k = self.get_first_match(
"var {} = '(.*)';".format(_k), html)
t = self.get_first_match(
"var {} = '(.*)';".format(_t), html)
data = {
"lx": lx,
"fid": fid,
"uid": str(uid),
"pg": pgs,
"rep": '0',
"t": t,
"k": k,
"up": 1,
"vip": '0',
"webfoldersign": ""
}
if data:
moreapk_res = requests.post(
'https://pan.lanzoub.com/filemoreajax.php',
json=data,
headers=self.headers
).json()
_apk_json = moreapk_res.get('text', '')
if isinstance(_apk_json, list):
for _json in _apk_json:
apk_info = {}
icon = _json.get('icon', '')
if icon == 'apk':
apk_info['url'] = urljoin(
self.host_url, _json['id'])
apk_info['title'] = _json['name_all']
apk_info['size'] = _json['size']
print(apk_info)
4. 密码登陆提取
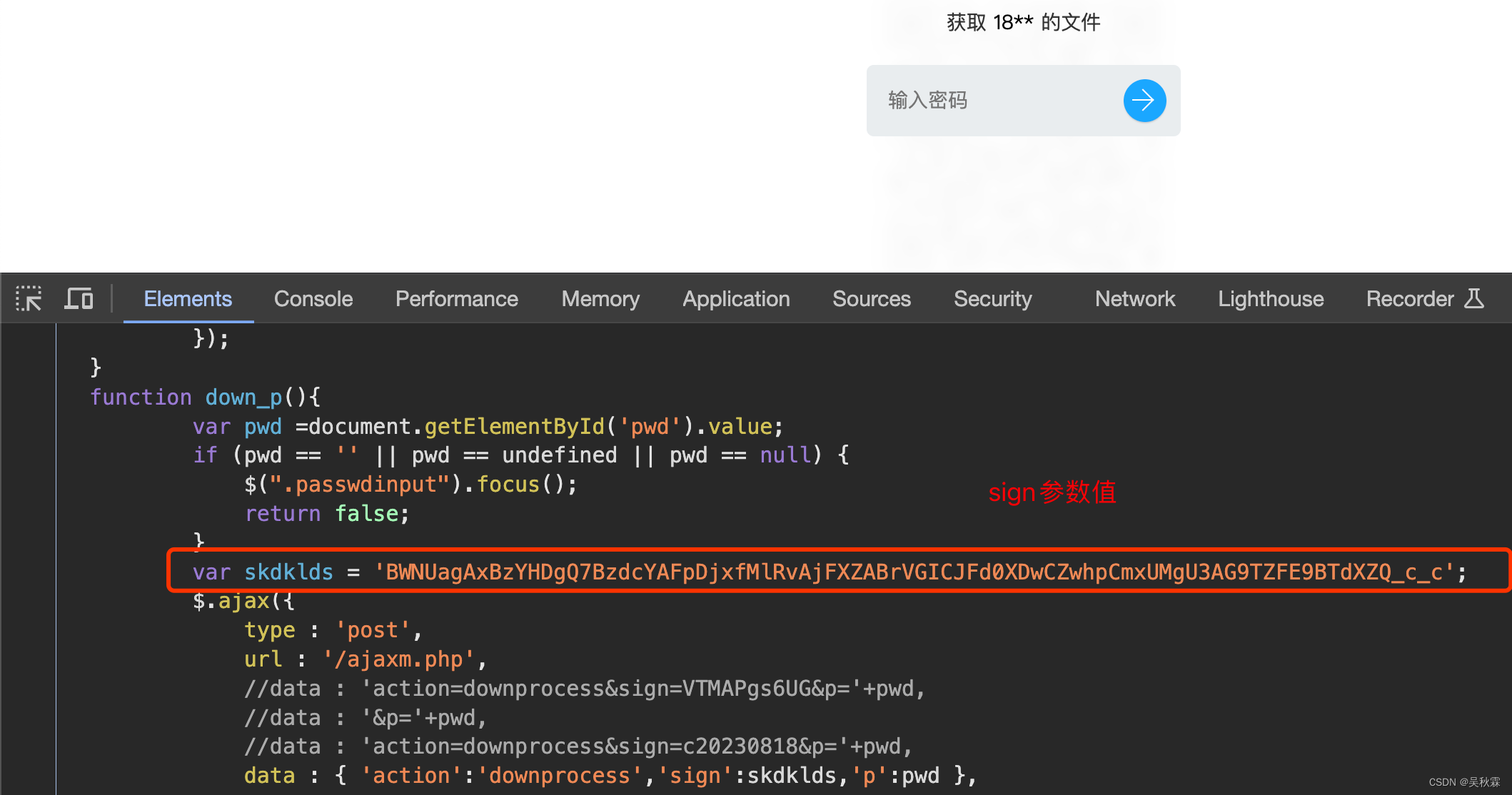
??最后一种就是常见的需要提取码(密码)提取的资源,跟上面单一文件分享流程是一样的,只不过在第一步请求的时候有一个p参数,这个参数就是密码,如下所示:

sign参数同样能够在影响的HTML代码中拿到,如下所示:
提交上面携带密码参数的请求之后,就会进入到分享文件页面,然后重复上面的流程,先构造携带file的链接进行请求,之后过检测,最后接口响应的数据如下所示:
{“zt”:1,“dom”:“https://developer-oss.lanzouc.com”,“url”:“?BGJXaQ08Dz4BCFBoBzIHa1plUmpS6QC6CqBTsAfWUd4I71a/CdoHugn8UJlW6ga3Bu1UDlU/U2kHMwc3AW1bdARlV3ANOw99ATFQbwc/B2NaX1I+UmkAPwo/U2IHaVFpCDxWNAljB2QJeVBgVnEGOgZtVGBVOlNpBzgHNwFqW20EIldwDSAPZgFlUDYHYQc2Wi9SZ1I1AC0KPVNnB3RRYwhtVmUJMQc2CWZQZVZgBmQGaVQ3VW5TNQdmBzYBPFtoBGVXOQ1oDz0BZlAxB2YHN1o0UjVSPQA0Cm9TZgdsUX4IaVZxCT8HdQkqUHVWZwZ1BjVUNVU3U2AHNQc3AWpbbgQ9VzMNdg8vAT5Qawc2B2BaPVJmUjoAMgo/U2YHblFiCD9WNwliB30JcVAgVmQGawYrVGxVO1NmBzAHMAFuW2oEN1czDWEPYgFxUHMHIwdxWj1SZlI4ADsKO1NmB29RaAg8VjQJYQd1CSpQb1ZyBjoGbVRhVTxTfwczBzkBc1trBDZXMQ1+D2oBblAy”,“inf”:“\u4e2d\u534e\u7f8e\u98df\u8c31_58360.apk”}
5. 防盗链处理
??请求过程中会遇到可能会防盗链,主要就是为了保护资源跟控制流量,稍微处理一下,代码参考如下:
iframe_element = response.xpath("//div[@class='iframe']")
# 防盗链处理
if 'plugin.php' in response.url or iframe_element:
share_link = response.xpath("//div[@class='iframe']//iframe/@src").extract_first()
# 拿到真实链接地址重新请求
yield scrapy.Request(
share_link,
callback=self.parse_handle,
meta=response.meta
)
6. 下载分享资源
??这里对于APK资源的下载使用开源仓库YouTube-dl,代码参考如下:
def rename_hook(d):
if d['status'] == 'finished':
print(
'====> APK Download Fnish. {}'.format(
d.get(
'filename',
'')))
def download(apk_link, apk_name):
try:
ydl_opts = {
'outtmpl': '{}.apk'.format(apk_name),
'progress_hooks': [rename_hook],
'writeautomaticsub': True,
'nocheckcertificate': True,
'nooverwrites': True,
'subtitleslangs': 'en',
'logger': MyLogger(),
'retries': 3,
'socket_timeout': 60
}
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
rest = ydl.download([apk_link])
if not rest:
return True, ''
else:
return False, FileNotFoundError
except Exception as e:
return False, e
??好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!