深度学习之全面了解预训练模型
在本专栏中,我们将讨论预训练模型。有很多模型可供选择,因此也有很多考虑事项。
这次的专栏与以往稍有不同。我要回答的问题全部源于 MathWorks 社区论坛(ww2.mathworks.cn/matlabcentral/)的问题。我会首先总结 MATLAB Answers 上的回答,然后基于问题提出问题:大家为什么会问这些问题?
因此,本专栏将介绍如何选择预训练模型、如何确定是否作出了正确的选择,并回答关于预训练模型的三个问题:
1. 训练网络时,应操作数据大小还是模型输入大小?
2. 为什么要在 MATLAB 中导入经过预训练的 YOLO 模型?
3. 为什么要冻结预训练模型的权重?
选择预训练模型
可供选择的模型非常多,而且只会越来越多。这当然带来很多便利,但也有些令人望而生畏:我们该如何挑选,又如何确定是否作出了正确的选择?
与其把所有预训练模型放在一起考虑,我们不妨将它们分成几类。
基本模型
这些模型架构简单,可以轻松上手。这些模型通常层数较少,支持预处理和训练选项的快速迭代。一旦掌握了训练模型的方法,就可以开始尝试改善结果。
尝试这些模型:GoogLeNet、VGG-16、VGG-19 和 AlexNet
高准确度模型
这些模型适用于基于图像的工作流,如图像分类、目标检测和语义分割。大多数网络,包括上述基本模型,都属于此类别。与基本模型的区别在于,高准确度模型可能需要更多训练时间,网络结构更复杂。
尝试这些模型:ResNet-50、Inception-v3、Densenet-201
目标检测工作流:一般推荐基于 DarkNet-19 和 DarkNet-53 创建检测和 YOLO 类型工作流。我也见过 ResNet-50 加 Faster R-CNN 的组合,因此多少有一些选择余地。我们将在之后的问题中进一步讨论目标检测。
语义分割:您可以选择一个网络并将其转换为语义分割网络。也有一些专门的 Segnet 结构,如 segnetLayers 和 unetLayers。
适合边缘部署的模型
当部署到硬件时,模型大小变得尤为重要。此类模型内存占用量较小,适合 Raspberry Pi? 等嵌入式设备。
尝试这些模型:SqueezeNet、MobileNet-v2、ShuffLeNet、NASNetMobile
以上只是一些常规原则,为模型选择提供基本思路。我将从第一类模型入手,之后如果需要,再选择更复杂的模型。我个人觉得 AlexNet 是一个不错的起点。它的架构非常容易理解,性能表现通常也不错,当然也取决于具体问题。
选择模型时,如何确定是否作出了正确的选择?
对于您的任务来说,合适的模型可能不止一个。
只要模型的准确度能满足给定任务的需求,就是一个可接受的模型。至于多高的准确度意味着“可接受”,则可能视应用不同而差异极大。
例如,购物时某宝推荐商品出错不是什么大事,但暴风雪漏报后果就很严重。
针对您的应用尝试各种预训练网络,方能确保获得最准确和最稳健的模型。
当然,要实现一个成功的应用,网络架构只是众多因素之一。
|
|

Q1
问题 1:训练网络时,应操作数据大小还是模型输入大小?
此问题来自论坛提问“如何在预训练模型中使用灰度图像”和“如何更改预训练模型的输入大小”。
-
如何在预训练模型中使用灰度图:?
https://ww2.mathworks.cn/matlabcentral/answers/448360-how-we-do-transfer-learning-using-pretrained-models-with-grey-scale-images-as-input
-
如何更改预训练模型的输入大小:?
https://ww2.mathworks.cn/matlabcentral/answers/458610-change-input-size-of-a-pre-trained-network
首先快速回顾一下模型数据输入的相关知识。
所有预训练模型都有一个预期,即需要什么样的输入数据结构,才能重新训练网络或基于新数据进行预测。
如果数据与模型预期不符,您就可能提出这些问题。
这就带来了一个有趣的问题:是要操作数据,还是操作模型?
最简单的方法是更改数据。
这很简单:只需调整数据的大小,就可以操作数据输入的大小。在 MATLAB? 中,使用?imresize?命令就能做到。灰度问题也变得很简单。
彩色图像通常采用 RGB 形式,包含三个层,分别表示红、绿、蓝三个颜色平面。灰度图像则只包含一个层而不是三个层。只需重复灰度图像的单个层,就可以创建网络所期望的输入结构,原理如下图所示。
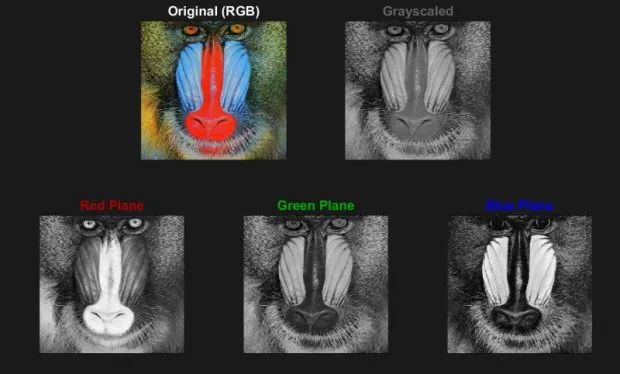
山魈照片的原始彩色图像,经灰度处理的图像,以及单独显示红、绿、蓝平面的图像。
这是一张色彩非常丰富的图像,可以看到,三个 RGB 平面看起来就像三张灰度图像,它们组合在一起形成一张彩色图像。
稍微复杂一点的方法是更改模型。为什么要大费周章地操作模型而不是数据?
因为现有的输入数据决定了只能这样做。
假设您的图像是 1000×1000 像素,您的模型接受 10×10 像素大小的图像。如果您将图像调整到 10×10 像素,就只能得到一张充满噪声的输入图像。
在这种情况下,您需要更改模型的输入层,而不是输入。
图像大小:1000×1000 像素:

图像大小:10×10 像素

我原以为对模型输入层进行操作会非常复杂,但在 MATLAB 里试了试,其实还好。相信我,真的不复杂。您只需完成以下操作:
1. 打开深度网络设计器 Deep Network Designer。
2. 选择一个预训练模型。
3. 删除当前输入层,并替换为新层。这样您就可以更改输入大小。
4. 导出模型,直接就能在迁移学习应用中使用。我推荐按照基本迁移学习示例进行操作:
https://ww2.mathworks.cn/help/deeplearning/ug/train-deep-learning-network-to-classify-new-images.html
整个过程非常轻松,您不必手动编码即可更改预训练模型的输入大小。
Q2
问题 2:为什么要在 MATLAB 中导入经过预训练的 YOLO 模型?
此问题源于基于 COCO 数据集训练 YOLO v3,答案很明确。背景并不复杂。
-
基于 COCO 数据集训练 YOLO v3
https://ww2.mathworks.cn/matlabcentral/answers/553528-yolo-v3-training-on-coco-data-set
此示例介绍如何使用 ResNet-50 训练 YOLO v2 网络以在 MATLAB 中使用:
https://ww2.mathworks.cn/help/deeplearning/ug/object-detection-using-yolo-v2.html
YOLO 是“you only look once”的缩写。
该算法有多个版本,相对于 v2,v3 改进了定位较小对象的功能。YOLO 从一个特征提取网络(使用预训练模型,如 ResNet-50 或 DarkNet-19)开始,然后进行定位。
YOLO v3: https://ww2.mathworks.cn/help/vision/ug/object-detection-using-yolo-v3-deep-learning.html
那么,为什么要在 MATLAB 中导入经过预训练的 YOLO 模型?
YOLO 是最流行的目标检测算法之一。与简单的目标识别问题相比,目标检测更具挑战性。
对于目标检测,面临的挑战不仅仅是识别目标,还要确定其位置。
有两类目标检测器:
单级检测器,如 YOLO;两级检测器,如 Faster R-CNN。
-
单级检测器可以实现快速检测。这篇文档详细介绍了 YOLO v2 算法。
https://ww2.mathworks.cn/help/vision/ug/getting-started-with-yolo-v2.html
-
两级检测器:定位和目标识别准确度高这篇文档介绍了 R-CNN 算法的基础知识。
https://ww2.mathworks.cn/help/vision/ug/getting-started-with-r-cnn-fast-r-cnn-and-faster-r-cnn.html

值得探索的目标检测应用有很多,不过我强烈建议从简单的目标检测示例开始,以此为基础逐步推进。
Q3
问题 3:为什么要冻结预训练模型的权重?
此问题源自如何冻结神经网络模型的特定权重?要回答此问题,我们先看一小段代码。
导入预训练网络后,您可以选择通过以下方式冻结权重:
冻结所有初始层:
layers(1:10) = freezeWeights(layers(1:10));
冻结单个层:
layer.WeightLearnRateFactor = 0;
冻结所有允许冻结的层:
function layers = freezeWeights(layers)
for ii = 1:size(layers,1)
??? props = properties(layers(ii));
??? for p = 1:numel(props)
??????? propName = props{p};
??????? if ~isempty(regexp(propName, 'LearnRateFactor$', 'once'))
??????????? layers(ii).(propName) = 0;
??????? end
??? end
end
end
如果该层有 LearnRateFactor,则将其设置为零。其他层保持不变。
冻结权重有两个好处,即您可以:
-
加快训练速度。由于不需要计算已冻结层的梯度,因此冻结多个初始层的权重可以显著加快网络训练速度。
-
防止过拟合。如果新数据集很小,冻结较浅的网络层可以防止这些层对新数据集过拟合。
实际上,您也可以将一个预训练模型的权重应用于您的模型,这样不经训练也能创建一个“经过训练的”网络。查看 MATLAB 中?assembleNetwork?的说明,了解如何不经训练直接基于层创建深度学习网络。
https://ww2.mathworks.cn/help/deeplearning/ref/assemblenetwork.html
最后,说到权重,对于类分布不平衡的分类问题,可以使用加权分类输出层。请参考关于使用自定义加权分类层的示例。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!