【索引的数据结构】第2章节:InooDB和MyISAM索引结构对比
目录结构

之前整篇文章太长,阅读体验不好,将其拆分为几个子篇章。
本篇章讲解 InnoDB 和 MyISAM 索引结构对比。
InnoDB 的 B+Tree 索引注意事项
根页面位置万年不变
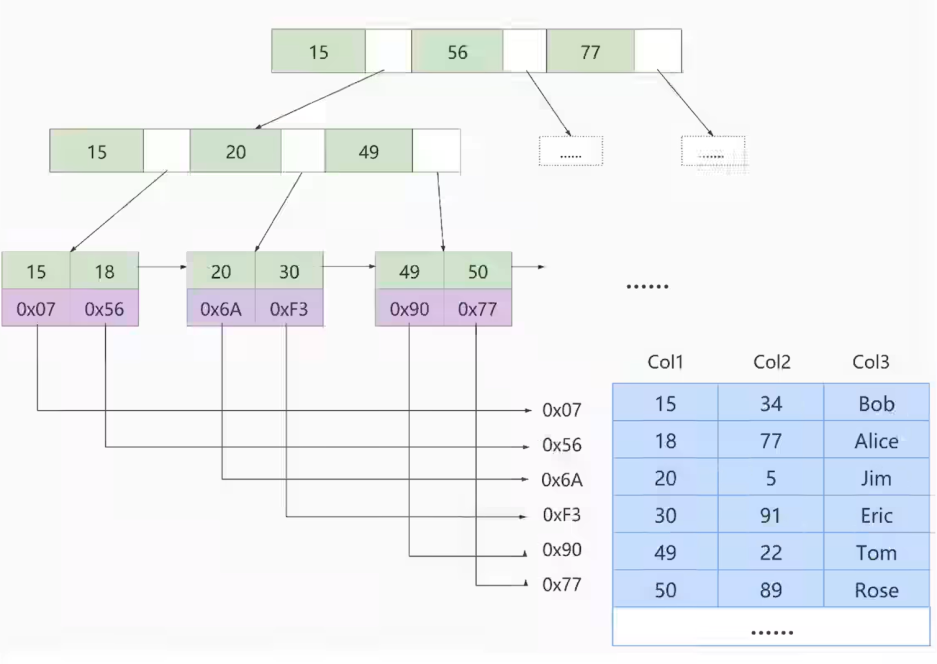
上述我们在索引迭代的过程中,为了更佳形象的描述,所以将顺序暂且定位自下而上,往上汇总目录项页。
但实际上 B+Tree 的形成是自上而下的,大致过程如下:
- 每当为某张表创建一个 B+Tree 索引(聚簇索引不是人为创建的,创建表的时候默认创建),都会为这个索引创建一个
根节点页面。最开始表中没有数据的时候,每个 B+Tree根节点中既没有用户记录,也没有目录项记录。 - 随后向表中插入记录时,先把用户记录存储到这个
根节点中。 - 当根节点中的
可用空间用完时,继续插入记录,此时存储引擎会将根节点中的所有记录复制一份到另一个新分配的页中,比如页 a,然后对这个新页进行页分裂的操作,得到另一个新的页,比如页 b。这时候根据插入记录的键值(聚簇索引的话根据主键值,二级索引的话根据索引列值、主键值)的大小就会被分配到页 a或者页 b中,而根节点就升级为存储目录项的页。
特别注意:
一个 B+Tree 索引创建之后,它的根节点便不会再移动。
也就是对某个表创建索引之后,它的根节点的页号就会被存储在某个地方,然后凡是 InnoDB 存储引擎需要用到这个索引的时候,就会从那个固定的地方取出对应根节点的页号,从而来访问这个索引。
内节点中目录项记录的唯一性
我们知道 B+Tree 聚簇索引 的内节点中目录项记录的内容是 索引列 + 页号的组合,但是这个组合对于 非聚簇索引就不太适用,拿 test_table表举例,总共有三个字段:c1(主键)、c2、c3,假设这个表中有如下几行数据:
| c1 | c2 | c3 |
|---|---|---|
| 1 | 1 | ‘u’ |
| 3 | 1 | ‘d’ |
| 5 | 1 | ‘y’ |
| 7 | 1 | ‘a’ |
当我们为 c2 列创建二级索引时,如果目录项页中的记录只是 索引列 + 页号的组合时,那么 c2列建立索引之后,B+Tree 的结构大致如下图所示:

B+Tree 数据结构组成如下:
- 黄色方块为索引列的值
- 蓝色方块为主键值
- 红色方块为页码值
通过上图二级索引数据结构,我们可以看到页 3 作为一个目录项记录页,当二级索引列存在多个相同值的记录时,非叶子节点中的目录项只存储索引列 + 页号时,我们无法区分应该去哪个数据页查询数据,或者说当新增数据时:(9、1、'u'),对应表中的字段顺序为:c1、c2、c3,此时插入的 c2 列的值也为 1,在上述页 3 中存储的两条目录项记录的索引值都为 1,所有无法区分到底该插入哪个记录对应的页中。
为了解决问题,也就是说无论是实际记录还是目录项记录,都要实现唯一性,此时我们就可以把 主键值和索引列值一起存储在目录项记录中,如下图所示:

插入数据:(9、1、'u') 的执行过程应该如下图所示:

一个页面中至少存储两个记录
一个 B+Tree 只需要很少的层级就可以轻松存储数亿条记录,查询速度也是相当不错。
B+Tree 本质上就是一个大的多层级目录,每经过一个目录时就会过滤掉很多无效的子目录,最终会查找到存储真实数据的目录。
如果说一个大的目录中只存放一个子目录是啥效果?也就是会有很多层目录,并且我们从根节点开始查找,经过很多层目录之后,最后找到了一个目录,里面只存储了一条数据,你说气人不,费老大劲,经历了那么多次数据库 I/O,就查到一条数据,效率贼低。
所以说 InnoDB 存储引擎中的一个数据页至少存储两条记录。
MyISAM 索引方案
MyISAM 索引的原理
MySQL 官方一般统称 B-Tree 为 B+树,适用于 B-Tree 的存储引擎如下表所示:
| 索引/存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| B-Tree 索引 | 支持 | 支持 | 支持 |
虽然多个存储引擎都支持 B-Tree 索引,但是在底层的实现原理上却是不同的。
InnoDB 和 MyISAM 的底层默认使用 B-Tree 索引,而 Memory 底层默认使用 hash 索引。
InnoDB 的索引即数据:
- 在聚簇索引的叶子节点中存储的是完整的数据:
主键 + 数据 - 在非聚簇索引的叶子节点中存储的数据是:
索引列 + 主键
MyISAM 的索引虽然也是 B-Tree 结构,但是底层确实将 数据和索引分开单独存储
数据文件(.myd 文件):存数据的文件,插入记录时,并没有按照主键大小刻意去排序,有多少塞多少索引文件(.myi 文件):MyISAM 为每张表的主键都创建一个 B-Tree 索引,但是叶子节点中存储的数据是:主键 + 地址
大致结构如下图所示:
索引组成结构:
- 绿色方块为
主键值 - 紫色方块为
地址偏移量
有一定我们要清楚,因为主键索引每一行记录都是唯一的,所以只需要存储 主键+地址即可,但是非主键列(二级索引)是不唯一的,很可能会重复,如果为非主键列创建索引,大致如下图所示:

这里康师傅应该是漏掉了二级索引数据重复的举例图,所以应该再加一个主键值,最终组成节点的机构为:
- 叶子节点:
索引列 + 主键 + 地址 - 非叶子节点:
索引列 + 主键 + 页码
MyISAM 和 InnoDB 的对比
- MyISAM 中的索引都是
非聚簇索引,InnoDB 中包含两种索引聚簇索引和非聚簇索引 - MyISAM 的叶子节点中存储的为
索引 + 地址,所以查询到地址之后,至少还需要一次回表查询;InnoDB 的聚簇索引叶子节点中的存储的是完整的记录,所以根据主键查询可以直接返回,不需要回表查询 - MyISAM 索引记录存储的是
地址,InnoDB 聚簇索引存储的是主键 + 数据,非聚簇索引 data 域 存储的是主键 - MyIASM 回表查询的速度
非常快,因为叶子节点中查询到是数据的地址偏移量直接去文件中查找相当的快,而 InnoDB 叶子节点查到的是主键值,根据主键再去聚簇索引中查询数据,虽然也不慢,但是相比于用地址查询,还是差了点 - MyISAM 可以没有主键;InnoDB 必须要有主键,如果没有显示指定,则 MySQL 自动选择一个
非空且能唯一标识记录的列作为主键,如果不存在这样的列,则会自动为 InnoDB 表生成一个隐含字段作为主键,字段长度为 6 个字节,类型为长整型。
索引的建议
为什么不建议使用过长的字段作为主键?
- 因为二级索引节点中都会引用主键索引,过长的主键索引会导致二级索引树结构变的很臃肿
- 用非单调的字段作为主键在 InnoDB 中不是一个好主意,已因为 InnoDB 索引本身是一颗 B+Tree,非单调的主键会导致在插入记录时,数据文件为了维护树的结构而频繁的进行
页分裂,导致性能比较低效,而使用自增且单一的字段作为主键是个好的选择
InnoDB 和 MyISAM 索引分布对比如下图所示:

索引的代价
索引虽好,但不能乱建(劲酒虽好,但不能贪杯哦):
占用空间:每个索引都要建立一棵 B+Tree,每个节点都是一个数据页,一个数据页为16KB,一棵很大的 B+Tree 由很多个数据页组成,就会占用很大的空间消耗时间:对表进行增删改操作时,都要去修改各个 B+Tree 的结构。因为 B+Tree 的各个节点都是根据索引列值从小到达按顺序存储的而存储的双向链表。而不论是叶子节点还是内节点(非叶子节点)中的记录都是按照索引列的值从小到达按顺序存储的而存储的单向链表,所以如果对表记性增删改的操作,会对各个节点和记录的排序造成破坏,存储引擎为了维护索引结构的平衡会进行额外的记录移位、页面分裂、页面回收等操作,会造成性能大幅下降。
一个表中创建的索引越多,占用的空间越大。在增删改操作时,存储引擎维护索引消耗的时间就越多。
为了能建立好的索引,所以要根据数据的分布情况建立合理的索引结构。
本文内容总结借鉴于康师傅的 MySQL 视频课:https://www.bilibili.com/video/BV1iq4y1u7vj

一起学编程,让生活更随和!
如果你觉得是个同道中人,欢迎关注博主gzh:【随和的皮蛋桑】。
专注于Java基础、进阶、面试以及计算机基础知识分享🐳。偶尔认知思考、日常水文🐌。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!