【CVPR2023】可持续检测的Transformer用于增量对象检测
目录
?

代码已开源:https://github.com/yaoyao-liu/CL-DETR
导读
本文旨在解决增量目标检测(IOD)问题,模型需要逐步学习新的目标类别,同时不忘记先前学到的知识。在这个背景下,论文提出了一种创新性的方法,称为ContinuaL DEtection TRansformer(CL-DETR),它基于Transformer架构,并允许有效地使用知识蒸馏(KD)和示例重播(ER)等技术来解决增量学习中的挑战。该方法不仅解决了目标检测中的灾难性遗忘问题,还提供了在增量学习任务中更好的性能,并通过实验证明了其有效性。
动机
人类学习的方式:人类在学习新知识时往往会保留之前学到的知识,不会因为学习新知识而忘记以前的知识。这种增量学习的方式对于机器学习领域具有重要的启发,因为它使得模型可以不断地积累新的知识,而不会丢失旧有的知识。
避免灾难性遗忘:在传统的机器学习中,当模型接触到新的数据时,往往会覆盖或忘记之前学到的知识,这被称为灾难性遗忘。在目标检测领域,灾难性遗忘可能导致模型无法有效地识别旧有的目标类别,从而降低了模型的实用性。因此,解决灾难性遗忘问题是增量目标检测的重要动机之一。
适应实际应用场景:在现实世界的应用中,目标检测模型可能需要逐步适应新的目标类别,而不是一次性地训练模型以识别所有可能的目标。例如,安全监控系统可能需要在不同时间学习新的监测对象。因此,增量目标检测有助于使模型更适应实际应用场景。
综上,本文旨在提出一种有效的方法来解决增量目标检测中的灾难性遗忘问题,使得模型可以逐步学习新的目标类别,同时保留之前学到的知识,从而更好地适应实际应用需求。
本文贡献
-
Detector Knowledge Distillation (DKD) 损失:本文引入了一种名为Detector Knowledge Distillation(DKD)的损失,该方法改进了知识蒸馏(KD)的方式,解决了蒸馏知识与新证据之间的冲突,并忽略冗余背景检测。(此处的"新证据" 指的是在增量目标检测任务中,模型在学习新的目标类别时所观察到的有关这些新类别的训练数据和标签。)
-
示例重播(ER)校准策略:将存储的样本与训练集分布匹配,以解决示例重播方法在不平衡目标分布情况下的问题。
-
IOD基准协议的重新定义:避免在不同训练阶段观察相同的图像,更贴近实际应用场景。
-
进行了广泛的实验,包括最先进的结果、消融研究和进一步的可视化。
相关工作/概念
相关工作包括增量学习、增量目标检测、以及基于Transformer的目标检测方法
增量学习:增量学习(Incremental Learning)是一个备受关注的领域,也被称为持续学习(Continual Learning)或终身学习(Lifelong Learning)。它的目标是使模型能够逐步学习新的知识,而不会忘记已经学到的知识。先前的增量学习方法可以分为两大类:一是知识蒸馏(Knowledge Distillation,KD),它试图通过匹配新模型和旧模型之间的输出来保留先前知识;二是示例重播(Exemplar Replay,ER),它通过保存旧数据的样本并在后续阶段重播它们来保留知识。
增量目标检测(IOD):增量目标检测是一种特殊的目标检测任务,其中模型需要逐步学习新的目标类别,而不会忘记旧有的目标类别。在以前的研究中,知识蒸馏和示例重播方法已经被应用于增量目标检测中。一些方法将知识蒸馏应用于目标检测的输出,而另一些方法则将示例重播用于保存旧有的数据。
基于Transformer的目标检测方法:近年来,基于Transformer的目标检测方法得到了广泛的关注,例如DETR(DEtection TRansformer)等。这些方法采用了Transformer架构,具有一定的优势,但传统的增量学习方法不一定适用于它们,因为它们的工作原理和传统目标检测器不同。
本文方法
?
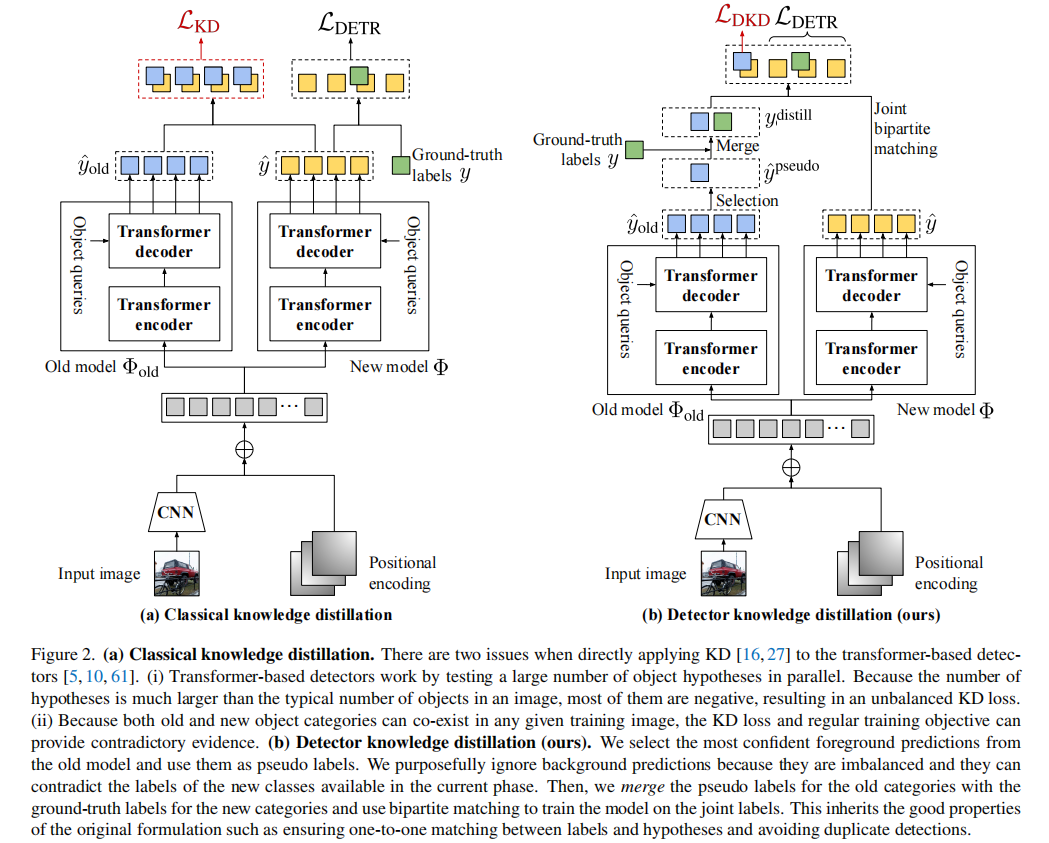
Detector Knowledge Distillation
作者提出了一种新的知识蒸馏方法,称为Detector Knowledge Distillation(DKD)。该方法从旧模型中选择最有信心的前景目标预测,并将它们用作伪标签。作者故意忽略背景预测,因为它们不平衡,并且可能与当前阶段提供的新类别的标签相矛盾。
然后,将旧类别的伪标签与新类别的地面真实标签合并,并使用双分图匹配方法来训练模型,以使模型在联合标签上进行训练。这个方法继承了原始方法的良好特性,确保了标签和假设之间的一对一匹配,并避免了重复检测。
具体步骤如下:
从旧模型的预测中确定一个前景预测的子集 F。这些前景预测是被预测为目标物体的预测。
![]()
?
![]()
?
选择具有最高自信度的 K 个预测,形成 F 的子集 P。这些预测被认为是最有把握的前景预测。
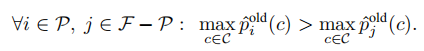
?
进一步限制了前景预测的子集,即 P 的子集 Q ,确保这些预测与新类别的地面真实标签没有太多重叠。
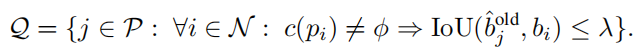
?
保留了一个经过筛选的伪标签集合:
?
从当前标签 y 和旧模型生成的伪标签蒸馏成一个一致的标签集合y^distill,这个集合包括了新类别的对象标签、伪标签和足够多的背景标签,以确保 y^distill 包含 N 个元素:
?
最后,模型通过使用与标准损失相同的训练损失(eq. (1))来训练
?
?
与标准损失的主要区别在于,对于新标签的类别分布 pi 是确定性的,但对于伪标签则不是。因此,知识蒸馏通过使用伪标签可以更全面地传递模型的知识,包括了模型的不确定性,以实现更好的知识传递和学习。
保持分布的校准
Exemplar Replay(ER)方法的基本思想是存储一小部分样本示例(exemplars),然后在未来的训练阶段重放它们,这种思想已被证明在保留旧类别知识方面是有效的。但是,在IOD中,旧类别和新类别的注释之间存在严重的不平衡问题。因此,为了解决上述问题,作者提出了一种选择示例的算法,该方法步骤如下:
选择样本来匹配训练分布:在每个训练阶段,算法会选择一组示例(exemplars),这些示例的选择是通过最小化示例子集
![]()
?
与当前数据子集
![]()
?
的类别分布之间的Kullback-Leibler散度来实现的:
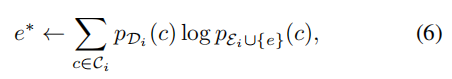
在每个训练阶段,新选择的示例子集与之前的示例子集进行合并,以形成一个新的示例子集。这确保了最终的示例子集的类别分布大致匹配整个训练数据集的类别分布。
使用平衡数据进行训练:在训练模型时,算法分两步进行。第一步,模型使用Detector Knowledge Distillation(DKD)损失函数在所有可用数据(包括当前数据子集
![]()
?
和示例子集
![]()
?
)上进行训练。这一步可以看作是模型的初始训练,虽然使用了丰富的数据,但可能不太平衡。在第二步中,模型使用新的示例子集
![]()
?
进行微调,而不使用当前数据子集
![]()
?
。这一步的目标是进一步改进模型的校准性,因为示例子集已经与类别分布相匹配。
实验
实验结果
?
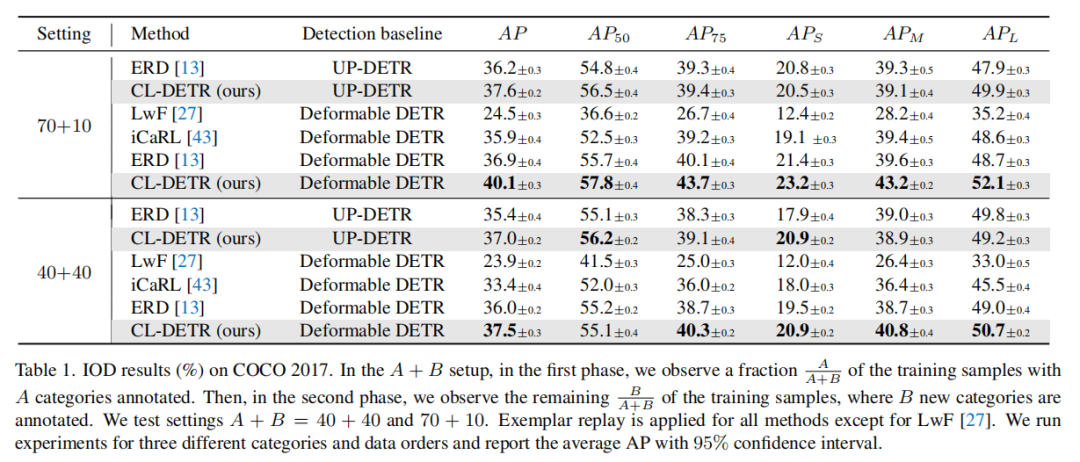
两阶段设置(Two-phase setting):在两阶段设置中,研究人员比较了应用 CL-DETR 到 Deformable DETR 和 UP-DETR 模型的性能。这些设置分为两个阶段,每个阶段有不同数量的目标类别。实验结果表明,在这些设置中,CL-DETR 总体上表现优于其他现有的增量目标检测方法,包括最先进的方法[13]。
例如,在 70+10 和 40+40 的两阶段设置中,Deformable DETR 模型与 CL-DETR 的结合达到了最高的平均精度(AP),分别为 40.1% 和 37.5%。当第一阶段包含更多类别时,性能差距更大,这表明 CL-DETR 更容易受益于一个经过充分预训练的模型。
?
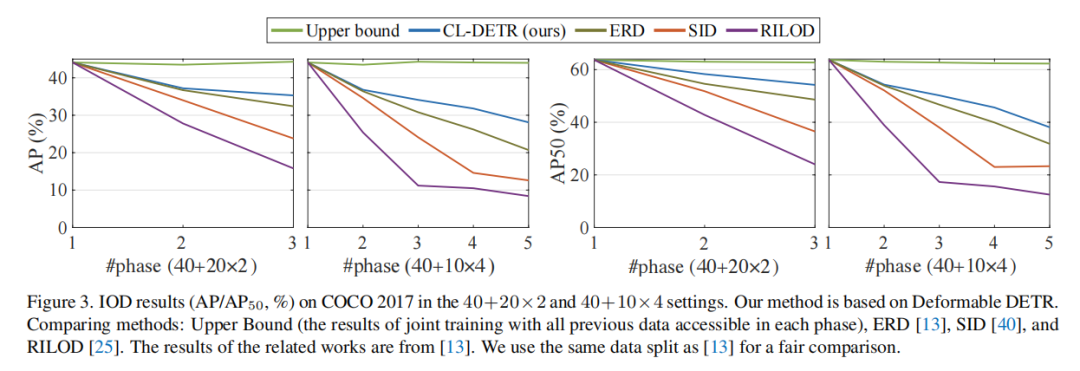
多阶段设置(Multiple-phase setting):在多阶段设置中,研究人员对 CL-DETR 进行了更多的评估,包括 40+20×2 和 40+10×4 这两个实验变种。实验结果显示,CL-DETR 相对于其他增量目标检测方法在这些设置中表现出更大的优势。随着阶段数量的增加,CL-DETR 的相对优势也增加。
例如,在 40+10×4 设置中,CL-DETR 将与方法 [13] 相比,将平均精度(AP)提高了 7.4 个百分点。这表明 CL-DETR 在更具挑战性的设置中表现更出色,因为在这些设置中,由于训练阶段数量较多,遗忘问题更为严重。
消融实验
?
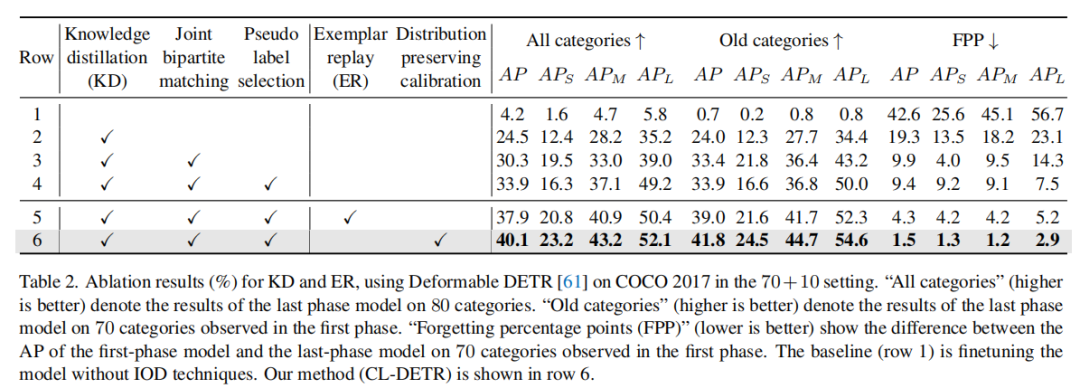
表 2 的1-4行:对于 DKD 方法的消融研究
表 2 的5-6行:对于 ER ?方法的消融研究
?
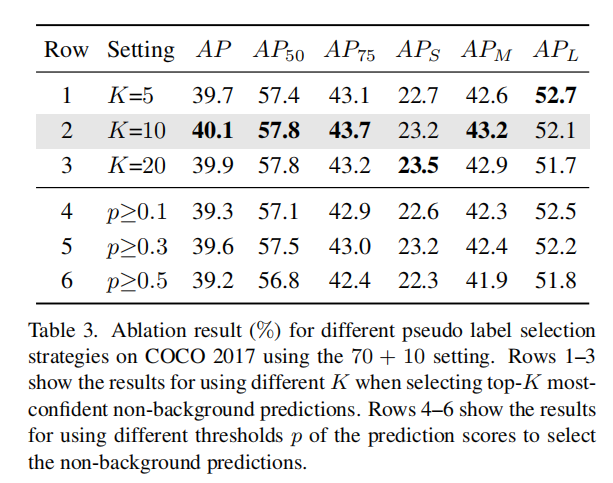
表 3:伪标签选择策略的消融研究
表 3 的1-3行:选择最自信的非背景预测
表 3 的4-6行:使用预测分数的阈值进行预测
可视化结果

?
图 4 展示了在COCO 2017数据集中一些训练样本中的旧类别伪标签(蓝色)和真实标签(绿色)的边界框。
-
在图4(a, b)中,CL-DETR生成准确的伪标签边界框,与真实标签边界框完全匹配。这显示了伪标签选择策略的有效性。这表明在一些情况下,模型能够生成准确的伪标签,从而提高了性能。
-
在图4(c, d)中,当图像中的目标太多时,CL-DETR无法为所有目标生成伪标签边界框。这是因为我们的策略是首先选择前K个最可信的非背景边界框作为伪标签,然后删除与新类别真实标签有过多重叠的边界框。因此,伪标签边界框的数量始终小于K。这种权衡是合理的,因为它在实验中的改进已经得到验证,它更倾向于正确但可能不完整的标注,而不是矛盾或嘈杂的标注。
结论
-
论文引入了一种名为CL-DETR的新型增量目标检测方法,它能够有效地利用知识蒸馏(KD)和示例重放(ER)技术,尤其适用于基于Transformer的检测器。
-
CL-DETR通过引入Detector Knowledge Distillation(DKD)改进了标准KD损失,DKD能够选择最具信息性的旧模型预测,消除冗余的背景预测,并确保蒸馏的信息与新的地面真相一致。
-
CL-DETR还通过选择与训练集分布匹配的示例来改进ER方法,从而提高了性能。
-
该方法具有通用性,可以应用于不同的Transformer-based检测器,包括Deformable DETR和UP-DETR,而且在这些检测器上实现了显著的性能提升。
-
论文还重新定义了一种更加现实的增量目标检测基准测试协议,避免在不同的训练阶段中使用重复的图像。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!