Python进阶(一)
1.Python中一切皆对象
1.1 Python中一切皆对象
JAVA中有class和object这两个概念,object只是class的一个实例。
而在Python中面向对象更加的彻底,class和函数都是对象。代码也是对象,模块也是对象。
函数和类也是对象,对象有四个特性
| 1、赋值给一个变量 |
|---|
| 2、可以添加到集合对象中 |
| 3、可以作为参数传递给函数 |
| 4、可以当作函数的返回值 |
代码演示如下
"""
对象的特性:
1、赋值给一个变量,
2、可以添加到集合对象中,
3、可以作为参数传递给函数,
4、可以当作函数的返回值
"""
def test(name='1'):
print(name)
# 将函数直接赋值给变量 ert
ert = test
ert('2') # 2
class SDFA:
def __init__(self):
print('bobby')
# 将类直接赋值给变量 sdr
sdr = SDFA
sdr() # bobby
# 2、可以添加到集合对象中,
ob_list = []
# 将函数和类都放进来
ob_list.append(test)
ob_list.append(SDFA)
print(ob_list) # [<function test at 0x0000018EEB8BD268>, <class '__main__.SDFA'>]
for i in ob_list:
print(i())
"""
1 来源于test函数
None 如果一个函数没有return值的话,它默认返回的是None,这个None来源于test函数
bobby 来源于SDFA类
<__main__.SDFA object at 0x000001C9ACB592E8> 返回于SDFA类的类对象
"""
# 4.当作函数的返回值
## 函数返回函数,也是装饰器的实现原理
def ask(name='11'):
print(name)
def decorator_fun():
print('我是执行函数')
return ask
myask = decorator_fun() # 返回的是ask函数
myask('JACK') # 相当于ask('JACK')
"""
我是执行函数
JACK
"""
decorator_fun()
"""
我是执行函数
"""
1.2 type、objcet和class的关系
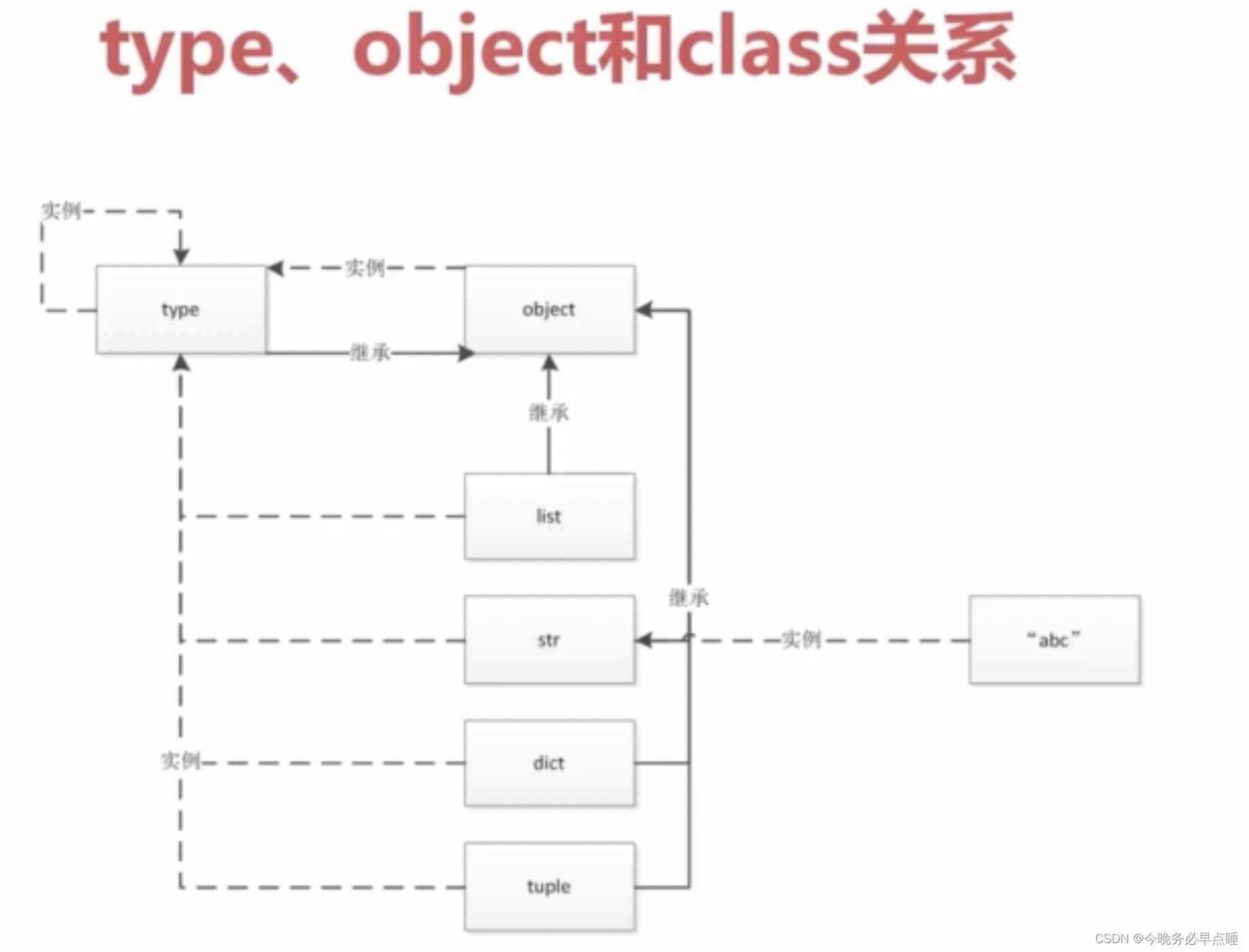
说明:
虚线代表的是实例,
实线代表的是继承关系。
| 1 | object是type的实例,type创建了所有的对象(包括object,list,str,dict,函数,类等等)。 |
|---|---|
| 2 | 所以说list是type的一个实例,还是一个(type的)对象。 |
| 3 | type继承了object,object是所有类的基类。 |
| 4 | type也是自身的实例。(从C角度理解,指针) |
| 5 | type做到了一切皆对象,还做到了一切皆继承object |
| 6 | type的对象还是type,type可以创建所有对象。 |
| 7 | 理解成对象,意味这可修改。函数和类都是可修改 |
演示代码如下:
"""
type的作用:1.生成一个类 2.返回指定对象的类型
"""
a = 1
print(type(1)) # <class 'int'> int类型,class也是一个对象
print(type(int)) # <class 'type'>
# 1是通过int这个类生成的对象,int这个类是通过type这个类生成的对象,即type生成int,int生成1
b = 'abcd'
print(type('abcd')) # <class 'str'>
print(type(str)) # <class 'type'>
# type->class->obj 即type生成class或者object,或者class生成object
class Student:
pass
class MyStudent(Student):
pass
stu = Student()
print(type(stu)) # <class '__main__.Student'>
print(type(Student)) # <class 'type'>
# 查看Student的基类
print(Student.__base__) # <class 'object'>
# 查看MyStudent的基类
print(MyStudent.__base__) # <class '__main__.Student'>
# object是最顶层基类,所有的类推到最后它们的父类都是object类
# type是一个类,也是一个对象。
print(type.__base__) # class 'object'> ,type的基类是object
print(type(object)) # <class 'type'> ,object这个对象或者这个类是通过type这个对象或者这个类生成的
print(object.__base__) # None ,object的基类指向空
1.3 python中常见的内置类型
对象的三个特征:身份,类型,值
身份:对象在内存当中的地址,通过id()函数可查看,eg: a =1, id(a)
类型: 在内存中的类型
值:eg: a= 1,代表a指向1
| 1 | None(全局只有一个) | a= None,b =None,id(a) == id(b) |
|---|---|---|
| 2 | 数值(int,float,complex(复数)、bool) | |
| 3 | 迭代类型 | 可以通过for循环来进行迭代,后面迭代器,生成器讲解 |
| 4 | 序列类型(list,[bytes,bytearray,memoryview(二进制序列)],range,tuple,str,array) | 后面自定义序列类讲解 |
| 5 | 映射(dict) | key,map |
| 6 | 集合(set,frozenset) | set和dict实现原理几乎一致,在判断是否in的时候,优先选择这两个处理时效率较高 |
| 7 | 上下文管理类型with | |
| 8 | 其他 | 包括模块类型,class和实例,函数类型,方法类型,代码类型,object对象,type类型,elipsis类型(省略号类型),notimplemented类型…(导包也是对象类型) |
2.魔法函数
2.1 什么是魔法函数
演示代码如下
"""
以双下划线开头,以双下滑线结尾的函数
魔法函数是用来增加类的
必须要使用Python提供的魔法函数,自己定义的魔法函数没有用
"""
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
# 变成可迭代类型的魔法函数
def __getitem__(self, item):
return self.employee[item]
company = Company(['tom','bury','jack'])
# 没用魔法函数,遍历员工时
# emloyee = company.employee
# for em in emloyee:
# print(em)
# 定义了getattr的魔法函数之后
for em in company:
print(em)
"""
tom
bury
jack
"""
# 此时,如果把魔法函数注释,报
"""
Traceback (most recent call last):
File "E:/code/20230709/chapter01/company.py", line 20, in <module>
for em in company:
TypeError: 'Company' object is not iterable
"""
2.2 Python的数据模型以及数据模型对Python的影响
魔法函数会直接影响Python语法本身
通过自己内置的魔法函数,让我们去定义一些对象或者类的时候,它的行为可以变的很神奇。
魔法函数都是Python自己提供好了的,自己不能随便定义
演示代码如下:
"""
以双下划线开头,以双下滑线结尾的函数
魔法函数是用来增加类的
必须要使用Python提供的魔法函数,自己定义的魔法函数没有用
"""
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
# 变成可迭代类型的魔法函数
def __getitem__(self, item):
return self.employee[item]
def __len__(self):
# return len(self.employee)
return 3
company = Company(['tom','bury','jack'])
# 没用魔法函数,遍历员工时
len(company)
company1 = company[:2] # ['tom', 'bury']
print(company1)
# 没加len魔法方法之前
"""
Traceback (most recent call last):
File "E:/code/20230709/chapter01/company.py", line 17, in <module>
len(company)
TypeError: object of type 'Company' has no len()
"""
# 加了len之后
print(len(company))
"""
3
"""
# 由此看到,先找len魔法函数,再找getiem魔法函数
2.3 Python的魔法函数一览
两种交互环境
ipython # linux常用,windows也很方便
notebook # 安装方式:pip install notebook
# 运行方式:ipython notebook
(也可以用ancoda方式启动,之前数据分析时介绍过)
效果如下
魔法函数分为非数字运算和数字运算
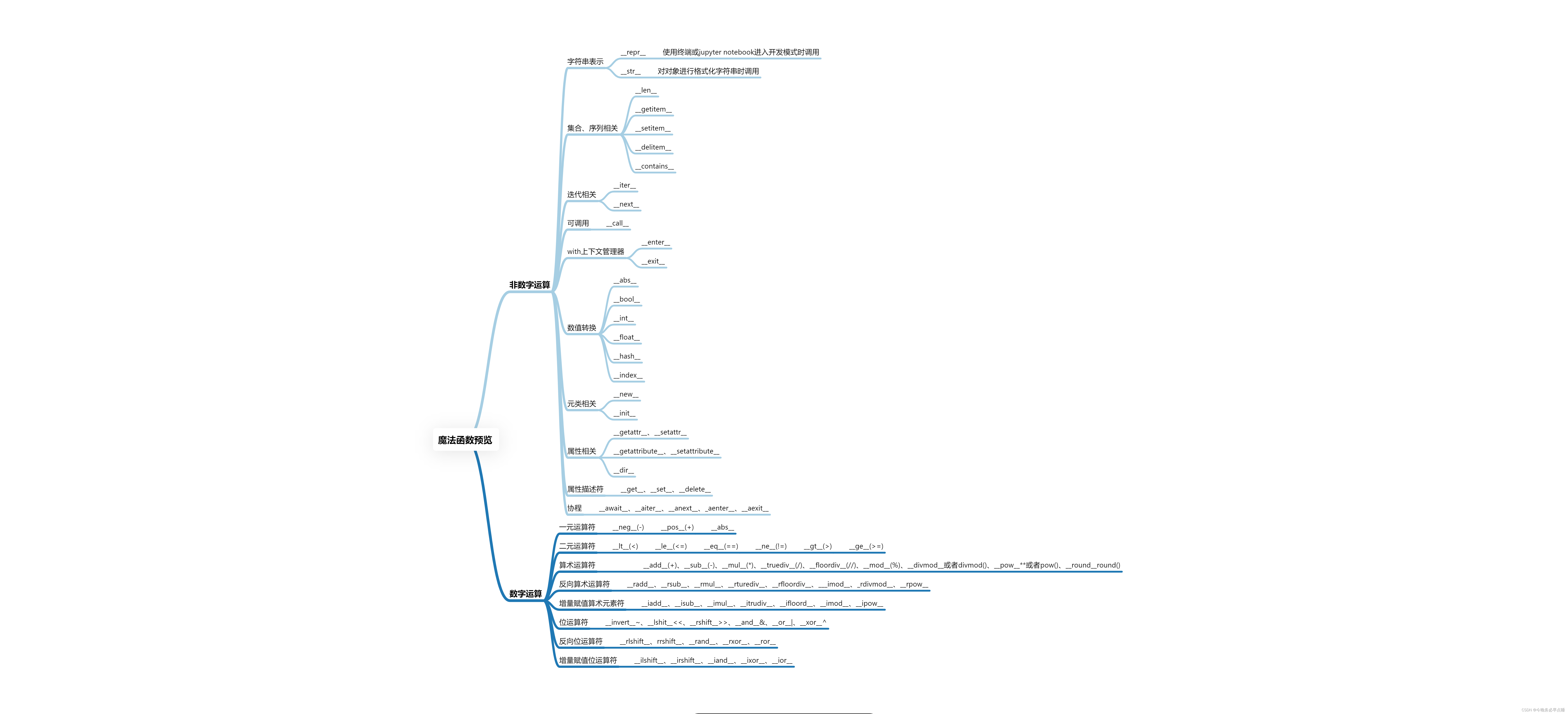
2.3.1 非数学运算
代码块
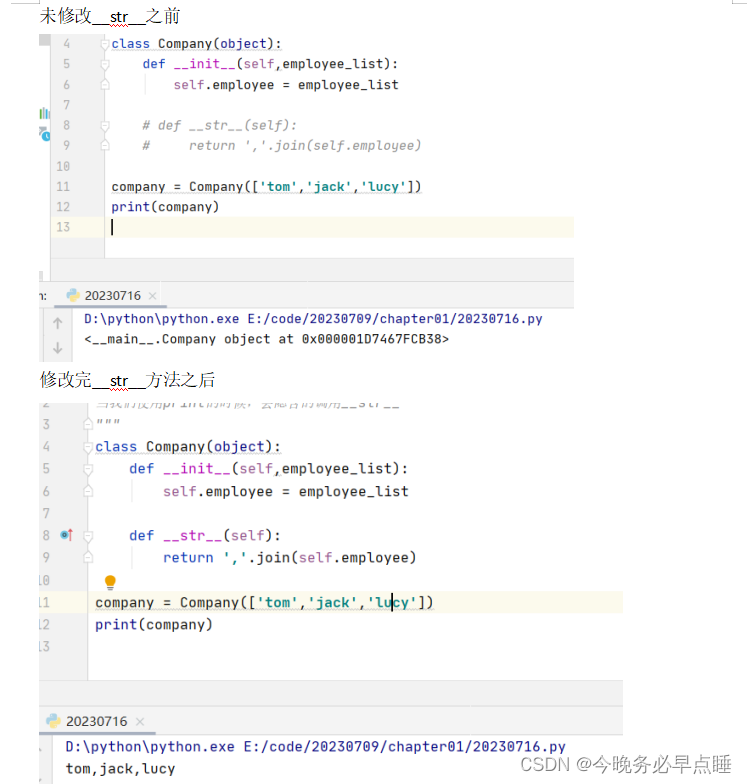
"""
当我们使用print的时候,会隐含的调用__str__
魔法函数跟继承类没有关系,任何类都可以写入魔法函数
魔法函数定义之后不用自己调用,python本身使用的时候会默认调用魔法函数
"""
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
# def __str__(self):
# return ','.join(self.employee)
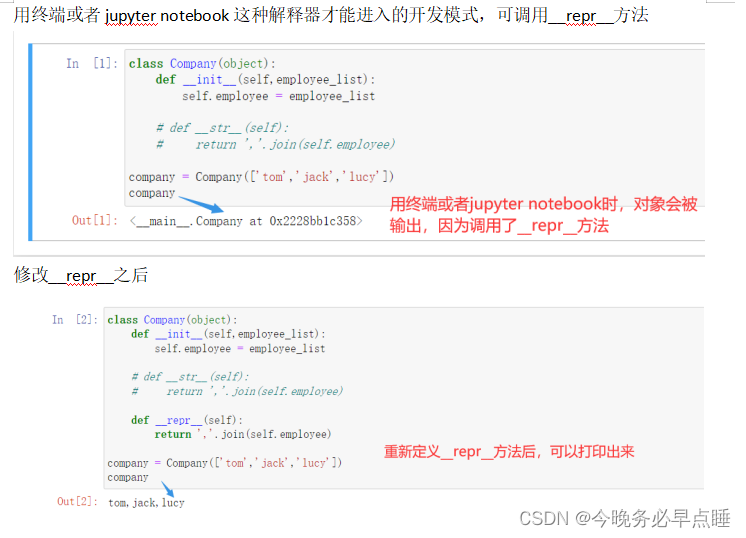
company = Company(['tom','jack','lucy'])
print(company)
示图
代码块二
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
# def __str__(self):
# return ','.join(self.employee)
def __repr__(self):
return ','.join(self.employee)
company = Company(['tom','jack','lucy'])
company # 相当于company.__repr__(),python本身会自己调用
示图
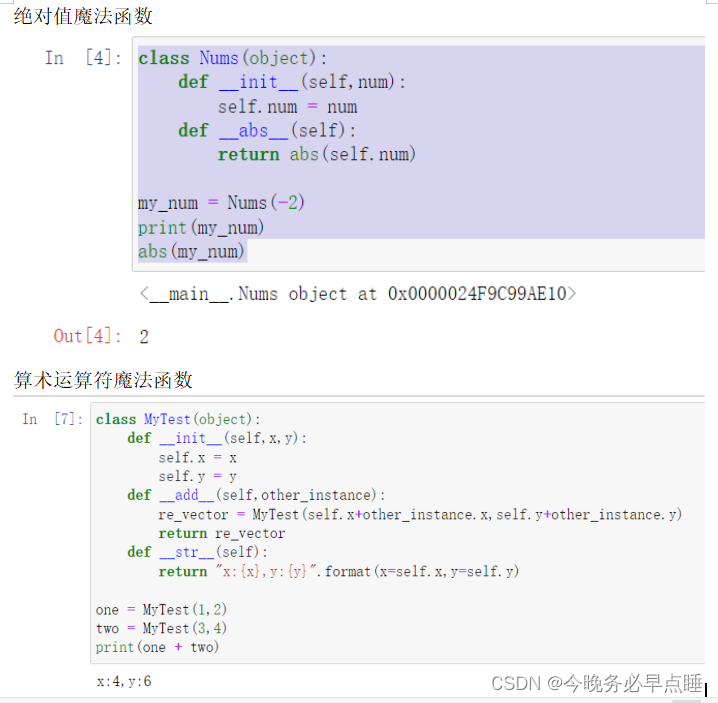
2.3.2 数学运算
代码块1
class Nums(object):
def __init__(self,num):
self.num = num
def __abs__(self):
return abs(self.num)
my_num = Nums(-2)
print(my_num)
abs(my_num)
代码块2
class MyTest(object):
def __init__(self,x,y):
self.x = x
self.y = y
def __add__(self,other_instance):
re_vector = MyTest(self.x+other_instance.x,self.y+other_instance.y)
return re_vector
def __str__(self):
return "x:{x},y:{y}".format(x=self.x,y=self.y)
one = MyTest(1,2)
two = MyTest(3,4)
print(one + two)
演示效果如下
2.3.3 重点了解len方法
当我们在len()里面涉及python六大数据结构(list、dict、set、tuple、str、int)的时候,会直接读取C语言的数据来表示它的长度,即会直接读取一个数,而不会遍历数据。所以尽量使用python原生的类型,对性能很高。
比如for循环的时候,先去调用__iter__获取迭代器,如果没有__iter__时,又回去找__getitem__调用并处理抛出来的异常。
2.3.4 小节
| 1.双下划线开头,双下划线结尾 |
|---|
| 2.名称比较固定,不能自己定义 |
| 3.只需要定义魔法函数,魔法函数不需要调用,python解析器内部会自己调用。 |
| 4.魔法函数和对象直接不存在继承关系,在任何对象都可以定义魔法函数。 |
3.类和对象
3.1 鸭子类型和多态
鸭子类型:当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。
举例一
"""
python多态实现:1.多个类有共同的,同一个方法(say方法),
鸭子类型:我们所有的类都实现了一个共同的方法,这个方法名要一样。这样把这些类就可以归为一种类型,这样在调用的时候,就可以同时调用这个方法(say方法)
特别注意:python的变量可以指向任何一个类型
"""
class Cat(object):
def say(self):
print('i am a cat')
class Dog(object):
def say(self):
print('i am a dog')
class Duck(object):
def say(self):
print('i am a duck')
# 将类直接赋值给变量 写法
# 等同于
# animal = Cat()
# animal.say()
# 而在python中实现多态就比较简单,变量是动态的变量,可以指向任何一个类型,这是静态语言和动态语言最大的区别。
# 在python中,不需要继承任何一个父类,只需要一件事,要有相同的方法(say方法),
animal = Cat
animal().say() # i am a cat
# 也可以写成
animal_list = [Cat,Dog,Duck]
for animal in animal_list:
animal().say()
"""
i am a cat
i am a dog
i am a duck
"""
# # 在java中如何实现多态
# class Animal:
# def say(self):
# print('i am animal')
#
# class Cat(Animal):
# def say(self):
# print('i am a cat')
#
# # 在java或者c++等静态语言当中,为了实现多态,定义一个父类,实例化传值的时候传子类
# animal an = Cat()
# an.say()
# # 如上,在java中如何要实现多态,1.子类要继承父类,2.必须要重写父类的方法,
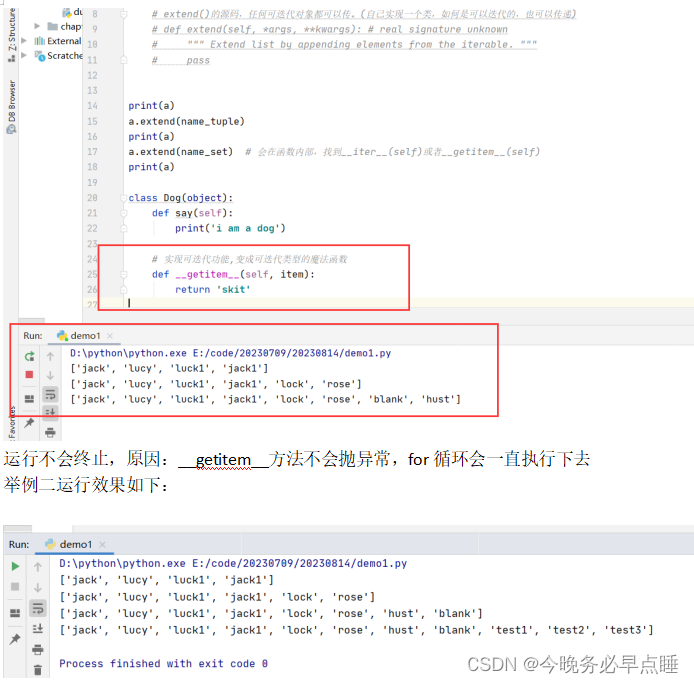
举例二
a = ['jack','lucy']
b = ['luck1','jack1']
name_tuple = ['lock','rose']
name_set = set()
name_set.add('blank')
name_set.add('hust')
a.extend(b)
# extend()的源码,任何可迭代对象都可以传。(自己实现一个类,如何是可以迭代的,也可以传递)
# def extend(self, *args, **kwargs): # real signature unknown
# """ Extend list by appending elements from the iterable. """
# pass
print(a)
a.extend(name_tuple)
print(a)
a.extend(name_set) # 会在函数内部,找到__iter__(self)或者__getitem__(self)
print(a)
class Dog(object):
def say(self):
print('i am a dog')
# 实现可迭代功能,变成可迭代类型的魔法函数
def __getitem__(self, item):
return 'skit'
# dog = Dog()
# a.extend(dog)
# print(a) # 运行不会终止,原因:__getitem__方法不会抛异常,for循环会一直执行下去
# 用之前可以抛异常的案例演示
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
def __len__(self):
return len(self.employee)
company = Company(['test1','test2','test3'])
a.extend(company)
print(a)
"""
从侧面验证了鸭子类型,比如__getitem__方法并不一定继承某个类,可以把这个函数塞到任何一个函数对象当中,不需要这个对象有什么前置条件,都可以塞进来。
实际魔法函数正是充分利用了鸭子类型,在很多对象当中去,去写入魔法函数,这些魔法函数,就可以被python解释器本身识别,在python内置的对象或者内置类中,都有很多特性,
比如有了__getitem__方法,就有了可迭代的特性,实现了__iter__和__next__,它就是一个迭代的类型。实现了__call__方法,它就是一个可调用特性,实现了__enter__和__exit__.它
就有了with上下文管理器的特性。
通过魔法函数,将python对象类型进行分组,有了这些分组,应用起来就非常灵活。
"""
效果如下
3.2 抽象基类(abc模块)
1.在基础类当中,我们去设定好一些方法,所有的继承基类的类都必须覆盖这个抽象基类的方法。
2.抽象基类是无法实例化的
举例代码1
"""
两种场景
"""
# 1.检查Company是否有长度的类型
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
def __len__(self):
return len(self.employee)
test1 = Company(['one','two','there','four'])
print(len(test1)) # 4 这个代表Company是可以计算长度的
# 如果把上面定义的len()注释掉,则上行代码会报错
# hasattr() 判断某个对象是否有某种属性
print(hasattr(test1,'__len__')) # True 即可以判断Company是有len这个属性的
# isinstance() 判断某个对象或者某个类,它是否是指定的类型
# 场景1:在某些情况下,希望判定某个对象的类型,
# 场景2:需要强制某个子类必须实现某些方法。,比如实现了一个web框架,集成缓存(redis或者cache或者memorychache),来自定义组件可以替换cache
# 此时就需要设定一个抽象基类,指定子类必须实现某些方法
# 例如
# class CacheBase():
# def get(self,key):
# pass
# def set(self,key,value):
# pass
# 用户在调用CacheBase时,必须强制实现这两个方法
# 如何去模拟一个抽象基类
class CacheBase():
def get(self,key):
raise NotImplementedError
def set(self,key,value):
raise NotImplementedError
class RedisCache(CacheBase):
pass
redis_cache = RedisCache()
# redis_cache.set() # TypeError: set() missing 2 required positional arguments: 'key' and 'value'
# 如果在子类中实现,它就不会抛异常
class RedisCache1(CacheBase):
def set(self,key,value):
pass
redis_cache1 = RedisCache1()
redis_cache1.set('1','2') # 此时不会抛异常
# 上述代码只有在调用方法的时候才能抛出异常,如何在初始化对象的就抛出异常呢?
import abc
class CacheBase1(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self,key):
pass
@abc.abstractmethod
def set(self,key,value):
pass
# 案例2
# class RedisCache2(CacheBase1):
# pass
#
# redis_cache2 = RedisCache2() # TypeError: Can't instantiate abstract class CacheBase1 with abstract methods get, set
# # 此时会报出需要实现get 和set方法
# 修改为
class RedisCache3(CacheBase1):
def set(self):
pass
def get(self):
pass
redis_cache2 = RedisCache3() # 此时正常
举例代码2
"""
案例 我们在某些情况下希望判定某个对象的类型
"""
from collections.abc import Sized
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
def __len__(self):
return len(self.employee)
com = Company(['one','two'])
# 检查某个类是否有某种方法 hasattr
print(hasattr(com,"__len__")) # True
isinstance(com,Sized)
print(isinstance(com,Sized)) # True,本质是判断com里面有没有__len__方法
""" 上行代码中,会用到collections.abc的__subclassshook__方法
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
return _check_methods(C, "__len__")
return NotImplemented
"""
class A:
pass
class B(A):
pass
b = B()
isinstance(b,A)
print(isinstance(b,A)) # True
# 可以看到,isinstance不仅仅会调用__subclassshook__方法,还会去做其他尝试,从b中找到B,判断B和A是不是相等。
"""
总结,在Python中,抽象基类有两个用途
1.用isinstance去做比较
2.用来做接口的强制规定,指定子类必须实现某些方法,如举例代码块的案例二内容
"""
不推荐实战应用,主要用来理解
3.3 isinstance和type的区别
"""
isinstance和type的区别
"""
class A:
pass
class B(A):
pass
b = B()
# 判断b是否为B的类型
print(isinstance(b,B)) # True
# 判断b是否为A的类型
print(isinstance(b,A)) # True 因为A是B的父类,实际上b也是A中的一种类型
# 因为isinstance回去检查所要判断类型的继承链
print(type(b)) # <class '__main__.B'>
print(type(b) is B) # True
# is 与 ==的区别;
# is是判断id是否相同,判断对象是否相同
# == 是判断值是否相等
print(type(b) is A) # False 因为type(b)指向的是B对象,A对象和B对象是不同的id,即不同的id
print(id(A),id(B)) # 2326128882168 2326128883112
"""
总结,判断类型是否相等,尽量用isinstance去判断
"""
# 补充
"""
`isinstance` 和 `type` 都是 Python 中用于判断对象类型的函数,它们之间有一些区别。
1. `type(object)` 函数返回对象的类型,可以用来判断一个对象的确切类型。例如:
x = 5
print(type(x)) # 输出:<class 'int'>
2. `isinstance(object, classinfo)` 函数用于检查一个对象是否是指定类或其子类的实例。这意味着它可以用来检查一个对象是否属于某个类或其派生类。例如:
```python
x = 5
print(isinstance(x, int)) # 输出: True
print(isinstance(x, float)) # 输出: False
```
总结一下,`type` 函数用于获取对象的类型,而 `isinstance` 函数用于检查对象是否是某个类或其派生类的实例。通常情况下,
建议使用 `isinstance` 来进行类型检查,因为它更加灵活,能够应对继承关系。
"""
3.4 类变量和对象变量
"""
类变量和对象变量
"""
class A: # 此处相当于class A(object): 它会默认继承object
aa = 1 # 这里的aa是类变量
def __init__(self,x,y):
# self指的是类的实例,它自己
self.x = x # 实例的x接收的是传进来的x
self.y = y # 实例的y接收的是传进来的y
a = A(3,6)
print(a.x,a.y,a.aa) # 3 6 1
# a.aa中,a是一个实例,aa是一个类变量,为什么会查到1,因为是因为属性的查找方式,先在对象变量中查找,如果查找不到在类变量中查找,向上查找
print(A.aa) # 1 此处隐含的意思是aa要通过类的方式来访问
# print(A.x) # AttributeError: type object 'A' has no attribute 'x'
# a是A的实例,A是一个类,它不会去它的实例里面查找,即不会向下查找
# 若修改A.aa =11
A.aa= 11
print(a.x,a.y,a.aa) # 3 6 11
print(A.aa) # 11
# 去修改类变量后,相关属性查找到这个变量后,它也会跟着变
# 若修改a.aa = 100
a.aa = 100
print(a.x,a.y,a.aa) # 3 6 100
print(A.aa) # 11
# 实例.属性赋值语句时,会把值赋给实例,实际上是类中多了一个属性,相当于实例a中多了一个属性,A.aa和a.aa不一样
# 即:A.aa修改的是类的属性,a.aa增加的是实例的属性
"""
在类里面定义的变量叫做类变量,上面的aa
在定义在类的方法中(通常是 __init__ 方法)的变量,上面的x,y
"""
b = A(3,5)
print(b.aa) # 11 此处不是1而是11的原因,类变量在整个类的所有实例之间共享,可以被所有实例访问和修改。它通常用于表示该类的所有实例共有的属性。
# 拓展
"""
在 Python 中,类变量和对象变量是面向对象编程中的重要概念,它们分别属于类和类的实例(对象),有着不同的作用和生命周期。
### 类变量
**定义**:类变量是定义在类中,但在任何类方法之外的变量。它属于类本身,而不是类的实例。
**作用**:类变量在整个类的所有实例之间共享,可以被所有实例访问和修改。它通常用于表示该类的所有实例共有的属性。
**示例**:
```python
class Car:
wheels = 4 # 这里的wheels就是一个类变量
car1 = Car()
print(car1.wheels) # 输出: 4
car2 = Car()
print(car2.wheels) # 输出: 4
Car.wheels = 6 # 修改类变量
print(car1.wheels) # 输出: 6
print(car2.wheels) # 输出: 6
```
### 对象变量
**定义**:对象变量是定义在类的方法中(通常是 `__init__` 方法)的变量,每个类的实例都有自己的一组对象变量。
**作用**:对象变量用于存储特定实例的状态或属性,每个实例都拥有自己的对象变量副本。
**示例**:
```python
class Car:
def __init__(self, color):
self.color = color # 这里的color就是一个对象变量
car1 = Car("red")
print(car1.color) # 输出: "red"
car2 = Car("blue")
print(car2.color) # 输出: "blue"
```
总结一下,类变量是属于类本身的变量,所有实例共享;而对象变量是属于实例的变量,每个实例拥有独立的一组对象变量。理解和使用好类变量和对象变量对于设计良好的面向对象程序至关重要。
"""
3.5 类属性和实例属性以及查找顺序
3.5.1 Python算法历史
举例一
"""
类和实例属性的查找顺序
"""
class A: # 实际类A也是对象
name = 'A_value' # 类变量
test = 'b_value'
def __init__(self):
self.name = 'obj' # 对象变量
self.te = 'te'
a = A() # 实例a本身有自己的属性
# 此时,A_value是类A的变量,obj是实例a的变量(属性)
print(a.name) # obj 查找顺序是由下而上,可以金类属性
print(a.test) # b_value
print(A.name) # A_value
# print(A.te) # AttributeError: type object 'A' has no attribute 'te'
"""
实例属性由下而上依次查找,可以进类属性
类属性由上而下,不可以进入实例属性查找
"""
# 拓展
"""
在 Python 中,当你访问一个类实例的属性时,Python 会按照特定的顺序进行查找。这个顺序通常被称为“属性查找顺序”,它涉及到类属性、实例属性以及继承关系。属性查找顺序如下:
1. **实例属性**:首先,Python 会检查实例对象本身是否具有对应名称的属性。如果实例对象包含了这个属性,那么将直接返回实例属性的值。
2. **类属性**:如果实例属性中没有找到对应的名称,Python 将会去类定义中查找是否存在同名的类属性。如果类属性存在,那么将返回类属性的值。
3. **父类属性**:如果类属性中也没有找到对应的名称,Python 将会在父类(如果存在继承关系)中查找是否存在同名的属性。它会沿着继承链依次检查父类,直到找到对应的属性或者到达继承链的顶端。
这种属性查找顺序保证了在 Python 中可以实现面向对象编程中的继承和多态特性。如果在子类中重写了父类的属性,Python 会按照上述顺序来查找属性,从而确保使用正确的属性值。
下面是一个简单的示例来演示属性查找顺序:
```python
class A:
x = "Class A"
class B(A):
y = "Class B"
obj = B()
print(obj.x) # 首先查找实例属性,然后查找类属性,输出:"Class A"
```
在这个示例中,我们创建了两个类 A 和 B,B 是 A 的子类。当我们通过 B 的实例 obj 访问属性 x 时,Python 首先会查找实例属性,然后查找类属性,最终输出 "Class A"。
"""
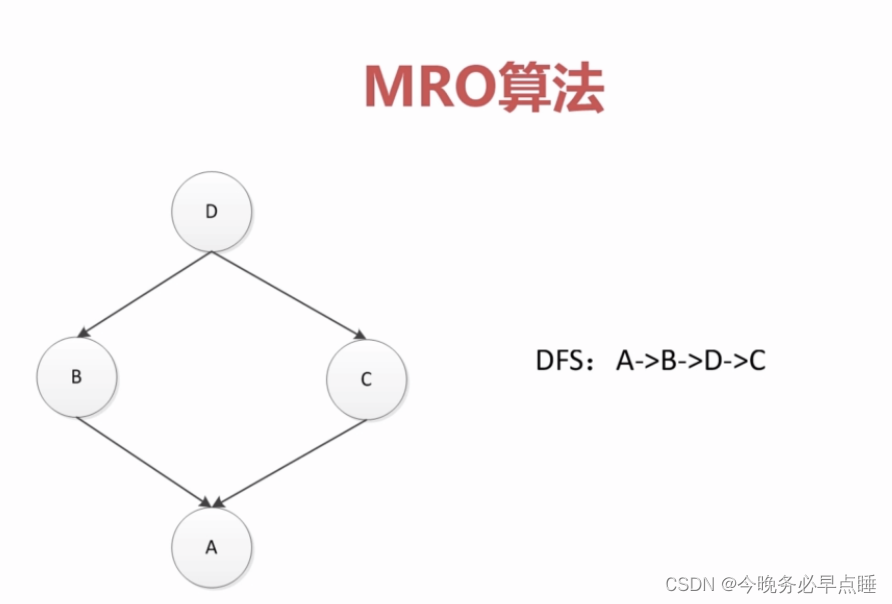
python1的时候,深度优先的算法
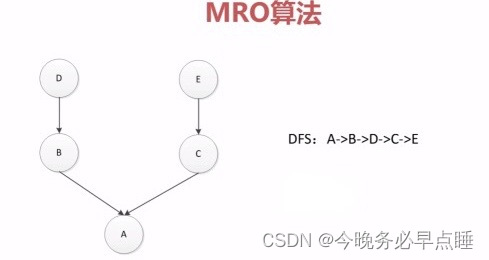
MRO(Method Resolution Order)算法是用于确定在多重继承的情况下,Python 中方法的查找顺序的算法。MRO 算法的实现采用 C3 线性化算法,它确保了在多重继承时能够准确地确定方法的查找顺序,避免了出现歧义和不一致性。
MRO 算法的核心思想是通过一系列的规则来确定方法的查找顺序,具体步骤如下:
-
每个类都有一个 Method Resolution Order 列表(MRO 列表),用于存储方法查找顺序。
-
子类的 MRO 列表中会包含父类的 MRO 列表,并且在子类 MRO 列表中父类的顺序要排在前面。
-
MRO 列表中的顺序遵循以下原则:
- 子类会优先于父类被搜索。
- 多个父类按照它们在类定义中出现的顺序被搜索。
-
算法会根据以上原则生成一个满足所有条件的线性化列表作为最终的 MRO 列表,如果无法满足条件则会抛出错误。
Python 使用这个 MRO 列表来确定方法的查找顺序,保证了在多重继承的情况下能够正确地确定方法的调用顺序,从而避免了歧义和不确定性。
下面是一个简单的示例来演示 MRO 算法的应用:
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
print(D.mro()) # 输出 MRO 列表
在这个示例中,我们创建了四个类 A、B、C 和 D,其中 D 是 B 和 C 的子类。通过调用 D.mro() 方法,我们可以查看 D 类的 MRO 列表,从而了解在方法查找时的顺序。
效果如下
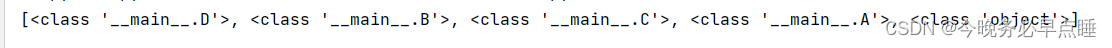
再写一个示例,A继承于B,C,B继承于D, 而C继承于E 。
class D:
def method(self):
print("D's method")
class E:
def method(self):
print("E's method")
class B(D):
def method(self):
print("B's method")
super().method()
class C(E):
def method(self):
print("C's method")
super().method()
class A(B, C):
def method(self):
print("A's method")
super().method()
obj = A()
obj.method()
在这个示例中,类 D 和类 E 分别定义了一个名为 method 的方法。类 B 继承于类 D,类 C 继承于类 E。最后,类 A 继承于类 B 和类 C。
当我们创建 A 的实例 obj 并调用 obj.method() 时,根据 MRO 算法的规则,Python 会按照以下顺序查找和调用方法:
- 首先,Python 在 A 类中查找
method方法,如果找到则调用。 - 如果在 A 类中没有找到
method方法,则按照 MRO 列表的顺序依次查找父类。在这里,MRO 列表为[A, B, C, D, E]。 - Python 在 B 类中查找
method方法,由于 B 类继承于 D 类,所以会调用 D 类中的method方法,并输出 “D’s method”。 - 接下来,Python 在 C 类中查找
method方法,由于 C 类继承于 E 类,所以会调用 E 类中的method方法,并输出 “E’s method”。
因此,最终的输出结果为

代码示例(上图的例子)
当一个类继承自多个父类,并且这些父类之间也存在继承关系时,MRO 算法可以帮助确定方法的查找顺序。以下是相应的示例代码:
class E:
pass
class D(E):
pass
class B(D):
pass
class C(E):
pass
class A(B, C):
pass
print(A.mro()) # 输出 MRO 列表
效果如下
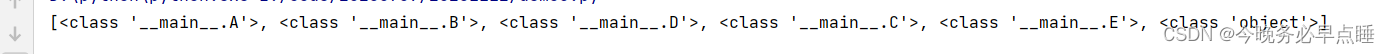
拓展
存在问题:对于深度优先的算法,当存在菱形关系时,C可能永远无法查到
所以在Python2之后,修改了深度优先算法,调整为广度优先算法
案例:
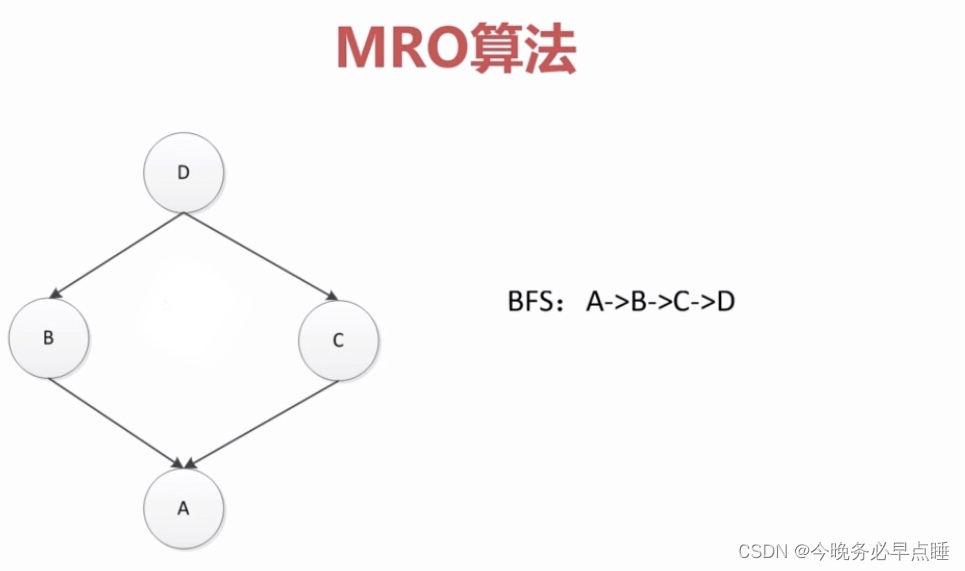
如图所示,先搜索A,搜不到的情况下,再搜索B,再搜索C,最后再搜索D
案例:
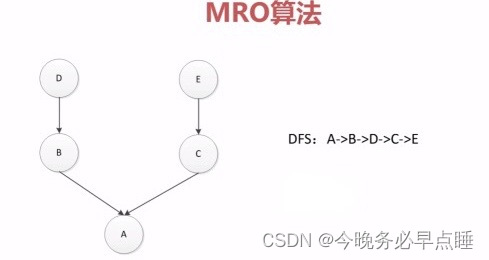
如果广度优先的时候,会出现一个问题
当C和D中有一个同名方法的时候,例如都有一个get方法,如果在B中搜不到get方法,则会去搜索C的get方法,但是C没有继承D,B继承了D,C的方法会覆盖掉D,所以MRO算法在Python2.3后被取代,之后的算法统一成了一种算法,叫做C3算法。
3.5.2 C3算法
C3算法是一种广泛使用的用于确定多重继承中方法解析顺序的算法。在Python中,多重继承会导致方法解析顺序的复杂性,C3算法通过一系列规则来确定合理的方法解析顺序,以避免歧义和不一致性。
C3算法的核心思想包括以下几点:
- 子类的方法解析顺序要优先于父类。
- 如果有多个父类,应该按照它们在类定义中出现的顺序进行搜索。
- 在搜索过程中,不能破坏这些顺序。也就是说,在搜索过程中,不能改变任何一个父类的顺序。
通过这些规则,C3算法可以生成一个满足条件的线性化列表,作为最终的方法解析顺序。
在Python中,C3算法被应用于多重继承的情况,确保方法的查找顺序是一致的、合理的,并且能够避免潜在的歧义问题。
下面是一个简单的示例来演示C3算法的应用:
class E:
pass
class D(E):
pass
class B(D):
pass
class C(E):
pass
class A(B, C):
pass
print(A.mro()) # 输出 MRO 列表
在这个示例中,我们创建了五个类 E、D、B、C 和 A。类 A 继承自类 B 和类 C,同时类 B 继承自类 D,而类 C 继承自类 E。通过调用 A.mro() 方法,我们可以查看类 A 的MRO列表,从而了解C3算法确定的方法解析顺序。
效果如下
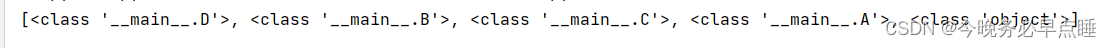
举例
在菱形继承关系中,一个类同时继承自两个其他类,而这两个其他类最终继承自同一个共同的基类,形成了菱形状的继承结构。这种情况下,如果不加以处理,可能会导致方法解析顺序出现歧义。
Python 中使用 C3 算法来解决菱形继承带来的问题。C3 算法通过一系列规则来确定合理的方法解析顺序,以避免歧义和不一致性。
下面是一个简单的示例来演示菱形继承中 C3 算法的应用:
class A:
def do_something(self):
print("Method defined in class A")
class B(A):
pass
class C(A):
def do_something(self):
print("Method defined in class C")
class D(B, C):
pass
d = D()
d.do_something() # 输出 "Method defined in class C"
在这个示例中,类 A 定义了一个名为 do_something 的方法,而类 B 和类 C 分别继承自类 A,类 D 继承自类 B 和类 C。当创建类 D 的实例并调用 do_something 方法时,根据 C3 算法确定的方法解析顺序,最终调用的是类 C 中定义的方法。这样就避免了菱形继承带来的歧义问题。
效果如下:

通过使用 C3 算法,Python 能够有效地处理菱形继承关系,确保方法解析顺序是一致的、合理的,从而避免潜在的歧义问题。
【举例】
问题1:
如果A继承B,B继承D,A也继承C,C继承E,假如C和D中有同名方法,先继承的是哪个 ?
解答:
在这种情况下,如果类 A 继承自类 B,而类 B 继承自类 D,同时类 A 也继承自类 C,而类 C 继承自类 E。如果类 C 和类 D 中有同名方法,那么根据 C3 算法的规则,先继承的是类 C 中的方法。
C3 算法会保证在多重继承的情况下,按照一定的顺序去搜索方法,确保继承关系的一致性和合理性。因此,如果类 A 继承自类 B 和类 C,而类 C 和类 D 中有同名方法,那么在实例化类 A 并调用该方法时,将会优先调用类 C 中定义的方法。
这样的设计可以帮助避免歧义,并确保在多重继承的情况下能够正确地确定方法的解析顺序。
问题2:
如果A继承B,B继承D,A也继承C,C继承E,假如C和D中有没有同名方法,什么继承顺序
解答:
在这种情况下,如果类 A 继承自类 B,而类 B 继承自类 D,同时类 A 也继承自类 C,而类 C 继承自类 E,并且类 C 和类 D 中没有同名方法,那么根据 C3 算法的规则,方法解析顺序可以按照以下顺序确定:
- 首先考虑当前类的父类,然后再考虑父类的父类,以此类推,直到最顶层的基类。
- 对于具有相同父类的两个类,先考虑继承列表中排在前面的父类。
- 保持搜索顺序的一致性,避免出现循环继承的情况。
根据上述规则,可以得出类 A 方法解析顺序的一个可能结果:
A -> B -> D -> C -> E
在这个方法解析顺序下,如果在类 A、B、D、C 和 E 中存在同名方法,将会按照这个顺序去搜索并调用方法。由于类 C 和类 D 中没有同名方法,因此在这种情况下,方法解析顺序不会引起歧义,并且能够按照一定的顺序来确定方法的调用顺序。
3.5.3 验证菱形查找问题解决
"""
解决菱形查找问题
"""
class D:
pass
class C(D):
pass
class B(D):
pass
class A(B,C):
pass
print(A.__mro__) # 属性的查找顺序 [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]
"""
python2的时候,如果类定义的时候,不叫object,它是不会去继承object的,python3的时候,写与不写也会统一去继承object,叫做新式类
"""
# 或者用方法
print(A.mro()) # [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]
【总结】
判断多继承的查找顺序,用A.mro()判断即可。Python3中都统一用了C3算法。
3.6 静态方法、类方法以及实例方法(对象方法)
代码举例
"""
类方法,静态方法和实例方法
一般情况下,在类中定义的方法都是实例方法
"""
class Date:
# 构造方法
def __init__(self,year,month,day):
self.year = year
self.month = month
self.day = day
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year,month=self.month,day=self.day)
def tomorrow(self):
self.day += 1 # 注意此处,修改了实例的变量,如果想修改类的变量,此处应写成Date.day += 1
return self.day
@staticmethod
def parise_from_string(date_str): # 此处不用穿类
year, month, day = tuple(date_str.split("-"))
new_day = Date(int(year),int(month),int(day)) # 当类名变化时,Date得手动改变,俗称硬编码
return new_day
@classmethod
def from_string(cls,date_str): # 此处cls传递的类本身
year, month, day = tuple(date_str.split("/"))
new_day =cls(int(year), int(month), int(day)) # 当类名变化时,Date不需要手动改动,俗称软编码
return new_day
# 判断是否合法的输入参数,此时没必要传入类
@staticmethod
def vaild_str(date_str):
year, month, day = tuple(date_str.split("/"))
if int(year)>0 and (int(month) > 0 and int(month) <=12) and int(day) > 0 and int(day) <= 30:
return True
else:
return False
if __name__ == '__main__':
new_day = Date(2023,12,12)
print(new_day) # 2023/12/12
new_day.tomorrow() # 此处调用时,python解释器会自动转换成tomorrow(new_day)进行调用执行
print(new_day.tomorrow()) # 14
# 目前调用Date需要三个参数,如何实现只传递一个参数呢,例如传递字符串2024-01-01
# # --------------逻辑开始,这里可以用静态方法实现--------------------
# date_str = '2024-01-01'
# year,month,day = tuple(date_str.split("-"))
# print(year,month,day) # 2024 01 01
# new_day = Date(int(year),int(month),int(day))
# print(new_day)
# # -------------逻辑结束------------------------
# 静态方法的调用 类名.静态方法 优势,重复的方法更加简化,更容易理解
print(Date.parise_from_string('2024-01-02'))
# 类方法的调用 类名.类方法
print(Date.from_string('2024/01/03'))
# 判断是否合法的输入参数
print(Date.vaild_str('2024/1/01')) # True
补充
在 Python 中,有三种不同类型的方法:实例方法、类方法和静态方法。它们各自有不同的特点和应用场景:
- 实例方法(Instance Method):
- 实例方法是最常见的方法类型,在方法定义中第一个参数通常被命名为
self,代表对类实例的引用。 - 实例方法可以访问并操作实例的属性,并且可以通过
self参数来调用其他实例方法。 - 应用场景:当需要操作或者修改对象的属性时,通常会使用实例方法。实例方法可以直接访问实例的属性,并且可以操作实例的状态。
- 实例方法是最常见的方法类型,在方法定义中第一个参数通常被命名为
class MyClass:
def instance_method(self):
# 这是一个实例方法
self.some_attribute = "some value"
return self.some_attribute
obj = MyClass()
print(obj.instance_method()) # 调用实例方法
- 类方法(Class Method):
- 类方法使用
@classmethod装饰器进行修饰,第一个参数通常被命名为cls,代表对类的引用。 - 类方法可以访问类的属性,并且可以通过
cls参数调用其他类方法。 - 应用场景:当需要操作类的属性而不是实例的属性时,通常会使用类方法。类方法可以用于创建工厂方法、修改类属性等场景。
- 类方法使用
class MyClass:
class_attribute = "class value"
@classmethod
def class_method(cls):
# 这是一个类方法
return cls.class_attribute
print(MyClass.class_method()) # 调用类方法
- 静态方法(Static Method):
- 静态方法使用
@staticmethod装饰器进行修饰,它不需要表示自身对象的self或者类的cls参数。 - 静态方法不能访问类的属性,也不能访问实例的属性,因此它与类和实例无关。
- 应用场景:当一个方法在逻辑上与类相关,但是并不需要访问类或实例的属性时,通常会使用静态方法。静态方法通常用于封装通用的功能性方法。
- 静态方法使用
class MyClass:
@staticmethod
def static_method():
# 这是一个静态方法
return "This is a static method"
print(MyClass.static_method()) # 调用静态方法
总结:
- 实例方法主要用于操作实例的状态和行为;
- 类方法主要用于操作类的属性和提供类级别的操作;
- 静态方法主要用于封装与类相关的功能性方法,但不需要访问类或实例的属性。
3.7 数据封装及私有属性
在Python中,如果不设置私有属性,任何实例都可以直接调用
class MyClass:
def __init__(self):
self.private_attribute = 42 # 公共属性
# 如果不设置私有属性,实例都可以直接调用
my_object = MyClass()
print(my_object.private_attribute) # 42
在Python中,私有属性是指以双下划线开头(例如__name)的属性,它们被视为类的内部实现细节,外部无法直接访问。私有属性通过名称重整(name mangling)来进行变量名转换,以确保其在类的作用域内是唯一的。
尽管私有属性在语法上是可以被访问和修改的,但是它们被视为类的私有部分,不建议在类外部直接访问。通常情况下,可以通过提供公共方法(例如getter和setter方法)来间接地访问和修改私有属性。
以下是一个示例,展示了如何定义私有属性和使用公共方法访问和修改私有属性:
class MyClass:
def __init__(self):
self.__private_attribute = 42 # 私有属性
def get_private_attribute(self): # 公共方法获取私有属性值
return self.__private_attribute
def set_private_attribute(self, value): # 公共方法设置私有属性值
self.__private_attribute = value
# 创建对象并使用公共方法访问和修改私有属性
my_object = MyClass()
print(my_object.get_private_attribute()) # 输出: 42
my_object.set_private_attribute(100)
print(my_object.get_private_attribute()) # 输出: 100
请注意,私有属性只是一种约定,并不像访问修饰符(如其他编程语言中的private)一样严格限制访问。在Python中,可以通过_ClassName__private_attribute的方式强制访问私有属性,但不建议这样做,因为这会违背类的封装性原则。应该尽量遵循类的设计意图,并通过公共方法来处理私有属性的访问和修改。
3.7.1 函数本身并没有所谓的“私有属性”
在Python中,函数本身并没有所谓的“私有属性”,因为函数不是一个类或对象,因此没有像类的私有属性那样的概念。然而,你可能在考虑函数内部的局部变量和闭包变量。
- 局部变量:在函数内部定义的变量属于局部变量,它们只能在函数内部被访问。这意味着这些变量对于函数外部的代码来说是“私有”的。例如:
def my_function():
x = 10 # 这里的x是my_function的局部变量
# 在函数外部无法直接访问x
- 闭包变量:如果一个函数内部定义了另一个函数,并且内部函数引用了外部函数的变量,那么这个外部函数的变量对于内部函数来说就形成了闭包。这些变量也可以看作是一种“私有”的属性,因为它们对于外部代码来说是不可见的。例如:
def outer_function():
x = 10
def inner_function():
print(x) # 内部函数引用了外部函数的变量x
return inner_function
# 外部函数的变量x对于外部代码来说是不可见的
总的来说,函数内部的局部变量和闭包变量可以被看作是一种“私有”的属性,因为它们对于函数外部的代码来说是不可见的。这有助于确保函数内部的数据不会被外部的代码直接访问和修改,实现了一定程度的封装性。
【说明】私有属性是指以双下划线开头(例如__name)的属性,单下划线开头是什么 ?
在Python中,以单下划线开头的属性是一种约定,被称为"弱约定"或者"半私有属性"。这种约定并不会强制限制对属性的访问,但它是一种暗示,告诉其他开发人员应该将其视为私有属性,不直接在外部使用。
当一个属性以单下划线开头时,它的含义是内部属性或者辅助属性,用于对象的实现细节。这个约定旨在提醒其他开发人员尽量不要直接访问或修改这些属性,而是通过提供的公共方法来操作。
虽然通过类的外部仍然可以访问和修改以单下划线开头的属性,但是这不是一种良好的编程实践,因为它打破了封装性。建议在使用类时,遵循约定,尽量不要直接访问以单下划线开头的属性。
3.7.2 Python私有属性变形机制原理
Python私有属性变形机制原理,代码如下
class MyClass:
def __init__(self):
self.__private_attribute = 42 # 公共属性
# 特例
my_object = MyClass()
# print(my_object.private_attribute) # AttributeError: 'MyClass' object has no attribute 'private_attribute'
print(my_object._MyClass__private_attribute) # 42
# 可以看到,python的私有属性并没有解决私有属性的绝对私有性,而是加了一些小技巧,将__private_attribute变形成_MyClass__private_attribute
# 这是一种结构化的方法,所以从语言的层面来说,Python并没有做到绝对的安全。java也可以突破。
3.7.3 Python的数据封装
在Python中,数据封装是指将数据和操作数据的方法(函数)捆绑在一起的编程概念。这种做法可以确保数据的安全性和一致性,同时也提供了一种简洁的方式来访问和操作数据。
在Python中,数据封装通常通过类来实现。类中的属性和方法可以被视为数据和操作数据的函数,通过封装,我们可以限制对数据的直接访问,而是通过类中定义的公共方法来间接地对数据进行操作。
以下是一个简单的示例,展示了如何在Python中使用类来实现数据封装:
class Student:
def __init__(self, name, age):
self.name = name # 公共属性
self.age = age # 公共属性
def get_name(self): # 公共方法获取name属性值
return self.name
def set_name(self, new_name): # 公共方法设置name属性值
self.name = new_name
def get_age(self): # 公共方法获取age属性值
return self.age
def set_age(self, new_age): # 公共方法设置age属性值
if new_age >= 0: # 对age属性进行验证
self.age = new_age
else:
print("年龄不能为负数")
# 创建对象并使用公共方法访问和修改属性
student1 = Student("张三", 20)
print(student1.get_name()) # 输出: 张三
print(student1.get_age()) # 输出: 20
student1.set_age(-5) # 输出: 年龄不能为负数
在这个示例中,Student类封装了学生的姓名和年龄属性,并提供了公共方法来访问和修改这些属性。通过这种方式,我们可以控制对数据的访问和修改,确保数据的安全性和一致性。
总之,数据封装是面向对象编程中非常重要的概念,它通过类的属性和方法实现了对数据的保护和控制,使得代码更加健壮和可维护。
3.7.4 Python不进行数据封装的影响
如果不进行数据封装,直接在类外部访问和修改类的属性,那么代码会变得不够安全和稳定。以下是一些可能发生的问题:
-
数据不可控:如果不限制属性的值范围,那么属性的值可能会被错误地设置为无效值,导致程序出现异常或者计算结果错误。
-
代码复杂度增加:如果不对类中的属性进行封装,那么在类的内部和外部都可以直接对属性进行操作,这样会导致代码变得混乱和复杂,因为你无法准确地知道类属性被哪些代码所修改或使用。
-
属性泄露:如果不对类中的属性进行封装,那么类的使用者可能会直接访问和修改属性,这样会导致类的部分实现细节暴露给外界,从而增加了代码被滥用或恶意攻击的风险。
因此,通过数据封装,我们可以限制对属性的访问和修改,降低程序出错的风险,并使得代码更加清晰和易于维护。
3.8 Python对象的自省机制
Python的自省机制指的是在运行时通过一些内置函数和特殊属性来获取对象的相关信息,包括对象的类型、属性、方法等。以下是几种常用的自省机制:
- type()函数:type(obj)返回对象obj的类型。例如,type(5)返回int,type(“hello”)返回str。
- isinstance()函数:isinstance(obj, cls)判断对象obj是否是类cls的实例(或者是其子类的实例)。例如,isinstance(5, int)返回True,isinstance(“hello”, str)返回True。
- dir()函数:dir(obj)返回对象obj所包含的所有属性和方法的列表。例如,dir(“hello”)返回一个包含字符串对象所有属性和方法的列表。
- getattr()函数:getattr(obj, attr)获取对象obj的属性attr的值。例如,getattr(“hello”, “upper”)返回字符串对象的upper()方法。
- hasattr()函数:hasattr(obj, attr)检查对象obj是否具有属性attr。例如,hasattr(“hello”, “upper”)返回True。
- setattr()函数:setattr(obj, attr, value)设置对象obj的属性attr的值为value。例如,setattr(my_obj, “name”, “Alice”)将对象my_obj的name属性设置为"Alice"。
- delattr()函数:delattr(obj, attr)删除对象obj的属性attr。例如,delattr(my_obj, “name”)删除对象my_obj的name属性。
__class__属性:obj.__class__返回对象obj所属的类。例如,“hello”.__class__返回str。__dir__():返回对象的属性和方法列表。__getattr__(name):在访问不存在的属性时调用。__setattr__(name, value):在设置属性值时调用。__delattr__(name):在删除属性时调用。__str__():返回对象的字符串表示形式,可通过str(obj)或者print(obj)调用。__repr__():返回对象的可打印表示形式,可通过repr(obj)调用。__len__():返回对象的长度,可通过len(obj)调用。__iter__():返回一个迭代器对象,可用于迭代对象的元素。__next__():在迭代器中返回下一个元素。
以上仅是Python自省机制的一部分,还有其他更多的函数和特殊方法可以用于获取对象的信息。自省机制在编写通用的、动态的代码时非常有用,可以实现更灵活的程序设计。
3.8.1 简单用法举例
当谈及Python中的自省函数,常见的有以下几个函数:
type(object):返回对象的类型。
num = 10
print(type(num)) # <class 'int'>
name = "Alice"
print(type(name)) # <class 'str'>
person = {"name": "Bob", "age": 30}
print(type(person)) # <class 'dict'>
isinstance(object, classinfo):检查对象是否是指定类或其子类的实例。
class Animal:
pass
class Dog(Animal):
pass
dog = Dog()
print(isinstance(dog, Dog)) # True
print(isinstance(dog, Animal)) # True
print(isinstance(dog, object)) # True
cat = Animal()
print(isinstance(cat, Dog)) # False
print(isinstance(cat, Animal)) # True
dir([object]):返回对象的属性和方法列表。
person = {"name": "Alice", "age": 25}
print(dir(person))
# 输出: ['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
hasattr(object, name):检查对象是否有指定的属性。
person = {"name": "Alice", "age": 25}
print(hasattr(person, "name")) # True
print(hasattr(person, "city")) # False
这些自省函数可以用于获取对象的类型、判断对象的类关系、查看对象的属性和方法,以及检查对象是否具有特定的属性。它们在编写灵活、动态的代码时非常有用。
3.8.2 复杂用法举例
这些特殊方法也可在自定义类中重写,用于定制对象的行为和表示方式。下面是它们的具体用法:
__class__:__class__是一个属性,用于获取对象所属的类。- 可以通过
obj.__class__或type(obj)方式获取对象的类。 - 通常情况下,可以使用
isinstance()函数来判断一个对象是否属于某个类。
class Animal:
pass
class Dog(Animal):
pass
dog = Dog()
print(dog.__class__) # <class '__main__.Dog'>
print(type(dog)) # <class '__main__.Dog'>
print(isinstance(dog, Dog)) # True
print(isinstance(dog, Animal)) # True
__dir__():__dir__()方法返回对象的属性和方法列表。- 可以通过调用
dir(obj)方式获取对象的属性和方法列表。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self):
print(f"Hello, I'm {self.name}, {self.age} years old.")
person = Person("Alice", 25)
print(dir(person))
# 输出: ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name', 'say_hello']
__str__():__str__()方法返回对象的字符串表示形式。- 可以通过调用
str(obj)或者print(obj)方式获取对象的字符串表示形式。 - 通常情况下,
__str__()方法被用于返回一个简洁、易读的对象描述,便于使用者理解。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Person(name={self.name}, age={self.age})"
person = Person("Alice", 25)
print(person) # Person(name=Alice, age=25)
__len__():__len__()方法返回对象的长度。- 可以通过调用
len(obj)方式获取对象的长度。 - 通常情况下,
__len__()方法被用于返回一个对象的元素个数,比如列表、字符串等。
class MyList:
def __init__(self, *args):
self.items = list(args)
def __len__(self):
return len(self.items)
lst = MyList(1, 2, 3, 4, 5)
print(len(lst)) # 5
【拓展】
这些特殊方法可以在自定义类中重写,用于对属性的访问、设置和删除进行控制和定制。下面是它们的具体用法:
__getattr__(self, name):- 当访问一个对象的不存在的属性时,
__getattr__方法会被调用,它接受两个参数:self(实例对象本身)和name(属性名),并且返回属性的值。 - 这个方法可以用于在属性不存在时动态计算或返回属性的值。
- 例如,当尝试获取一个对象的某个不存在的属性时,可以通过
__getattr__方法根据需要返回相应的默认值或计算得到的值。
- 当访问一个对象的不存在的属性时,
class DynamicAttr:
def __getattr__(self, name):
if name == 'age':
return 25
else:
raise AttributeError(f"'DynamicAttr' object has no attribute '{name}'")
obj = DynamicAttr()
print(obj.age) # 25
print(obj.name) # AttributeError: 'DynamicAttr' object has no attribute 'name'
__setattr__(self, name, value):- 当设置对象的属性值时,
__setattr__方法会被调用,它接受三个参数:self(实例对象本身)、name(属性名)和value(要设置的值)。 - 这个方法可以用于在设置属性值时进行额外的逻辑判断或处理,比如数据验证、触发其他操作等。
- 注意在
__setattr__方法中设置属性值时,需要避免出现无限递归调用。
- 当设置对象的属性值时,
class ProtectedAttr:
def __init__(self):
self._age = 0
def __setattr__(self, name, value):
if name == 'age':
if value < 0:
raise ValueError("Age can't be negative")
else:
self._age = value
else:
super().__setattr__(name, value)
obj = ProtectedAttr()
obj.age = 30 # 正常设置属性值
print(obj._age) # 30
obj.age = -5 # ValueError: Age can't be negative
__delattr__(self, name):- 当删除对象的属性时,
__delattr__方法会被调用,它接受两个参数:self(实例对象本身)和name(要删除的属性名)。 - 这个方法可以用于在删除属性时执行一些清理操作或引发异常。
- 当删除对象的属性时,
class LockedAttr:
def __init__(self):
self._locked = False
def __delattr__(self, name):
if name == 'locked':
raise AttributeError("Cannot delete 'locked' attribute")
else:
super().__delattr__(name)
obj = LockedAttr()
del obj.locked # AttributeError: Cannot delete 'locked' attribute
通过重写这些特殊方法,可以对属性的访问、设置和删除进行自定义控制,从而实现更灵活和定制化的对象行为。
3.8.2 【拓展】__dict__并不是一个自省函数
__dict__并不是一个自省函数,而是一个特殊属性。在Python中,每个对象都有一个__dict__属性,它是一个字典,包含了对象的所有属性和方法。
通过访问__dict__属性,您可以查看对象的属性和方法,并可以对其进行动态操作。下面是一个简单的示例:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person = Person("Alice", 25)
# 使用__dict__查看对象的属性和方法
print(person.__dict__)
# 输出: {'name': 'Alice', 'age': 25}
# 动态添加新的属性
person.city = "New York"
print(person.__dict__)
# 输出: {'name': 'Alice', 'age': 25, 'city': 'New York'}
在上述示例中,我们创建了一个Person类的实例person,并使用__dict__打印出其属性和方法。随后,我们动态地添加了一个新的属性city,再次使用__dict__打印出更新后的属性和方法。
请注意,虽然__dict__是一个强大的特性,它提供了对对象内部结构的直接访问,但通常情况下并不推荐直接操作__dict__属性,而是使用点号语法来访问和修改对象的属性。
高阶代码演示
"""
类定义的时候的特别用法
"""
class TestCase:
def __init__(self):
self.a = 'a'
self.b = 'b'
self.c = 'c'
self.e = '前端'
self.f = '后端'
self.d = '{e}{f}.txt'
fmt = self.__dict__
print(fmt)
self.d = self.d.format(**fmt)
print(fmt)
test = TestCase()
输出结果如下
{'a': 'a', 'b': 'b', 'c': 'c', 'e': '前端', 'f': '后端', 'd': '{e}{f}.txt'}
{'a': 'a', 'b': 'b', 'c': 'c', 'e': '前端', 'f': '后端', 'd': '前端后端.txt'}
3.8.3 自省函数的实战
代码如下:
"""
自省函数是通过一定的机制查询到对象的内部结构,用__dict__可以获取任意对象的属性,也可以赋值
"""
class Persion:
"""
测试文档属性__doc__
"""
name = 'user'
class Student(Persion):
def __init__(self,school_name):
self.school_name = school_name
if __name__ == '__main__':
user = Student('理工')
# 通过__dict__查询属性
print(user.__dict__) # {'school_name': '理工'}
print(user.name) # user
# 这个实例可以调用父类的属性,为什么父类的属性没有进入到实例的属性之中?
# 因为Persion是一个类,也是一个对象,name是Persion的属性,而不是Student的属性。
# 为什么可以user.name查询到,因为通过mro算法(C3算法)查找出来了。
print(Persion.__dict__)
# 输出,因为Persion是一个类,比user实例输出的更加的丰富。weakref是弱引用
# {'__module__': '__main__', 'name': 'user', '__dict__': <attribute '__dict__' of 'Persion' objects>,
# '__weakref__': <attribute '__weakref__' of 'Persion' objects>, '__doc__': '\n 测试文档属性__doc__\n '}
# 给对象赋值,动态操作user对象的过程
user.__dict__['addr'] = '北京市'
print(user.__dict__) # {'school_name': '理工', 'addr': '北京市'}
# dir 函数 列出对象中的所有属性
print(dir(user))
# ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
# '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__',
# '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
# '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'addr', 'name', 'school_name']
# 查看a的属性
a = [1,2]
# print(a.__dict__) # AttributeError: 'list' object has no attribute '__dict__'
print(dir(a))
# ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__',
# '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__',
# '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__',
# '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
# '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__',
# 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
在Python中,__dict__是一个特殊的属性,它返回一个对象的命名空间(namespace)或者说是字典,其中包含对象的所有属性。通过访问__dict__属性,你可以查看对象的属性和对应的数值。因此,__dict__可以用于自省(introspection),即在运行时获取对象的信息。例如,你可以使用__dict__属性来遍历对象的所有属性以及它们的值。
所以,__dict__本身并不是一个函数,但它提供了一种方式来进行自省,帮助你在运行时获取对象的信息。
3.9 Super函数
super()函数是一个内置函数,用于调用父类(超类)中的方法。它提供了一种方便的方式来使用父类的方法,而不需要显式地指定父类的名称。
通常在子类中,我们可以通过super()函数来调用父类的构造函数或者其他方法。这样可以确保父类的代码得到执行,同时还可以在子类中添加额外的逻辑。
super()函数的常见用法是在子类的构造函数中调用父类的构造函数。例如:
class ChildClass(ParentClass):
def __init__(self, arg1, arg2):
super().__init__(arg1) # 调用父类的构造函数
self.arg2 = arg2 # 子类的额外属性
def some_method(self):
super().some_method() # 调用父类的方法
# 子类的其他逻辑
在上面的例子中,super().__init__(arg1)调用了父类的构造函数,确保了父类的初始化代码得到执行。然后,子类可以添加自己的逻辑,例如初始化子类特有的属性self.arg2。
需要注意的是,super()函数返回的是一个特殊的对象,称为"super object",它绑定了父类和子类之间的关系,可以用来调用父类的方法。通过super()函数,你可以实现多层继承中的方法调用,确保在继承链上的所有父类方法都得到执行。
代码示例1
"""
super函数讲解
调用父类的方法
"""
# # 前言
# class A:
# def __init__(self):
# print('A')
#
# class B(A):
# def __init__(self):
# print('B')
# #
# if __name__ == '__main__':
# b = B()
# print(b)
# # B
# # <__main__.B object at 0x000001352F2E60F0>
# 如何来调用父类的方法呢
class A:
def __init__(self):
print('A')
class B(A):
def __init__(self):
# super(B,self).__init__() # python 2中的用法
super().__init__() # python 3写法
print('B')
if __name__ == '__main__':
b =B()
print(b)
"""
A
B
<__main__.B object at 0x000002165206C6D8>
"""
# 拓展
# 1.既然我们重写了B的构造函数,为什么还有去调用super?
# 举例:多线程场景中,传递两个参数时,如果父类有相同参数时,不需要再重复传参
# from threading import Thread
# class MyThread(Thread):
# def __init__(self,user,name):
# self.user = user
# # 此时就没必要self.name = name 了,因为类Thread源码中已经有name了,可以拿来共用
# # def __init__(self, group=None, target=None, name=None,
# # args=(), kwargs=None, *, daemon=None):
# # 如何共用呢,如下
# super().__init__(name=name)
# 2.super执行顺序是什么样的?
"""
在 Python 中,super() 执行的顺序是由方法解析顺序(Method Resolution Order, MRO)决定的。MRO 是根据 C3 算法计算出的一个线性顺序,用于确定多继承时方法的调用顺序。
在经典类(Python 2.x 中的类)中,MRO 遵循深度优先、从左到右的顺序。而在新式类(Python 3.x 中默认的类)中,MRO 使用 C3 算法按照一定规则进行计算,以保证在多继承时能够正确地找到方法的调用顺序。
在 Python 3.x 中,可以通过以下方式查看类的 MRO:
?```python
print(ClassName.mro())
?```
这将打印出类的方法解析顺序,帮助你理解 super() 调用的具体顺序。
总的来说,super() 的执行顺序取决于 MRO 的计算结果,在多继承的情况下会按照 MRO 的顺序依次调用各个父类的方法。
"""
class A:
def __init__(self):
print("A")
class B(A):
def __init__(self):
print("B")
super().__init__() # 关键监测点 ,此处调用super之后,它打印的是C而不是A,
class C(A):
def __init__(self):
print("C")
super().__init__()
class D(B, C):
def __init__(self):
print('D')
super(D, self).__init__()
if __name__ == '__main__':
print(D.__mro__) # (<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
d = D() # DBCA
# 上面这两个保持一致
# Method defined in class B
# [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
# 通俗点说,不是调用父类的函数,而是调用mro顺序的构造函数
【拓展1】
当涉及多继承时,Python 会使用 C3 算法来确定方法解析顺序(MRO)。下面是一个简单的例子,演示了多继承情况下的方法解析顺序:
class A:
def do_something(self):
print("Method defined in class A")
class B(A):
def do_something(self):
print("Method defined in class B")
class C(A):
def do_something(self):
print("Method defined in class C")
class D(B, C):
pass
d = D()
d.do_something()
print(D.mro())
在这个例子中,类 D 继承自类 B 和类 C,而类 B 和类 C 都继承自类 A。当调用 d.do_something() 时,Python 会根据 MRO 确定方法解析顺序。
运行上述代码将输出以下结果:
Method defined in class B
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
从输出结果可以看出,方法解析顺序为 D -> B -> C -> A -> object。这就是由 C3 算法计算得出的方法解析顺序,它保证了在多继承的情况下能够正确地确定方法的调用顺序。
因此,在多继承的情况下,通过查看类的 MRO 可以更好地理解 super() 的执行顺序。
【拓展2】
在 Python 中,通过super()只能调用父类的方法,并不能直接访问父类的属性。如果你想要在子类中访问父类的属性,可以通过在子类中定义属性或者使用父类的方法来间接获取。
下面是一个修正后的示例,展示了如何在子类中通过间接方式访问父类的属性:
class A:
def __init__(self):
self.x = 10
def method(self):
print("Method in A")
class B(A):
def __init__(self):
super().__init__()
self.y = 20
def method(self):
super().method()
print("Method in B")
print("x =", self.x) # 使用子类属性间接访问父类属性
b = B()
b.method()
输出结果:
Method in A
Method in B
x = 10
在这个修正后的例子中,我们在类B的方法method中使用了self.x来间接访问父类A的属性x。通过在子类中定义一个与父类相同名称的属性,在访问时可以使用子类属性来间接访问父类的属性。
3.10 继承案例——Django rest framework
要点:
"""
Django rest framework 中对多继承使用的经验
不推荐使用多继承,如果设计不好,很容易造成继承关系的混乱
推荐mixin模型,混合模式
- 1.Mixin类功能单一
- 2.不能和基类关联,可以和任意基类组合,基类可以不和mixin关联就能初始化成功
- 3.在mixin中不要使用super这种用法(因为super会根据mro的顺序去调用方法)
"""
Django REST framework (DRF) 中有很多 Mixin 类可以用来扩展 API 视图类的功能。下面是一些常用的 DRF Mixin 类及其用途:
ListAPIView:提供了列表视图的基本功能,如获取查询集、序列化和响应数据。CreateAPIView:提供了创建视图的基本功能,如反序列化、验证表单和保存模型实例。RetrieveAPIView:提供了单个对象视图的基本功能,如获取查询集、序列化和响应数据。UpdateAPIView:提供了更新视图的基本功能,如获取查询集、反序列化、验证表单和保存模型实例。DestroyAPIView:提供了删除视图的基本功能,如获取查询集、删除模型实例和响应数据。ListModelMixin:提供了列表视图的额外功能,如分页、过滤、排序和搜索。CreateModelMixin:提供了创建视图的额外功能,如在创建前检查权限或在创建后执行其他操作。RetrieveModelMixin:提供了单个对象视图的额外功能,如在获取前检查权限或在获取后执行其他操作。UpdateModelMixin:提供了更新视图的额外功能,如在更新前检查权限或在更新后执行其他操作。DestroyModelMixin:提供了删除视图的额外功能,如在删除前检查权限或在删除后执行其他操作。
以下是一个使用 DRF Mixin 类的例子:
from rest_framework import generics, mixins
from .models import Book
from .serializers import BookSerializer
class BookListAPIView(mixins.ListModelMixin,
mixins.CreateModelMixin,
generics.GenericAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
在这个例子中,我们使用了两个 Mixin 类:ListModelMixin 和 CreateModelMixin,以及一个通用视图类 GenericAPIView。通过多继承,我们可以将这些 Mixin 类的功能组合到我们的视图中。
在 BookListAPIView 中,我们定义了查询集和序列化器,并在 get 和 post 方法中使用 Mixin 类提供的 list 和 create 方法来处理 GET 和 POST 请求。
使用 DRF 的 Mixin 类可以大大简化编写 API 视图的过程,提高代码的可读性和可维护性。
示例
Mixin 模型是一种在面向对象编程中用于代码重用的设计模式。它通过创建可复用的、独立的类,然后将这些类与其他类组合使用,从而实现代码的重用和功能的扩展。
Mixin 类通常包含一些方法或属性,这些方法或属性可以被其他类继承或混入。通过将 Mixin 类与其他类进行多继承,可以将其功能添加到目标类中,而无需修改目标类的原始结构。
Mixin 模型有以下特点:
- Mixin 类通常只关注单一功能,具有高内聚性。
- Mixin 类一般不会被单独实例化,而是通过多继承的方式与其他类组合使用。
- Mixin 类的命名通常以 “Mixin” 结尾,以便清楚地表明其用途。
下面是一个简单的例子来演示 Mixin 模型的应用:
class LogMixin:
def log(self, message):
print(f"Logging: {message}")
class DatabaseMixin:
def save(self):
print("Saving to the database")
class User(LogMixin, DatabaseMixin):
def __init__(self, name):
self.name = name
def greet(self):
print(f"Hello, {self.name}!")
user = User("Alice")
user.greet()
user.log("User created")
user.save()
在这个例子中,我们定义了两个 Mixin 类:LogMixin 和 DatabaseMixin。这些 Mixin 类分别提供了日志记录和数据库操作的功能。
然后,我们定义了一个名为 User 的类,它继承了 LogMixin 和 DatabaseMixin。通过多继承,User 类获得了 LogMixin 和 DatabaseMixin 提供的方法和属性。
最后,我们创建了一个 User 对象,并调用了 User 类的方法 greet、log 和 save,这些方法来自于 User 类本身以及其继承的 Mixin 类。
通过使用 Mixin 模型,我们可以灵活地组合和重用类中的功能,提高代码的可维护性和复用性。
Hello, Alice!
Logging: User created
Saving to the database
【拓展】
当涉及到更复杂的应用场景时,Mixin 模型可以发挥更大的作用。一个常见的复杂示例是在大型 Web 框架中使用 Mixin 模型来实现各种功能模块的组合和扩展。
举一个简化的例子,假设我们有一个 Web 框架,其中有多个功能模块,比如用户认证、权限管理、日志记录、缓存管理等。每个功能模块都有一些独立的方法和属性,同时又需要与其他模块进行交互。我们可以使用 Mixin 模型来实现这种功能模块的组合和扩展。
# 用户认证模块
class AuthenticationMixin:
def authenticate(self, request):
# 进行用户认证的逻辑
pass
# 权限管理模块
class PermissionMixin:
def check_permission(self, request, permission):
# 检查用户权限的逻辑
pass
# 日志记录模块
class LoggingMixin:
def log(self, message):
# 记录日志的逻辑
pass
# 缓存管理模块
class CachingMixin:
def cache(self, key, value):
# 缓存数据的逻辑
pass
# 组合功能模块
class WebFramework(AuthenticationMixin, PermissionMixin, LoggingMixin, CachingMixin):
def handle_request(self, request):
self.authenticate(request)
self.check_permission(request, 'read')
self.log("Request handled")
self.cache('key', 'value')
# 处理请求的逻辑
在上面的示例中,我们定义了几个独立的 Mixin 类,每个类代表一个功能模块。然后,我们创建了一个名为 WebFramework 的类,它通过多继承来组合各个 Mixin 类,从而获得了用户认证、权限管理、日志记录和缓存管理等功能。
在 WebFramework 类的 handle_request 方法中,我们调用了各个 Mixin 类提供的方法,实现了这些功能模块的组合和扩展。
这个例子展示了如何使用 Mixin 模型来构建一个复杂的功能模块组合系统。通过这种方式,我们可以将各个功能模块进行解耦,使其具有高内聚性,同时实现了功能的复用和扩展。
3.11 Python的with语句
示例1
"""
Python中的with语句 ————为了简化try finally写法而诞生
"""
# #经典代码
# try:
# f_read = open('one.txt') # 1
# print('code started')
# raise KeyError
# except KeyError as e:
# print('key error')
# # f_read.close() # 2 如果有多个except时,需要在多个except加f_read.close()
# else:
# print('other error')
# finally:
# print('finally')
# # f_read.close() # 3
# 放在函数里面后
def exc():
try:
print('code started')
raise KeyError
return 1
except KeyError as e:
print('key error')
return 2 # 此处会将2压入堆栈里面,如果finally里面有return,也会把finally里return的值压入堆栈里面。
else:
print('other error')
return 3
finally:
print('finally')
return 4
if __name__ == '__main__':
print(exc()) # 4
# 上面为什么不返回2,而会返回4呢,
# 用法:如果finally有return语句,他就会返回finally的return语句;如果没有finally的语句,会返回调用时候的return
# 上面例子,把return 4 注释掉,会返回 2
示例2
"""
with语句
————上下文管理器
Python是基于协议来进行编程的
上下文管理器协议,需要实现两个魔法函数__enter__和__exit__
"""
class Sample:
def __enter__(self):
print('enter')
# 获取资源
return self
def __exit__(self, exc_type, exc_val, exc_tb):
# 释放资源
print('exit')
def do_something(self):
print('doing something')
with Sample() as sample:
sample.do_something()
"""
enter
doing something
exit
"""
举例
with 语句是 Python 中用于处理上下文管理器的一种语法结构。上下文管理器是实现了上下文管理协议的对象,它必须定义 __enter__() 和 __exit__() 方法。
上下文管理器协议定义了在进入和退出某个代码块时应该发生的操作。当执行进入代码块时,会调用上下文管理器的 __enter__() 方法,而在退出代码块时,会调用上下文管理器的 __exit__() 方法。
下面是上下文管理器协议的具体定义:
__enter__(self):这个方法在进入代码块之前被调用,可以用于准备资源或者执行一些设置操作。它将在with语句中的代码块开始执行之前被调用,并且可以返回一个对象,以供在代码块中使用。__exit__(self, exc_type, exc_value, traceback):这个方法在退出代码块时被调用,无论代码块是否发生异常。它可以用于释放资源、清理操作或处理异常。如果代码块正常退出,exc_type、exc_value和traceback的值都为None。如果代码块发生异常,这些参数将包含异常的相关信息。
使用上下文管理器协议时,可以通过 with 语句来自动管理资源的获取和释放。当 with 语句结束时,无论代码块是否发生异常,上下文管理器的 __exit__() 方法都会被调用。
下面是一个简单的示例,演示了如何使用 with 语句和上下文管理器协议:
class MyContextManager:
def __enter__(self):
# 进入代码块前的准备操作
print("Entering the context")
def __exit__(self, exc_type, exc_value, traceback):
# 退出代码块时的清理操作
print("Exiting the context")
# 使用上下文管理器
with MyContextManager() as cm:
# 在这里执行一些操作
print("Inside the context")
输出结果为:
Entering the context
Inside the context
Exiting the context
在这个示例中,MyContextManager 类实现了上下文管理器协议。当进入 with 代码块时,会调用 __enter__() 方法打印 “Entering the context”。然后,在代码块中执行一些操作,打印 “Inside the context”。最后,在退出 with 代码块时,会调用 __exit__() 方法打印 “Exiting the context”。
通过使用上下文管理器和 with 语句,可以方便地管理资源的获取和释放,同时确保在退出代码块时进行必要的清理操作。这在处理文件、数据库连接、线程锁等需要手动关闭或释放的资源时特别有用。
3.12 contextlib简化上下文管理器
contextlib 模块是 Python 标准库中的一个工具模块,提供了一些用于简化上下文管理器定义的函数和装饰器。
其中最常用的是 contextmanager 装饰器,它可以将一个生成器函数转换成一个上下文管理器。使用 contextmanager 装饰器,可以避免显式地定义一个新的上下文管理器类,而是使用一个生成器函数来实现上下文管理器的逻辑。
下面是一个示例,演示了如何使用 contextmanager 装饰器简化上下文管理器的定义:
from contextlib import contextmanager
@contextmanager
def my_context_manager():
print("Entering the context")
try:
yield
finally:
print("Exiting the context")
# 使用上下文管理器
with my_context_manager():
# 在这里执行一些操作
print("Inside the context")
输出结果为:
Entering the context
Inside the context
Exiting the context
在这个示例中,@contextmanager 装饰器将 my_context_manager() 函数转换成了一个上下文管理器。在 my_context_manager() 函数中,我们打印 “Entering the context”,然后使用 yield 关键字将控制权转移到代码块中。在代码块中执行一些操作,然后在 finally 语句块中打印 “Exiting the context”。
通过使用 contextmanager 装饰器,我们可以避免定义一个新的上下文管理器类,并简化上下文管理器的实现方式。这对于编写一些简单的上下文管理器非常有用,比如临时修改环境变量、打开和关闭文件等。
3.13 小节
1.动态语言中多态是天然的
2.尽量不使用抽象基类,用mixin去设计基类
3.私有属性并没有真正做到私有属性的访问权限
4.Python是基于协议来进行编程的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!