shp与数据库(插入数据)
前言
?前一篇讲解了通过shp创建表,shp文件与数据库(创建表)-CSDN博客?,
后来感觉写麻烦了。因为可以用geopandas来创建表和写入数据,非常简单。但是笔者还是想根据自己的想法继续写下去。
正文
geopandas与shp文件创建表和录入数据
如果使用geopandas,创建表和录入数据都显得很简单,代码如下。
import geopandas as gpd
import pandas as pd
from sqlalchemy import create_engine
from geoalchemy2 import Geometry, WKTElement
engine = create_engine('postgresql+psycopg2://username:password@localhost/arcgis')
# 读取Shapefile文件
gdf = gpd.read_file('成都/成都.shp')
# 几何数据转换为 Well-Known Text (WKT) 格式
gdf['geometry'] = gdf['geometry'].apply(lambda x: WKTElement(x.wkt, srid=4326))
# 存入数据库
gdf.to_sql('cd2', engine, if_exists='replace', index=False,dtype={'geometry': Geometry('GEOMETRY', srid=4326)})
# repalce 替代表?运行结果如下。

解释一下上面的代码
gdf = gpd.read_file('成都/成都.shp')读取shp文件,但通过geopandas读取shp文件和通过shapefile读取shp二者是有区别的,
因为geopands是在pandas的基础上建立的库,很明显二者的数据类型一定是不一样的,可以打印一下。
gdf = gpd.read_file('成都/成都.shp')
print(gdf.dtypes)?结果如下。
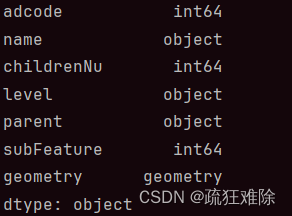
其中最关键的数据类型是geometry,后面会提及,打印一下geometry
gdf = gpd.read_file('成都/成都.shp')
print(gdf.geometry)?结果如下
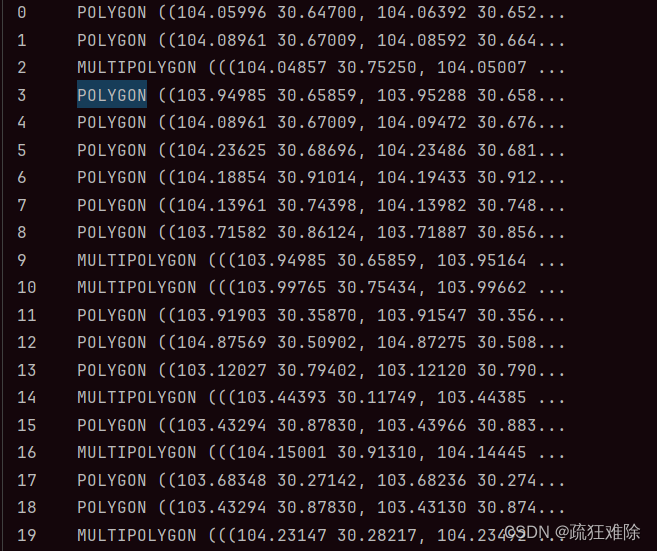
可以看到既有PLOYGON,也有MULTIPOLYGON。正因为如此,如果最后一行的代码写dtype的geometry写PLOYGON,将会报错,写MULTIPOLYGON可以运行,报错如下。

但类型可以是点、线等其他,不知道是什么类型,所以写个最大的类型是GEOMETRY。
当然可以使用如下代码,将MULTIPOLYGON分解成PLOYGON。
gdf = gdf.explode(index_parts=True)对于如下行代码
gdf['geometry'] = gdf['geometry'].apply(lambda x: WKTElement(x.wkt, srid=4326))
这一步将 GeoDataFrame 中的几何数据转换为 Well-Known Text (WKT) 格式,这是一种可以被 SQLAlchemy 和许多数据库系统识别的地理空间数据格式。
不写,也会报错,报错如下。

虽然只有几行代码,但一不小心就会报错,但是geopandas还是非常可以的。
查询cd2表的geometry字段
需要添加与空间数据有关的扩展
-- 添加扩展
create extension postgis;查询语句?
-- 查询cd2表的geometry字段
select St_astext(geometry) from cd2;结果如下

查看一下表
通过datagrip查看建表的语句,如下图

从图中可以看出geometry的类型
geometry(Geometry, 4326)和前面代码相对应。可以用,
有些字段加上引号,字段不统一,对于引号,可以去除掉,在上面代码的基础上,添加如下代码。
gdf.columns=gdf.columns.str.lower()把列名变成小写,当然也可以转下划线,看个人喜好吧,笔者猜测应该有专门的方法解决这个,笔者也不知道。
再次运行结果如下。

前一篇博客的冲突
对于前一篇博客,shp文件与数据库(创建表)-CSDN博客,
从上面用geopandas创建表的过程中,最关键的一步,就是geometry的类型是判断,可以直接写最大的类型Geometry,不管shp文件中有什么数据,POINT还是POLYGON等,都在Geometry中。
前一篇博客,笔者创造的表的geometry是POLYGON类型的,如下图所示。

笔者之所以会认为是PLOYGON类型的,是根据如下代码的结果
import shapefile
shp=shapefile.Reader('成都/成都.shp')
for i in shp.shapes():
print(i)结果如下。
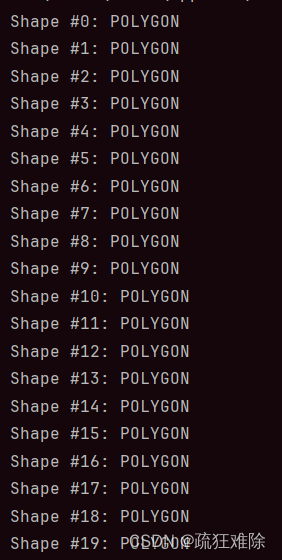
类型是POLYGON,但数据中既有POLYGON又有MUTLIPOLYGON,怎么办,怎么确定那个数据是POLYGON,那个是MUTLIPOLYGON???还是全部都是POLYGON?全部都是MUTLIPOLYGON?
问题的解决
POLYGON与MUTLIPOLYGON的说明
POLYGON:表示一个单独的多边形,它由一个或多个线性环组成。第一个线性环定义了多边形的外部边界,其余的线性环(如果有的话)定义了多边形的内部孔洞。 ?
MULTIPOLYGON:表示一组多边形,每个多边形都是独立的,可以有自己的外部边界和内部孔洞。简单是说,MultiPoylgon由多个Plygon构成,Plygon之间的空间关系是相离,因此MultiPolygon并没有外环
解决问题的代码
笔者经过多次的探索,问了多种ai,最后解决了,一言难尽,一言难尽,直接说最后的结果吧,看代码。
import shapefile
# 第三方库
from shapely.geometry.polygon import LinearRing
# 闭合的线性环(Linear Ring)对象,用于判断是否为环
shp=shapefile.Reader('成都/成都.shp')
for i in shp.shapes():
ring=LinearRing(i.points)
if ring.is_ring:
print('POLYGON')
else:
print('MULTIPOLYGON')有环则是POLYGON,为True
无环则是MUTLIPOLYGON,为False
打印结果如下
POLYGON
POLYGON
MULTIPOLYGON
POLYGON
POLYGON
POLYGON
POLYGON
POLYGON
POLYGON
MULTIPOLYGON
MULTIPOLYGON
POLYGON
POLYGON
POLYGON
MULTIPOLYGON
POLYGON
MULTIPOLYGON
POLYGON
POLYGON
MULTIPOLYGON修改表的创建
根据前面的说明,可以得知。geometry的类型,需要判断环,结论如下。
1、如果全是有环的,则设为PLOYGON
2、如果全是无环的,则设为MUTLIPOLYGON
3、如果二者都有,则设为GEOMETRY
表的创建的代码如下。
from geoalchemy2 import Geometry
# Geometry 空间数据类型
from sqlalchemy.schema import CreateTable
from sqlalchemy.orm import declarative_base
from sqlalchemy import Table, Column, Integer, VARCHAR, create_engine, BigInteger, Numeric, DATE, Boolean
from dataclasses import dataclass, fields
from shapely.geometry.polygon import LinearRing
import shapefile
Base = declarative_base()
@dataclass
class Shp2Postgres:
shp_path: str
table_name: str = 'shp'
pg_db: str = 'arcgis'
engine: create_engine = create_engine(f'postgresql+psycopg2://username:password@localhost/{pg_db}')
file: shapefile.Reader = None
words: list = None
shape_name: str = None
"""
:param shp_path: shp文件路径
:param table_name: 表名
:param pg_db: 数据库名
:param engine: 数据库引擎
:param file: shp文件
:param words: shp文件字段
:param shape_name: shp文件类型
:param ShpTable: shp文件对应的表
"""
def __post_init__(self):
self.file = shapefile.Reader(self.shp_path)
self.words = self.file.fields[1:]
self.shape_name = self.file.shapeTypeName
self.set_geometry_type()
class ShpTable(Base):
__tablename__ = self.table_name
id = Column(Integer(), primary_key=True, autoincrement=True, nullable=False, comment='id')
geometry = Column(Geometry(geometry_type=self.shape_name, srid=4326), comment='空间信息')
self.ShpTable = ShpTable
self.add_column()
def set_geometry_type(self):
"""
设置几何类型
:return:
"""
if self.shape_name == 'POLYGON':
POLYGON = 0
MULTIPOLYGON = 0
for i in self.file.shapes():
ring = LinearRing(i.points)
if ring.is_ring:
POLYGON += 1
else:
MULTIPOLYGON += 1
if POLYGON == 0:
self.shape_name = 'MULTIPOLYGON'
elif MULTIPOLYGON == 0:
self.shape_name = 'POLYGON'
else:
self.shape_name = 'GEOMETRY'
else:
pass
def add_column(self):
"""
添加字段
:return:
"""
for field in self.words:
name = field[0]
_type = field[1]
length = field[2]
decimal = field[3]
match _type:
case 'N':
_type = BigInteger()
case 'C':
_type = VARCHAR(length)
case 'F':
_type = Numeric(length, decimal)
case 'L':
_type = Boolean()
case 'D':
_type = DATE()
case 'M':
_type = VARCHAR(255)
case _:
_type = VARCHAR(255)
setattr(self.ShpTable, name, Column(_type, comment=name, name=name, quote=False))
def execute(self):
"""
执行创建
:return:
"""
# 执行创建
Base.metadata.create_all(self.engine)
# 打印创建表的sql语句
table = CreateTable(self.ShpTable.__table__).compile(self.engine)
print(table)
Shp2Postgres('成都/成都.shp', table_name='cd').execute()打印语句如下。
CREATE TABLE cd (
id SERIAL NOT NULL,
geometry geometry(GEOMETRY,4326),
adcode BIGINT,
name VARCHAR(80),
childrenNu BIGINT,
level VARCHAR(80),
parent VARCHAR(80),
subFeature BIGINT,
PRIMARY KEY (id)
)设置类型为GEOMETRY。
shapefile和sqlalchemy插入数据
直接该出代码,当然比较麻烦。(0.o)
import shapefile
from sqlalchemy import create_engine, Table, MetaData, insert
from sqlalchemy.orm import Session
from sqlalchemy.exc import NoSuchTableError
from geoalchemy2 import Geometry
from attrs import define, Factory, fields
from shapely.geometry import shape
from logging import StreamHandler, getLogger, DEBUG
from colorlog import ColoredFormatter
from typing import List, Optional
import sys
engine = create_engine('postgresql+psycopg2://username:1234@localhost/arcgis')
@define
class InsertData:
shp_path: str
table_name: str
session: Session = None
shp_file: shapefile.Reader = None
table: Table = None
record_data: List[dict] = []
"""
:param shp_path: shp文件路径
:param table_name: 表名
:param session: 数据库会话
:param shp_file: shp文件
:param table: shp文件对应的表
:param record_data: 记录数据
"""
@property
def log(self):
"""
日志的配置
:return:
"""
colors = {
'DEBUG': 'bold_red',
'INFO': 'bold_blue',
'WARNING': 'bold_yellow',
}
logger = getLogger(__file__)
stream_handler = StreamHandler()
logger.setLevel(DEBUG)
color_formatter = ColoredFormatter(
fmt='%(log_color)s %(asctime)s %(filename)s %(funcName)s line:%(lineno)d %(levelname)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
log_colors=colors
)
stream_handler.setFormatter(color_formatter)
logger.addHandler(stream_handler)
return logger
def __set_table(self):
"""
获取表
:return:
"""
try:
self.table = Table(self.table_name, MetaData(), autoload_with=engine)
self.log.info('获取表成功')
except NoSuchTableError as e:
self.log.error('获取表失败,请检查表名是否正确')
return None
def start(self):
self.shp_file = shapefile.Reader(self.shp_path)
self.session = Session(bind=engine)
self.__set_table()
if self.table is None:
return
words = self.shp_file.fields[1:]
word_names = [word[0].lower() for word in words]
for record in self.shp_file.shapeRecords():
record_dict = {word_names[i]: record.record[i] for i in range(len(word_names))}
# 几何数据转换为 Well-Known Text (WKT) 格式
record_dict['geometry'] = shape(record.shape).wkt
self.record_data.append(record_dict)
self.insert()
def insert(self):
"""
插入数据
:return:
"""
self.session.execute(insert(self.table), self.record_data)
self.session.commit()
self.log.info('插入成功')运行结果

数据库查询
-- 查询cd2表的geometry字段
select St_astext(geometry) from cd;结果
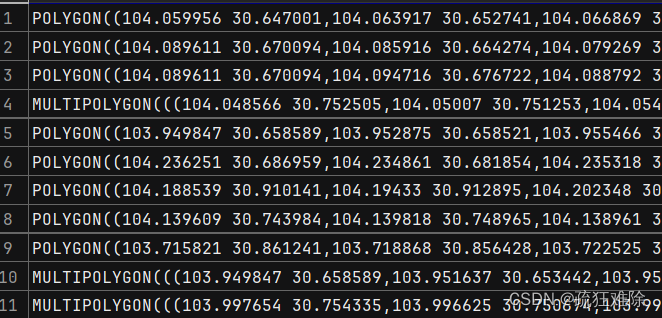
ok。
最后
插入数据还是用geopands简单。
不能确定代码一定正确,有错再修改。
后面再把数据库中的数据变成shp文件。
后面可以加上UI界面。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!