深度学习中的感知机
感知机是一种判别模型,其目标是求得一个能够将数据集中的正实例点和负实例点完全分开的分离超平面。

- 感知机在1957年由弗兰克·罗森布拉特提出,是支持向量机和神经网络的基础。
- 感知机是一种二类分类的线性分类模型,输入为实例的特征向量,输出为实例的类别,正类取1,负类取-1。
- 感知机是一种判别模型,其目标是求得一个能够将数据集中的正实例点和负实例点完全分开的分离超平面。如果数据不是线性可分的,则最后无法获得分离超平面。
3.1 单层感知机及其基本原理
基本结构 — 由两层神经元构成的网络结构。

-
上面所讲到的M-P神经元模型其实就是对单个神经元的一种建模,需要注意的一点是,M-P模型的权重和阈值都是人为给定的,所以对这一类模型不存在“学习”的说法。其实,这也是M-P模型与单层感知机最大的区别,感知机中引入了学习的概念,权重和阈值是通过学习得来的。
-
单层感知机模型是由美国科学家Frank Rosenblatt(罗森布拉特)在1957年提出的,它的基本结构如图所示,简单来说,感知机(Perceptron)就是一个由两层神经元构成的网络结构:输入层接收外界的输入信号,通过激活函数(阈值)变换,把信号传送至输出层,因此它也被称为“阈值逻辑单元”;输出层(也被称为是感知机的功能层)就是M-P神经元。
-
输出的数学表达式如图所示。可以看到,大于阈值的时候输出为1,小于等于阈值的时候输出为0。
通过区分香蕉和西瓜的经典案例来看看感知机是如何工作的。

- 如图所示。为了简单起见,我们假设西瓜和香蕉由且仅有两个特征:形状和颜色,其他特征暂不考虑。这两个特征都是基于视觉刺激而最易得到的。假设特征 代表输入颜色,特征 代表形状,权重 和 的默认值暂且都设为1。为了进一步简化,我们把阈值 (也有教程称之为偏置—bias)设置为0。为了标识方便,我们将感知机输出数字化,若输出为“1”,代表判定为“西瓜”;若输出为“0”,代表判定为“香蕉”。

-
这样一来,可以很容易根据感知机输出 数学表达式,如下式所示,对西瓜和香蕉做出鉴定: 西瓜:𝑦=𝑓(𝑤_1 𝑥_1+𝑤_2 𝑥_2?𝜃)=𝑓(1×1+1×1?0)=𝑓(2)=1 香蕉:𝑦=𝑓(𝑤_1 𝑥_1+𝑤_2 𝑥_2?𝜃)=𝑓(1×(?1)+1×(?1)?0)=𝑓(?2)=0 这里,我们使用了最简单的阶跃函数作为激活函数。在阶跃函数中,输出规则非常简单:当 中 时, 输出为1,否则输出为0。通过激活函数的“润滑”之后,结果就变成我们想要的样子,这样就实现了西瓜和香蕉的判定。 这里需要说明的是,对象的不同特征(比如水果的颜色或形状等),只要用不同数值区分表示开来即可,具体用什么样的值,其实并没有关系。但你们或许还会疑惑,这里的阈值(threshold) 和两个连接权值 和 ,为啥就这么巧分别就是0、1、1呢?如果取其它数值,会有不同的判定结果吗? 接下来我们假定 还是等于1,而 等于-1,阈值 还是等于0。然后我们对于西瓜的特征:绿色圆形通过加权求和再经过阶跃激活函数后输出如下式所示: 西瓜:𝑦=𝑓(𝑤_1 𝑥_1+𝑤_2 𝑥_2?𝜃)=𝑓(1×1+(?1)×1?0)=𝑓(0)=0
-
输出为0,而我们假设的输出值0为香蕉,显然判断错了,对于香蕉的特征我们加权求和经过阶跃激活函数得到输出值为0,对应香蕉,判断正确。由此观之,我们判断正确错误和我们的权值 、 和阈值相关。那么怎么选择权值和阈值呢?事实上,我们并不能一开始就知道这几个参数的取值,而是一点点地“折腾试错”(Try-Error),而这里的“折腾试错”其实就是感知机的学习过程。
3.2 感知机的学习过程
神经网络的学习规则 — 调整神经元之间的连接权值和神经元内部阈值的规则。

- 中国有句古话:“知错能改,善莫大焉”说的就是,犯了错误而能改正,没有比这更好的事了。放到机器学习领域,这句话显然属于“监督学习”的范畴,因为“知错”,就表明事先已有了事物的评判标准,如果你的行为不符合或者偏离这些标准,那么就要根据偏离的程度,来“改善”自己的行为。
- 下面,我们根据这个思想来制定感知机的学习规则。从前面的讨论中,我们已经知道,感知机学习属于“有监督学习”(也称分类算法),具有明确的结果导向性,其实这就类似于“不管白猫黑猫,抓住老鼠就是好猫”的说法,无论是什么样的学习规则,能达到良好的分类目的,就是好的学习规则。我们都知道,对象本身的特征值一旦确定下来就不会变化,可视为常数。因此,如下图所示,神经网络的学习规则就是调整神经元之间的连接权值和神经元内部阈值的规则(这个结论对于深度学习而言依然是适用的)。
感知机的学习过程分为四个阶段。

- 第一个阶段,在学习之前我们会对权重和阈值进行随机初始化,如果初始化的值能判断出是西瓜还是香蕉,则无需学习。但如果判断错了那么就会根据感知机的学习规则,来调整权值和阈值。

- 第二个阶段、上面我们假定的权值ω1=1,ω2 =-1,θ=0,判断出来的结果是错误的,下面我们就用上面的学习规则来模拟感知机的学习过程,完成判定西瓜的学习。第一次判断西瓜的输出值 y如图所示,判断错误。

- 第三个阶段、假设学习规则如下: 在𝜀=𝑦?𝑦^′ 𝑦为期望输出,𝑦^′是实际输出。也就是说 是二者的“落差”。这个差值就是整个网络中权值和阔值的调整动力。进行第一次学习如下。 𝜀_1=𝑦?𝑦^′=1?0=1𝑤_(𝑛𝑒𝑤_1)=𝑤_(𝑜𝑙𝑑_1)+𝜀_1=1+(1?0)=2𝑤_(𝑛𝑒𝑤_2)=𝑤_(𝑜𝑙𝑑_2)+𝜀_1=(?1)+(1?0)=0𝜃_𝑛𝑒𝑤=𝜃_𝑜𝑙𝑑+𝜀_1=0+(1?0)=1

- 结果显示判断正确,因此我们可以认为这个模型在这一的权重和阈值下是没有问题的。
- 在上述案例中,我们仅仅经过一轮“试错法”,我们就搞定了参数的训练,但其实这相当于一个“Hello World”版本的神经网络。事实上,在有监督的学习规则中,我们需要根据输出与期望值的差值,经过多轮重试,反复调整神经网络的权值,直至这个“落差”收敛到能够忍受的范围之内,训练才告结束。比如上面学习的例子中,我们最后得到的新的权重。也就是说没有考虑形状这个特征,虽然我们能正确分类,但显然是不够合理的。

- 综上所述,当我们给定训练数据、神经网络中的参数(权重和阈值)时,都可以通过不断地“纠偏”学习得到最终参数。为了方便,我们通常把阈值视为,而其输入值固定为“-1”(也资料将这个固定值设置为1,其实都是一样的,主要取决于表达式前面的正负号),那么阈值就可被视为一个“哑元节点(Dummy Node)”这样一来,权重和阈值的学习就可以统一为“权重”的学习了。
3.3 感知机的几何意义
- 刚刚我们学习了感知机的训练过程,其实感知机实际解决的是一个二分类问题。下面我们来分析一下感知机的几何意义。
单个特征的感知机 — 在红点和蓝点交界的区间内直接任取一点都可以将这两部分样本分开。
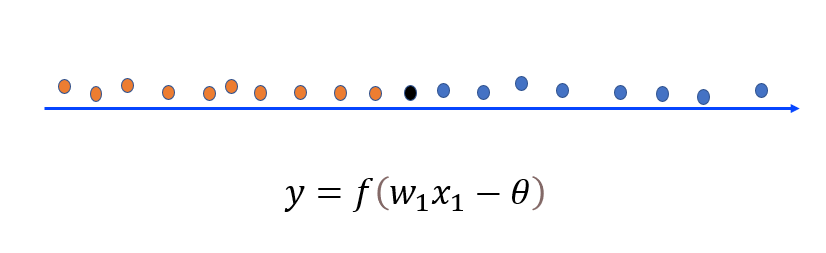
- 先来看一个例子,上图是一个只有𝑥轴的一维坐标轴,该轴同样存在原点,𝑥轴正方向和𝑥轴反方向,且该轴上分布了很多红点和蓝点,此时如果要求在坐标轴上找一个分割点,来分割红点和蓝点,而且要求只允许找一个点来分割这两部分样本,并且要求此点分割效果最好,如何去找呢?答案是:在红点和蓝点交界的区间内直接任取一点都可以将这两部分样本分开,比如这个黑点。其实这个就是我们刚刚学习到的𝑤_2等于0的情况,也就是只根据特征𝑤_1判断输出。
二维特征的感知机 — 可以找到一条直线将两类样本点分开。

- 上面是一维坐标下的情况,我们再来看一个二维坐标下的例子,如下图左侧所示的二维直角坐标系中要将红点与蓝点分开如何做呢?答案是:我们可以找到一条直线将两类样本点分开。在数学中,找到这条直线可以分两步:
-
找到两类样本之间最近的那一部分点;
-
找到一条直线使得最近的那些样本点到此直线的距离相等且尽量最大,此处可以用“点到直线的距离”来解决,并且由于要把两类样本分开,所以必然一部分样本点在直线上方,一部分在直线下方,点的位置由两个输入特征横坐标和纵坐标来决定。这个例子就类似于我们一开始权重 、 都等于1,阈值等于0的情况。
三维特征的感知机 —用一个面将红点和蓝点分离开,这样平面的位置就由三个输入特征决定。
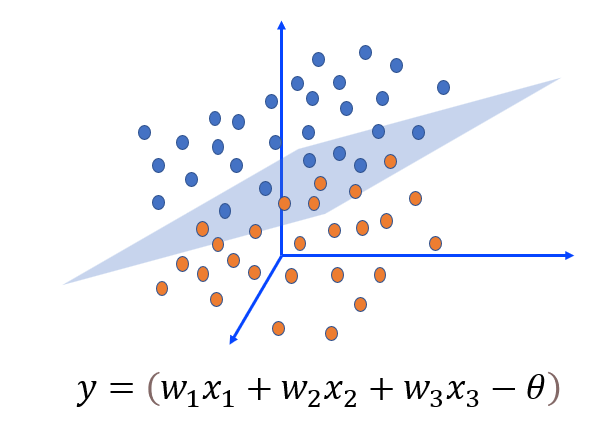
- 同样,在如图右侧所示的三维空间中,我们可以用一个面将红点和蓝点分离开,这样平面的位置就由三个输入特征决定。相对应的,如果这是在上面所提到的西瓜香蕉分类问题中,输入特征再加上重量这一条,类似于在三维坐标下了。
由上述内容,我们总结得到:

- 如果是更高维的数据呢?这时就需要引入超平面。超平面指 维 线性空间中维度为 的子空间。它可以把线性空间分割成不相交的两部分,即把一个空间分成了两个半平面。这就是感知机几何意义,因此,感知机可看作一个由超平面划分空间位置的识别器。
3.4?感知机的应用
布尔函数 — 输入输出都是布尔值的一种函数,主要有“与”门、“与非”门、“或”门、“异或”门。
- 在学习感知机的应用之前,我们可以先来了解一下布尔函数:计算机语言中的布尔变量,只有0和1两种可能的值,布尔函数就是输入输出都是布尔值的一种函数,主要有“与”门、“与非”门、“或”门、“异或”门,以下是各自的功能。
- 1.“与”门,表示输入有0值,输出就为0,输入全为1输出才为1;
- 2.“与非”门,和“与”门相反,输入有0,则输出为1,输入全1才输出0;
- 3.“或”门,表示输入有1,就输出1,输入全0才输出0;
- 4.“异或”门,表示输入相同输出为0,输入不同输出则为1。
- 其实感知机模型的输出就是0和1,以两个输入为例,有没有可能调整权重𝑤和偏置𝜃的值使这个感知机实现“与”门、“与非”门、“或”门和“异或”门的功能呢?我们接下来分别看一下。
“与”门 — 当两个输入均为1时输出为1,其他时候输出为0。

- 与门为有两个输入和一个输出的门电路,它的真值表如下图中左侧所示,当两个输入均为1时输出为1,其他时候输出为0。这里我们可以根据输出 值将结果分为“0”和“1”两类,也可以看为一个二分类问题。
- 将𝑥_1、𝑥_2作为横纵坐标轴,将对应点花在坐标轴上如图3-10所示,其中三角形表示输出𝑦=0,圆形表示输出𝑦=1。我们发现在两临界边界(如图中虚线所示)之间的任意一条线均可作为实现“与”门感知机的分类超平面。
- 如果要使用感知机实现与门真值表的逻辑功能,按照我们之前的理解,只需设定合适的权重参数就可以了。其实我们可以尝试根据感知机的网络参数学习算法求解一个线性方程来表示“与”门,确定满足上表的参数值。方法过程和上面讲的分类香蕉西瓜的例子相同,此处不再赘述,例如[𝑤_1,𝑤_2,𝜃]可以取[1,1,2],[0.5,0.5,0.6]等,大家可以将输入𝑥_1、𝑥_2值代入我们的感知机中进行验证。
“与非”门 — 当输入全1的时候输出为0,当输入有0则输出为1。

- 将𝑥_1、𝑥_2作为横纵坐标轴,将对应点如下图所示标在坐标系中,其中三角形表示输出𝑦=0,圆形表示输出𝑦=1。不难发现在两临界边界(如图中虚线所示)之间的任意一条线均可作为实现“与非”门感知机的分类超平面。
- 根据感知机的网络参数学习算法求解线性方程来表示“与非”门,从而确定满足上表的参数值。方法过程和上面讲的分类香蕉西瓜的例子相同,此处不再赘述,如[𝑤_1,𝑤_2,𝜃]可以取[-0.5,-0.5,-0.7]等值,将输入𝑥_1、𝑥_2值代入我们的感知机中验证。
“或”门——只要有一个输入信号为1,输出就为1的逻辑电路。

- 我们可以将𝑥_1、𝑥_2作为横纵坐标轴,将对应点如下图所示标注在坐标系中,其中三角形表示输出𝑦=0,圆形表示输出𝑦=1。这是在两临界边界(如图中虚线所示)之间的任意一条线均可作为实现“或”门感知机的分类超平面。
- 根据感知机的网络参数学习算法求解一个线性方程来表示“或”门,确定满足上表的参数值。方法过程和上面讲的分类香蕉西瓜的例子相同,此处不再赘述,如[𝑤_1,𝑤_2,𝜃]可以取[1,1,0.5]等值,将输入𝑥_1、𝑥_2值代入我们的感知机中验证。
“异或”门——当𝑥_1和 𝑥_2相同时输出为0,𝑥_1和𝑥_2不同时则输出为1。
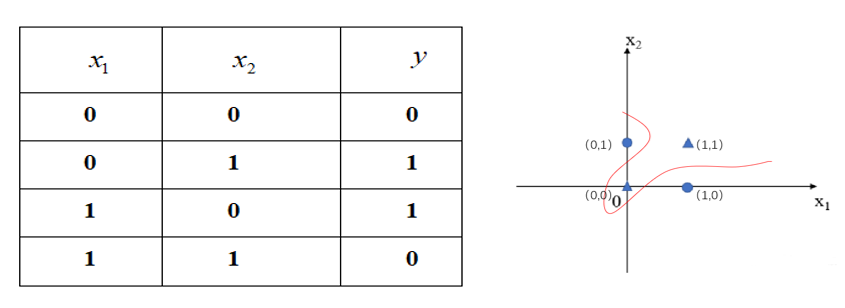
- 将𝑥_1、𝑥_2作为横纵坐标轴,并将对应点标注在下图所示坐标系中,根据图像可知,我们已经无法再通过一条直线将一个整体划为两部分,若强行将它分为两部分,那么就只能是曲线,所划空间也成为非线性空间。
- 在这种情况下,感知机的学习过程就会发生“震荡(Fluctuation)”,权重就难以求得合适的解。因此,单个感知机的局限性在于它只能表示由一条直线分割的空间,对于非线性问题(即线性不可分问题,如上图中的非线性空间)仅用单个感知机无法解决。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!