Hive常见报错与解决方案
背景
公司近期上火山云,hive、hadoop、tez等都有较大的版本升级,继而引发了 一系列的报错。现将遇到的报错内容以及相应解决方法列出来,供大家参考。
关于版本:
| 组件 | 升级前 | 升级后 |
|---|---|---|
| Hive | 1.2 | 2.3 |
| Hadoop | 2.6 | 2.10 |
| Tez | 0.7 | 0.10 |
常见报错
1.hive中无法执行HDFS命令,查看目录属性等

原因:
开源的2.3版本 hive不支持直接dfs这种命令
解决方案:
将命令替换为:
hive> !hdfs fs -ls /ods/table_location;
加!可以将命令转为shell执行
2.同一字段在两张表中类型分别为int 和string,不支持union all
FAILED: SemanticException Schema of both sides of union should match: Column c1 is of type int on first table and type string on second table.
原因:
新版版校验更加严格,要cast为同一种类型后才能union在一起
解决方案:
统一字段类型,cast( as string) 或者 cast( as int)
3.不支持连续的 0< a<25
原因:
版本不兼容,这个是社区低版本的bug,高版本已不允许这样来使用
解决方案:
拆分为:a>0 and a<25
4.FAILED: SemanticException [Error 10305]: CREATE-TABLE-AS-SELECT creates a VOID type, please use CAST to specify the type, near field: ins_choose_date

原因:
建表时必须要交代null的类型
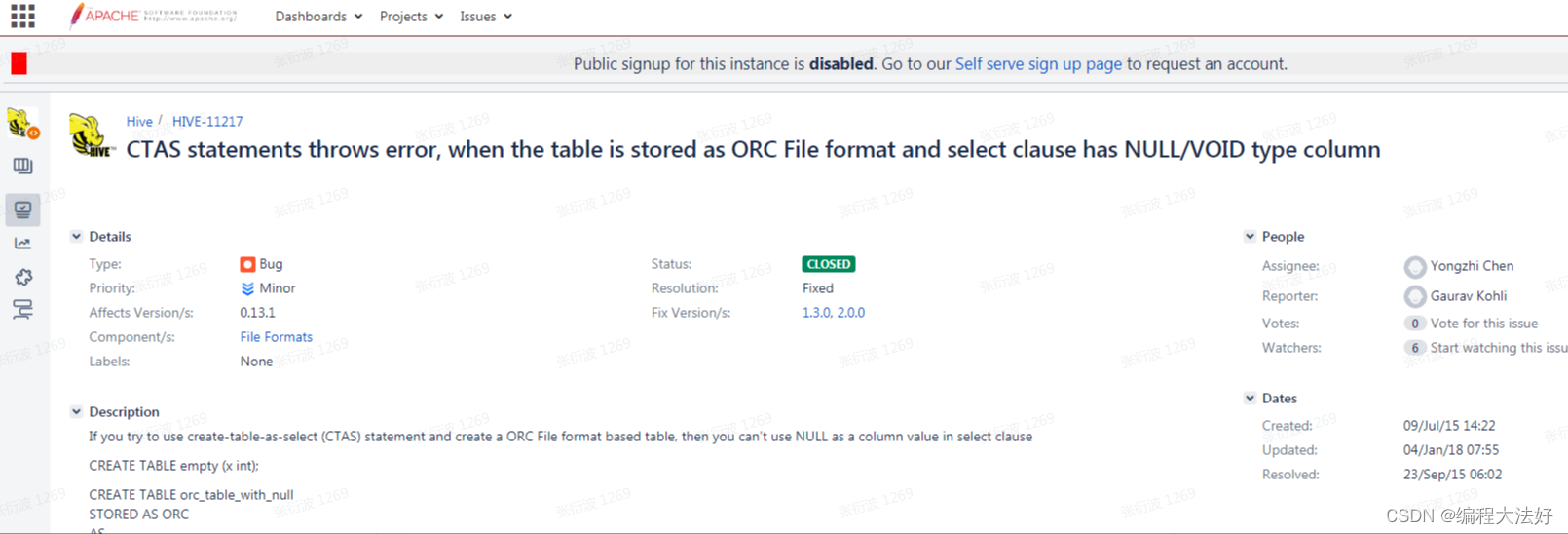
解决方案:
建表时 null 给个默认类型
5.row 、order不支持作为字段别名
原因:
row、order是关键字,作为别名不能使用,在低版本中允许该语法,版本兼容性问题
解决方案:](https://img-blog.csdnimg.cn/direct/9a4266b507834870b8e8eaad1bf9701e.png)
换个别名,同时要考虑下游的使用情况。
6.translate 不支持date类型参数
原因:
translate入参不支持日期类型(timestamp)

解决方案:
改类型
7.concat_ws不兼容date类型参数
Argument 2 of function CONCAT_WS must be “string or array”, but “array” was found
原因:
和6一样,都是版本差异

7.usage: 5.0 GB of 4 GB physical memory used; 6.5 GB of 8.4 GB virtual memory used. Killing container.
原因:
container内存不足,需要扩大container内存,当前是默认1核4G
解决方案:
单个任务
set hive.tez.container.size =6144;
8. Caused by: java.io.IOException: Not a file: hdfs://emr-cluster/ods/ods_dd/2
原因:
ods_dd表下的数据确实有1子目录,需要确认数据来源
解决方案:
set mapreduce.input.fileinputformat.input.dir.recursive=true;
9. tez执行多一层目录 /1 /2…
原因:
- 所有的union all 都会产生1和2这种子目录
- 只要满足merge File的条件(这里逻辑很复杂,主要一个是merge的阈值)都会都会merge,merge了之后就不会有子目录
- 如果union all里只有一个表有数据,那么只会产生一个子目录(即只有1或者2),这样的情况下不会merge
解决方案:
先写入临时表,在将临时表插入正式表
10.Caused by: java.lang.ArrayIndexOutOfBoundsException: 1
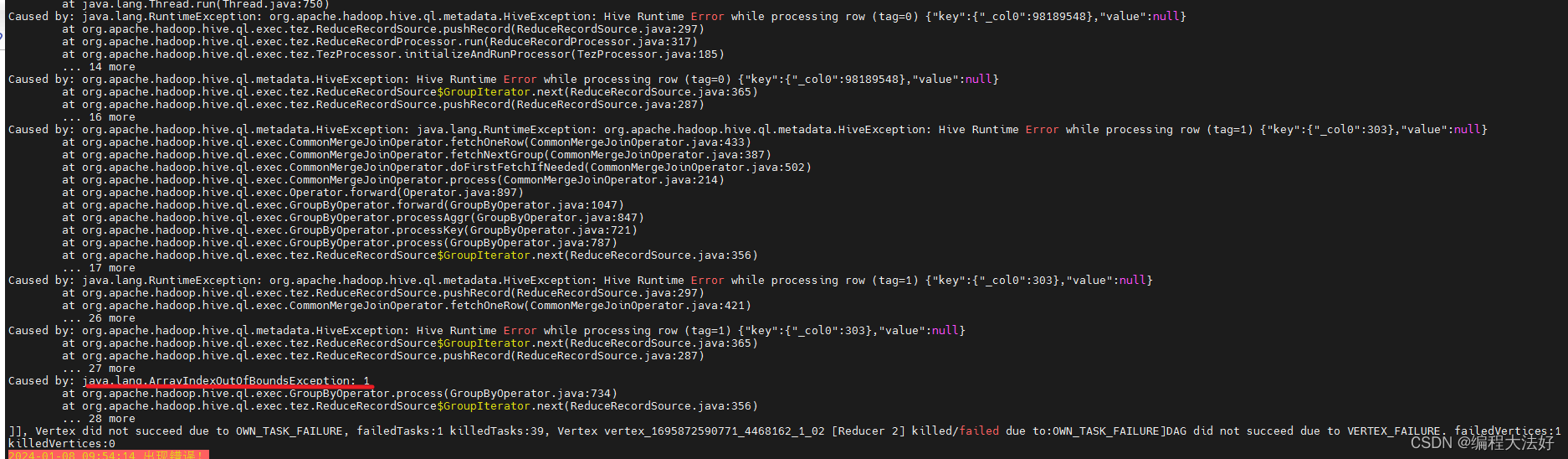
原因:
据本身的问题,存在这么一种情况,全部字段只有一个有值,另外全部为null,这个建议看看hdfs文件
解决方案:
1.替换执行引擎为TEZ
2. set hive.auto.convert.sortmerge.join =false;
11.动态分区load 多partition数据失败
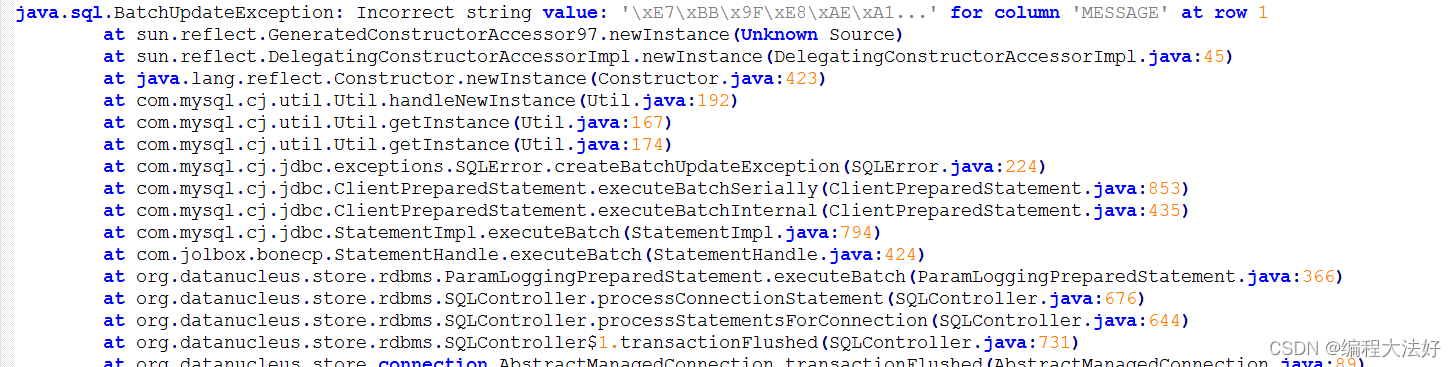
原因:
元数据库字段字符集类型不对
解决方案:
--notification_log 表 MESSAGE 字段需要 改为 utf-8 编码
mysql> alter table notification_log modify MESSAGE longtext CHARACTER SET utf8 COLLATE utf8_general_ci;
12.Hive on tez和mr执行同一张表多次join结果不一致
此现象发生在a join a 的时候,且a是orc表。
原因:
总结了以下特征,是会必现上述结果:
1.同一脚本内(即多次查询在同一个Application内),对于一个orc格式的表,多次查询,条件不同
2.开启了run time filter
3.开启了orc push down
4.有inner join情况
5.run time filter作用的是orc表
解决方案:
建议切换hive on Tez引擎来处理。
如果不可切换tez引擎,建议修改参数 hive.optimize.index.filter=false,对执行性能有一定的影响,慎重修改。参数 hive.optimize.index.filter=false 可以避免将 TableScan 的 Filter 下推
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!