爬取涛声网音频
代码展现: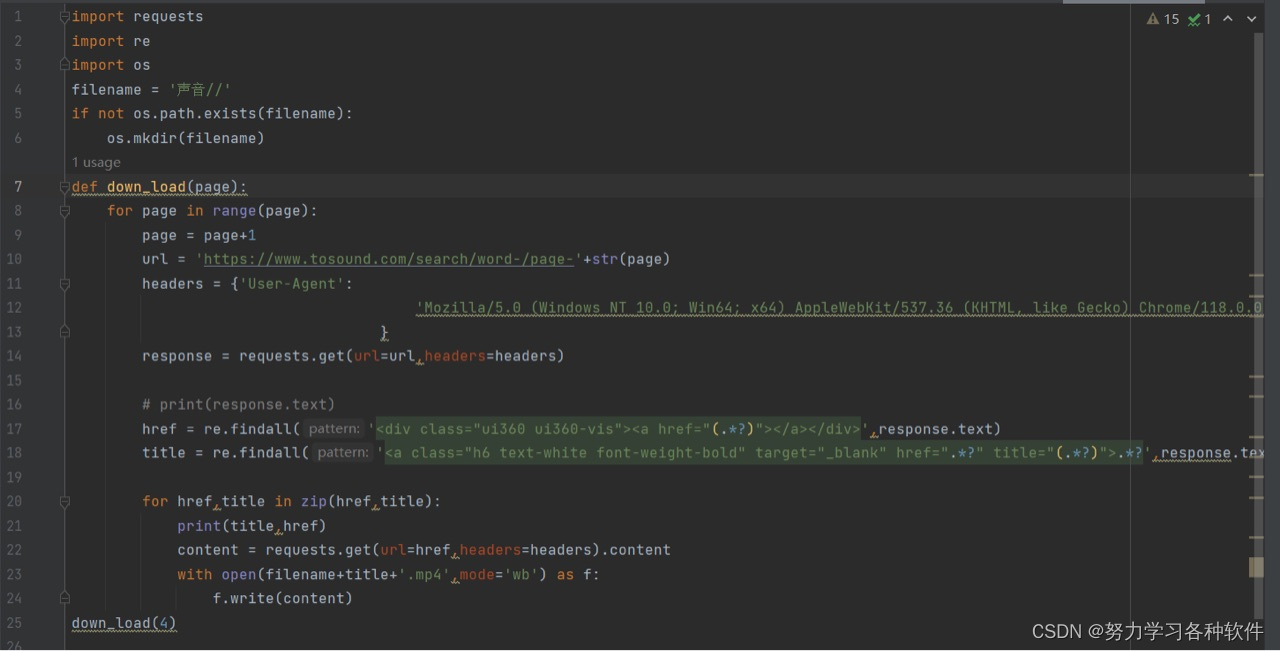
代码详情:
import requests
import re
import os
filename = '声音//'
if not os.path.exists(filename):
? ? os.mkdir(filename)
def down_load(page):
? ? for page in range(page):
? ? ? ? page = page+1
? ? ? ? url = 'https://www.tosound.com/search/word-/page-'+str(page)
? ? ? ? headers = {'User-Agent':
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?}
? ? ? ? response = requests.get(url=url,headers=headers)
? ? ? ? # print(response.text)
? ? ? ? href = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>',response.text)
? ? ? ? title = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?',response.text)
? ? ? ? for href,title in zip(href,title):
? ? ? ? ? ? print(title,href)
? ? ? ? ? ? content = requests.get(url=href,headers=headers).content
? ? ? ? ? ? with open(filename+title+'.mp4',mode='wb') as f:
? ? ? ? ? ? ? ? f.write(content)
down_load(4)
结果展现:
总结:
1.这同样是一个动态加载的页面,在xhr中找到包后,发现跟前面爬好看视频的不同点在于,它不是json的数据格式,不确定链接在不在里面(其实是在的,用正则解析可以轻松获取)
2.所以首先还是打开一个音频,在media中找到他,复制url的关键部分,在All中搜索,找他含有这个链接的包,发现就是xhr获取到的。
3.接下来按照常规步骤走,复习了一遍os ,re.find all,zip,with open的用法。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!