做点记录:Attention稀疏化与线性化
背景
本文来自苏剑林老师的为节约而生:从标准Attention到稀疏Attention。
Attention 来源于 18 年初的 Attention is All You Need(乘性 Attention), 其核心在于 QKV 三个向量序列的交互融合,其中,QK 的交互给出了两两向量之间的某种权重,最后由 V 按照权重求和得到输出序列。常见的 Attention 为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
?
d
k
)
V
Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^\top}{\sqrt{d_k}}\right)\boldsymbol{V}
Attention(Q,K,V)=softmax(dk??QK??)V
此外,还有加性 Attention,但该类 Attention 并行不容易实现或实现所需资源较多,所以一般只用来将变长向量序列编码为固定长度的向量(取代简单的 Pooling)。
乘性 Attention 中,最广泛使用的是 Self-Attention,该情况下,QKV 均为同一个 X 经过线性变换得到的。这样,输出结果就是跟 X 一样长的向量序列,并且能够直接捕捉 X 中任意两个向量的关联,而且易于并行。 这都是 Self Attention 的优点。
理论上来讲,Self-Attention 的计算时间和显存占用均为平方级别,因此不可避免地会导致 OOM 。
Softmax 妙用
常见的 Attention 的一般化定义:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
i
=
∑
j
=
1
n
sin
?
(
q
i
,
k
j
)
v
j
∑
j
=
1
n
sin
?
(
q
i
,
k
j
)
Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i=\frac{\sum_{j=1}^n\sin(\boldsymbol{q}_i,\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum_{j=1}^n\sin(\boldsymbol{q}_i,\boldsymbol{k}_j)}
Attention(Q,K,V)i?=∑j=1n?sin(qi?,kj?)∑j=1n?sin(qi?,kj?)vj??
为保证 Attention 的相似特性,要确保
s
i
m
(
q
i
,
k
j
)
≥
0
sim (q_i, k_j)\geq 0
sim(qi?,kj?)≥0 恒成立。这种形式的 Attention 在 CV 中也被称为 Non-Local 网络。若直接去除 Softmax,
s
i
m
(
q
i
,
k
j
)
=
q
i
T
k
j
sim(q_i,k_j)=q_i^Tk_j
sim(qi?,kj?)=qiT?kj?,无法保证内积的非负性,因此有几个可行的方案:
核函数
一个自然的想法是,若 q i , k j q_i,k_j qi?,kj? 的每个元素均为非负,那么内积自然也就是非负。为完成该点,给 q i , k j q_i,k_j qi?,kj? 各自加激活函数,即: sin ? ( q i , k j ) = ? ( q i ) ? φ ( k j ) \sin(\boldsymbol{q}_i,\boldsymbol{k}_j)=\phi(\boldsymbol{q}_i)^\top\varphi(\boldsymbol{k}_j) sin(qi?,kj?)=?(qi?)?φ(kj?),其中, ? ( ? ) , φ ( ? ) \phi (\cdot),\varphi(\cdot) ?(?),φ(?) 均为值域非负的激活函数。该公式可联想到和方法,特别是当 ? = φ \phi=\varphi ?=φ 时, ? \phi ? 相当于核函数,而 < ? ( q i ) , φ ( k j ) > <\phi(q_i),\varphi(k_j)> <?(qi?),φ(kj?)> 就是通过核函数定义的内积。
妙用 SoftMax
若 Q 在 d 维是归一化的,K 在 n 维是归一化的,那么 Q K T QK^T QKT 就自动归一化,即: A t t e n t i o n ( Q , K , V ) = s o f t m a x 1 ( Q ) s o f t m a x 2 ( K ) ? V Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=softmax_1(\boldsymbol{Q})softmax_2(\boldsymbol{K})^\top\boldsymbol{V} Attention(Q,K,V)=softmax1?(Q)softmax2?(K)?V, 各自给 QK 加 softmax,而不是 Q K T QK^T QKT 计算完才加 Softmax。
作者自己的构思
该构思的出发点来自对 Attention 的原始定义,由泰勒展开可知: e q i ? k j ≈ 1 + q i ? k j e^{\boldsymbol{q}_i^\top\boldsymbol{k}_j}\approx1+\boldsymbol{q}_i^\top\boldsymbol{k}_j eqi??kj?≈1+qi??kj?,若 q i ? k j ≥ ? 1 \boldsymbol{q}_i^\top\boldsymbol{k}_j\geq -1 qi??kj?≥?1,那么可保证右端的非负性,从而可以让 s i m ( q i , k j ) = 1 + q i T k j sim(q_i,k_j)=1+q_i^Tk_j sim(qi?,kj?)=1+qiT?kj?。因此,想要保证 q i ? k j ≥ ? 1 \boldsymbol{q}_i^\top\boldsymbol{k}_j\geq -1 qi??kj?≥?1,只需要分别对 q i , k j q_i,k_j qi?,kj? 做 l 2 l_2 l2? 归一化。所以,最终方案为: sin ? ( q i , k j ) = 1 + ( q i ∥ q i ∥ ) ? ( k j ∥ k j ∥ ) \sin(\boldsymbol{q}_i,\boldsymbol{k}_j)=1+\left(\frac{\boldsymbol{q}_i}{\|\boldsymbol{q}_i\|}\right)^\top\left(\frac{\boldsymbol{k}_j}{\|\boldsymbol{k}_j\|}\right) sin(qi?,kj?)=1+(∥qi?∥qi??)?(∥kj?∥kj??)
Sparse Attention
所谓自注意力是
O
(
n
2
)
O(n^2)
O(n2) 的,因为它要对序列中任意两向量都要计算相关度,得到
n
2
n^2
n2 大小的相关度矩阵: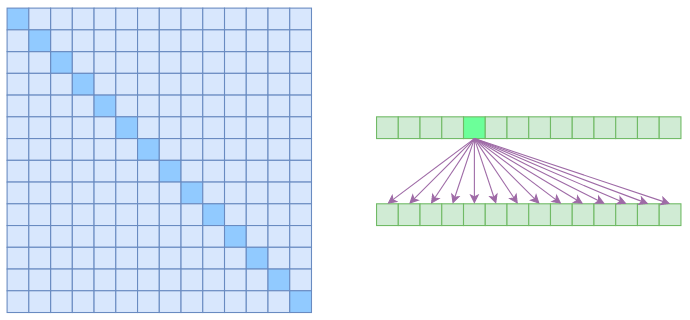
上图中,左边显示了注意力矩阵,右边显示其关联性,这表明每个元素都与序列内所有元素关联。若要节省显存,加快计算速度,那么基本的思路就是减少关联性计算,也就是认为每个元素只与序列内一部分元素有关,此即稀疏 Attention的基本原理。文章所介绍的 Sparse Attention,来源于 OpenAI 的论文 Generating Long Sequences with Sparse Transformers
Atrous Self Attention
首先,引入Atrous Self Attention, 中文名为膨胀自注意力、空洞自注意力等。该注意力启发自膨胀卷积,如下图所示,其对相关性进行约束,强行要求每个元素只与其相对距离为 k, 2k, 3k 的元素关联,其中,k>1 是预先设定的超参数。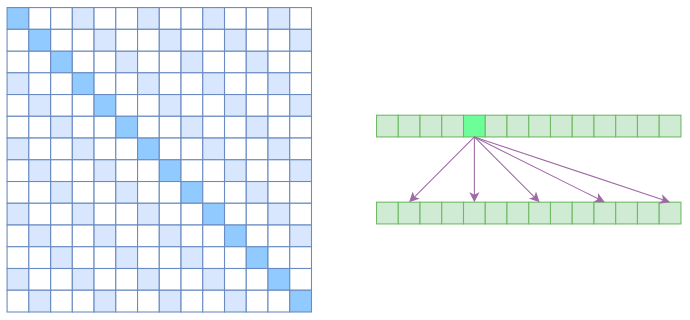
在这种计算方式中,每个元素只与
N
k
\frac{N}{k}
kN? 个元素计算相关性,因此,理想情况下,运算效率和显存占用都变为
O
(
N
2
k
)
O(\frac{N^2}{k})
O(kN2?)
Local Self Attention
另一个要引入的过渡概念是?Local Self Attention,中文可称之为“局部自注意力”。其实自注意力机制在 CV 领域统称为“Non Local”,而显然 Local Self Attention 则要放弃全局关联,重新引入局部关联。具体来说也很简单,就是约束每个元素只与前后 k 个元素以及自身有关联,如下图所示:
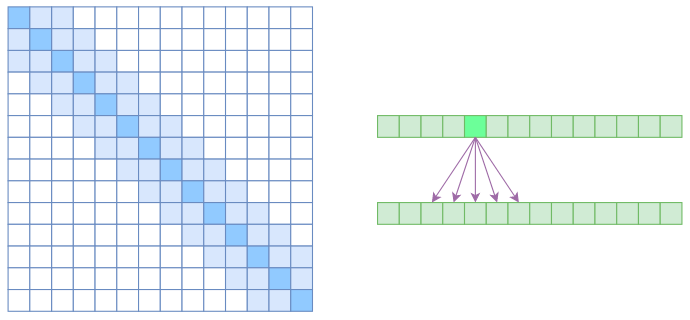
也即,相对距离超过 k 的权重值均设定为 0。对于 Local Self Attention 来说,每个元素只跟 2k+1 个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了
O
(
(
2
k
+
1
)
n
)
~
O
(
k
n
)
O ((2k+1) n)~O (kn)
O((2k+1)n)~O(kn) 了,也就是说随着 n 而线性增长,这是一个很理想的性质——当然也直接牺牲了长程关联性。
Sparse Self-Attention
到此,就可以很自然地引入 OpenAI 的?Sparse Self Attention?了。我们留意到, Atrous Self Attention 是带有一些洞的,而 Local Self Attention 正好填补了这些洞,所以一个简单的方式就是将 Local Self Attention 和 Atrous Self Attention 交替使用,两者累积起来,理论上也可以学习到全局关联性,也省了显存。
简单来说,假定两层 Attention,第一层采用 Local Self Attention,第二层采用 Atrous Self Attention。那么,在第一层,输出的每个向量均融合局部的几个输入向量,第二层的输出理论上可与任意输入向量相关,实现长程关联。
但是 OpenAI 是将两个 Atrous Self Attention 和 Local Self Attention 合并为一个,如下图所示:
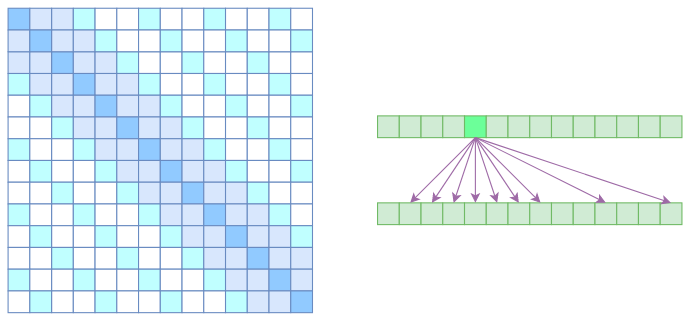
从注意力矩阵上看就很容易理解了,就是除了相对距离不超过 k 的、相对距离为 k, 2k, 3k,… 的注意力都设为 0,这样一来 Attention 就具有**“局部紧密相关和远程稀疏相关”**的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
与之后的 LongFormer 类似,该方法有两个不足之处:
- 保留的注意力区域由人工决定,带有很大的主观性;
- 需要从编程上进行特定优化,才能得到一个高效的实现,不容易推广。
Reformer
该工作将 Attention 的复杂度降至
O
(
n
l
o
n
g
n
)
O(nlongn)
O(nlongn)。某种意义上来说,也算稀疏 Attention 的一种,只不过其稀疏模式由 LSH(Locality Sensitive Hashing) 技术(近似地)快速地找到最大的若干个 Attention 值,然后只计算那若干个值。
此外,Reformer 通过构造可逆形式的 FFN(Feedforward Network)替换掉原来的 FFN,然后重新设计反向传播过程,从而降低了显存占用量。
所以,相比前述稀疏 Attention,Reformer 解决了它的第一个缺点,但是依然有第二个缺点:实现起来复杂度高。要实现 LSH 形式的 Attention 比标准的 Attention 复杂多了,对可逆网络重写反向传播过程对普通读者来说更是遥不可及。
LinFormer
该模型依然保留原始 Scale-Dot Attention 形式,但在进行 Attention 之前,用两个
m
×
n
m\times n
m×n 的矩阵
E
,
F
E,F
E,F 分别对
K
,
V
K,V
K,V 投影,即变为
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
(
E
K
)
?
)
F
V
Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=softmax(\boldsymbol{Q}(\boldsymbol{EK})^\top)\boldsymbol{FV}
Attention(Q,K,V)=softmax(Q(EK)?)FV。这样,
Q
(
E
K
)
T
Q(EK)^T
Q(EK)T 就只是一个
n
×
m
n\times m
n×m 的矩阵,而作者声称对于哪怕很大的序列,
n
,
m
n,m
n,m 也可保持一个适当的常数,从而该 Attention 就是线性的。
但是,原论文中对于长序列作者只做了 MLM 任务,而很明显 MLM 并不那么需要长程依赖,所以这个实验没什么说服力。因此,Linformer 是不是真的 Linear,还有待商榷。
下采样技术
从结果上看,LinFormer 的 Q ( E K ) T Q(EK)^T Q(EK)T 就是将序列变短(下采样),实现该操作的最朴素的办法是 Pooling,所以也可尝试采用 Pooling。当然,其实还有其他的下采样技术,比如可以通过 stride > 1 的一维卷积来实现,基于这个思路,或许我们可以把 FFN 里边的 Position-Wise 全连接换成 stride > 1 的一维卷积?总之这方面应该也能玩出很多花样来,不过跟 Linformer 一样,这样糅合之后做自回归生成就很难了。
采用随机投影将 Attention 的复杂度线性化
针对平方复杂度的 Attention,改进思路有两种:稀疏化和线性化。本部分介绍一个新的改进工作 Performer,其目标是通过随机投影,在不损失精度的情况下,将 Attention 的复杂度线性化。理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了
O
(
n
)
O(n)
O(n)。其最大贡献在于,找到一个很好的映射方案:
e
q
?
k
=
E
ω
~
N
(
ω
;
0
,
1
d
)
[
e
ω
?
q
?
∥
q
∥
2
/
2
×
e
ω
?
k
?
∥
k
∥
2
/
2
]
≈
1
m
(
e
ω
1
?
q
?
∥
q
∥
2
/
2
e
ω
2
?
q
?
∥
q
∥
2
/
2
?
e
ω
m
?
q
?
∥
q
∥
2
/
2
)
?
q
?
1
m
(
e
ω
1
?
k
?
∥
k
∥
2
/
2
e
ω
2
?
k
?
∥
k
∥
2
/
2
?
e
ω
m
?
k
?
∥
k
∥
2
/
2
)
?
k
\begin{aligned} e^{q\cdot k}& =\mathbb{E}_{\boldsymbol{\omega}\sim\mathcal{N}(\boldsymbol{\omega};0,\mathbf{1}_{d})}\left[e^{\boldsymbol{\omega}\cdot\boldsymbol{q}-\|\boldsymbol{q}\|^{2}/2}\times e^{\boldsymbol{\omega}\cdot\boldsymbol{k}-\|\boldsymbol{k}\|^{2}/2}\right] \\ &\approx\underbrace{\frac1{\sqrt{m}}\begin{pmatrix}e^{\boldsymbol{\omega}_1\cdot\boldsymbol{q}-\|\boldsymbol{q}\|^2/2}\\e^{\boldsymbol{\omega}_2\cdot\boldsymbol{q}-\|\boldsymbol{q}\|^2/2}\\\vdots\\e^{\boldsymbol{\omega}_m\cdot\boldsymbol{q}-\|\boldsymbol{q}\|^2/2}\end{pmatrix}}_{\boldsymbol{q}}\cdot\underbrace{\frac1{\sqrt{m}}\begin{pmatrix}e^{\boldsymbol{\omega}_1\cdot\boldsymbol{k}-\|\boldsymbol{k}\|^2/2}\\e^{\boldsymbol{\omega}_2\cdot\boldsymbol{k}-\|\boldsymbol{k}\|^2/2}\\\vdots\\e^{\boldsymbol{\omega}_m\cdot\boldsymbol{k}-\|\boldsymbol{k}\|^2/2}\end{pmatrix}}_{\boldsymbol{k}} \end{aligned}
eq?k?=Eω~N(ω;0,1d?)?[eω?q?∥q∥2/2×eω?k?∥k∥2/2]≈q
m?1?
?eω1??q?∥q∥2/2eω2??q?∥q∥2/2?eωm??q?∥q∥2/2?
????k
m?1?
?eω1??k?∥k∥2/2eω2??k?∥k∥2/2?eωm??k?∥k∥2/2?
???? 第一个等号意味着只要从标准正态分布中采样无穷尽的
ω
\omega
ω,然后算出
e
ω
?
q
?
∥
q
∥
2
/
2
×
e
ω
?
k
?
∥
k
∥
2
/
2
e^{\boldsymbol{\omega}\cdot\boldsymbol{q}-\|\boldsymbol{q}\|^2/2}\times e^{\boldsymbol{\omega}\cdot\boldsymbol{k}-\|\boldsymbol{k}\|^2/2}
eω?q?∥q∥2/2×eω?k?∥k∥2/2 的平均,结果就等于
e
q
?
k
e^{q\cdot k}
eq?k,写成积分形式就是:
1
(
2
π
)
d
/
2
∫
e
?
∥
ω
∥
2
/
2
×
e
ω
?
q
?
∥
q
∥
2
/
2
×
e
ω
?
k
?
∥
k
∥
2
/
2
d
ω
=
1
(
2
π
)
d
/
2
∫
e
?
∥
ω
?
q
?
k
∥
2
/
2
+
q
?
k
d
ω
=
e
q
?
k
\begin{aligned} &\frac1{(2\pi)^{d/2}}\int e^{-\|\boldsymbol{\omega}\|^2/2}\times e^{\boldsymbol{\omega}\cdot\boldsymbol{q}-\|\boldsymbol{q}\|^2/2}\times e^{\boldsymbol{\omega}\cdot\boldsymbol{k}-\|\boldsymbol{k}\|^2/2}d\boldsymbol{\omega} \\ &= \frac1{(2\pi)^{d/2}}\int e^{-\|\boldsymbol{\omega}-\boldsymbol{q}-\boldsymbol{k}\|^2/2+\boldsymbol{q}\cdot\boldsymbol{k}}d\boldsymbol{\omega} \\ &= e^{q\cdot\boldsymbol{k}} \end{aligned}
?(2π)d/21?∫e?∥ω∥2/2×eω?q?∥q∥2/2×eω?k?∥k∥2/2dω=(2π)d/21?∫e?∥ω?q?k∥2/2+q?kdω=eq?k?
当然,实际情况中只能采样有限的 m 个,因此就得到约等,正好可表示为两个 m 维向量的内积的形式,此即
e
q
?
k
≈
q
~
?
k
~
e^{q\cdot k}\approx\tilde{q}\cdot\tilde{k}
eq?k≈q~??k~。借助该加你,就可以得到两个 d 维向量的内积的直属,转为两个 m 维向量的内积,理论上,就可以将 head_size=d 的标准 Attention,转化为 head_size=m 的线性 Attention。
文中,各个
ω
\omega
ω 是独立重复地从
N
(
ω
;
0
,
1
d
)
\mathcal{N}(\omega;0,\mathbf{1}_d)
N(ω;0,1d?) 中采样得到,若将这些
ω
\omega
ω 正交化(保持模长不变,仅对其方向进行施密特正交化),能有效降低估算的方差,提高单次估算的平均精度。该策略有效的最根本原因是采样分布
N
(
ω
;
0
,
1
d
)
\mathcal{N}(\omega;0,\mathbf{1}_d)
N(ω;0,1d?) 的各向同性,即其概率密度函数
(
2
π
)
?
d
/
2
e
?
∥
ω
∥
2
/
2
(2\pi)^{-d/2}e^{-\|\boldsymbol{\omega}\|^2/2}
(2π)?d/2e?∥ω∥2/2 值依赖于
ω
\omega
ω 的模长
∥
ω
∥
\left\|\omega\right\|
∥ω∥,所以在方向上是均匀的。若要降低估算的方差,那么就要降低采样的随机性,使得采样的结果更为均匀。而各个向量正交化,是方向上均匀的一种实现方式,换句话说,将各个
ω
i
\omega_i
ωi? 正交化促进了采样结果的均匀化,从而降低估算的方差。此外,正交化操作一般只对
m
≤
d
m\leq d
m≤d 有效,若
m
>
d
m > d
m>d,则将每 d 个向量为一组分别进行正交化。可以联想到,正交化操作只是让采样的方向更均匀,若做得彻底些,可以让采样的模长也均匀化。具体来说,将标准正态分布变换为 d 维球坐标得到其概率微元:
1
(
2
π
)
d
/
2
r
d
?
1
e
?
r
2
/
2
d
r
d
S
\frac{1}{(2\pi)^{d/2}}r^{d-1}e^{-r^{2}/2}drdS
(2π)d/21?rd?1e?r2/2drdS 其中,
d
S
=
sin
?
d
?
2
φ
1
sin
?
d
?
3
φ
2
?
sin
?
φ
d
?
2
d
φ
1
d
φ
2
?
d
φ
d
?
1
dS=\sin^{d-2}\varphi_1\sin^{d-3}\varphi_2\cdots\sin\varphi_{d-2}d\varphi_1d\varphi_2\cdots d\varphi_{d-1}
dS=sind?2φ1?sind?3φ2??sinφd?2?dφ1?dφ2??dφd?1? 代表在 d 维球面上的积分微元。上式就显示出,标准正态分布是均匀的,模长的概率密度函数正比于
r
d
?
1
e
?
r
2
/
2
r^{d-1}e^{-r^{2}/2}
rd?1e?r2/2, 我们可以定义其累积概率函数:
P
d
(
r
≤
R
)
=
∫
0
R
r
d
?
1
e
?
r
2
/
2
d
r
∫
0
∞
r
d
?
1
e
?
r
2
/
2
d
r
P_d(r\leq R)=\frac{\int_0^Rr^{d-1}e^{-r^2/2}dr}{\int_0^\infty r^{d-1}e^{-r^2/2}dr}
Pd?(r≤R)=∫0∞?rd?1e?r2/2dr∫0R?rd?1e?r2/2dr? 若要采样 m 个样本,那么让
P
d
(
r
≤
R
i
)
=
i
m
+
1
,
i
=
1
,
2
,
?
?
,
m
P_d(r\leq R_i)=\frac{i}{m+1},i=1,2,\cdots,m
Pd?(r≤Ri?)=m+1i?,i=1,2,?,m,从中解出 m 个
R
i
R_i
Ri? 作为模长即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!