大模型LLM训练的数据集
引言
2021年以来,大预言模型的开发和生产使用呈现出爆炸式增长。除了李开复、王慧文、王小川等“退休”再创业的互联网老兵,在阿里巴巴、腾讯、快手等互联网大厂的中高层也大胆辞职,加入这波创业浪潮。
通用大模型初创企业MiniMax完成了新一轮融资,总规模超2.5亿美元,项目估值超过10亿美元,跻身独角兽行列。阿里巴巴技术副总裁贾扬清在朋友圈回应了离职传言,称其和团队已于3月20日从阿里“毕业”,贾扬清表示,“白驹过隙,我也计划走向职业生涯的下一个挑战”。
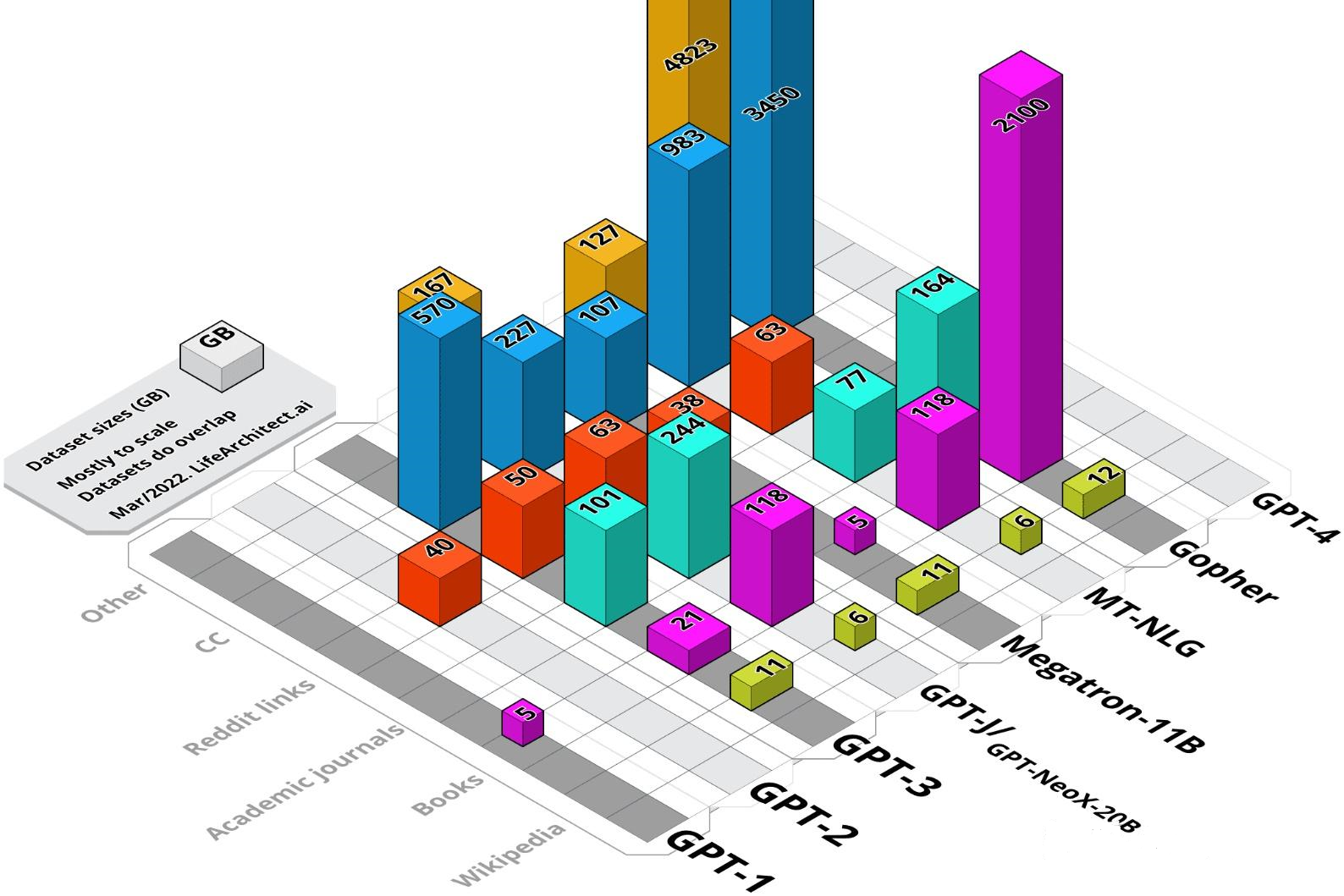
随着新型AI技术的快速发展,模型训练数据集的相关文档质量有所下降。模型内部到底有什么秘密?它们又是如何组建的?本文综合整理并分析了现代大型语言模型的训练数据集。说白了,大模型很火,数据感觉很神秘。
1 概述
大模型预训练需要从海量的文本数据中学习到充分的知识存储在其模型参数中。预训练所用的数据可以分为两类。
1)一类是网页数据(web data),这类数据的获取最为方便,各个数据相关的公司比如百度、谷歌等每天都会爬取大量的网页存储起来。其特点是量级非常大,比如非盈利性机构构建的CommonCrawl数据集是一个海量的、非结构化的、多语言的网页数据集。它包含了超过 8 年的网络爬虫数据集,包含原始网页数据(WARC)、元数据(WAT)和文本提取(WET),包含数百亿网页,数据量级在PB级规模,可从 Amazon S3 上免费获取。
2)第二类称之为专有数据(curated high-quality corpora),为某一个领域、语言、行业的特有数据。比如对话、书籍、代码、技术报告、论文考试等数据。这类数据比较难获取,如果在中国那么最优代表性的就应该是在我们的图书馆、国家数字档案馆、国家数字统计局等机构和地方。
在OpenAI的GPT3,4模型以及谷歌的PaLM系列模型训练中,大量用到了专有数据,如2TB的高质量书籍数据(Books – 2TB)和社交媒体对话数据(Social media conversations)等。这些专业数据是不对公众开放的,就拿高质量的book书籍数据来说,在网上能直接获取到数据来自The pile中的Book3,量级也才85GB左右,和这些巨头所用数据量级相差数十倍。
因此现在有一种普遍观点认为“GPT、PaLM等模型的成功很大程度源自于其他模型难以企及的大量的、高质量的专有数据”。比如LLM大模型的小火种,LLaMA在论文中就提到,自己所用的高质量数据只有177GB所以在MMLU等知识性推理任务上和PaLM相差了十几个点,如果能给LLaMA更多更好的数据,LLaMA说我还能更强。
2 数据分类
在很多论文中,或者很多材料中会经常出现下面这种图,说实话刚开始看的时候觉得挺酷的,然后就没然后了。其实这种图对于观察我们的数据分布非常有用。
因为其后面对大模型预训练时候的数据类型、数据量、数据格式都有规范化后的统一统计,例如上面图中来源《The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset》,对BLOOM大模型训练的时候使用了1321.89 GB数据,一共超过40+不同国家的语预语言,对于代码Code有10+不同的编程语言。

又好像下面这个图来源于《aLM: Scaling Language Modeling with Pathways》,里面对PALM大模型预训练的数据集进行了类型的统计,有多少是新闻类、多少是社交数据、多少是法律条纹数据等,这个时候就知道为什么PALM大模型会比BLOOM大模型的效果更好的原因,因为可以更加清晰或者深入地清晰和梳理数据,搞清楚用来做大模型预训练数据的比例。

3 常用数据集
大多数基于Transformer的大型语言模型 (LLM) 都依赖于英文维基百科
和Common Crawl、C4、Github的4个大型数据集。这几个数据集是最常用的,基本上大部分大模型训练过程都会使用到,其中CommonCrawl的数据集比较大,而wiki Pedia的数据集比较规整相对来说比较少。
3.1 English CommonCrawl
使用模型:LLaMA(67%)、LaMDA、PaLM
处理方案:Common Crawl是2008年至今的一个网站抓取的大型数据集,数据包含原始网页、元数据和文本提取,它的文本来自不同语言、不同领域。基于AllenAI (AI2)的C4论文,可以确定,过滤后的英文C4数据集的每个域的token数和总体百分比,该数据集为305GB,其中token数为1560亿。在大模型训练的过程中,很少直接使用CommonCrawl的数据集,而是首先对CommonCrawl数据集进行了两个主要的处理,即低质量页面过滤、页面相似性去重,以避免过拟合。
下载链接:https://github.com/karust/gogetcrawl

3.2 Wikipedia
使用模型:LLaMA(4.5%)、GPT-NEOX(1.53%)、LaMDA、PaLM
处理方案:数据集中添加了2022年6月至8月期间的维基百科dumps,涵盖20种语言,包括使用拉丁字母或西里尔字母的语言,具体为bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk;然后对数据进行预处理,以去除超链接、评论和其他格式化的html模板。wiki Pedia 数据集涵盖了2015年抽样的1001篇随机文章,研究人员注意到随时间推移文章传播的稳定性。假设一个11.4GB、经过清理和过滤的维基百科英文版有30亿token,就可以确定类别大小和token。
下载链接:https://huggingface.co/datasets/wikipedia、https://github.com/noanabeshima/wikipedia-downloader

3.3 C4
使用模型:LLaMA(15%)、LaMDA、PaLM
处理方案:CommonCrawl和C4有着很强的关系,因为都是同源的,重点研究实验室一般会首先选取它的纯英文过滤版(C4)作为数据集。C4数据集是Common Crawl在2019年的快照,包含新闻、法律、维基百科和通用网络文档等多种文本类型。C4的预处理也包含重复数据删除和语言识别步骤:与CCNet的主要区别是质量过滤,主要依靠启发式方法,如是否存在标点符号,以及网页中的单词和句子数量。
下载链接:https://huggingface.co/datasets/c4、https://paperswithcode.com/dataset/c4

3.4 Github
使用模型:LLaMA(4.5%)、GPT-NEOX(7.59%)、PaLM、OPT、GLM130B
使用谷歌BigQuery上的GitHub公共数据集,只保留在Apache、BSD和MIT许可下发布的项目。然后用基于行长或字母数字字符比例的启发式方法过滤了低质量的文件,并用正则表达式删除了HTML boilerplate(如等)。最后在文件层面上对所生成的数据集进行重复计算,并进行精确匹配。
下载链接:https://github.com、https://github.com/EleutherAI/github-downloader
4 其他数据
4.1 Pile-CC
模型:GPT-NEOX(18.11%)
基于Common crawl的数据集,在Web Archive文件(包括页面HTML在内的原始HTTP响应)上使用jusText (Endrédy和Novák, 2013)的方法进行提取,这比直接使用WET文件(提取的明文)产生更高质量的输出。
下载链接:https://github.com/leogao2/commoncrawl_downloader
4.2 WebText2
模型:GPT-NEOX(10.01%)
OpenWebText2 (OWT2)是一个基于WebText (Radford et al, 2019)和OpenWebTextCorpus (Gokaslan and Cohen, 2019)的广义web抓取数据集。
下载链接:https://github.com/EleutherAI/openwebtext2
4.3 Gutenberg and Books3
模型:LLaMA(4%)、GPT-NEOX(12.07%)、GPT-NEOX(2.17%)
训练数据集中包括两个书籍相关的语料库,Gutenberg Project为公共领域的书籍;ThePile中Books3部分是一个用于训练大型语言模型的公开数据集。预处理操作主要是删除重复内容超过90%的书籍。
下载链接:https://shibamoulilahiri.github.io/gutenberg_dataset.html、https://twitter.com/theshawwn/status/1320282149329784833、https://github.com/deepmind/pg19
4.4 BookCorpus2
模型:GPT-NEOX(0.75%)
BookCorpus2是原版BookCorpus (Zhu et al, 2015)的扩展版本,由“尚未出版的作者”撰写的书籍组成。
下载地址:https://github.com/shawwn/scrap/blob/master/epub2txt-all
4.5 ArXiv
模型:LLaMA(2.5%)、GPT-NEOX(8.96%)
提供一些科学的话题,删掉联系方式、text、宏等冗余信息,用来提高论文的一致性。该数据集包括大约 94K 篇论文(可以使用 LaTeX 源代码),这些论文采用结构化形式,其中论文分为标题、摘要、部分、段落和参考文献。
下载地址:https://www.kaggle.com/datasets/Cornell-University/arxiv、https://huggingface.co/datasets/arxiv_dataset、https://gist.github.com/leogao2/e09b64eae3b987925ccf3b86401624c6
4.6 Stack Exchange
模型:LLaMA(2%)、GPT-NEOX(10.01%)
该数据集包含来自Stack Overflow数据转储的问题和答案,用于偏好模型训练。保留了28个最大网站的数据,删除了文本中的HTML标签,并按分数(从高到低)对答案进行了排序。
下载地址:https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences、https://github.com/EleutherAI/stackexchange-dataset
4.7 OpenSubtitles
模型:GPT-NEOX(1.55%)
open副标题数据集是由Tiedemann(2016)收集的电影和电视节目的英文字幕数据集。
下载地址:https://github.com/sdtblck/Opensubtitles_dataset
4.8 PubMed Central
模型:GPT-NEOX(8.96%)
PubMed Central (PMC)是由美利坚合众国国家生物技术信息中心(NCBI)运营的PubMed生物医学在线资源库的一个子集,提供对近500万份出版物的开放全文访问。
下载地址:https://github.com/EleutherAI/pile-pubmedcentral
4.9 PubMed Abstracts
模型:GPT-NEOX(3.07%)
PubMed摘要由来自PubMed的3000万份出版物的摘要组成,PubMed是由国家医学图书馆
运营的生物医学文章在线存储库。
下载地址:https://github.com/thoppe/The-Pile-PubMed
4.10 FreeLaw
模型:GPT-NEOX(6.12%)
自由法律项目是一个在美国注册的非营利组织,为法律领域的学术研究提供访问和分析工具。
下载地址:https://github.com/thoppe/The-Pile-FreeLaw
4.11 USPTO Backgrounds
模型:GPT-NEOX(3.65%)
USPTO Backgrounds是美国专利商标局授权的专利背景部分的数据集,来源于其公布的批量档案。
下载地址:https://github.com/EleutherAI/pile-uspto
5 大模型大数据
下面汇总几个把训练的数据暴露出来的模型,目前对比了业界很多大模型,其实他们的数据非常隐秘,并没有得到一个很好的开源。目前只找到LLaMA、NEOX、BLOOM。
5.1 LLAMA
业界基于llama衍生了各种驼,羊驼、华佗、小驼、大驼、骆驼、孖拖,为啥LLaMA这么火,主要是因为LLaMA除了被公开了模型权重,很重要的是他的训练数据集也得到了一个很好的被公开。
模型与数据参数量:30B/65B 1.4T 300B tokens
下载地址:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
预处理:https://github.com/togethercomputer/RedPajama-Data
5.2 BLOOM
模型与数据参数量:1.6TB 350B tokens
ROOTS (Responsible Open-science Open-collaboration Text Sources) 这个数据集是一个由 huggingface datasets, dataset collections, pseudo-crawl dataset,Github Code, OSCAR 这几个数据构成的,它包含 46 个 natural 语言和 13 个编程语言
(总共 59 个语言),整个数据集的大小有 1.6TB。问题在于要申请。
5.3 NEOX
模型与数据参数量:20B 800G 184B tokens
一个825GiB的英语文本语料库被提出,该数据集由22个不同的高质量子集构建而成,既有现有的,也有新建的,其中许多来自学术或专业资源。其实就是用了Pile数据集。
下载地址:https://pile.eleuther.ai/
6 中文数据集
上面提到的大模型主要是业界比较著名的大模型论文里面提到如何训练的(GPT3、LLaMA、BLOOM)等,实际上呢。对于中文其实目前唯一一个比较好的大模型主要是智谱GLM-130B大模型,至于盘古之前试过中文效果一般,考究其主要还是对英文预料为主。
因此中文的数据集变得非常重要啦,因为国内并没有公布太多关于训练中文大模型的中文数据集相关的材料,下面我们也一起来梳理下中文的数据集。
6.1 中文文本分类数据集THUCNews
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,划分出 14 个候选分类。
6.2 清华大学NLP实验室开放数据集
这是一个由清华大学自然语言处理与社会人文计算实验室维护的中文自然语言处理共享平台,提供了大量的中文文本数据集,包括新闻、论坛、微博、问答等。
6.3 wiki百科中文
中文维基百科是维基百科协作计划的中文版本,自2002年10月24日正式成立,由非营利组织──维基媒体基金会
负责维持,截至2010年6月30日14:47,中文维基百科已拥有314,167条条目。
6.4 WuDaoCorpora
WuDaoCorpora是北京智源研究院最新构建的高质量数据集,由全球最大的纯文本数据集、全球最大的多模态图文数据集和全球最大的中文对话数据集三部分构成。
https://openi.pcl.ac.cn/BAAI/WuDao-Data/
6.5 Chinese book
包含13.3万余册中文图书的数据集。包含书名、作者、出版社、关键词、摘要、图书分类号、出版年月等7个字段。提供百度网盘下载。可用于机器学习、数据挖掘、自然语言处理等领域。
https://github.com/JiangYanting/Chinese_book_dataset
6.6 千言
百度联合中国计算机学会自然语言处理专委会、中国中文信息学会评测工作委员会共同发起的,由来自国内多家高校和企业的数据资源研发者共同建设的中文开源数据集。如果是追求规模,可以关注下。
6.7 天池
天池数据集是阿里集团对外开放的科研数据平台,由阿里巴巴集团业务团队和外部研究机构联合提供,覆盖了电商、娱乐、物流、医疗健康、交通、工业、自然科学、能源等十多个行业。。如果是追求规模,同样可以关注下。
https://tianchi.aliyun.com/dataset/
6.8 中华古诗词数据库
最全中华古诗词数据集,唐宋两朝近一万四千古诗人, 接近5.5万首唐诗加26万宋诗. 两宋时期1564位词人,21050首词。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!