Pandas数据结构
2023-12-14 14:30:46
Series
DataFrame和Series是Pandas最基本的两种数据结构
可以把DataFrame看作由Series对象组成的字典,其中key是列名,值是Series ? ? ? ?Series和Python中的列表非常相似,但是它的每个元素的数据类型必须相同
创建 Series 的最简单方法是传入一个Python列表
import pandas as pd
s = pd.Series([ ' banana ' ,42]
print(s)输出结果
0 banana
1 42
dtype: object创建Series时,可以通过index参数 来指定行索引
s = pd.Series(['Bill Gates','男'],index=['姓名','性别'])
姓名 Bill Gates
性别 男Series代表一列数据, 需要注意 Pandas里面没有一种数据结构对应行的概念
创建DataFrame
name_list = pd.DataFrame({'姓名':['Tome','Bob'],'职业':['AI工程师','AI架构师'],'年龄':[28,36]})
# 生成三列数据,列索引分别为姓名,职业和年龄pd.DataFrame() 默认第一个参数放的就是数据
- data 数据
- columns 列名
- index 行索引名 行名
pd.DataFrame(data={'职业':['AI工程师','AI架构师'],'年龄':[28,36]},columns=['职业','年龄'],index=['Tome','Bob'])
# 原始行索引为0,1,现在行索引为Tome,Bob?Series DataFrame 在这里调用的时候, 都是大写的 (Pandas 的API 有些是大写字母开头的)
Series常用属性
1.加载CSV文件
data = pd.read_csv('data/nobel_prizes.csv',index_col='id')2.使用 DataFrame的loc 属性获取数据集里的一行,就会得到一个Series对象
first_row = data.loc[941]
first_row3.可以通过 index 和 values属性获取行索引和值
first_row.values # 获取Series中所有的值, 返回的是np.ndarray对象first_row.index # 返回Series的行索引Series的一些属性
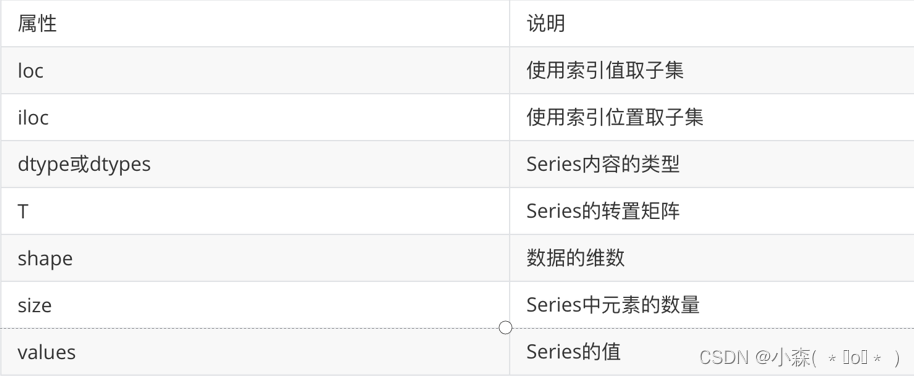
Series常用方法
针对数值型的Series,可以进行常见计算
share = data.share
share.mean() # 计算平均值
share.max()
share.std() # 计算标准差
share.value_counts() # 统计每个取值在数据集中出现了多少次
share.count() # 返回有多少非空值
share.describe() # 一次性计算出 每一列 的关键统计量 平均值, 标准差, 极值, 分位数
movie.head(10) # 默认取前5条数据

文章来源:https://blog.csdn.net/qq_64685283/article/details/134656920
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!