2023年12月9日~12月15日周报(调试OpenFWI代码、利用TensorBoard进行可视化、完成论文附录阅读)
目录
一、前言
? ? ? ? 上周完成了OpenFWI代码中相关细节的理解,包括warm-up策略、Tensorboard的使用、Loss的理解等,同时也完成了OpenFWI论文的正文部分阅读计划。
? ? ? ? 在本周,对Tensorboard的使用进行了尝试,完成了一些训练,并阅读了OpenFWI论文剩余的附录部分。
二、学习情况
2.1 日志记录—Tensorboard
? ? ? ? Tensorboard是常用的日志记录工具,部分研究人员可能习惯使用TensorboardX,TensorboardX是一个第三方库,在Tensorboard的基础上额外拓展了一些其他的功能。但是对于常用的三个功能来说,Tensorboard与TensorboardX的使用是一致的。
? ? ? ? 常用功能:
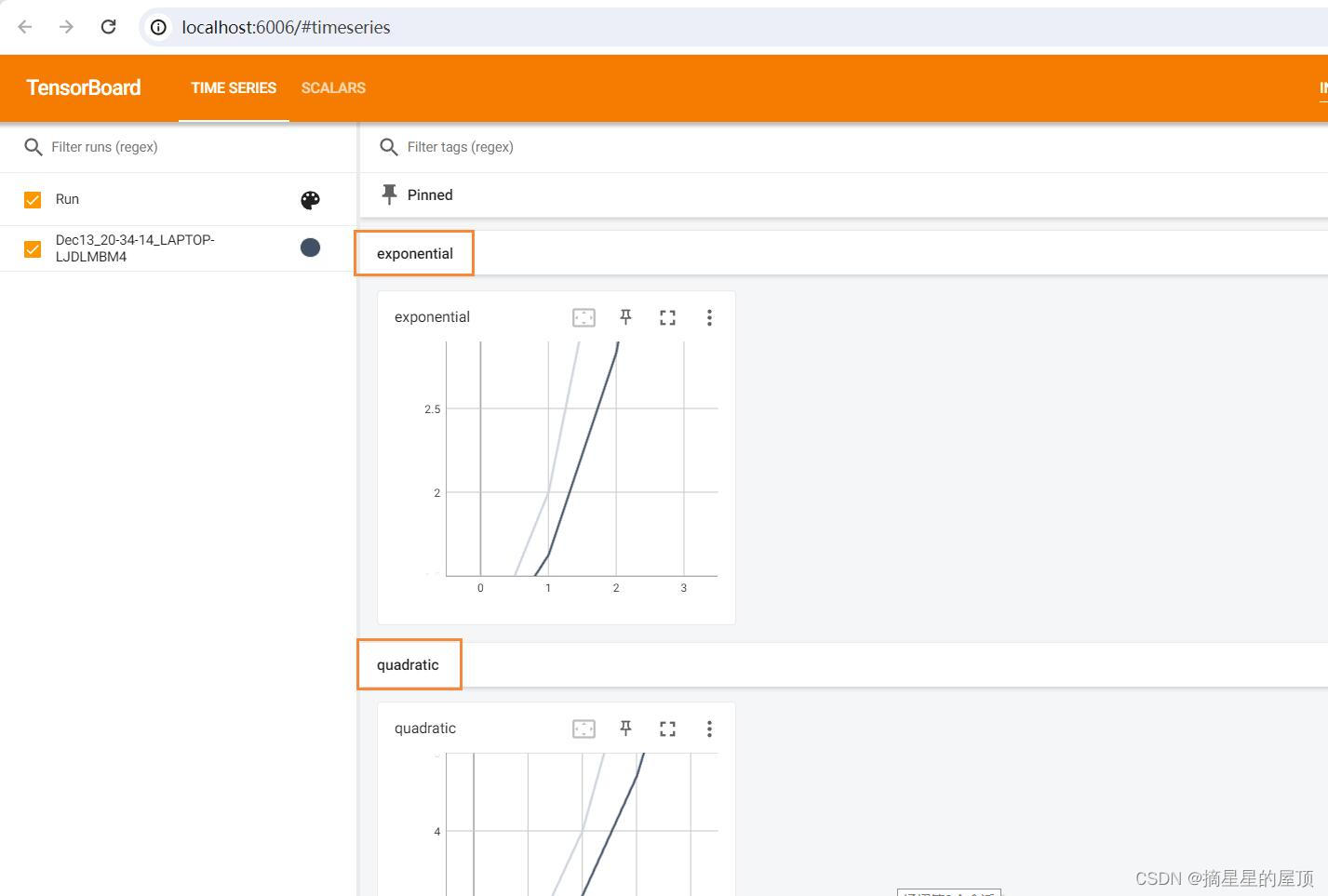
- 记录训练的数据指标,例如在进行分类任务时,记录每个epoch的loss、准确率等,达到实施监控训练过程的目的;
- 查看网络模型结构,进行可视化;
- 记录图像,在做生成式模型的时候,查看不同时刻T图像的效果,帮助进行模型的调试;
2.1.1 实例化SummaryWriter类
- 实例化SummaryWriter类
from torch.utils.tensorboard import SummaryWriter
# 1 不指定任何参数,在当前项目文件夹下创建,默认日志路径为:"runs/CURRENT_DATETIME_HOSTNAME"
# CURRENT:当前日期 DATETIME:当前时间 HOSTNAME
# 类似于"Nov22-17-54-55_EneodeMBP"
writer = SummaryWriter()
# 2 通过参数 log_dir 指定日志路径
writer = SummaryWriter(log_dir="./runs/version")
# 3 通过参数comment指定默认日志路径名称后缀,类似于"runs/Dec13_20-34-14_LAPTOP-LJDLMBM4"
# 与参数log_dir同时使用,不起作用
writer = SummaryWriter(comment="_log")
 ?
?
查看方式:
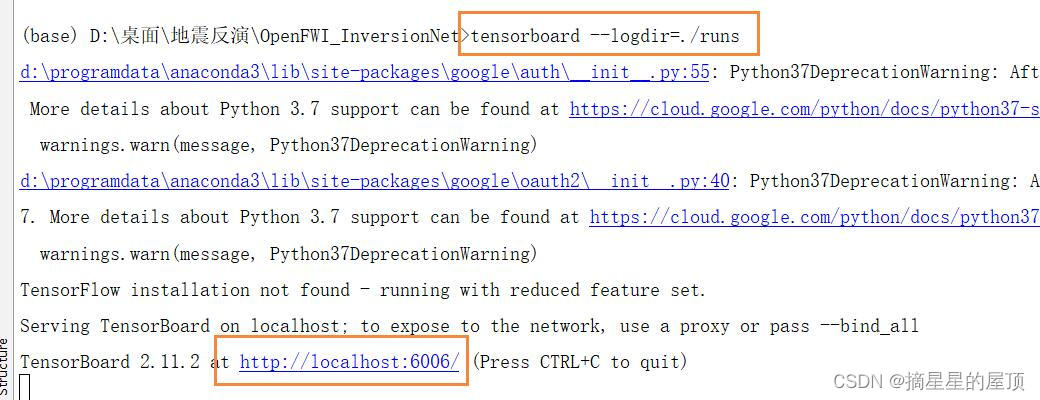
- ?step1:cd到生成的runs同级目录下
- ?step2:在终端输入tensorboard --logdir=./runs --post 6006(端口号可以省略或修改)
- ?step3:点击链接或在浏览器中输入网址: http://localhost:6006/
 ?
?
 ?
?
- OpenFWI代码情况:
from torch.utils.tensorboard import SummaryWriter
train_writer, val_writer = None, None
if args.tensorboard:
utils.mkdir(args.log_path) # create folder to store tensorboard logs
if not args.distributed or (args.rank == 0) and (args.local_rank == 0):
# SummaryWriter:在给定目录中创建事件文件,并向其中添加摘要和事件。
# 该类异步更新文件内容,允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度。
train_writer = SummaryWriter(os.path.join(args.output_path, 'logs', 'train')) # 指定日志路径
val_writer = SummaryWriter(os.path.join(args.output_path, 'logs', 'val')) ?
?
?2.1.2 使用各种add方法记录数据
? ? ? ? (1)使用add_scalar记录数字常量(可视化损失值)
writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)?参数:
- tag:(string)数据图表名称;
- scalar_step:(float)需要记录的数据,通常在图表中作为y轴的数据;
- global_step:(int, optional)训练的step,通常在图表中作为x轴的数据;
- walltime:(float, optional)记录生成的时间,默认为time.time();
? ? ? ? 我们一般会使用add_scalar方法来记录训过程中的loss、accuracy等数值的变化,直观地监控训练过程。?
writer.add_scalar('loss', loss_val, step)
writer.add_scalar('loss_g1v', loss_g1v_val, step)
writer.add_scalar('loss_g2v', loss_g2v_val, step)?
? ? ? ? (2)使用add_graph记录模型结构(计算图)?
writer.add_graph(model, input_to_model=None, verbose=False)参数:
- model:待可视化的网络模型;
- input_to_model:待输入神经网络的变量或一组变量
- verbose:?是否在控制台中打印图形结构
# 输入到模型中的数据
input = torch.zeros((10, 5, 1000, 70))
# 模型对象
model = InversionNet(inchannel= 5, w = 70)
with SummaryWriter(comment='_model') as w:
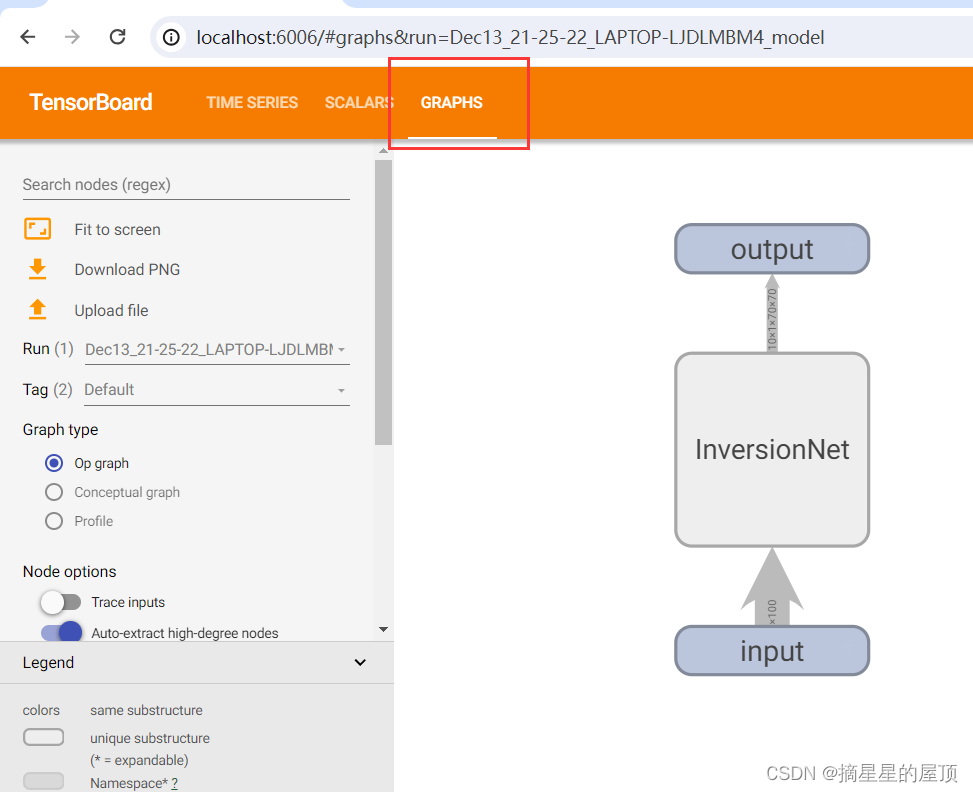
w.add_graph(model, input)?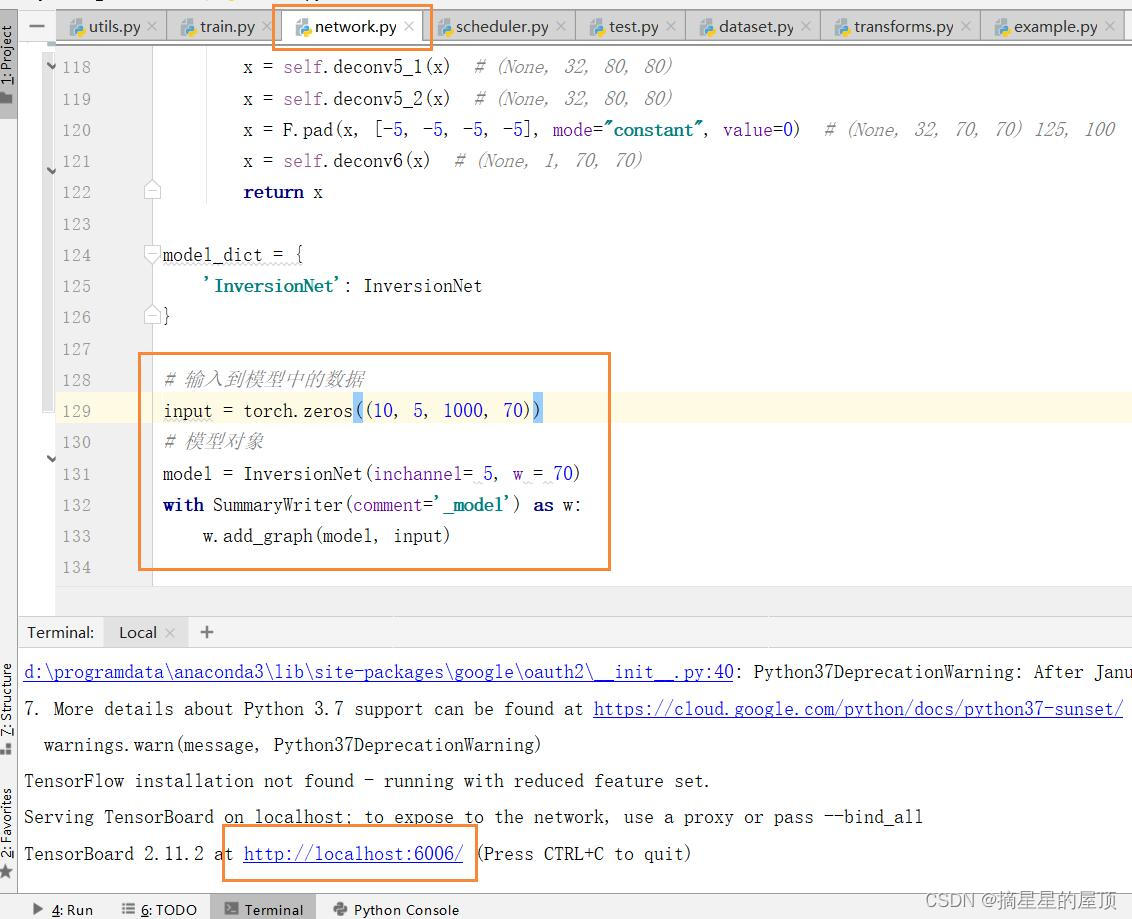
? ? ? ? 由此可以查看每一层网络的细节,包括维度的变化等,双击网络可查看具体情况。?
?
 ?
?
? ? ? ? (3)使用add_image记录图像
writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')参数:
- tag(string):图像窗口名称;
- img_tensor(torch.Tensor / numpy.array):图像数据;
- global_step(int, optional):训练的step;
- walltime(float, optional):记录发生的事件,默认为time.time();
- dataformats(string, optional):图像数据的格式,默认为“CHW”,还可以是“HWC”或“HW”等;
? ? ? ? 一般会使用add_image()来实时观察生成式模型的生成效果,或者可视化分割、目标检测的结果,帮助调试模型。?
注意:add_imgae()方法一次只能插入一张图片,如果要一次性插入多张图片,有两种方法:
- 使用torchvision中的make_grid方法将多张图片合成一张图片后,在调用add_image()方法;
- 使用SummaryWriter的add_images()方法【官方文档】,参数和add_image()类似。
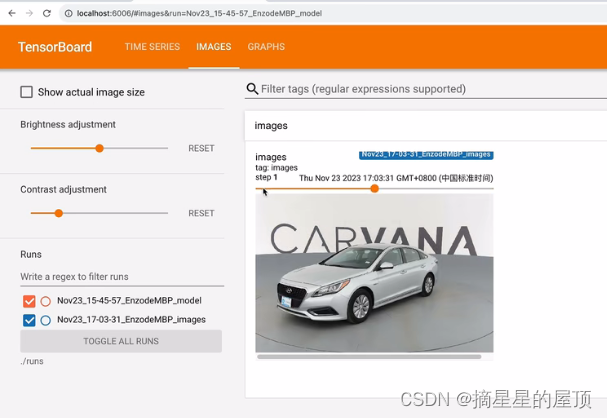 ?
?
? ? ? ? 学习参考:训练日志 | tensorboard / tensorboardX | (1)记录训练数据指标_哔哩哔哩_bilibili
2.2 OpenFWI论文学习情况
? ? ? ? 本周学习了OpenFWI论文剩余的附录部分,见:论文学习记录之OpenFWI(Large-scale Multi-structuralBenchmark Datasets for Full Waveform Inversion)-CSDN博客。
2.3 训练情况
2.3.1 个人训练情况
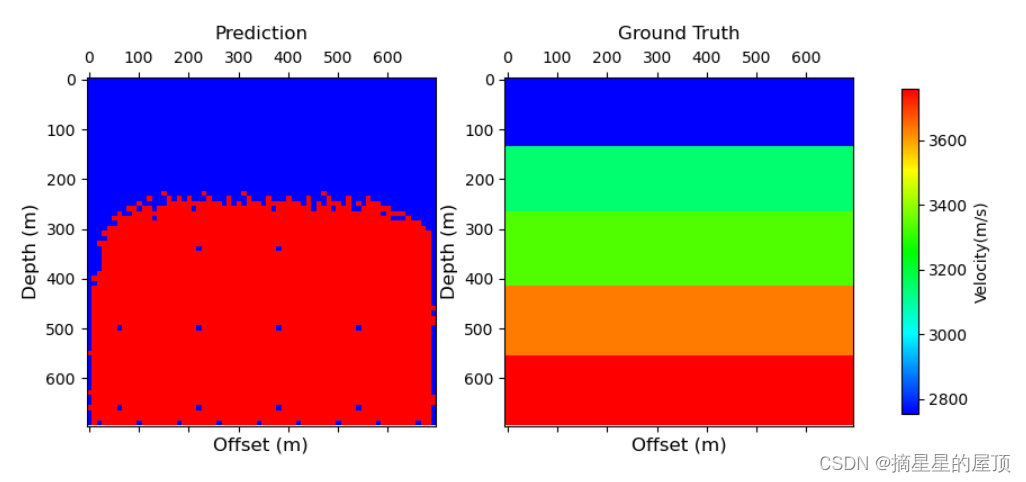
? ? ? ??? ? ? ? 下图为使用FlatFault-A预训练模型的训练结果展示(本机训练):
 ?
?
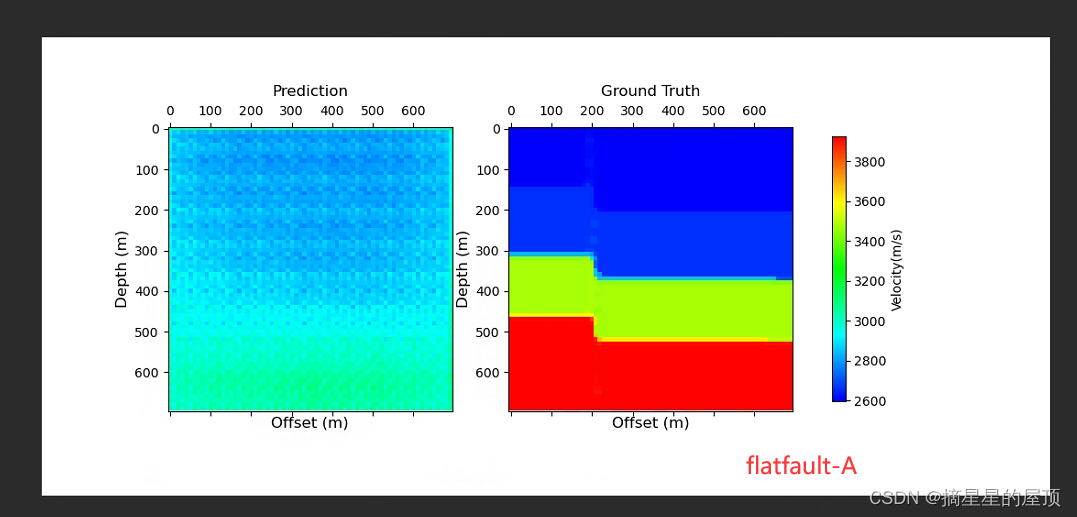
? ? ? ? ?下图为使用FlatFault-A预训练模型的训练结果展示(工作站训练):
 ?
?
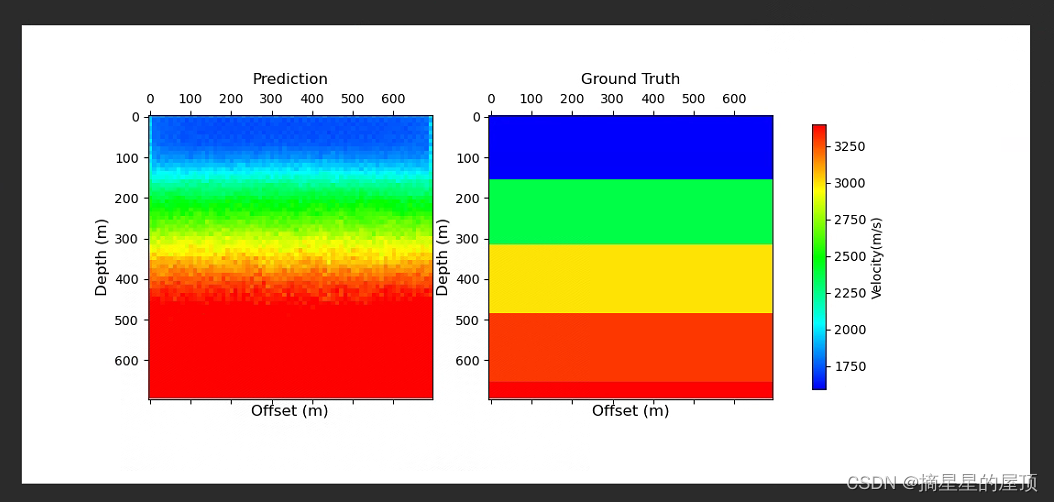
? ? ? ? ?下图为使用FlatVel-A预训练模型的训练结果展示(工作站训练):

 ?
?
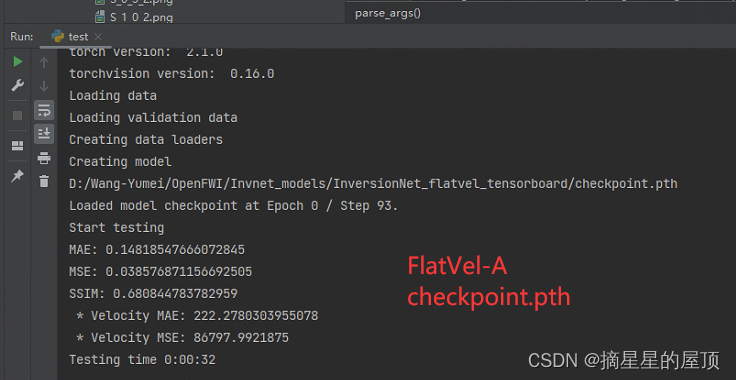
2.3.2 OpenFWI提供的预训练模型的训练情况
? ? ? ? Google Drive发布了预训练模型:https://tinyurl.com/bddzkxfz
? ? ? ? 下图为使用ffb_l1.pth预训练模型的训练结果展示:

 ?
?
 ??
??
 ?
?
? ? ? ? 设置missing(number of missing traces)与std(stardard deviation of gaussian noise) 后的训练情况:
? ? ? ? 高斯噪声是深度学习中用于为输入数据或权重添加随机性的一种技术。 它是一种通过将均值为零且标准差 (σ) 正态分布的随机值添加到输入数据中而生成的随机噪声。 向数据中添加噪声的目的是使模型对输入中的小变化更健壮,并且能够更好地处理看不见的数据。 高斯噪声可用于广泛的应用,例如图像分类、对象检测、语音识别、生成模型和稳健优化。


三、遇到的部分问题及解决
? ? ? ? 问题描述:加载数据集时出现错误_pickle.UmpicklingError:pickle data was truncated(数据被损坏了)
? ? ? ? 可能报错的原因及解决方案:
- ①运行文件时中断,导致文件加载被截断,电脑的不知名地方出现了权重文件,再次运行也报同样的错误——需要删除相应的权重文件(权重文件的位置:C:\Users\用户名\.keras\datasets);(失败)
- ②尝试将num_workers、或者batch_size改小;(将num_workers改为4之后成功)
- ③可能是txt文件夹中文件命名出错;

四、总结
4.1 存在的疑惑
- 有哪些可以提升预测准确率的方式,比如更改网络模型结果?(除了扩大训练轮次、数据集个数等)
- 毕业论文选题等
4.2 下周安排
? ? ? ? 找一篇全波形反演方向的论文研读。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!