数据结构:跳表的原理和运用
2023-12-20 18:21:56
本篇总结的是跳表的相关内容
什么是跳表
skiplist本质上也是一种查找结构,用于解决算法中的查找问题,跟平衡搜索树和哈希表的价值是一样的,可以作为key或者key/value的查找模型
- 假如我们每相邻两个节点升高一层,增加一个指针,让指针指向下下个节点,如下图所示。这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半。由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了,需要比较的节点数大概只有原来的一半
- 以此类推,我们可以在第二层新产生的链表上,继续为每相邻的两个节点升高一层,增加一个指针,从而产生第三层链表。如下图,这样搜索效率就进一步提高了
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似二分查找,使得查找的时间复杂度可以降低到O(log n)。但是这个结构在插入删除数据的时候有很大的问题,插入或者删除一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)

skiplist的设计为了避免这种问题,做了一个大胆的处理,不再严格要求对应比例关系,而是插入一个节点的时候随机出一个层数。这样每次插入和删除都不需要考虑其他节点的层数,这样就好处理多了。细节过程入下图:
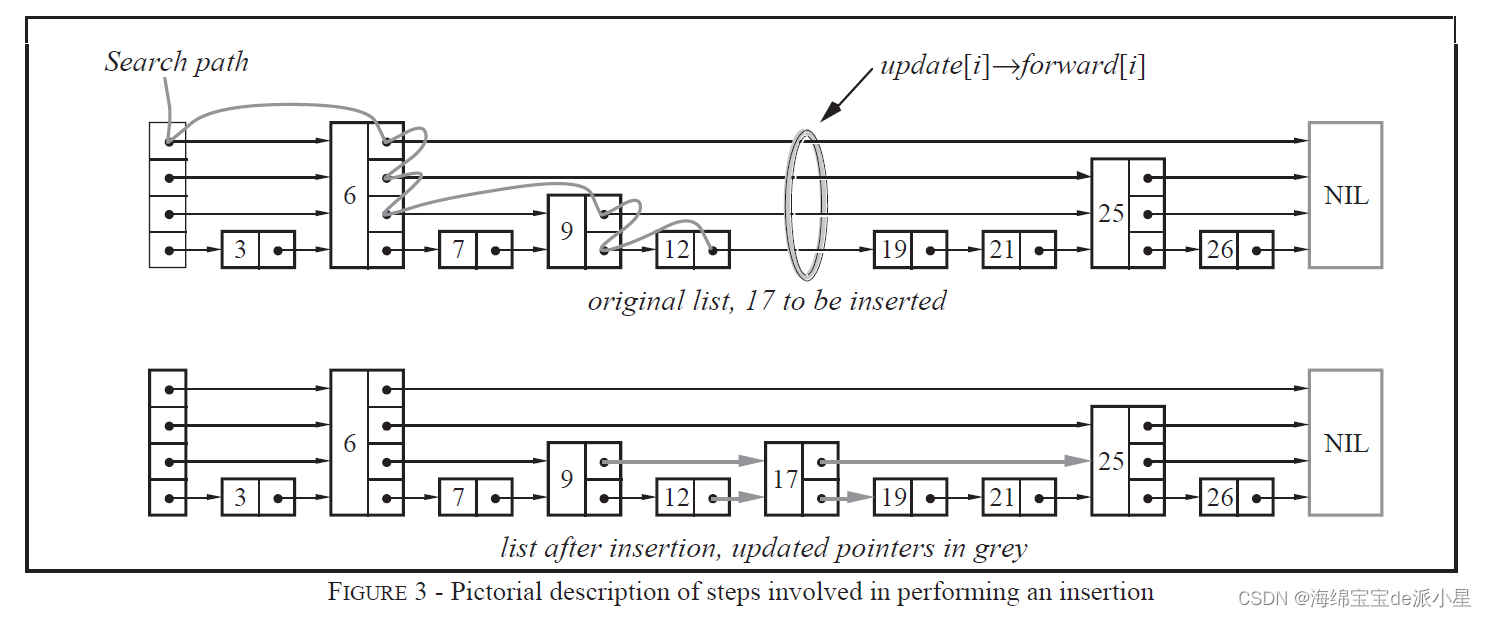
那问题是,跳表的效率是如何保证的呢?看下面的解释
跳表的效率原理
上面我们说到,skiplist插入一个节点时随机出一个层数,听起来怎么这么随意,如何保证搜索时的效率呢?
这里首先要细节分析的是这个随机层数是怎么来的。一般跳表会设计一个最大层数maxLevel的限制,其次会设置一个多增加一层的概率p。那么计算这个随机层数的伪代码如下图

节点层数至少为1。而大于1的节点层数,满足一个概率分布:
节点层数恰好等于1的概率为1-p
节点层数大于等于2的概率为p,而节点层数恰好等于2的概率为p(1-p)
节点层数大于等于3的概率为p2,而节点层数恰好等于3的概率为p2(1-p)
节点层数大于等于4的概率为p3,而节点层数恰好等于4的概率为p3(1-p)
跳表的难点其实就是在于跳表的结构上,在理解了跳表的结构后,下面来进行跳表的模拟实现
跳表的模拟实现
这里借助leetcode上的一道题来实现

// 首先要定义跳表中的节点的信息
struct SkiplistNode
{
// 节点中的内容应当包括数据域和一个指针数组的指针域
int _data;
vector<SkiplistNode*> _nextV;
// 定义关于节点信息的构造函数
SkiplistNode(int data, int level)
:_data(data)
, _nextV(level, nullptr)
{}
};
class Skiplist
{
typedef SkiplistNode Node;
public:
// 构造函数默认给的头节点高度为1
Skiplist()
{
srand(time(0));
_head = new Node(-1, 1);
}
bool search(int target)
{
// 跳表的搜索函数,就是一个不断寻找不断降高度的过程
Node* cur = _head;
int curlevel = _head->_nextV.size();
curlevel--;
while (cur && curlevel >= 0)
{
// 如果下一个跳表值存在,并且小于目标值,就跳到后面去找
if (cur->_nextV[curlevel] && cur->_nextV[curlevel]->_data < target)
cur = cur->_nextV[curlevel];
// 如果下一个跳表值不存在,或者大于目标值,就降低高度寻找
else if (cur->_nextV[curlevel] == nullptr || cur->_nextV[curlevel]->_data > target)
curlevel--;
// 如果相等,那就是找到了
else
return true;
}
return false;
}
void add(int num)
{
// 看看跳表中有没有这个值,如果有就不加它了
// if (search(num))
// return;
// 首先要创建好这个节点
int newnodelevel = RandomLevel();
Node* newnode = new Node(num, newnodelevel);
// 下一步要找到这个节点插入位置前面的节点分别是多少
vector<Node*> PrevV = GetPrevVector(num);
// 如果新插入节点的高度大于头节点高度,就把头节点拉高
if (newnodelevel > _head->_nextV.size())
{
_head->_nextV.resize(newnodelevel, nullptr);
PrevV.resize(newnodelevel, _head);
}
// 现在把新节点链入到跳表中
for (int i = newnodelevel - 1; i >= 0; i--)
{
newnode->_nextV[i] = PrevV[i]->_nextV[i];
PrevV[i]->_nextV[i] = newnode;
}
}
bool erase(int num)
{
// 先去跳表中找一下它,如果没找到就不能删除
if (search(num) == false)
return false;
// 删除它首先要找到它的前驱指针数组
vector<Node*> PrevV = GetPrevVector(num);
// 再把它从跳表中删除
Node* del = PrevV[0]->_nextV[0];
for (int i = 0; i < del->_nextV.size(); i++)
PrevV[i]->_nextV[i] = del->_nextV[i];
delete del;
return true;
}
// 用来找这个节点插入位置前面节点的指针
vector<Node*> GetPrevVector(int num)
{
// 寻找前面的值,就是一个不断寻找不断降高度的过程
Node* cur = _head;
int curlevel = _head->_nextV.size();
vector<Node*> PrevV(curlevel, nullptr);
curlevel--;
while (cur && curlevel >= 0)
{
// 如果下一个跳表值存在,并且小于目标值,就跳到后面去找
if (cur->_nextV[curlevel] && cur->_nextV[curlevel]->_data < num)
{
cur = cur->_nextV[curlevel];
}
// 如果下一个跳表值不存在,或者大于目标值,就先存储节点信息,再降低高度寻找
else if (cur->_nextV[curlevel] == nullptr || cur->_nextV[curlevel]->_data >= num)
{
PrevV[curlevel] = cur;
curlevel--;
}
}
return PrevV;
}
// 用来求创建一个新节点的高度
int RandomLevel()
{
size_t level = 1;
while (rand() <= RAND_MAX * _p && level < _maxLevel)
++level;
return level;
}
private:
// 跳表内部结构是一个指针,还要给最大高度和概率值
Node* _head;
int _maxLevel = 32;
float _p = 0.25;
};
难点在于理清思路,理清思路后配合画图实现代码没有那么困难
跳表和其他搜索结构的对比
- skiplist相比平衡搜索树(
AVL树和红黑树)对比,都可以做到遍历数据有序,时间复杂度也差不多
skiplist的优势是:
1、skiplist实现简单,容易控制。平衡树增删查改遍历都更复杂
2、skiplist的额外空间消耗更低。平衡树节点存储每个值有三叉链,平衡因子/颜色等消耗。skiplist中p=1/2时,每个节点所包含的平均指针数目为2;skiplist中p=1/4时,每个节点所包含的平均指针数目为1.33
skiplist相比哈希表而言,就没有那么大的优势了。相比而言
1、哈希表平均时间复杂度是O(1),比skiplist快。
2、哈希表空间消耗略多一点
skiplist优势如下:
1、遍历数据有序
2、skiplist空间消耗略小一点,哈希表存在链接指针和表空间消耗。
3、哈希表扩容有性能损耗。
4、哈希表再极端场景下哈希冲突高,效率下降厉害,需要红黑树补足接力。
文章来源:https://blog.csdn.net/qq_73899585/article/details/135109498
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!