trino-435: 理论基础
2023-12-31 18:28:46
一、trino介绍
Trino是?种?持使? SQL 访问任意数据源的 开源的分布式SQL 查询引擎,其能够提供更加灵活与?效的查询服务。为不同的异构数据源提供统?的sql访问,并?持联邦查询和并?查询。

应?场景
Trino是定位在数据仓库和数据分析业务的分布式SQL引擎,适合以下应?场景:
? 统?SQL访问各类数据源
? 执?sql转换与ETL
? Ad-Hoc查询
? 海量结构化数据或半结构化数据分析
? 海量多维数据聚合或报表分析
二、trino架构
trino集群由?个coordinator和多个worker节点组成,client可以使?Trino CLI或者JDBC驱动程序连接到Coordinator,coordiantor通过协调worker与数据源进??作。
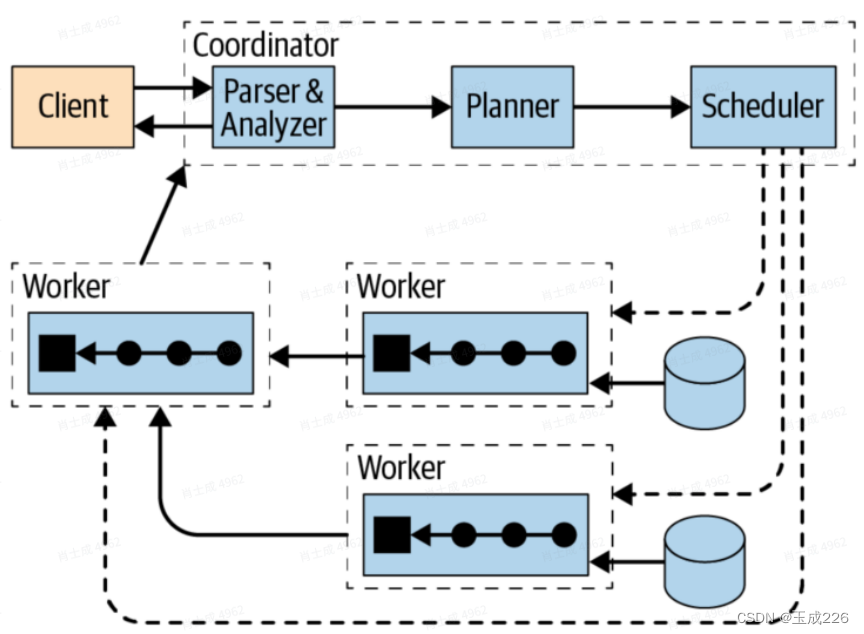
1、Trino coordinator节点的作?
- 查询协调:coordinator节点负责协调所有查询操作,如解析sql语句、?成查询计划、调度和分配查询任务等。它会根据查询的复杂度和数据源的规模来判断查询是否需要被分割和并?执?,以提?查询效率和资源利?率。
- 资源管理:coordinator节点负责管理整个集群的资源,如内存、CPU等。它会根据每个查询的资源需求和集群的可?资源情况来动态调整资源使?情况,以保证集群的稳定性和性能。
- 节点管理:coordinator节点负责管理集群的所有worker节点,包括状态更新、任务分配、?跳检测等。它会监测节点的可?性和状态,并根据集群负载情况来动态调整节点的任务分配和负载平衡策略,以保证整个集群的稳定性和可?性。
- 集群监控:coordinator节点负责监控整个集群的运?状况,包括各个节点的状态、负载情况、查询性能等。它会将这些信息进?汇总和分析,并?成相应的报告和指标,以便管理员进?集群的优化和调整。
- 系统管理:coordinator节点负责管理整个Trino系统,包括配置?件管理、插件管理、安全管理等。它会根据管理员的设定和权限来进?相应的管理和控制,以保证整个系统的稳定性和安全性。
2、Trino worker节点的作?
- 任务执?:worker节点负责执?coordinator分配给它的任务,如数据读取、数据过滤、数据聚合等。它会将数据处理的结果返回给coordinator节点,以便进?下?步的处理和计算。
- 数据存储:worker节点负责存储集群中的数据,包括数据的分?、存储和管理等。它会维护?个数据存储仓库,并根据查询计划和任务分配来读取和处理数据,以提?查询效率和资源利?率。
- 资源管理:worker节点会根据集群的资源限制和任务优先级,动态调整资源的分配和使?情况,以保证集群的稳定性和性能。
- ?络通信:worker节点负责与coordinator节点进?通信,并根据分配的任务来读取和处理数据。它需要保证和coordinator节点的通信畅通,并及时反馈处理结果。
三、trino基本概念
1、数据模型
数据模型即数据的组织形式。Trino使?Catalog、Schema和Table三层结构来管理数据。
- Catalog
?个Catalog可以包含多个Schema,物理上指向?个外部数据源,可以通过Connector访问该数据源。?次查询可以访问?个或多个Catalog。系统catalog:包括system、memory、information_schema和metadata,?于管理和查询Trino系统和运?时信息。 - Schema
相当于?个数据库实例,?个Schema包含多张数据表。 - Table
数据表,与?般意义上的数据库表相同
2、Connector
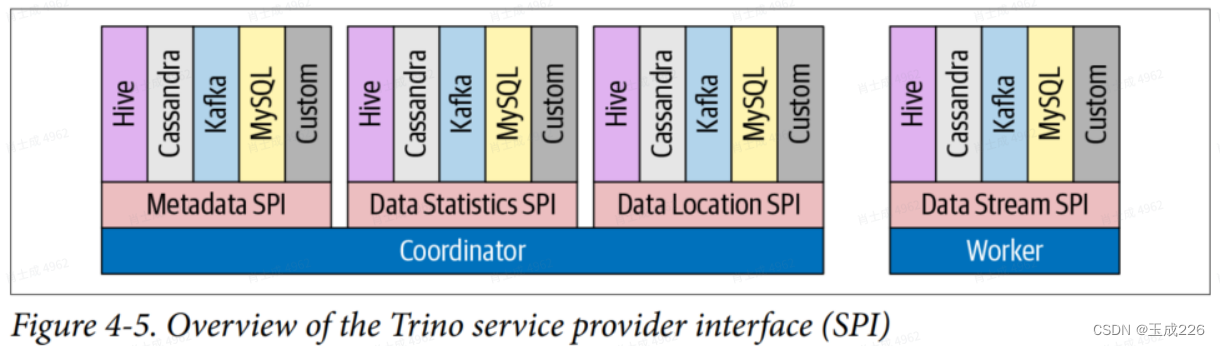
Trino通过各种Connector来接?多种外部数据源。Trino提供了?套标准的SPI接?,用户可以使?这套接口开发自己的Connector,以便访问?定义的数据源。?个Catalog通常会绑定?种类型的Connector,在Catalog的Properties?件中设置。Trino内置了多种Connector。下图展示了Trino SPI如何包含用于协调器使?的元数据、数据统计和数据位置以及?作器使?的数据流的单独接?。
3、查询执?模型
(1)总体流程
coordinator接受来?最终用户、CLI软件(使?ODBC或JDBC驱动程序或其他客?机库)的SQL语句。然后,coordinator触发worker从数据源获取所有数据,创建结果数据集,并使其对客户机可?。
(2)流程分析
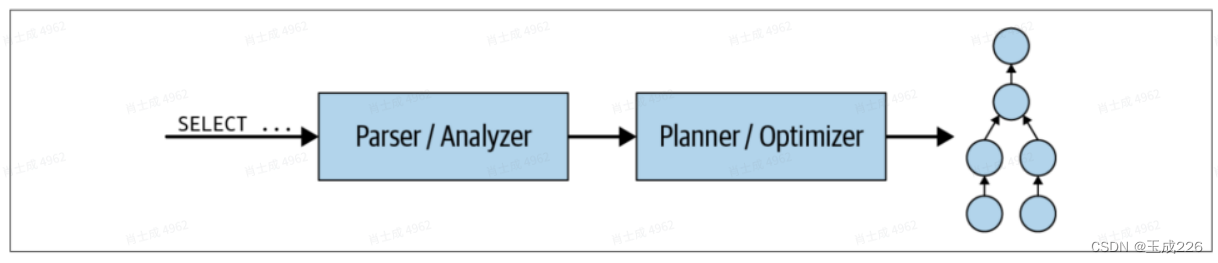
- 当将SQL语句提交给协调器时,将以?本格式接收它。协调器获取?本并对其进?解析和分析。然后,它通过使?Trino中称为查询计划的内部数据结构创建?个执?计划。该流程如图4-6所?。查询计划?致表?每个SQL语句处理数据和返回结果所需的步骤。
- 如图4-7所?,使?元数据SPI和数据统计SPI[1]来创建查询计划。因此,coordinator使?SPI来收集有关直接连接到数据源的表和其他元数据的信息。
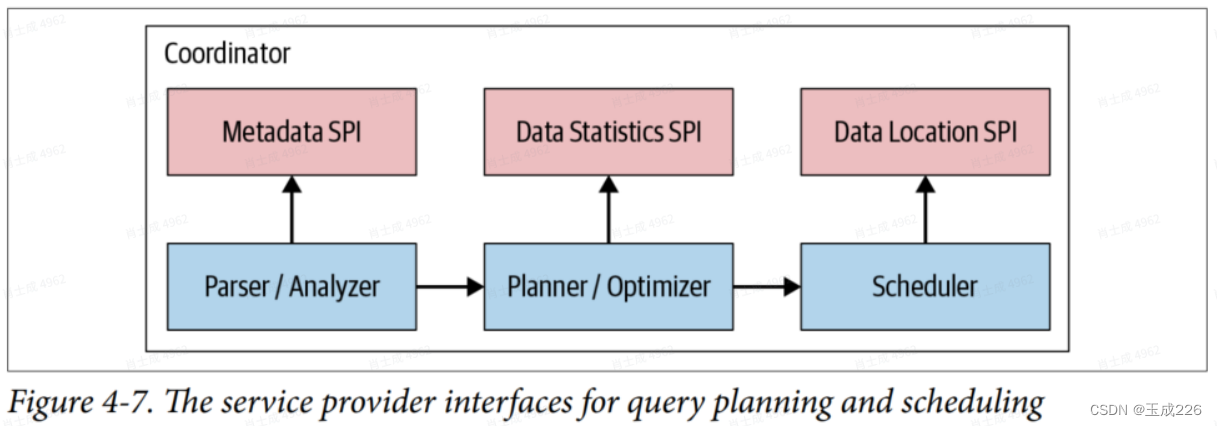
coordinator使?Metadata SPI获取关于表、列和类型的信息。它们?于验证查询在语义上是否有效,并对原始查询中的表达式执?类型检查和安全检查。Data Statistics SPI?于获取有关?数和表??的信息,以便在规划期间执?基于成本的查询优化。Data Location SPI?于?成表内容的逻辑分割。拆分是?作分配和并?的最?单位。 - 逻辑查询计划在集群coordinator上转化为分布式查询计划的过程如图4-8所示:
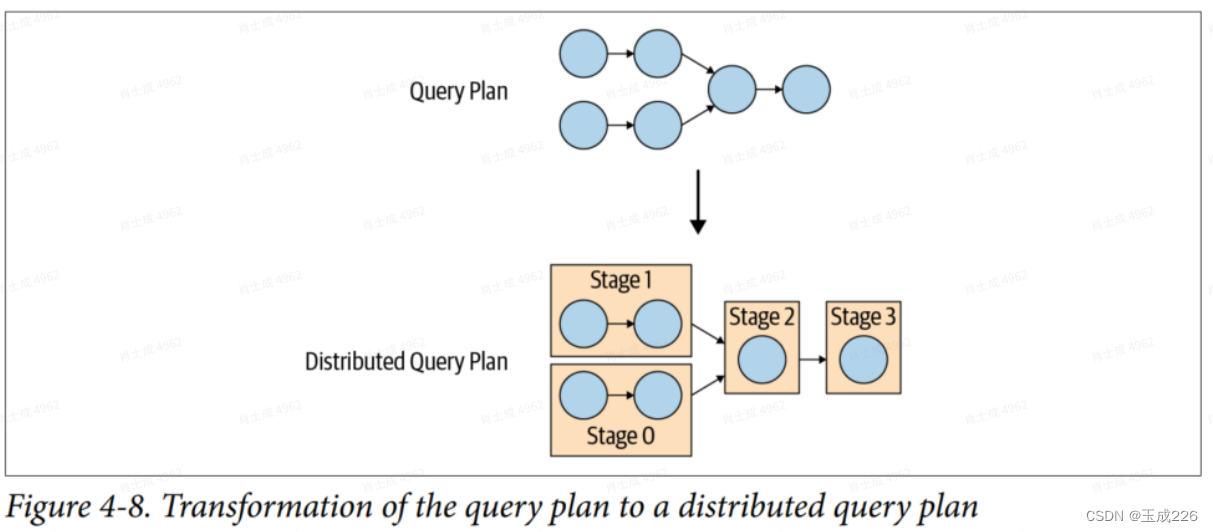
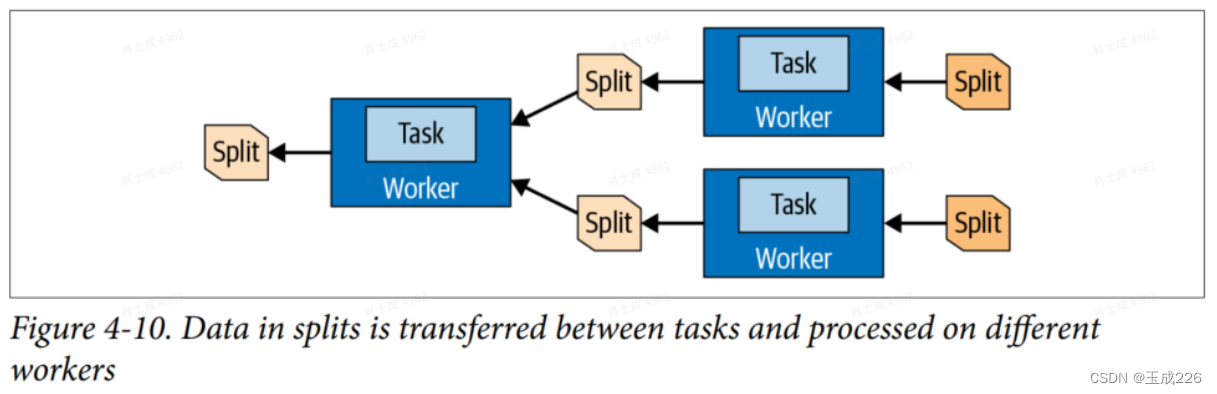
- 分布式查询计划定义了在Trino集群上执?查询的阶段和?式。协调器使?它来进?步计划和安排跨worker的任务。?个stage由?个或多个Task组成。通常,涉及许多Task,每个Task处理?部分数据。coordinator从stage向集群中的worker分配Task,如图4-9所?。

任务处理的数据单位称为split。split相当于?部分数据集,每个task会去处理对应的split。
在Task中,每个Split将作?于?个Driver上,?个Driver有许多Operator组成,Split上的所有Page会依次经过各个operator进?转换和计算,最终完成SQL所需要的结果输出。
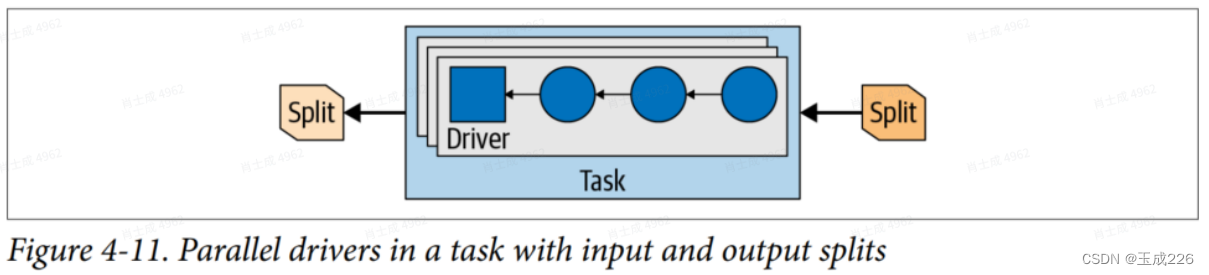
operator处理输?数据,为下游operator产?输出数据。?例operator包括表扫描、过滤器、连接和聚合。?系列这样的操作符构成?个operator管道。例如,您可能有?个管道,它?先扫描和读取数据,然后对数据进?过滤,最后对数据进?部分聚合。
文章来源:https://blog.csdn.net/yuming226/article/details/135315347
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!