梯度下降法
前言:在均方差损失函数推导中,我使用到了梯度下降法来优化模型,即迭代优化线性模型中的
和
。现在进一步了解梯度下降法的含义以及具体用法。
一、梯度下降法(入门级理解)
定义:梯度下降是一种用于最小化损失函数的优化算法。在机器学习和深度学习中,梯度下降被广泛应用于更新模型参数,以使模型能够更好地拟合训练数据。
基本思想:通过不断迭代,沿着损失函数的负梯度方向更新模型参数,直到达到损失函数的最小值。具体来说,对于每个迭代步骤,算法会计算损失函数对每个参数的偏导数(梯度),然后沿着负梯度的方向更新参数。
理解:
????????对于我们所建立的损失函数,我们需要不断改变其中的w、b来使得
取得最小值。通常而言,我们会首先设w、b均为0,通过不断改变w、b的取值求得对应
的值,并找到其中的最小值。
? ? ? ? 吴恩达老师给出的例子中绘制了对应的函数图像,我们通过高中导数求函数最小值的知识很容易得出
取得最小值的点。梯度下降法就是为了得到
取得最小值时对应的点。

????????然而,真实情况下,我们的数据通常不会只有两个维度。下图展现的才是我们通常需要分析的图:
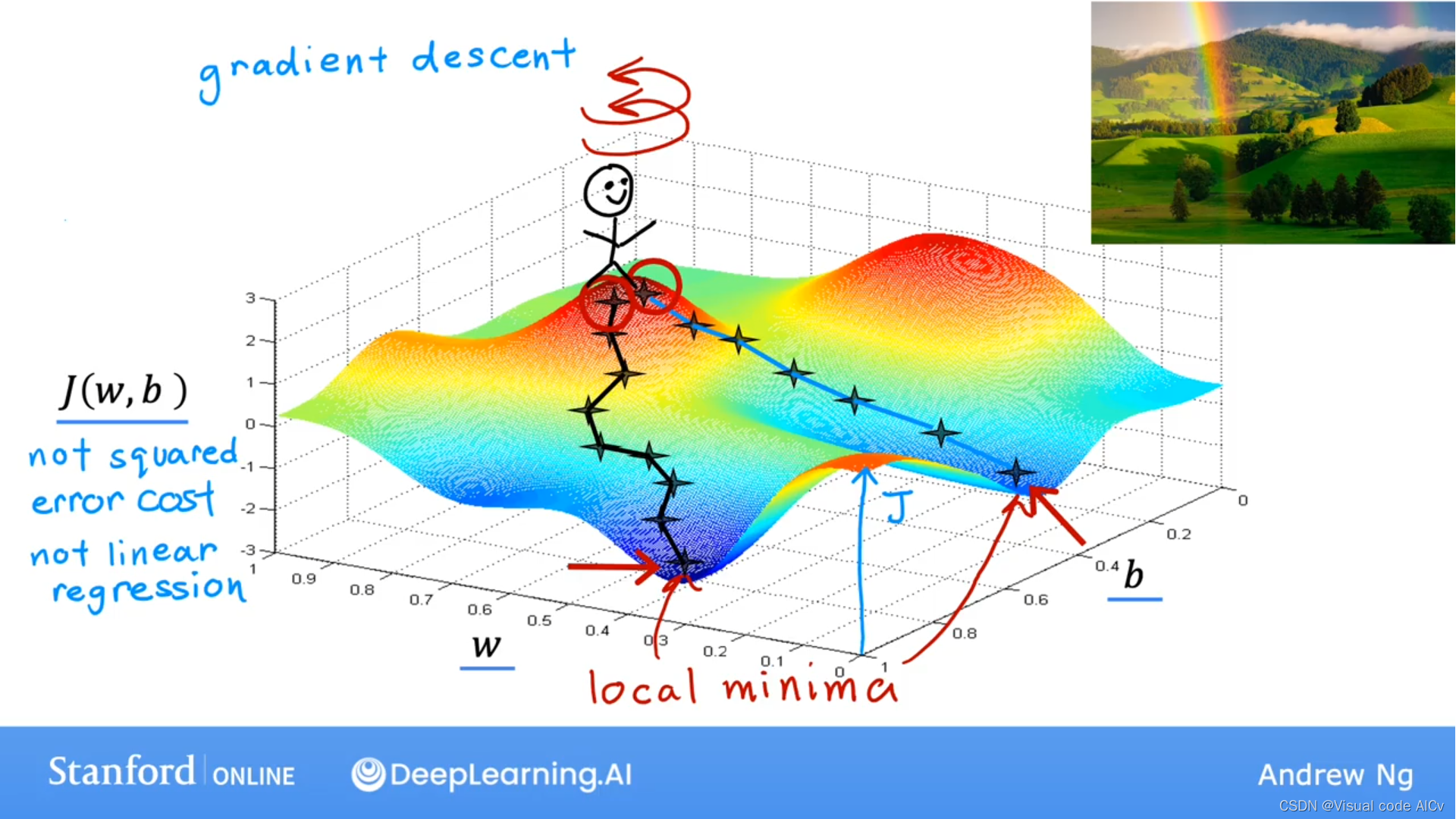 ?
?
????????将上面的图看作山峰,梯度下降法所做的是,你要自旋环顾四周并询问自己,如果我想尽快下山并去往其中一个山谷,我应该选哪个方向迈出一步。很明显应该是梯度最大的方向(
不会被摔死,不要瞎想)。所以可以理解梯度下降法的核心就是每一步都选择下降梯度最大的方向。
? ? ? ? ?需要注意的是选择不同的出发点会到达不同的局部最小值。
二、梯度下降算法
对于模型
- 首先对w,b赋予初值【可以使用随机数、或者其他方式初始化】
- 然后求损失函数J(w,b)并对w、b分别求偏导数(梯度)
????????????????
???????????????????????
???????????????????????
- 更新w,b的值:沿着梯度的反方向更新参数 w 和 b,即向着损失函数减小的方向移动。这个更新过程可以使用不同的学习率α来控制每次更新的步长。
- 重复迭代:重复执行求偏导数和更新w、b值的工作,直到达到预定的迭代次数或者损失函数收敛到一个满意的值。

三、(附)学习率α?
上面提到在求解新的w和b时需要使用到学习率α,以下是学习率α的详细介绍。
定义:学习率是梯度下降算法中的一个重要参数,用于控制每次参数更新的步长。在梯度下降算法中,我们沿着损失函数的负梯度方向更新参数,学习率就是用来调节这个更新步长的参数
注意点:如果学习率设置得太小,那么参数更新的步长就会很小,收敛速度会很慢,需要更多的迭代次数才能收敛到最优值;而如果学习率设置得太大,可能会导致参数更新过大,甚至导致算法发散。(学习率α一般通过实验和经验进行选择)
常见自适应学习率优化算法:
-
AdaGrad(Adaptive Gradient Algorithm):AdaGrad 是一种自适应学习率算法,它根据参数的梯度历史信息来调整学习率。具体来说,它对每个参数的学习率进行缩放,使得在训练过程中梯度较大的参数的学习率变小,而梯度较小的参数的学习率变大。
-
RMSprop(Root Mean Square Propagation):RMSprop 也是一种自适应学习率算法,它通过引入一个衰减系数,来对梯度的平方进行加权平均。这样可以使得梯度较大的参数的学习率减小,而梯度较小的参数的学习率增大。
-
Adam(Adaptive Moment Estimation):Adam 是一种结合了动量(momentum)和自适应学习率的优化算法。它利用梯度的一阶矩估计和二阶矩估计来调整参数的学习率,同时具有一定的动量效果,可以加速收敛过程。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!