从零开发短视频电商 Tesseract OCR 的 Java 拓展库 javacpp-presets
文章目录
简介
项目地址:https://github.com/bytedeco/javacpp-presets
JavaCPP:
JavaCPP 是一个用于在 Java 中使用本地库的工具,它允许通过 Java 代码访问本地(C/C++)库,而无需编写过多的本地代码。这种方法可以使 Java 与其他语言编写的库进行集成,提供了对性能关键的原生功能的访问。JavaCPP 使用 Java 注解和本地代码生成,使得在 Java 中调用本地代码变得相对容易。
javacpp-presets:
javacpp-presets 是 JavaCPP 的一个相关项目,它提供了预定义的配置(presets)和原生库绑定,以便在 Java 中使用。这些预定义的配置通常与特定的本地库相关联,允许 Java 开发人员轻松地在其项目中使用这些库。
具体而言,https://github.com/bytedeco/javacpp-presets 存储了由 JavaCPP 团队提供的预定义配置,以支持许多常见的本地库。这些预定义配置文件中包含了与本地库相关的 Java 接口和本地代码,使得 Java 开发者可以方便地在其 Java 项目中集成这些本地库。
一些例子可能包括 OpenCV、FFmpeg、tesseract、TensorFlow 等库的预定义配置,让您能够在 Java 中直接使用它们的功能,而无需深入了解本地代码的细节。
总的来说,javacpp-presets 是一个简化在 Java 中使用本地库的工具,使得开发人员可以更轻松地利用性能强大的本地库功能。
添加依赖
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>tesseract-platform</artifactId>
<version>5.3.1-1.5.9</version>
</dependency>
https://central.sonatype.com/artifact/org.bytedeco/tesseract-platform
将下载适用于所有平台的二进制文件,导致打包后的包特别大。
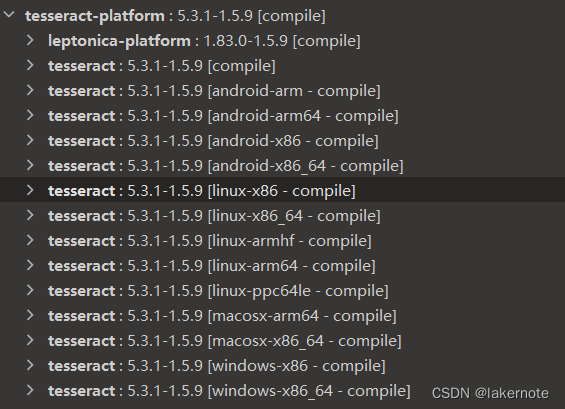
这样会导致我们打出的包特别大,所以要瘦身。
方式一 仅获取某个平台的二进制文件,我们可以将 javacpp.platform系统属性(通过 -D 命令行选项)设置为类似 android-arm、linux-x86_64、macosx-x86_64、windows-x86_64 等。
mvn -Djavacpp.platform=linux-x86_64 ...
我们还可以指定多个平台,要包含 2 个或更多平台的二进制文件,我们可以依赖不同的配置文件集,但始终首先通过设置 javacpp.platform.custom 系统属性来重置 javacpp.platform 的默认值。例如,在主机平台的情况下,加上 Mac 和 Windows,我们可以使用以下命令:
mvn -Djavacpp.platform.custom -Djavacpp.platform.host -Djavacpp.platform.macosx-x86_64 -Djavacpp.platform.windows-x86_64 ...
方式二(推荐 推荐) 如果你只需要 Windows 64 和 Linux 64 的依赖,你可以通过指定这两个平台的依赖来优化你的 Maven 配置。具体来说,你可以使用下面的配置:
<dependencies>
//<dependency> 不要这个大而全的方式
//<groupId>org.bytedeco</groupId>
// <artifactId>tesseract-platform</artifactId>
// <version>5.3.1-1.5.9</version>
//</dependency>
<!-- java代码 -->
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>tesseract</artifactId>
<version>5.3.1-1.5.9</version>
</dependency>
<!-- 动态库文件 这里只需要 linux 和 Windows的动态库,会减少打包后的体积 -->
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>tesseract</artifactId>
<version>5.3.1-1.5.9</version>
<classifier>windows-x86_64</classifier>
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>tesseract</artifactId>
<version>5.3.1-1.5.9</version>
<classifier>linux-x86_64</classifier>
</dependency>
<!-- tesseract 强依赖 leptonica -->
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>leptonica</artifactId>
<version>1.83.0-1.5.9</version>
<classifier>windows-x86_64</classifier>
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>leptonica</artifactId>
<version>1.83.0-1.5.9</version>
<classifier>linux-x86_64</classifier>
</dependency>
</dependencies>
这样的配置只会下载和安装 tesseract 的 Windows 64 和 Linux 64 版本的依赖,而不会下载和安装其他平台的依赖。
支持的平台名称列表:
android-armandroid-arm64android-x86android-x86_64ios-arm64ios-x86_64linux-armhflinux-arm64linux-ppc64lelinux-x86linux-x86_64macosx-arm64macosx-x86_64windows-x86windows-x86_64
识别示例
https://tesseract-ocr.github.io/tessdoc/APIExample
https://github.com/tesseract-ocr/tessdoc/tree/main/examples
首先要下载训练数据:
有三个仓库可以下载,但是它们的精度和速度有所不同:
- tessdata:这个仓库包含了Tesseract 4.0的原始训练数据,这些数据在精度和速度之间达到了一种平衡。如果你在精度和速度之间都有需求,可以使用这个仓库的数据。
- tessdata_best:这个仓库包含了Tesseract 4.0的最高精度训练数据,这些数据的识别精度更高,但是运行速度较慢。如果你的应用场景对识别精度有很高的要求,可以使用这个仓库的数据。
- tessdata_fast:这个仓库包含了Tesseract 4.0的快速训练数据,这些数据的运行速度更快,但是识别精度较低。如果你的应用场景对运行速度有很高的要求,可以使用这个仓库的数据。
在选择训练数据时,你需要根据你的应用场景和需求进行权衡。如果你对识别精度和运行速度都有一定的要求,可以尝试使用不同仓库的数据,看看哪种数据最适合你的需求。
我这里只下载了
tessdata_best中的eng.traineddata。
示例一 识别本地图片
import org.bytedeco.javacpp.*;
import org.bytedeco.leptonica.*;
import org.bytedeco.tesseract.*;
import static org.bytedeco.leptonica.global.leptonica.*;
import static org.bytedeco.tesseract.global.tesseract.*;
public class BasicExample {
public static void main(String[] args) {
BytePointer outText;
// 初始化 Tesseract API
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 tesseract-ocr,不指定 tessdata 路径
if (api.Init(null, "eng") != 0) {
System.err.println("无法初始化 Tesseract。");
System.exit(1);
}
// 使用 Leptonica 库打开输入图像
PIX image = pixRead("/usr/src/tesseract/testing/phototest.tif");
api.SetImage(image);
// 获取 OCR 结果
outText = api.GetUTF8Text();
System.out.println("OCR 输出:\n" + outText.getString());
// 销毁使用的对象并释放内存
api.End();
outText.deallocate();
pixDestroy(image);
}
}
示例二 识别图像中的各个组件(比如文本行,单词,或单个字符)
GetComponentImages这个功能在许多场景下都可能会用到,以下是一些常见的应用场景:
- 文本定位和提取:在图像处理或计算机视觉的应用中,经常需要定位并提取出图像中的文本内容。例如,在车牌识别、名片识别、表格识别等场景中,我们需要找到并读取图像中的文本信息。
- 文档分析:在处理扫描或拍摄的文档时,我们可能需要分析文档的布局,识别并提取出文档中的标题、段落、表格等各个部分。这时,我们可以使用
GetComponentImages方法找到各个部分的位置和大小。 - OCR后处理:在使用OCR技术识别文本后,我们可能需要对识别结果进行后处理,例如纠正错误、提高识别精度等。在这些场景中,我们可以使用
GetComponentImages方法获取每个字符或单词的位置和大小,然后根据这些信息进行后处理。
以上只是一些常见的应用场景,实际上,GetComponentImages这个功能在任何需要分析图像内容、提取图像中的特定部分,或处理图像中的文本的应用中都可能会用到。
import java.io.File;
import java.net.URL;
import org.bytedeco.javacpp.*;
import org.bytedeco.leptonica.*;
import org.bytedeco.tesseract.*;
import static org.bytedeco.leptonica.global.leptonica.*;
import static org.bytedeco.tesseract.global.tesseract.*;
public class GetComponentImagesExample {
public static void main(String[] args) throws Exception {
BytePointer outText;
// 初始化 Tesseract API
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 tesseract-ocr,并使用标准 ENV 变量初始化 tessdata 路径
if (api.Init(System.getenv("TESSDATA_PREFIX") + "/tessdata", "eng") != 0) {
System.err.println("无法初始化 Tesseract。");
System.exit(1);
}
// 使用 Leptonica 库打开输入图像
URL url = new URL("https://img-blog.csdnimg.cn/direct/37d4f5eac7f442bea2d268982fd6c3d7.png");
File file = Loader.cacheResource(url);
PIX image = pixRead(file.getAbsolutePath());
api.SetImage(image);
// 查找所有组件图像
int[] blockIds = {};
// BOXA对象,包含了图像中每一行文本的边界框(即每一行文本的位置和大小)。
BOXA boxes = api.GetComponentImages(RIL_TEXTLINE, true, null, blockIds);
for (int i = 0; i < boxes.n(); i++) {
// 对于每个图像框,OCR 在其区域内进行
BOX box = boxes.box(i);
api.SetRectangle(box.x(), box.y(), box.w(), box.h());
outText = api.GetUTF8Text();
String ocrResult = outText.getString();
// 使用MeanTextConf方法计算这个区域的平均置信度。
int conf = api.MeanTextConf();
String boxInformation = String.format("Box[%d]: x=%d, y=%d, w=%d, h=%d, confidence: %d, text: %s", i, box.x(), box.y(), box.w(), box.h(), conf, ocrResult);
System.out.println(boxInformation);
outText.deallocate();
}
// 销毁使用的对象并释放内存
api.End();
pixDestroy(image);
}
}
图片为:

结果为:
Box[0]: x=67, y=85, w=1264, h=160, confidence: 82, text: The Quick Brown
Box[1]: x=71, y=251, w=1168, h=160, confidence: 94, text: Fox Jumps Over
Box[2]: x=67, y=418, w=1049, h=160, confidence: 69, text: lhe Lazy Dog.
Box[3]: x=65, y=582, w=1811, h=71, confidence: 73, text: abcdefghijklmnopqrstuvwxyz0123456789 | | ( ) { } /\ < >
示例三 使用迭代器遍历识别结果及其选择项
使用 Tesseract OCR 对给定的图像进行文本识别,并通过迭代器遍历输出每个识别结果及其选择项(如果有的话)。在处理图像的过程中,它使用 Leptonica 库打开图像,并通过 Tesseract API 进行文本识别。输出包括每个识别到的符号(symbol)以及其对应的置信度,以及针对每个符号的选择项及其置信度。此程序可以用于分析文本中的字符及其置信度,以及可能的替代选择项。
import java.io.File;
import java.net.URL;
import org.bytedeco.javacpp.*;
import org.bytedeco.leptonica.*;
import org.bytedeco.tesseract.*;
import static org.bytedeco.leptonica.global.leptonica.*;
import static org.bytedeco.tesseract.global.tesseract.*;
public class IteratorOverClassifierChoicesExample {
public static void main(String[] args) throws Exception {
BytePointer outText;
BytePointer choiceText;
// 创建 Tesseract API 对象
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 Tesseract-OCR,并使用标准的环境变量设置 tessdata 路径
if (api.Init(System.getenv("TESSDATA_PREFIX") + "/tessdata", "eng") != 0) {
System.err.println("Could not initialize tesseract.");
System.exit(1);
}
// 使用 Leptonica 库打开输入图像
URL url = new URL("https://upload.wikimedia.org/wikipedia/commons/thumb/7/74/Computer_modern_sample.svg/1920px-Computer_modern_sample.svg.png");
File file = Loader.cacheResource(url);
PIX image = pixRead(file.getAbsolutePath());
api.SetImage(image);
// 创建 Tesseract 文本监视器
ETEXT_DESC recoc = TessMonitorCreate();
api.Recognize(recoc);
// 获取结果迭代器
ResultIterator ri = api.GetIterator();
int pageIteratorLevel = RIL_SYMBOL;
if (ri != null) {
do {
// 获取当前迭代器位置的文本和置信度
outText = ri.GetUTF8Text(pageIteratorLevel);
float conf = ri.Confidence(pageIteratorLevel);
String symbolInformation = String.format("symbol: '%s'; \tconf: %.2f", outText.getString(), conf);
System.out.println(symbolInformation);
// 遍历选择项迭代器并输出选择项及其置信度
boolean indent = false;
ChoiceIterator ci = TessResultIteratorGetChoiceIterator(ri);
do {
if (indent)
System.out.print("\t\t");
System.out.print("\t-");
choiceText = ci.GetUTF8Text();
System.out.println(String.format("%s conf: %f", choiceText.getString(), ci.Confidence()));
indent = true;
choiceText.deallocate();
} while (ci.Next());
outText.deallocate();
} while (ri.Next(pageIteratorLevel));
}
// 销毁使用的对象并释放内存
api.End();
pixDestroy(image);
}
}
结果:
symbol: 'T'; conf: 99.22
-T conf: 99.222244
symbol: 'h'; conf: 99.54
-h conf: 99.542496
symbol: 'e'; conf: 99.54
-e conf: 99.541702
...
示例四 方向和脚本检测
需要osd.traineddata
使用 Tesseract OCR 对给定图像进行文本识别,并通过迭代器分析文本布局,获取图像的方向、脚本、文本行顺序和去倾角度等信息。
适用于需要获取图像文本布局信息的场景,例如自动化文档处理、图像文字分析、以及需要检测和调整文本方向的应用。通过分析文本布局信息,可以更好地理解图像中的文本结构,为后续处理提供有用的信息。
import java.io.File;
import java.net.URL;
import org.bytedeco.javacpp.*;
import org.bytedeco.leptonica.*;
import org.bytedeco.tesseract.*;
import static org.bytedeco.leptonica.global.leptonica.*;
import static org.bytedeco.tesseract.global.tesseract.*;
public class OrientationAndScriptDetectionExample {
public static void main(String[] args) throws Exception {
BytePointer outText;
// 创建 Tesseract API 对象
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 Tesseract-OCR,并使用标准的环境变量设置 tessdata 路径
if (api.Init(System.getenv("TESSDATA_PREFIX") + "/tessdata", "eng") != 0) {
System.err.println("Could not initialize tesseract.");
System.exit(1);
}
// 使用 Leptonica 库打开输入图像
URL url = new URL("https://upload.wikimedia.org/wikipedia/commons/thumb/7/74/Computer_modern_sample.svg/1920px-Computer_modern_sample.svg.png");
File file = Loader.cacheResource(url);
PIX image = pixRead(file.getAbsolutePath());
// 设置 Tesseract 页面分割模式为自动方向和脚本检测
api.SetPageSegMode(PSM_AUTO_OSD);
api.SetImage(image);
// 创建 Tesseract 文本监视器
ETEXT_DESC reco = TessMonitorCreate();
api.Recognize(reco);
// 获取页面迭代器,用于分析布局信息
PageIterator iterator = api.AnalyseLayout();
int[] orientation = new int[1];
int[] writing_direction = new int[1];
int[] textline_order = new int[1];
float[] deskew_angle = new float[1];
// 获取页面布局信息,包括方向、书写方向、文本行顺序和去倾角度
iterator.Orientation(orientation, writing_direction, textline_order, deskew_angle);
String osdInformation = String.format("Orientation: %d;\nWritingDirection: %d\nTextlineOrder: %d\nDeskew angle: %.4f\n",
orientation[0], writing_direction[0], textline_order[0], deskew_angle[0]);
System.out.println(osdInformation);
// 销毁使用的对象并释放内存
api.End();
pixDestroy(image);
}
}
结果:
Orientation: 0;
WritingDirection: 0
TextlineOrder: 2
Deskew angle: 0.0055
Estimating resolution as 1024
Estimating resolution as 1024
-- 页面布局信息:
Orientation(方向): 0,表示图像方向为正常方向。
WritingDirection(书写方向): 0,表示水平书写。
TextlineOrder(文本行顺序): 2,表示文本行的阅读顺序是从上到下。
Deskew angle(去倾角度): 0.0055,表示需要微小的逆时针旋转图像,以使文本更加水平。
最后,给出了图像分辨率的估计值为 1024。
enum Orientation {
ORIENTATION_PAGE_UP = 0, // 页面朝上
ORIENTATION_PAGE_RIGHT = 1, // 页面朝右
ORIENTATION_PAGE_DOWN = 2, // 页面朝下
ORIENTATION_PAGE_LEFT = 3, // 页面朝左
};
enum WritingDirection {
WRITING_DIRECTION_LEFT_TO_RIGHT = 0, // 从左到右
WRITING_DIRECTION_RIGHT_TO_LEFT = 1, // 从右到左
WRITING_DIRECTION_TOP_TO_BOTTOM = 2, // 从上到下
};
enum TextlineOrder {
TEXTLINE_ORDER_LEFT_TO_RIGHT = 0, // 从左到右
TEXTLINE_ORDER_RIGHT_TO_LEFT = 1, // 从右到左
TEXTLINE_ORDER_TOP_TO_BOTTOM = 2, // 从上到下
};
示例五 结果迭代器
此程序使用 Tesseract OCR 对给定图像进行文本识别,并通过迭代器遍历输出每个识别结果的单词、置信度和边界框信息。
适用于需要详细分析文本的应用场景,例如文本布局分析、单词级别的文本处理、或者需要获取文本边界框信息的图像处理任务。通过迭代器遍历,可以获得每个单词的具体位置和识别置信度,为后续处理和分析提供更多信息。
import java.io.File;
import java.net.URL;
import org.bytedeco.javacpp.*;
import org.bytedeco.leptonica.*;
import org.bytedeco.tesseract.*;
import static org.bytedeco.leptonica.global.leptonica.*;
import static org.bytedeco.tesseract.global.tesseract.*;
public class ResultIteratorExample {
public static void main(String[] args) throws Exception {
BytePointer outText;
// 创建 Tesseract API 对象
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 Tesseract-OCR,并使用标准的环境变量设置 tessdata 路径
if (api.Init(System.getenv("TESSDATA_PREFIX") + "/tessdata", "eng") != 0) {
System.err.println("Could not initialize tesseract.");
System.exit(1);
}
// 使用 Leptonica 库打开输入图像
URL url = new URL("https://upload.wikimedia.org/wikipedia/commons/thumb/7/74/Computer_modern_sample.svg/1920px-Computer_modern_sample.svg.png");
File file = Loader.cacheResource(url);
PIX image = pixRead(file.getAbsolutePath());
api.SetImage(image);
// 创建 Tesseract 文本监视器
ETEXT_DESC recoc = TessMonitorCreate();
api.Recognize(recoc);
// 获取结果迭代器
ResultIterator ri = api.GetIterator();
int pageIteratorLevel = RIL_WORD;
if (ri != null) {
do {
// 获取当前迭代器位置的文本、置信度和边界框信息
outText = ri.GetUTF8Text(pageIteratorLevel);
float conf = ri.Confidence(pageIteratorLevel);
int[] x1 = new int[1], y1 = new int[1], x2 = new int[1], y2 = new int[1];
ri.BoundingBox(pageIteratorLevel, x1, y1, x2, y2);
String riInformation = String.format("word: '%s'; \tconf: %.2f; BoundingBox: %d,%d,%d,%d;\n", outText.getString(), conf, x1[0], y1[0], x2[0], y2[0]);
System.out.println(riInformation);
outText.deallocate();
} while (ri.Next(pageIteratorLevel));
}
// 销毁使用的对象并释放内存
api.End();
pixDestroy(image);
}
}
结果:
word: 'The'; conf: 94.56; BoundingBox: 67,86,340,211;
word: 'Quick'; conf: 96.57; BoundingBox: 409,85,818,245;
word: 'Brown'; conf: 96.79; BoundingBox: 879,88,1331,211;
word: 'Fox'; conf: 93.97; BoundingBox: 71,254,314,377;
word: 'Jumps'; conf: 95.90; BoundingBox: 382,254,836,411;
word: 'Over'; conf: 96.67; BoundingBox: 900,251,1239,379;
word: 'The'; conf: 94.07; BoundingBox: 67,418,340,543;
word: 'Lazy'; conf: 96.35; BoundingBox: 410,420,738,578;
word: 'Dog.'; conf: 92.79; BoundingBox: 807,420,1116,578;
word: 'abcdefghijkmnopqrstuvwxyz0123456789'; conf: 18.28; BoundingBox: 65,585,1335,650;
word: '[|'; conf: 66.39; BoundingBox: 1369,582,1415,653;
word: '()'; conf: 54.27; BoundingBox: 1454,582,1518,653;
word: '{'; conf: 62.11; BoundingBox: 1560,582,1586,653;
word: '}'; conf: 62.11; BoundingBox: 1618,582,1643,653;
word: '/\'; conf: 73.02; BoundingBox: 1675,582,1738,653;
word: '<'; conf: 86.10; BoundingBox: 1770,606,1804,639;
word: '>'; conf: 96.04; BoundingBox: 1842,607,1876,639;
示例六 设置引擎、页面分割模式、语言
import org.bytedeco.javacpp.BytePointer;
import org.bytedeco.leptonica.PIX;
import org.bytedeco.tesseract.TessBaseAPI;
import org.bytedeco.tesseract.global.tesseract;
import static org.bytedeco.leptonica.global.leptonica.pixDestroy;
import static org.bytedeco.leptonica.global.leptonica.pixRead;
import static org.bytedeco.tesseract.global.tesseract.PSM_AUTO;
public class BasicExample {
// 执行 OCR 的方法
public static String doOCR(String dataPath, String fileName) {
BytePointer outText;
// 初始化 Tesseract API
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 tesseract-ocr,指定 tessdata 路径
// 如果使用的是中文,请使用 tessdata-best/chi_sim 或者 tessdata-best/chi_tra
// 指定 OCR 引擎为 LSTM_ONLY
if (api.Init(dataPath, "eng", tesseract.OEM_LSTM_ONLY) != 0) {
System.err.println("无法初始化 Tesseract。");
System.exit(1);
}
// 设置页面分割模式
api.SetPageSegMode(PSM_AUTO);
// 使用 Leptonica 库打开输入图像
PIX image = pixRead(fileName);
api.SetImage(image);
// 获取 OCR 结果
outText = api.GetUTF8Text();
System.out.println("OCR 输出:\n" + outText.getString());
// 销毁使用的对象并释放内存
api.End();
outText.deallocate();
pixDestroy(image);
return outText.getString();
}
}
示例七 识别限制为图像的子矩形
import org.bytedeco.javacpp.BytePointer;
import org.bytedeco.leptonica.PIX;
import org.bytedeco.tesseract.TessBaseAPI;
import java.io.File;
import static org.bytedeco.leptonica.global.leptonica.pixDestroy;
import static org.bytedeco.leptonica.global.leptonica.pixRead;
public class Main {
public static void main(String[] args) {
BytePointer outText;
// 初始化 Tesseract API
TessBaseAPI api = new TessBaseAPI();
// 使用英语初始化 Tesseract-ocr,不指定 tessdata 路径
if (api.Init(null, "eng") != 0) {
System.err.println("无法初始化 Tesseract。");
System.exit(1);
}
// 使用 Leptonica 库打开输入图像
File imageFile = new File("phototest.tif");
PIX image = pixRead(imageFile.getAbsolutePath());
api.SetImage(image);
// 限制识别范围为图像的子矩形
// SetRectangle(left, top, width, height)
api.SetRectangle(30, 86, 590, 100);
// 获取 OCR 结果
outText = api.GetUTF8Text();
System.out.println("OCR 输出:\n" + outText.getString());
// 销毁使用的对象并释放内存
api.End();
outText.deallocate();
pixDestroy(image);
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!