103、GAUDI: A Neural Architect for Immersive 3D Scene Generation
简介
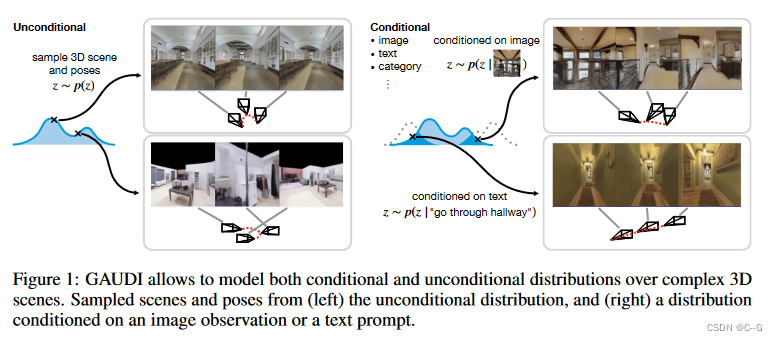
?GAUDI在多个数据集的无条件生成环境中获得了最先进的性能,并允许在给定条件变量(如稀疏图像观察或描述场景的文本)的情况下有条件地生成3D场景。
实现流程
?目标是在给定3D场景中轨迹经验分布的情况下,学习一个生成模型,设
X
=
{
x
i
∈
{
0
,
…
,
n
}
}
X = \{x_{i∈\{0,…,n\}} \}
X={xi∈{0,…,n}?} 表示定义经验分布的示例集合,其中每个示例
x
i
x_i
xi? 是一个轨迹。每个轨迹
x
i
x_i
xi? 被定义为相应的RGB,深度图像和6DOF相机姿态的可变长度序列,如下图。
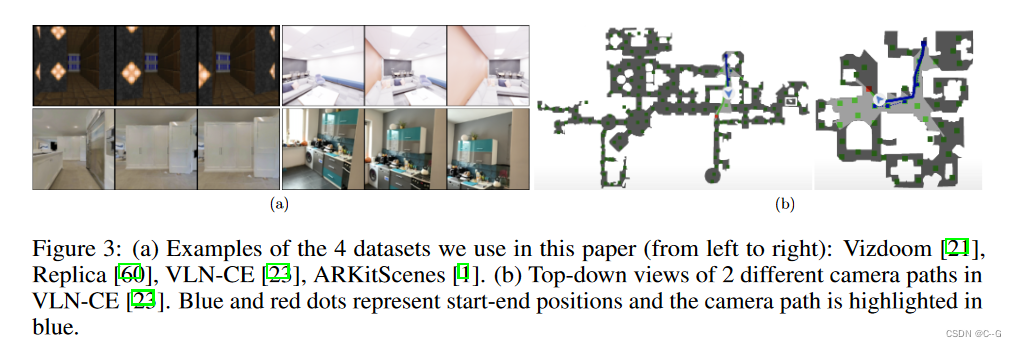
?实现过程包括两阶段:
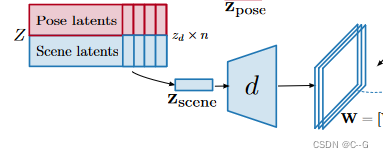
- 为每个示例 x ∈ X x∈X x∈X 获得一个 latents representation z = [ z s c e n e , z p o s e ] z = [z_{scene}, z_{pose}] z=[zscene?,zpose?],它表示场景辐射场和在单独的解纠缠向量中姿态。为了获得这种latents representation,采取 encoder-less [Deepsdf: Learning continuous signed distance functions for shape representation.] 的方法,并将 z 解释为通过优化问题找到的自由参数。
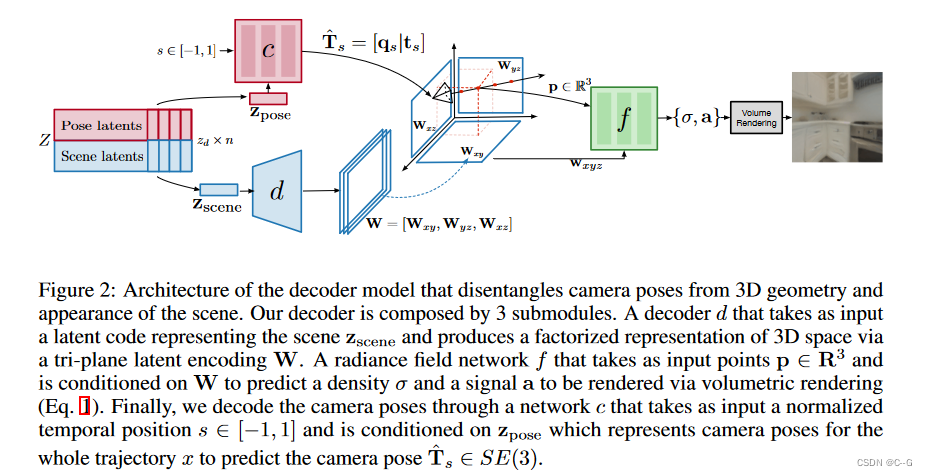
- 给定潜在集合 Z = { z i ∈ { 0 , … , n } } Z = \{z_{i∈\{0,…,n\}} \} Z={zi∈{0,…,n}?}学习分布p(Z),为了将 latents z 映射到轨迹 x,设计了一个网络架构(即解码器,如下图),可以解缠相机姿态和辐射场参数化。
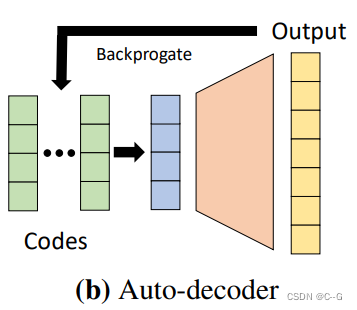
encoder-less:在Deepsdf中使用了一种Auto-decoder方法实现SDF建模,即只要中间 latents 和解码器,每一次训练一个模型的时候,随机初始化一个可训练的 latents code z,并和3d点一起输入解码器,公共优化 z 和解码器。当处理测试数据集的时候,冻结解码器权重同时初始化一个 latents code z,由于解码器经过了训练,因此该过程收敛很快。Auto-decoder网络结构如下图。
因此,简单而言,训练好Auto-decoder得到了训练好了 decoder 和 每个模型的 latents,利用DDPM得到 latents 的生成扩散模型,结合两者就可以得到3d场景生成模型。即利用DDPM得到去噪后的 latent,将latent输入 decoder得到场景 三平面 特征和相机位姿。
解码器
逻辑

?相机姿态解码器网络 c (由 θ c θ_c θc? 参数化)以表示整个轨迹中相机姿态的 z p o s e z_{pose} zpose? 为条件,负责预测轨迹中归一化时间位置 s∈[- 1,1] 的相机姿态 T ^ s ∈ S E ( 3 ) \hat{T}_s∈SE(3) T^s?∈SE(3)。为了确保 c 的输出是有效的相机姿态(例如SE(3)的元素),输出一个表示方向的归一化四元数 q s q_s qs? 的3D向量和一个3D平移向量 t s t_s ts?。
?场景解码器网络 d (由 θ d θ_d θd?参数化)负责预测辐射场网络 f 的调节变量。该网络将表示场景 z s c e n e z_{scene} zscene? 的潜代码作为输入,并预测一个轴对齐的三平面表示 W ∈ R 3 × S × S × F W∈R^{3×S×S×F} W∈R3×S×S×F。对应空间维度 S × S 和 F 通道的 3 个特征图 [ W x y , W x z , W y z ] [W_{xy}, W_{xz}, W_{yz}] [Wxy?,Wxz?,Wyz?],每个轴向对齐平面一个: xy, xz 和 yz。
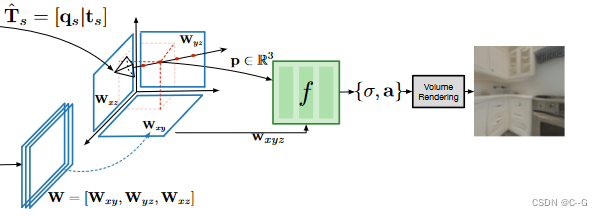
?辐射场解码器网络 f (由 θ f θ_f θf?参数化)的任务是使用体渲染方程重建图像级目标。该过程就是[K-Planes]。
网络架构
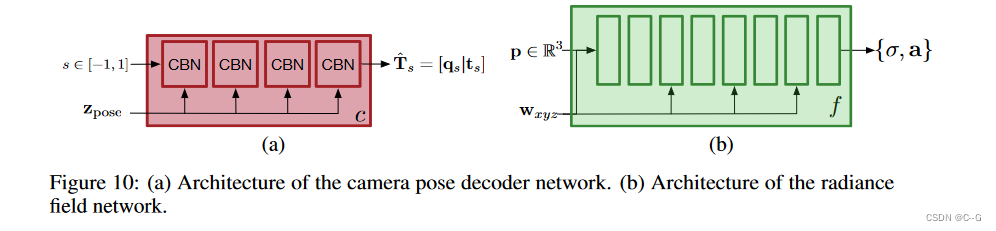
?场景解码器网络 d 遵循VQGAN解码器的架构,使用在每个块的末尾包含自注意力层的卷积架构进行参数化。场景解码器的输出是形状为64 × 64 × 768的特征图。为了获得三平面表示 W = [ W x y , W x z , W y z ] W = [W_{xy}, W_{xz}, W_{yz}] W=[Wxy?,Wxz?,Wyz?],将输出特征图的通道维度划分为3个大小相等的块64 × 64 × 256。
?相机姿态解码器 c被实现为具有4个条件批归一化(CBN)块的MLP,残差连接和隐藏大小为256。条件批归一化参数从 z p o s e z_{pose} zpose? 预测。将位置编码应用于相机姿态编码器(s∈[- 1,1])的输入。
?辐射场解码器 f被实现为一个具有8个线性层、隐藏维度为512和 LeakyReLU 激活的MLP。应用位置编码输入辐射场解码器 ( p ∈ R 3 ) (p∈R^3) (p∈R3) 和连接调节变量 w x y z w_{xyz} wxyz? 向MLP每隔一层的输出从输入层(如层0、2、4、6),为了提高效率,呈现一个小分辨率特性的地图512个频道(两次小于输出分辨率),而不是一个RGB图像和使用UNet额外反褶积层预测最终的图像。
?在训练时,初始化所有 latents z = 0,并使用3个模块的参数联合训练它们。使用Adam优化器,潜变量的学习率为0.001,模型参数的学习率为0.0001。在8块A100 NVIDIA gpu上训练模型2-7天(取决于数据集大小),批处理大小为16个轨迹,其中每个轨迹随机采样2张图像。
损失函数
?制定了一个去噪重建目标来联合优化。如扩散模型一样,latents z 由公式
z
=
z
+
β
N
(
0
,
s
t
d
(
Z
)
z = z+ \beta \N(0,std(Z)
z=z+βN(0,std(Z)得到。
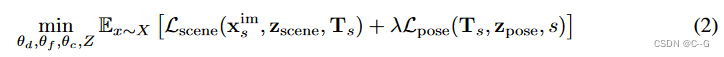
? L s c e n e L_{scene} Lscene?在 z s c e n e z_{scene} zscene? 中编码的辐射场和轨迹 x s i m x^{im}_s xsim?中的图像之间的重建(其中 s 表示轨迹中帧的归一化时间位置),给定渲染所需的地面真实相机姿态 T s T_s Ts?,对 RGB 使用 l 2 l_2 l2? 损失,对深度使用 l 1 l_1 l1? 损失。
? L p o s e L_{pose} Lpose?测量 z p o s e z_{pose} zpose? 中编码的姿态 T ^ s \hat{T}_s T^s? 和真实姿态之间的相机姿态重建误差,对平移采用 l 2 l_2 l2? 损失,对相机姿态的归一化四元数部分采用 l 1 l_1 l1? 损失。虽然理论上归一化四元数不一定是唯一的(例如q和- q),但在训练过程中没有观察到任何问题
?给定一组因最小化公式2中的目标而产生的潜 z ∈ Z z∈Z z∈Z,目标是学习一个捕获其分布的生成模型 p(z) (即在最小化公式2中的目标后,将 z ∈ Z z∈Z z∈Z解释为潜空间中经验分布的示例)。为了对 p(Z) 建模,采用了去噪扩散概率模型(DDPM),为了训练的先验 p θ p ( Z ) p_{θ_p}(Z) pθp??(Z),采用公式3中定义的目标函数。
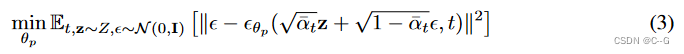
?在推理时,按照 DDPMs 中的推理过程对 z ~ p θ p ( z ) z \sim p_{θ_p} (z) z~pθp??(z) 进行采样,采样 z T ? N ( 0 , I ) z_T ~ N (0, I) zT??N(0,I),并迭代地应用 ? θ p \epsilon_{\theta_p} ?θp?? 逐步去噪 z T z_T zT?,从而反转扩散马尔可夫链以获得 z 0 z_0 z0?。然后将 z 0 z_0 z0?作为输入输入到解码器架构,并重建辐射场和相机路径。
实验
数据集
Vizdoom , Replica VLN-CE 和 ARKit Scenes
文本条件生成
?使用VLN-CE中提供的导航文本描述来调节模型。这些文本描述包含有关场景以及导航路径的高级信息。“走出卧室,进入客厅”,“从旋转门走出房间,然后进入卧室”)。采用预训练的 RoBERTa-base 文本编码器,并使用其中间表示来调节扩散模型。下图显示了GAUDI对这项任务的定性结果。这是第一个允许以摊销方式从文本中有条件地生成3D场景的模型(即不通过昂贵的优化问题提取CLIP)。

图像条件生成
?随机选择轨迹
x
∈
X
x∈X
x∈X 中的图像,并将其作为条件变量 y。在这个实验中,使用VLN-CE数据集中的轨迹。在每次训练迭代中,为每个轨迹 x 采样一个随机图像,并将其用作调节变量。采用预训练的 ResNet-18 作为图像编码器。在推理过程中,产生的条件GAUDI模型能够对从随机角度观察给定图像的辐射度场进行采样。在下图中,显示了以不同RGB图像为条件的模型样本。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!