【算法提升—力扣每日一刷】五日总结【11/30-12/04】

2023/11/30
力扣每日一刷:1.两数之和
给定一个整数数组
nums和一个整数目标值target,请你在该数组中找出 和为目标值target的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。示例 2:
输入:nums = [3,2,4], target = 6 输出:[1,2]示例 3:
输入:nums = [3,3], target = 6 输出:[0,1]提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
//利用哈希表 时间复杂度 O( n ) 优!
public static int[] twoSum(int[] nums, int target) {
//定义一个变量存放数组长度
int len = nums.length;
//定义一个哈希表,对应的Key —— Value分别指:Key-数组中的数值 Value-该值对应的数组下标
Map<Integer,Integer> map = new HashMap<>(len-1);
//循环该数组
for(int i = 0; i<len;i++){
//如果在哈希表中存在符合要求(目标值-当前遍历的值)的值,则返回该值对应的Value(数组下标)与当前遍历的值的数组下标组成的新数组
if (map.containsKey(target-nums[i])) {
return new int[]{i,map.get(target-nums[i])};
}
//如果哈希表中没有符合要求的值,则将当前遍历的值存放进哈希表
map.put(nums[i],i);
}
throw new IllegalArgumentException("数组中没有两数和为目标值");
}
//暴力枚举 时间复杂度 O( n^2 )
public int[] twoSum2(int[] nums, int target) {
int len = nums.length;
//暴力递归
for(int i=0; i < len-1; i++){
int x = nums[i];
for(int j = i + 1;j < len; j++){
int y = nums[j];
if(x + y == target){
return new int[]{i,j};
}
}
}
throw new IllegalArgumentException("数组中没有两数和为目标值");
}
📖 文字题解
方法一:暴力枚举
思路及算法最容易想到的方法是枚举数组中的每一个数 x,寻找数组中是否存在 target - x。
当我们使用遍历整个数组的方式寻找 target - x 时,需要注意到每一个位于 x 之前的元素都已经和 x 匹配过,因此不需要再进行匹配。而每一个元素不能被使用两次,所以我们只需要在 x 后面的元素中寻找 target - x。
方法二:哈希表
思路及算法注意到方法一的时间复杂度较高的原因是寻找 target - x 的时间复杂度过高。因此,我们需要一种更优秀的方法,能够快速寻找数组中是否存在目标元素。如果存在,我们需要找出它的索引。
使用哈希表,可以将寻找 target - x 的时间复杂度降低到从 O(N) 降低到 O(1)。
这样我们创建一个哈希表,对于每一个 x,我们首先查询哈希表中是否存在 target - x,然后将 x 插入到哈希表中,即可保证不会让 x 和自己匹配。
2023/12/01
力扣每日一刷:9.回文数
- 给你一个整数
x,如果x是一个回文整数,返回true;否则,返回false。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
- 例如,
121是回文,而123不是。示例 1:
输入:x = 121 输出:true示例 2:
输入:x = -121 输出:false 解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。示例 3:
输入:x = 10 输出:false 解释:从右向左读, 为 01 。因此它不是一个回文数。提示:
-231 <= x <= 231 - 1
//反转一半数字 优!
class Solution {
public boolean isPalindrome(int x) {
// 特殊情况:
// 如上所述,当 x < 0 时,x 不是回文数。
// 同样地,如果数字的最后一位是 0,为了使该数字为回文,
// 则其第一位数字也应该是 0
// 只有 0 满足这一属性
if (x < 0 || (x % 10 == 0 && x != 0)) {
return false;
}
int revertedNumber = 0;
while (x > revertedNumber) {
revertedNumber = revertedNumber * 10 + x % 10;
x / = 10;
}
// 当数字长度为奇数时,我们可以通过 revertedNumber/10 去除处于中位的数字。
// 例如,当输入为 12321 时,在 while 循环的末尾我们可以得到 x = 12,revertedNumber = 123,
// 由于处于中位的数字不影响回文(它总是与自己相等),所以我们可以简单地将其去除。
return x == revertedNumber || x == revertedNumber / 10;
}
}
📖 文字题解
方法一:反转一半数字
思路映入脑海的第一个想法是将数字转换为字符串,并检查字符串是否为回文。但是,这需要额外的非常量空间来创建问题描述中所不允许的字符串。
第二个想法是将数字本身反转,然后将反转后的数字与原始数字进行比较,如果它们是相同的,那么这个数字就是回文。
但是,如果反转后的数字大于 int.MAX\text{int.MAX}int.MAX,我们将遇到整数溢出问题。按照第二个想法,为了避免数字反转可能导致的溢出问题,为什么不考虑只反转 int\text{int}int 数字的一半?毕竟,如果该数字是回文,其后半部分反转后应该与原始数字的前半部分相同。
例如,输入 1221,我们可以将数字 “1221” 的后半部分从 “21” 反转为 “12”,并将其与前半部分 “12” 进行比较,因为二者相同,我们得知数字 1221 是回文。
算法
首先,我们应该处理一些临界情况。所有负数都不可能是回文,例如:-123 不是回文,因为 - 不等于 3。所以我们可以对所有负数返回 false。除了 0 以外,所有个位是 0 的数字不可能是回文,因为最高位不等于 0。所以我们可以对所有大于 0 且个位是 0 的数字返回 false。
现在,让我们来考虑如何反转后半部分的数字。
对于数字 1221,如果执行 1221 % 10,我们将得到最后一位数字 1,要得到倒数第二位数字,我们可以先通过除以 10 把最后一位数字从 1221 中移除,1221 / 10 = 122,再求出上一步结果除以 10 的余数,122 % 10 = 2,就可以得到倒数第二位数字。如果我们把最后一位数字乘以 10,再加上倒数第二位数字,1 * 10 + 2 = 12,就得到了我们想要的反转后的数字。如果继续这个过程,我们将得到更多位数的反转数字。
现在的问题是,我们如何知道反转数字的位数已经达到原始数字位数的一半?
由于整个过程我们不断将原始数字除以 10,然后给反转后的数字乘上 10,所以,当原始数字小于或等于反转后的数字时,就意味着我们已经处理了一半位数的数字了。
2023/12/02
力扣每日一刷:13.罗马数组转整数
罗马数字包含以下七种字符:
I,V,X,L,C,D和M。字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000例如, 罗马数字
2写做II,即为两个并列的 1 。12写做XII,即为X+II。27写做XXVII, 即为XX+V+II。通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做
IIII,而是IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。给定一个罗马数字,将其转换成整数。
示例 1:
输入: s = "III" 输出: 3示例 2:
输入: s = "IV" 输出: 4示例 3:
输入: s = "IX" 输出: 9示例 4:
输入: s = "LVIII" 输出: 58 解释: L = 50, V= 5, III = 3.示例 5:
输入: s = "MCMXCIV" 输出: 1994 解释: M = 1000, CM = 900, XC = 90, IV = 4.提示:
1 <= s.length <= 15s仅含字符('I', 'V', 'X', 'L', 'C', 'D', 'M')- 题目数据保证
s是一个有效的罗马数字,且表示整数在范围[1, 3999]内- 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 - Mathematics 。
//哈希表存数据 优!
// 定义一个Map,用来存储字符和整数的映射关系
static Map<Character, Integer> symbolValues = new HashMap<Character, Integer>() {{
put('I', 1);
put('V', 5);
put('X', 10);
put('L', 50);
put('C', 100);
put('D', 500);
put('M', 1000);
}};
// 定义一个函数,用来将罗马数字转换为整数
public static int romanToInt(String s) {
// 定义一个变量ans,用来存储转换后的整数
int ans = 0;
// 获取罗马数字的长度
int n = s.length();
// 遍历罗马数字中的每一个字符
for (int i = 0; i < n; ++i) {
// 获取每一个字符对应的整数
int value = symbolValues.get(s.charAt(i));
// 如果当前字符的整数小于下一个字符的整数,则减去当前字符的整数
if (i < n - 1 && value < symbolValues.get(s.charAt(i + 1))) {
ans -= value;
// 否则,加上当前字符的整数
} else {
ans += value;
}
}
// 返回转换后的整数
return ans;
}
//暴力模拟
public static int romanToInt2(String s) {
int len = s.length();
int result = 0;
for(int i=0;i<len;i++){
switch (s.charAt(i)){
case 'I':
if(i==len-1 ){
result += 1;
}
else if( s.charAt(i+1)== 'V' || s.charAt(i+1)== 'X'){
result -= 1;
}else{
result += 1;
}
case 'V':result += 5;
case 'X':
if(i==len-1 ){
result += 10;
}
else if(s.charAt(i+1)=='L' || s.charAt(i+1)=='C'){
result -= 10;
}else{
result += 10;
}
case 'L':result += 50;
case 'C':
if(i==len-1 ){
result += 100;
}
else if(s.charAt(i+1)=='D' || s.charAt(i+1)=='M'){
result -= 100;
} else{
result += 100;
}
case 'D': result += 500;
default:result += 1000;
}
}
return result;
}

2023/12/03
力扣每日一刷:26. 删除有序数组中的重复项
给你一个 非严格递增排列 的数组
nums,请你** 原地** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回nums中唯一元素的个数。考虑
nums的唯一元素的数量为k,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。- 返回
k。判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组 int[] expectedNums = [...]; // 长度正确的期望答案 int k = removeDuplicates(nums); // 调用 assert k == expectedNums.length; for (int i = 0; i < k; i++) { assert nums[i] == expectedNums[i]; }如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2] 输出:2, nums = [1,2,_] 解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4] 输出:5, nums = [0,1,2,3,4] 解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。提示:
1 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums已按 非严格递增 排列
//暴力解法 !不满足题目中原地的要求
public static int removeDuplicates(int[] nums) {
//定义一个变量len,用来存储数组的长度
int len = nums.length;
//定义一个List集合
List<Integer> list = new ArrayList<>();
//遍历数组
for(int i=0;i<len;i++){
//如果list集合中不包含当前元素
if(!list.contains(nums[i])){
//将当前元素添加到list集合中
list.add(nums[i]);
}
}
//遍历list集合
for(int i=0;i<list.size();i++){
//将list集合中的元素赋值给数组
nums[i] = list.get(i);
}
//返回list集合的长度
return list.size();
}
//双指针解法 优!
public static int removeDuplicates2(int[] nums) {
//如果数组为空,则返回0
if(nums==null){
return 0;
}
//定义两个指针,i指向下一个不重复的元素,j指向当前元素
int len = nums.length;
int i=1;
for(int j=1;j<len;j++){//j指针用来扫描数组,i指针指向需要被替换的元素
//如果当前元素不等于前一个元素,则将当前元素赋值给i指向的位置,i自增
if(nums[j]!=nums[i-1]){
nums[i] = nums[j];
i++;
}
}
//返回i的值,即不重复元素的数量
return i;
}
class Solution {
public int removeDuplicates(int[] nums) {
// 数组的长度
int n = nums.length;
// 如果数组为空,则返回0
if (n == 0) {
return 0;
}
// 快慢指针,初始值都为1
int fast = 1, slow = 1;
// 当快指针小于数组长度时,循环
while (fast < n) {
// 如果快指针指向的元素不等于前一个元素
if (nums[fast] != nums[fast - 1]) {
// 将快指针指向的元素赋值给慢指针指向的元素
nums[slow] = nums[fast];
// 慢指针加1
++slow;
}
// 快指针加1
++fast;
}
// 返回慢指针的值
return slow;
}
}
2023/12/04
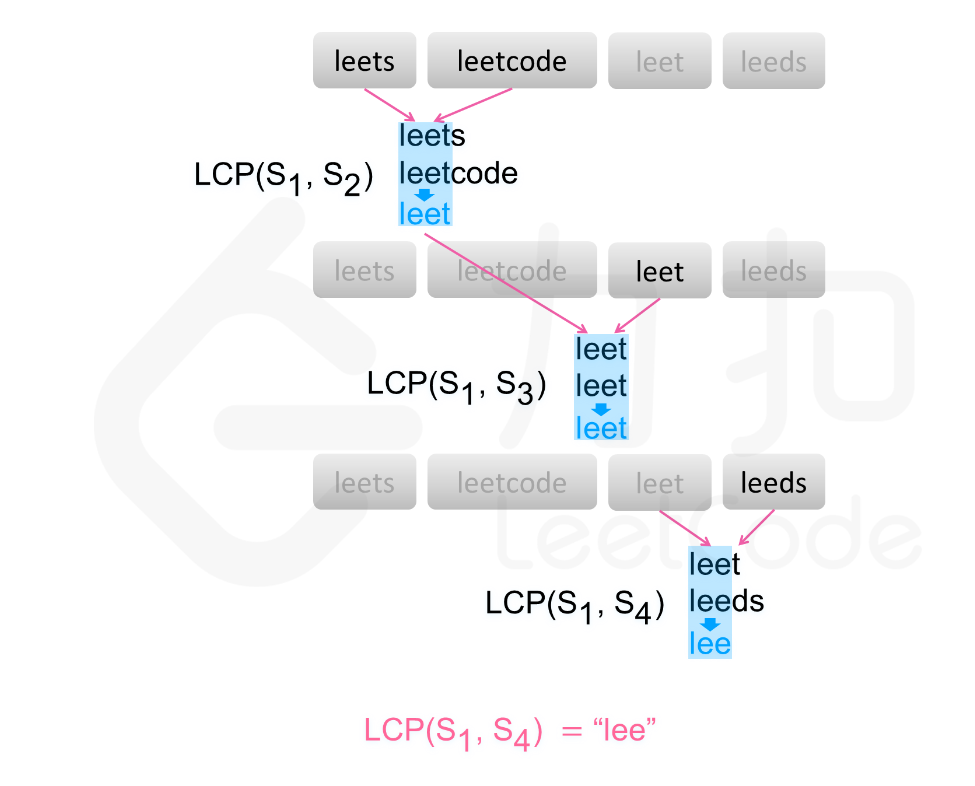
力扣每日一刷:14. 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串
""。示例 1:
输入:strs = ["flower","flow","flight"] 输出:"fl"示例 2:
输入:strs = ["dog","racecar","car"] 输出:"" 解释:输入不存在公共前缀。提示:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]仅由小写英文字母组成
//横向扫描
public String longestCommonPrefix(String[] strs) {
// 判断字符串数组是否为空
if(strs ==null||strs.length==0){
return "";
}
// 获取字符串数组的第一个字符串
String s1 = strs[0];
// 获取字符串数组的长度
int count = strs.length;
// 遍历字符串数组
for(int i=1;i<count;i++){
// 获取两个字符串的最长公共前缀
s1 = towLongestCommon(s1, strs[i]);
// 如果最长公共前缀为空,则跳出循环
if(s1.isEmpty()){
break;
}
}
// 返回最长公共前缀
return s1;
}
private String towLongestCommon(String s1,String s2){
// 获取两个字符串的最小长度
int min = Math.min(s1.length(),s2.length());
// 定义索引
int index = 0;
// 遍历两个字符串
while (index<min && s1.charAt(index) == s2.charAt(index)){
index++;
}
// 返回两个字符串的最长公共前缀
return s1.substring(0,index);
}

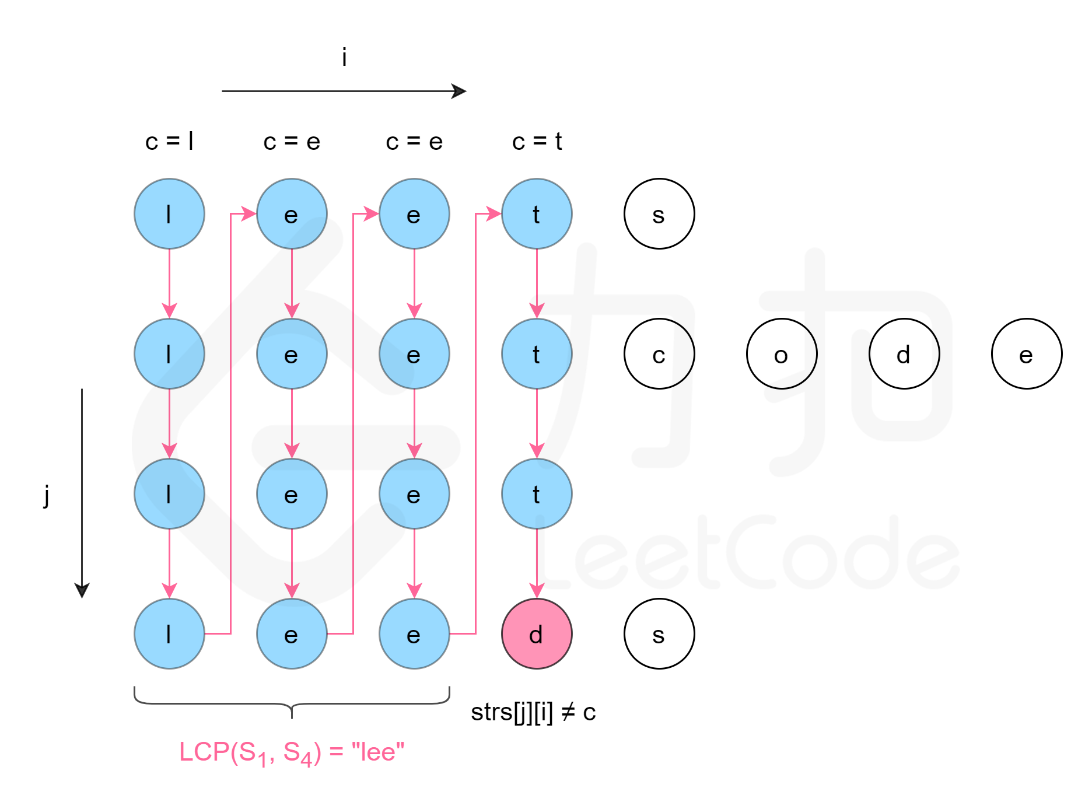
public String longestCommonPrefix(String[] strs) {
// 如果字符串数组为空或者为null,则返回空字符串
if(strs.length==0||strs==null){
return "";
}
// 获取字符串数组中第一个字符串的长度
int length = strs[0].length();
// 获取字符串数组中字符串的数量
int count = strs.length;
// 遍历字符串数组中第一个字符串的每一个字符
for(int i=0;i<length;i++){
// 获取字符串数组中第一个字符串的第i个字符
char c = strs[0].charAt(i);
// 遍历字符串数组中剩余的字符串
for(int j=1;j<count;j++){
// 获取字符串数组中第j个字符串的第i个字符
char c1 = strs[j].charAt(i);
// 如果字符串数组中第j个字符串的长度小于i或者字符串数组中第j个字符串的第i个字符与第一个字符串的第i个字符不相等,则返回第一个字符串的前i个字符
if(i==strs[j].length() || c!=c1){
return strs[0].substring(0,i);
}
}
}
// 如果遍历完字符串数组中第一个字符串的所有字符,没有出现上面的情况,则返回第一个字符串
return strs[0];

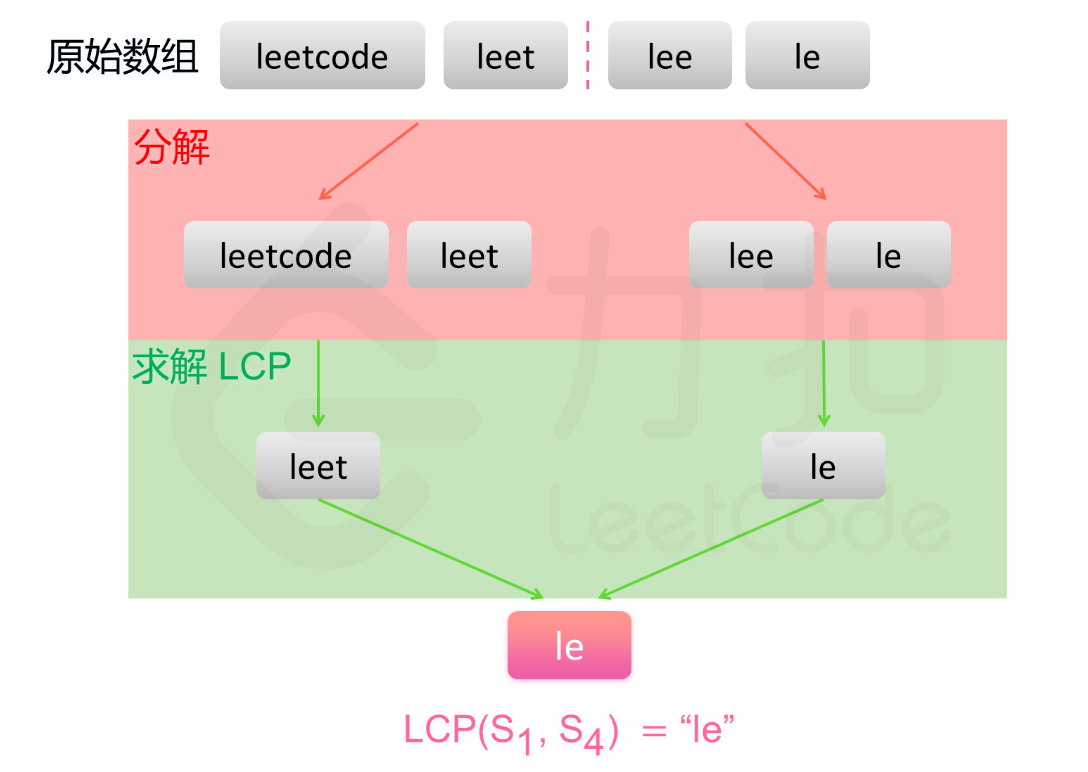
//分治算法
class Day5_longestCommonPrefix_3 {
public String longestCommonPrefix(String[] strs) {
// 获取字符串数组的长度
int len = strs.length;
// 如果字符串数组为空或者长度为0,则返回空字符串
if (strs == null || len == 0) {
return "";
} else {
// 否则调用longestCommonPrefix方法,传入字符串数组,以及起始位置和结束位置
return longestCommonPrefix(strs, 0, len - 1);
}
}
private String longestCommonPrefix(String[] strs, int start, int end) {
// 如果起始位置等于结束位置,则返回该位置的字符串
if (start == end) {
return strs[start];
}
// 计算中间位置
int mid = (end - start) / 2 + start;
// 递归调用longestCommonPrefix方法,获取左边字符串的最长公共前缀
String left = longestCommonPrefix(strs, start, mid);
// 递归调用longestCommonPrefix方法,获取右边字符串的最长公共前缀
String right = longestCommonPrefix(strs, mid + 1, end);
// 返回左右字符串的最长公共前缀
return longestCommonPrefix(left,right);
}
private String longestCommonPrefix(String left,String right){
// 获取左右字符串的最小长度
int min = Math.min(left.length(), right.length());
// 遍历最小长度,比较左右字符串的每一个字符
for (int i = 0; i < min; i++) {
// 如果左右字符串的每一个字符不相等,则返回从开头到当前字符的字符串
if(left.charAt(i)!=right.charAt(i)){
return left.substring(0,i);
}
}
// 如果左右字符串的每一个字符都相等,则返回最小长度长度的字符串
return left.substring(0,min);
}
}

力扣每五日一总结【11/30–12/04】
哈希表: Key—数组中数的值 Value—当前值对应的数组下标
? 每次遍历数组中的一个数时,从哈希表中查找是否有与当前数和为目标值的数,如果有,则返回他的Value,如果没有,将当前数存放到哈希表中。
- 反转一半数字:
- 先判断满足回文数的条件,把不满足回文数条件【负数和个位数为零】的先Pass
- 反转数字计算方法,每次将原数%10,取个位数加到反转数上,将反转数原有的数*10(挪出个位数),将原数/10(除去已经被加在反转数中的个位数)循环结束条件(原数<反转数)
- 判断是否为回文数的条件(情况一:当原数为偶数—如果反转数直接等于原数,则为回文数,情况二:当原数为奇数—此时反转数比原数多一位,需要先将反转数/10去除个位数,再与原数比较,如果相等,则为回文数)
- 哈希表存数据: Key—罗马数字 Value—罗马数字对应的值
- 循环当前罗马字符串,依次从哈希表中取出对应的值,计算规律:如果当前值小于下一个罗马字符对应的值,则减去当前值,如果大于下一个罗马字符对应的值,则加上当前值。
- 暴力模拟
- 双指针:
- 定义两个指针,一个快指针,用于扫描数组中的值,一个满指针,用于指向待替换元素,一旦快指针扫描到的元素与满指针上一元素不同时,则将快指针的值赋值给满指针,快慢指针均加一,如果快指针指向的值等于满指针指向的上一元素,则快指针继续扫描,满指针不变。
- 暴力模拟
- 横向扫描:
- 固定数组中的第一个字符串,遍历从第二个字符串开始以后的字符串,分别与第一个字符串求最长公共前缀,把每次求出的最长公共前缀赋值给第一个字符串,以此类推。
- 纵向扫描:
- 固定每个字符串的第一个字符并记录,然后开始遍历每个字符串,如果每个字符串的第一个字符都相同,则比较下一个字符,如果不同,则使用字符串剪切方法substring返回(0,当前字符)的字符串,即为公共前缀。
- 分治算法:
- 计算一组字符串数组中各个字符串的公共前缀,则可以划分为小问题:计算两个字符串的公共前缀,使用分治思想。
- 使用递归法,分别求数组左右部分的最长公共前缀,最后输出左右部分的最长公共前缀的公共前缀即为最终答案。
声明:以上文字题解为力扣官方题解,本人思路均在代码注释以及五日总结中体现,更加详细和朴素,相比官方题解更易于接受,在此感谢力扣官方提供题解,拓展思维,感谢!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!