正则表达式与bs4选择器筛选论文数准确率之比较
2023-12-23 19:38:16
一、正则爬取论文网首页论文标题的示例
import requests
import re
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36'}
def get_html(url):
try:
res = requests.get(url, headers=headers)
res.raise_for_status()
res.encoding = 'gbk'
return res.text
except:
print('response error!')
def paper_title(page):
my_items = re.findall(r'<a href="(.*?)" target="_blank">(.*?)</a>', page)
print('paper count of main page:' + str(len(my_items))) # 用正则的findall得出首页所有论文的超链接数量
for item in my_items:
print(item)
二、主函数使用bs4的CSS选择器select()一样算出了论文数:
if __name__ == '__main__':
url = 'https://www.lunwendata.com/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
size = len(soup.select('a[target="_blank"]')) # 用CSS选择器得出首页所有论文超链接数
print('paper count of main page:' + str(size))
paper_title(html)
三、输出结果得出用正则方法筛选准确率更高:
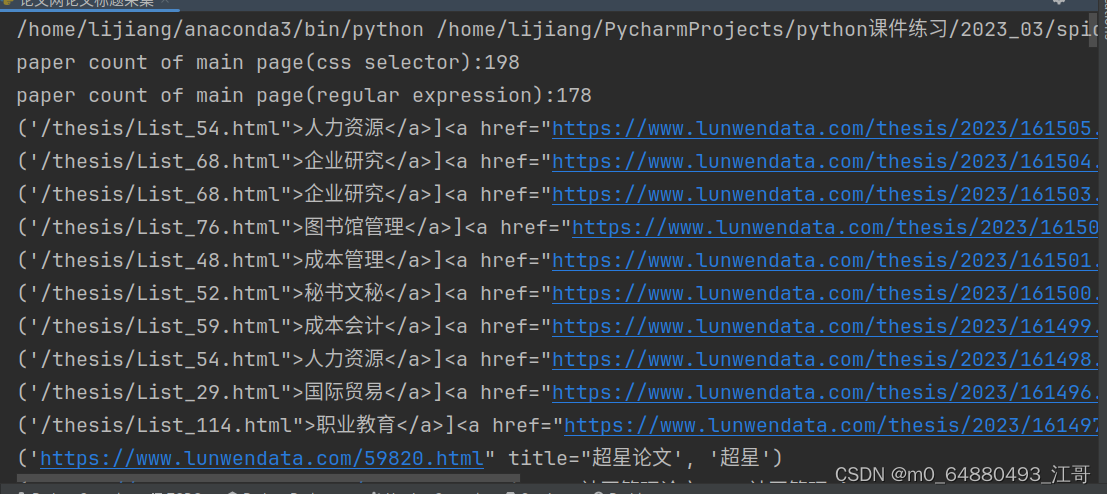
可以看到,用正则的方法筛选出的数量比bs4的select选择器筛选出的少了20个,证明正则的方法筛选数量的准确率更高。
文章来源:https://blog.csdn.net/m0_64880493/article/details/135171813
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!