万字长文谈自动驾驶bev感知(一)
文章目录
- prologue
- paper list
- camera bev :
- 1. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
- 2. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird's-Eye View Representation
- 3. BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
- 4. BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
- lidar det:
- fusion bev:
- 1.[BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation](https://arxiv.org/pdf/2205.13542.pdf) [[code]](https://github.com/mit-han-lab/bevfusion)
- 2. [Cross Modal Transformer: Towards Fast and Robust 3D Object Detection](https://arxiv.org/pdf/2301.01283.pdf) [[code]](https://github.com/junjie18/CMT)
- 3.[TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers](https://arxiv.org/pdf/2203.11496.pdf) [[code]](https://github.com/XuyangBai/TransFusion/)
- Interesting thing
prologue
这有可能是更的最长的文章系列了,先说为什么,一方面是看到分割大模型对小模型的提升效果需要时间,另一方面是之前对自动驾驶的BEV算法做了很长时间的预研,自己也应该好好梳理一下了。
(很多事情都是环环相扣,都需要去决断。比如分割大模型对小模型性能有没有提升,效果提升的投入和输出是否合适,提升不大还有有没有必要继续做,是换个方向还是继续探索,继续探索还有多少资源支撑,太多太多了。bev预研到什么时候才有可能落地,看过的paper有没有转化为产出的机会,产出能不能给自己带来收益,这些也都是问题。虽然看起来问题很复杂,但不过也就是个马尔可夫链,一切都还在变化之中,静待靴子落地吧)
其实自动驾驶bev算法是个很宽泛的说法,bev也就是bird’s-eye-view,是指从鸟瞰视角来做task的范式;从数据来说有纯视觉的bev,纯雷达的bev,也有视觉雷达or其他多传感器融合的bev。
这也是有很多说法的,对于一个公司项目来说,走什么样的技术路线,用什么样的传感器,运行在什么平台上,都对相应的算法有着要求,在现实的种种妥协之下最sota的算法也不一定就是最好的,指标高的算法也不见得就一定是能用的。
就先简单说一下,也给大家share一下自己的一些paper list:
paper list
camera bev :
1. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
-
点评:
纯视觉bev的开山鼻祖,在后续的文章里面但凡有用到将二维图像feature提升到三维空间然后拍扁到bev空间都有用到其提出的lift-splat的操作,代码也很干脆易读。(shoot部分是做规划的,代码没开出来)核心是将每个图像单独提升为一个特征的视锥,然后将所有视锥拍平到栅格化的BEV网格上,如下图所示。当然由于是初代版本也就不可避免的存在一些问题,最主要的两个点,一是splat的过程中运算耗时,二是在深度估计部分由于给予每个点可能的深度时并没有用深度真值监督,导致不够准确,越远效果越差性能和现在的新一些算法比起来差很多。但这仍旧不妨碍其在bev算法中的份量。
题外话:我也有过对lss进行优化,说来话长,可以给大家推一些我之前相关的博文。简单说就是之前有想着打一打nuscenes的榜单,对公司对自己也都有好处,于是就打算从Lss入手来搞,当时主要考虑他是plug and play 的,基于lss的bev算法很多,如果能在这样基础算法上做出改进那就可以对所有使用了lss模块的算法都带来提升,这是一件有意义的事情。至于后面就不说了,都是汗与累啊!
一个是对代码的解读
一个是对LSS做改进的nuscenes sota
一个是我之前搞得nuscenes 深度图

2. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
- 点评:这是一篇没有开源的文章,和lss一样也是nvidia的工作,也是从2d到3d再投影到bev空间但由于假设沿射线的深度分布是均匀的,这意味着沿相机射线的所有体素都填充与2D空间中单个像素对应的相同特征,所以内存高效速度更快,单从文章看效果比lss要好,号称是第一个用统一框架同时做检测和分割任务的,但没开源。
- 这里有一个点是,这篇文章假设沿着射线的深度分布是均匀的,这意味着沿着相机射线的所有体素都填充有与2D空间中的P中的单个像素相对应的相同特征。好处是这种统一的假设通过减少学习参数的数量来提高计算和存储效率。但lss却不是这样,他是a non-uniform depth distribution。

3. BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
- 点评:lss算法后来者,或者说包了一层皮(有点直白),改进了前处理和后处理核心没变,之前lss是做分割任务,这篇是拿来做检测任务。这篇工作是鉴智机器人做的,后续还有一系列文章与改进版本。虽然但是从这里开始后面的很多文章就会对lss中的所谓“棱台求和”部分进行优化和加速了。
题外话(+1):鉴智机器人还是可以的创始人都是清华背景,当初大概21年后半年的时候有面过,那时候他们刚开始创业也就几十个人,说过去做感知后处理,非常可惜当时自己也还年轻,互相也都没看上。后面再来看他们确实做了不少有意义的工作,点赞!不过现在自动驾驶环境也一般,大家也都过的不容易。

这里给大家放一下bevdet系列的发展历程:
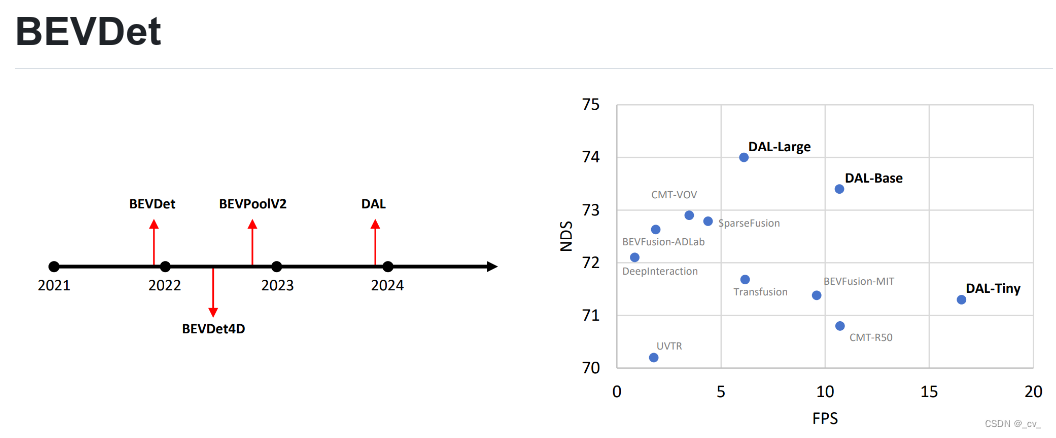
bevdet做出来以后,后面还有bevdet4d (BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection)主要就是增加了时序,将过去帧与当前帧特征融合来提高精度,比较有趣的。主要原因有:在做特征融合的时候,BEVDet4D在BEVDet的基础上,通过保留过去帧的中间BEV特征,并通过与当前帧对齐和拼接来融合特征。这样,BEVDet4D可以通过查询两个候选特征来获取时间线索,而仅需要可忽略的计算增加。对任务进行了简化,BEVDet4D通过移除自我运动和时间因素来简化速度预测任务。这使得BEVDet4D能够减少速度误差,使得基于视觉的方法在这方面首次与依赖LiDAR或雷达的方法相媲美。BEVDet4D的性能提升主要来源于速度估计更准确1。此外,小模型上的mAP有一定的增长,主要是小分辨率无法覆盖50米的范围,历史帧提供了一定的线索。
在往后就是bevpoolv2主要做对于lift-splat的提速,用预处理来优化计算流程做到了4.6 - 15.1倍速度的提升,同时也降低了内存的占用。这个处理确实很高级,点赞!对于工程化落地来说真是太重要了。

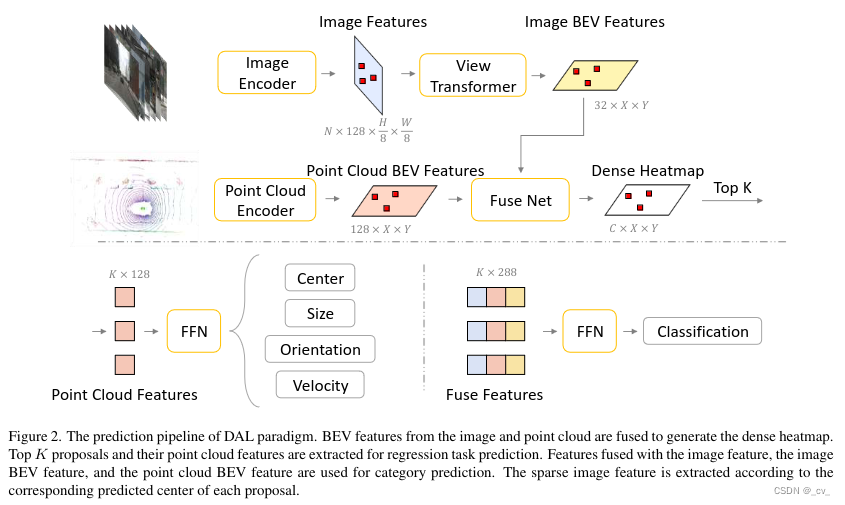
截止到2023年12月22日,bevdet系列的最新发展是DAL(Detecting As Labeling:Rethinking LiDAR-camera Fusion in 3D Object Detection),是做视觉和lidar融合的,效果和速度都有提升。如果直接点说,和bevfusion(mit版本)的流程大同小异,只是在视觉雷达的分支上更加相信雷达,然后包了一个“模仿数据注释过程”的故事,比较粗浅的来说就是这样。当然这并不妨碍人家效果好,也还是做了很多细节上的工作的。也比较期待他们接下来的工作。
以下是DAL paper中的框架图:
4. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
- 点评:使用transformer和temporal来做bev感知任务(检测和分割)提升性能,有一些设计比如bev
queries,spatial cross-attention,temporal self-attention。主要注意的是这里的两个attention并不是经典的transformer,而是用的DeformAtt.这里我记得当时在看整个流程的时候废了一点功夫,代码也相对来说复杂一些。
不过大家也可以从这里开始,顺便看一看detr的发展脉络。这里的bev queries 是随机生成初始化的,然后我记得后面有一篇nvidia打榜cvpr 2023 挑战赛的时候的fb-bev or fb-occ来着,对于queries的初始化这部分有做改进,能学的快一点。

上面是论文出处,不是我乱说哦!这里没有把这篇文章放进来主要是最开始fb-occ是做占用网格用的,后面做bev放出来的fb-bev效果反倒没有很惊艳,再加上打榜的工作本来就不是为了产品化来设计的,前向投影查一遍反向投影(2d-3d,3d-2d)速度当然就很慢了,所以就没说。(不过也有懒得成分了)

后续还有一些改进的版本,比如BEVFormer++,bevformerv2当然这个工作不是原班人马,所以就简单说一下bevformerv2。这篇主要就是没开源,paper说要开但是还没,所以也就只能看看idea;bevformer++
则是一篇技术报告,原班人马拿了Waymo Open Dataset Challenge 2022的第一名,可以看一看吧。
5. BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
- 点评:bevdepth是我非常欣赏的一篇工作,在lss的基础上用雷达作为深度的真值,深度估计网络考虑到相机内参,深度细化模块专门对深度估计部分进行了优化,更重要的是使用gpu并行对原来lss的"cumsum
trick"进行了优化,大大提升了lss环节的速度,在gpu下相较原版lss快了80x。真是把lss depth估计的效果提升了一个档次(其实这也是我当时想在lss深度上做文章的灵感来源,ps这句话不重要)
6. CVT:Cross-view Transformers for real-time Map-view Semantic Segmentation
- 点评:前视图投影顶视图的原理,用transformer的注意力机制搞跨视图分割。

7. GKT:Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer
- 点评:之前有注释过核心代码https://blog.csdn.net/weixin_46214675/article/details/131169769?spm=1001.2014.3001.5501,不是什么很出名的paper,像其他的可能都是cvpr,eccv,iccv啥的,之所以会搞这个主要是当时有项目在地平线的芯片上,他们对这个算法有支持,然后一看原来是人在地平线实习的时候搞得,目前为止没看到有中稿,就他们自家东西支持一下我觉得也很正常。感兴趣大家可以自己看看,简单说是bev投到图像,然后在投影周边一定范围内做注意力,当然也有一些其他的比如对外参加一些噪声让网络更鲁棒,建查找表加速。
lidar det:
对于雷达来说,bev其实就没有那么必须,雷达bev和detection关系比较密切。一般用雷达做检测有几个范式?不知道咋说,要么就是基于点来做,像pointnet,pointnet++;基于视角来做的话就可以是顶视这就是bev,也可以是前视图,这两种视角变化做雷达图像融合也会看到的;也可以基于体素来做。当然这么说并不准确,不管什么范式总有互相借鉴的地方。
1. pointpillar
- 点评:https://blog.csdn.net/weixin_46214675/article/details/125927515?spm=1001.2014.3001.5502,很久之前浅浅有做过个ppt,当时主要是当科普来讲,所以没有很细,但确实是篇对工业界有用的paper,点赞!
2. centerpoint
- 点评:CenterPoint使用标准的基于激光雷达的主干网络,VoxelNet或PointPillars。CenterPoint预测连续帧之间物体的相对偏移(速度),然后贪婪地连接这些帧。因此,在CenterPoint中,3D物体跟踪简化为贪婪的最近点匹配。这种检测和跟踪算法既高效又有效。在nuScenes基准测试中,CenterPoint实现了最先进的性能。在Waymo开放数据集上,CenterPoint的性能超过了所有以前的单一模型方法。
- 青出于蓝胜于蓝,也是一篇很不错的paper,工业界目前还有在使用的,点赞!
fusion bev:
1.BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation [code]
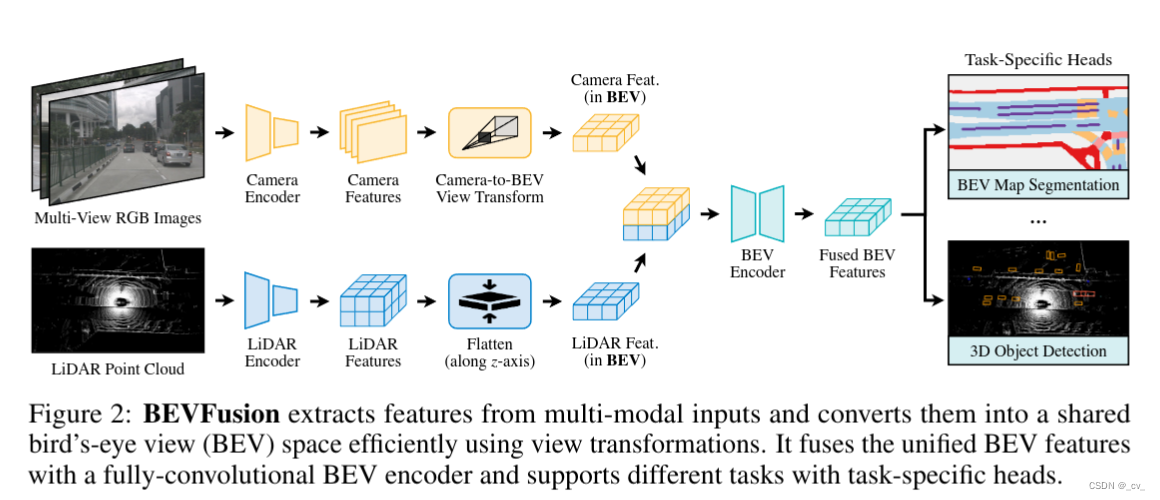
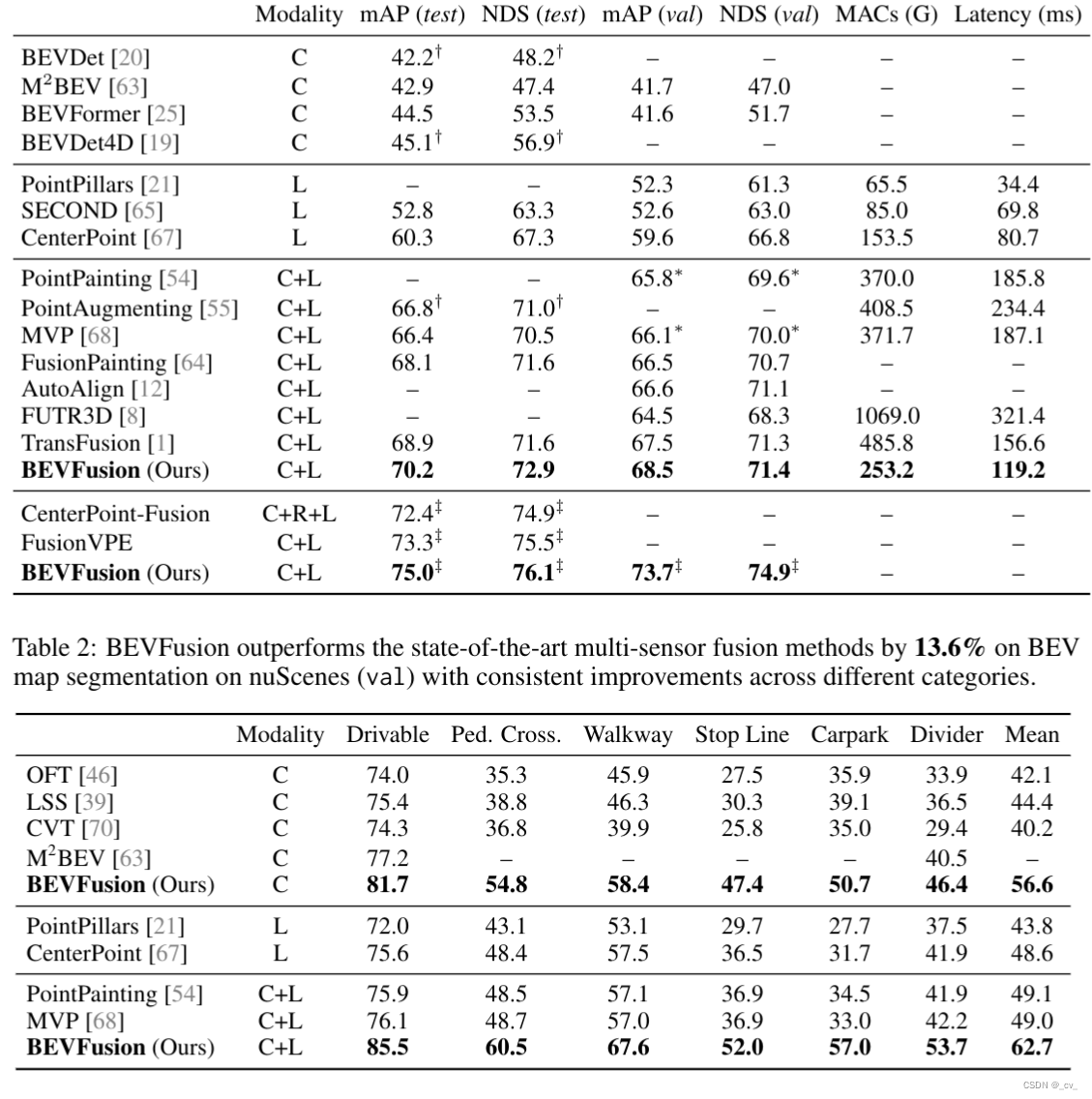
- 点评:bevfusion是一篇图像激光雷达融合的bev算法,支持同时检测和分割任务。在nuScenes detection task
榜单上有许多该方法的变体,从总体架构上来看基本方法很清晰,camera分支和lidar分支分别提取特征,然后转移到共享的bev空间下,再提取bev特征来做多任务,真可谓是大道至简。值得一提的是,bevfusion对于camera to bev 部分的优化做了不少工作,预计算部分减少了13ms,gpu计算间隔优化减少了498ms,真是把优化做到了极致,很多公司都做不到这样。

此外,从paper实验对比部分我们也能看出bevfusion的强大,对于许多想学习bev的工程师来说bevfusion真是一个很优秀的框架了,正如团队所说希望BEVFusion可以作为一个简单但强大的基线,启发未来多任务多传感器融合的研究。但遗憾的是,尽管团队针对速度做了很多工作但仍不能达到实时。(8.4 FPS)
在实际的工程项目中,如果想要使用bevfusion最大的问题其实还是优化问题,因为作者的优化都是基于cuda是做的,一旦离开nvidia的平台很多地方会受到影响,这部分就需要针对不同平台来编写定制化的算子。
2. Cross Modal Transformer: Towards Fast and Robust 3D Object Detection [code]
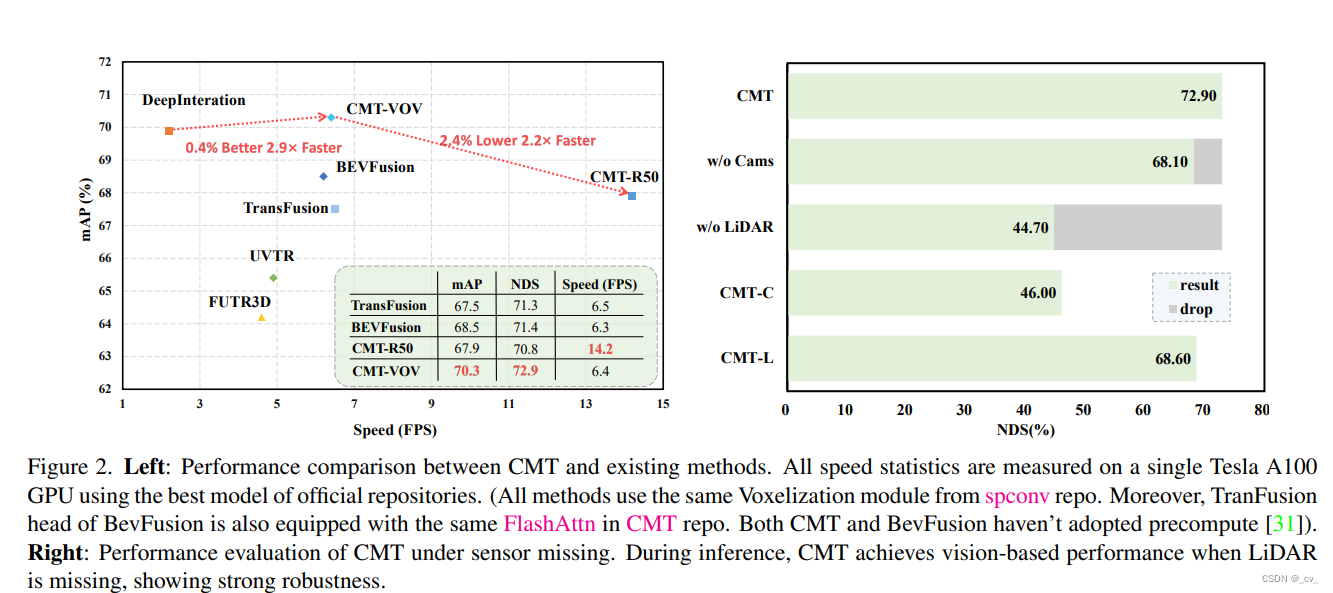
当然算法永远是在进步更新的,新算法往往会更快更强,就比如CMT也是在nuscenes 榜上有名的。既然都说到这里了,那就简单说一下cmt精髓,属实是把位置编码玩明白了。
对于图像,先把pixel左乘内参的逆然后乘外参转到雷达坐标系下,然后用mlp输出其位置编码
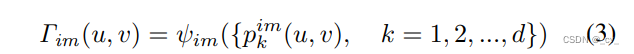
对于雷达则是用voxelnet或者pointpillar编码为点云token后在bev feature gird上沿着高度简单采样,然后也是用Mlp输出其位置编码。
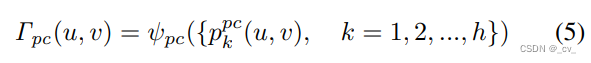
Position-guided Query 则是先随机选点A,A:(ax,i ,ay,i ,az,i)是[0,1]之间随机生成的,然后乘以范围加上最小值转到the region of interest (RoI) of 3D world space.
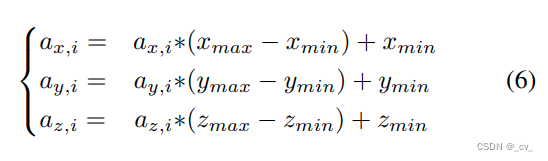
然后把这个坐标投影到图像和雷达模态中获取相应的位置编码,相加得到Q查询
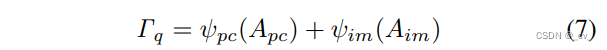
代码如下:这个参考点是可以学习的
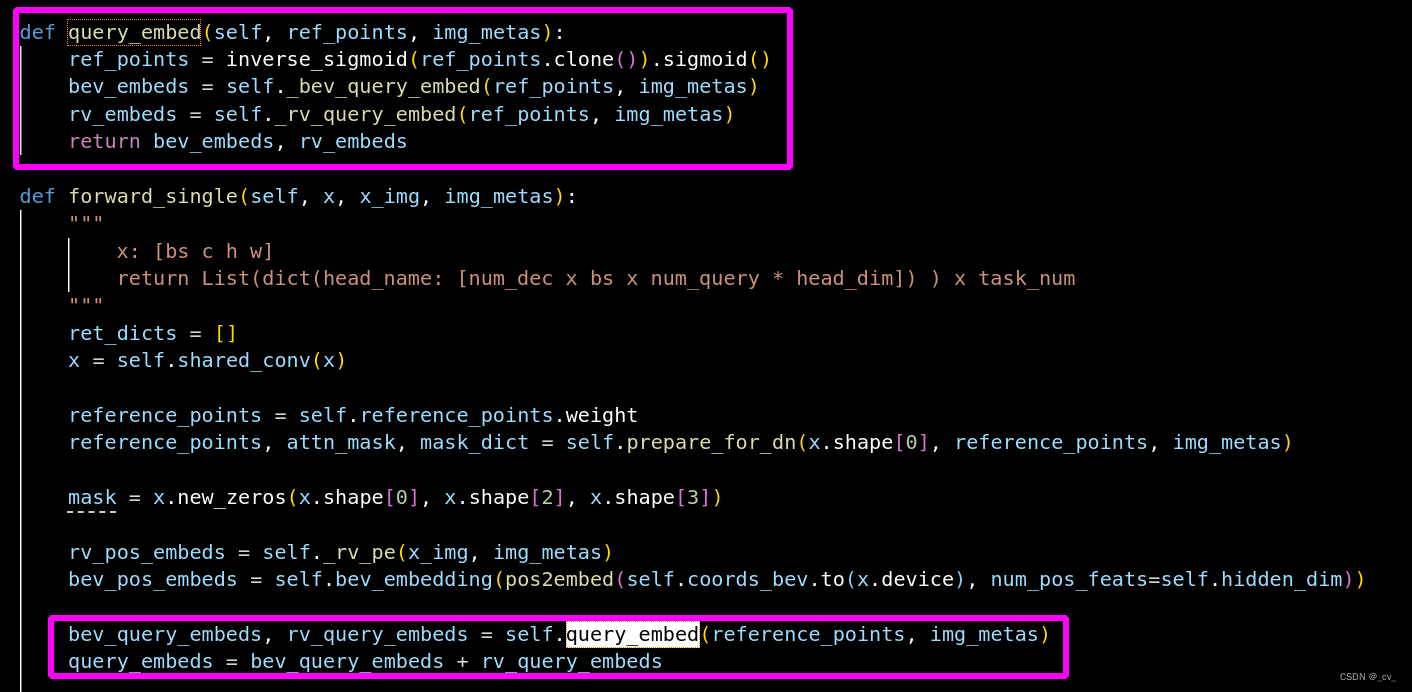
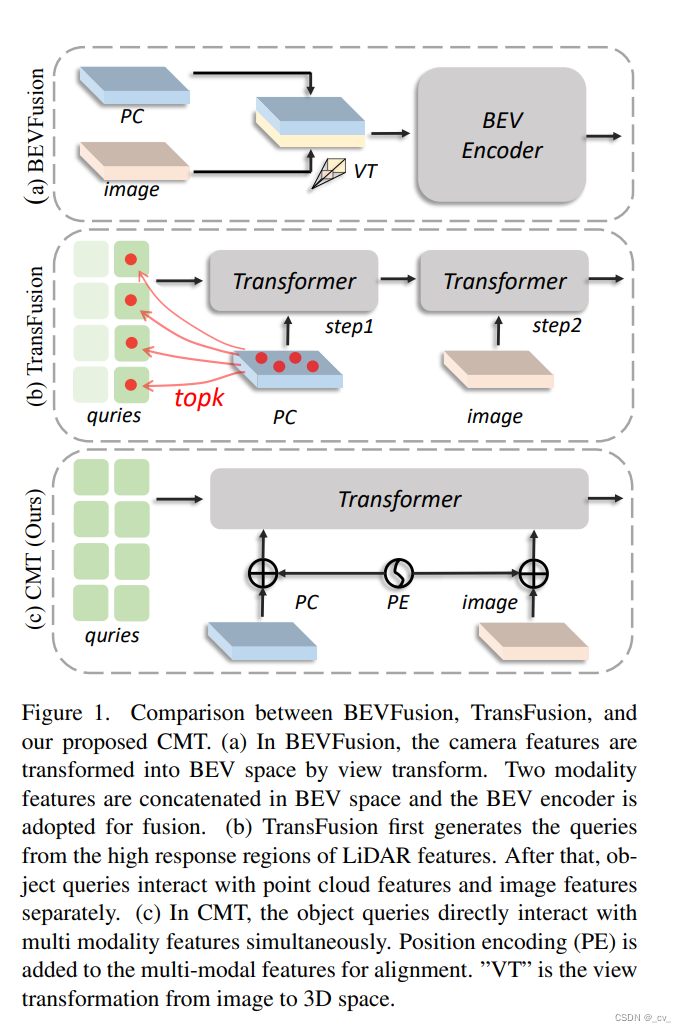
最主要的操作就是这个了。在paper里面也写的很清楚,bevfusion是两个模态转到bev空间后拼接,transfusion先在lidar特征中生成Q取top-k再查图像特征。而CMT则是对象查询直接与多模态特征同时交互,使用位置编码来对齐两个模态。当然也取得了不错的效果。
3.TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers [code]
- 点评:transfusion当然也是一篇不错的工作,而且除检测外还做了跟踪,当时在nuScenes跟踪排行榜上排名第一。一个主要的亮点是,使用了一种软关联机制,可以处理图像质量较差和传感器未配准的情况。这种机制使得模型能够自适应地确定从图像中获取何处和何种信息,从而实现了一种鲁棒且有效的融合策略。简单说就是利用cross-attention建立了激光雷达和图像之间的soft association。翻译一下论文就是:
(Spatially Modulated Cross Attention,SMCA)模块通过在每个查询的投影2D中心周围使用一个2D圆形高斯掩膜来加权交叉注意力。权重掩膜M的生成方式与CenterNet[66]类似,使用了以下公式: M i j = exp ? ( ? ( i ? c x ) 2 + ( j ? c y ) 2 σ r 2 ) M_{ij} = \exp\left(-\frac{(i-cx)^2+(j-cy)^2}{\sigma r^2}\right) Mij?=exp(?σr2(i?cx)2+(j?cy)2?)。其中, ( i , j ) (i, j) (i,j)是权重掩膜M的空间索引, ( c x , c y ) (cx, cy) (cx,cy)是通过将查询预测投影到图像平面上计算得到的2D中心, r r r是3D边界框投影角的最小外接圆的半径, σ \sigma σ是用来调节高斯分布带宽的超参数。然后,这个权重图与所有注意力头之间的交叉注意力图进行元素级的乘法操作。这样,每个对象查询只关注到投影2D框周围的相关区域,使得网络可以更好、更快地学习根据输入的LiDAR特征选择图像特征的位置。
当然他的问题在于如果图像质量极差,例如在照明条件较差的情况下,其性能可能会受到影响。由于使用了Transformer解码器,因此会增加计算复杂度和内存需求。
(不过毕竟是fusion的bev跑实时确实不容易,更不用说之后的占用网格)
从上面对比的一系列表格也可以看出,bev相关的paper还是很多的,大家感兴趣可以随便找一篇相关文章,然后从对比表格中找到一连串同类型文章。此外,这篇博客也只是粗浅的写一些与我相关的见过的部分paper,也只是个开篇,等有空的时候会陆续再更新吧。
Interesting thing
写到这里了就再分享个自己觉得有趣的事情,那就是有一件看似很反直觉的事情,单从fusion bev的三个算法来看cmt明显性能不错,速度也可以,其次是bevfusion,最后是transfusion。但如果去看这三者的github就会发现,最好的cmt其实是受关注最少的,transfusion是fork最多的,bevfusion是star最多的。以下数据截止到2023年12月27日.

- Transfusion 1.4k fork,539 star

- CMT 30 fork,259 star

- bevfusion 322 fork,1.8k star
至于为什么会出现这样的情况,大家可以各抒己见,正所谓三个臭皮匠,赛过诸葛亮。让我想起来当初学社会心理学的时候,也是很有趣了。撤了这么久终于有上万字了,这也算是万字长文章了,哈哈哈。大家有什么想交流的想聊的都欢迎!我其实也有在想要不要也搞一下nlp,后面搞Embodied AI,还在犹豫,不过我觉得都能搞,没什么不能搞得!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!