Spark
2023-12-23 19:37:17
一、Spark 框架概述
1.1 spark是什么
Apache Spark
是用于
大规模数据
(
large-scala data
)处理的
统一(
unified
)分析引擎
。

Spark 借鉴了 MapReduce 思想发展而来,保留了其
分布式并行计算的优点
并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
Spark的适用面非常广泛,所以,被称之为 统一的(适用面广)的分析引擎(数据处理)
1.2 spark VS Hadoop

尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- ?在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- ?Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据 体系的核心架构
Hadoop的基于进程的计算和Spark基于线程方式优缺点?
????????Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于
进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。
比如多个map task读取不同数据源文件需要将数据源加 载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行 单位,但缺点是
线程之间会有资源竞争
。
1.3?Spark四大特点
- 速度快:其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
- 易于使用:支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语
- 通用性强:在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库
- 运行方式:Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark2.3开始支持)上。
1.4?Spark 框架模块

1.5?Spark的运行模式

① local 本地模式(单机)
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境
② standalone 独立集群模式
Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境
③ standalone-HA 高可用模式
生产环境使用
基于 standalone 模式,使用 zk 搭建高可用,避免 Master 是有单点故障的。
④ on yarn 集群模式
Spark中的各个角色
运行在
YARN
的容器内部
,并组成Spark集群环境
生产环境使用
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
⑤ on mesos 集群模式
国内使用较少
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
⑥ on cloud 集群模式
中小公司未来会更多的使用云服务
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon 的 S3。
1.6 架构角色
1.6.1YARN角色回顾
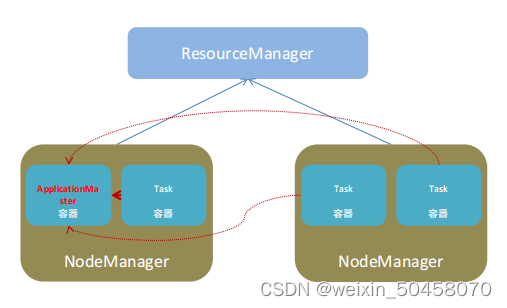
YARN
主要有
4
类角色,从
2
个层面去看:
资源管理层面
?
集群资源管理者(
Master
):
ResourceManager
?
单机资源管理者(
Worker
):
NodeManager
任务计算层面
?
单任务管理者(
Master
):
ApplicationMaster
?
单任务执行者(
Worker
):
Task
(容器内计算框 架的工作角色)
1.6.2 spark运行角色
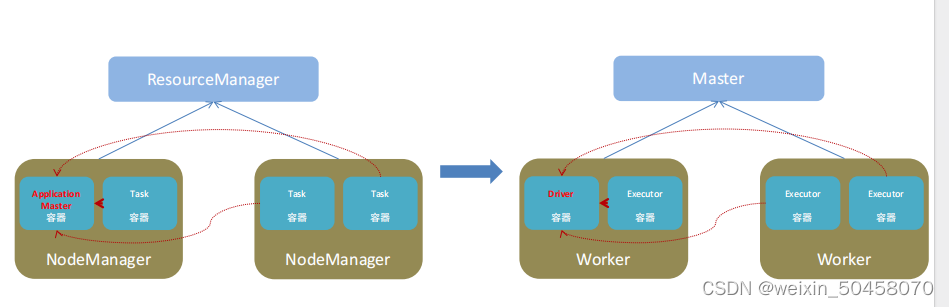
- Master:集群资源管理(类同ResourceManager)
- Worker:单机资源管理(类同NodeManager)
- Driver:单任务管理者(类同ApplicationMaster)
- ?Executor:单任务执行者(类同YARN容器内的Task)
二、Spark环境搭建
2.1 课程服务器环境
本质:启动一个
JVM Process
进程
(
一个进程里面有多个线程
)
,执行任务
Task
- Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或 Local[*]
- 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程该线程有1个core)。 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力.
- 如果是local[*],则代表 Run Spark locally with as many worker threads as?logical cores on your machine.按照Cpu最多的Cores设置线程数
Local 下的角色分布:资源管理:Master:Local进程本身Worker:Local进程本身任务执行:Driver:Local进程本身Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class demo1 {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("MapExample")
.setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建输入RDD
JavaRDD<Integer> inputRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
System.out.println(inputRDD.getNumPartitions());
// 应用map()操作将每个元素加倍
JavaRDD<Integer> outputRDD = inputRDD.map(x -> x * 2);
// 打印输出RDD的内容
List<Integer> outputList = outputRDD.collect();
for (Integer num : outputList) {
System.out.println(num);
}
// 关闭SparkContext
sc.close();
}
}?
12
2
4
6
8
10
文章来源:https://blog.csdn.net/weixin_50458070/article/details/135152141
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!