AI绘画训练一个扩散模型-上集
介绍
AI绘画,其中最常见方案基于扩散模型,Stable Diffusion 在此基础上,增加了 VAE 模块和 CLIP 模块,本文搞了一个测试Demo,分为上下两集,第一集是denoising_diffusion_pytorch ,第二集是diffusers。
对于专业的算法同学而言,我更推荐使用 diffusers 来训练。原因是 diffusers 工具包在实际的 AI 绘画项目中用得更多,并且也更易于我们修改代码逻辑,实现定制化功能。
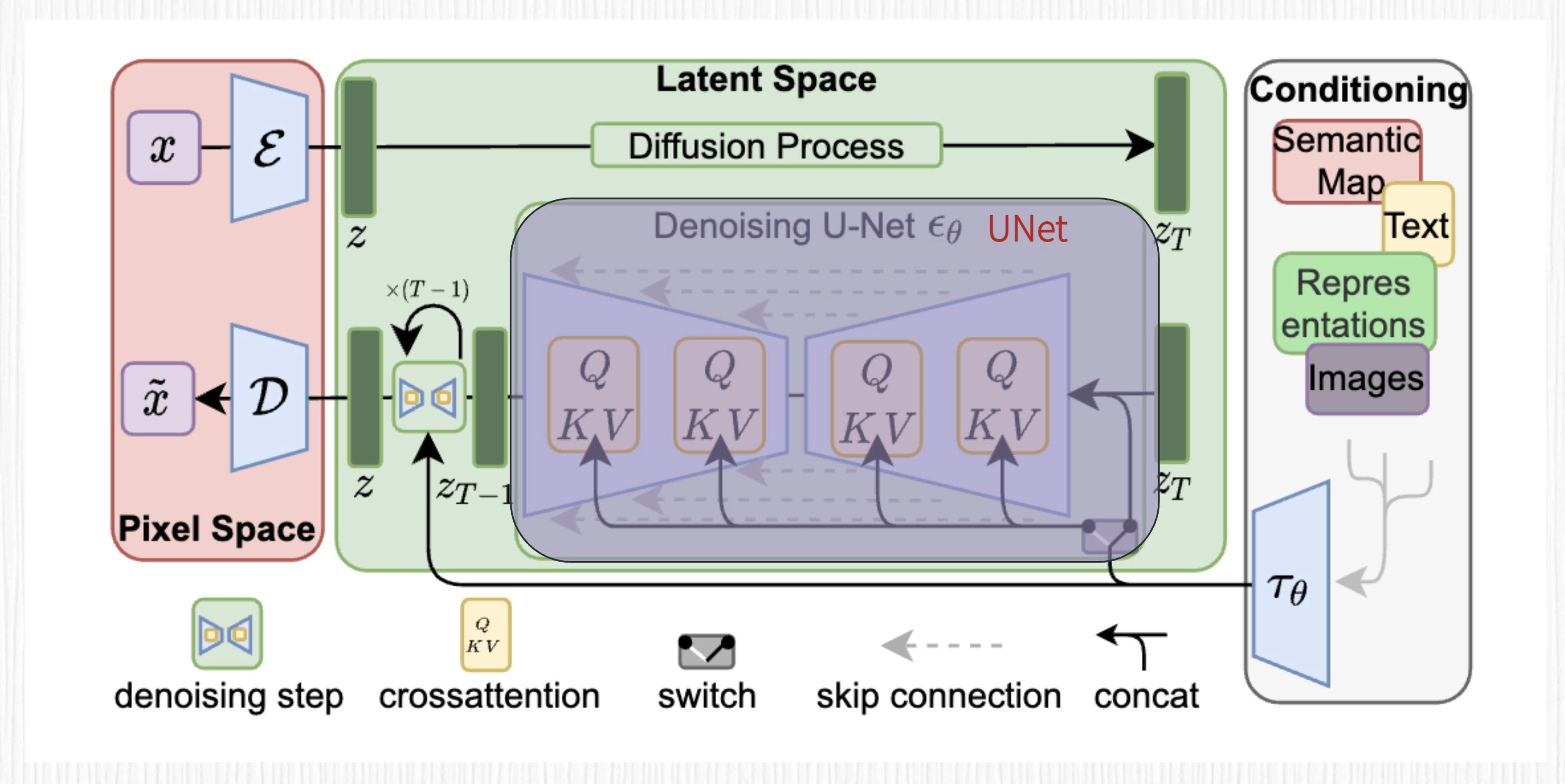
基础模块
- 创建UNet模型和高斯扩散模型(Gaussian Diffusion)。
UNet是一个编码器-解码器结构的全卷积神经网络。Gaussian Diffusion用于定义噪声过程和损失函数。
-
将模型加载到GPU上(如果有GPU)。
-
使用随机初始化的图片进行一次训练,计算损失并反向传播。
这一步的目的是对模型进行一次预热,更新权重。
- 使用diffusion模型采样生成图片。
这里采样1000步,也就是将噪声逐步减少,每步用UNet预测下一步的图像,最终输出生成的图片。
-
如果图片在GPU上,将其移回到CPU。
-
可视化第一张生成图片。
plt.imshow显示图片。
这样通过DDPM框架,可以从随机噪声生成符合数据分布的新图片。每次训练会使模型逐步逼近真实数据分布,从而产生更高质量的图片。
# 创建UNet和扩散模型
from denoising_diffusion_pytorch import Unet, GaussianDiffusion
import torch
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000 # number of steps
).cuda()
# 使用随机初始化的图片进行一次训练
training_images = torch.randn(8, 3, 128, 128)
loss = diffusion(training_images.cuda())
loss.backward()
# 采样1000步生成一张图片
sampled_images = diffusion.sample(batch_size = 4)
import torch
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
import torchvision.transforms as transforms
# 如果张量在 GPU上,需要移动到 CPU上
if sampled_images.is_cuda:
sampled_images = sampled_images.cpu()
# 检查我们生成的一张图
img = sampled_images[0].clone().detach().permute(1, 2, 0)
plt.imshow(img)
数据集
-
导入所需的库:PIL、io、datasets等。
-
使用datasets库中的load_dataset方法加载Oxford Flowers数据集。
-
创建一个目录来保存图片。
-
遍历数据集的训练、验证、测试split,逐个图像获取图片bytes数据,并保存为PNG格式图片。
-
使用PIL库的Image对象将bytes数据加载并保存为图片文件。
-
使用tqdm显示循环进度。
# 数据集下载
from PIL import Image
from io import BytesIO
from datasets import load_dataset
import os
from tqdm import tqdm
dataset = load_dataset("nelorth/oxford-flowers")
# 创建一个用于保存图片的文件夹
images_dir = "./oxford-datasets/raw-images"
os.makedirs(images_dir, exist_ok=True)
# 遍历所有图片并保存,针对oxford-flowers,整个过程要持续15分钟左右
for split in dataset.keys():
for index, item in enumerate(tqdm(dataset[split])):
image = item['image']
image.save(os.path.join(images_dir, f"{split}_image_{index}.png"))
模型训练
-
定义Unet模型架构和Gaussian Diffusion过程。
-
加载数据,指定训练参数:
- 训练总步数20000
- batch size 16
- 学习率2e-5
- 梯度累积步数2
- EMA指数衰减参数0.995
- 使用混合精度训练
- 每2000步保存一次模型
- 创建Trainer进行模型训练。Trainer封装了训练循环逻辑。
-
调用trainer.train()进行训练。
# 模型训练
import torch
from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000 # 加噪总步数
).cuda()
trainer = Trainer(
diffusion,
'./oxford-datasets/raw-images',
train_batch_size = 16,
train_lr = 2e-5,
train_num_steps = 20000, # 总共训练20000步
gradient_accumulate_every = 2, # 梯度累积步数
ema_decay = 0.995, # 指数滑动平均decay参数
amp = True, # 使用混合精度训练加速
calculate_fid = False, # 我们关闭FID评测指标计算(比较耗时)。FID用于评测生成质量。
save_and_sample_every = 2000 # 每隔2000步保存一次模型
)
trainer.train()
# 你可以等待上面的模型训练完成后,查看生成结果
from glob import glob
result_images = glob(r"./results/*.png")
print(result_images)
# 可视化图像看看
from PIL import Image
img = Image.open("./results/sample-1.png")
img
测试
https://colab.research.google.com/github/NightWalker888/ai_painting_journey/blob/main/lesson12/train_diffusion_v2.ipynb#scrollTo=8BVjfBPI93Ar
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!