广义零样本学习综述的笔记
1 Title
????????A Review of Generalized Zero-Shot Learning Methods(Farhad Pourpanah; Moloud Abdar; Yuxuan Luo; Xinlei Zhou; Ran Wang; Chee Peng Lim)【IEEE Transactions on Pattern Analysis and Machine Intelligence 2022】
2 conclusion
????????Generalized zero-shot learning (GZSL) aims to train a model for classifying data samples under the condition that some output classes are unknown during supervised learning. GZSL leverages semantic information of the seen (source) and unseen (target) classes to bridge the gap between both seen and unseen classes.
????????This paper?introduce a hierarchical categorization for the GZSL methods and discuss the representative methods in each category. In addition, it discuss the available benchmark data sets and applications of GZSL, along with a discussion on the research gaps and directions for future investigations.
3 Good Sentences
? ? ? ? 1、ZSL aims to train a model that can classify objects of unseen classes (target domain) via transferring knowledge obtained from other seen classes (source domain) with the help of semantic information and the semantic information embeds the names of both seen and unseen classes in high-dimensional vectors.?(The principle of ZSL and semantic information)
? ? ? ? 2、In conventional ZSL techniques, the test set only contains samples from the unseen classes, which is an unrealistic setting and it does not reflect the real-world recognition conditions. In practice, data samples of the seen classes are more common than those from the unseen ones, and it is important to recognize samples from both classes simultaneously rather than classifying only data samples of the unseen classes. This setting is called generalized zero-shot learning (GZSL) (The shortcoming of ZSL and the difference between ZSL and GZSL)
????????这篇论文仅回顾了从 2016 年流行到 2021 年初与 GZSL 相关的已发表文章、会议论文、书籍章节和高质量预印本(即 arXiv),最近两年的没有。
1 介绍
????????标准深度学习模型只能识别属于在训练阶段见过的类的样本,无法处理未见过的类的样本。而在现实世界中,给大量数据集手动标注标签工作量大(而且大部分需要专业知识),或者直接没有大量数据(濒危动物),还有在训练阶段不存在而在测试阶段存在的类(比如变异的新冠病毒)零样本学习技术(ZSL)为应对这种情况提供了一个很好的解决方案。
????????ZSL 旨在训练一个模型,该模型可以通过借助语义信息传递从已知类(源域)获得的知识来对未知类(目标域)的对象进行分类,(比如训练阶段给出熊猫的黑白,栗毛马的外形就就能在测试阶段分类出斑马,而斑马不在训练阶段出现过。)
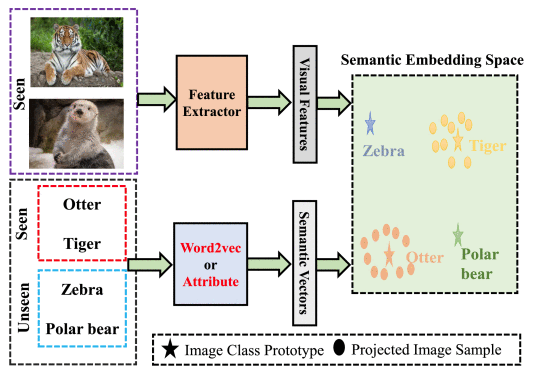
????????语义信息可以是手动定义的属性向量?、自动提取的词向量?、基于上下文的嵌入或它们的组合,语义信息会把将已知类和未知类的名称嵌入高维向量中去。
????????在传统的 ZSL 技术中,测试集仅包含来自未知类的样本,这不切实际,它不能反映现实世界的识别条件。在实践中,已知类的数据样本比未知类的数据样本更常见,因此同时识别这两个类别的样本而不是仅对未知类别的数据样本进行分类非常重要。这种设置称为广义零样本学习(GZSL)

2 广义零样本学习概述? ? ? ??
? ? ? ? 令![]() 和
和![]() 分别表示已知类和未知类的数据集。其中
分别表示已知类和未知类的数据集。其中![]() 表示特征空间X中的D维图像(视觉特征),在X中使用预训练的深度学习模型,比如VGG19,RetNet。
表示特征空间X中的D维图像(视觉特征),在X中使用预训练的深度学习模型,比如VGG19,RetNet。![]() 则表示语义空间A中的K维语义表示,
则表示语义空间A中的K维语义表示,![]() 和
和![]() 表示标签空间Y中已知类和未知类的标签集,
表示标签空间Y中已知类和未知类的标签集,和
分别表示已知类和未知类的不同类的种类数量。
![]() ,
,![]() 。
。
在GZSL中,目标是训练出一个模型,![]() 能对
能对个测试样例分类,
![]()
![]()
GZSL方法的训练阶段可以分为两大类设置:归纳(inductive)学习和转导(transductive)学习
? ? ? ? 归纳学习:仅利用已知类的视觉特征和语义信息来构建模型
? ? ? ? 转导学习:除了已知类信息外,还利用未知类的语义表示和未标记的视觉特征进行学习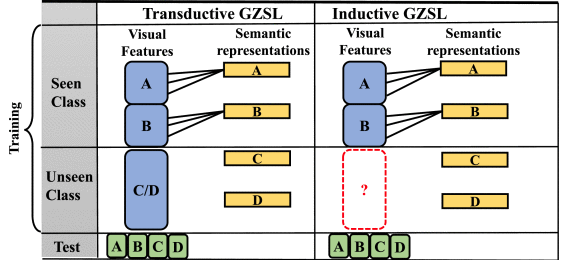
在归纳设置中,只有已知类的视觉特征和语义表示(?A?和?B?)可用。在转导设置中,除了已知类信息之外,还可以访问未知类的未标记视觉样本。但是假设所有未知类的未标记数据都可用是不切实际的,所以转导学习并不是很实用。
语义信息???????
????????语义信息是GZSL的关键。由于不存在来自未知类的标记样本,所以通常使用语义信息来建立已知类和未知类之间的关系,这样广义零样本学习才能成为可能。语义信息必须包含所有未知类的识别属性,以保证为每个未知类提供足够的语义信息。它还应该与特征空间中的样本相关,以保证可用性。也就是说,在语义空间中,必须包括已知类和未知类的所有语义信息。举个例子,如果未知类里有斑马,那么语义信息就必须包括“黑白花纹”、“马”等信息。
???????? ? ? ? 在这个语义空间中,可以执行ZSL和GZSL,语义信息可以分为手动定义的属性、词向量和它们的组合。
手动定义的属性:包含高级语义信息,使得GZSL能识别所有类,属性准确,但需要人工标注,不适合大规模问题
词向量:从大型文本语料库(例如维基百科)中自动提取,用于表示各种单词之间的异同并描述每个对象的属性,人力需求较小。适用于大规模数据集,但是包含噪声,对模型有损害。
嵌入空间
?????????????????????大多数 GZSL 方法都会学习嵌入/映射函数,以将已知类的低级视觉特征与其相应的语义向量相关联。然后,通过测量嵌入空间中数据样本的原始表示和预测表示之间的相似度,使用学习到的函数来识别新类别。由于属性向量的每个条目都代表该类的描述,所以具有相似描述的类在语义空间中被希望包含相似的属性向量。
????????然而,在视觉空间中,具有相似属性的类可能有很大的差异。因此,找到合适的嵌入空间是一项具有挑战性的任务,否则会导致视觉语义歧义问题。
? ? ? ? 从类别来说,嵌入空间可以分为欧几里德空间或非欧几里德空间。虽然欧几里得空间更简单,但它容易丢失信息。非欧空间通常基于图网络、流形学习或聚类,通常利用空间之间的几何关系来保存数据样本之间的关系,从内容来说,嵌入空间可以分为:语义嵌入、视觉嵌入和潜在空间嵌入。
语义嵌入:
????????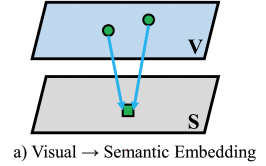
语义嵌入使用不同的约束或损失函数学习从视觉空间到语义空间的(前向)投影函数,并在语义空间中执行分类。语义嵌入的目的是强制语义嵌入属于一个类的所有图像都将映射到一些ground-truth的标签嵌入,语义嵌入获得最佳投影函数后,就可以通过执行最近邻搜索来识别给定的测试图像。
视觉嵌入:

视觉嵌入学习一个(反向)投影函数将语义表示(向后)映射到视觉空间,并在视觉空间中执行分类。目标是使语义表示接近其对应的视觉特征?。在获得最佳投影函数后,可以使用最近邻搜索来识别给定的测试图像。
潜在空间嵌入:

潜在空间嵌入将视觉特征和语义表示投影到公共空间L中,L即潜在空间,以探索不同模态的一些共同语义属性。其目标是将附近每个类的视觉和语义特征投射到潜在空间中。理想的潜在空间应该满足两个条件: (i) 类内紧凑,以及 (ii) 类间分离
具有挑战性的问题
???????????????在GZSL中,必须解决几个具有挑战性的问题,包括枢纽点问题(hubness problem)【在高维空间中,一部分测试集的类别可能会成为很多数据点的K近邻(KNN),但其类别之间却没什么关系】,映射域迁移问题(projection domain shift problem)【模型使用了已知类样本学习由样例特征空间到类标签语义空间的映射,由于没有测试类的未知类样例可以用于训练,因此,在映射输入样例的时候,就会产生一定的偏差】这个问题在 GZSL 中更严重,因为训练过程中GZSL就有已知类和未知类,在测试阶段,模型会更倾向于将样例分类为已知类中的类而不是未知类的类。
???????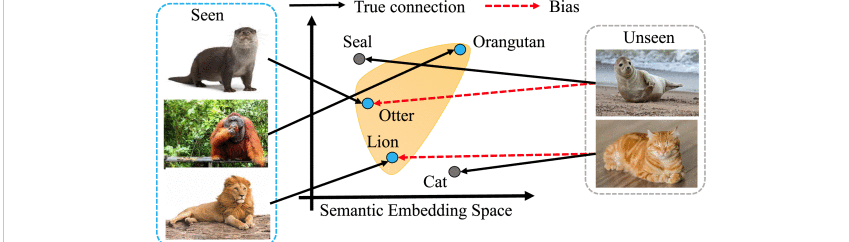
为了缓解这个问题,已经提出了几种策略,例如temperature scaling(温度标控)
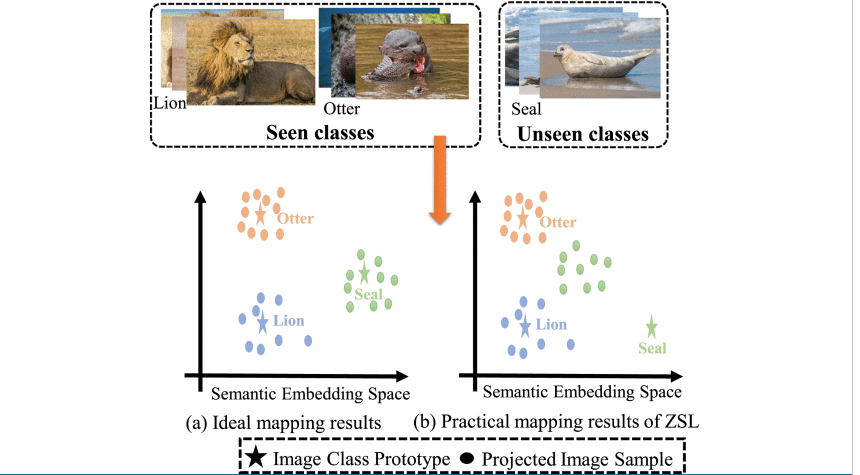 上图显示了一个理想的无偏映射函数,该函数强制已知和未知类的投影视觉样本在潜在空间中围绕它们自己的语义特征。在实践中,GZSL任务中的训练样本和测试样本是不相交的。这导致仅用已知类数据学习的无偏映射函数可能会将未知类的视觉特征投射到远离其语义特征的地方
上图显示了一个理想的无偏映射函数,该函数强制已知和未知类的投影视觉样本在潜在空间中围绕它们自己的语义特征。在实践中,GZSL任务中的训练样本和测试样本是不相交的。这导致仅用已知类数据学习的无偏映射函数可能会将未知类的视觉特征投射到远离其语义特征的地方
3.GZSL方法综述
? ? ? ? GZSL必须解决两个关键问题:(i)如何将知识从已知类转移到未知类(ii) 如何学习一个模型来识别来自已知类和未知类的图像,而无需访问未知类的样本。
???????? ? ? ? 目前已经提出了许多方法,大致可分为:
- ???????基于嵌入的方法:学习嵌入空间,将已知类的低级视觉特征与其对应的语义向量相关联。学习到的投影函数用于通过测量嵌入空间中数据样本的原始表示和预测表示之间的相似性水平来识别新类
??????????????
- 基于生成的方法:学习一个模型,根据已知类的样本和两个类的语义表示,为未知类生成图像或视觉特征。通过为未知类生成样本,GZSL问题可以转换为传统的监督学习问题。基于单一的同质过程,可以训练模型对属于已知类和未知类的测试样本进行分类,并解决偏差问题。


? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? GZSL方法及其子类对应的方法
因为我是为了之前那篇3D点云数据上的GZSL对比循环网络才看这篇综述的,所以我只关心基于生成的GAN方法,其他的不写了。
???????基于生成的方法:生成对抗网络:
????????GANs通过使用类条件密度![]() 和类先验概率???????
和类先验概率???????![]() 计算样本的联合分布
计算样本的联合分布![]() 来生成新的数据样本。GAN由一个生成器
来生成新的数据样本。GAN由一个生成器![]() 一个判别器
一个判别器![]() ???????组成。其中,生成器用语义属性
???????组成。其中,生成器用语义属性![]() 和随机均匀噪声或者高斯噪声
和随机均匀噪声或者高斯噪声![]() 来生成视觉特征。判别器区分真实视觉特征和生成的视觉特征
来生成视觉特征。判别器区分真实视觉特征和生成的视觉特征![]() 。
。
????????当生成器学习 以已知类的语义表示![]() 为条件合成的数据样本???????后,它可以通过未知类的语义表示
为条件合成的数据样本???????后,它可以通过未知类的语义表示![]() 来生成数据样本???????。然而,GAN有个常见问题:模式坍缩【生成的样本中出现一模一样的样例】这是因为GAN中没有明确的损失。
来生成数据样本???????。然而,GAN有个常见问题:模式坍缩【生成的样本中出现一模一样的样例】这是因为GAN中没有明确的损失。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!