探秘AI赋能的未来世界:CyberAI深度学习技术助力变革
CyberAI平台概述
随着AI技术的极速发展,AI能力正在助力产业加速场景化落地。CyberAI是数新网络面向开发者和企业的一站式AI数据科学平台,提供交互式和可视化建模服务,算法模型全生命周期管理。平台可帮助开发者快速开发AI应用,解决本地代码维护不方便、数据传输不安全、模型部署工程难等现实问题,从而提升团队协同效率,以信息化的手段引领技术创新,为客户提供全方位AI管理服务。
CyberAI的突出特点
·?具备一站式机器学习平台能力
·?100+可视化建模算子支持无代码机器学习
·?支持多种数据处理支持模型部署
·?20+多数据源接入
·?支持主流深度学习框架
CyberAI构建高效准确模型的强大算子
CyberAI是一种创新的深度学习平台,提供了多种强大的算子用于构建高效、准确的模型。其中包括DNN的二分类和多分类、回归,以及CNN和LSTM等。DNN适用于各种任务,能学习输入数据的复杂特征,并输出概率值;CNN专注于图像和视频数据处理,通过卷积和池化提取特征;LSTM则用于序列数据处理,能更好地捕捉长期依赖关系。通过合适的算子选择和优化方法,CyberAI可以实现准确、高效的模型训练和预测。下面将一一介绍:
DNN - 二分类??
简介:
DNN是一种多层神经网络模型,适用于解决二分类问题。通过学习非线性特征,DNN可以对输入样本进行预测,并根据输出结果进行分类。合理设置模型的架构和超参数,以及进行适当的训练和调优,可以提高DNN在二分类任务上的性能。在二分类问题中,DNN的输出层通常使用Sigmoid激活函数,将输出值限定在0到1之间,表示样本属于某个类别的概率。当输出值大于阈值时,可以将样本归为一类;当输出值小于阈值时,可以将样本归为另一类。
举例说明:
假设你想要建立一个猫和狗的图像分类器,即输入一张图片,判断该图片是属于猫还是狗。准备一批带有标签(猫或狗)的图像作为训练数据,每个图像都有相应的标签。然后构建DNN模型进行训练,通过不断优化模型的结构、调整超参数和增加数据量,你可以提高DNN模型在猫狗分类问题上的性能,使其能够准确地将输入图像划分为猫或狗。
代码实现:
import numpy as npimport matplotlib.pyplot as pltfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense
# 创建虚拟数据
X = np.random.rand(100, 1) # 输入特征 (100个样本,1个特征)
y = np.random.randint(0, 2, 100) # 标签(随机生成的0和1)
# 构建模型
model = Sequential([
Dense(64, activation='relu', input_shape=(1,)),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
history = model.fit(X, y, epochs=10, verbose=0)
# 可视化训练过程
plt.plot(history.history['loss'])
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()代码结果:
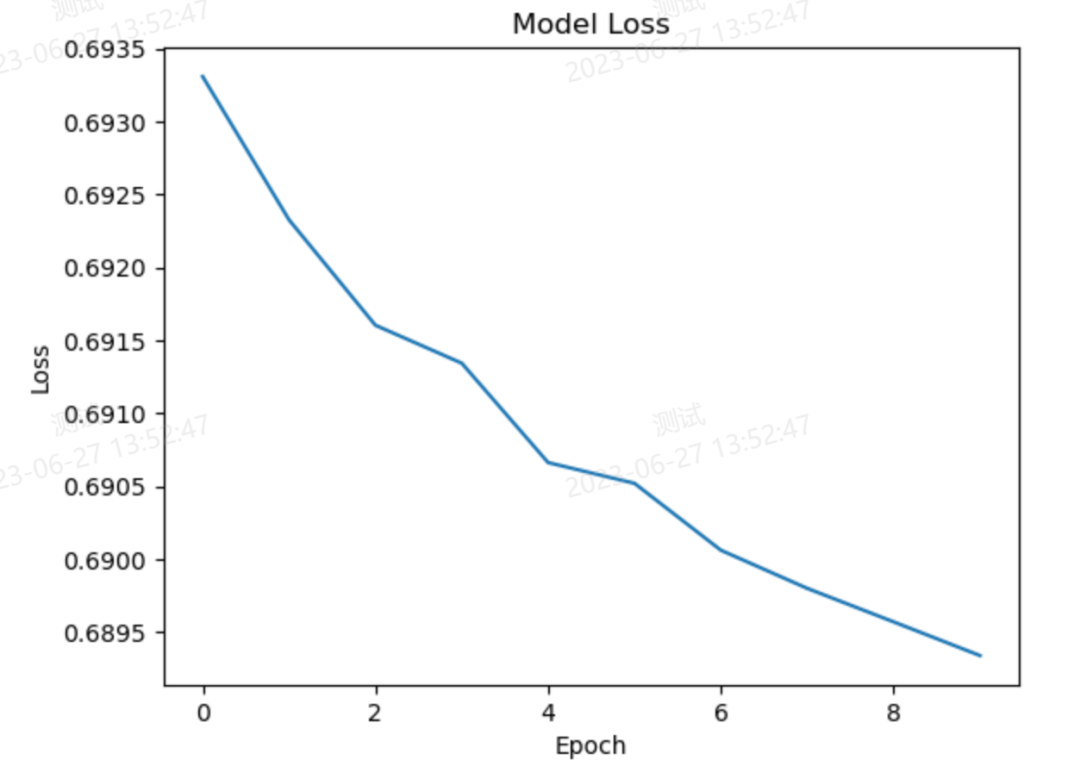
CyberAI系统训练图
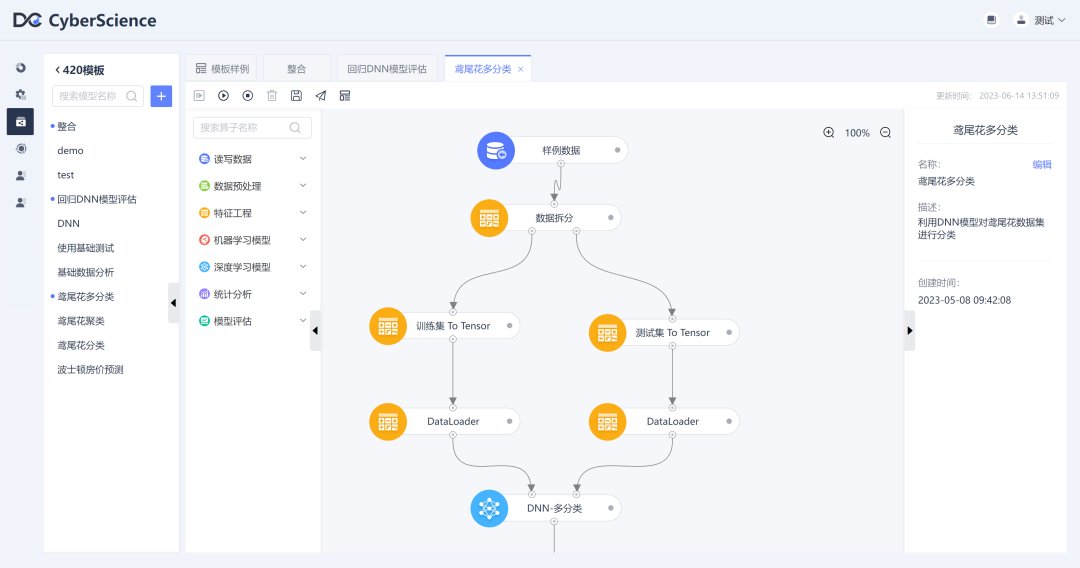
DNN - 多分类?? ?
简介:
对于多分类任务,DNN通常使用Softmax函数作为输出层的激活函数。Softmax函数能够将输出转化为表示各个类别概率的向量。具体地,Softmax函数会对输出进行指数化处理,并归一化为一个概率分布,使得各个类别的概率之和为1。模型将根据这些概率来进行分类预测,选择概率最大的类别作为最终的分类结果。? ? ? ? ?
在训练DNN时,通常使用交叉熵损失函数(Cross-Entropy Loss)来度量模型的预测和真实标签之间的差异。通过最小化交叉熵损失,模型可以调整权重和偏置,以提高对不同类别的分类能力。? ? ? ? ?
为了提高DNN的性能和避免过拟合,还可以使用一些常见的技术,例如正则化、批归一化、dropout等。此外,调整DNN的网络结构、激活函数、优化算法和超参数等也是提高模型性能的重要策略。
举例说明:
假设我们有一堆动物的图像数据集,其中包括猫、狗和鸟三类。我们想要训练一个DNN模型来自动识别这些动物的照片属于哪个类别。首先,我们将准备好带有标签的图像数据,标签表示图像所属的类别(比如0代表猫,1代表狗,2代表鸟)。然后,我们设计一个DNN模型,该模型由多个隐藏层组成,每个隐藏层包含多个神经元。在训练过程中,我们将图像数据输入到DNN中进行前向传播。DNN的隐藏层将会逐渐提取出图像的特征,从低级特征(例如图像的边缘)到高级特征(例如图像的形状和纹理)。最后一个隐藏层的输出将连接到一个具有三个节点的输出层,分别代表猫、狗和鸟三个类别。
? ? ? ? ?
为了使输出层能够给出每个类别的概率,我们使用了Softmax函数作为输出层的激活函数。Softmax函数将输出转化为概率分布,例如对于一张照片,它可能给出[0.7, 0.2, 0.1]的概率分布,表示该照片有70%的可能性是猫,20%的可能性是狗,10%的可能性是鸟。? ? ? ? ?接下来,我们使用交叉熵损失函数来计算模型的预测和真实标签之间的差异。通过最小化交叉熵损失,我们可以调整DNN的权重和偏置,使得模型能够更好地对不同类别进行分类。
? ? ? ? ?
最后,在训练完成后,我们就可以使用这个经过训练的DNN模型来预测新的动物照片的类别了。例如,如果我们输入一张新的猫的照片,模型可能会给出[0.9, 0.05, 0.05]的概率分布,表示该照片有90%的可能性是猫,5%的可能性是狗,5%的可能性是鸟。
? ? ? ? ?
通过这种方式,DNN多分类模型可以帮助我们自动识别照片中的动物类别,从而实现了图像分类的任务。?? ?
代码实现:
import matplotlib.pyplot as plt
# 训练过程中的准确率和损失值数据
accuracy = [0.6, 0.7, 0.75, 0.8, 0.85]
loss = [1.2, 1.0, 0.8, 0.6, 0.4]
# 创建一个新的图形
plt.figure()
# 绘制准确率曲线
plt.plot(range(1, len(accuracy)+1), accuracy, label='Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training Accuracy')
plt.legend()
# 创建一个新的图形
plt.figure()
# 绘制损失值曲线
plt.plot(range(1, len(loss)+1), loss, label='Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.legend()
# 展示图形
plt.show()执行结果:??
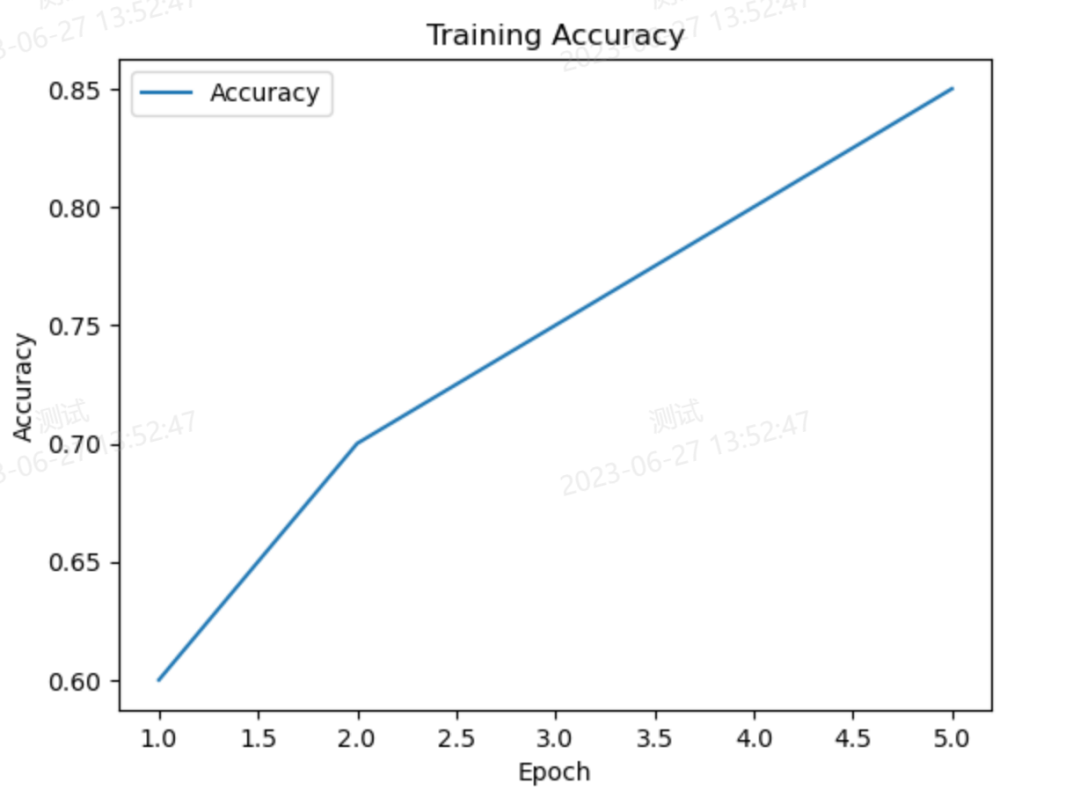
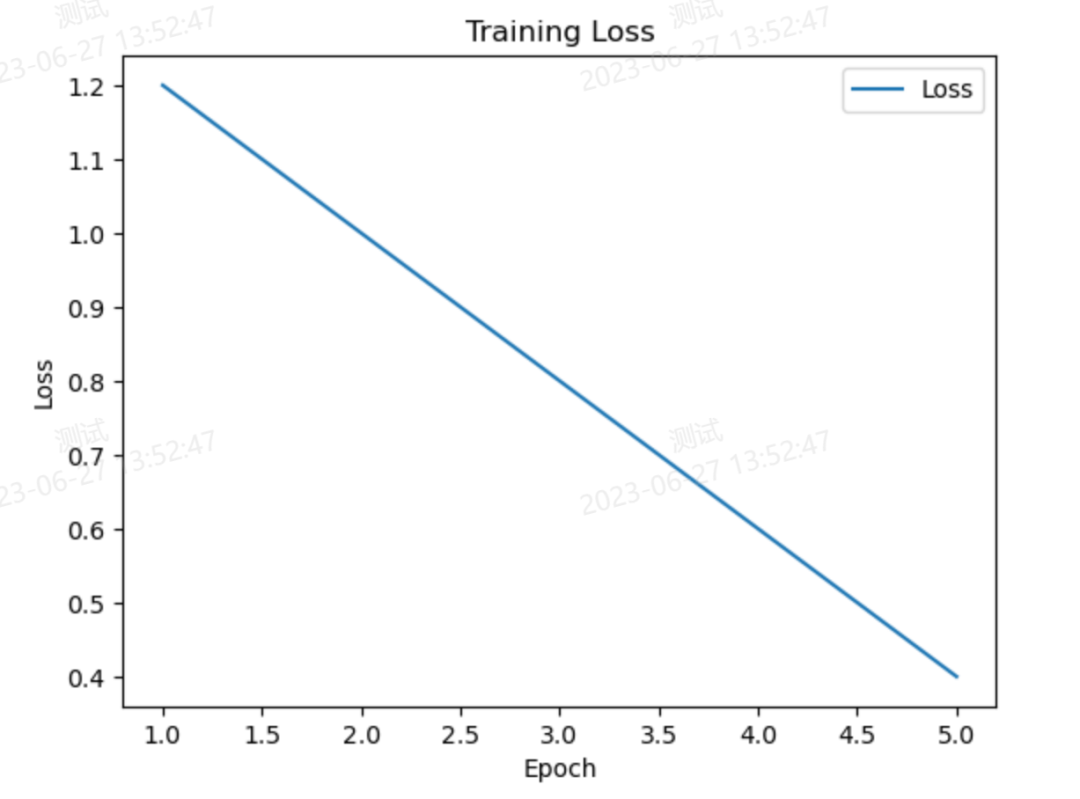
CyberAI系统训练图:??
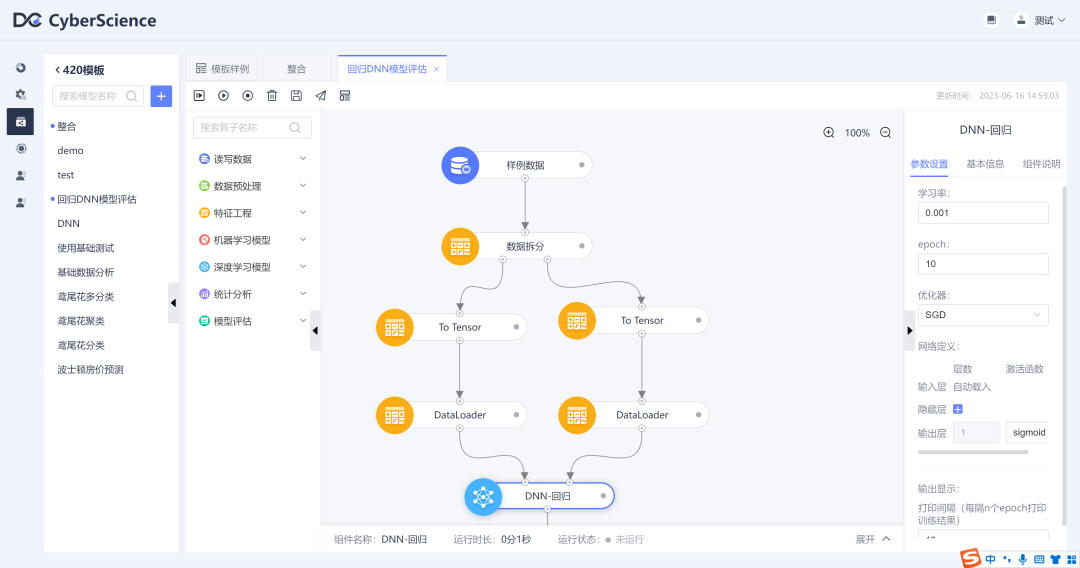
DNN - 回归??
简介:
DNN回归基于深度神经网络模型,它由多个隐藏层组成,每个隐藏层包含多个神经元。与分类任务不同,回归任务的输出是一个连续值,因此通常使用线性激活函数或者无激活函数的输出层。DNN回归具有较强的非线性建模能力,可以处理复杂的数据关系。它适用于各种领域的回归问题,如预测房价、股票价格、销售额等连续值预测任务。然而,模型的选择、超参数调整和足够的训练数据等因素仍然需要仔细考虑,以获得良好的回归性能。
举例说明:
房价预测。我们可以假设有一份数据集,其中包含了各个房屋的特征信息(如面积、卧室数量、地理位置等)以及相应的房价。?
首先,我们收集到了一定数量的带有标签的训练数据,每个数据包含输入特征(如房屋的面积和卧室数量等)和对应的输出值(即房价)。我们的目标是通过已知的特征预测未知房屋的价格。
然后,我们设计一个DNN模型来进行回归预测。这个模型可以由多个隐藏层组成,每个隐藏层都包括多个神经元。我们可以选择使用全连接层并配置每个层的神经元数量和激活函数。
接下来,我们选择适合回归问题的损失函数,常见的选择是均方误差(Mean Squared Error,MSE)。这个损失函数将衡量模型的预测值与真实房价之间的差距。? ? ? ?
然后,我们使用训练数据集对DNN模型进行训练。通过反向传播算法,根据损失函数的梯度来更新模型中的权重和偏置参数,不断优化模型的性能。在训练过程中,模型会学习到输入特征与房价之间的复杂关系。一旦训练完成,我们可以使用这个训练好的模型对新的未知房屋的特征进行预测,并得到一个回归输出结果,即预测的房价。
最后,我们可以通过评估指标(如均方根误差)来评估模型在新数据上的性能。如果模型的预测结果与真实房价相匹配,那么我们可以说这个DNN回归模型在房价预测任务上具有较好的性能。?? ?
代码实现:
# 构建模型
model = Sequential()
model.add(Dense(32, activation='relu', input_shape=(2,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='linear'))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X_train, y_train, batch_size=1, epochs=50, verbose=0)
# 模型评估
loss = model.evaluate(X_test, y_test, verbose=0)print('测试集损失:', loss)
# 使用模型进行预测
new_data = np.array([[1400, 3], [2200, 4], [1300, 2]])
new_data_scaled = scaler.transform(new_data)
predictions = model.predict(new_data_scaled)print('预测的房价:', predictions.flatten())?
执行结果:

CyberAI系统训练图:
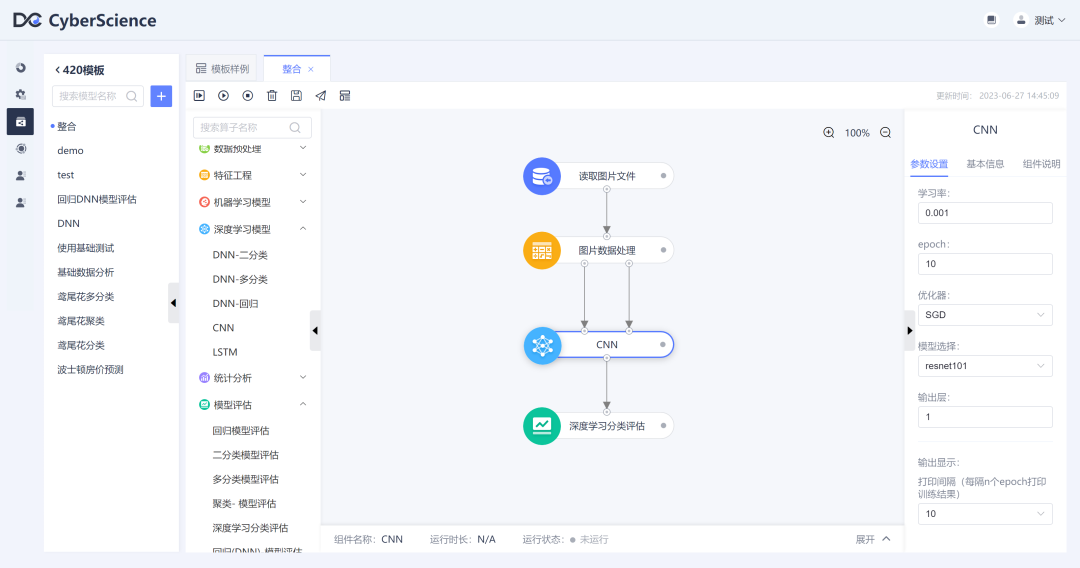
CNN??
简介:
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,主要用于处理具有网格结构的数据,例如图像、语音和文本等。CNN 在计算机视觉领域取得了巨大成功,广泛应用于图像分类、目标检测、图像生成等任务。CNN 在训练过程中通常使用反向传播算法进行优化,通过最小化损失函数来调整网络权重,以使网络能够更好地拟合训练数据。此外,还可以采用正则化、批归一化、dropout 等技术来提高模型的泛化能力和防止过拟合。?? ?
举例说明:
假设你是一名植物学家,你想要建立一个模型来识别不同种类的花朵。你决定使用CNN来完成这个任务。?
下面是CNN在花朵识别中的工作方式:? ? ? ? ?
数据准备:首先,你需要收集包含不同种类花朵的图像数据集。每张图像都会有一个对应的标签,表示图像所属的花朵种类。? ? ? ? ?
卷积层:你将图像输入到CNN的卷积层中。卷积层会通过滑动卷积核的方式来提取图像中的特征,例如花朵的形状、颜色以及纹理等。? ? ? ? ?
激活函数:卷积层的输出会经过激活函数进行非线性变换。激活函数可以增加模型的表达能力,并引入非线性特征,使得模型能够更好地区分不同种类的花朵。? ? ? ? ?
池化层:接下来,池化层会减小特征图的空间尺寸,同时保留最显著的特征。它可以帮助减少参数数量,并提高模型的计算效率。? ? ? ? ?
全连接层:在池化层之后,特征图会被展平,并输入到全连接层中。全连接层的神经元与前面提取的特征相连,通过权重的组合来确定花朵的种类。? ? ? ? ?
输出层:最后,CNN会将全连接层的输出传递到输出层。输出层的神经元数量与花朵的种类数量相对应。通常使用softmax激活函数来计算每个类别的概率分布,确定花朵属于哪个类别的概率最高。
通过训练这个CNN模型,并使用大量的花朵图像进行学习,模型可以学会从图像中提取花朵的特征,并正确地识别不同种类的花朵。?? ?
代码实现:
from keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 构造CNN模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3))) # 卷积层
model.add(MaxPooling2D((2, 2))) # 池化层
model.add(Conv2D(64, (3, 3), activation='relu')) # 卷积层
model.add(MaxPooling2D((2, 2))) # 池化层
model.add(Conv2D(128, (3, 3), activation='relu')) # 卷积层
model.add(MaxPooling2D((2, 2))) # 池化层
model.add(Flatten()) # 展平层
model.add(Dense(128, activation='relu')) # 全连接层
model.add(Dense(5, activation='softmax')) # 输出层,假设有5个类别
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 打印模型概述
model.summary()执行结果:

CyberAI系统训练图:
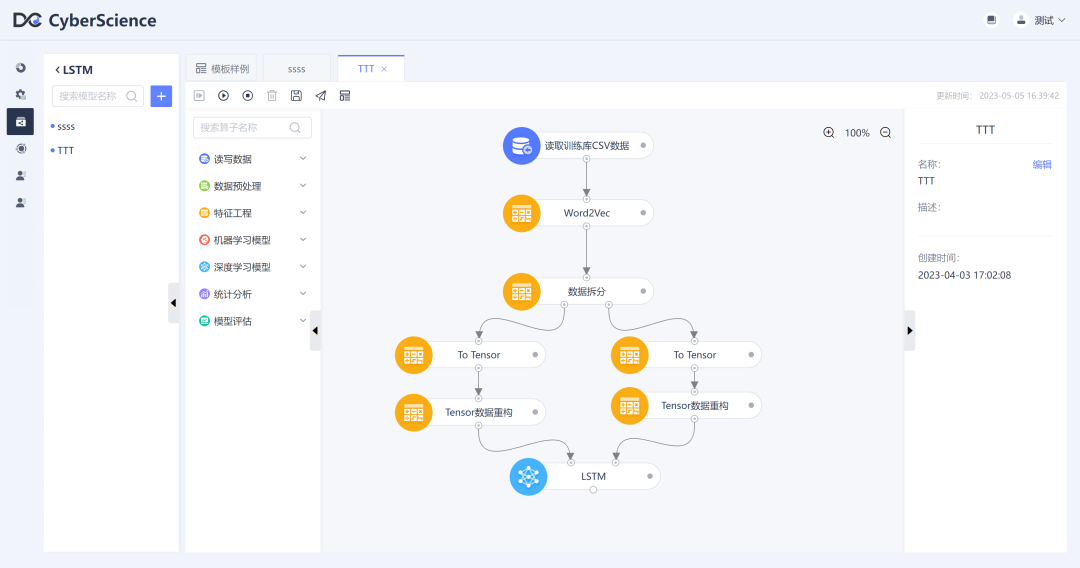
LSTM??
简介:
LSTM(Long Short-Term Memory,长短期记忆)是一种常用于处理序列数据的深度学习算法。它是循环神经网络(Recurrent Neural Network,RNN)的一种变种。LSTM以时间步为单位进行计算,每个时间步都接收输入数据和前一个时间步的隐藏状态作为输入。然后,它使用门控机制来控制哪些信息应该被传递、遗忘或输出,以及如何更新记忆单元中的内容。这使得LSTM在处理长序列数据时能够更好地捕捉序列中的关键信息。?
? ? ? ?
LSTM被广泛应用于各种任务,包括自然语言处理(如语言建模、机器翻译和情感分析)、语音识别、时间序列预测等。它在处理时序数据和处理长期依赖性方面表现出色。?? ?
举例说明:
天气预测。我们希望根据过去几天的天气状况(如温度、湿度等)来预测未来一天是否会下雨。使用LSTM来处理这个问题,它可以通过记忆单元来存储过去的天气情况,并在预测时考虑到这些信息。每个时间步,LSTM会根据过去几天的天气情况和当前的输入(如当前的温度)更新记忆单元,并利用门控机制来控制哪些信息应该被传递、遗忘或输出。这样,LSTM可以更好地捕捉到过去天气与未来是否下雨之间的关系,提供更准确的预测结果。??
在实际应用中,我们可以将过去几天的天气数据作为输入序列,将未来一天是否下雨作为目标。利用大量的历史数据进行训练,LSTM可以学习到天气数据的模式和规律,并用于预测未来天气情况。
代码实现:
import numpy as npfrom keras.models import Sequentialfrom keras.layers import LSTM, Dense
# 构造输入序列和目标序列
input_sequence = np.array([[0.1, 0.2, 0.3], [0.2, 0.3, 0.4], [0.3, 0.4, 0.5], [0.4, 0.5, 0.6]])
target_sequence = np.array([0.4, 0.5, 0.6, 0.7])
# 将输入序列修改为LSTM所需的形状 [样本数,时间步长,特征维度]
input_sequence = input_sequence.reshape((input_sequence.shape[0], input_sequence.shape[1], 1))
# 创建LSTM模型
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(3, 1)))
model.add(Dense(1))
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(input_sequence, target_sequence, epochs=100, verbose=0)
# 对新的输入序列进行预测
new_input = np.array([[0.5, 0.6, 0.7], [0.6, 0.7, 0.8]])
new_input = new_input.reshape((new_input.shape[0], new_input.shape[1], 1))
predictions = model.predict(new_input)
print(predictions)执行结果:??
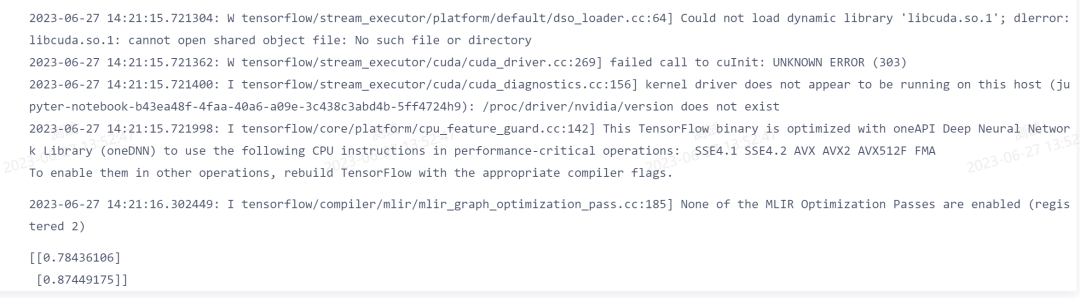
CyberAI系统训练图:
CyberAI申请试用:
申请试用可访问该链接:
https://www.datacyber.com/product/CyberAI
总结:
在CyberAI深度学习平台上,我们拥有多种强大的算子,可以帮助构建高效、准确的模型。无论是二分类还是多分类、回归、图像处理还是序列数据分析,我们都能找到适合的算子来应对挑战。通过合理选择算子和优化方法,我们可以实现准确、高效的模型训练和预测。感谢大家对我们公众号的关注,希望我们的内容能帮助您更好地了解和应用深度学习技术!?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!