Dual-MVSNet/DMVSNet论文精读
本文是Constraining Depth Map Geometry for Multi-View Stereo:
A Dual-Depth Approach with Saddle-shaped Depth Cells的阅读记录
1. 问题引入
使用基于学习的多视点立体(MVS)技术重建场景涉及两个阶段:深度预测[【主要在于优化此过程】和融合渲染。
具有较小估计误差的深度图在融合渲染后可能无法实现更好的三维重建质量。是否还有其他因素限制了三维重建的准确性?在对融合过程进行深入研究后,本论文发现深度几何是MVS中被忽视的一个重要因素。
MVS方法过程:已知Ref和Src,相机内参和平移矩阵,MVS方法预测Ref的深度图D,D经过滤波和在给定的相机内参和平移矩阵下被使用融合成3D点云。
融合过程 :
- 使用估计的深度图将Ref视图中的像素投影到三维空间
- 进一步将其投影到Src视图中的子像素
- 将子像素用其周围像素的深度估计的线性插值深度重新投影到3-D空间
在线性插值中,假设有两个相邻像素A和B,其位置分别为(x1, y1)和(x2, y2),对应的像素值分别为VA和VB。假设我们想要在这两个像素之间的某个位置(x, y)处进行插值。 首先,计算位置(x, y)相对于A和B的相对位置权重: 水平权重:w1 = (x2 - x) / (x2 - x1) 垂直权重:w2 = (x - x1) / (x2 - x1) 然后,根据相邻像素的权重,对像素值进行插值: 插值像素值:V = VA * w1 + VB * w2 这样,根据权重对相邻像素的像素值进行线性组合,即可得到在位置(x, y)处的插值像素值V。
线性插值能够平滑地从已知像素中估计出中间像素的值,使图像看起来更连续和自然
- 子像素深度是通过线性插值相邻像素的深度来估计的,其精度受到估计偏差和深度单元的影响 要考虑不同单元的深度几何形状对MVS的影响
通过一系列实验证明鞍形单元对于深度预测的精读是有效的,如何生成具有更多鞍形单元的深度图是本文研究的重点
2. 双深度预测
提出了一种新的Lint损失来监督它们的预测值,具体如式5,Lint鼓励估计偏差不大于|max(D)?min(D)|,使得间隔随着估计偏差的增加而增加,这保证了双重深度分布在地面实况深度的两侧
3. 棋盘选择策略
为每个像素选择合适的深度预测值【当真实深度值介于预测的双深度之间时】
我们在选择最大和最小预测深度值之间交替,创建类似棋盘的分布,如式(6)
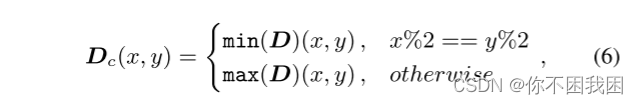
当真实深度值不在预测的双深度范围内,可能会造成误差,为此提出使用级联双深度
4. 级联双深度
在双深度估计中,如果像素预测的最大和最小深度值之间的差很大,则我们认为估计偏差很大。该像素的深度搜索空间将在下一次迭代中被放大。
- 使用max(D)和min(D)之间的绝对距离作为深度假设的边界
- 给定深度假设的范围,我们可以构建特征量、成本量和概率分布[4.1节详述]
- 根据第4.2节中概述的原理,我们计算了精细的双重深度D′,然后根据棋盘选择策略使用该深度来获得最终深度Dr。
5. 损失计算



Lsub是子像素(x + 0.5, y + 0.5)和地面实况图的L1损失
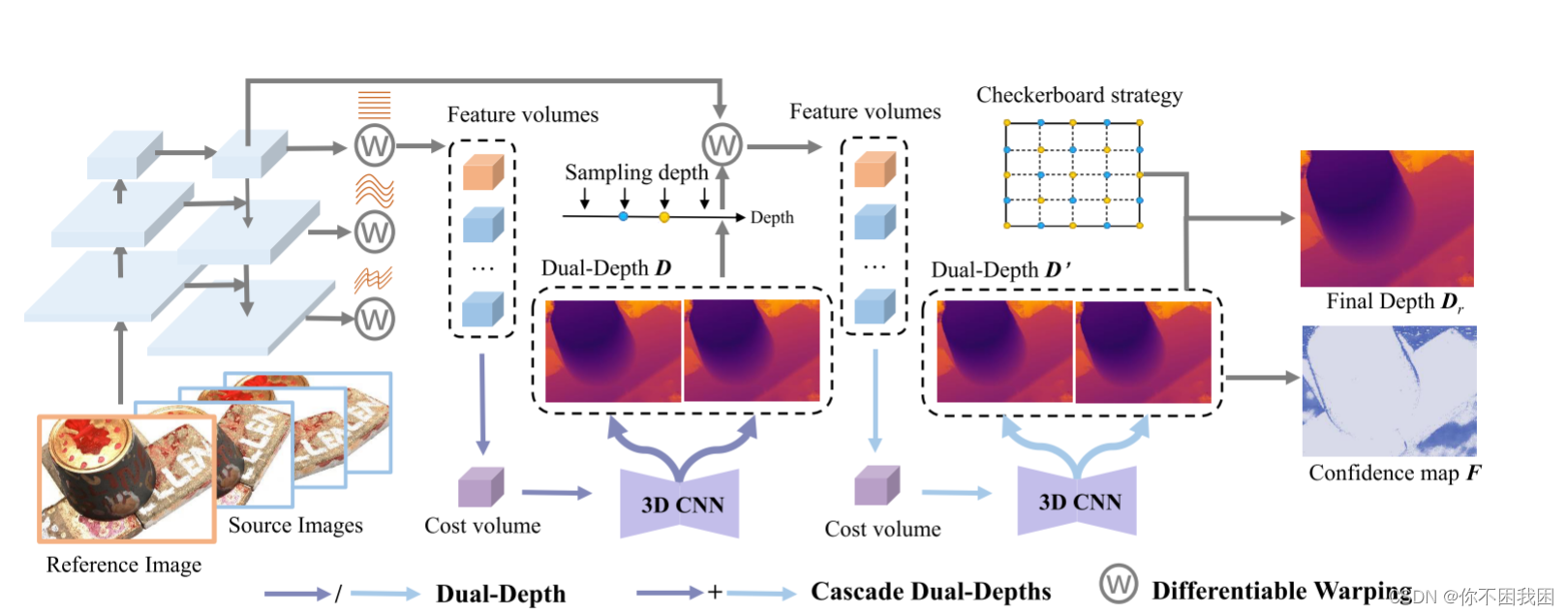
6. DMVSNet框架
-
首先分别约束两个深度值的预测误差,以确保它们都尽可能接近地面实况深度 【双深度】
-
通过约束这两个预测深度的间隔来联合优化它们 【级联双深度】
-
提出了一种新的棋盘选择策略,将两个深度值相结合,以获得最终的深度图
采用特征金字塔网络(FPN)来提取多尺度特征,如CasMVSNet,并将输出通道加倍以获得级联双深度的特征图。

然后,通过采样深度假设对特征图进行扭曲来构建特征体积。

然后使用相似性度量(例如基于内部产品的度量)将特征量聚合为成本量。

利用三维CNN将成本体积转换为概率分布。

为了获得双重深度D,我们将3-D CNN加倍以获得两个概率分布,并使用等式生成深度图。(3)。

使用自适应采样的深度假设重复这一过程【级联】,以生成精细的双深度D′,该深度D′用于使用棋盘选择策略构建最终深度Dr。
生成的置信图在融合过程中使用阈值来去除深度显著偏离的像素。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!