C++入门

开篇有话说:
 当谈到使用 C++ 进行编程时,你可能会想到其强大的面向对象编程功能、高效的性能和广泛的应用范围。C++ 是一种通用的编程语言,可以用于开发各种类型的应用程序,从桌面应用程序到操作系统内核,甚至是游戏引擎。
当谈到使用 C++ 进行编程时,你可能会想到其强大的面向对象编程功能、高效的性能和广泛的应用范围。C++ 是一种通用的编程语言,可以用于开发各种类型的应用程序,从桌面应用程序到操作系统内核,甚至是游戏引擎。
从本章开始,来撰写有关c++的博客。在本系列博客中,我们将介绍C++的基础知识、编程范例和一些最佳实践,以帮助你更好地了解和掌握这门编程语言。我们将从最简单的语法开始,逐步深入探讨C++的复杂性,涵盖诸如变量、运算符、流控制语句、函数、类、模板等主题。
命名空间:
已经学习了C语言,我们可以知道C语言的一大缺陷之一是它无法解决命名冲突的问题。所以在C++中引入了命名空间这一新概念。
命名空间是一种用来组织和区分不同实体(如函数、类、变量等)名称的机制。它可以避免命名冲突,使代码更加清晰和可读。
?在C++中,你可以使用关键字namespace来定义自己的命名空间。命名空间的定义通常放在头文件或源文件的顶部。例如:
namespace mynamespace {
// 声明和定义实体(函数、类、变量等)
}
?在同一个命名空间中声明的实体可以直接使用,或者通过使用命名空间名称作为前缀来引用。例如:
namespace myNamespace {
void myFunction() {
// 函数实现
}
class MyClass {
// 类定义
}
}
int main() {
// 直接调用函数
myFunction();
// 通过命名空间名称引用类
myNamespace::MyClass obj;
}
?命名空间还可以嵌套使用,形成层次结构。这样可以更好地组织和管理代码,避免命名冲突。例如:
namespace outerNamespace {
namespace innerNamespace {
// 声明和定义实体(函数、类、变量等)
}
}
通过这几种方式,可以在不同的命名空间中定义具有相同名称的实体,而它们之间不会发生冲突。
指定展开命名空间
指定展开命名空间是指在C++中使用using指令来显示地展开一个命名空间中的成员,以便可以直接使用该命名空间中的成员,而无需使用限定符。
在C++中,可以使用using关键字来展开一个命名空间。有两种方式可以实现这一点:
using namespace语句:可以使用using namespace语句来展开整个命名空间,使得其中的所有成员都可直接访问。例如:
#include <iostream>
namespace MyNamespace {
int value = 42;
}
int main() {
using namespace MyNamespace;
std::cout << value << std::endl; // 直接使用命名空间中的成员
return 0;
}
在上述示例中,我们使用了using namespace MyNamespace来展开命名空间MyNamespace,因此可以直接访问其中的成员value。
using声明:可以使用using声明来展开命名空间中的特定成员,而不是整个命名空间。例如:
#include <iostream>
namespace MyNamespace {
int value = 42;
}
int main() {
using MyNamespace::value;
std::cout << value << std::endl; // 直接使用命名空间中的成员
return 0;
}
在上述示例中,我们使用了using MyNamespace::value来展开命名空间MyNamespace中的成员value,因此可以直接访问该成员。
需要注意的是,当命名空间中的成员名称与当前作用域中的其他名称冲突时,展开命名空间可能会导致命名冲突。因此,建议谨慎使用展开命名空间,以避免潜在的命名冲突问题。
总结起来,指定展开命名空间就是使用using指令来显示地展开命名空间中的成员,以便可以直接访问该命名空间中的成员而无需使用限定符。这样可以简化代码,并提高可读性。
::域作用解析符
在上面命名空间的命名方法中,有一个与C语言不同的符号:::域作用解析符是在C++中使用的一种语法,用于指定一个变量、函数或类的作用域。域作用解析符由两个冒号::组成,位于标识符之前。
域作用解析符有以下几种用法:
1. 访问命名空间中的成员
当一个标识符位于某个命名空间中时,可以使用域作用解析符来访问该命名空间中的成员。例如,如果有一个命名空间myNamespace中定义了一个函数myFunction(),可以使用myNamespace::myFunction()来调用该函数。
namespace myNamespace {
void myFunction() {
// some code here
}
}
int main() {
myNamespace::myFunction(); // 调用myFunction函数
return 0;
}
2. 访问类的成员
在类的定义中,可以使用域作用解析符来指定某个成员函数或成员变量属于哪个类。例如,如果有一个类MyClass,并且其中定义了一个成员函数myFunction(),可以使用MyClass::myFunction()来引用该成员函数。
class MyClass {
public:
void myFunction() {
// some code here
}
};
int main() {
MyClass obj;
obj.myFunction(); // 调用MyClass类的myFunction函数
return 0;
}
3.*访问类的静态成员
对于类的静态成员(包括静态函数和静态变量),也可以使用域作用解析符来访问。静态成员属于整个类,而不是某个特定的对象实例。因此,在引用静态成员时,可以使用类名::成员名的形式。
class MyClass {
public:
static int myStaticVariable;
static void myStaticFunction() {
// some code here
}
};
int MyClass::myStaticVariable = 0;
int main() {
MyClass::myStaticVariable = 10; // 访问静态变量
MyClass::myStaticFunction(); // 调用静态函数
return 0;
}
在这个例子中,我们使用MyClass::来访问类的静态成员变量和静态成员函数。
域作用解析符是C++中非常有用的语法,它允许我们在复杂的命名空间和类结构中准确定位和使用成员。

总而言之,命名空间是一种用来组织和隔离代码中实体名称的机制,使代码更加模块化、可读性更高,并减少命名冲突的可能性。
在常见的C++代码中,经常会在代码头看见using namespace std;这样一行代码。在C++中,标准库的函数和类都被放置在std命名空间中,通过使用"std::"前缀来引用这些实体。例如,std::cout表示输出流对象cout,std::vector表示向量容器类vector,等等。使用std命名空间可以使代码更加清晰和可读,并且有助于避免命名冲突。
IO流:
谈到C++,就不得不说IO流,I/O(输入/输出)流是C++中处理输入 和输出 的机制。它们是用于读取和写入数据的抽象概念,可以从不同的来源读取数据(如键盘、文件等),并将数据写入不同的目标(如屏幕、文件等)。
C++中的I/O流被分为了两种类型:输入流(input stream)和输出流(output stream)。输入流用于从外部读取数据,而输出流用于将数据发送到外部。这些流可以与各种设备进行交互,包括终端(键盘和显示器)、文件、网络等。
在C++中,我们首先要包含的头文件 <iostream> 是用于处理标准输入和输出的头文件。它包含了一些与输入/输出流相关的类和函数的声明。
以下是一些常用的 <iostream> 头文件中定义的类和函数:
1. std::cin:标准输入流对象,用于从键盘读取输入数据。
示例用法:std::cin >> variable;
2. std::cout:标准输出流对象,用于向屏幕打印输出数据。
示例用法:std::cout << "Hello, World!";
3. std::endl:用于插入换行符并刷新输出缓冲区。
示例用法:std::cout << "Hello" << std::endl;
4. std::cerr:标准错误流对象,用于向屏幕打印错误信息。
示例用法:std::cerr << "Error occurred!";
5. std::ifstream:文件输入流类,用于从文件中读取数据。
示例用法:std::ifstream inputFile("input.txt");
6. std::ofstream:文件输出流类,用于将数据写入文件。
示例用法:std::ofstream outputFile("output.txt");
使用 <iostream> 头文件时,可以使用 std:: 前缀来访问其中定义的类和函数。例如,std::cout 表示标准输出流对象。
下面是一个简单的示例程序,使用 <iostream> 头文件输出 “Hello, World!” 到屏幕上:
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
在这个示例中,我们使用 std::cout 输出字符串 “Hello, World!”,并使用 std::endl 插入换行符。最后,通过返回值 0 来表示程序执行成功。
在C++中,流插入操作符 << 和流提取操作符 >> 是用于实现输入和输出的运算符。
总之,<iostream> 是C++中用于处理标准输入和输出的头文件,提供了处理输入/输出流的类和函数的声明。通过包含该头文件,可以方便地进行输入和输出操作。
缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
以下是一个使用缺省值的函数示例:
#include <iostream>
// 带有默认参数值的 add 函数声明
int add(int x, int y = 0);
int main() {
std::cout << add(5) << std::endl; // 输出 5
std::cout << add(5, 3) << std::endl; // 输出 8
return 0;
}
// 带有默认参数值的 add 函数定义
int add(int x, int y) {
return x + y;
}
在上述示例中,我们定义了一个带有默认参数值的
add函数。该函数有两个参数,其中第二个参数y的默认值为 0。在main
函数中,我们通过调用add函数来进行加法运算。
当我们只传递一个实参时,会使用默认参数值 0 来代替缺失的第二个参数,从而实现了对单独参数进行求和的目的。而当我们提供了两个实参时,第二个实参将覆盖默认参数值,从而实现了两个数的求和。
总结起来,通过在函数声明时指定参数的默认值,可以为函数的参数提供缺省值,从而实现更加灵活的函数调用。在实际编程中,使用缺省值可以简化代码,提高程序可读性和可维护性。
需要注意的是,指定默认参数值的参数必须位于参数列表的最后。也就是说,如果一个参数具有默认值,则它右侧的所有参数都必须具有默认值。这是因为在函数调用时,提供的实参从左到右与函数的形参进行匹配。
另外,缺省函数不能在一个函数的声明和定义中同时出现,最好在函数声明的地方给,如果函数的声明和定义分离的话,那么尽量在函数声明里给出函数的缺省值
重名函数
在 C++ 中,如果定义了两个或两个以上以上名称相同的函数,这种情况被称为函数重载。
C++ 允许我们在同一个作用域内定义多个名称相同但参数列表不同的函数。参数列表的不同可以体现在参数的类型、数量和顺序上。当我们调用一个函数时,编译器会根据实参的类型和数量来选择对应的函数进行调用。
例如,我们定义了下面两个函数:
int add(int a, int b) {
return a + b;
}
double add(double a, double b) {
return a + b;
}
这里定义了两个名称相同的函数 add,但是它们的参数列表不同,一个接收两个整数参数,另一个接收两个浮点数参数。当我们调用 add 函数时,编译器会根据实参的类型和数量来选择对应的函数进行调用。例如:
int x = add(1, 2); // 调用 add(int, int)
double y = add(1.0, 2.0); // 调用 add(double, double)
引用
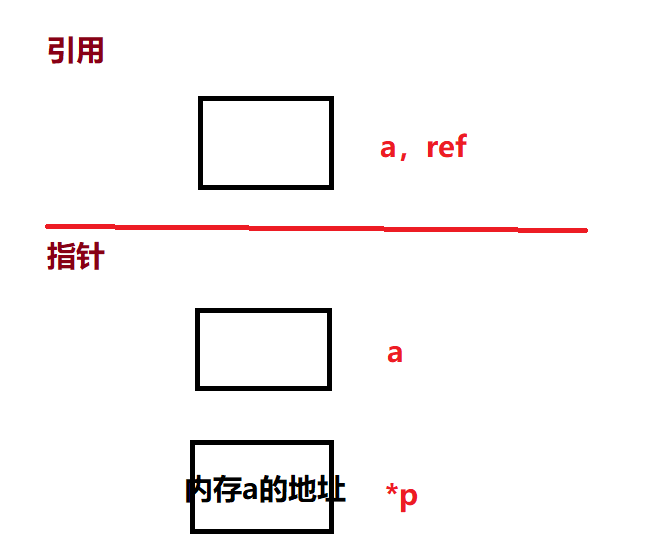
在 C++ 中,引用是一种别名,它允许我们使用一个已存在的变量来创建一个新的名称。通过引用,我们可以通过不同的名称来访问同一个变量,而不需要拷贝变量的值。在我看来它与C语言的指针类似,但注意,也仅仅是类似而已。。。。
引用的声明方式是在变量类型前面加上 & 符号。例如,如果有一个整型变量 x,我们可以创建一个引用 ref 来引用它:
int x = 10;
int& ref = x; // 创建一个名为 ref 的引用,它引用了变量 x
在这个例子中,ref 是 x 的引用,它和 x 实际上引用了同一个内存空间,它们是等价的。因此,我们可以通过 ref 来修改 x 的值,也可以通过 x 来修改 ref 的值。
引用的一些特性和注意事项如下:
- 引用必须在创建时初始化,并且不能再引用其他变量。
- 引用在创建后不能改变引用的目标,即一旦引用被初始化,它将一直引用同一个变量。
- 引用可以作为函数的参数或返回值,可以在函数中通过引用修改外部变量的值。
- 引用不能引用空值,所以在创建引用时必须确保被引用的对象是有效的。
引用的一个常见应用是作为函数参数,可以通过引用参数修改传入的变量。这其实是引用的最大价值,例如:
void increment(int& num) {
num++; // 通过引用修改传入的变量
}
int main() {
int x = 5;
increment(x); // 传入 x 的引用
cout << x; // 输出 6
return 0;
}
在上面的例子中,通过将 x 的引用传递给 increment 函数,我们可以在函数中通过引用修改 x 的值,使其增加了 1。最后输出的结果为 6。
但是在函数返回时,不能返回引用,因为出了函数作用域以后,返回对象就销毁了,不能用引用返回,否则结果是不确定。
知道了大概用法,既然它指针有类似之处,那么其实引用的底层也是通过指针来实现的。在 C++ 中,引用被认为是指向某个变量的指针的别名,它们共享同一个内存地址。
例如,当我们创建一个引用时,编译器会在内部生成一个指针,该指针指向实际的变量。下面是一个示例:
int x = 10;
int& ref = x;
在上面的代码中,ref 实际上是一个指针,指向变量 x。这可以通过取 ref 的地址来证明:
cout << &x << endl; // 输出变量 x 的地址
cout << &ref << endl; // 输出引用 ref 的地址
输出结果应该相同,因为它们共享同一个内存地址。所以引用的底层实现是通过指针来实现的,而指针是由 C++ 编译器转换为对应的汇编代码的,所以引用底层是用汇编实现的,引用在底层也是开了空间。
内联函数
内联函数是一种编译器优化技术,它的目标是减少函数调用的开销,提高程序的执行效率。内联函数是在编译时将函数的代码插入到调用处,而不是通过函数调用的方式来执行函数。
在 C++ 中,我们可以使用 inline 关键字来声明一个内联函数。例如:
inline int add(int a, int b) {
return a + b;
}
上面的代码中,add 函数被声明为内联函数。当我们在程序中调用 add 函数时,编译器会将函数的代码直接插入到调用处,避免了函数调用的开销。这样可以节省函数调用的时间和空间开销,特别是对于一些简短的函数。
我们已经知道了,内联函数在编译时是直接将代码插入到调用处,所以需要注意的是,内联函数适合用于函数体较短的函数,如果函数体过大,频繁地使用内联函数可能会导致代码膨胀,增加可执行文件的大小,反而降低程序的性能。
另外,内联函数不能声明和定义分离开在两个文件,内联函数的定义通常放在头文件中,以便在多个源文件中使用。
auto
auto 是 C++11 引入的关键字,用于自动推导变量的类型。使用 auto 关键字可以减少代码中的类型冗余,并且使代码更加简洁和易读。
以下是一些使用 auto 的示例:
auto num = 10; // 自动推导 num 的类型为 int
auto name = "John"; // 自动推导 name 的类型为 const char*
auto pi = 3.14159; // 自动推导 pi 的类型为 double
std::vector<int> numbers = {1, 2, 3, 4, 5};
for (auto it = numbers.begin(); it != numbers.end(); ++it) {
// 使用 auto 推导迭代器的类型
std::cout << *it << " ";
}
在循环中,auto 用于推导迭代器 it 的类型,无需手动指定。这使得代码更加简洁,并且不需要担心容器中元素的具体类型。
auto不可以做参数,不支持返回值,auto意义是定义对象时,类型较长,用它比较方便,并且auto不能用来直接声明数组
需要注意的是,auto 推导的变量类型是在编译时确定的,而不是在运行时。因此,使用 auto 时需要确保变量的初始化表达式具有明确的类型,以便编译器可以正确推导类型。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!