GaussDB技术解读系列:运维自动驾驶探索
近日,在第14届中国数据库技术大会(DTCC2023)的GaussDB“五高两易”核心技术,给世界一个更优选择专场,华为云数据库运维研发总监李东详细解读了GaussDB运维系统自动驾驶探索和实践。
随着企业数字化转型进入深水区,数据库系统越来越复杂,运维团队维护的数据库规模越来越大,传统工具化的运维已无法满足当前运维的要求,数据库运维逐渐向智能化发展。
如何更好地感知和预测数据库故障,进而进行智能诊断、自适应恢复,是我们一直探索的内容。接下来本篇将分享GaussDB在运维自动化驾驶上的探索与实践,分别从云数据库运维挑战,GaussDB运维体系架构,以及我们如何进行快速感知和快速诊断4个方向进行分享。
云数据库运维面临哪些挑战?
随着企业将数据库搬迁上云,云上数据库运维面临的挑战更加复杂。数据库可能会部署在裸金属、虚拟机、容器等多样化的基础设施上,不同的基础设施面对的故障场景也随之多样化。
如果我们遇到一个性能抖动的亚健康问题,通常解决思路是从应用数据库、操作系统、计算、存储、网络等方面多层次全面分析,每一层都可能发生故障,不同层次发生故障可能引发相同的亚健康现象。比如说一个慢SQL,可能是磁盘故障导致的,也有可能是网络抖动引起的,但是表现上对于客户来讲都是一个慢SQL。
如果运维能力不足,我们很难在短时间内去定位和解决亚健康问题,因为它在处理过程中一般有三个挑战:
第一,无法准确预测和监控亚健康问题
这里主要涉及到多和少的问题,“少”就是在每一层上缺少对亚健康问题的监控,比如说磁盘故障了,可以很容易感知到;但如果磁盘出现了坏块或者慢盘的情况,我们就没有办法快速监控。“多”体现在我们在每一层都做了监控和告警,但告警之间是没有关联性的,很难从这些告警中识别真正发生问题的点在哪里,所以很难精确发现当前的亚健康问题。
第二,发现亚健康问题之后没有办法进行快速诊断
对于数据库内部发生的问题,往往依赖DBA经验进行诊断和决策,对运维的能力要求比较高,效率也无法保证。
第三,恢复能力不足
我们当前诊断到发生问题的根源之后需要去恢复,但恢复能力不足,比如限流、扛过载的有效能力不足,涉及数据库参数调优、烂SQL优化等需要很深的数据库能力和经验的积累。
GaussDB整体运维架构?
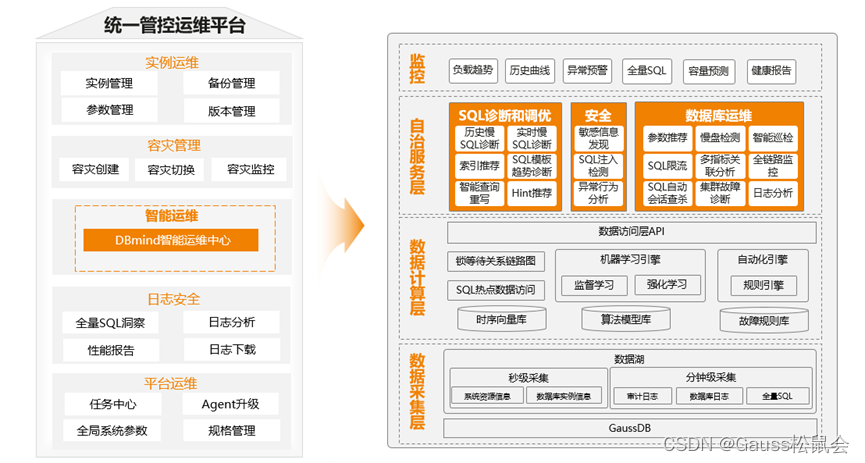
GaussDB是如何处理这些问题的?下面我们看一下GaussDB整体运维的架构,
GaussDB统一运维平台主要分为5个部分:
第一部分是实例运维,主要负责GaussDB集群生命周期的管理,比如创建、变更以及进行备份恢复和参数调整。
第二部分是容灾管理,主要提供流式容灾、同城容灾、两地三中心能力。
第三部分是智能运维,是GaussDB运维体系中最关键的部分,通过AI4DB的能力打造自治运维系统,主要分为以下四层:
-
第一层是数据采集层,负责采集各层的监控数据以及上层下发的操作指令。
-
第二层是数据计算层,负责将采集到的数据进行缓存、持久化以及数据加工,包括时序数据库、算法模型库、故障规则库等。
-
第三层是自治服务层,包括SQL诊断调优、安全、数据库运维等能力。
-
第四层是全景监控,包括告警监控、全量SQL等能力。
GaussDB通过构建一系列的智能运维中心,打造了全链路、端到端的自动驾驶体验。
?
GaussDB故障快速感知
- ??数据库全景监控大盘,实时感知系统运行状态?
?下面我们看一下GaussDB全景监控大盘,通过全景监控可以看出我们所维护的数据库集群哪些是正常的,哪些是异常的,哪些是存在亚健康情况的。比如查看告警统计模块,通过分析可以看出整个集群当前的告警情况,如果有紧急告警和重要告警,可以优先处理。也可以看到资源使用的风险,通过资源使用预测能力预警即将会发生哪些资源瓶颈,比如说磁盘空间不足、CPU不足,方便我们及时处理和恢复。智能诊断这块,通过分析当前数据库有哪些性能瓶颈,同时也支持自定义监控大盘,选取用户重点业务数据库,自定义重点监控指标,对重点业务进行自定义维度的保障监控。
数据库全景大盘首先要依赖全链路、全方位的监控。数据库的可观测能力对于数据库的运维十分重要,GaussDB全链路监控具备从硬件、OS、DB等分层监控,构建从采集、发送、展示、分析到巡检等全链路能力,并且打通了硬件到操作系统,到数据库整个监控链的通道。比如说硬件出现故障问题,如果在云上,硬件故障属于不同部门维护,数据库部门只能看到数据库集群,如何感知到硬件发生亚健康或者操作系统存在问题,这个时候就得联合硬件部门,打通硬件到操作系统、数据库的通知机制,如果在这层发生了亚健康问题,可以把故障信息向上通知相关的运维部门解决。

- 全量SQL数据采集分析
接下来看一下全量SQL采集的能力。相较于传统全量SQL采集方式,即通过流量抓取或者日志方式获取全量SQL,GaussDB通过轻量化的方式构建了全量SQL的洞察。采集进程与数据库建立内存缓冲区通道,直接从内存通道里把SQL信息进行采集并转存到外部设备中,这个过程不需要发生任何磁盘IO操作,对性能影响极低。
传统的采集场景我们可能需要开启全量SQL,对业务的影响在30%左右,一般情况下,用户是不敢开启的。而GaussDB的全量SQL,可以把风险降到最低。GaussDB提供的全量SQL方案具备以下4个特点:
低风险
GaussDB通过内存方式把日志信息全部读取完再转存到第三方,对数据库性能损耗不超过5%。
?低成本
GaussDB不将全量SQL数据转存到本地IO,而是直接转存到第三方,比如说云上的OBS,并支持全量SQL的压缩,成本比较低。
高扩展
GaussDB全量SQL会默认采集部分信息,如果这些信息不满足当前的诉求,可以进行扩展。
?高安全
当需要将全量SQL转存到第三方设备上时,GaussDB在转存过程中进行了默认的数据脱敏,确保数据安全。
通过全链路监控,GaussDB支持快速自动巡检,对可用性、可靠性、性能、资源使用趋势等内容进行巡检,并输出巡检报告,由此可以查看当前存在的问题,并给出一些相应建议。所以,通过上述全链路以及自动巡检的能力,GaussDB可以做到快速感知。
?GaussDB智能诊断
下面我们看一下GaussDB在故障诊断方面有哪些能力?
1. SQL自诊断
我们基于离线+在线的方式进行SQL诊断,首先收集可能存在慢SQL的场景,包括SQL文本、SQL执行时间以及扫描行数、返回行数,并收集跟数据库、操作系统或者是资源相关的关键指标,通过业务SQL信息和关键指标信息,进行离线的训练,最终得到一个慢SQL特征库。
这个特征库有什么用呢?当我们在生产环境中遇到慢SQL问题,可以基于特征库和KNN算法进行在线推理,诊断出SQL产生的原因,然后针对根因给出一些优化建议。
2. SQL全链路分析
之前有客户反馈,平时我们的SQL执行非常快,能在一秒内返回,但是最近反馈偶现执行频繁超时。我们业务人员通过查看每一层状况,对客户端、数据库CN、DN、操作系统等进行串行分析,发现这个偶现的问题可能发生在某个分片上,这样的诊断效率非常低。
GaussDB提供的SQL全链路监控分析能力则很好地解决了这个问题。它包括全链路追踪和聚合分析两方面,通过业务SQL关键字或客户端traceID等条件查询到数据库SQLID,并追踪该SQL在数据库集群中的解析过程和执行耗时,以及每条SQL在集群中的转发、聚合情况,进而追踪到问题发生的源头。
3. 多维指标关联分析
数据库运维过程中需要对大量指标进行监控,当其中某个或多个关键指标发生异常时,运维人员需要快速准确定位到异常根因,以便决定下一步的操作。但是当指标数量很多时,筛选信息的工作量也会很庞大,因此我们需要一个高效的工具去解决这个问题。
我们知道某些数据库指标之间是存在强关联性的,通过有方向性的关联性算法,在异常发生时将同一时间段的指标进行比对,根据相关性的强弱将异常时间段内与关键指标相关的指标筛选出来。GaussDB当前支持毛刺、持续增长、漂移、周期性等场景的检测算法,可以帮助运维人员迅速定位问题,减轻运维人员的工作量,助其锁定问题的根因。
4. 趋势预测
在日常系统运维及故障处置实践中,负载的变化往往也蕴含着当前系统的亚健康及故障的影响反馈,基于传统的组件指标监控和告警,在故障异常发现的及时性上具有挑战。GaussDB通过建立对实例级关键指标的监控,基于历史数据和时序预测、异常检测等关键算法,对黄金KPI进行指标预测,发现异常信息,进而提醒用户采取措施,避免异常情况造成严重后果。
5. 索引推荐
应用开发者在对SQL进行优化的过程中,索引优化是关键的优化内容,但由于其在性能分析、优化手段等多方面存在复杂分析和实践门槛,给SQL优化带来了挑战。
索引推荐的核心方法是基于原生的词法和语法解析,对查询语句中的字句和谓词进行分析和处理,再结合字段选择度、聚合条件、多表join关系等输出最优的索引建议。GaussDB 提供索引推荐功能,给出索引推荐列表,以及每一个索引的正向和负向SQL的收益,识别当前数据库存在的冗余索引、无用索引,优化数据库查询速度。GaussDB还提供了优化器评估能力,它提供了一个虚拟索引的能力,不需要真实创建索引,通过虚拟索引评估索引推荐的结果是不是合适;通过持续对索引配置进行优化,可以解决用户的负载漂移情况,及时发现索引不优、冗余索引,以便避免故障发生。
6. SQL会话查杀
应用开发的复杂逻辑可能导致人工难以发现的逻辑问题,出现异常SQL,需要有对应手段帮助运维人员快速对异常会话进行查杀限制。GaussDB应用平台提供了一个会话管理的能力,实时会话页面支持会话统计、活跃会话、会话锁分析、会话查杀等功能,帮助运维和管理人员快速掌握实例的会话信息,管理实例会话,并高效定位数据库会话连接相关人工难以发现的逻辑问题。
7.?SQL限流和自治限流
我们可以想象一个场景,在数据库正常运行过程中,某一个应用上线了一个新功能,这个新功能引入了一个超级烂SQL,导致数据库逐渐从正常对外服务状态转为资源使用逐渐升高,大量的SQL因为获取不到线程、CPU等资源而执行的速度变慢,最终导致业务异常。如果遇到异常SQL(如不优索引)、SQL并发上升等场景,会对整个数据库的可服务性影响比较大,这时我们就可以通过对SQL精准化限流的方式进行抑制,保证业务能够正常运行。
GaussDB提供的SQL限流提供了以下能力:
-
全局快慢车道。所谓全局快慢车道,就是定义两个资源池,一个是正常资源池,我们称为快车道,快车道提供大量的资源,正常业务在快车道运行,如果出现交通事故,这里的交通事故就是指异常的SQL业务,我们可以通过页面一键将异常SQL放到慢车道中,慢车道限制了对资源的使用,这样交通事故处理完了,快车道可以继续保持高速运行。
-
单类SQL精准管控。对于单类SQL,需要从执行时间、IO使用等角度进行精准管控,因为管控这类SQL的资源占用,可以起到紧急限流的效果。
-
内存熔断。提供内存上下限配置,内存使用超过最大内存上限后禁止新连接接入并kill当前会话,待内存恢复到内存下限后停止kill会话并允许新连接接入。
-
SQL自治限流。提供按照一定的SQL规则,或者CPU、内存等资源使用规则,来进行SQL的自治限流能力,避免对应类别的SQL拖慢整个数据库。
今天我分享的内容主要到这里,谢谢大家!?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!