PyTorch的Tensor(张量)
一、Tensor概念
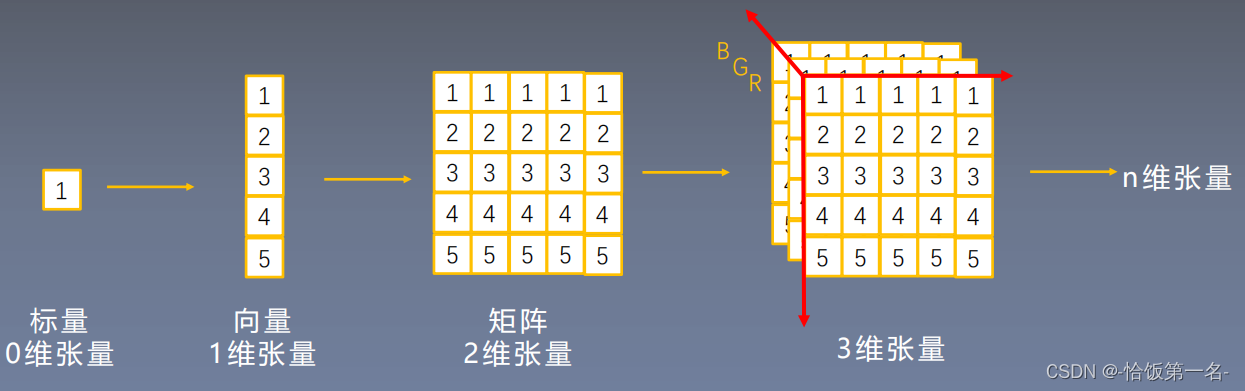
什么是张量?
张量是一个多维数组,它是标量、向量、矩阵的高维拓展
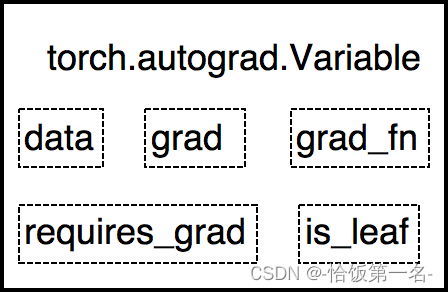
Tensor与Variable
Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行自动求导。
- data: 被包装的Tensor
- grad: data的梯度(梦回数一)
- grad_fn: 创建Tensor的Function,是自动求导的关键
- requires_grad: 指示是否需要梯度
- is_leaf: 指示是否是叶子节点(张量)
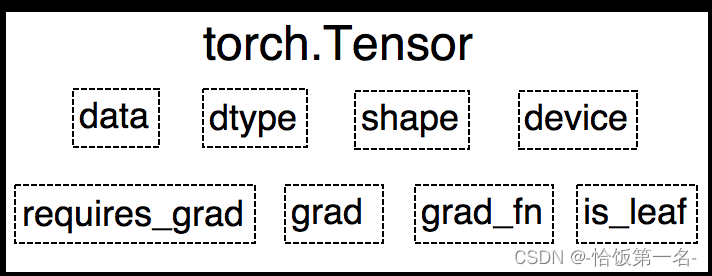
Tensor
PyTorch 0.4.0版本开始,Variable已并入Tensor。
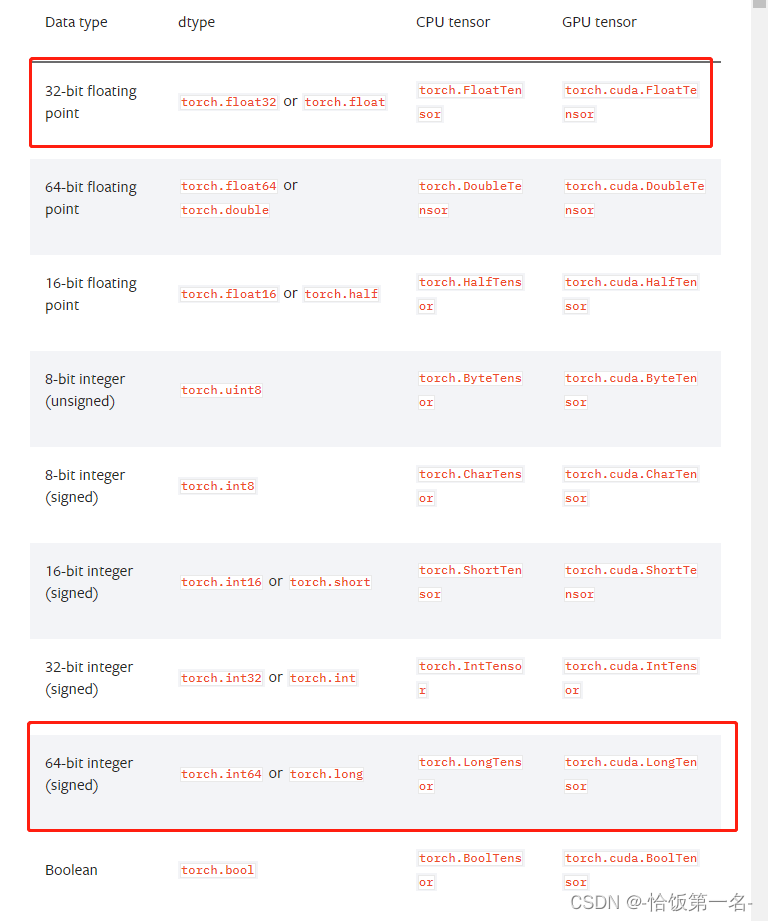
- dtype: 张量的数据类型,例如torch.FloatTensor, torch.cuda.FloatTensor
- shape: 张量的形状,例如 (64, 3, 224, 224)
- device: 张量所在设备,GPU/CPU,是加速的关键
Create Tensor
一、直接创建
torch.tensor(
data,
dtype=None,
device=None,
requires_grad=False,
pin_memory=False
)
功能:从data创建tensor
? data: 数据, 可以是list, numpy
? dtype : 数据类型,默认与data的一致
? device : 所在设备, cuda/cpu
? requires_grad:是否需要梯度
? pin_memory:是否存于锁页内存
torch.from_numpy(ndarray)
功能:从numpy创建tensor。
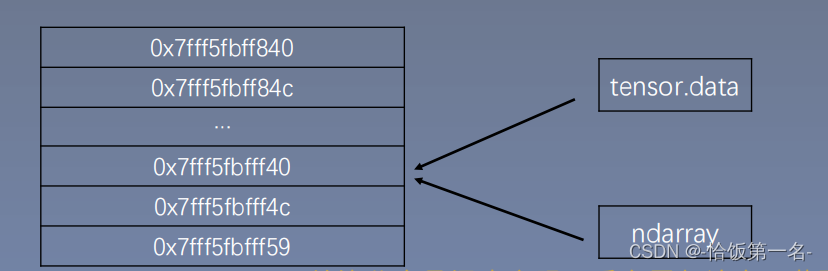
注意事项:从torch.from_numpy创建的 tensor 与原始 ndarray 共享内存。
当修改其中一个的数据时,另一个也会被改动。
二、依据数值创建
torch.zeros(
*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
功能:依照size创建全0张量
? size: 张量的形状, 如(3, 3)、(3, 224,224)
? out : 输出的张量
? layout : 内存中布局形式, 有strided,sparse_coo等
? device : 所在设备, gpu/cpu
? requires_grad:是否需要梯度
torch.zeros_like(
input,
dtype=None,
layout=None,
device=None,
requires_grad=False
)
功能:依照 input 形状创建全0张量
参数说明:
- input: 作为模板的输入张量,新创建的张量将具有与此张量相同的形状和数据类型。
- dtype(可选): 新创建张量的数据类型,默认为 None(即与输入张量相同)。
- layout(可选): 新创建张量的布局,默认为 None(即与输入张量相同)。
- device(可选): 新创建张量所在设备,默认为 None(即与输入张量相同)。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
torch.ones(
*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- *size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
torch.ones_like(
input,
dtype=None,
layout=None,
device=None,
requires_grad=False
)
参数说明:
- input: 作为模板的输入张量,新创建的张量将具有与此张量相同的形状和数据类型。
- dtype(可选): 新创建张量的数据类型,默认为 None,即与输入张量相同。
- layout(可选): 新创建张量的布局,默认为 None,即与输入张量相同。
- device(可选): 新创建张量所在设备,默认为 None,即与输入张量相同。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
- torch.ones() 用于创建所有元素值为1的张量,而 torch.ones_like() 则创建与输入张量形状相同的张量,但所有元素的值都为1。这两个函数都可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.full(
size,
fill_value,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- fill_value: 填充张量的值,可以是标量或与指定数据类型相同的张量。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数用于创建指定形状并用指定值填充的张量。填充值可以是一个标量或与指定数据类型相同的张量。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.arange(
start=0,
end,
step=1,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- start: 序列起始值,默认为 0。
- end: 序列结束值(不包含),创建的序列不包含该值。
- step: 序列中相邻值之间的步长,默认为 1。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数用于创建一个从 start 到 end(不包含 end)的数值序列,并以 step 为步长。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.linspace(
start,
end,
steps=100,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- start: 序列起始值。
- end: 序列结束值。
- steps: 序列中的元素数量,默认为 100。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数创建一个在指定范围内(从 start 到 end)以均匀间隔的方式生成的数值序列,并且序列的元素数量由 steps 参数指定。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.logspace(
start,
end,
steps=100,
base=10.0,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- start: 序列起始值的指数。
- end: 序列结束值的指数。
- steps: 序列中的元素数量,默认为 100。
- base: 序列中的数值以此为底进行指数计算,默认为 10.0。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数创建一个在对数刻度上以均匀间隔分布的数值序列,start 和 end 参数指定序列起始值和结束值的指数,base 参数确定对数的底。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.eye(
n,
m=None,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- n: 矩阵的行数。
- m(可选): 矩阵的列数,默认为 None,如果为 None,则创建的是 n x n 的方阵。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数可以创建一个单位矩阵。如果提供了 m 参数,则创建的是一个 n x m 的矩阵,否则创建的是 n x n 的方阵。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
三、依概率分布创建张量
torch.normal(
mean,
std,
out=None
)
torch.normal() 是 PyTorch 中用于生成服从指定均值和标准差的正态分布随机数的函数。以下是该函数的参数说明:
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- out(可选): 输出张量,用于保存生成的随机数。
torch.normal(
mean,
std,
out=None
)
用于生成服从指定均值和标准差的正态分布随机数。
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- out(可选): 输出张量,用于保存生成的随机数。
torch.normal(
mean,
std,
size,
out=None
)
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- size: 生成张量的形状。
- out(可选): 输出张量,用于保存生成的随机数。
四种模式:
mean为标量,std为标量
mean为标量,std为张量
mean为张量,std为标量
mean为张量,std为张量
这个函数与前一个函数类似,但是多了一个 size 参数,用于指定生成张量的形状。返回一个形状为 size 的张量,其中的元素服从均值为 mean、标准差为 std 的正态分布。可以选择性地提供一个输出张量 out 用于保存生成的随机数。
torch.randn(
*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
torch.rand() 是 PyTorch 中用于生成服从标准正态分布(均值为0,标准差为1)的随机数的函数。以下是该函数的参数说明:
torch.rand(
*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
- *size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- out(可选): 输出张量,用于保存生成的随机数。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个张量,其中的元素是在区间 [0, 1) 上均匀分布的随机数,形状由参数 *size 指定。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.randint(
low=0,
high,
size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False
)
- low: 区间的下界(包含在内)。
- high: 区间的上界(不包含在内)。
- size: 生成张量的形状。
- out(可选): 输出张量,用于保存生成的随机整数。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个张量,其中的元素是在区间 [low, high) 上均匀分布的随机整数,形状由参数 size 指定。
三、依概率分布创建张量
这个函数用于生成随机排列和按照伯努利分布生成随机二元数。
torch.randperm(
n,
out=None,
dtype=torch.int64,
layout=torch.strided,
device=None,
requires_grad=False
)
参数说明:
- n: 生成随机排列的长度。
- out(可选): 输出张量,用于保存生成的随机排列。
- dtype(可选): 张量的数据类型,默认为 torch.int64。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个长度为 n 的张量,包含从 0 到 n-1 的随机排列整数。
torch.bernoulli(
input,
*,
generator=None,
out=None
)
- input: 输入张量,用于指定伯努利分布的概率值。
- generator(可选): 随机数生成器,默认为 None。
- out(可选): 输出张量,用于保存生成的随机二元数。
这个函数返回一个张量,其中的元素按照输入张量中的概率值在伯努利分布上进行采样生成随机二元数(0 或 1)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!