MyBatis原理–缓存机制
MyBatis原理–缓存机制
- 一级缓存:作用域是一个sqlsession内;
- 二级缓存:作用域是针对mapper进行缓存。
一级缓存
概述
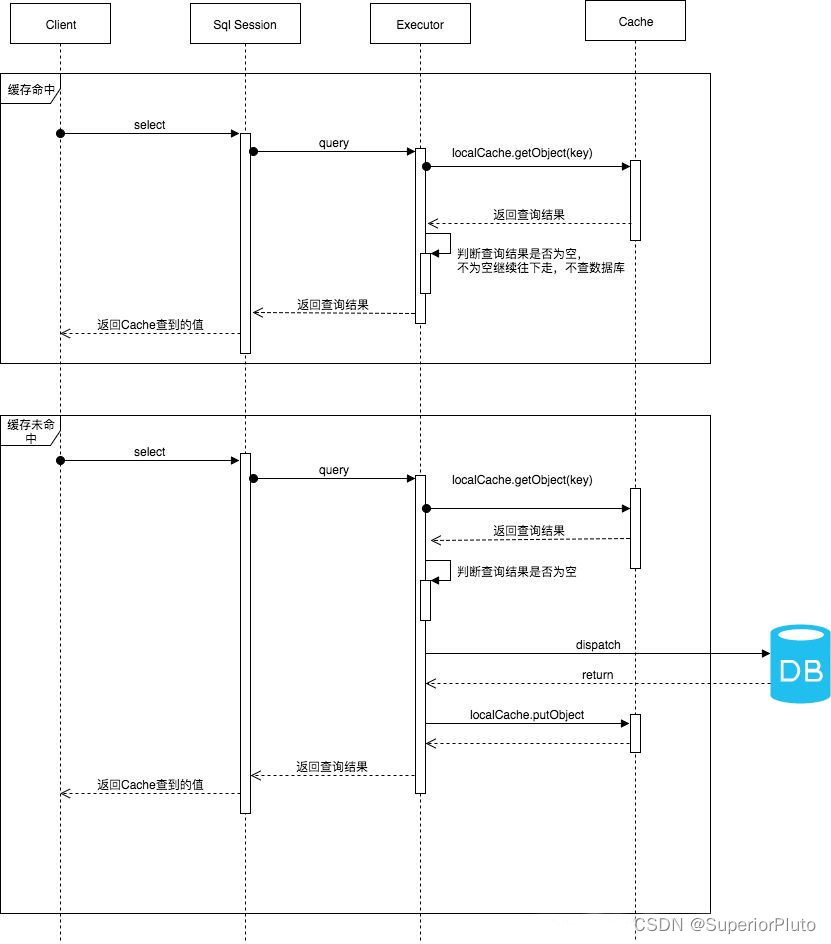
开启一级缓存后:在参数和SQL完全一样的情况下,同一个SqlSession对象调用一个Mapper方法,只执行一次SQL。因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,SqlSession都会取出当前缓存的数据,而不会真是的发送SQL到数据库,走的是一个查询缓存。这也就是为什么一个查询,第一次慢,第二次及以后相对快。
【如何确定是同一个查询】三部分组成的(hashcode + sqlid + sql语句)
缺点
- 多个 SqlSession 或者分布式的环境下,数据库写操作会引起脏数据;
- 一级缓存内部设计简单, HashMap无容量限定。
清除场景
-
增删改之后将缓存commit之后提交就会删除;
-
关闭了sqlSession;
-
调用了clearCache(),或者查询语句中包含了 flushcache == true
【一级缓存是一个粗粒度的缓存,没有更新缓存和缓存过期的概念】
-
对于数据变化频率大,并且需要高时效准确性的数据要求,我们使用 SqlSession 查询的时候,要控制好 SqlSession 的生存时间,SqlSession 的生存时间越长,他缓存的数据可能越旧,从而造成和真实数据库的误差;同时对于这种情况用户可以手动适当的情况SqlSession中的缓存。对于**只执行、并且频繁执行大范围的 select 操作的 SqlSession 对象,SqlSession 对象的生存时间不宜过长**
简要流程
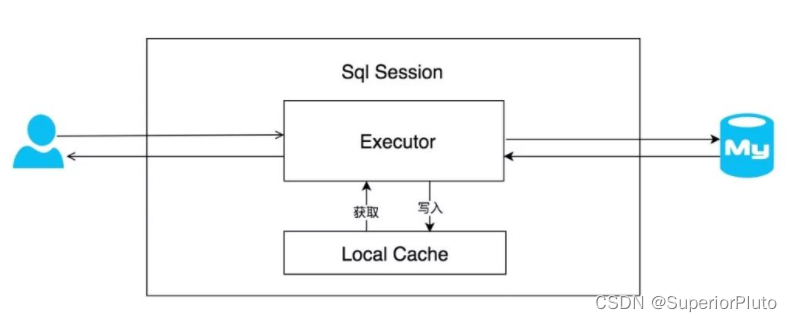
详细流程
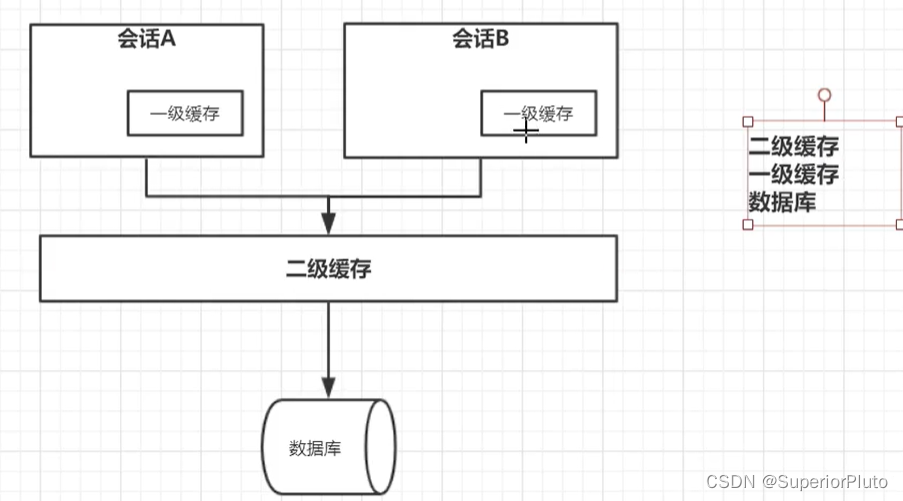
二级缓存
简述
一级缓存中,其最大的共享范围就是一个 SqlSession 内部,如果多个 SqlSession 之间需要共享缓存,则需要使用到二级缓存。
MyBatis的二级缓存实现可以有很多种,可以是MemCache、Ehcache、Redis等,但是需要额外的Jar包。
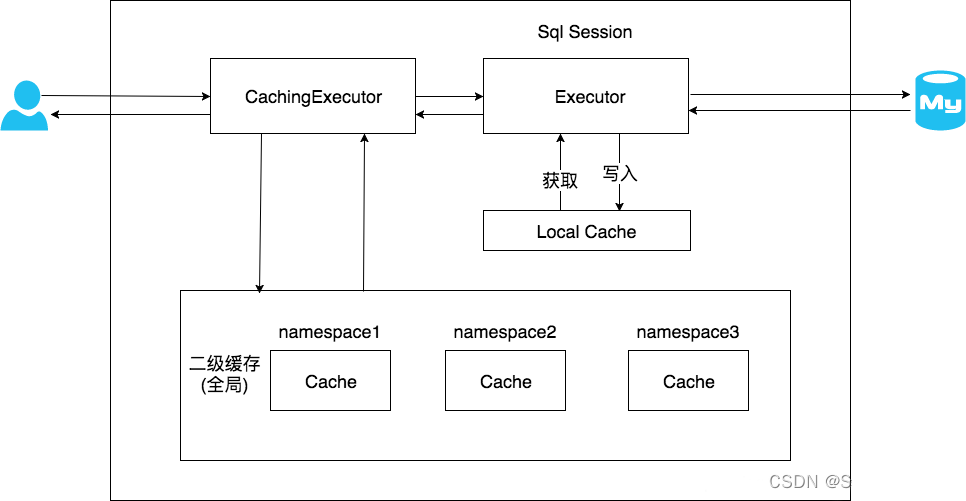
开启二级缓存后,查询先后逻辑顺序:二级缓存-=> 一级缓存=> 数据库;
缺点
- 一个Spring里边只有一个SQLSession,所以根本用不到二级缓存
- 二级缓存默认是不支持分布式的。虽然可以用MemCache、Ehcache、Redis等实现方式来做,但生产中一般不会这样。
开启方式
//1.在配置文件中开启二级缓存的总开关
<setting name="cacheEnabled" value="true" />
//2.mapper映射文件中开启二级缓存
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
| 参数名 | 属性 |
|---|---|
| eviction | 收回策略 |
| flushInterval | 刷新间隔 |
| size | 引用数目 |
| readOnly | 只读 |
eviction细化
| 参数名 | 属性 |
|---|---|
| eviction=”LRU” | 最近最少使用的:移除最长时间不被使用的对象。 (默认) |
| eviction=”FIFO” | 先进先出:按对象进入缓存的顺序来移除它们。 |
| eviction=”SOFT” | 软引用:移除基于垃圾回收器状态和软引用规则的对象。 |
| eviction=”WEAK” | 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。 |
简要流程
详细流程
Spring+Mybatis的缓存失效
- 在未开启事物的情况之下,每次查询,spring都会关闭旧的sqlSession而创建新的sqlSession,因此此时一级缓存是没有起作用的;
- 在开启事物的情况之下,Spring使用threadLocal获取当前资源绑定同一个sqlSession,因此此时一级缓存是有效的。
Appendix——MyBatis和SpringDataJPA
常见的三种开发方式:
-
前端驱动
前端根据设计稿和产品文档实现了UI之后,后端再根据前端UI去设计后台架构,好处在于无论是客户还是开发,都能面向一个具体的页面进行需求讨论和架构设计,最终实现结果不会跑偏。此时呢,MyBatis最合适。
-
后端驱动
如果一个项目非常大,例如从头开始设计一个B2B的交易平台(包括后台ERP)产品,就不能采用这种方式。
因为采用这种方式的坏处在于他不能站在高处俯瞰全貌,都是一点一点的往上堆砌,就是大家常说的摸着石头过河,最终会导致抽象不足,代码冗余,重构成本高,维护成本高,数据孤岛严重,子系统甚至是子模块业务互斥,向着恶性循环发展,最终项目变得越来越庞杂,无数的内耗产生。大的项目,一定要从数据建模开始设计,一定是后端驱动,要认真仔细的思考每一个细节,先做抽象设计,然后具象到模块,再由模块具象到每一个实体、接口。当这一切都设计好了之后,开始模拟数据流转,注意,此时还没有开始写一行代码。
数据流转通畅之后,剩下的编码只是水到渠成的事情,编码过程根本不重要。而这么做,JPA是最合适的。
- 数据驱动
最后一种,是数据驱动,这种开发方式也很常见,最明显的就是报表以及大部分挂羊头卖狗肉的大数据处理,因为就这些数据,你很难去做后端驱动,你设计的再好,数据就是缺失的你没办法。所以数据驱动,MyBatis也是比较合适的,JPA可能不太合适。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!