Pytorch:模型的保存加载、模型微调、GPU的使用
目录
一、模型的保存与加载
建立的模型训练好是可以保存的,以便后面的使用。如果不保存的话,岂不是要使用的时候又得重新开始训练?要是数据集非常大,训练的成本可是不低的。所以如何保存模型和加载模型呢? 我们下面来看看
1.1 序列化与反序列化
序列化与反序列化主要讲的是硬盘与内存之间的数据转换关系
模型在内存中是以一个对象的形式被存储的,且不具备长久存储的功能;而在硬盘中,模型是以二进制数序列进行存储。
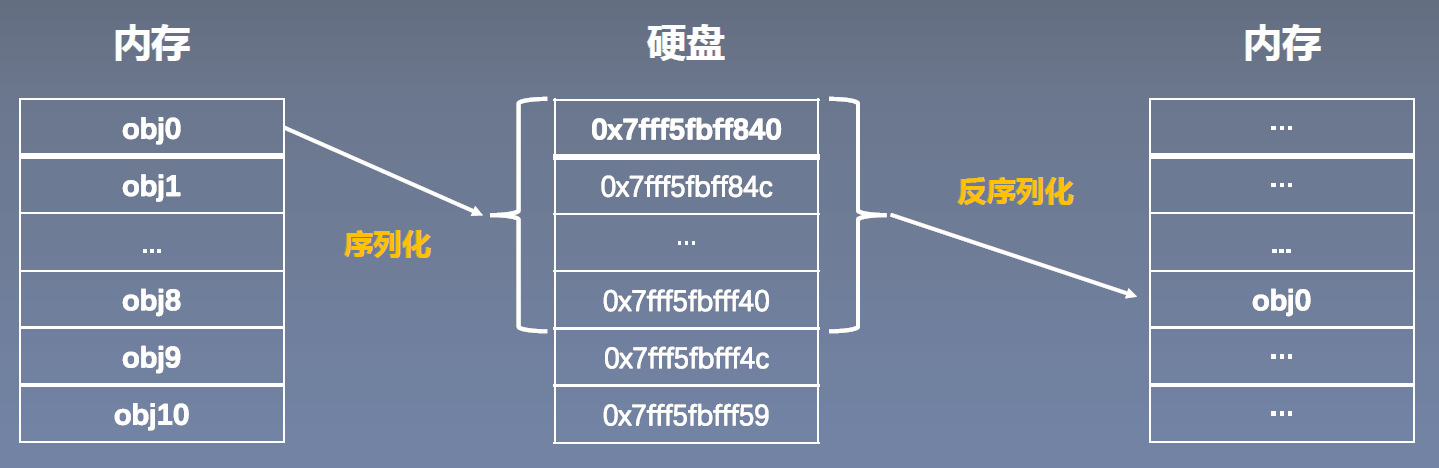
- 序列化是指将内存中的某一个对象保存在硬盘当中,以二进制序列的方式存储下来
- 反序列化是指将存储的这些二进制数反序列化的放到内存当中作为一个对象
序列化和反序列化的目的就是将我们的模型长久的保存。
pytorch中序列化和反序列化的方法:
(1)torch.save
功能:序列化
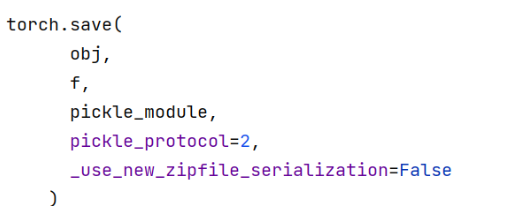
| 参数 | 含义 |
|---|---|
| obj | 表示对象,也就是我们想要保存的数据,模型、张量等 |
| f | 表示输出的路径 |
(2)torch.load
功能:序列化

| 参数 | 含义 |
|---|---|
| f | 表示文件的路径 |
| map_location | 表示指定存放位置, CPU或者GPU |
1.2 保存加载模型基本用法
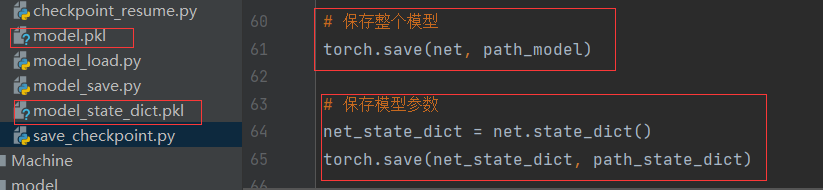
Pytorch的模型保存有两种方法, 一种是保存整个Module, 另外一种是保存模型的参数。
- 保存和加载整个Module: torch.save(net, path), torch.load(fpath)
- 保存模型参数: torch.save(net.state_dict(), path), net.load_state_dict(torch.load(path))
1.2.1 保存模型
在上一节中,我们也提到了torch.save()和torch.load(),现在再来看看是怎么使用torch.save()。
测试代码:
import torch
import numpy as np
import torch.nn as nn
import random
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
class LeNet2(nn.Module):
def __init__(self, classes):
super(LeNet2, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
def initialize(self):
for p in self.parameters():
p.data.fill_(20191104)
net = LeNet2(classes=2019)
# "训练"
print("训练前: ", net.features[0].weight[0, ...])
net.initialize()
print("训练后: ", net.features[0].weight[0, ...])
path_model = "./model.pkl"
path_state_dict = "./model_state_dict.pkl"
# 保存整个模型
torch.save(net, path_model)
# 保存模型参数
net_state_dict = net.state_dict()
torch.save(net_state_dict, path_state_dict)
运行结果:
1.2.2 加载模型
上面保存加载的 net.pkl其实一个字典,通常包含如下内容:
- 网络结构:输入尺寸、输出尺寸以及隐藏层信息,以便能够在加载时重建模型。
- 模型的权重参数:包含各网络层训练后的可学习参数,可以在模型实例上调用
state_dict()方法来获取,比如前面介绍只保存模型权重参数时用到的model.state_dict()。 - 优化器参数:有时保存模型的参数需要稍后接着训练,那么就必须保存优化器的状态和所其使用的超参数,也是在优化器实例上调用
state_dict()方法来获取这些参数。 - 其他信息:有时要保存一些其他的信息,比如
epoch,batch_size等超参数。
(1)加载整个网络
path_model = "./model.pkl" # 这里是保存pkl格式文件的路径
net_load = torch.load(path_model)
(2)加载模型参数
path_state_dict = "./model_state_dict.pkl" # 这里是保存pkl格式文件(模型参数字典)的路径
state_dict_load = torch.load(path_state_dict) # 加载模型参数
net_new = LeNet2(classes=2019) # 新建立一个网络
net_new.load_state_dict(state_dict_load) # 传入加载的模型参数
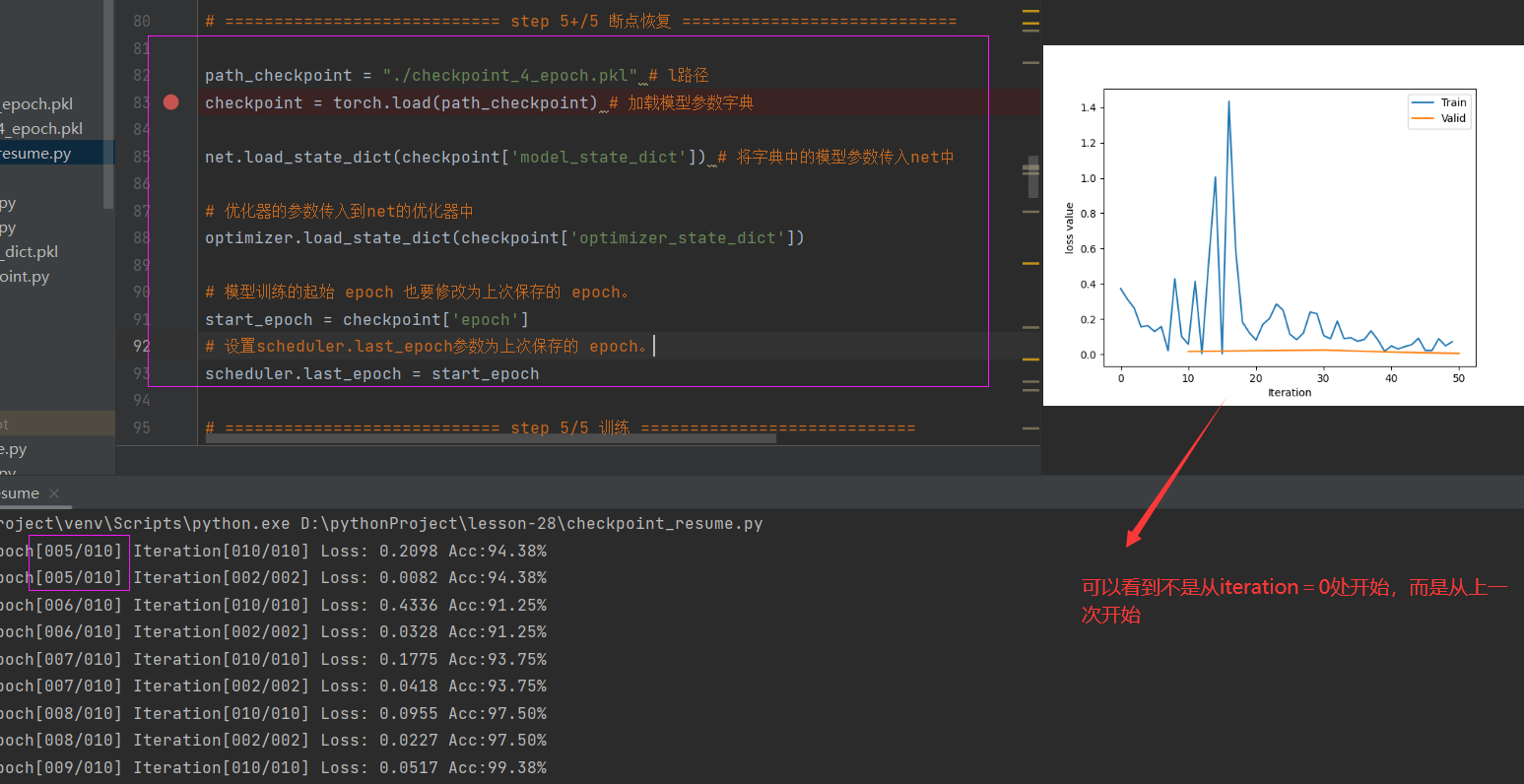
1.3 模型的断点续训练
在训练过程中,可能由于某种意外原因如欠费(针对云端训练)导致训练终止,这时需要重新开始训练。断点续训练是在训练过程中每隔一定次数的 epoch 就保存模型的参数和优化器的参数,这样即使出现意外而终止训练,下次也可以重新加载最新的模型参数和优化器的参数,在这个基础上继续训练。所以模型训练过程中设置checkpoint也是非常重要的。
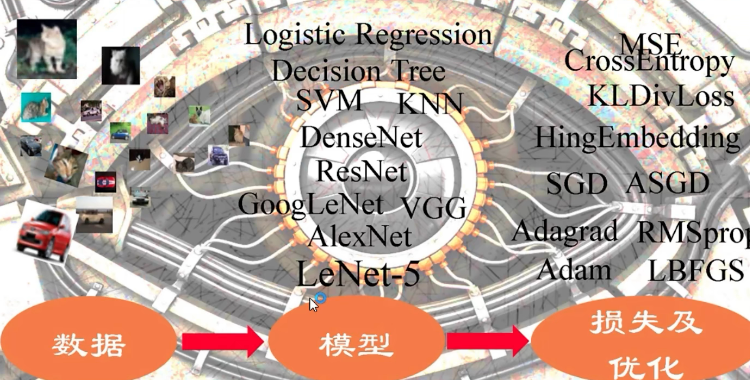
我们回顾一下模型训练的步骤图:

由上图可以看到模型训练的五个步骤: 数据 -> 模型 -> 损失函数 -> 优化器 -> 迭代训练这五个步骤,其中数据和损失函数是没法改变的,而在迭代训练的过程中模型的一些可学习参数和优化器中的一些缓存是会变的,所以需要保留这些信息,另外还需要保留迭代的次数,如下:

下面仍然通过人民币二分类的实验,模拟一个训练过程中的意外中断以及恢复的过程,看看断点续训练是怎么使用的:
部分测试代码:
# 以下为保存模型参数字典部分代码
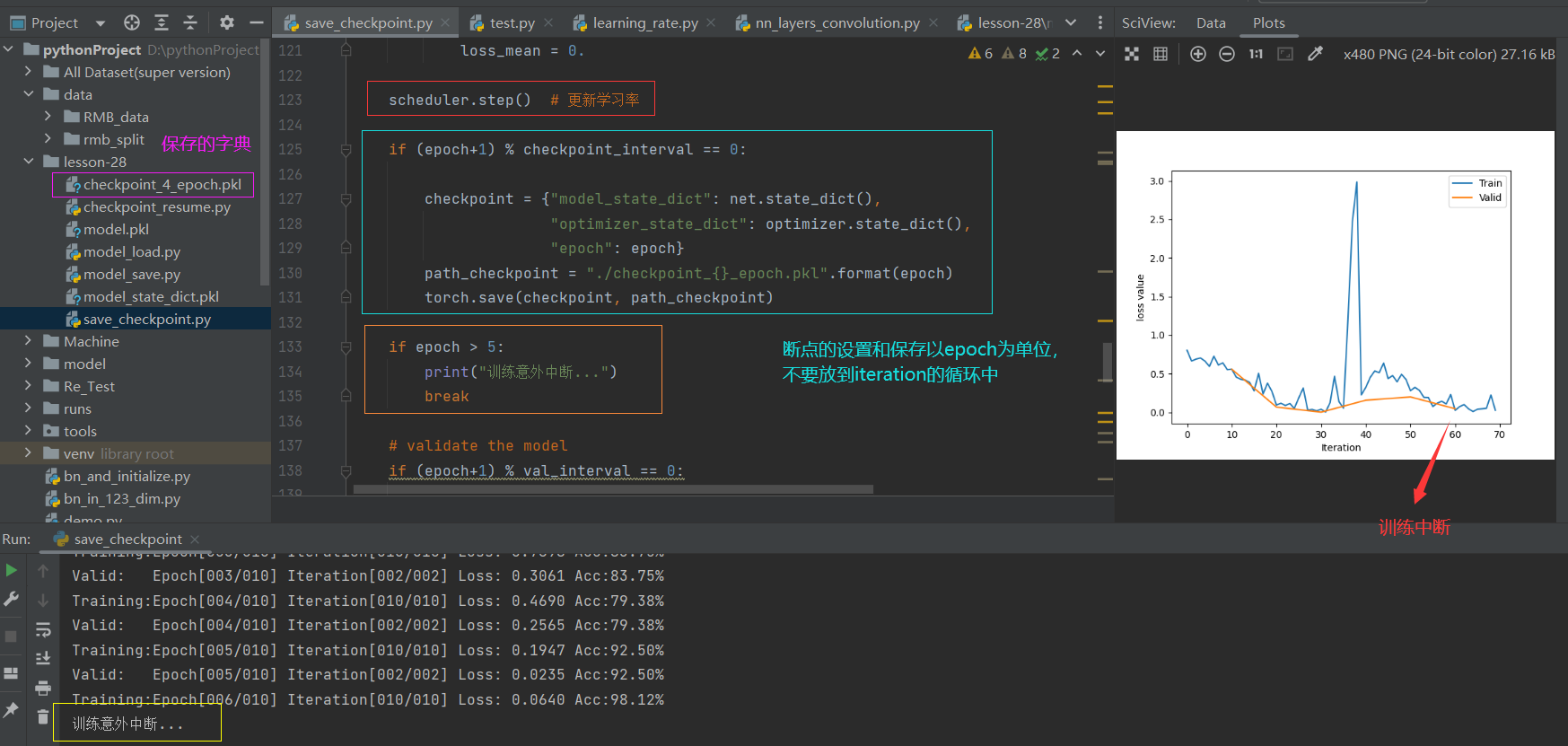
scheduler.step() # 更新学习率
if (epoch+1) % checkpoint_interval == 0:
# 设置断点需要保存那些模型参数
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch}
# 根据epoch来命名
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
# 保存模型参数
torch.save(checkpoint, path_checkpoint)
if epoch > 5:
print("训练意外中断...")
break
# 以下为断点恢复部分代码
path_checkpoint = "./checkpoint_4_epoch.pkl" # l路径
checkpoint = torch.load(path_checkpoint) # 加载模型参数字典
net.load_state_dict(checkpoint['model_state_dict']) # 将字典中的模型参数传入net中
# 优化器的参数传入到net的优化器中
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# 模型训练的起始 epoch 也要修改为上次保存的 epoch。
start_epoch = checkpoint['epoch']
# 设置scheduler.last_epoch参数为上次保存的 epoch。
scheduler.last_epoch = start_epoch
 由于设置断点并且保存,那么下面就尝试恢复并从断点处进行训练,也就第6个epoch开始,看看怎么断点续训练:
由于设置断点并且保存,那么下面就尝试恢复并从断点处进行训练,也就第6个epoch开始,看看怎么断点续训练:
二、模型微调
2.1 Transfer Learning & Model Finetune
在说模型的finetune之前,得先知道迁移学习。迁移学习(Transfer Learning ): 机器学习分支, 研究源域的知识如何应用到目标域,用来提升目标模型的性能。
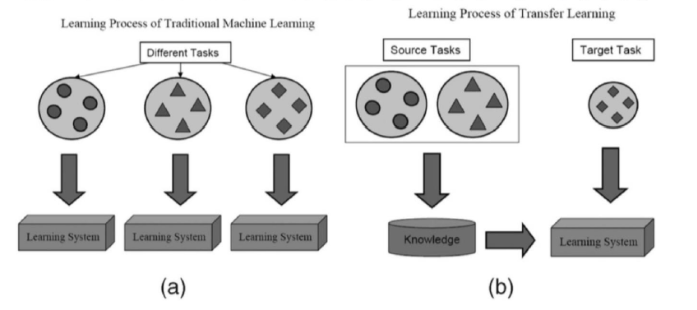
以下便是一个迁移学习的栗子:
滤波器能改变照片的颜色风格,从而使风景照更加锐利或者令人像更加美白。但一个滤波器通常只能改变照片的某个方面。如果要照片达到理想中的风格,可能需要尝试大量不同的组合。这个过程的复杂程度不亚于模型调参。
风格迁移(style transfer)可以自动将一个图像中的风格应用在另一图像之上。首先我们需要两张输入图像:一张是内容图像,另一张是风格图像。然后我们将使用神经网络修改内容图像,使其在风格上接近风格图像。下面的内容图像是李沫老师在西雅图郊区的雷尼尔山国家公园拍摄的风景照,而风格图像则是一幅主题为秋天橡树的油画。最终输出的合成图像应用了风格图像的油画笔触让整体颜色更加鲜艳,同时保留了内容图像中物体主体的形状。

模型微调(Fine-Tuning)是迁移学习的一个技巧,应用时一般根据任务修改最后一个全连接层的输出神经元个数(也就是不需要修改全连接层之前的参数,需要被固定)。 但是一定要注意,只能在类似任务上模型迁移(不要试图将一个NLP的模型迁移到CV里面去)。
微调的步骤如下:
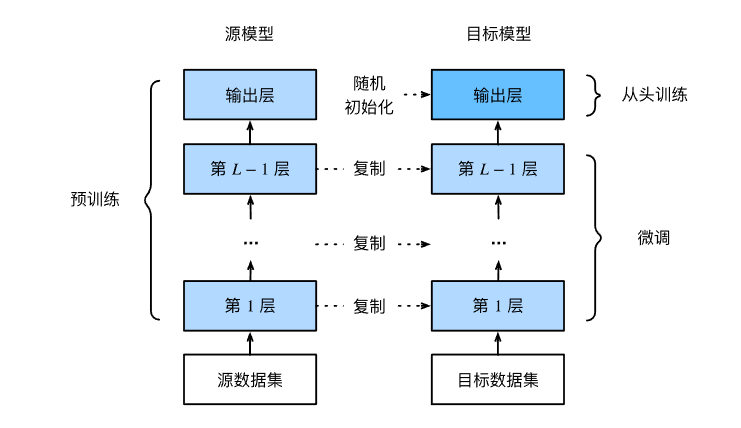
- 在源数据集上预训练神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
- 向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
- 在目标数据集上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
模型微调的训练方法:
- 固定预训练的参数 (requires_grad=False; lr=0)
- Features Extractor 较小学习率 (params_group)
下面我们来使用训练好的ResNet-18进行蚂蚁和蜜蜂二分类。
2.2 Finetune的实例

该数据集训练数据有120张,验证数据有70张,训练数据太少,所以用模型重新训练可能达不到想要的效果,这里用迁移学习,用已经训练好的ResNet-18来完成这个二分类任务。
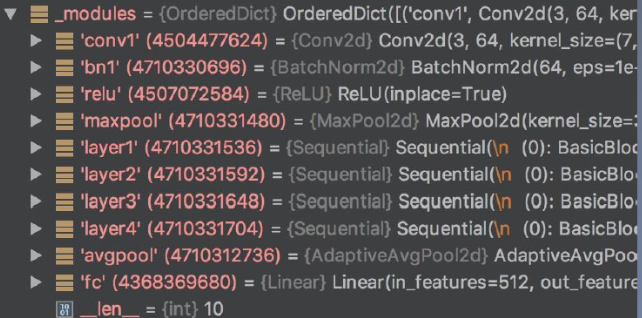
Resnet18的结构:
部分测试代码:
# 1/3 构建模型
resnet18_ft = models.resnet18() # 建立Resnet18,随机参数
# 2/3 加载参数
path_pretrained_model = os.path.join("finetune_resnet18-5c106cde.pth") # 路径
state_dict_load = torch.load(path_pretrained_model) # 加载预训练模型的参数字典
resnet18_ft.load_state_dict(state_dict_load) # 传入模型字典参数
# 冻结层卷积层(特征提取层), 全连接层的参数不结掉
for param in resnet18_ft.features.parameters():
# for param in resnet18_ft.parameters():
param.requires_grad = False
print("conv1.weights[0, 0, ...]:\n {}".format(resnet18_ft.conv1.weight[0, 0, ...]))
# 3/3 替换fc层
# 修改resnet18的全连接层,把神经元的个数换成我们需要的个数(即classes的个数)
num_ftrs = resnet18_ft.fc.in_features # 最后一个全连接层的输入个数
resnet18_ft.fc = nn.Linear(num_ftrs, classes)
resnet18_ft.to(device) # 放到device上训练(GPU或者CPU)
此外,训练时的技巧还有第二个,就是不冻结前面的层,而是修改前面的参数学习率:我们可以把网络的前面和后面分成不同的参数组,使用不同的学习率进行训练。
部分测试代码:
# Resnet18的全连接层的参数
fc_params_id = list(map(id, resnet18_ft.fc.parameters())) # 返回的是parameters的 内存地址
# Resnet18的卷积层(特征提取层)的参数
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())
# 优化器的参数组,可以发现前面特征提取层的参数的学习率为0,即被冻结了(不训练),也可以设置一个很小的数;后面的全连接层的参数可以设置一个较大的数
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0}, # 0
{'params': resnet18_ft.fc.parameters(), 'lr': LR}], momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
测试结果:
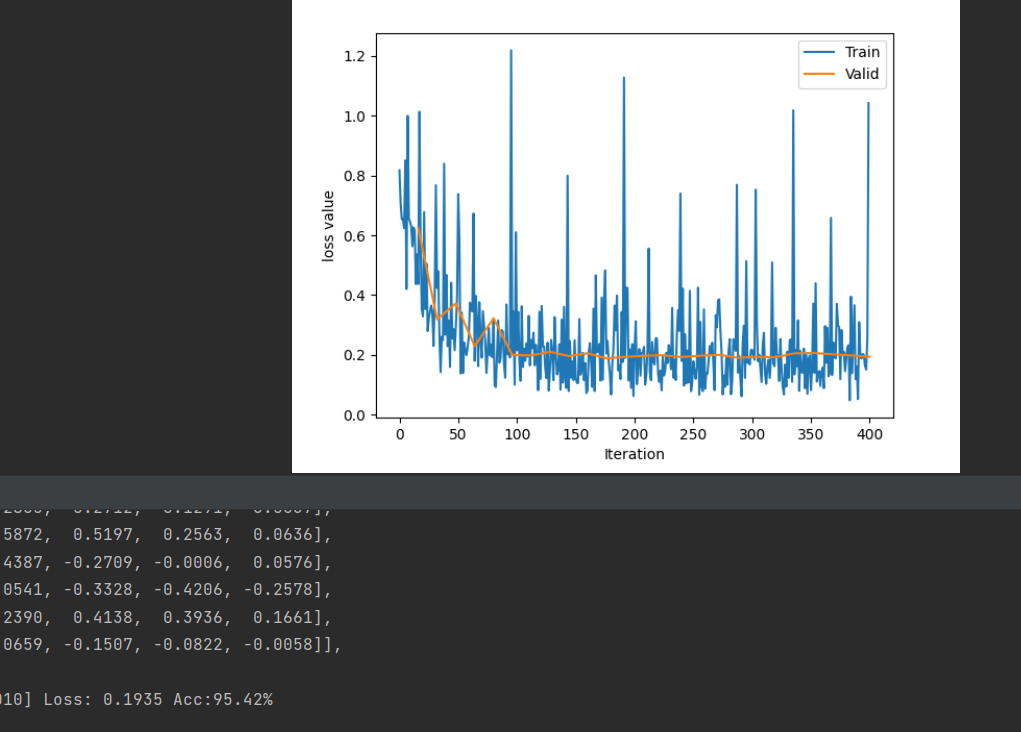
通过模型的迁移,可以发现这个任务完成得不错,准确率能达到95%。
三、GPU的使用
3.1 CPU VS GPU
CPU(Central Processing Unit,中央处理器):主要包括控制器和运算器
GPU(Graphics Processing Unit,图形处理单元):处理统一的,无依赖的大规模数据运算
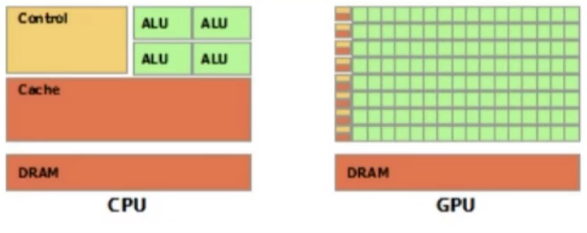
3.2 数据迁移至GPU
首先, 这个数据主要有两种: Tensor和Module
- CPU -> GPU: data.to(“cpu”)
- GPU -> CPU: data.to(“cuda”)
to函数: 转换数据类型/设备
(1)tensor.to(*args, **kwargs)
测试代码:
import torch
x = torch.ones((3,3))
x = x.to(torch.float64) # 转换数据类型
x = torch.ones((3,3))
x = x.to("cuda") # 设备转移
(2)module.to(*args, **kwargs)
测试代码:
import torch
linear = nn.Linear(2,2)
linear.to(torch.double) # 将可学习参数的数据类型变成float64
gpu1 = torch.device("cuda")
linear.to(gpu1) # 把模型从CPU迁移到GPU
关于二者的区别,先贴上测试代码:
import torch
import torch.nn as nn
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 如果GPU可用就用GPU计算
print(device)
# ========================== tensor to cuda============================
x_cpu = torch.ones((3, 3))
print("x_cpu:\ndevice: {} is_cuda: {} id: {}".format(x_cpu.device, x_cpu.is_cuda, id(x_cpu)))
x_gpu = x_cpu.to(device)
print("x_gpu:\ndevice: {} is_cuda: {} id: {}".format(x_gpu.device, x_gpu.is_cuda, id(x_gpu)))
# ========================== module to cuda============================
net = nn.Sequential(nn.Linear(3, 3))
print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
net.to(device)
print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))
运行结果:
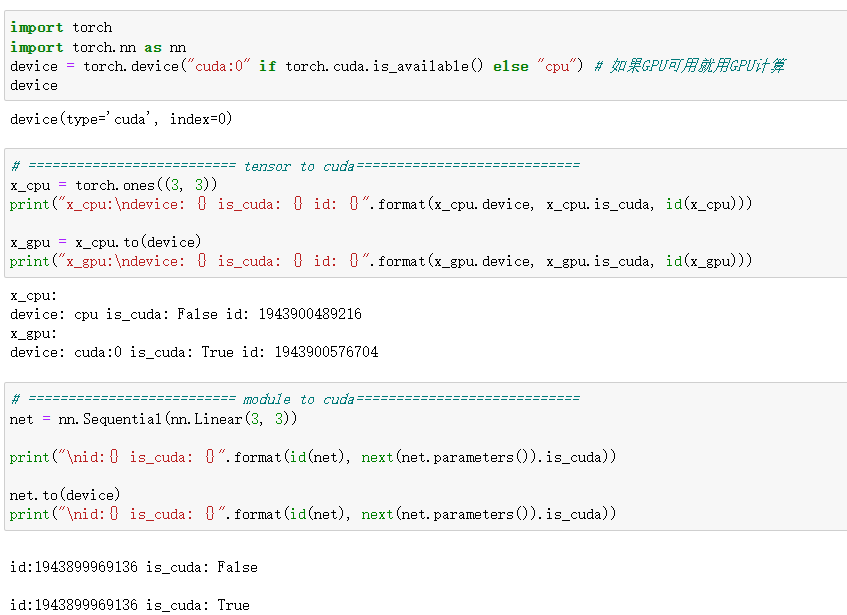
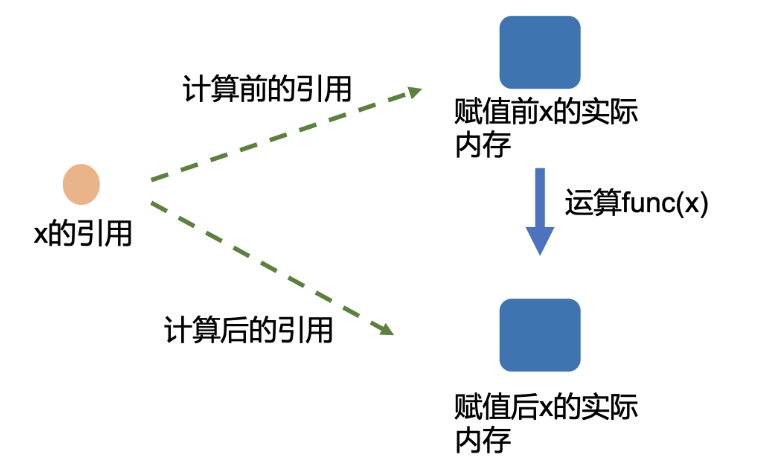
由上述结果我们可以发现张量tensor不执行inplace, 所以上面看到需要等号重新赋值,而模型执行inplace, 所以不用等号重新赋值。关于inplace,实际上python的变量名是一个类似索引的东西,其指向内存中的一个对象。该变量重新赋值实际上是将该变量名指向内存中的其它对象,原对象本身其实并未改变。而Inplace操作并非如此,该操作会直接改变原对象的内容,这样能减少内存的消耗,但也会带来一些隐患。参考博客:Pytorch中inplace操作
非inplace操作:
inplace操作:
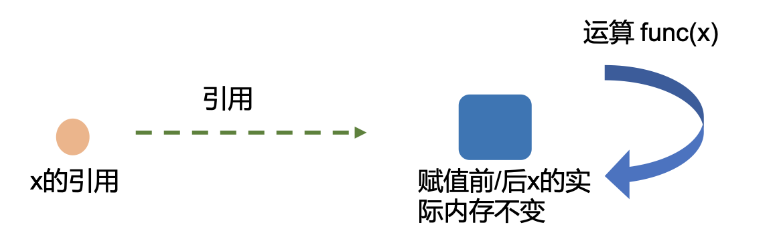
同时还要注意数据和模型必须在相同的设备上。如果模型在GPU上, 那么数据也必须在GPU上。
torch.cuda常用的方法:
torch.cuda.device_count(): 计算当前可见可用的GPU数torch.cuda.get_device_name(): 获取GPU名称torch.cuda.manual_seed(): 为当前GPU设置随机种子torch.cuda.manual_seed_all(): 为所有可见可用GPU设置随机种子torch.cuda.set_device(): 设置主GPU(默认GPU)为哪一个物理GPU(不推荐)
推荐的方式是设置系统的环境变量:os.environ.setdefault("CUDA_VISIBLE_DEVICES", "2,3")通过这个方法合理分配GPU。这句话地意思就是设置物理GPU2和物理GPU3为逻辑GPU(物理GPU指的是实际参与运算的GPU),由于这里有两块GPU,那么各自对应逻辑GPU0和逻辑GPU1(注意:物理GPU和逻辑GPU的索引都是从0开始的)
如果执行os.environ.setdefault("CUDA_VISIBLE_DEVICES", "0,3,2")呢?这样的话物理GPU0对应逻辑GPU1,物理GPU3对应逻辑GPU1,物理GPU2对应逻辑GPU2。主GPU的概念,通常指的是GPU0,在下面多GPU并行运算会解释。
3.3 多GPU并行运算
多GPU并行运算, 简单的说就是使用多块GPU进行计算。举个例子,现在有4块GPU, 里面有个主GPU,传入样本数据后主GPU会先执行一个分配任务。比如主GPU拿到了16个样本数据, 那么它会经过16/4=4的运算,把数据分成4份, 自己留一份,然后把那3份分发到另外3块GPU上进行运算, 等其他的GPU算完了之后, 主GPU再把结果收回来负责整合。所以, 多GPU并行运算可以分为三步:分发 -> 并行计算 -> 整合。
pytorch中多GPU并行运算机制的实现torch.nn.DataParallel
功能:包装模型,实现分发并行机制。
 *
*
| 参数 | 含义 |
|---|---|
| module | 需要包装分发的模型 |
| device_ids | 可分发的gpu, 默认分发到所有的可见可用GPU, 通常这个参数不管它,而是在环境变量中管这个。 |
| output_device | 结果输出设备, 通常是输出到主GPU |
测试代码:
import os
import numpy as np
import torch
import torch.nn as nn
# ============================ 选择gpu
gpu_list = [0] # 选定主GPU
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果有GPU就用GPU进行计算
# 定义一个model
class FooNet(nn.Module):
def __init__(self, neural_num, layers=3):
super(FooNet, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
def forward(self, x):
print("\nbatch size in forward: {}".format(x.size()[0]))
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
return x
if __name__ == "__main__":
batch_size = 16
# data
inputs = torch.randn(batch_size, 3)
labels = torch.randn(batch_size, 3)
inputs, labels = inputs.to(device), labels.to(device)
# model
net = FooNet(neural_num=3, layers=3)
net = nn.DataParallel(net) # 使用DataParallel进行模型包装来实现并行计算
net.to(device)
# training
for epoch in range(1):
outputs = net(inputs) # 这一步会进行样本的分发
print("model outputs.size: {}".format(outputs.size()))
print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
print("device_count :{}".format(torch.cuda.device_count()))
运行结果:(由于我的Computer只有一块GPU
,所以device_count的个数为1;可见GPU的索引CUDA_VISIBLE_DEVICES为0,也就是主GPU)

多GPU服务器上的运行结果:

下面代码是多GPU训练的时候,查看每一块GPU的缓存:
def get_gpu_memory():
import platform
if 'Windows' != platform.system():
import os
os.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')# -q 表示查询 -d Memory表示内存信息 grep表示查询 Free表示有空余,其实就是查询Memory有空余的GPU的信息,然后输出到tmp.txt文件
memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]# 逐行读取,然后执行split后转换为int
os.system('rm tmp.txt')# 删除临时的tmp.txt文件,rm表示删除
else:
memory_gpu = False
print("显存计算功能暂不支持windows操作系统")
return memory_gpu
gpu_memory = get_gpu_memory()
if not gpu_memory:
print("\ngpu free memory: {}".format(gpu_memory))
gpu_list = np.argsort(gpu_memory)[::-1] # 排序,为了将所剩Memory最多的GPU设置为主GPU
gpu_list_str = ','.join(map(str, gpu_list)) # 转换成list,每个元素是str类型
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str) # 设置GPU为有空余的
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
GPU模型加载常见的两个问题

这个报错是因为训练模型是以cuda的形式进行保存的,但保存完后在一个没有GPU的机器上使用这个模型,就会报上面的错误。解决办法是修改参数如下:torch.load(path_state_dict, map_location="cpu"), 这样便可以在CPU设备上加载GPU上保存的模型。

这个报错是因为在使用多GPU进行并行运算的时候,调用DataParallel对数据进行包装的时候,使得每一层的参数名称前面会加了一个module.的前缀,导致参数不匹配所以不能够调用,于是便有了上述的报错。这时候需要重新创建一个字典,把名字改好后再导入。
下面看看怎么报错的:
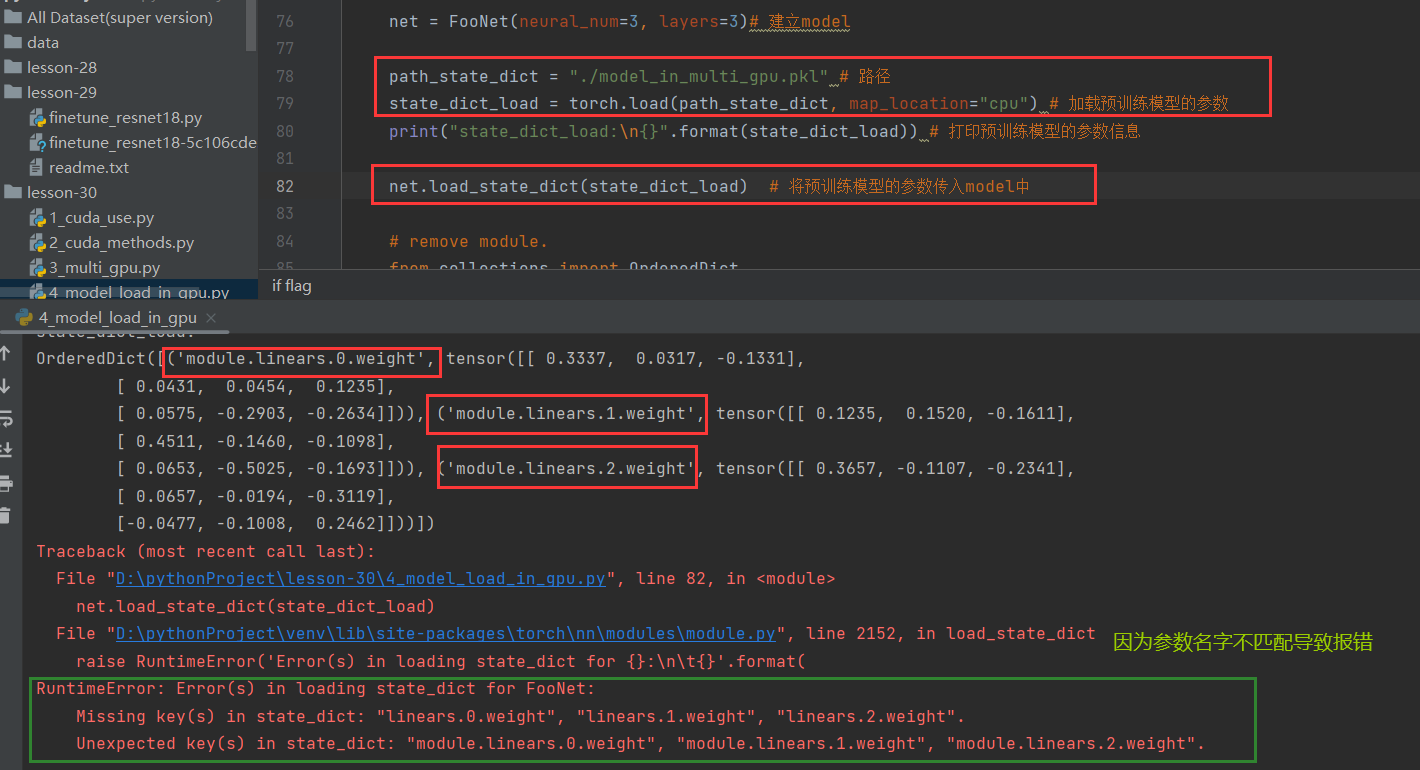
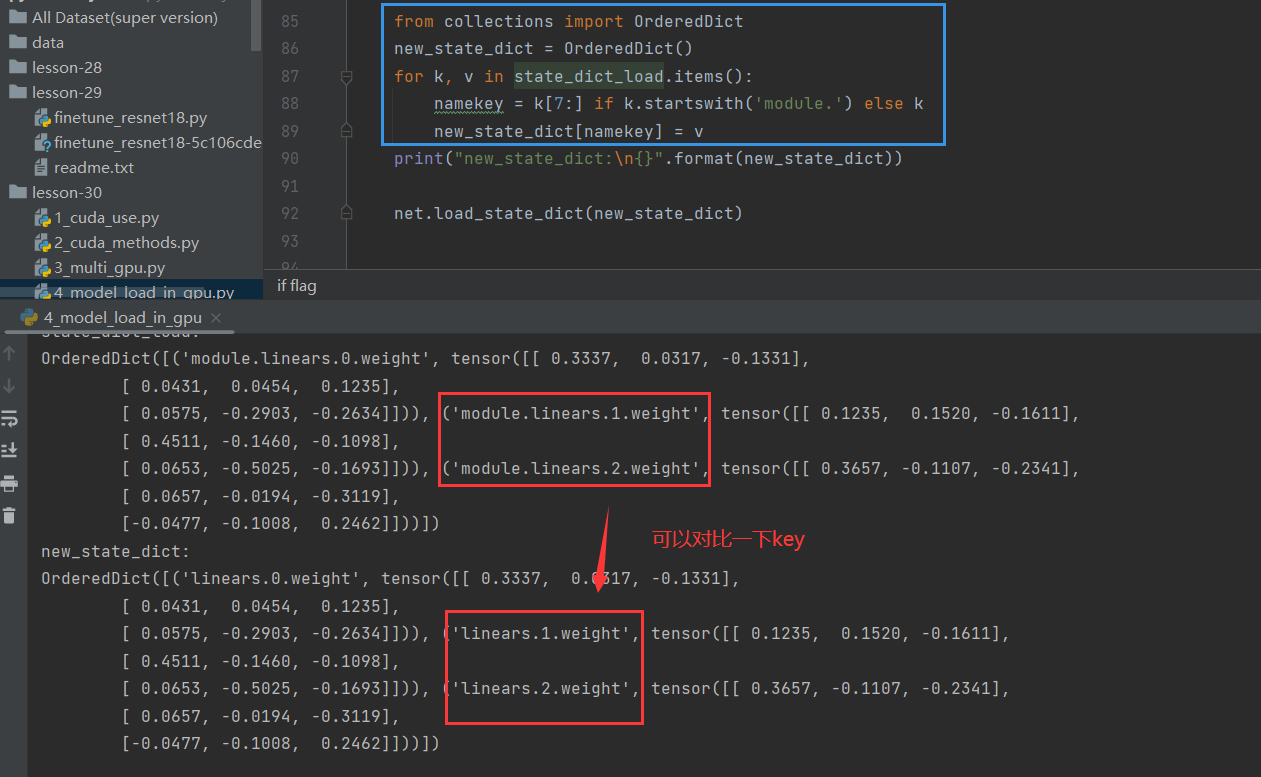
解决办法:(去掉前面的”module.“)
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_load.items(): # 遍历有序字典,k是key,v是value
namekey = k[7:] if k.startswith('module.') else k # 如果k是'module.'开头,则去掉;否则k不变
new_state_dict[namekey] = v 给v赋值(与原来的字典保持一致)
print("new_state_dict:\n{}".format(new_state_dict))
net.load_state_dict(new_state_dict)
运行结果:
这里面目前有一些常见的报错信息,可以查看:Pytorch常见错误
四、总结
首先第一部分学习了模型的保存与加载,介绍了两种模型保存与加载的方法, 然后迁移学习以及模型的微调技术,还介绍了迁移学习中常用的两个技巧。 第二部分学习了如何使用GPU加速训练和GPU并行训练方式, 最后贴上了Pytorch中常见的几种报错信息文档。
下面对Pytorhc的博客进行一个总结,这些博客主要围绕着机器学习模型训练的五大步骤进行展开的: 首先是先了解Pytorch的基本知识,学习了张量, 自动求导系统,计算图机制等。 对Pytorch有了一个基本的了解之后,就开始学习数据模块中的数据读取机制,了解了nn中的DataLoader和Dataset,还学习了图像预处理的模块transform。然后接着学习如何搭建一个模型,以及模型如何初始化,还学习了容器、常用网络层的使用。 然后就是网络层的权重初始化方法和损失函数。学习了损失函数后,就可以学习各种优化器来更新参数, 还有学习率调整的策略。于是,在凑齐了上述积木后,就可以进行迭代训练了,在迭代训练过程中还了解了Tensorboard。然后学习了正则化和标准化技术, 正则化是缓解模型的策略,在正则化一文中学习了L1,L2和Dropout的原理和使用,而标准化可以更好的解决数据尺度不匹配的问题。有BN, LN, IN, GN四种标准化方法,并对比了它们的不同及应用场景。 最后以本文作为收尾,本文学习了模型的保存加载,模型微调,如何使用GPU。 这便是一个大致的总结了。可以用下图来总结下:
当然了,这些基础知识只是能够入门Pytorch而已,但可以保障我们看到相应的概念的时候不至于什么都不明白,有这一步是非常重要的。当然啦,如果你说想一下子手写神经网络,仅仅看这些博客还是不够的,这需要非常多的训练以及阅读非常多的专业论文,但是也不要气馁,只要照着代码和论文反复训练,反复思考和钻研,然后多做项目,我相信你一样也可以在未来成为一个深度学习的大神呢~好了,写到这里,我还得去看论文啦。以上便是我对Pytorch的一个回顾。
参考博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!