【Datawhale 大模型基础】第九章 新的模型架构
第九章 新的模型架构
It is very easy to consider two categories of improving the performance of LLMs: Mixture-of-Experts (which has been mentioned in Chapter six) and Retrieval-Augmented LLM. This blog is based on datawhale files. And I will discuss something about Retrieval-Augmented LLM.
For the original study files, it illustrates some paper of Retrieval-Augmented LLM, and I’d like to discuss another one: REALM.
Pre-trained language models can learn a lot of common knowledge from unsupervised textual corpora. However, this knowledge is stored in the parameters and has the following two drawbacks:
- This knowledge is implicit, making it difficult to explain the knowledge stored and used by the model.
- The amount of knowledge learned by the model is related to the size of the model (number of parameters), so in order to learn more knowledge, the model size needs to be increased.
This paper proposes REALM, which introduces a retrieval module, as shown in the following figure:
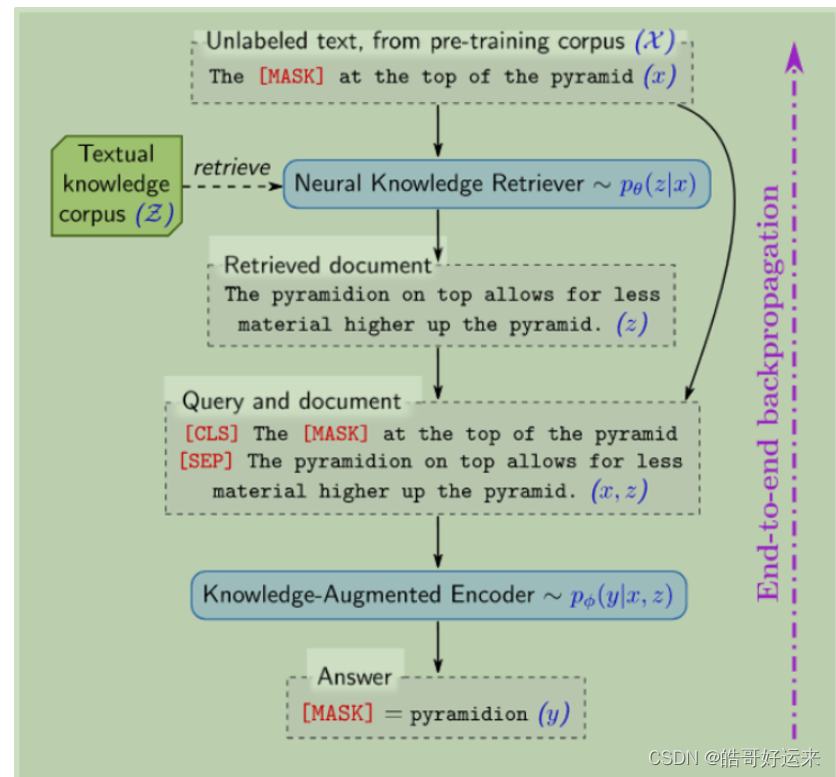
- First, sample from the pre-training corpus and mask some tokens (the [MASK] at the top of the pyramid).
- Through the retrieval module, retrieve documents from an external knowledge base (such as Wikipedia) based on the sample to help recover the masked token (The pyramidion on top allows for less material higher up the pyramid).
- Use information from the sample and the retrieved documents to jointly predict the masked token (pyramidion).
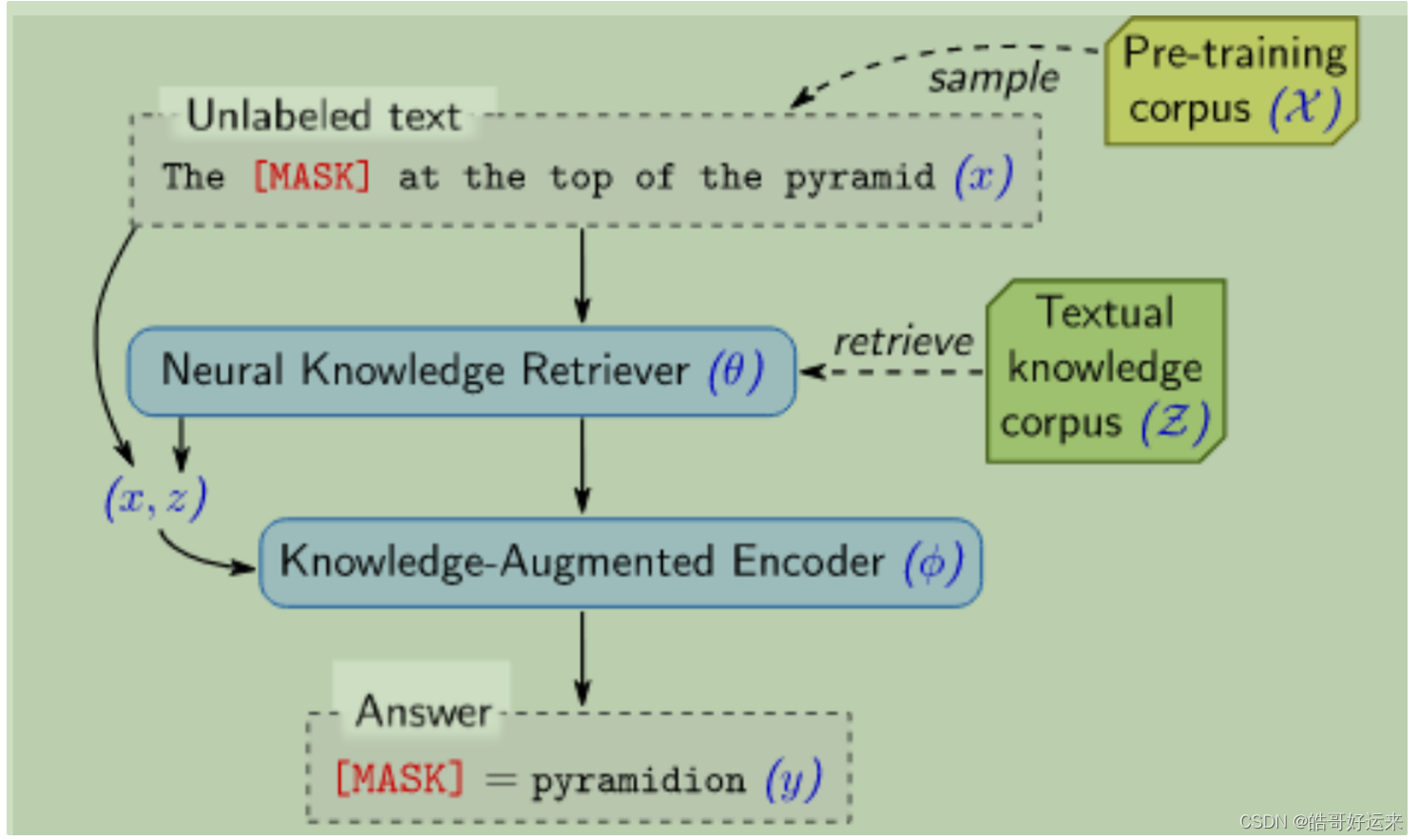
The model proposed in this paper is called REALM (REtrieval Augmented Language Model), which models both the pre-training and fine-tuning of the model as a process of retrieve-then-predict. The language model pre-training involves predicting the masked token based on the masked sentence, i.e., modeling p ( y ∣ x ) p(y|x) p(y∣x). Traditional language models like BERT directly model p ( y ∣ x ) p(y|x) p(y∣x) using a single network. However, this paper divides it into two steps, first based on x x x to retrieve document z : p ( z ∣ x ) z:p(z|x) z:p(z∣x), then using x x x and z z z to generate answers. The authors consider z z z as a latent variable and model the final task objective p ( y ∣ x ) p(y|x) p(y∣x) as the marginal probability for all potential documents:
p ( y ∣ x ) = ∑ z ∈ Z p ( y ∣ z , x ) p ( z ∣ x ) p(y|x)=\sum_{z\in Z}p(y|z,x)p(z|x) p(y∣x)=z∈Z∑?p(y∣z,x)p(z∣x)
During the pre-training phase, the task is MLM, which involves recovering the masked token.
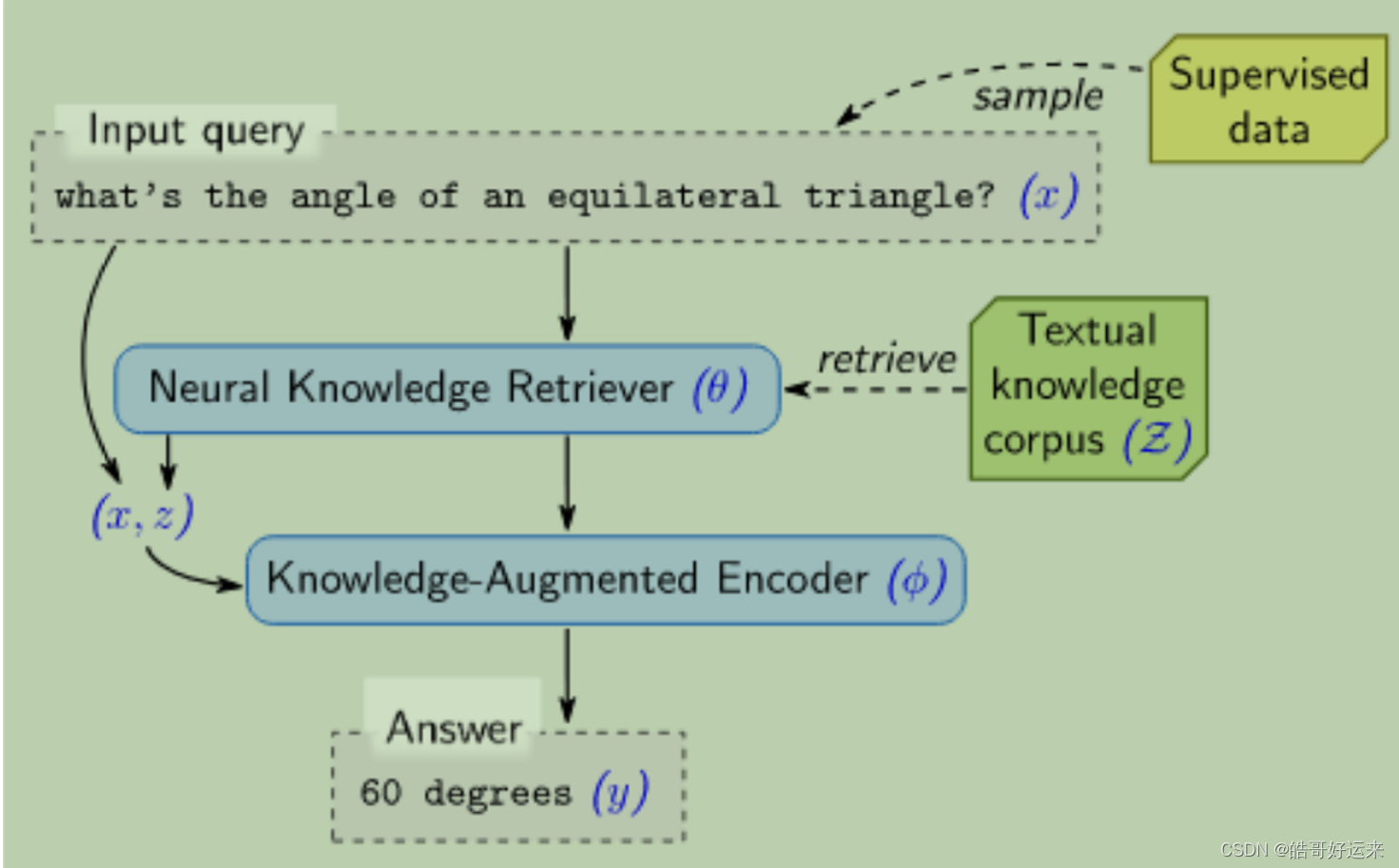
During the fine-tuning phase, the task is Open-domain QA, where
x
x
x represents a question. The authors assume that the answer can be found at certain positions (spans) in
z
z
z, and thus model it as a task of predicting the span:
A key issue is that the number of documents is extremely large, and computing the above equation will be very time-consuming. The solution is to only consider the top-k most relevant documents. The authors believe this approximation is reasonable because the vast majority of documents in the external document library are irrelevant to the input, with their probability
p
(
z
∣
x
)
p(z|x)
p(z∣x) being almost 0.
Even with this approximation, finding the top-k most relevant documents from the document library still requires a huge amount of computation. This paper uses the Maximum Inner Product Search (MIPS) algorithm to find the top-k most relevant documents (the external knowledge base consists of approximately 13,000,000 candidate documents from Wikipedia).
To use MIPS, it is necessary to pre-calculate the embedding for all documents and then build an index. However, because the parameters of the retriever are constantly being updated, the MIPS index should also be constantly refreshed, which is very time-consuming, as updating the index requires recalculating the embeddings of the document library and then updating the MIPS index for each step. The authors’ solution is to refresh the MIPS index only every few steps, as shown in the figure below:
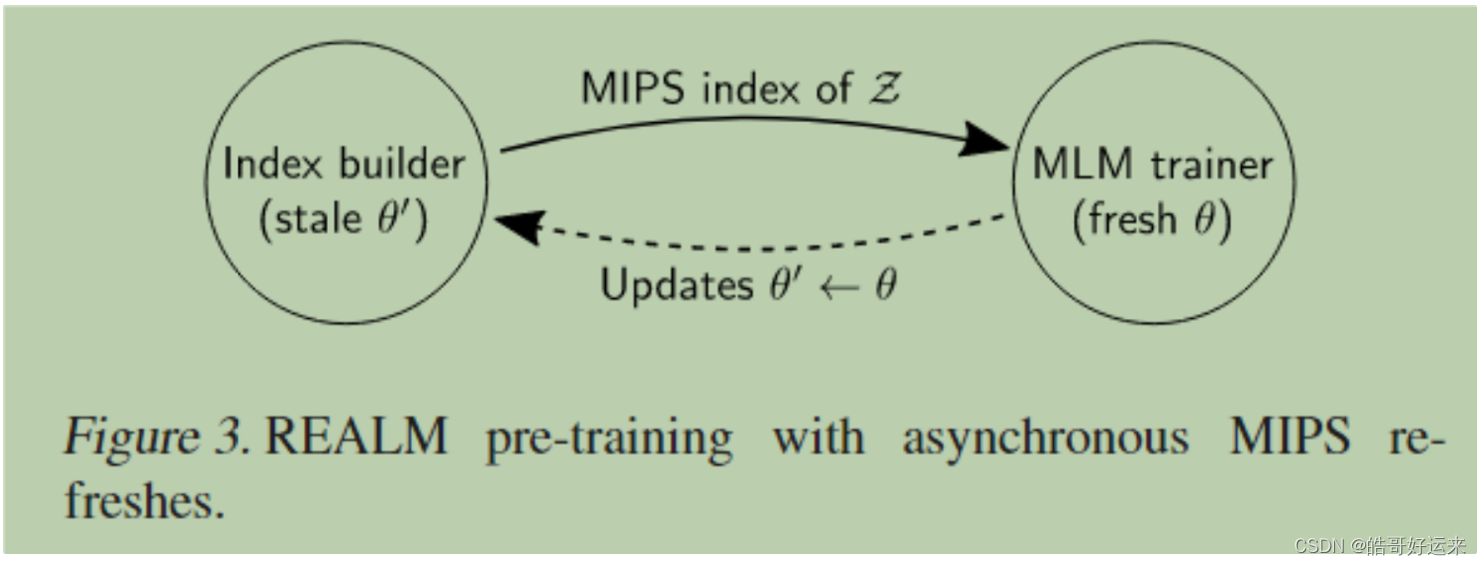 The MIPS index refresh described above is only used during the pre-training phase. During the fine-tuning phase, the MIPS index is only established once at the beginning (using the pre-trained retriever parameters) and is not updated thereafter. This is done for convenience, as the authors believe that the retriever has already learned a good enough representation of document relevance during the pre-training phase. However, the authors believe that if the MIPS index were iteratively updated during the fine-tuning phase, the effect might be even better.
The MIPS index refresh described above is only used during the pre-training phase. During the fine-tuning phase, the MIPS index is only established once at the beginning (using the pre-trained retriever parameters) and is not updated thereafter. This is done for convenience, as the authors believe that the retriever has already learned a good enough representation of document relevance during the pre-training phase. However, the authors believe that if the MIPS index were iteratively updated during the fine-tuning phase, the effect might be even better.
And there are two surveys about Retrieval-Augmented LLM:
- A Survey on Retrieval-Augmented Text Generation, 2022.02, https://arxiv.org/pdf/2202.01110.pdf
- Retrieval-Augmented Generation for Large Language Models: A Survey, 2023.12, https://arxiv.org/pdf/2312.10997.pdf
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!