一文读懂NISQ时代的量子竞赛

/目·录/
一、关于NISQ,业内专家怎么看?
二、NISQ时代的量子硬件资源估算
2.1.?NISQ量子比特要求
2.2.?NISQ计算时间
2.3.?NISQ代码经典模拟
三、主流量子算法“优势”的资源估算
3.1.?用于化学模拟的VQE算法
3.2.?用于组合优化的QAOA算法
3.3.?量子机器学习算法
四、如何解决NISQ QPU目前的弱点?
4.1.?量子比特保真度和能力
4.2.?量子比特连接性
4.3.?量子错误抑制与缓解
4.4.?算法进展
4.5. 扩展模拟量子计算机
4.6.?其他NISQ技术
4.7.?寻找其他量子优势
4.8.?能量
五、从NISQ迈向容错量子计算
六、展望未来的量子计算机:谨慎乐观
2017年12月,约翰·普莱斯基尔(John Preskill)在加利福尼亚州QC Ware公司举办的首届Q2B会议上发表主题演讲,首次定义了NISQ时代,并在2018年发表在《量子》(Quantum)杂志上的一篇论文中进行了阐述。

他说:“拥有50-100量子比特的量子计算机或许能够执行超越当今经典数字计算机能力的任务,但量子门中的噪声将限制能够可靠执行的量子电路的大小[......]。我编了一个词:NISQ。这是‘含噪声的中等规模量子’(Noisy Intermediate-Scale Quantum)的缩写。”
“这里的‘中等规模’指的是未来几年内将出现的量子计算机的规模,其量子比特数从50到几百不等[......]。使用这些噪音较大的设备,我们预计无法执行包含超过约1000个门的电路。”
约翰·普莱斯基尔接着补充说,除了NISQ之外,“即使经典超级计算机运行速度更快,如果量子硬件具有更低的成本和功耗,量子技术也可能成为首选。”
迄今为止,对最后一部分的研究还不多。大多数发表的关于NISQ算法的科学论文都涉及某种形式的计算优势,但没有涉及其他更经济的优势,特别是与能量消耗有关的优势。事实上,我们必须努力寻找一种情况,使NISQ系统有朝一日能产生与一流超级计算机或HPC算法类似的结果,不一定更快,但能耗更低。
各种可能有所帮助的技术,如改进量子比特保真度、各种量子误差缓解方法、模拟/数字混合、使用特定量子比特类型(如多模光子)以及量子退火器和模拟量子计算机(又称量子模拟器或可编程哈密尔顿模拟器),这些技术似乎更接近于提供有用的应用,尽管它们也有自己的中长期可扩展性挑战。
考虑到这些不同解决方案的所有限制因素,我们似乎可以期待NISQ系统出现一些实际用例,但在各种扩展问题出现之前,这个窗口非常狭窄。
展望未来,NISQ需要百来个门保真度远高于99.99%的量子比特,才能在速度或能效上超越传统超级计算机;而FTQC可接受的门保真度较低,约为99.9%,但需要数百万量子比特和超远距离纠缠能力。
这就提出了一个关键问题,即在未来的量子计算机设计中,可能需要在量子比特规模和量子比特保真度之间做出权衡。

最适合NISQ系统的已知量子算法属于广义变分量子算法(VQA)。考虑到现有和不久将来的量子比特门保真度,这些算法的量子电路深度应该较浅,即量子比特门周期数较少,最好在10个以下。
这类算法包括用于量子物理模拟的VQE、用于各种优化任务的QAOA、用于求解线性方程的VQLS以及用于各种机器学习和深度学习的QML。人们还提出了许多其他种类的NISQ VQA算法,特别是在化学模拟和搜索方面。
这些算法大多是启发式算法,可确定各种形式优化问题的近似最优解,VQE、QAOA和QML都是寻找能量或成本函数最小值的各种优化问题。变分算法在设计上是混合型的,其中很大一部分是在经典计算机中实现的,而这本身就是一个NP-hard类问题,会随着输入规模的增大而呈指数级增长。还提出了一些其他非变量NISQ算法,如量子游走。
完全不属于NISQ相关算法的还有整数和离散对数因式分解算法(最著名的算法来自1994年的Peter Shor)、基于oracle的搜索算法(如Grover算法和Simon算法),以及所有依赖量子傅立叶变换的算法,包括线性代数的HHL和许多偏导数方程 (PDE) 求解算法。?
所有这些算法都需要容错量子计算(FTQC)架构,特别是在给定量子比特数的情况下,典型的基于FTQC门的算法的计算深度会随着量子比特数的增加而呈类对数增长。
在空间和速度领域,量子优势至少需要50到100个物理量子比特。然而,空间和速度领域的优势是截然不同的。在某些情况下,30-50个量子比特就能获得一定的速度提升,至少在比较具有完美量子比特、快速门的QPU和在仿真模式下执行相同代码的经典服务器集群时是如此,后者通常不是同类最佳的等效经典解决方案。
在18量子比特以下,甚至建议使用本地量子代码模拟器。这不仅更便宜,而且更快、更方便,因为计算任务不会被放在可能很长的等待列表中,也无需为昂贵的云QPU(量子处理单元)资源访问付费。在这种情况下,笔记本电脑、单个云服务器或服务器集群总是比量子计算机便宜。

各种量子优势的分类标准,包括空间、速度、质量、能量和成本
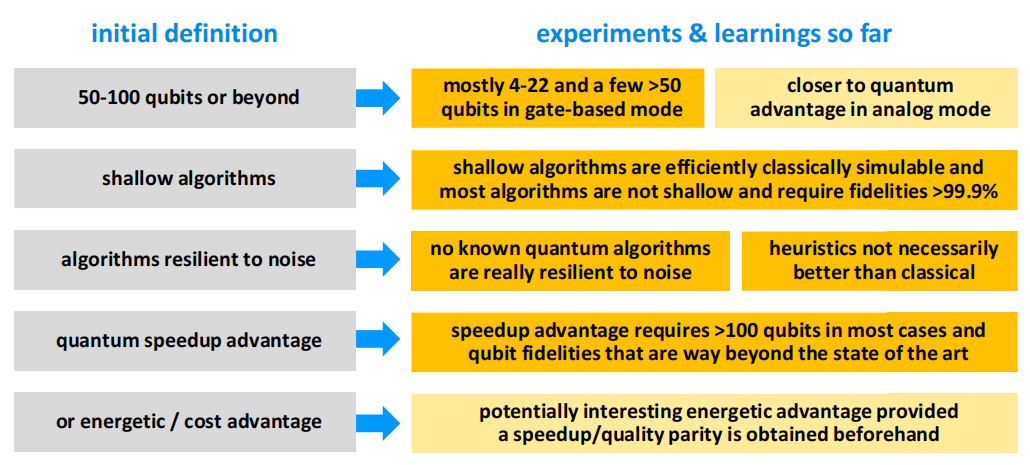
从约翰·普莱斯基尔的NISQ定义到实际实验
迄今为止,大多数NISQ实验都是用少于30个量子比特进行的,因此最好被称为“前 NISQ”。虽然这些实验是对概念的优雅证明,但它们尚未证明比经典计算有任何提速,这意味着它们尚未进入约翰·普莱斯基尔定义的NISQ体系。
量子计算供应商及其生态系统(分析师、服务提供商和一些软件供应商)正在吹嘘“商业量子计算”的到来,这意味着他们的系统已经准备好在黄金时间使用。
由QC Ware公司在硅谷、东京和巴黎举办的Q2B会议就是以“实用量子计算”为主题,世界各地的此类“量子商业”会议大行其道,实际上是在夸大NISQ的企业就绪程度,敦促企业加入量子计算的行列。
供应商有兴趣宣传量子计算准备就绪的故事,至少是为了吸引投资者(因为他们正在筹集资金)和潜在客户,以增加收入,进而帮助获得资金。他们会夸大宣传各种用例,而这些用例的细节在大多数情况下都能以更低的成本部署,甚至可以在传统计算机上更快地运行,通常甚至可以在价值1,000美元的笔记本电脑上运行。
这与模拟量子计算解决方案有些不同,模拟量子计算解决方案更接近于达到一定的量子计算和经济优势,但却无法从同样的市场推动力中获益,至少由于该领域的供应商数量较少(D-Wave、Pasqal、QuEra)。
一些行业供应商,如微软、Alice&Bob、QCI、亚马逊网络服务(AWS)和PsiQuantum,则跳过了NISQ的路线,直接专注于创建容错量子计算机。
科学家们既有谨慎乐观的,也有单纯悲观的。以马里兰大学的丹尼尔·戈特曼(Daniel Gottesman)为例,他在全球风险研究所发布的《2022 年量子威胁时间表报告》中提出了一些见解。他认为:“目前还不清楚是否会有任何有用的NISQ算法:已经提出的许多算法都是启发式的,扩大规模后可能完全不起作用。而那些非启发式的算法,如噪声量子模拟,在真实设备噪声存在的情况下,可能不会产生有用的信息。我认为很有可能会成功并有用,但绝对不确定。”
在2023年2月一篇关于超导量子比特的综述论文中,查尔姆斯大学的戈兰·文丁(G?ran Wendin)直言不讳地指出:“有用的NISQ数字量子优势=不可能完成的任务?简短的回答是:是的,不幸的是,在NISQ时代可能是不可能完成的任务。”
Horizon Quantum ?Computing公司的乔·菲茨西蒙斯(Joe Fitzsimons)也认为:“人们希望这些计算机在进行任何纠错之前就能得到很好的应用,但现在的重点已经从这一点上转移了。”他甚至在2023年1月的预测中指出,NISQ将直接消亡。

翻译成通俗易懂的语言,这就意味着在量子计算机的容错品种出现并以足够的规模运行之前,任何量子计算机都不会有用,而我们至少还要等上十年。

硬件资源和时间估算是量子计算的一门关键学科,甚至还有专门的“QRE研讨会”,它在实际用例、相关算法及其所需的物理资源和计算时间之间架起了一座桥梁。
2022年底,微软发布了一款资源估算软件工具,可用于容错量子计算算法。
同时,对NISQ资源的任何估算都应与解决相同问题所需的经典计算资源估算进行比较。目前,还缺乏此类最佳经典算法计算资源的估算器。我们总是根据具体情况进行分析,并与移动的经典目标进行比较,通常是在不同的情况下,采用或不采用启发式方法。
如果能够量化量子计算机与现有经典解决方案相比的经济成本和效益,那么做出使用量子计算机解决特定问题的 “商业”决策确实会更好。
在经典计算中,“总体拥有成本”(TCO)的概念经常被使用,但由于量子计算技术不够成熟,也没有实际应用案例,因此尚未被采用。TCO不仅包括硬件和软件成本,还包括服务、培训以及各种直接和间接的解决方案生命周期成本。?
不过,研究当前的NISQ文献可以提供一些线索。
1)NISQ量子比特要求
我们将在此探讨成功运行NISQ算法所需的量子比特资源。令人惊讶的是,这并不难评估;有一条经验法则可以确定这些物理资源要求。它将物理量子比特错误率与特定算法的广度和深度联系起来,所考虑的错误率与保真度最低的门相对应,对于大多数量子比特技术来说,这些门都是双量子比特门,如CNOT。
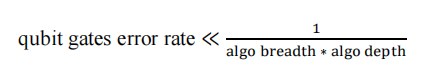
广度与算法中使用的量子比特数相对应,深度与量子门周期数相对应。从量子电路的角度来看,这是一种量子算法量子体积。你可以在这两个维度之间做一些权衡,用更多的量子比特运行一个非常浅的算法,或者用更少的量子比特运行一个更深的算法。如上公式所示,量子比特错误率必须低于计算广度 x 深度的倒数。

基于NISQ门的硬件资源需求
然而,使用现有量子硬件计算这些数字时,你会发现情况并不尽如人意。一方面,要获得一定的量子优势并符合NISQ限制,至少需要50个物理量子比特;另一方面,最浅算法的深度为8量子门周期。
最终,你需要的物理量子比特门保真度约为99.7%,主要适用于双量子比特门和量子比特读出。在本周前,还没有任何一款QPU具有这种超过50个量子比特的双量子比特栅极保真度。拥有72个量子比特的谷歌Sycamore “2022 版”的双量子比特门保真度为99.4%,IBM的2020 Prague/Egret系统更接近这一门槛,33量子比特的保真度为99.66%。
刚刚,IBM在2023年推出的Heron 133量子处理器达到了超99.9%的双量子比特门保真度。纵观所有供应商的路线图,IBM是唯一一家达到这一目标的供应商。
另一个例子是,Rigetti计划创建一个84量子比特的QPU,其双量子比特门保真度仅为99%,随后,336量子比特版本的保真度勉强达到99.5%,这显然不足以运行具有如此多量子位的任何NISQ算法。
行业供应商提供的大多数双量子比特门保真度都是中位数或平均保真度,通常未报告的一个重要指标是它们的标准偏差和最小值。好的中位保真度和高的标准偏差并不实用,特别是对于给定算法的第一个门。高错误率会对大部分运行中的算法造成不可逆转的损害。
一种解决方案是在校准之后,停用相邻的量子比特,因为硬件缺陷会造成“稳定”的双量子比特错误门。不过,即使使用这些平均保真度值,公开的双量子比特门保真度仍然不足以成功运行NISQ算法。
离子阱量子比特的情况也是如此,它们具有非常好的保真度,但似乎很难扩展到几十个量子比特以上,这使得开发人员无法获得与空间相关的计算优势。这些量子比特的驱动速度也太慢,损害了它们在量子优势机制中产生加速的潜力。
在当前的行业供应商计划和路线图中,预计大多数QPU都无法支持NISQ或FTQC所需的超过99.9%的双量子比特门保真度。
最常采用的方案是将多个QPU连接在一起的“向外扩展”方法,这有点像高性能计算(HPC)中使用的分布式并行计算。这些连接必须保持量子比特的整体纠缠和保真度。只有少数几家量子计算公司已经开始下一阶段的工作,可以在开发QPU的同时进行探索。
扩展架构可以使用多种技术,如量子比特之间的微波导引或基于纠缠光子的连接。专门的量子信息网络初创公司,如WelinQ(法国)和QPhoX(荷兰),已经开始建立基于纠缠光子连接的量子链路,还为计算和中间通信缓冲区提供量子存储器功能。
在拥有几百或上千个量子比特的情况下,最终需要99.9% 到99.9999%的门保真度,这对于今天的量子计算机来说显然是遥不可及的,即使是在拥有几个量子比特的实验室环境中也是如此。而且这还忽略了一个事实,即许多需要如此多量子比特的NISQ算法并不一定像那些只需要不到10个门周期的算法那样浅显。
2)NISQ计算时间
另一个需要估算的资源是NISQ算法的总计算时间,包括其经典部分。毕竟,我们正在寻求一些计算速度的提升,但同时也需要与我们的耐心相关的合理计算时间。在量子优势机制下,必须仔细估算其缩放比例,这涉及到各种成本:泡利弦的数量、所追求的精度以及量子错误缓解的指数成本。
无论使用情况和速度如何,NISQ的计算时间都应该是合理的。我们将看到,在量子优势机制下,当它比经典计算更好时,情况未必如此。大多数NISQ变分算法的计算时间都有大量变量,等于 Ni ? It,其中 It = (ct + S ? Qt ),Ni = 变分算法的迭代次数,S ? Qt = 变分算法的迭代次数:
Ni = 变分算法收敛到可接受值的迭代次数。它与具体情况有关,取决于变分算法收敛到预期解的方式。
ct还包括对来自量子计算镜头的数据进行经典后处理所需的时间,以便从反演中生成哈密顿观测值的期望值。它在很大程度上取决于下面描述的镜头数。
S = 量子电路的次数,相当于为达到给定精度而必须在量子计算机上执行反演以计算反演观测值的期望值的次数。
对于量子化学模拟中使用的VQE算法来说,目标误差率可能非常低,因此所需的拍摄次数会增加到天文数字级别。
2015年,据估计,利用VQE找到具有112个自旋轨道的铁红毒素(Fe2S2)的基底能态需要10^19次电路运算和10^26次门电路运算。为了消除与数据量子比特数有关的多项式或指数诅咒,人们提出了各种优化方案,但这些方案与算法有关。否则,它将成为NISQ实现超过N=40时的一个关键障碍,并阻碍实现一些实用的量子优势。
然后,你可以用各种量子错误缓解技术开销来补充这一清单,如果量子比特具有足够的保真度,那么使用优化的VQE算法进行相当简单的化学计算,即使不使用超导量子比特,也能持续数十年甚至数百年。
那么,具有高保真度的更好的捕获离子量子比特呢?由于量子门的速度比超导量子比特慢1000倍左右,因此这些量子比特完全不在竞争之列。与经典计算相比,理论上的提速如果实际发生在非人类的时间尺度上,就没有任何价值!
同样,在讨论潜在的NISQ量子优势时,对所有这些时间成本进行实际的全栈评估将非常有用。许多NISQ算法论文并不总是研究这个问题,这些论文大多涉及少于30量子比特的亚NISQ扩展机制。但它仍能推动一些有趣的架构设计,在这些设计中,许多这样的镜头将在不同的QPU上并行运行,或者甚至在单个QPU中并行运行,而单个QPU在逻辑上被划分为多个运行相同电路的小量子比特区。
3)NISQ代码经典模拟
评估量子计算机与经典计算机之间的差异主要有两种方法。
一种更简单但并不完美的方法是比较给定量子算法在QPU上的执行情况及其在各类经典计算机上的代码仿真。这种仿真可以通过重现完美量子比特的行为(使用状态向量仿真)或噪声量子比特的行为(使用密度矩阵或张量网络技术)来实现。
另一种方法是进行类似的比较,但使用同类最佳的经典算法来满足与量子算法相同的需求。事实上,同类最佳的经典算法可能比在经典装置上简单模拟的量子算法更快。经典计算机与NISQ系统之间的比较还必须考虑到与启发式、输出采样、寻找一个解决方案与寻找最佳解决方案等相关的各种微妙之处。
所有这些比较只能在少数情况下正确进行。我们只能猜测哪种类型的NISQ量子算法可以在经典系统上进行仿真,并比较它们的相对速度、成本和耗能。此外,仿真并不是一站式解决方案,因为它可以通过多种方式实现,例如仿真完美量子比特、使用状态向量,或者使用张量网络等压缩技术,这些技术可以通过浅层算法处理大量量子比特,并且与NISQ代码仿真相关。根据量子比特数和算法深度,可以在不同级别的量子代码仿真之间定义一些关键阈值。
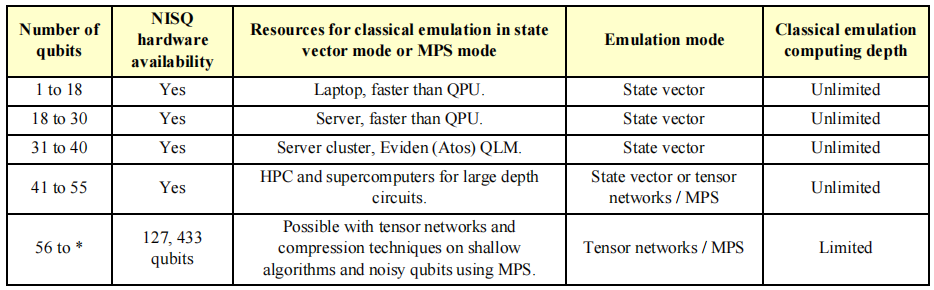
模拟门基量子算法所需的典型经典资源评估表
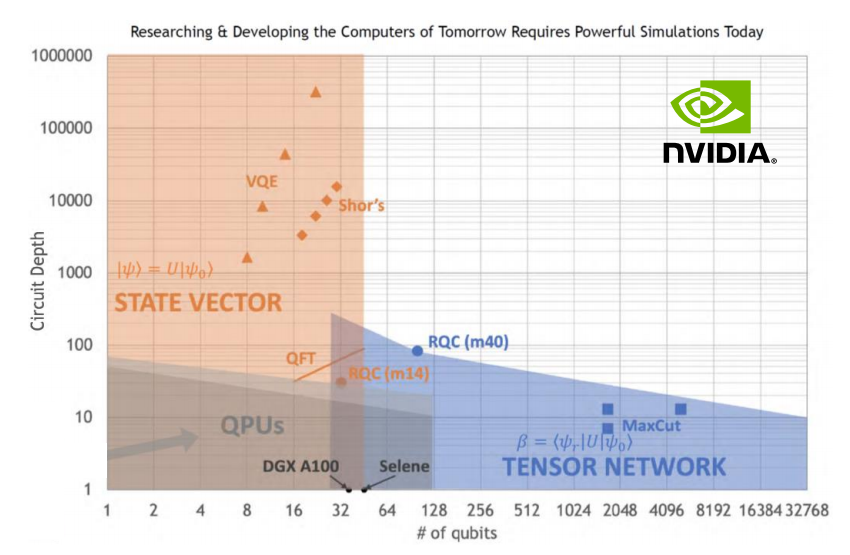
英伟达将状态矢量量子仿真的范围定位在少于32个量子比特但电路深度(Y轴)不受限制的系统中,而张量网络仿真则可以通过浅层算法扩展到数百个量子比特。从图中可以看出,经典仿真比现有的NISQ量子计算机(灰色)范围更广
此外,“量子优势”通常会在QPU至少拥有与最强大超级计算机相同的能力时显现出来,但这种等效性可以在与普通较弱的高性能计算机进行比较时进行评估。
在这种情况下,QPU的大小会有很大不同吗?经典解决方案的成本会比量子解决方案低吗?便宜多少?这是一个悬而未决的问题。
在NISQ系统中,情况变得复杂起来,因为所有量子算法都是混合算法,需要大量经典部分来准备“解析”,并在量子处理器上重复调整和运行。就QML算法而言,经典计算机要做大量的数据摄取和准备工作,比如为自然语言处理任务做一些向量编码。在与一些经典代码仿真进行比较时,经典仿真器应与处理算法经典部分的相同经典计算机配对。
衡量经典仿真能力的一种经典方法是评估可用内存。每多仿真一个量子比特,容量就会增加一倍。在要求最苛刻的状态矢量仿真模式下,29个量子比特需要8GB内存,这在大多数笔记本电脑中都很合适。
但内存和处理要求之间存在一些差异。拥有16GB内存的强大笔记本电脑可能不足以比QPU更快地模拟29量子比特。
一个英特尔服务器节点最多可模拟32个量子比特。虽然 Eviden(Atos)的QLM可以用超过1 TB的RAM仿真多达40个量子比特,但无论结果质量如何,相关的执行时间都可能比QPU更长。基于GPU的仿真是迄今为止最高效的仿真,英伟达凭借其V100、A100和最新的H100 GPGPU系列处于领先地位,它们的通用GPU与用于游戏和3D图像渲染的GPU有着不同的需求。

现在,我们将对适用于NISQ QPU的量子算法进行综述,重点不在于其基本原理,而在于其量子比特资源需求和计算时间尺度。
基肖尔·巴蒂(Kishor Bharti)曾在其长达91页的NISQ算法综述中指出:“这些计算机由数百个噪声量子比特组成,即没有纠错的量子比特,因此在有限的相干时间内执行的操作并不完美。在利用这些设备寻找量子优势的过程中,人们提出了各种算法,应用于物理学、机器学习、量子化学和组合优化等多个学科。”
“这些算法的目标是利用有限的可用资源来完成具有挑战性的经典任务。有趣的是,他们首先将NISQ定位在数百量子比特的范围内。”
尽管各个学者众说纷纭,他们相应地共同指出,“我们可能要在这个时代待很长时间”。

研究人员和行业供应商提出的主要NISQ算法类别以蓝色表示,绿色表示的是依赖量子纠错的容错量子计算机所特有的算法。理论上,这些NISQ变分算法应能抵御噪声和浅层算法,但迄今为止,它们并不能做到这一点
实际上,研究最多的NISQ算法属于变分量子算法类。它主要包括用于化学模拟的VQE、用于组合优化的QAOA以及许多QML算法。
所有这些算法都是基于启发式的经典量子混合算法。这些算法使用一个反演函数来计算量子系统的哈密顿参数,该参数由一些CNOT门完成的单量子比特Rx、Ry和Rz门的任意角度的多次旋转构成。
此外,大多数已知的NISQ算法都是变分算法,其中一部分在经典计算机上运行,另一部分在量子计算机上循环运行,直到收敛。这里有几个问题值得注意。第一个问题是,在NISQ量子优势机制中,经典部分如何扩展到大型问题?
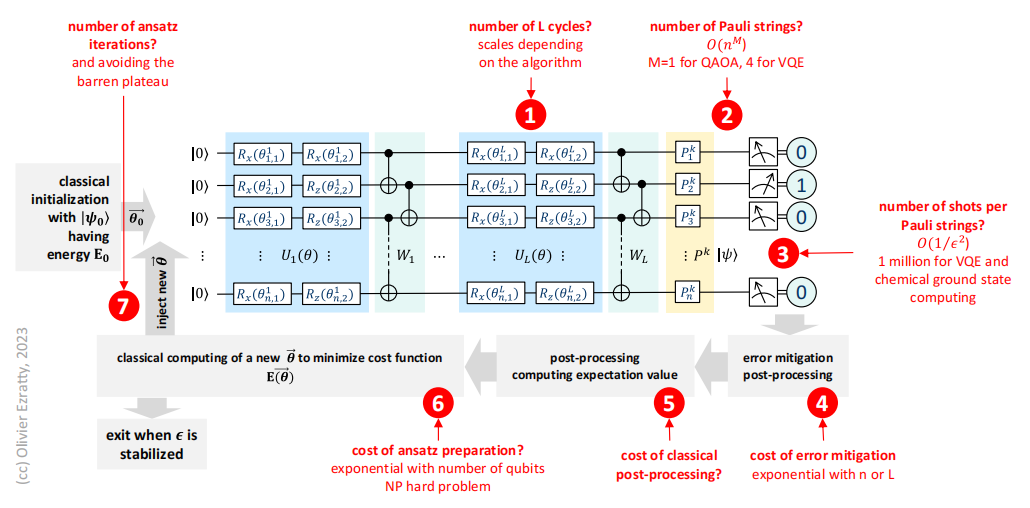
描述变分量子算法(VQA)运行方式及其缩放参数的图表。灰色部分对应的是这些算法的经典组成部分,变分法包含一个用单旋转和双量子比特CNOT门循环编码的哈密顿。在计算若干次运行后,它以经典方式生成哈密顿的预期值,其他的辅助量子比特和运算可以添加到反演中
美国能源部桑迪亚实验室的肯尼思·鲁丁格(Kenneth Rudinger)宣称:“当量子计算机最终能够实现其承诺时,变分法可能并不实用。”
“我们有充分的理由相信,对于变分法来说,你想要解决的问题的规模太大了;在这种规模下,传统计算机基本上不可能为量子设备找到好的设置。”
另一个重要但通常未得到解决的问题是,在变分量子算法中,经典计算部分在计算时间和总运行成本方面的相对权重是多少?在这一点上,大多数论文都没有过多阐述变分算法的经典资源成本。
1)用于化学模拟的VQE算法
迄今为止,大多数VQE实验都是用几个量子比特实现的,远远低于量子优势阈值,这些实验是在前NISQ阶段完成的,远远低于 50 量子比特,这有几个原因。
首先,许多博士生项目持续时间在一到三年之间。其次,虽然有几种QPU的比特数超过50,特别是来自IBM和谷歌的QPU,但这些QPU的比特门保真度太低,无法实现更大规模的VQE(和VQA)抗噪声算法。真正可用的QPU量子量非常低,Quantinuum捕获离子QPU的记录为2^22。?
在QPU能够扩展并容纳更多量子比特之前,这些实验对于测试算法的下落非常有用。
在化学模拟领域,VQE实验通常仅限于寻找简单的两到三个原子分子(如LiH、BeH2或H2O)哈密顿的基态能量。正如我们之前所见,寻找苯这种稍复杂分子的基态会使NISQ系统进入未知领域,并需要很长的计算时间和对高保真物理量子比特的要求。
结果表明,对于各种分子,即使是性能最好的VQE算法也需要10^-6到10^-4数量级的门误差概率才能达到化学精度,VQE还有助于计算分子的激发态。
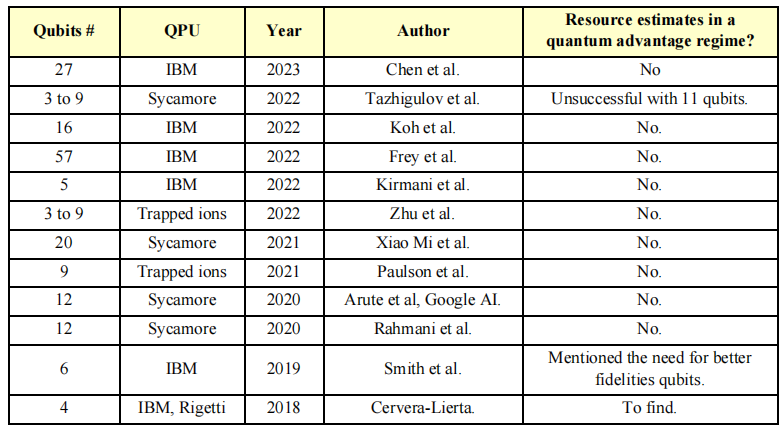
NISQ算法论文及其测试的量子比特数
现在,VQE还不能满足更迫切的计算化学需求,如确定大分子结构、寻找复杂的振动和旋转光谱以及分子对接,而这些在药物设计和化学工业中都非常有用。这些用例一般属于FTQC范畴,而且在大多数情况下,是在逻辑比特数量非常大的极端情况下。例如,在FTQC领域估算复杂分子哈密顿的基态时,需要使用量子相位估算(QPE)算法。它的精度取决于对特征值结果进行编码的辅助量子比特的数量。
2)用于组合优化的QAOA算法
QAOA是与NISQ QPU第二类最相关的VQA算法。然而,它似乎并不能很好地扩展,而且需要比现有数量更多的高质量量子比特,才能在企业运营领域的实际用例中带来一些量子优势。
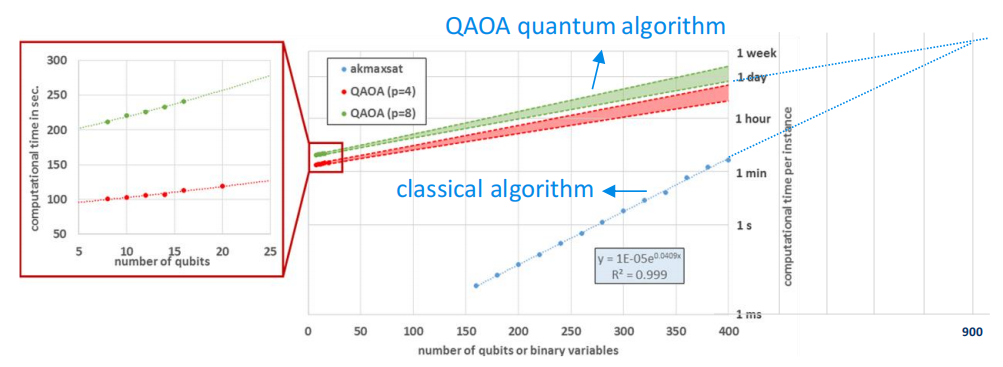
p相当于QAOA电路块在算法解析式中重复的次数。这意味着p=8的深度是p=4的两倍。这就要求物理量子比特保真度达到99.9986%,而这远远超出了NISQ架构的范围
QAOA 算法通常依赖于QAOA组件。安东·西门·阿尔比诺(Anton Simen Albino)等人指出:“由于问题的维度与量子比特数量之间存在线性关系,在使用QAOA及其变体解决这些问题之前,需要数千量子比特。然而,由于启发式本身的特点,所使用的量子比特并不一定是误差校正的,它需要低深度电路和对最终状态的少量测量。”
约翰内斯·魏登费勒(Johannes Weidenfeller)等人提供了大量在NISQ系统上运行QAOA的线索。他们强调了一些需要克服的障碍,以“提高QAOA的竞争力,如门保真度、门速度等”。
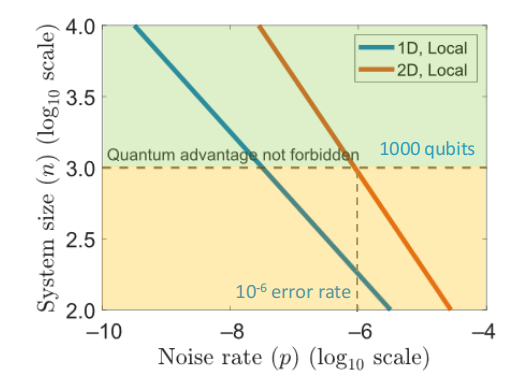
图中显示,利用QAOA取得量子优势所需的双量子比特门误差率远非目前所能达到
因此,在量子优势系统中实施QAOA算法似乎需要FTQC和超过一百万个物理量子比特!一种变通办法是构建具有高量子比特连接性的相对大型NISQ系统。
3)量子机器学习算法
在文献中,量子机器学习的情况似乎也好不了多少。与QAOA算法相比,在NISQ上运行的相关算法在实际扩展方式上也存在同样的问题。
2022年11月,卢卡斯·斯莱特里(Lucas Slattery)等人估计,“在使用经典数据的QML上,NISQ没有量子优势”。更糟的是,“表现良好”的量子模型与经典模型之间的几何差异很小,而且随着量子比特数的增加而减小。
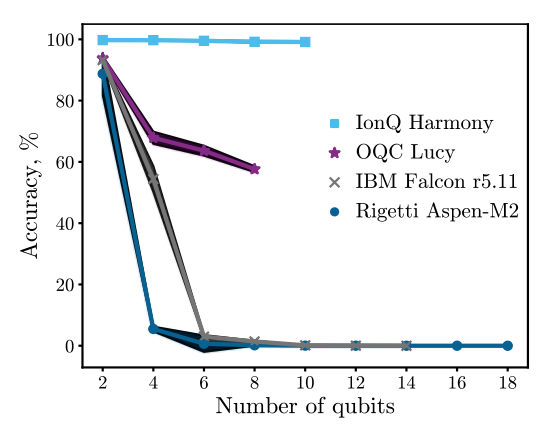
在运行一些混合量子神经网络算法推论时,NISQ的实际算法深度与当前IBM和AWS云服务提供的一些QPU相比较。在此,我们可以看到当前的NISQ平台在广度(量子比特数量)和深度(与量子比特保真度相关的门周期数量)方面的困难
另一方面,量子机器学习提速并不是唯一的潜在量子优势属性,但正如玛丽亚·舒尔德(Maria Schuld)和内森·基洛兰(Nathan Killoran)所指出的,经典和量子机器学习算法之间的比较是复杂的。
它涉及分类质量、在未见过的训练数据上的泛化能力、训练数据要求等,几乎没有基准参考。此外,训练数据的摄取主要由经典部分完成,以准备算法的量子方差,它与数据大小成线性比例,因此没有可预见的量子优势。
最后,与VQE算法一样,QML算法也必须应对著名的贫瘠高原问题,除非反演电路非常浅,否则无法实现训练收敛。
这相当于经典机器学习中的避免局部最小值陷阱,即搜索全局最小值但难以达到。解决这一问题的研究非常活跃,比如增加额外的参数和约束条件,以提高变分训练循环中的梯度,而不诉诸低效的过度拟合。

到目前为止,我们已经对NISQ的去向描绘了一幅相当黯淡的图景,至少在短期内是这样。
在此,我们将讨论潜在的解决方案,尽管这些方案还很粗略,也未经证实。如何解决NISQ QPU目前的一些弱点,使其能够发挥某种形式的量子计算优势?
我们可以把这些问题归结为改进:
- 量子错误抑制和缓解技术,尽管众所周知,这些技术的成本与电路深度或量子比特数呈指数关系。
- 算法对噪声和其他硬件要求限制的适应能力。这种弹性相当罕见,主要体现在一些特殊的量子机器学习技术上。
- 扩展模拟量子计算平台,因为它们有自己的限制,属于NISQ领域的另一个类别。
- 量子比特保真度和能力,以实现更大的量子体积和更多的高保真度量子比特。
- 利用量子比特的连通性,实现更浅的算法实施和更快的计算时间。
- 除速度提升外的量子优势。
- 能源,只要首先进行有用的计算,它就可能成为NISQ系统的关键运行优势。
1)量子比特保真度和能力
提高量子比特保真度当然是一件知易行难的事。所有量子计算研究实验室和行业供应商都在朝着这个方向努力,并取得了各种成果。
量子比特保真度包括量子比特初始化保真度、单量子比特和双量子比特栅极保真度以及量子比特读出保真度。
有趣的QPU,无论是现有的还是未来的,都是那些双量子比特栅保真度超过99.5%的QPU;目前只有IonQ、Quantinuum和IBM的几款捕获离子和超导QPU。
捕获离子似乎很难实际扩展到40个以上的量子比特。迄今为止,还没有一个平台能达到99.9%的双量子比特门保真度,以及量子比特的制备和读出。
一些替代方案正在酝酿之中:
- C12量子电子公司的碳纳米管自旋量子比特可以达到99.9%的临界值,迄今为止已经进行了数字模拟。
- 氮和碳化硅空位中心也是高保真量子比特的理想候选材料,尽管它们目前还难以大规模制造。
- 光量子比特具有不同的优越性,因为它们并不天然解旋。要解决的问题是它们的统计量,需要有确定的光子源,最好是纠缠光子的群集态,并使用确定的光子探测器。
- 玻色子量子比特家族中的自主校正量子比特也很有前途。其中包括Alice&Bob和AWS开发的猫比特,以及Nord Quantique和QCI开发的其他玻色编码比特。它们的比特翻转误差率很低,但相位误差率很高,需要进行一些误差校正,因此这些量子比特直接进入了FTQC领域。
- 同样,马约拉纳费米子(或MZM,马约拉纳零模)量子位也提供某种形式的自校正,但只有在容错纠错方案有效时才会实施。它们不属于NISQ QPU类别。
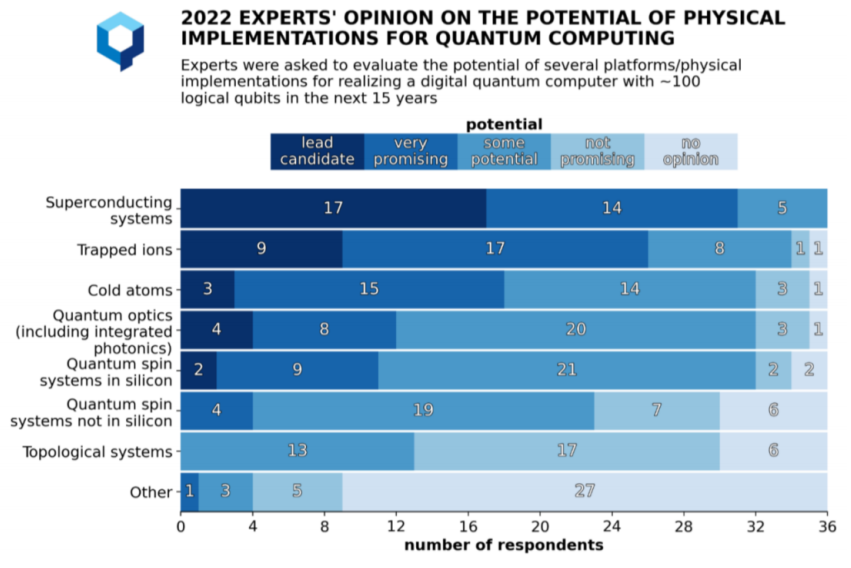
量子计算专家对量子比特扩展的信任主要来自超导和俘获离子量子比特,少数人信任光子和自旋量子比特
2)量子比特连接性
无论是在NISQ还是FTQC体系中,量子比特连通性在最大限度地降低许多算法的深度方面都发挥着关键作用,例如,在许多算法的实现过程中,限制了所需的SWAP门的数量。
连接性最好的量子比特是捕获离子。它们展示了多对多的连接性,加上出色的保真度,使其成为领先的量子计算平台。
这也解释了为什么离子阱QPU拥有迄今为止最好的量子体积,遗憾的是,在目前的发展阶段,这些量子比特的数量并没有得到很好的扩展。目前所有供应商(IonQ、Quantinuum、AQT、Universal Quantum、eleQtron)的QPU都只有不到30个量子比特,而且进展非常缓慢。

不同平台的超导量子比特连接性差异
超导量子比特具有各种类型的连接。最好的是D- Wave公司的产品,虽然是量子退火模式,但其量子比特簇与15 邻居相连,很快就会与20个邻居相连。然后,谷歌的Sycamore量子比特通过使用可调耦合器与4个邻居相连。最后,IBM 的重六面体晶格实现了有限的1对2和1对3连接。
一些量子纠错码(如 LDPC)需要量子比特之间的远距离连接,而在量子比特芯片组下面使用堆叠连接芯片组似乎可以实现这一点。在量子比特芯片组下面的连接芯片组中增加更多的金属层,有望在这方面取得一些进展。IBM、麻省理工学院林肯实验室正在开发3层和7层连接芯片组,以改善超导量子比特的连接性。
3)量子错误抑制与缓解
量子计算机以不同方式处理错误。NISQ系统使用的技术是量子错误抑制和量子错误缓解。容错量子计算机将使用与NISQ QPU无关的量子纠错技术。
量子误差抑制技术涉及在物理层面改进量子比特,以尽量减少退相干(叠加和纠缠的损失)、串扰(当对某些量子比特的操作干扰其他量子比特时)和泄漏(当一个量子比特脱离其|0?和|1?计算基础时,例如超导量子比特就会发生这种情况),并最大限度地提高门保真度和速度。它还能处理量子比特初始化误差和读出校正。
它通过优化电子控制(脉冲整形、减少相位、振幅和频率抖动)以及先进的器件鉴定和校准来实现。这取决于量子比特的类型。如果实施得当,误差抑制技术会随着量子比特数量和算法复杂度的增加而得到相对较好的扩展。
误差抑制技术也可用于FTQC设置。误差过滤(EF)是一种变化的误差抑制技术,它重复使用了一种最初为量子通信设计的技术。
量子误差缓解(QEM)是指在多次运行算法并平均其结果的基础上,结合经典后处理技术和一些潜在的电路修改,减少量子算法的误差。与基于QEC 有源量子比特测量和影响单次运行结果的快速反馈修正相比,QEM利用多次运行和后续测量以及一些经典处理来减少量子误差的影响。
QEM提议在2016年前后开始涌现 。它们大多是为了了解噪声对量子比特演化的影响,并创建可用于调整量子计算结果的预测噪声模型。大多数QEM方法不会增加特定算法所需的量子比特数。
已知的QEM技术大多有各种局限性,包括精度和扩展问题,计算时间的指数开销反过来又限制了NISQ算法在高端系统中的潜在量子优势。
不过,在NISQ可以实现的狭窄量子优势范围内,这些缺点可能会受到限制。
4)算法进展
我们在前面关于NISQ算法的部分已经看到,要产生一定的量子优势,对这些算法的要求相当苛刻。大多数算法都是在很低的尺度上进行测试的,需要更多的量子比特和更高的栅极保真度,这在目前是不可能实现的,甚至在中短期内也是不可预见的。
不过,算法设计的改进还是令人鼓舞的。其中许多算法减少了典型变分算法(VQE、QAOA)的量子比特数量和门深度要求。
另一种利用VQE优化分子模拟的方法由Algorithmiq公司和都柏林圣三一学院提出,使用ADAPT-VQE-SCF方法,他们预计这些技术将在2023年产生有用的量子优势。
一直以来,在VQE领域,一个由德国和西班牙研究人员组成的团队找到了一种改进机场航班登机口飞机分配(FGA)算法的方法。该算法的目标是“通过找到航班的最佳登机口分配”,最大限度地减少“乘客在机场的总停留时间”。
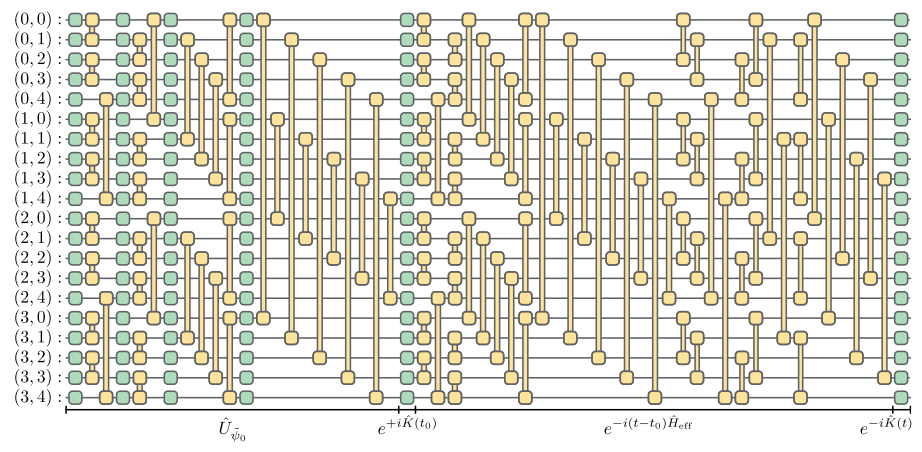
在Quantinuum QPU上执行的20量子比特40深度的NISQ算法。这种使用大量双量子比特门的非浅层NISQ算法目前只能在捕获离子QPU上运行。这种特殊算法的设计者希望它能在未来的系统中提供一些量子优势,因为它使用了固定深度的电路。不过,这仍然需要更多的俘获离子QPU,而且保真度要比现有的QPU
最后,利用NISQ获得量子优势的一个相对奇特的方法是直接向QPU提供量子数据,理论上可以通过量子传感器来实现,它是在2021年利用40个超导量子比特和1300个量子门运行QML算法实现的。它很有趣,但只适用于非常特殊的用例。
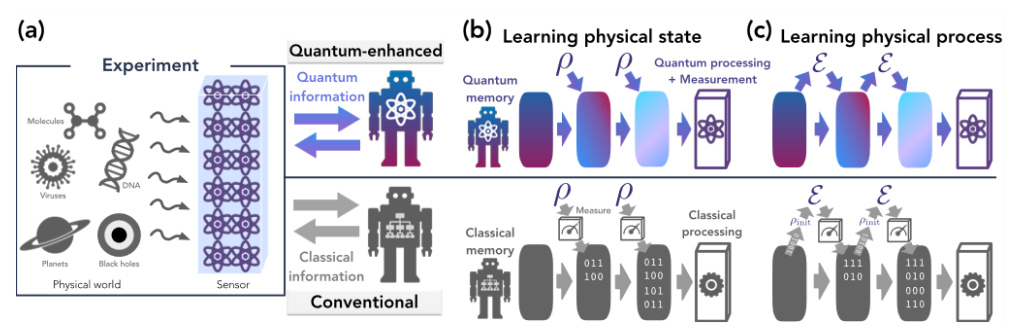
直接用来自量子传感器的量子数据(上图)哺育QML算法,与通过经典方式生成数据的经典设置(下图)相比,速度呈指数级提升,因为量子机器学习中使用的大多数数据都来自经典数据源
5)扩展模拟量子计算机
量子退火和模拟量子计算并非量子计算行业的宠儿。一方面,在量子退火领域,D-Wave因“不属于量子”或无法带来任何计算优势而长期受到批评。另一方面,模拟量子计算机(可编程哈密顿模拟或可编程量子模拟器)是由PASQAL和QuEra等极少数厂商开发和商业化的,据说它们自身也面临着可扩展性的挑战。
尽管如此,当客观地比较周围有记录的案例研究时,我们会发现许多解决方案距离实现某种量子优势并不遥远。它们中的大多数还未达到“量产级”,但与所有基于NISQ的原型算法相比,它们更接近于“量产级”。

比较了基于门的VQE、D-Wave退火和经典张量网络的动态组合优化解决方案的准确性和运行时间,显示了量子在大型问题的利润和D-Wave 2000Q处理器的运行时间方面的潜在优势
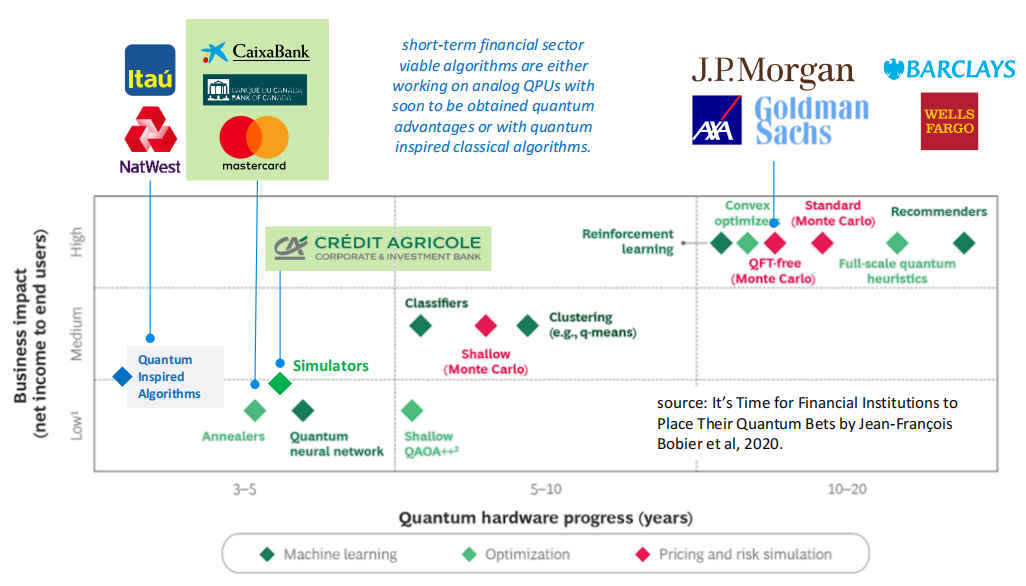
金融领域的案例研究:量子退火、量子模拟和量子启发算法。截至2023年,对业务影响较小的短期案例研究可采用经典量子启发算法。量子退火器和量子模拟器已经创建了原型解决方案,但一般还不能扩展到生产级水平。最后,最有趣的商业用例和算法需要具有数千个逻辑量子比特的容错量子计算机,因此,这些系统的可扩展性还有待实际验证
在回顾所有这些门量子计算和模拟量子计算类别的案例研究时,有一点非常引人注目:现有最强大的解决方案是在模拟领域,而不是在门领域。实现线性代数和张量网络计算的量子启发经典解决方案也在多个领域使经典计算更具竞争力,而这些根本不是量子计算。
然后,其他用例直接将我们置于FTQC区域,需要数千个逻辑量子比特,因此需要数百万到数亿个物理量子比特。
不过,即使模拟量子计算的现有用例比基于门的等效用例更接近现实生活中的生产级水平,要利用模拟量子计算机产生量子优势,仍有一些挑战需要克服。
对于中性原子,它们的扩展与在超真空中控制大块位置良好的纠缠原子的能力有关。相关工具由更强大、更稳定的激光器及其相关控制电子设备组成。此外,还必须重新设计用于控制所有量子计算机设备的研究级光学台,以避免在设置和校准这些QPU时进行繁琐的定位调整。
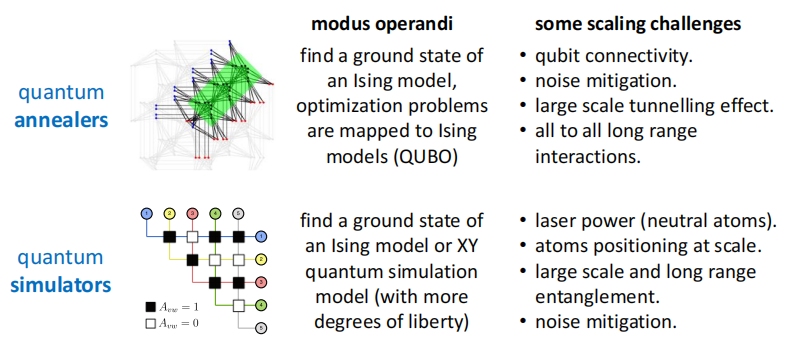
量子退火器和模拟量子计算机的一些扩展挑战
6)其他NISQ技术
现在让我们来盘点一下有可能使NISQ变得可行的各种技术,尽管对这些技术的评估仍在进行中,因为大多数情况下,这些技术尚未得到实际验证。
DAQC(数模量子计算)是实现基于门的混合模拟量子计算模型的建议。DAQC可以更有效地利用量子计算资源,使NISQ算法使用更少的量子比特,运行速度比普通NISQ QPU更快。它适用于优化和机器学习。它由Kipu Quantum(德国)和Qilimanjaro(西班牙)提出, Kipu Quantum正在研究超导、陷落离子和中性原子量子比特的使用。人们对这种架构的提速效果、其对算法类别的依赖性及其对控制电子学和能源学的影响充满疑问。此外,调试算法更加复杂,支持它的开发工具也很少。
由 ParityQC(奥地利)开发的LHZ架构(发明者名称:Lechner-Hauke-Zoller)在量子退火的变体中使用小型逻辑量子比特,使其可编程。该架构可通过超导、NV色心、量子点和中性原子量子比特实现。ParityQC提出了一种相关技术,通过量子误差缓解来减少QAOA误差。
电路切割和纠缠锻造是IBM研究院提出的两种NISQ技术。电路切割将“一个量子电路拆分成多个量子比特和门数更少的较小电路,这样通过利用后续的经典后处理,执行较小电路集合的结果与执行原始电路的结果相同”。这种方法可以提高QAOA期望值,但其优势会随着图的大小而减小。
纠缠锻造“利用经典资源捕捉量子相关性,使量子硬件可模拟的系统规模翻倍”。它主要与VQE一起用于分子模拟或量子机器学习,基于将量子态分解为N+N量子比特的二元态的施密特分解和 SVD(奇异值分解),其可扩展性有待进一步验证。
第三种技术是电路编织,即在同一个QPU上将电路集群为高交互部分,跨越多核和分布式架构,并使用一些量子通信,如微波链路或光子纠缠链路。
Q-CTRL(澳大利亚)提供了一种量子控制基础架构软件,可在低级固件层面控制量子比特驱动微波脉冲,并利用机器学习改进这些量子比特控制脉冲和优化量子纠错码,这是一种量子错误抑制技术。
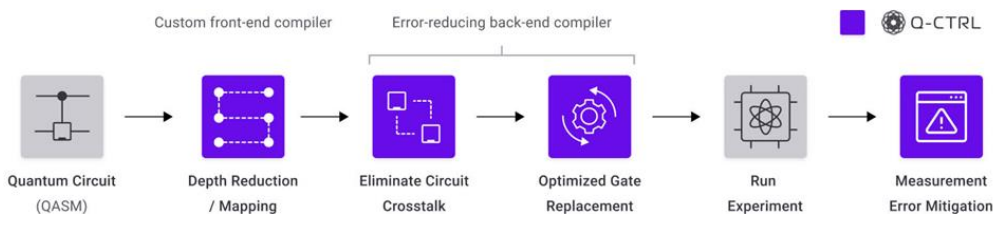
Q-QTRL Boulder Opal架构优化超导量子比特控制脉冲
使用IBM Qiskit、Rigetti和量子机器微波脉冲发生器的量子计算机设计人员都在使用他们的Python工具包。他们实施的纠错技术可将量子硬件上量子计算算法成功的可能性提高1000倍到9000倍:这是用QED-C算法基准测量的结果。
NISQ+是英特尔、芝加哥大学和南加州大学(USC)于2020年提出的一项技术,它使用快速近似量子纠错和量子纠错缓解技术、运行速度为3.5K的SFQ超导控制电子电路和轻量级逻辑量子比特。?
它介于NISQ和FTQC之间,可以将NISQ QPU的可用性提高几个数量级。例如,它只需使用1000个物理量子比特,就能将40到78个量子比特QPU的计算深度扩展到数百万门周期。
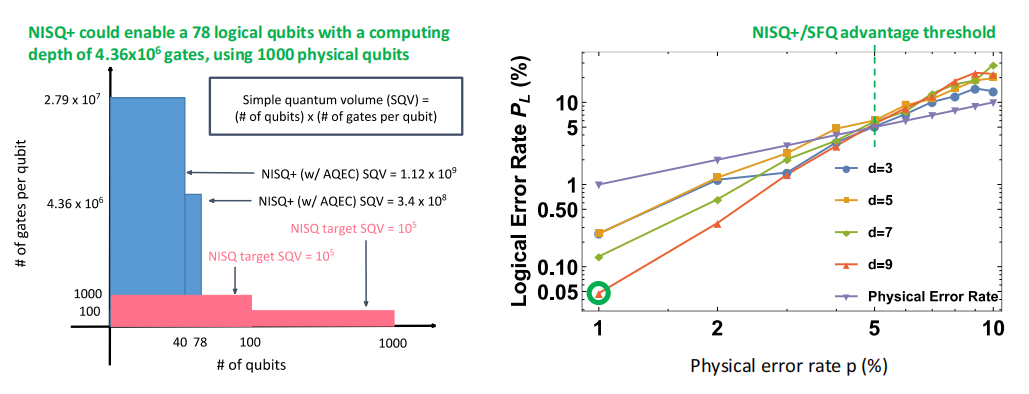
NISQ+有可能实现78个逻辑量子比特和良好的计算深度
7)寻找其他量子优势
大多数量子算法的目标是实现量子速度超过同类最佳经典算法。理论上,这种计算时间的加速通常是多项式或指数级的,圣杯就是指数级的加速。
但实际上,大多数NISQ算法似乎最多只有中等程度的多项式加速。由于量子机制中的高常数和量子计算机相当慢的门周期,与同类最佳经典算法的交叉可能发生在非常大的时间阈值上。
这意味着,在计算时间超过数天、数月甚至数年的情况下,NISQ的实现要优于经典体系。如果变分算法计算的经典部分非常长,而且不能很好地扩展,那么差别甚至可能微乎其微。
不过,在某些情况下,NISQ量子算法可以帮助创建比经典算法更好的解决方案。但这很难评估,尤其是QML。
NISQ解决方案所产生的一些定性方面可能是:QML的预测和分类精度更高、QML的训练数据更少,或者QAOA或VQE变化的物理模拟中实施的优化有更好的启发式结果。?
另一个潜在优势是量子计算机的有利能量学。但要对其进行评估,任何NISQ量子算法都必须至少能与同类最佳的经典算法做得一样好,因为要进行比较绝非易事。
量子计算系统与经典计算系统的比较比单纯看速度更微妙,经典比较点不一定是现有最大的超级计算机。此外,该分类法并不局限于理论上的渐近多项式或指数优势,而是针对使用生产级输入数据集的给定算法集和实际用例的实际优势。
许多论文都讨论了这些方面,但却没有考虑到经典计算技术的实际状况。在这方面还有很多工作要做,需要更多的理论和实验数据,以及更精确的用于比较的经典计算等价物。?
8)能量
如果NISQ算法能在速度上显示出一些优越性,甚至与各种经典算法不相上下,那么比较它们的能耗就很有意思了。
我们可能会得到一个令人惊讶的结果:NISQ平台的一个关键优势是,与经典平台相比,其能量成本更低。
正如我们迄今所看到的,目前只有IBM、D-Wave、PASQAL和QuEra的NISQ QPU值得关注。我们必须看看它们在NISQ时代的路线图,看看它们是否能带来一些计算优势和一些能量优势。
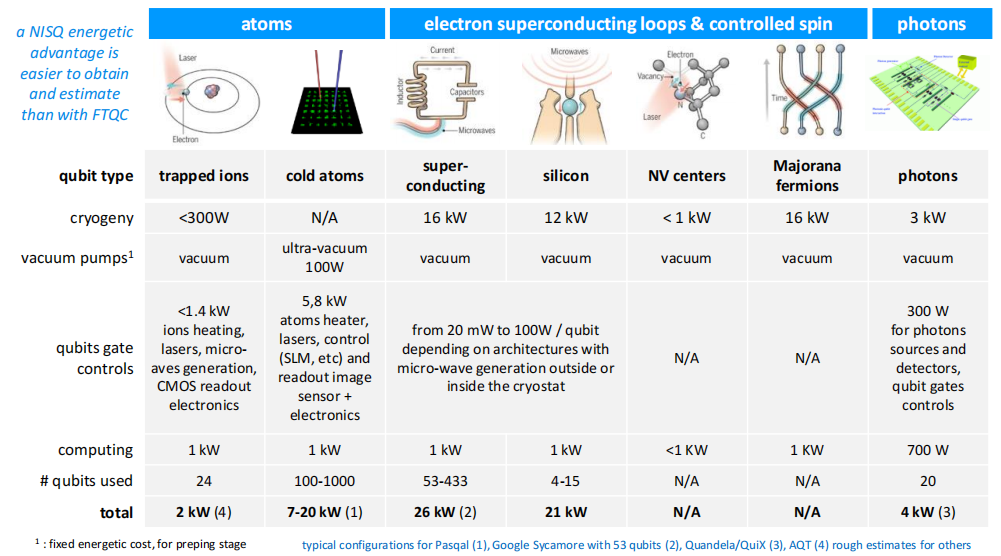
现有QPU的典型功耗及其来源,这些系统在目前(2023 年)都不具备量子优势
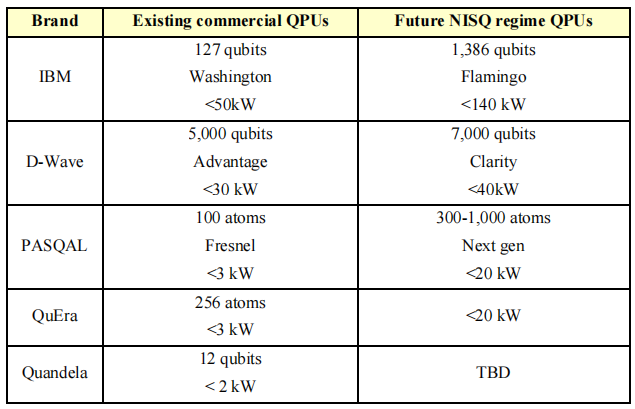
几家供应商现有QPU和未来NISQ级QPU的功耗比较表,如果这些未来系统在不久的将来带来了量子计算优势,那么也可能会带来相关的能量优势
IBM及其将于2024年发布的1386比特Flamingo系统可能会很有趣,而Condor的1121比特平台可能没有足够的保真度来成功运行NISQ算法。
至于PASQAL和QuEra,我们必须考虑它们的下一代中性原子模拟量子计算机,其实际可控原子数在300到1000之间。其他值得考虑的QPU是基于多模光子的,如Quandela的QPU和Xanadu的其他系统。
为了理解IBM未来Flamingo平台140千瓦的估计值,我们可以猜测它将使用一个Bluefors KIDE低温恒温器,该恒温器包含9个脉冲管和Cryomech压缩机,每个耗电量约为10千瓦,外加一个用于压缩机的互补式外部水-水冷却器。三个稀释器的气体处理系统和控制系统的功耗各约为1千瓦。再加上几台个人电脑、真空泵和控制电子设备,每个量子比特的功耗约为20瓦。
由于必须考虑计算时间,因此不能直接将功耗与经典比特进行比较。能源足迹不是功率,而是功率 × 时间。要估算这一足迹,我们需要计算特定QPU算法所需的门周期数,然后乘以平均门长度。这样就能估算出每次计算的功耗(焦耳)。当然,还需要努力找出性能与经典算法相当的此类计算,然后对它们各自的功耗进行基准测试。
举例来说,IBM未来的Flamingo平台功耗估计在140千瓦以下,如果它能在合理的优化周期内成功运行NISQ算法,那么它与HPC相比可能会更胜一筹。
此外,还有三个稀释装置,其GHS(气体处理系统)和控制系统的功率约为1千瓦。再加上几台个人电脑、一台真空泵和控制电子设备,每个物理量子比特的合理功率预算为20瓦。但所有这些都必须经过模拟、测试和计算才能得出结论。
最后,通过将这些量子系统与工作在类似功能状态下的经典系统进行比较,这一点是有意义的。例如,我们知道一个完整机架的Nvidia DGX功率约为30千瓦,而美国能源部橡树岭国家实验室最大的超级计算机Aurora Frontier在全规模使用时的功率为22兆瓦。
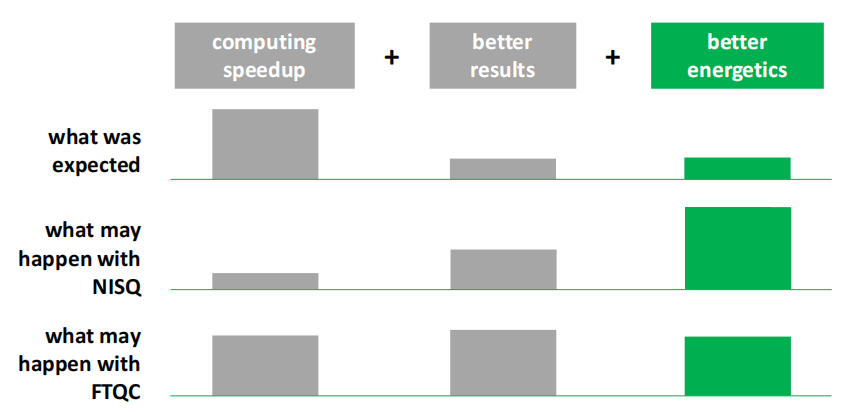
新的量子优势视角。条形图的高度(不含单位)对应于解决方案与等效经典解决方案相比的相对附加值。当然,前提条件是NISQ和FTQC算法能带来一定的计算优势,或者至少能与完成相同任务的经典计算机相媲美
总之,NISQ的量子优势最终可能与质量和能量有关,而不是与计算时间有关:在资源有限的世界里,这将使NISQ 解决方案完全适用于高性能计算领域。

从使用案例的角度来看,NISQ和FTQC有什么区别?
我们已经看到,NISQ算法在达到尚未显现的量子优势时,涵盖了广泛的优化、机器学习和物理模拟。虽然还没有很好的记录,但就其可解决的问题规模而言,其潜力是适中的。
事实上,正如我们在本文前几部分所看到的,NISQ的扩展性并不是很好,原因至少有三个:很难创造出保真度非常高的量子比特,从而实现拥有数百个量子比特和门周期的中规模NISQ;量子误差缓解成本向错误的方向呈指数扩展;计算时间完全不合理,尤其是用于各种化学模拟的VQE算法。
FTQC算法增加了一些附加功能:
- 解决变量较多的问题,如模拟较大的分子、解决较大的组合问题但具有确定性,以及较大的量子机器学习模型。
- 依赖量子傅立叶变换的各种算法,如量子相位估计、量子放大估计、线性代数和偏微分方程的HHL。这些算法正被用于量子多体模拟、量子机器学习、金融应用和许多其他用例。基于QPE(量子相位估算)的化学模拟算法的计算时间比NISQ VQE等效算法慢。
- Shor整数和离散对数算法,其主要“商业价值”显然不在“技术造福”领域,而在于破解公钥基础设施中的密钥以及共享对称密钥。
- 使用Grover算法等解决基于甲骨文的搜索和优化问题。在某些情况下,它依赖于各种形式的量子存储器的可用性,而这些量子存储器也尚未出现。而且它的扩展性并不好,只能带来潜在的多项式加速。
FTQC、这些算法及其实际应用案例的典型问题,是在物理比特方面所需的大量资源。许多论文都做过这样的资源估算,包括上文提到的微软最近的资源估算工具。?
此外,与VQE等NISQ算法一样,FTQC算法的计算时间也可能过长。
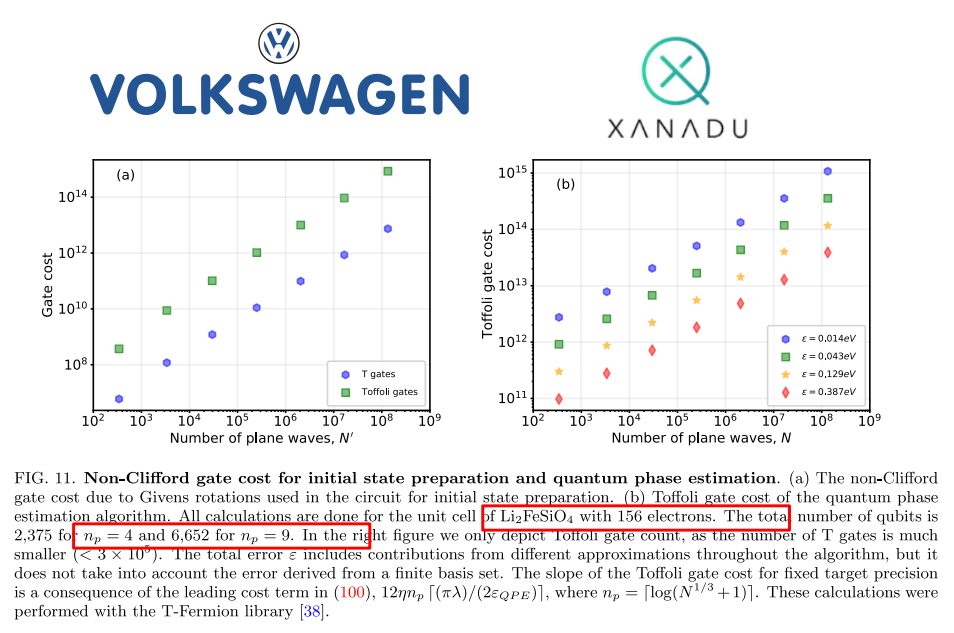
根据Xanadu和大众公司的研究,模拟电池的关键特性(电压、离子迁移率和热稳定性,包括使用第一量子化算法模拟阴极材料)需要2,375到6,652个逻辑量子比特
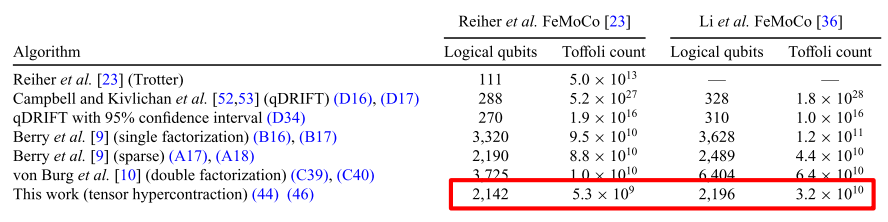
FeMoCo模拟至少需要2000个逻辑量子比特
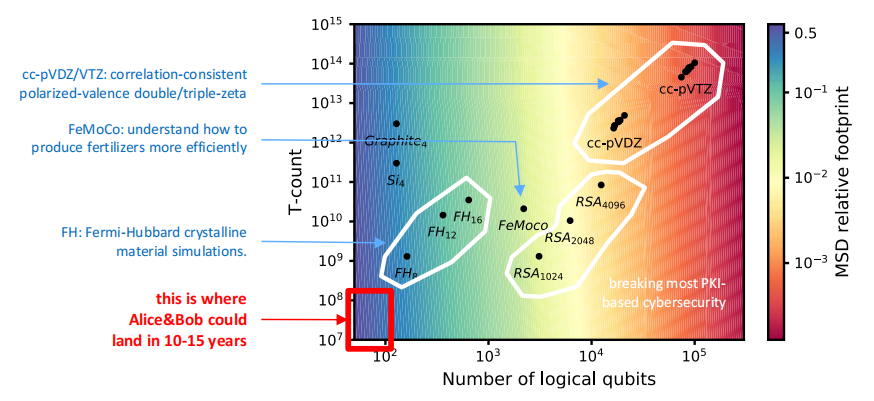
PsiQuantum用于实施费米-哈伯晶体材料模拟的估算,典型RSA密钥大小和cc-pVDZ/VTZ分子化合物的Shor算法

实施特定期权定价算法所需的一些资源
那么,NISQ和FTQC的先后顺序是什么?
约翰·普莱斯基尔对NISQ的定义意味着,它是通往FTQC的中间道路:一个接一个。如果这种顺序不是唯一的选择呢?我们在这里看到,NISQ和FTQC可能是两条平行的道路,它们各自拥有不同的工具和挑战。
我们已经看到,许多NISQ算法需要保真度远远高于99.99%的QPU。这意味着FTQC事实上是实现所谓的NISQ算法的更可行的途径,甚至能带来一些量子优势:?这或许可以解释为什么一些物理学家认为FTQC是获得量子优势的唯一可行途径。
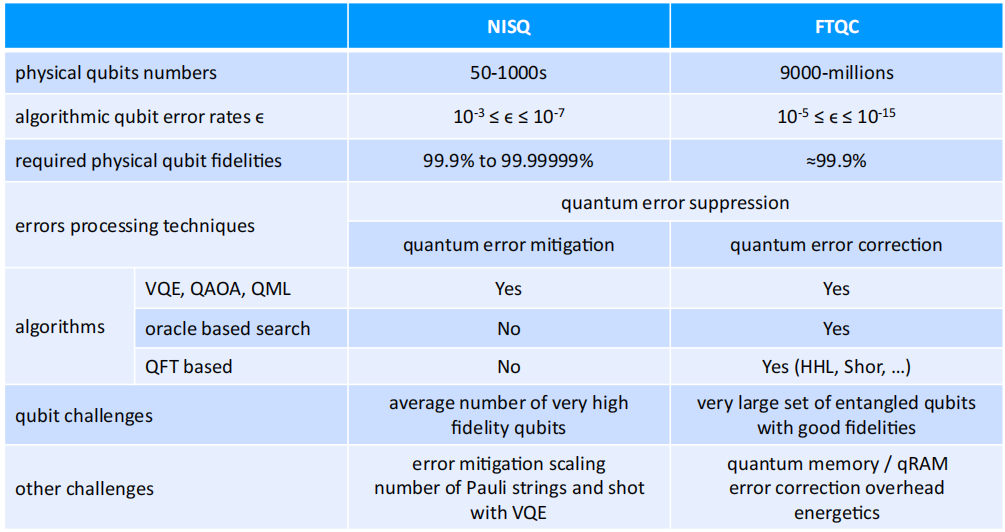
NISQ和FTQC各自的一些优点和挑战
但也可以推断,为NISQ创建几百个高质量量子比特可能比为FTQC创建大量99.9%的良好纠缠量子比特更容易。要利用NISQ QPU获得真正的量子优势,这一点必不可少,因为在99.9%的保真度下,QPU很容易进行经典模拟。如果不可能将量子比特扩展到万到百万量级,这意味着NISQ可能是唯一可行的途径。
另一方面,如果我们能够制造出质量非常高的量子比特,并且能够很好地扩展,那么就可以用较少的物理量子比特创建FTQC QPU,从而减轻可扩展性负担,尤其是在布线、控制电子设备和信号复用方面。
这仍然是一个悬而未决的问题。量子比特纠缠网能有多大?它会达到著名的量子-经典约束吗?我们需要更好地了解各类量子比特的“噪声预算源”。在这两者之间,IBM等业内厂商坚信,NISQ和FTQC之间的界限将变得模糊,尤其是在各种量子错误缓解技术的帮助下。
在NISQ和FTQC之间还有中间道路。其中一条来自日本的富士通公司、大阪大学和理化研究所,包括减少构建逻辑量子比特所需的物理量子比特数量,使用经过校正的精确模拟相位旋转门,其中涉及一种低开销的校正方案,而不是用昂贵的纠错H门和T门组合来构建逻辑量子比特。这样就能创建有用的早期FTQC设置:只需10,000个物理量子比特就能支持64个逻辑量子比特。
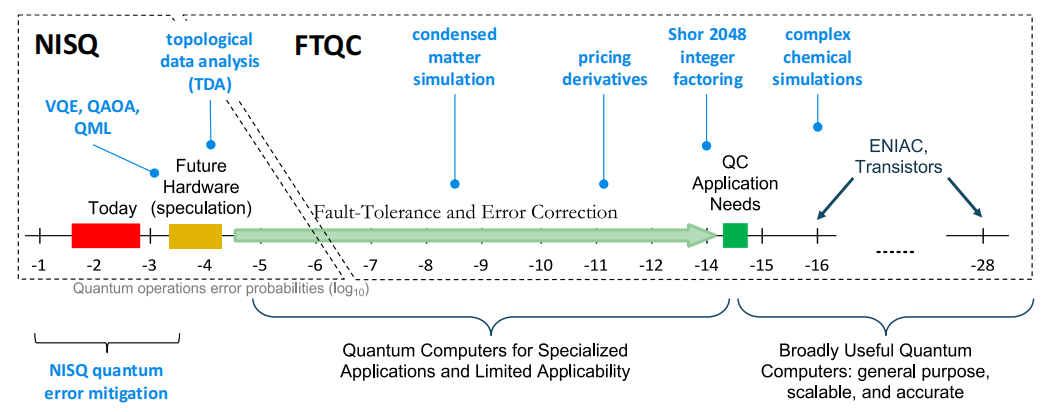
从NISQ到FTQC的道路是不确定的。我们可能有一条长长的NISQ道路,穿过保真度非常高的量子比特;而另一条道路则是用质量较差的量子比特构建的FTQC逻辑量子比特。总而言之,一个要求是能够控制大量量子对象的纠缠
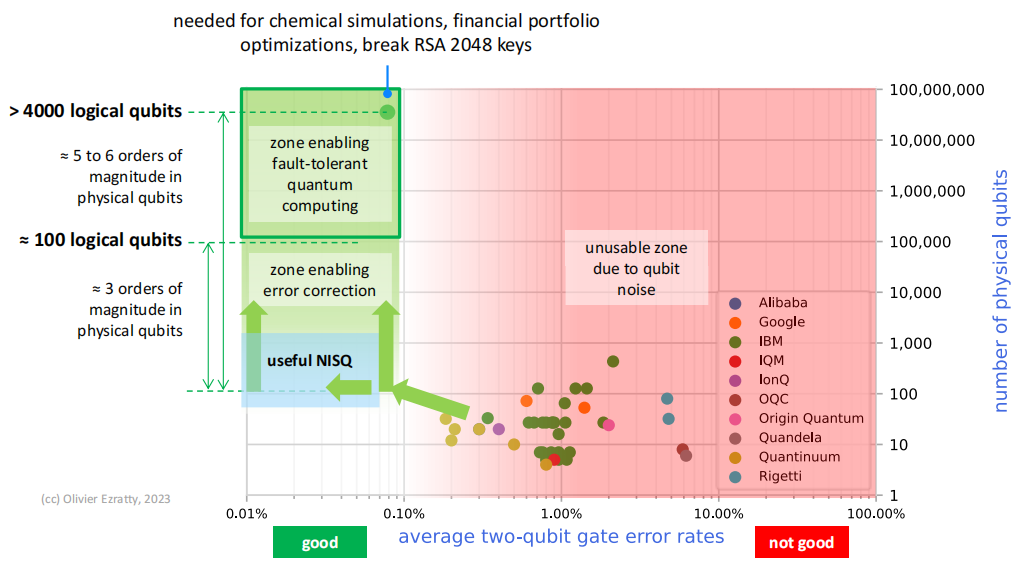
通向NISQ和FTQC的路径略有不同,NISQ的中间是质量非常高的量子比特,而FTQC的中间是质量较低的量子比特

总之,在目前的发展阶段,NISQ的缺点是多方面的:
1)现有硬件很难实现实用的NISQ。在大多数硬件供应商的路线图中,这是一个相当长期的目标。
2)对现有甚至未来硬件的量子比特数、保真度和算法深度的要求相互冲突。
3)NISQ算法的设计者并没有很好地研究或记录QPU及其经典部分的硬件资源需求如何扩展,以达到某种形式的量子优势。对于基于启发式的算法来说,这是一项特别艰巨的任务。
4)大多数QAOA和VQE算法都不能很好地利用现有和近期的硬件达到量子优势水平,特别是当你查看它们的测量步骤细节时,至少需要多项式次数的拍摄。?
此外,NISQ量子优势与用例和算法高度相关,并不通用,在许多情况下,如使用VQE算法进行多体模拟,目前估计的计算时间非常高,甚至超过人的一生。许多新的理论边界也阻碍了 NISQ 在量子优势机制下的扩展。
5)现有的含噪声的NISQ门式算法的实际实现大多可以在经典硬件上轻松仿真。使用基于张量网络的技术,基于浅门的量子算法大多可以在经典计算机上高效地仿真。
6)许多有用的量子算法需要拥有数百万甚至数十亿物理量子比特的FTQC硬件。
7)目前,NISQ硬件供应商往往会夸大其系统的功能,助长不合理的炒作,这主要是因为他们正在筹集资金,希望取悦潜在投资者,寻找客户和短期收入机会。大多数硬件初创企业仍然是低TRL的私人研究实验室。
反其道而行之,从更长远的角度来看,将NISQ变为现实有一些潜在的优势,尽管它们都值得进一步审视:
1)短期量子硬件在量子比特数量甚至保真度方面可能会达到NISQ功率范围的要求,主要来自IBM的Heron处理器。
2)必须对许多新的量子错误缓解技术进行研究,并量化其效益和开销。这些技术可以扩展当前和近期的NISQ平台,但也面临着自身的可扩展性挑战。在量子误差缓解达到极限之前,小型NISQ规模的量子优势潜力可能还很小。
3)模拟量子计算似乎是一种功能更强的NISQ计算范例,尽管其扩展能力尚不可知,而且可能由于缺乏纠错技术而受到限制。相关行业的供应商空间可能远远超出目前提供的中性原子,例如硅量子比特和捕获离子。
4)NISQ算法的发展间接推动了经典算法与量子算法之间的良性竞争,这可能会刺激这两个领域的进步。
5)NISQ也是通向FTQC的学习途径。跳过NISQ直接进入FTQC可能会被认为是一种错误的方法,因为NISQ的失败也可能意味着 FTQC 的直接失败。但是,与控制数以百万计的物理量子比特相比,NISQ路线可能更容易实现。
量子层面(纠缠、保真度)和经典层面(控制成本、冷却)的巨大可扩展性挑战,将是质与量之间的权衡。
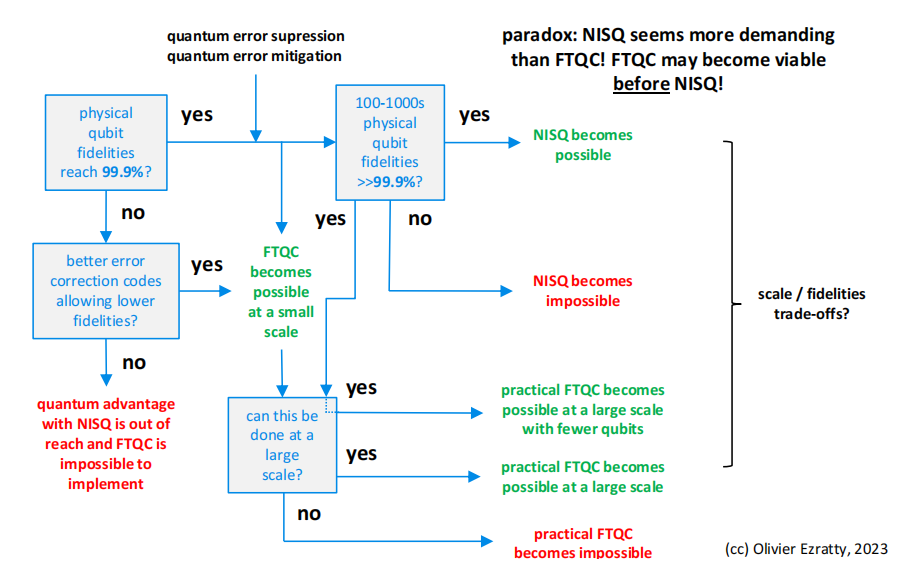
NISQ和FTQC QPU的出现有多种情况。其中一种情况是,FTQC可能会在NISQ出现之前变得可行。这是一个量子比特保真度阈值差异的问题,FTQC的需求和可行的NISQ会带来一些量子优势。但是,如果NISQ是创建保真度更高的量子比特的途径,并且有可能大规模地构建它们,那么NISQ可能是创建FTQC QPU的途径,每个逻辑量子比特的物理量子比特数量更少
- NISQ系统可以带来一些量子优势、一些算法质量优势和能量优势——这仍是一个有待研究的未知领域。
这些弊端与谨慎乐观之间的矛盾不仅仅是关于NISQ的“争论”,也是基础研究与供应商技术开发及其商业化之间界限模糊的新兴领域的特征。
本文展示了量子计算的科技现实与当前一些分析师和行业供应商的过度承诺之间的巨大差距。目前对所谓量子计算商业准备就绪的谩骂可能会适得其反,产生意想不到的负面影响。
量子计算是一项相当长远的探索,政府、政策制定者和投资者应对此有清醒的认识。
参考链接:
[1]https://arxiv.org/abs/2305.09518
[2]https://arxiv.org/abs/2202.03459
[3]https://arxiv.org/abs/2101.08448
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!