《Java 已死、前端已凉》 我的评价是:中肯的
《Java 已死、前端已凉》 我的评价是:中肯的
如题所述
此次包含了前端、后端开发
以下为论述:
文章目录
前端
前端说白了就是网页界面、上位机等设计
目前市场上喜欢把HTML设计与前端混淆
前者只是HTML语言+CSS控件等等 后者需要JS与后端交互等等
前者严格意义上来说我觉得不算程序员 应该算“网页设计师” 而不是“前端工程师”
后者才是真正的前端工程师
后端
狭义的后端只是指与前端交互的部分
但广义上也包含了算法、数据库、任务调度、服务器、网络、云计算、下位机等
所以 后端工程师需要了解全栈的知识才有一席之地 我说的没错吧
当前环境
自从计算机专业爆火以来 前端由于其简单易上手 甚至很多地方都不需要逻辑上的编程 所以各大相关培训班如雨后春笋 纷纷建立
各个专业跳槽计算机都是首选前端
另外 前端环境基本上没什么变化 开发手段大同小异 无非就是适配的问题
既不像人工智能算法模型版本更新 也不像底层嵌入式开发各种芯片环境
以目前来看 基本已饱和
就拿我公司最近参与的一次招聘会看:
都是一个前后端开发培训班包车来的 一个个全是什么智能图书馆智能教室项目开发
所以 招你和招他到底有什么区别呢?
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
压缩Packed-ASCII字符串
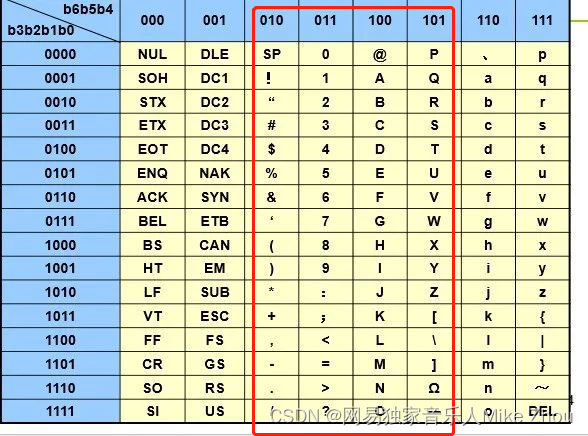
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(buf,0,str_len/4*3);
for(i=0;i<str_len;i++)
{
if(str[i]==0x00)
{
str[i]=0x20;
}
}
for(i=0;i<str_len/4;i++)
{
buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);
buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);
buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);
}
return 1;
}
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(str,0,str_len);
for(i=0;i<str_len/4;i++)
{
str[4*i]=(buf[3*i]>>2)&0x3F;
str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);
str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);
str[4*i+3]=buf[3*i+2]&0x3F;
}
return 1;
}
大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};
memcpy(&dat,buf,4);
float f=0.0f;
f=*((float*)&dat); //地址强转
printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40};
float f=0.0f;
memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&dat); //大小端转换
f=*((float*)&dat); //地址强转
printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&f); //大小端转换
printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
float f=0.0f;
dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)
f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{
uint16_t *ptr=p;
uint16_t x = *ptr;
x = (x << 8) | (x >> 8);
*ptr=x;
}
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
void swap64(void * p)
{
uint64_t *ptr=p;
uint64_t x = *ptr;
x = (x << 32) | (x >> 32);
x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);
x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);
*ptr=x;
}
附录:列表的赋值类型和py打包
列表赋值
BUG复现
闲来无事写了个小程序 代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
我在程序中 做了一个16次的for循环 把列表a的每个值后面依次加上"_"和循环序号
比如循环第x次 就是把第x位加上_x 这一位变成x_x 我在输出测试中 列表a的每一次输出也是对的
循环16次后列表a应该变成[‘0_0’, ‘1_1’, ‘2_2’, ‘3_3’, ‘4_4’, ‘5_5’, ‘6_6’, ‘7_7’, ‘8_8’, ‘9_9’, ‘10_10’, ‘11_11’, ‘12_12’, ‘13_13’, ‘14_14’, ‘15_15’] 这也是对的
同时 我将每一次循环时列表a的值 写入到空列表c中 比如第x次循环 就是把更改以后的列表a的值 写入到列表c的第x位
第0次循环后 c[0]的值应该是[‘0_0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘10’, ‘11’, ‘12’, ‘13’, ‘14’, ‘15’] 这也是对的
但是在第1次循环以后 c[0]的值就一直在变 变成了c[x]的值
相当于把c_list[0]变成了c_list[1]…以此类推 最后得出的列表c的值也是每一项完全一样
我不明白这是怎么回事
我的c[0]只在第0次循环时被赋值了 但是后面它的值跟着在改变
如图:
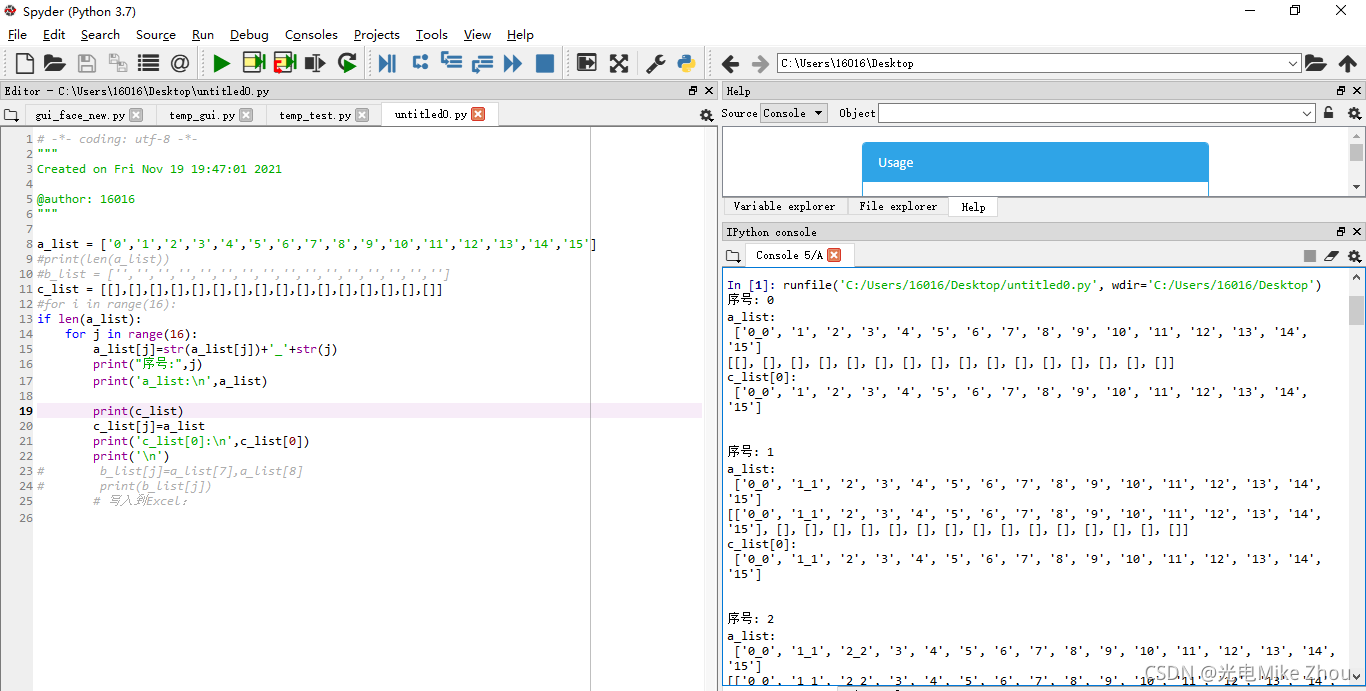
第一次老出bug 赋值以后 每次循环都改变c[0]的值 搞了半天都没搞出来
无论是用appen函数添加 还是用二维数组定义 或者增加第三个空数组来过渡 都无法解决
代码改进
后来在我华科同学的指导下 突然想到赋值可以赋的是个地址 地址里面的值一直变化 导致赋值也一直变化 于是用第二张图的循环套循环深度复制实现了
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
for i in range(16):
c_list[j].append(a_list[i])
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
print(c_list,'\n')
解决了问题
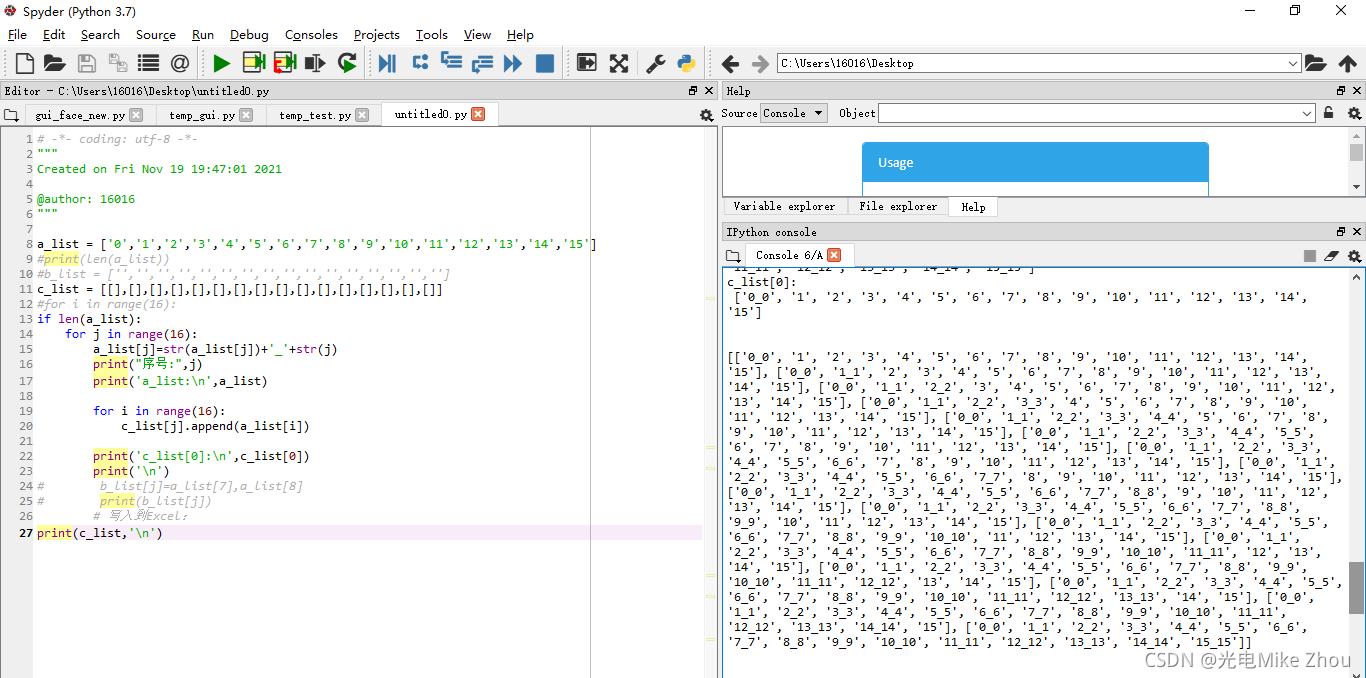
优化
第三次是请教了老师 用copy函数来赋真值
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list.copy()
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
同样能解决问题
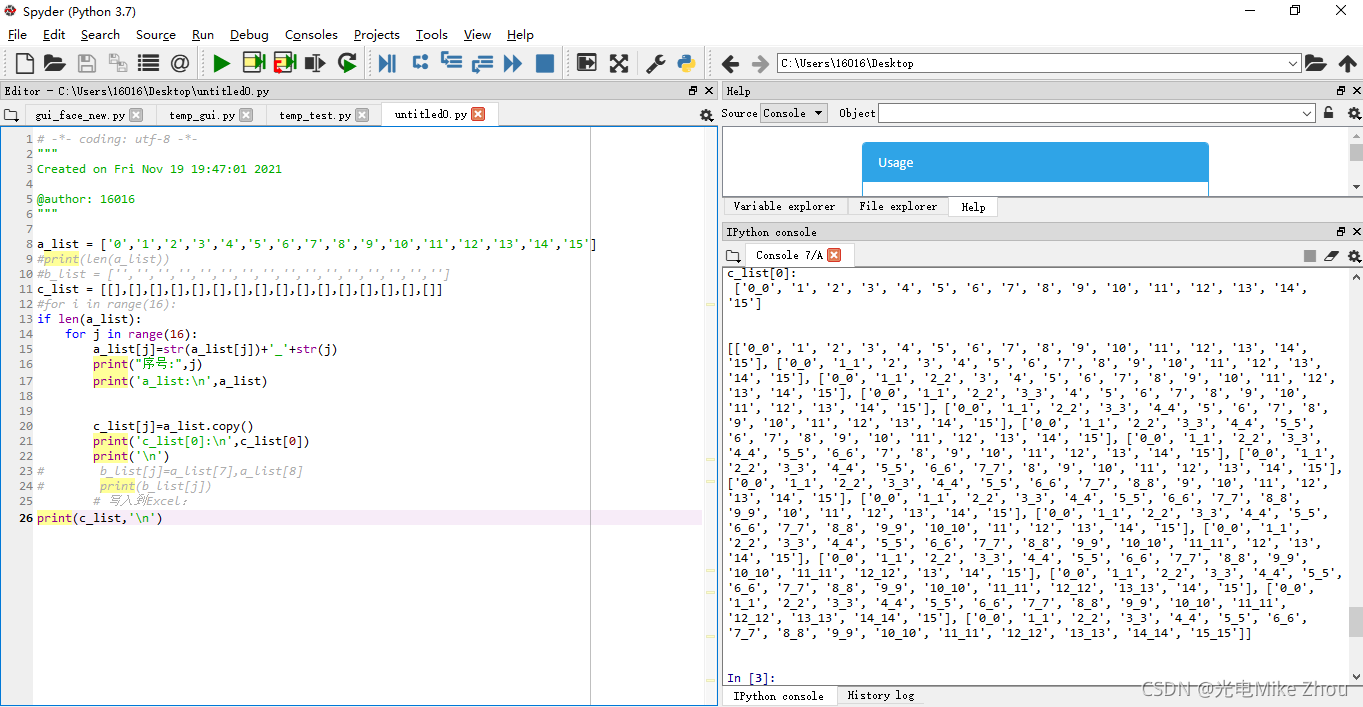
最后得出问题 就是指针惹的祸!
a_list指向的是个地址 而不是值 a_list[i]指向的才是单个的值 copy()函数也是复制值而不是地址
如果这个用C语言来写 就直观一些了 难怪C语言是基础 光学Python不学C 遇到这样的问题就解决不了
C语言yyds Python是什么垃圾弱智语言
总结
由于Python无法单独定义一个值为指针或者独立的值 所以只能用列表来传送
只要赋值是指向一个列表整体的 那么就是指向的一个指针内存地址 解决方法只有一个 那就是将每个值深度复制赋值(子列表内的元素提取出来重新依次连接) 或者用copy函数单独赋值
如图测试:
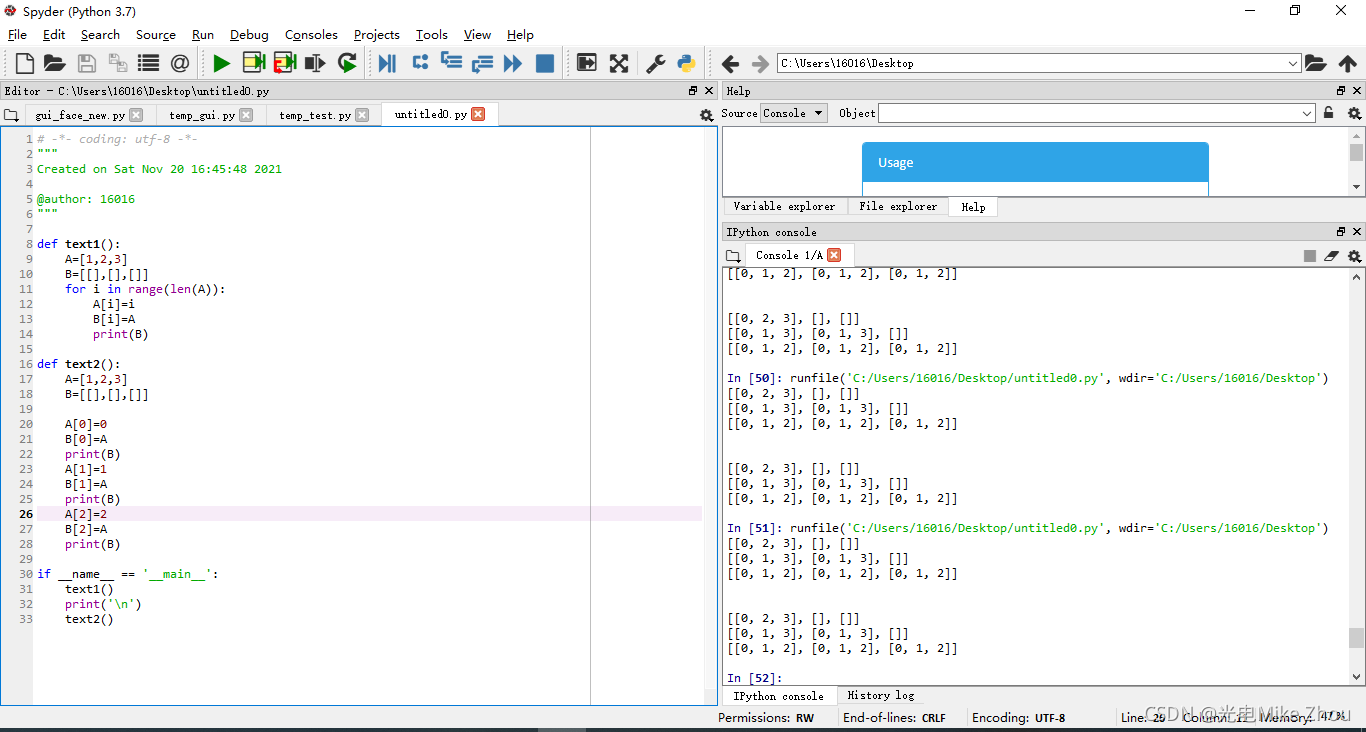

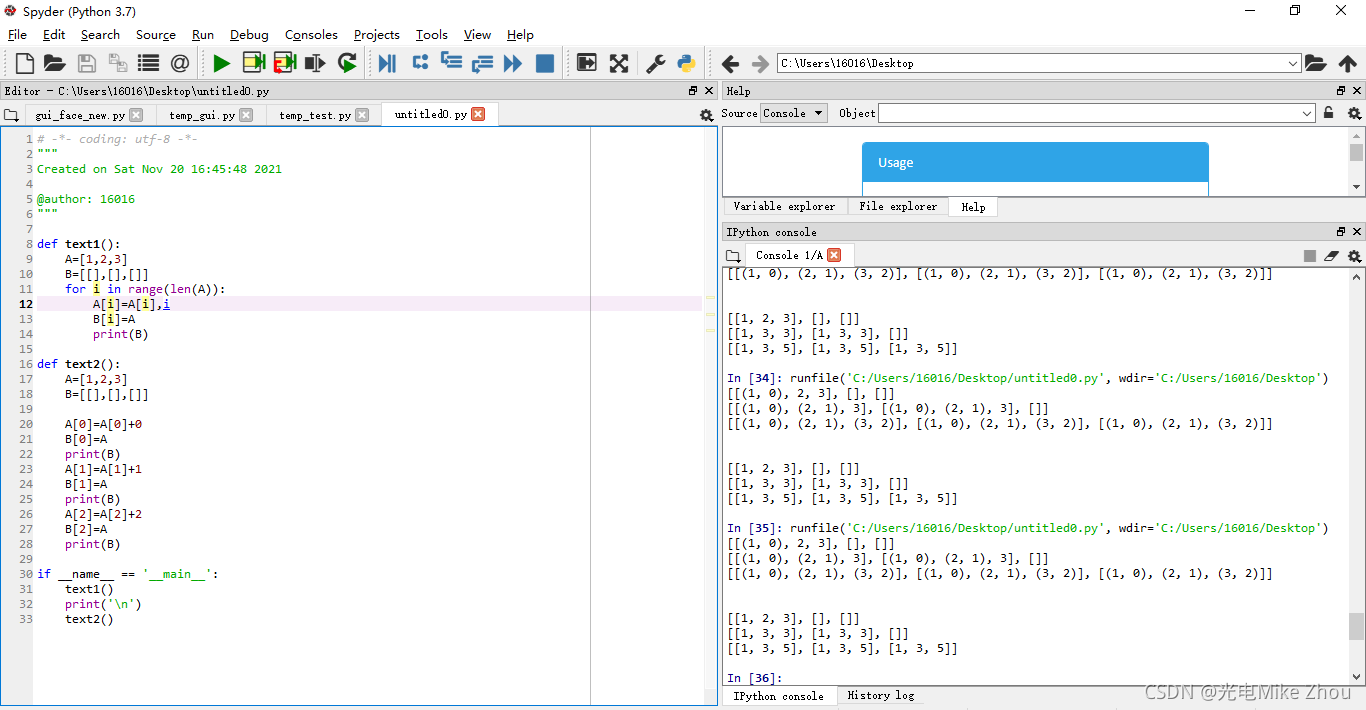
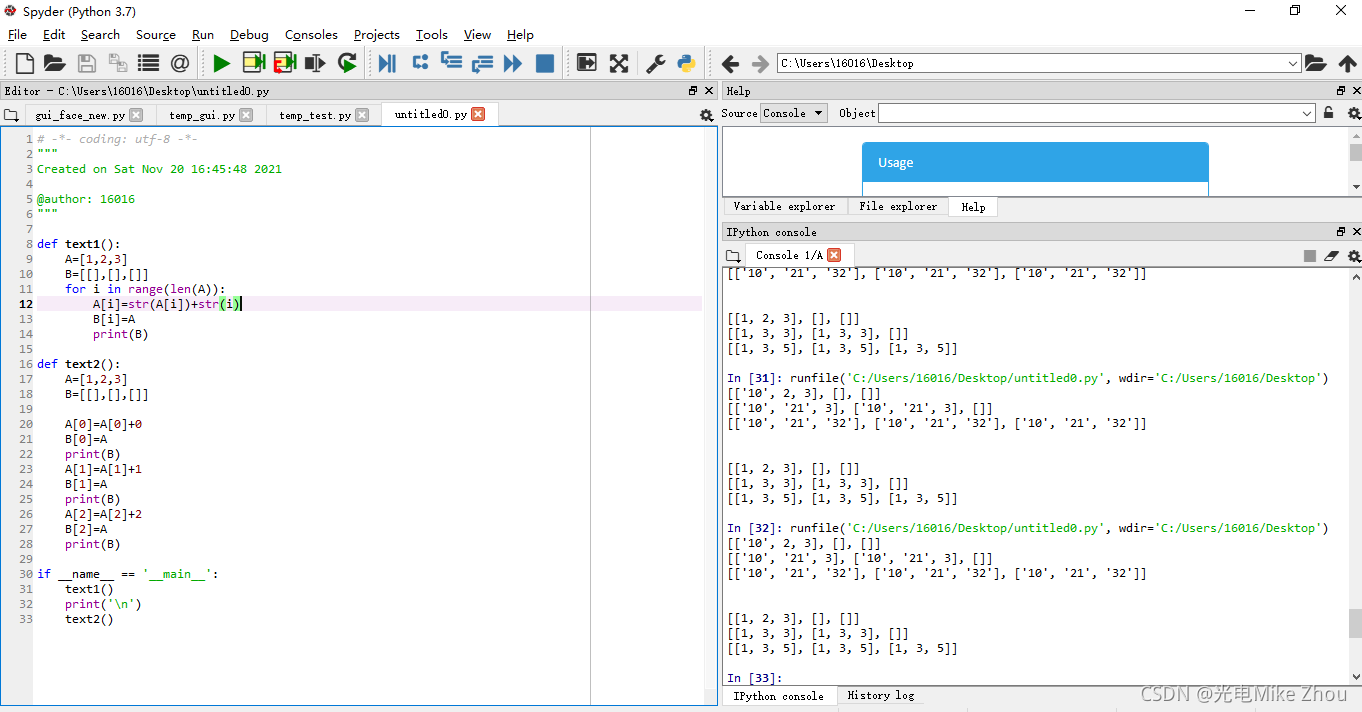
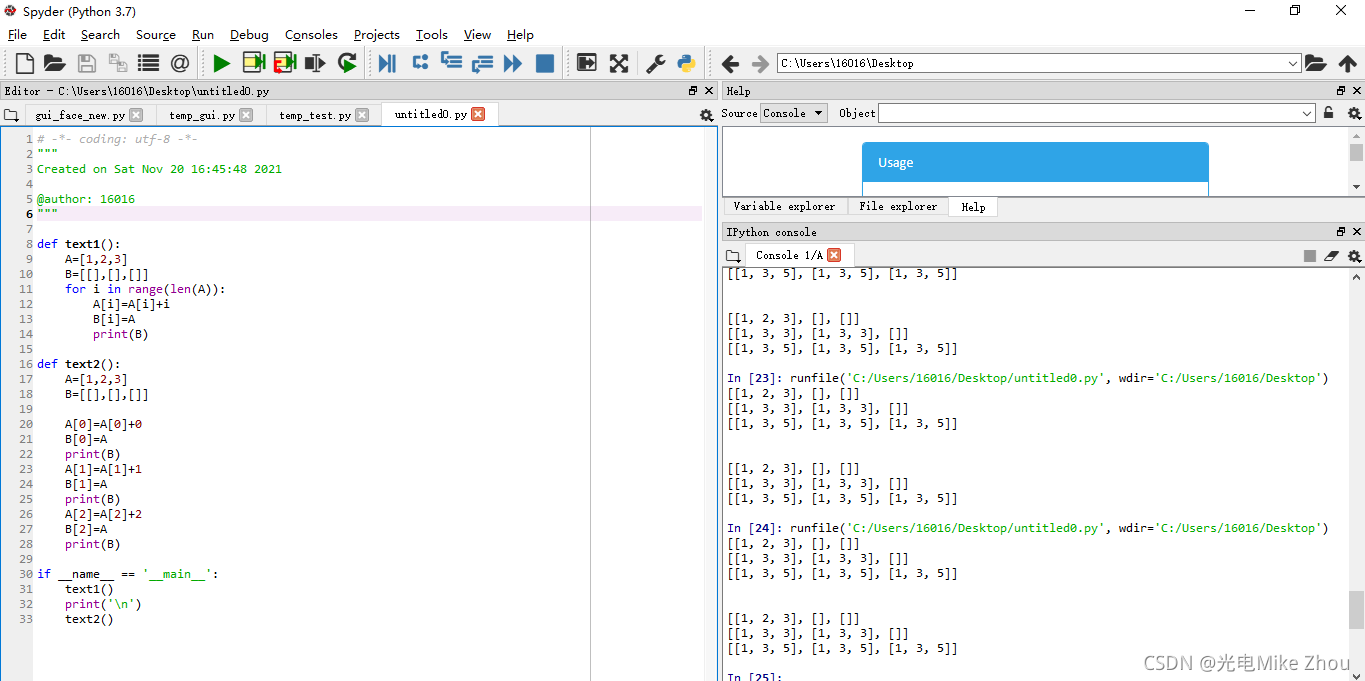
部分代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 20 16:45:48 2021
@author: 16016
"""
def text1():
A=[1,2,3]
B=[[],[],[]]
for i in range(len(A)):
A[i]=A[i]+i
B[i]=A
print(B)
def text2():
A=[1,2,3]
B=[[],[],[]]
A[0]=A[0]+0
B[0]=A
print(B)
A[1]=A[1]+1
B[1]=A
print(B)
A[2]=A[2]+2
B[2]=A
print(B)
if __name__ == '__main__':
text1()
print('\n')
text2()
py打包
Pyinstaller打包exe(包括打包资源文件 绝不出错版)
依赖包及其对应的版本号
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py 打包exe
Pyinstaller -F -w setup.py 不带控制台的打包
Pyinstaller -F -i xx.ico setup.py 打包指定exe图标打包
打包exe参数说明:
-F:打包后只生成单个exe格式文件;
-D:默认选项,创建一个目录,包含exe文件以及大量依赖文件;
-c:默认选项,使用控制台(就是类似cmd的黑框);
-w:不使用控制台;
-p:添加搜索路径,让其找到对应的库;
-i:改变生成程序的icon图标。
如果要打包资源文件
则需要对代码中的路径进行转换处理
另外要注意的是 如果要打包资源文件 则py程序里面的路径要从./xxx/yy换成xxx/yy 并且进行路径转换
但如果不打包资源文件的话 最好路径还是用作./xxx/yy 并且不进行路径转换
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
而后再spec文件中的datas部分加入目录
如:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
而后直接Pyinstaller -F setup.spec即可
如果打包的文件过大则更改spec文件中的excludes 把不需要的库写进去(但是已经在环境中安装了的)就行
这些不要了的库在上一次编译时的shell里面输出
比如:

然后用pyinstaller --clean -F 某某.spec
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!